一种基于分布式算术编码的隐马尔科夫相关信源编码方法与流程
本发明属于分布式算术编码领域,尤其涉及一种基于分布式算术编码的隐马尔科夫相关信源编码方法。
背景技术:
分布式算术编码(DistributedArithmeticCoding,DAC)可以有效地应用于斯理篇-伍夫编码,特别是对于短数据块。最近,一些基于熵编码的SWC技术被提出,比如分布式算术编码(DistributedArithmeticCoding,DAC)和重叠的准算术编码(OverlappedQuasi-Arithmetic,OQAC),这些技术可以看做是经典算术编码(ArithmeticCodingAC)的扩展,其原理是允许码率概率区间的重叠以实现在码率H(X|Y)≤R<H(x)的条件下编码信源X。引入重叠区域后,将产生一个较大的最终区间和一个较短的码字。然而,同时解码端将存在有歧义的码字。一个软连接解码器利用边信息Y来解码X。之后,研究者提出了时间共享DAC(time-sharedDAC,TS-DAC)以解决对称的SWC问题。为了实现率增量SWC,研究者提出了率自适应DAC。
技术实现要素:
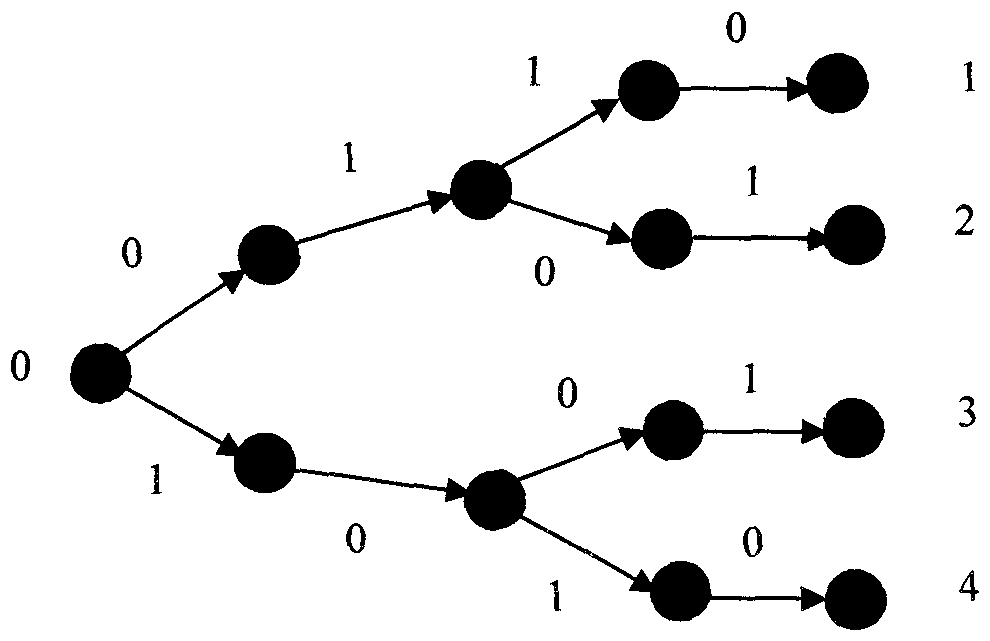
本发明提供了一种基于分布式算术编码的隐马尔科夫相关信源编码方法,旨在解决现有基于熵编码的SWC技术,重叠区域后,解码端将存在有歧义的码字和SWC对称的问题。本发明的目的在于提供一种基于分布式算术编码的隐马尔科夫相关信源编码方法,所述基于分布式算术编码的隐马尔科夫相关信源编码方法包括以下步骤:产生信源;对隐马尔科夫相关信源编码;利用前向算法进行的解码。进一步、所述产生信源的步骤为:读取HMM文件,确定隐马尔科夫模型;应用隐马尔科夫模型计算观察值序列O;根据偏差概率p,生成信源X;将信源X与观察值序列O进行异或运算,生成边信息Y。进一步、所述对隐马尔科夫相关信源编码步骤为:设p是二元信源X的偏差概率,即p=P(xt=1),在经典的算术编码中,信源符号xt被迭代的映射到[0,1)的子区间中,这个子区间的长度与(1-p)和p成比例,在分布式算术编码中,分配的子区间会有重叠,即符号xt=0和xt=1分别对应于区间[0,(1-p)γ)和[1-pγ,1),定义low和high表示编码区间,range表示整个区间长度,half_range表示区间的一半,first_quarter表示整个区间的四分之一大小,third_quarter表示整个区间的四分之三大小。进一步、所述对隐马尔科夫相关信源编码还包括具体的区间放大操作当high<half_range时,这时子区间完全处在上半区,该区间的上下端点的最高有效位都是0,输出相同的最高有效位0,然后将区间的上界和下界分别扩大2倍,即:low=2*low,high=2*high;当low>half_range时,这时子区间完全处在下半区,该区间的上下端点的最高有效位都是1,此时输出相同的最高有效位1,然后将区间的上界和下界分别扩大,即:low=2*(low-half_range),high=2*(high-half_range);当first_quarter≤low≤high≤third_quarter,如果还是按照上述的方法对low和high进行更新,由于子区间不断缩小,所以子区间总是会处在first_quarter≤low≤high≤third_quarter这个区间里,而始终没有相同的最高比特位可以输出,所以在这种情况下就用新的方法进行子区间更新:low=2*(low-first_quarter),high=2*(high-first_quarter)+1。