一种高性能静态随机存储器比特单元结构的制作方法
1.本发明涉及场效应晶体管技术领域,具体为一种高性能静态随机存储器比特单元结构。
背景技术:
2.静态随机存取存储器(sram)是随机存取存储器的一种,其包含有用于cpu/gpu计算缓存的比特单元,比特单元占整个集成电路芯片面积的30%~60%左右。静态随机存取存储器中使用较多的是6t静态随机存储器(6thdsram),主要用在三级或二级缓存,其中小部分的是6t高性能静态随机存储器(6thcsram),主要用在二级或一级缓存。
3.用于衡量6thcsram的比特单元(bitcell)的技术指标主要包括速度、功耗、单元面积等,也是用于衡量各个逻辑工艺技术节点的关键技术指标。6thcsram对密度、数据存储量要求不高,但对速度要求较高,因此对6thcsram工艺进行改善,提高其结构合理性,是提高6thcsram的速率性能的主要方式,但现有技术中在22纳米场效应晶体管工艺上实现6t高性能静态随机存储器的比特单元仍存在结构设计不合理、速度性能低等问题,例如中国台湾积体电路制造股份(tsmc)提供了一种22nm平面晶体管(ulp)的6thcsrambitcell,其速度性能为28nmhpc+的srambitcell的100%、功耗为70%、单元成本为89%,可见其速度性能相对于28nmhpc+的srambitcell未得到提升;英特尔(intel)公司提供了一种22nmfinfet的6thcsrambitcell,其速度性能为28nmhpc+的srambitcell的105%、功耗为27%、成本为121%,其速度性能相对于28nmhpc+的srambitcell有所提升,同时功耗降低,但其成本较高,因此,现有技术中srambitcell仍存在速度性能低、功耗、成本无法得到同时优化等问题。
技术实现要素:
4.针对现有技术中存在的22nm场效应晶体管工艺上实现的静态随机存储器比特单元中存在结构设计不合理,导致其速度性能低,功耗和成本无法得到同时优化的问题,本发明提供了一种高性能静态随机存储器比特单元结构,其结构设计合理,可提高比特单元的速度性能,同时可降低功耗和成本。
5.为实现上述目的,本发明采用如下技术方案:
6.一种高性能静态随机存储器比特单元结构,其包括衬底、分布于所述衬底表面的鳍片、分布于所述鳍片的栅极区、光刻胶层、接触层、读取比特线,所述比特单元包括鳍形场效应晶体管,所述栅极区长度为22nm;其特征在于,所述鳍片包括六根,且依次间隔平行分布,设相邻两根鳍片之间的鳍间距为fp,鳍高度为fh,所述鳍间距fp最小为42nm,所述鳍高度fh最小为55nm,单个所述鳍对应有效沟道宽度为118nm。
7.其进一步特征在于,
8.六根所述鳍片包括依次分布的第一鳍片~第六鳍片,所述第一鳍片、第六鳍片位于两侧,第二鳍片、第五鳍片分布于所述第一鳍片、第六鳍片之间,第三鳍片、第四鳍片分布
于所述第二鳍片、第五鳍片之间,所述第三鳍片的尾部、第四鳍片的首部均为切割区;
9.所述鳍形场效应晶体管为pmos管;
10.所述鳍形场效应晶体管为体硅鳍形场效应晶体管,所述衬底为硅(si)衬底;
11.所述比特单元的有源区竖向总宽度(即鳍间距方向总宽度)为10*fp,所述鳍间距fr为42nm,则所述有源区竖向总宽度10*fp为420nm;
12.设接触层间距为cpp,有源区横向总宽度(即栅极区间距方向总宽度)为 2*cpp;
13.所述接触层间距cpp为110nm,则所述有源区横向总宽度为 2*cpp=220nm;
14.所述比特单元的有源区面积为(10*fp)*(2*cpp),所述比特单元有源区的最小面积为0.0924μm2。
