基于误差修正和提升小波组合预测模型的风电功率预测方法与流程
本发明属于电力系统预测与控制技术领域,尤其涉及一种基于误差修正和提升小波组合预测模型的风电功率预测方法。
背景技术:
随着风电技术的不断发展和风电场的规模不断增大,为了保证电力系统的稳定运行和供电可靠性,必须对风电系统进行有效的规划和调度。风电本身所特有的间歇性和不确定性,增加了电网调度的难度,增加了电力企业安排电网发电机组的起停和制订机组检修计划的难度,所以需要对风电场的输出功率进行预测。只有通过对风电场发电功率进行准确的预测,才可以有效降低风力发电系统的运行成本,为电网调度运行提供可靠依据。
风电功率预测方法根据不同的预测物理量可分为两大类:(1)先预测风速,再依据风电机组或者风电场的功率曲线从而获得风电场的输出功率;(2)直接预测风场的输出功率。这里直接选择输出功率为预测目标,该类方法可以简单的分为两大类。第ⅰ类是基于确定性时序模型的预测方法,该类方法通过找出风电功率历史数据本身在时间上的相关性来进行风电功率预测,常用方法有:卡尔曼滤波法、时间序列法(arma)、指数平滑法等。第ⅱ类是基于智能模型的预测方法,其实质是根据人工智能方法提取风电功率变化特性,进而进行风电功率预测。常用的方法有:人工神经网络法、小波分析法、最小二乘支持向量机(lssvm)回归法和模糊逻辑法等。上述方法都有各自的优点,但也有很多局限性。在预测的过程中,不同的预测对象往往具有不同的特点,在选择预测方法时也是根据不同的特点选择最适合的预测方法,以提高预测精度。当预测对象受随机性太大,单一的预测方法已经不能满足其预测精度,这就可以用多种预测方法同时预测。
而现有的风电功率预测误差分析和补偿方法主要分为两类:一类是直接通过模型预测获得下一时刻误差预测值,进而对误差进行补偿和修正;另一类是应用统计方法对某一时期风电功率预测误差的概率密度曲线进行模型拟合,根据误差概率密度特征对未来误差进行估计。在第1类方法中,研究人员通过模型预测对误差数据时间及幅值特性进行分析。这类方法在结合误差数据特征的基础上进行未来误差模型预测而得到的结果精度比较有限,尤其是在误差产生大幅波动的情况下,其分析能力具有较大局限性。在第2类方法中,通常情况下风电功率预测误差幅值概率密度被假设为服从正态分布,这种假设是根据大多数预测方法和时间尺度而得到的。但是在很多情况下,尤其是在风电并网容量较大时,正态分布并不能很好的描述误差分布。而现有研究的概率分布模型拟合精度方面存在不足,并且单纯通过概率分布拟合估计预测误差的效果有限。
技术实现要素:
本发明的目的在于针对现有技术的不足,提供一种基于误差修正和提升小波组合预测模型的风电功率预测方法,运用提升小波来处理历史数据,不仅可以提取数据的主要特性,还能达到消除噪声的效果,使其适用于各种预测算法,而组合预测模型算法是根据数据特征来选取预测模型,则可以消除单一预测方法的不足。本发明还对预测误差进行分析来修正预测结果,消除大的误差偏差,达到风电功率预测结果更加精确的效果。
为了实现上述目的,本发明提供了一种基于误差修正和提升小波组合预测模型的风电功率预测方法,具体包括以下步骤:
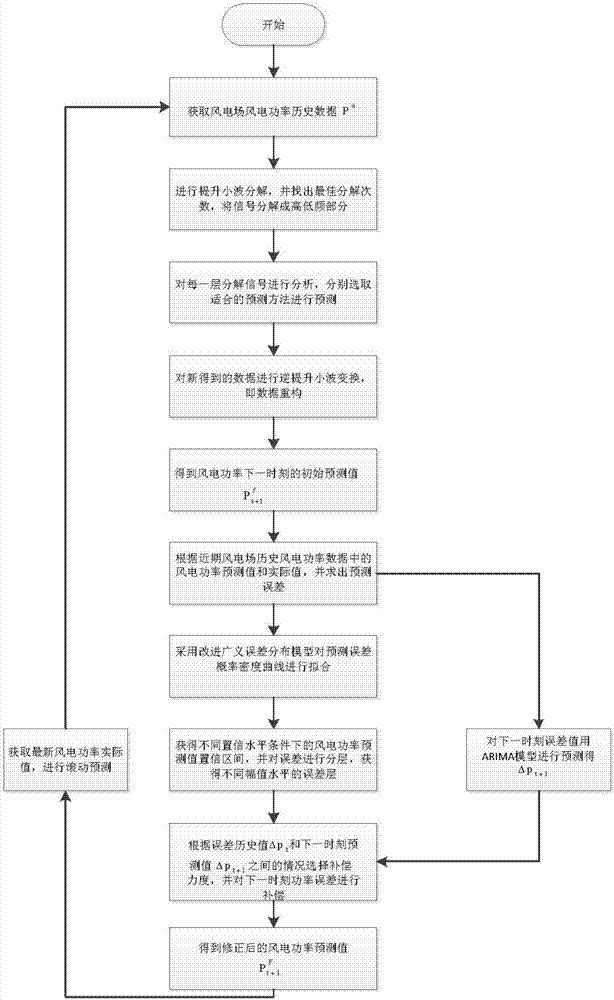
步骤一,获取风电功率历史数据,对风电功率历史数据进行提升小波分解的预处理,将数据信号分解为高频部分和低频部分;
步骤二,根据高低频部分信号的特性分别选择灰色预测模型、差分自回归滑动平均(arima)模型和最小二乘支持向量机(lssvm)回归模型中的一个模型来建立其对应的预测模型;
步骤三,将预测模型的预测数据进行数据重构,得到风电功率的预测初值;
步骤四,利用风电场风电功率历史数据的预测初值和实际值得到历史预测误差值,进而得到预测误差概率密度曲线,采用改进广义误差分布模型对预测误差概率密度曲线进行拟合,得到概率密度拟合模型;