进一步、所述利用前向算法进行的解码步骤为:定义一个结构体node,结构体包括low,high,用来表示概率区间,metric用来表示每个分支的重要程度即分支中各个结点度量的总和,alpha用来记录局部概率αt(i),path用来保存解码出的字符,另外定义数组scale[2],其中scale[0]表示当前解码符号为0或1时,边信息对应位置符号为0的总概率,scale[0]=alpha[0][0]+alpha[0][1];scale[1]表示当前解码符号为0或1时,边信息对应位置符号为1的总概率,scale[1]=alpha[1][0]+alpha[1][1];步骤一、根据原始信源X的长度N,分配解码所需的结点空间,并初始化分布式算术码的解码缓冲区;步骤二、在第i次解码过程中(0<i≤N),读取边信息当前位置的字符si,步骤三、使用前向算法,对每个结点,计算第i次解码时,产生0分支和1分支的概率,当i=1即在状态处于初始时刻时,局部概率用公式a1(i)=πibi(z1)来计算并用alpha数组记录,当i>1时,局部概率用公式计算,公式中变量αt-1(j)由结构体node内取得,每次计算后,得到本次迭代的alpha[0],alpha[1],scale[0]和scale[1],scale[0]表示当前解码符号为0或1时,边信息对应位置符号为0的总概率,scale[0]=alpha[0][0]+alpha[0][1];scale[1]表示当前解码符号为0或1时,边信息对应位置符号为1的总概率,scale[1]=alpha[1][0]+alpha[1][1];步骤四、计算第i次解码的符号ci,如果码字没有落在重叠区域内,则把当前的符号写入node.path,并将解码符号ci和边信息si进行异或运算,当前点的度量就用到达该点的所有路径的概率之和来表示,也就是scale[0]或者scale[1],如果边信息和当前解码符号相同,当前点的度量就用scale[0]表示,如果边信息和当前解码符号不同,就用scale[1]表示,并将结点中的局部alpha更新为更新整条分支的重要性,对于第k条分支,如果码字落在重叠区域内,则产生两个分支m和n,这时候node[m].metric表示的是与边信息相同的分支的度量,即当边信息为1时,node[m].metric表示1分支的度量,当边信息为0时,node[m].metric表示0分支的度量,而node[n].metric则相反,表示与边信息相反的分支的度量,对于m分支,其存储的符号与边信息相同,此时所以m分支的整体重要性就用node[m].metric+=log(scale[0])表示,即m分支上当前所有点的scale值的乘积,而n分支的整体重要性就用node[n].metric+=log(scale[1])表示,即n分支上当前所有点的scale值的乘积,并用新的概率alpha[0]更新原node点中node[m].alpha,用新的alpha[1]更新原node点中的node[n].alpha;步骤五、由于解码一次就会产生新的解码区间,所以计算完分支的度量并更新了局部概率后,要更新概率区间和相关的信息;步骤六、对所有分支按照metric值从大到小进行排序,如果分支数大于我们所设定的阈值M,则将多余的分支剪掉,如果i<N,则返回步骤二;否则,解码结束,将分支排序后的第一条分支中path保存的数据作为解码输出。本发明通过使用DAC来压缩记忆相关的信源,在具体实现中,将信源之间的相关性建模为一个隐马尔科夫过程,实验结果表明,新方案的执行结果接近斯理篇-伍夫理论界限,较好的解决了现有基于熵编码的SWC技术,重叠区域后,解码端将存在有歧义的码字和SWC对称的问题。本发明较好的利用现有的技术,实验效果好,有着很好的应用价值。附图说明图1是本发明提供的基于分布式算术编码的隐马尔科夫相关信源编码方法的流程图;图2是本发明提供的基于分布式算术编码的一个解码树的示意图。具体实施方式为了使本发明的目的、技术方案及优点更加清楚明白,以下结合附图及实施例,对本发明进行进一步的详细说明。应当理解,此处所描述的具体实施例仅仅用以解释本发明,并不用于限定发明。图1示出了本发明实施例提供的基于分布式算术编码的隐马尔科夫相关信源编码方法的实现流程。