一种置信域策略优化的电力系统稳定器自抗扰控制方法
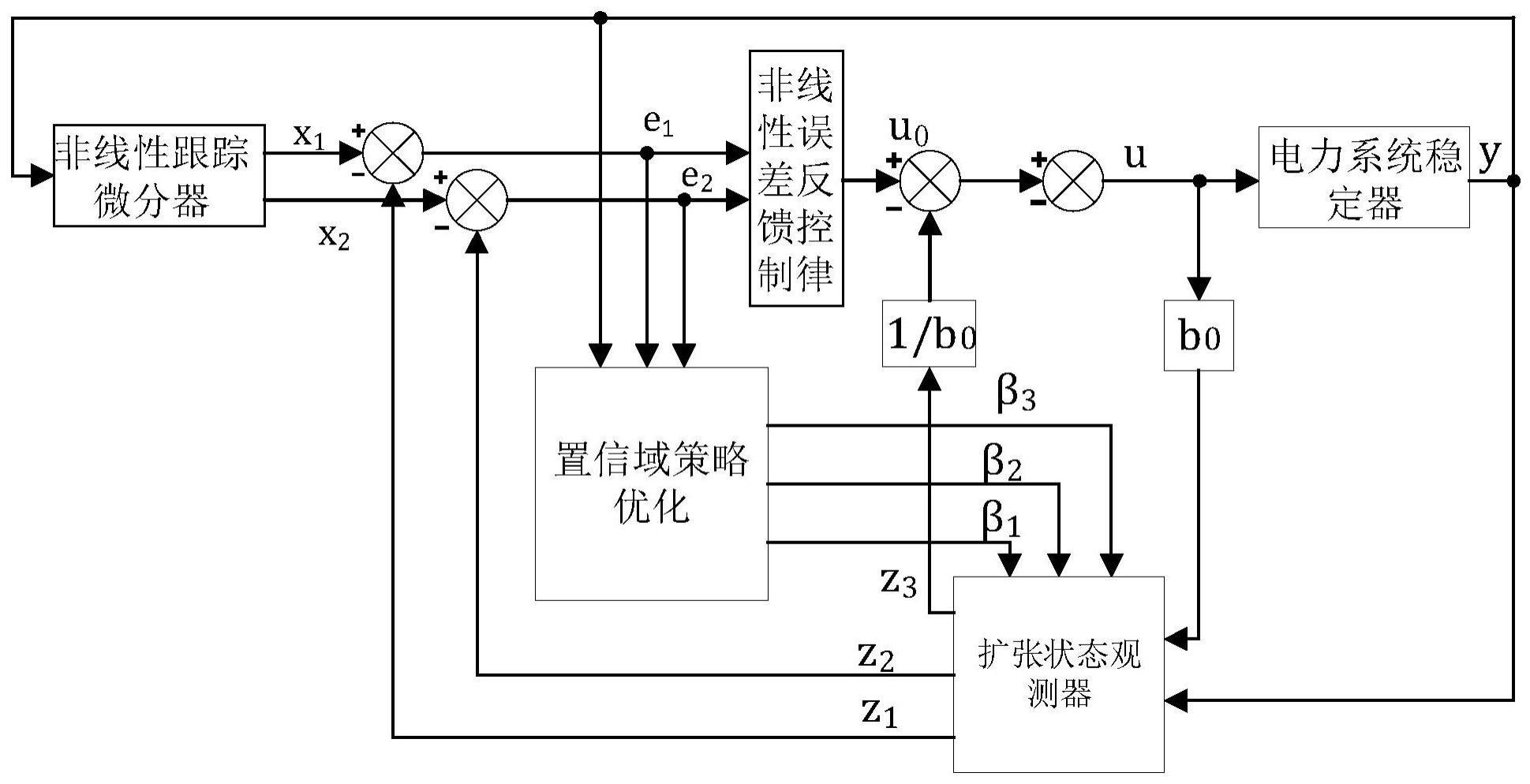
本发明属于电力系统稳定控制领域,涉及一种人工智能和传统自抗扰控制方法相结合的电力系统稳定控制方法,适用于电力系统稳定器的优化与控制。
背景技术:
1、现有电力系统稳定器存在面对外界和内部的干扰导致稳定性失衡,无法快速恢复到原始稳定状态的问题。
2、另外,赵凯岐和刘洋在2022年8月《组合机床与自动化加工技术》第八期发表的“基于adrc的pmsm无传感器控制及参数辨识”的文章提到自抗扰控制方法存在无法实时更新参数的问题。
3、因此,提出一种置信域策略优化的自抗扰控制方法,来解决电力系统稳定器无法快速恢复到原始稳定状态和自抗扰控制方法无法实时更新参数的问题。
技术实现思路
1、一种置信域策略优化的电力系统稳定器自抗扰控制方法,将置信域策略优化方法和自抗扰控制方法进行结合,用于电力系统稳定器的控制,具有控制效率和精度提高、减小控制误差、实现自我整定和在线优化的功能;在使用过程中的步骤为:
2、步骤(1):扩张状态观测器检测到来自系统网络输入信号y(k)和其中,y(k)是第k步输入信号;是第k步输入信号微分;扩张状态观测器的离散表达为:
3、e(k)=z1(k)-y(k) (1)
4、z1(k+1)=z1(k)+h(z2(k)-β1fal(e1,a1,δ)) (2)
5、z2(k+1)=z2(k)+h(z3(k)-β2fal(e1,a2,δ)+bu) (3)
6、z3(k+1)=z3(k)+hβ3fal(e1,a3,δ) (4)
7、式中,β1,β2,β3为输出误差校正增益可调参数;δ为滤波常数;e(k)为第k步检测误差;h为积分步长;z1(k)为输入信号y(k)第k步估计值;z2(k)为微分信号第k步估计值;z3(k)为第k步扰动估计值;z1(k+1)为输入信号y(k)第k+1步估计值;z2(k+1)为微分信号第k+1步估计值;z3(k+1)为第k+1步扰动估计值;u为控制量;b为增益因子;e1为误差信号;a1,a2,a3为0~1之间的常数;
8、fal(e1,aj,δ),j=1,2,3为扩张状态观测器非线性函数,用于抑制信号抖动,表达式为:
9、
10、式中,sgn(e1)为符号函数,当e1>0,sgn(e1)=1;当e1=0,sgn(e1)=0;当e1<0,sgn(e1)=-1;aj为0~1之间的常数;δ为影响滤波效果的常数;||表示为取绝对值;aj为0~1之间的常数;
11、扩张状态观测器将观测到的信号进行补偿处理,输出z1,z2,z3给非线性反馈控制律,离散表达式为:
12、e1(k+1)=x1(k+1)-z1(k+1) (6)
13、e2(k+1)=x2(k+1)-z2(k+1) (7)
14、u0(k+1)=α1fal(e1(k+1),a3,δ3) (8)