15.采用本发明上述结构可以达到如下有益效果:1、该静态随机存储器比特单元结构包括六根鳍片,相邻两个鳍片之间的鳍间距为fp、鳍高度为fh,鳍间距fp最小为42nm,鳍高度fh最小为55nm,单个所述鳍对应有效沟道宽度为 118nm,相比于现有的tsmc公司的22纳米ulp的6t hc sram bitcell,鳍高度为37nm,英特尔(intel)公司22纳米finfet的6t hc sram bitcell,鳍高度为34nm,在鳍宽度相等条件下,本技术比特单元的鳍高度增大,使得比特单元有效宽度增大,鳍片中单位面积内通过的电流增多,从而提高了静态随机存储器比特单元的电流传输速度,即提高了比特单元的速度性能。
16.2、该结构的比特单元中,在22nm鳍形场效应晶体管工艺上实现的静态随机存储器比特单元的速度性能可以达到157%,功耗为27%,成本为68%,相比于现有的tsmc公司的22纳米ulp sram bitcell、英特尔(intel)公司22 纳米finfet sram bitcell,本技术比特单元有效宽度增大,速度性能有效提升,同时功耗和成本大大降低,因此,采用本技术比特单元结构,使其在高速度性能、低功耗、低成本三个方面同时得到了优化。
附图说明
17.图1为tsmc公司包含有22纳米ulp静态随机存储器比特单元的鳍片分布的俯视结构示意图;
18.图2为英特尔(intel)公司包含有22纳米finfet静态随机存储器比特单元的鳍片分布的俯视结构示意图;
19.图3为本发明包含有22纳米finfet的静态随机存储器比特单元的鳍片分布的俯视结构示意图;
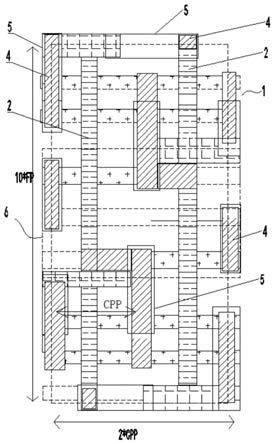
20.图4为本发明静态随机存储器比特单元的俯视结构示意图。
具体实施方式
21.见图4,一种高性能静态随机存储器比特单元结构,其包括衬底、分布于衬底表面的鳍片1、分布于鳍片1的栅极区2、光刻胶层14、接触层4、读取比特线5,衬底为硅,该比特单元包括22nm鳍形场效应晶体管6,鳍形场效应晶体管6为pmos管,包括两根鳍片、栅极区、接触层、读取比特线的部分区域;鳍片1包括六根:第一鳍片~第六鳍片,且依次间隔平行分布,第一鳍片、第六鳍片位于两侧,第二鳍片、第五鳍片分布于第一鳍片、第六鳍片之间,第三鳍片、第四鳍片分布于所述第二鳍片、第五鳍片之间,第三鳍片的尾部、第四鳍片的首部均为切割区。设相邻两根鳍片1之间的鳍间距为fp、鳍高度为fh、接触层间距为cpp,有源区
竖向总宽度即鳍间距方向总宽度为10*fp,鳍间距 fp为42nm,则有源区竖向总宽度为10*fp=420nm;见图3、图4,有源区竖向总宽度10*fp=1.25fp+1.75fp+2.0fp+1.75fp+2.0fp+1.25fp,有源区横向总宽度即栅极区间距方向总宽度为2*cpp,接触层间距cpp为110nm,则有源区横向总宽度为2*cpp=220nm,计算获取比特单元有源区的面积为(10*fp)* (2*cpp),即420nm*220nm=0.0924μm2,鳍高度fh为55nm,单个鳍对应有效沟道宽度为118nm。
22.将本技术在22纳米体硅鳍形场效应晶体管工艺上实现的静态随机存储器比特单元,与现有的tsmc公司22纳米ulp静态随机存储器比特单元、英特尔(intel)公司22纳米finfet静态随机存储器比特单元的速度性能、功耗、成本进行对比,图1为tsmc公司包含有22纳米ulp的静态随机存储器比特单元的鳍片分布情况,该比特单元中,有源区竖向总宽度为10fp1,10 fp1=1.0fp1+2.0fp1+2.0fp1+2.0fp1+2.0fp1+1.0fp1,有源区横向总宽度为 2*cpp1,cpp1=114.8,则2*cpp1=230nm,有源区面积为0.138μm2,鳍片间距 fp1为48nm,鳍片高度fh2为37nm;图2为英特尔(intel)公司22纳米finfet 的静态随机存储器比特单元的鳍片分布情况,该比特单元中,有源区竖向总宽度为10fp2,fp2=60nm。