为了便于说明,仅仅示出了与本发明相关的部分。本发明的基于分布式算术编码的隐马尔科夫相关信源编码方法,包括以下步骤:产生信源;对隐马尔科夫相关信源编码;利用前向算法进行的解码。作为本发明实施例的一优化方案,产生信源的步骤为:读取HMM文件,确定隐马尔科夫模型;应用隐马尔科夫模型计算观察值序列O;根据偏差概率p,生成信源X;将信源X与观察值序列O进行异或运算,生成边信息Y。作为本发明实施例的一优化方案,对隐马尔科夫相关信源编码步骤为:设p是二元信源X的偏差概率,即p=P(xt=1),在经典的算术编码中,信源符号xt被迭代的映射到[0,1)的子区间中,这个子区间的长度与(1-p)和p成比例,在分布式算术编码中,分配的子区间会有重叠,即符号xt=0和xt=1分别对应于区间[0,(1-p)γ)和[1-pγ,1),定义low和high表示编码区间,range表示整个区间长度,half_range表示区间的一半,first_quarter表示整个区间的四分之一大小,third_quarter表示整个区间的四分之三大小。作为本发明实施例的一优化方案,对隐马尔科夫相关信源编码还包括具体的区间放大操作当high<half_range时,这时子区间完全处在上半区,该区间的上下端点的最高有效位都是0,输出相同的最高有效位0,然后将区间的上界和下界分别扩大2倍,即:low=2*low,high=2*high;当low>half_range时,这时子区间完全处在下半区,该区间的上下端点的最高有效位都是1,此时输出相同的最高有效位1,然后将区间的上界和下界分别扩大,即:low=2*(low-half_range),high=2*(high-half_range);当first_quarter≤low≤high≤third_quarter,如果还是按照上述的方法对low和high进行更新,由于子区间不断缩小,所以子区间总是会处在first_quarter≤low≤high≤third_quarter这个区间里,而始终没有相同的最高比特位可以输出,所以在这种情况下就用新的方法进行子区间更新:low=2*(low-first_quarter),high=2*(high-first_quarter)+1。作为本发明实施例的一优化方案,利用前向算法进行的解码步骤为:定义一个结构体node,结构体包括low,high,用来表示概率区间,metric用来表示每个分支的重要程度即分支中各个结点度量的总和,alpha用来记录局部概率αt(i),path用来保存解码出的字符,另外定义数组scale[2],其中scale[0]表示当前解码符号为0或1时,边信息对应位置符号为0的总概率,scale[0]=alpha[0][0]+alpha[0][1];scale[1]表示当前解码符号为0或1时,边信息对应位置符号为1的总概率,scale[1]=alpha[1][0]+alpha[1][1];步骤一、根据原始信源X的长度N,分配解码所需的结点空间,并初始化分布式算术码的解码缓冲区;步骤二、在第i次解码过程中(0<i≤N),读取边信息当前位置的字符si,步骤三、使用前向算法,对每个结点,计算第i次解码时,产生0分支和1分支的概率,当i=1即在状态处于初始时刻时,局部概率用公式α1(i)=πibi(z1)来计算并用alpha数组记录,当i>1时,局部概率用公式计算,公式中变量αt-1(j)由结构体node内取得,每次计算后,得到本次迭代的alpha[0],alpha[1],scale[0]和scale[1],scale[0]表示当前解码符号为0或1时,边信息对应位置符号为0的总概率,scale[0]=alpha[0][0]+alpha[0][1];scale[1]表示当前解码符号为0或1时,边信息对应位置符号为1的总概率,scale[1]=alpha[1][0]+alpha[1][1];步骤四、计算第i次解码的符号ci,如果码字没有落在重叠区域内,则把当前的符号写入node