15、α2fal(e2(k+1),a4,δ3)(9)式中,α1,α2为非线性误差增益;u0(k+1)为非线性反馈控制律按一定的非线性组合形成的第k+1步的控制量;e1(k+1)为输出值和估计值第k+1步误差值;e2(k+1)为微分信号值和微分信号估计值第k+1步误差值;x1(k+1)为非线性跟踪微分器第k+1步输出值;x2(k+1)为非线性跟踪微分器第k+1步微分信号值;a3,a4为0~1之间的常数;δ3为影响滤波效果的常数;
16、从而,控制变量为:
17、
18、其中,b0为增益因子;u(k+1)为第k+1步的控制量;
19、非线性跟踪微分器的离散表达式为:
20、
21、式中,x1(k)为非线性跟踪微分器第k步输出值;x2(k)为非线性跟踪微分器第k步微分信号值;r为决定跟踪速度;h0为滤波因子;fst(x1(k)-y(k),x2(k),r,h0)为离散系统最速控制函数,fst(x1(k)-y(k),x2(k),r,h0)展开为:
22、
23、
24、
25、y(k)=x1(k)+hx2(k) (15)
26、式中,y(k)为系统第k步输出信号实际值;d,d0为延迟作用常数;c为计算量;c0为观测量;
27、置信域策略优化方法是马尔可夫决策过程、置信域方法和策略梯度优化方法相结合的深度强化学习方法;马尔可夫决策过程是一随机过程,将环境与智能体交互的过程以概率的形式表现出来,马尔可夫决策过程被定义为:
28、m=<s,a,p,r,γ> (16)
29、式中,m为一集合;s为一系列环境状态;a为一系列动作;r为奖励函数;p为状态转移概率;γ为未来奖励折扣因子;
30、在马尔可夫决策过程中,智能体在时间t时观察到的环境状态st∈s,并依据状态st采取一个动作at∈a积分得到t+1时刻状态st+1∈s;同时,为评估状态转换的程度,智能体得到即时奖励rt+1(st,at)∈r,p表示状态转移概率;
31、马尔可夫决策过程和智能体与环境交互,进行重要性采样,返回一组序列:
32、{s0,a0,r1,s1,a1,…,st-1,at-1,rt,st} (17)
33、式中,st为t时刻的状态;at为t时刻的动作;rt为t时刻的价值;st-1为t-1时刻的状态;at-1为t-1时刻的动作;rt-1为t-1时刻的价值;st+1为t+1时刻的状态;at+1为t+1时刻的动作;rt+1为t+1时刻的价值;
34、智能体在状态st时的动作选择被建模成策略π(at|st)的映射,将环境的状态值st映射到一个动作集合的概率分布为:
35、π(a|s)=p(at=a|st=s) (18)
36、式中,π(a|s)表示为在状态s下采取动作a的策略;π(at|st)表示为在t时刻,状态s下采取动作a的策略;p()为概率函数;a为采取的动作;s为环境状态;p(at=a|st=s)为在状态s下采取动作a的概率;
37、在强化学习中,累计奖励为:
38、
39、式中,γ∈(0,1]为未来奖励折扣因子,对未来奖励进行加权;rt为t时刻的累计奖励函数;st-1为t-1时刻的状态;at-1为t-1时刻的动作;rt(st-1,at-1)为在状态st-1,采取动作at-1,在t时刻产生的奖励;t-t0为当前时刻t与开始时刻t0的差;t0为开始时刻;tend为结束时刻;∑为求和符号;表示为从t0时刻到tend时刻对奖励函数求和;