步骤五,利用概率密度拟合模型计算出在不同置信水平下的风电功率预测值置信区间,并对误差进行分层;
步骤六,根据历史预测误差值,采用差分自回归移动平均模型对历史数据的最后一个时刻t的下一个时刻t+1的误差值进行预测;
步骤七,根据t+1时刻的误差预测值及t时刻的误差值在误差层中所处位置,选择不同的补偿力度对t+1时刻的误差值进行补偿,从而修正t+1时刻的风电功率预测初值,得到t+1时刻的预测结果;
步骤八,获取最新风电功率实际值,对误差和风电功率值进行滚动预测。
进一步地,所述步骤一中,首先获取风电场风电功率的实际值pactual和预测初值pforecast,而实际值pactual的数据序列可用pa表示,设
再通过提升小波分解风电功率的实际值数据,获取数据特性,使得数据更有利于建模预测。而提升小波算法通过构造双正交小波函数,使用线性、非线性或空间变化的预测和更新算子进行提升变换,而且确保了变换的可逆性。
所述步骤一中,提升小波分解的预处理步骤具体如下:
1)分裂:将风电功率实际值pa分割成相互关联的奇偶两部分,即
其中k=1,2,...,[n/2],[n/2]为取n/2的整数部分;
2)预测:用
式中,预测算子p可用预测函数
则
3)更新:经过分裂步骤产生子集的某些整体特征可能与原始数据并不一致,为了保持风电功率数据的这些整体特征,需要一个更新的过程。将更新过程用算子u来代替,其过程为:
式中,s1是pa的低频部分,更新算子u可以用函数uk()表示,即:
uk(d1)={d1,1/2,d1,2/2,...,d1,k/2},k=1,2,...,[n/2](5)
经提升小波分解,可将风电功率数据pa分解为低频部分s1和高频部分d1,对于低频数据子集s1可以再进行相同的分裂、预测和更新,把s1进一步分解成s2和d2;…;如此下去,经过n次分解后,风电功率数据pa的小波表示为{sn,dn,dn-1,…,d1}。其中sn代表了风电功率数据的低频部分,而{dn,dn-1,…,d1}则是功率数据从低到高的高频部分系列。
进一步地,所述步骤二中,根据步骤一所得每一个高频分量和低频分量的特性分别选择灰色预测模型、差分自回归滑动平均(arima)模型和最小二乘支持向量机(lssvm)回归模型中的一个模型来建立其对应的预测模型。低频分量变化较平缓且波动小,适合选用灰色预测法预测。高频分量代表原始信号中随机性最强的突然波动且无规律可循,而最小二乘支持向量机回归模型具有很强的泛化性,可对高频分量进行训练预测。对于高频信号中的周期序列则可选用arima模型进行预测。
进一步地,所述步骤三中,数据重构,即提升小波的反变换过程,可以用替代的方式来计算:
merge()即将奇序列和偶序列
进一步地,所述步骤四中,首先根据风电场历史风电功率数据中的风电功率预测初值pforecast和实际值pactual求出预测误差δp,即:
再算出风电功率预测误差的标幺值x(也是相对于总装机容量的相对误差),即x=(pforecast-pactual)/pbase=δp/pbase,其中pbase是样本数据系统所接入的风电装机总容量。再根据每个预测点的误差标幺值的概率密度来得到其概率密度曲线。
使用改进广义误差分布模型来拟合预测误差概率密度曲线,改进广义误差分布模型概率密度函数为:
其中v和λ为形状参数;γ(·)为伽马函数。公式(8)中计算得到参数λ决定了曲线总体形状的平坦与陡峭程度,斜度参数α剥离了曲线斜度和峰度的关系使得曲线变化更具有灵活性,位置参数μ可以使模型具有拟合带偏度曲线的能力。
该模型的参数估计的方法确定:由于本文所研究的概率分布模型大部分为指数形式,故采用极大似然估计(mle)法对模型参数进行估计。这样可以通过最大化对数似然值(log-likelihood,ll),将样本数据与模型参数的关系进行转变,便于参数估计。