23.10fp2=1.0fp2+2.0fp2+2.0fp2+2.0fp2+2.0fp2+1.0fp2=600nm,有源区横向总宽度为2*cpp2,cpp2为90nm,则2*cpp2=180nm,有源区面积为0.108μm2,鳍片间距fp2为60nm,鳍高度fh2为34nm,而本技术中,单个鳍对应有效沟道宽度为118nm,可见,本技术22nm finfet静态随机存储器比特单元的鳍高度、有效宽度大于tsmc公司、英特尔(intel)公司的比特单元的鳍高度、单个鳍对应有效沟道宽度。tsmc公司、英特尔(intel)公司与本技术22纳米晶体管的静态随机存储器比特单元尺寸结构及其效能、功耗、成本对比情况见表 1,tsmc公司22nm平面场效应晶体管(ulp)、英特尔(intel)公司的 22nmfinfet以及本技术22nm体硅鳍形场效应晶体管均是基于28hpc+通过光学微缩加工工艺优化获得。
24.表1,tsmc公司、英特尔(intel)公司与本技术包含有22纳米晶体管的静态随机存储器比特单元尺寸结构及其效能、功耗、成本对比情况
[0025][0026]
tsmc 22nm ulp、intel 22nm finfet、本技术22nmfinfet工艺的6t静态随机存储器比特单元的单位晶圆工艺成本、速度、功耗、有效区面积等均以 28nmhpc+为基准,从表1也可以看出,本技术中比特单元的最小面积是0.0924 μm2,是28nmhpc+的60%,单位晶圆工艺成本是28nmhpc+的114%,比特单元工艺成本是28nmhpc+的68%,鳍片宽度为8nm、鳍片高度为55nm,单个鳍片对应有效沟道宽度为118nm,其实现的比特单元的器件速度是 28nmhpc+的157%,其实现的比特单元的功耗是28nmhpc+的27%,因此相比于tsmc 22nm ulp sram bitcell和intel 22nm finfet sram bitcell,本技术比特单元的单个鳍片对应有效沟道宽度增大,速度性能提高,速度提高了约40%,功耗同样低、单元成本近似,因此,本技术静态随机存储器比特单元结构在高性能、低功耗、低成本三个方面同时达到了优化。
[0027]
一种用于加工上述高性能静态随机存储器比特单元的方法,该方法基于自对准双重图形转移工艺实现,采用自对准双重图形转移工艺,获取包含有六根鳍片、且相邻两根所述鳍片之间的鳍间距为fp的比特单元,在自对准双重图形转移工艺中,在衬底上做出非均匀的光刻胶层,本技术比特单元需要五个非均匀光刻胶层产生六根所述鳍片。采用光刻工艺进行鳍片切除,即采用光刻机的光罩进行鳍片切除,获取六根鳍片及第三鳍片的尾部、第四鳍片的首部的切割区;光罩为arv、arh。
[0028]
本技术中,比特单元需要五个非均匀光刻胶层产生十个鳍片,采用光刻工艺,即采
用光刻机的光罩进行鳍片切除,获取六根鳍片,并对第三鳍片尾部、第四鳍片首部的切割区进行切除。现有的tsmc公司、intel公司的比特单元 22nm finfet静态随机存储器比特单元的鳍制作工艺中,均采用了通过五个均匀的光刻胶层产生十根鳍的方式,其中鳍片切除均需要两张光罩arh(主动水平移动光罩)、arv(主动垂直移动光罩)实现鳍片切除(图1、图2中虚线构成的鳍片为需要切除的鳍片),在本技术工艺方法中,整个比特单元同样需要五个非均匀光刻胶层形成十根鳍片,并且需要两个光罩arh(主动水平移动光罩)、arv(主动垂直移动光罩)实现鳍片切除(图3中虚线构成的鳍片为需要切除的鳍片)。从表1可以看出,相比于tsmc公司、intel公司的22nmfinfet静态随机存储器比特单元的鳍制作工艺,本技术加工工艺简化,降低了功耗和投入成本,并且从图3、图4可以看出,本技术加工工艺方法使bitcell 上下单元之间的多晶硅切割线区的工艺窗口由2.0*fp增大到2.5*fp,更便于加工工艺的实现。
[0029]
以上的仅是本技术的优选实施方式,本发明不限于以上实施例。可以理解,本领域技术人员在不脱离本发明的精神和构思的前提下直接导出或联想到的其他改进和变化,均应认为包含在本发明的保护范围之内。
相关技术
网友询问留言
已有0条留言
- 还没有人留言评论。精彩留言会获得点赞!
1