40、状态价值函数定义为当采取某一策略π(a|s)后,累计回报在状态st时的期望值为:
41、
42、式中,vπ(s)为在策略π下的状态价值函数;eπ[]为在策略π下的期望;为在状态s下,从t0时刻到tend时刻对奖励函数求和;
43、策略优化过程为得到一个最优策略π*(a|s),需获得最大化的折扣奖励为:
44、
45、式中,π*(a|s)为在状态s,动作a下的最优策略;argmax为最大化函数;
46、动作价值函数为当在状态st和动作at均确定时的长期期望奖励:
47、
48、式中,qπ(s,a)为策略π下的动作价值函数;eπ[]为策略π下的期望;表示为在t时刻状态s下,采取动作a从t0时刻到tend时刻对奖励函数求和;
49、策略梯度方法是通过学习策略π(a|s)对目标函数j(π)=vπ(s)进行最大化,将带有权重θ的深度神经网络来构成策略网络,近似函数为πθ(a|s);
50、在深度强化学习网络中,目标函数j(θ)为:
51、
52、式中,θ*为目标函数j(θ)在权重θ下的近似函数;πθ(a|s)为在权重θ,状态s采取动作a的策略π;
53、权重θ的更新为:
54、
55、θnew←θold+α·g (25)
56、式中,g为目标函数在权重θold下的梯度;α为学习率,决定更新步长;θnew为新的权重θ;为j(θ)对θ的偏导;θnew←θold+α·g为梯度上升算法;
57、在权重θ神经网络下,将动作价值函数近似处理为qπ(s,a;θ),状态价值函数近似为vπ(s;θ);
58、(20),(22)式均为长期期望奖励,对所有动作的动作价值函数求期望,便能得到状态价值函数为:
59、vπ(s;θ)=eπ[qπ(s,a;θ)] (26)
60、式中,qπ(s,a;θ)为在权重θ,策略π下的动作价值函数;vπ(s;θ)为在权重θ,策略π下的状态价值函数;
61、目标函数j(θ)近似为:
62、j(θ)=es[vπ(s;θ)] (27)
63、式中,es[]为对状态s求期望;j(θ)为目标函数;
64、将状态价值函数进行处理,最终目标函数为:
65、
66、式中,s为一系列状态;a为一系列动作;π(a|s;θ)为在权重θ,状态s采取动作a的概率;π(a|s;θold)为在权重θold,状态s采取动作a的概率;es[]为状态s的期望;ea[]为动作a的期望;qπ(s,a)为在策略π,状态s下对动作a的动作价值函数;
67、置信域策略优化方法将置信域方法和神经策略网络结合,并采用蒙特卡洛对目标函数近似为:
68、
69、式中,l(θ|θold)为目标函数在基于权重θold,在权重θ下的蒙特卡洛近似;si为第i个状态观测值;ai为第i个动作观测值;qπ(si,ai)为在动作ai和状态si下的动作价值函数;n为观测数量;π(ai|si;θ)为权重θ,状态si采取动作ai的策略;π(ai|si;θold)为权重θold,状态si采取动作ai的策略;