进一步地,所述步骤五中,在确定误差概率密度的拟合模型后,根据分析对象数据特征选取一低一高两个不同的置信度水平
在大多数情况下,预测误差概率密度曲线是可以看作对称的,所以计算单侧概率密度累积值f可以判断总体误差水平。
进一步地,所述步骤六中,根据历史预测误差值,采用差分自回归移动平均(arima)模型对历史数据的最后一个时刻t的下一个时刻t+1的误差值进行预测;arima是由三部分组成:自回归项(ar)、差分项(i)和滑动平均模型(ma),是在自回归滑动平均(arma)模型的基础上提出来的。
arma数学表达式如下:
式中,δpt+1是t+1时刻风电功率预测误差值的预测值;
一个风电功率预测误差值时间序列在某时刻可以用p个历史观测值的线性组合加上一个白噪声序列的q项滑动平均来表示,则该时间序列为arma(p,q)过程。
使用自回归滑动平均模型时,首先判断风电功率预测误差值序列δp是否为平稳序列,若非平稳序列,则通常使用差分使之变为平稳序列,即arima过程。之后根据数据的自相关和偏相关系数进行模式识别,再由最小信息准则(aic)进行模型定阶。最后由arma模型的表达公式,即可估计出模型的参数值。
进一步地,所述步骤七中,由于在t+1刻误差值的预测过程中,已经考虑过去几个时刻的风电功率预测历史误差值。因而,在进行分层补偿时只需要根据t+1时刻的误差预测值及t时刻的误差值在误差层中所处位置,选择不同的补偿力度对t+1时刻的误差值进行补偿。
t+1时刻误差预测值相对于t时刻误差历史值可能会在同侧(正误差或负误差)的同一层之内或者在多误差层之间波动。为了防止产生补偿方法的误判,对误差预测值与误差历史值在不同层和不同侧做相应的补偿办法。补偿情况基于如下:
1、当误差预测值在单侧波动
当t时刻误差历史值δpt和误差预测值δpt+1均处于单侧同一误差层内时,此时的误差波动较小,只需要对误差预测值进行等幅反向补偿即可。即当两者都处于小误差层时,说明误差较小,则不进行补偿;当两者都处于中误差层或是大误差层时则对误差预测值进行等幅反向补偿。
2、误差预测值在层间波动
误差预测值可能会在正负误差两侧各3个误差层之间任意波动,因此对于误差预测值的层间波动不能仅考虑误差预测值(t+1时刻)的幅值大小,还应该考虑未来误差(t+2时刻)的发展趋势。此时,本文引入δpt和δpt+1连线斜率
式中|ψ1-ψ2|为由拟合模型和置信度水平确定的单侧置信区间临界值之差的绝对值。
当δpt和δpt+1均在双侧的小误差层中时,对风电功率预测误差不进行补偿。当δpt+1处于双侧任一小误差层而δpt不在小误差层中时,虽然误差仍具有较大的变化趋势,但是无法排除未来误差持续处于小误差层的情况,因此也不再进行补偿。除了以上两种特殊情况外,误差预测值均按照表1中的补偿方式和补偿幅度进行补偿。
表1误差预测值处于层间波动时的补偿方法
当
进一步地,所述步骤八中,获取下一时刻的风电功率实际值,将其和预测值一起当作新的历史数据,并丢弃历史数据中的第一个历史数据。则第i+1次滚动预测所利用的数据序列为
本发明的有益效果为:
(1)该发明利用提升小波分解技术处理风电功率历史数据,不仅可以提取功率数据序列的主要特性,得到特征更加明显的各频率分量,还能达到消除噪声的效果,使其更适用于各种预测算法。而根据各高低频分量的特性来选择适应的预测模型,可以消除单一预测方法的不足,并能大大的提高预测精度。
(2)该发明利用误差分层分析方法来处理误差的修正,相对于直接用预测模型来获得下一时刻误差预测值,在误差产生大幅波动情况下,该方法更能精确的分析下一时刻误差情况及补偿力度,降低在误差的预测过程中带来的误差,从而降低整体预测方法的误差。
附图说明
图1为短期风电功率组合预测方法流程图;
图2为风电功率序列提升小波分解的流程图;
具体实施方式