70、通过观测智能体n种状态和动作的均值和来更精确近似期望;
71、对于观测到的价值ri,引入折扣回报函数为:
72、ui=ri+γ·ri+1+…+γn-irn (30)
73、式中,ui为折扣回报函数;ri为第i个价值观测值;
74、用折扣回报函数ui作为动作价值函数qπ(si,ai)的蒙特卡洛近似;
75、为l(θ|θold)的进一步近似,为:
76、
77、式中,为l(θ|θold)的近似函数;
78、对近似函数作最大化处理,即梯度上升:
79、
80、式中,n(θold)为θold的邻域;
81、防止新策略和之间差异过大,置信域策略网络优化方法引入kullback-leibler散度来衡量两者差异;kullback-leibler散度满足:
82、
83、式中,δ为一小距离的值;kl[]为距离函数;π(·|si;θnew)为权重θnew,状态si下采取任何动作的策略;π(·|si;θold)为权重θold,状态si下采取任何动作的策略;从而,保证θnew和θold之间的距离不会过大,保证优化的准确程度;
84、电力系统稳定器作为电力系统的重要稳定控制环节,通过提供附加励磁控制从而提供抑制低频振荡的附加阻尼转矩,优化电力系统稳定的控制,提高系统的稳定性;电力系统稳定器的传递函数为:
85、
86、式中,t1和t3为超前时间常数;t2和t4为滞后时间常数;k为增益常数;tω为隔直时间常数;u为输入信号;s为拉普拉斯变换中的变量;y为输出信号;
87、电力系统稳定器输出电压的上下幅值分别为和
88、训练置信域策略优化方法时,为训练速度更快,智能体能够提取到更多重要的信息,将状态空间设为:
89、st=[e1,e2,y]t (35)
90、式中,[]t为矩阵转置符号;
91、考虑到自抗扰控制的状态到动作是连续过程,采用连续动作空间描述,将动作空间设置为:
92、at=[β1,β2,β3]t (36)
93、评价网络是反映智能体学习好坏的指标,使用采样得到的状态空间中的y直接进行评价;
94、步骤(2):将置信域策略优化方法用于自抗扰控制中的扩张状态观测器输出误差校正增益可调参数β1,β2,β3的整定,通过计算输出优化后的z1,z2,z3;
95、步骤(3):将自抗扰控制方法应用于电力系统稳定器的优化控制。
96、本发明相对于现有技术具有如下的优点及效果:
97、(1)和没有参数自我整定功能的自抗扰控制方法相比,置信域策略优化的电力系统稳定自抗扰控制方法具有自我整定和在线优化的功能。
98、(2)相较于自抗扰控制方法,置信域策略优化自抗扰控制方法能够减少控制的误差,是实时在线的控制方法,属于深度强化学习方法,能够依据系统的动态情况动态更新策略,从而不断适应不断改变的环境的情况。(3)置信域策略优化的电力系统稳定自抗扰控制方法能提高控制效率、加快收敛速度。
- 还没有人留言评论。精彩留言会获得点赞!