下面结合附图与实施例对本发明的具体实施方式作进一步详细说明。
本发明提供的一种基于误差修正和提升小波组合预测模型的风电功率预测方法,具体包括以下步骤:
步骤一,获取风电功率历史数据,对风电功率历史数据进行提升小波分解的预处理,将数据信号分解为高频部分和低频部分;
步骤二,根据高低频部分信号的特性分别选择灰色预测模型、差分自回归滑动平均(arima)模型和最小二乘支持向量机(lssvm)回归模型中的一个模型来建立其对应的预测模型;
步骤三,将预测模型的预测数据进行数据重构,得到风电功率的预测初值;
步骤四,利用风电场风电功率历史数据的预测初值和实际值得到历史预测误差值,进而得到预测误差概率密度曲线,采用改进广义误差分布模型对预测误差概率密度曲线进行拟合,得到概率密度拟合模型;
步骤五,利用概率密度拟合模型计算出在不同置信水平下的风电功率预测值置信区间,并对误差进行分层;
步骤六,根据历史预测误差值,采用差分自回归移动平均模型对历史数据的最后一个时刻t的下一个时刻t+1的误差值进行预测;
步骤七,根据t+1时刻的误差预测值及t时刻的误差值在误差层中所处位置,选择不同的补偿力度对t+1时刻的误差值进行补偿,从而修正t+1时刻的风电功率预测初值,得到t+1时刻的预测结果;
步骤八,获取最新风电功率实际值,对误差和风电功率值进行滚动预测。
进一步地,所述步骤一中,首先获取风电场风电功率的实际值pactual和预测初值pforecast,而实际值pactual的数据序列可用pa表示,设
再通过提升小波分解风电功率的实际值数据,获取数据特性,使得数据更有利于建模预测。而提升小波算法通过构造双正交小波函数,使用线性、非线性或空间变化的预测和更新算子进行提升变换,而且确保了变换的可逆性。
所述步骤一中,提升小波分解的预处理步骤具体如下:
1)分裂:将风电功率实际值pa分割成相互关联的奇偶两部分,即
其中k=1,2,...,[n/2],[n/2]为取n/2的整数部分;
2)预测:用
式中,预测算子p可用预测函数
则
3)更新:经过分裂步骤产生子集的某些整体特征可能与原始数据并不一致,为了保持风电功率数据的这些整体特征,需要一个更新的过程。将更新过程用算子u来代替,其过程为:
式中,s1是pa的低频部分,更新算子u可以用函数uk()表示,即:
uk(d1)={d1,1/2,d1,2/2,...,d1,k/2},k=1,2,...,[n/2](5)
经提升小波分解,可将风电功率数据pa分解为低频部分s1和高频部分d1,对于低频数据子集s1可以再进行相同的分裂、预测和更新,把s1进一步分解成s2和d2;…;如此下去,经过n次分解后,风电功率数据pa的小波表示为{sn,dn,dn-1,…,d1}。其中sn代表了风电功率数据的低频部分,而{dn,dn-1,…,d1}则是功率数据从低到高的高频部分系列。
进一步地,所述步骤二中,根据步骤一所得每一个高频分量和低频分量的特性分别选择灰色预测模型、差分自回归滑动平均(arima)模型和最小二乘支持向量机(lssvm)回归模型中的一个模型来建立其对应的预测模型。低频分量变化较平缓且波动小,适合选用灰色预测法预测。高频分量代表原始信号中随机性最强的突然波动且无规律可循,而最小二乘支持向量机回归模型具有很强的泛化性,可对高频分量进行训练预测。对于高频信号中的周期序列则可选用arima模型进行预测。
进一步地,所述步骤三中,数据重构,即提升小波的反变换过程,可以用替代的方式来计算:
merge()即将奇序列和偶序列
进一步地,所述步骤四中,首先根据风电场历史风电功率数据中的风电功率预测初值pforecast和实际值pactual求出预测误差δp,即:
再算出风电功率预测误差的标幺值x(也是相对于总装机容量的相对误差),即x=(pforecast-pactual)/pbase=δp/pbase,其中pbase是样本数据系统所接入的风电装机总容量。再根据每个预测点的误差标幺值的概率密度来得到其概率密度曲线。
使用改进广义误差分布模型来拟合预测误差概率密度曲线,改进广义误差分布模型概率密度函数为:
其中v和λ为形状参数;γ(·)为伽马函数。公式(8)中计算得到参数λ决定了曲线总体形状的平坦与陡峭程度,斜度参数α剥离了曲线斜度和峰度的关系使得曲线变化更具有灵活性,位置参数μ可以使模型具有拟合带偏度曲线的能力。
该模型的参数估计的方法确定:由于本文所研究的概率分布模型大部分为指数形式,故采用极大似然估计(mle)法对模型参数进行估计。这样可以通过最大化对数似然值(log-likelihood,ll),将样本数据与模型参数的关系进行转变,便于参数估计。
进一步地,所述步骤五中,在确定误差概率密度的拟合模型后,根据分析对象数据特征选取一低一高两个不同的置信度水平
在大多数情况下,预测误差概率密度曲线是可以看作对称的,所以计算单侧概率密度累积值f可以判断总体误差水平。
进一步地,所述步骤六中,根据历史预测误差值,采用差分自回归移动平均(arima)模型对历史数据的最后一个时刻t的下一个时刻t+1的误差值进行预测;arima是由三部分组成:自回归项(ar)、差分项(i)和滑动平均模型(ma),是在自回归滑动平均(arma)模型的基础上提出来的。
arma数学表达式如下:
式中,δpt+1是t+1时刻风电功率预测误差值的预测值;
一个风电功率预测误差值时间序列在某时刻可以用p个历史观测值的线性组合加上一个白噪声序列的q项滑动平均来表示,则该时间序列为arma(p,q)过程。
使用自回归滑动平均模型时,首先判断风电功率预测误差值序列δp是否为平稳序列,若非平稳序列,则通常使用差分使之变为平稳序列,即arima过程。之后根据数据的自相关和偏相关系数进行模式识别,再由最小信息准则(aic)进行模型定阶。最后由arma模型的表达公式,即可估计出模型的参数值。
进一步地,所述步骤七中,由于在t+1刻误差值的预测过程中,已经考虑过去几个时刻的风电功率预测历史误差值。因而,在进行分层补偿时只需要根据t+1时刻的误差预测值及t时刻的误差值在误差层中所处位置,选择不同的补偿力度对t+1时刻的误差值进行补偿。
t+1时刻误差预测值相对于t时刻误差历史值可能会在同侧(正误差或负误差)的同一层之内或者在多误差层之间波动。为了防止产生补偿方法的误判,对误差预测值与误差历史值在不同层和不同侧做相应的补偿办法。补偿情况基于如下:
1、当误差预测值在单侧波动
当t时刻误差历史值δpt和误差预测值δpt+1均处于单侧同一误差层内时,此时的误差波动较小,只需要对误差预测值进行等幅反向补偿即可。即当两者都处于小误差层时,说明误差较小,则不进行补偿;当两者都处于中误差层或是大误差层时则对误差预测值进行等幅反向补偿。
2、误差预测值在层间波动
误差预测值可能会在正负误差两侧各3个误差层之间任意波动,因此对于误差预测值的层间波动不能仅考虑误差预测值(t+1时刻)的幅值大小,还应该考虑未来误差(t+2时刻)的发展趋势。此时,本文引入δpt和δpt+1连线斜率
式中|ψ1-ψ2|为由拟合模型和置信度水平确定的单侧置信区间临界值之差的绝对值。
当δpt和δpt+1均在双侧的小误差层中时,对风电功率预测误差不进行补偿。当δpt+1处于双侧任一小误差层而δpt不在小误差层中时,虽然误差仍具有较大的变化趋势,但是无法排除未来误差持续处于小误差层的情况,因此也不再进行补偿。除了以上两种特殊情况外,误差预测值均按照表1中的补偿方式和补偿幅度进行补偿。
表1误差预测值处于层间波动时的补偿方法
当
进一步地,所述步骤八中,获取下一时刻的风电功率实际值,将其和预测值一起当作新的历史数据,并丢弃历史数据中的第一个历史数据。则第i+1次滚动预测所利用的数据序列为
实施例:选用某风电场5天的风电功率数据作为样本,利用第6天的风电功率数据进行虚拟预测对比分析,风功率数据的时间分辨率是每15分钟一个采样数据点(一天96点)。对风电场功率序列进行基于提升小波的组合模型预测及误差修正,如图1所示,包括以下步骤:
步骤(1):获取风电功率历史数据序列:将选取以上的采样数据点,获得历史风电功率序列
步骤(2):利用提升小波分解历史风电功率序列
根据仿真实验,对历史风电功率序列进行三层提升小波的分解比较适合预测方法的训练和预测。所得到的频率分量为{sn,dn,dn-1,…,d1},其中sn代表了风电功率数据的低频部分,而{dn,dn-1,…,d1}则是功率数据从低到高的高频部分系列。历史风电功率时间序列的提升小波分解如图2所示。
步骤(3):对每一个频率分量进行分析,并分别选取相适应的预测模型分别对风电功率序列每一个高低频分量进行预测:低频分量变化较平缓且波动小,适合选用灰色预测法预测。高频分量代表原始信号中随机性最强的突然波动且无规律可循,而最小二乘支持向量机具有很强的泛化性,可对高频分量进行训练预测。对于高频信号中的周期序列则可选用arima模型进行预测。
步骤(4):进行提升小波逆运算即数据重构得到下一时刻的风电功率预测初值
步骤(5):通过对历史风电功率实际值的前480个数据的预测,按照步骤(3)和步骤(4)获得480个历史风电功率的预测初值,并根据这480个历史风电功率的实际值和预测初值求出预测误差序列δp,δp={δp1,δp2,...,δpt},t=480;
且
步骤(6):使用改进广义误差分布模型来拟合预测误差概率密度曲线。改进广义误差分布模型概率密度函数为:
其中v和λ为形状参数;γ(·)为伽马函数。
步骤(7):利用概率密度拟合模型计算出在不同置信水平下的风电功率预测初值置信区间,并利用风电功率预测初值置信区间与实际值之间的关系来对误差进行分层;置信度水平参考值如表2所示。
表2置信度水平参考值
根据样本数据预测误差水平,本例选取95%和80%置信度水平作为分层依据,利用改进误差分布模型进行计算,可得95%置信度水平所对应的风电功率预测误差标幺值的绝对值及其对应误差区间,和80%置信度水平所对应的风电功率预测误差标幺值的绝对值及其对应误差区间。根据风电功率误差标幺值所对应的功率预测初值及误差区间,可得出风电功率预测初值在一定置信水平的置信区间。再根据风电功率误差标幺值所对应的功率实际值,依照步骤五中描述的误差分层方法实现对误差的分层,依次分为大误差层、中误差层和小误差层。
步骤(8):选取步骤(5)中所获取的历史预测误差序列δp,利用arima模型对其预测获得t+1时刻误差预测值δpt+1,即第6天的第一个时间点的风电功率预测误差的初步预测值。
步骤(9):根据风电功率预测误差历史值的最后一个数据δpt和步骤(8)所得的t+1时刻风电功率预测的误差预测值δpt+1在误差层级之间所处位置的情况对误差预测值δpt+1进行补偿。具体补偿按照步骤七中所述的情况进行对应补偿。
步骤(10):将步骤(9)中所得的补偿后的误差对步骤(4)中所得的下一时刻风电功率预测值进行修正,则可得到修正后的风电功率预测值
步骤(11):依照步骤八所述,获得下一时刻风电功率的实际值,按上述步骤及步骤八的方法进行滚动预测,获得第6天的96个预测点的风电功率预测值,并与历史实际值中第6天的数据进行对比,可得到预测方法的预测精度。
最后应当说的是,以上实施例仅用以说明本发明的技术方案而非对其限制,尽管参照上述实施例对本发明进行了详细说明,所属领域的普通技术人员应当理解:依然可以对本发明的具体实施方式进行修改或者等同替换,而未脱离本发明精神和范围的任何修改或者等同替换,其均应涵盖在本发明的权利要求范围当中。
- 还没有人留言评论。精彩留言会获得点赞!