.path,并将解码符号ci和边信息si进行异或运算,当前点的度量就用到达该点的所有路径的概率之和来表示,也就是scale[0]或者scale[1],如果边信息和当前解码符号相同,当前点的度量就用scale[0]表示,如果边信息和当前解码符号不同,就用scale[1]表示,并将结点中的局部alpha更新为更新整条分支的重要性,对于第k条分支,如果码字落在重叠区域内,则产生两个分支m和n,这时候node[m].metric表示的是与边信息相同的分支的度量,即当边信息为1时,node[m].metric表示1分支的度量,当边信息为0时,node[m].metric表示0分支的度量,而node[n].metric则相反,表示与边信息相反的分支的度量,对于m分支,其存储的符号与边信息相同,此时所以m分支的整体重要性就用node[m].metric+=log(scale[0])表示,即m分支上当前所有点的scale值的乘积,而n分支的整体重要性就用node[n].metric+=log(scale[1])表示,即n分支上当前所有点的scale值的乘积,并用新的概率alpha[0]更新原node点中node[m].alpha,用新的alpha[1]更新原node点中的node[n].alpha;步骤五、由于解码一次就会产生新的解码区间,所以计算完分支的度量并更新了局部概率后,要更新概率区间和相关的信息;步骤六、对所有分支按照metric值从大到小进行排序,如果分支数大于我们所设定的阈值M,则将多余的分支剪掉,如果i<N,则返回步骤二;否则,解码结束,将分支排序后的第一条分支中path保存的数据作为解码输出。下面结合附图及具体实施例对本发明的应用原理作进一步描述。如图1所示,本发明实施例的基于分布式算术编码的隐马尔科夫相关信源编码方法包括以下步骤:S101:产生信源;S102:对隐马尔科夫相关信源编码;S103:利用前向算法进行的解码。本发明的原理为:A.二进制算术编码:设p是二元信源X的偏差概率,即p=P(xt=1)。在经典的算术编码中,信源符号xt被迭代的映射到[0,1)的子区间中,这个子区间的长度与(1-p)和p成比例。由此产生的码长大于X的信息熵,即R≥H(X)。在分布式算术编码[4]中,子区间的长度与修改后的概率(1-p)γ和pγ成比例,其中γ满足公式:产生的码长满足R≥γH(X)≥H(X|Y)。为了适应区间[0,1),子区间必须部分重叠。更具体的说,符号xt=0和xt=1分别对应于区间[0,(1-p)γ)和[1-pγ,1)。引入重叠区域后,将产生一个较大的最终区间和一个较短的码字。由此产生代价是,没有边信息Y,解码器不能准确地解码X。为了描述解码的过程,本文定义一个三元符号集{0,χ,1},其中χ表示一个有歧义的解码。定义Cx是码字,是第t个解码的符号,可以得到当第t个符号被解码的时候,如果该解码器产生分支:两个候选分支产生,对应两个符号xt=0或xt=1。对于每一个新的分支,它的度量值是不断更新的,并且它对应的区间会作为下一次迭代的开始。为了降低复杂性,每次解码完一个符号,解码器使用M-自由度算法来保证至多保留M个重要性最大的分支,而把其他分支都删除掉。需要注意的是,对于一个有限长度序列X,对最后的一些符号进行度量是不可靠的。因此,对最后T个符号的编码,其概率区间不重叠,即采用传统的算术编码。在1≤t≤(N-T)这个范围内,xt被映射到[0,(1-p)γ)和[1-pγ,1)这两个区间中;而对于(N-T+1)≤t≤N这个范围内,xt映射到区间[0,1-p)和[1-p,1)。因此,一个二进制DAC系统可以由四个参数来描述:{p,γ,M,T}。隐马尔科夫模型和前向算法:设是一个状态序列,是一个观察值序列。用λ=(A,B,π)来定义一个隐马尔科夫过程:A={aji}:状态转移概率矩阵,其中aji=P(st=i|st-1=j);B={bi(k)}:观察概率分布,其中bi(k)=P(zt=k|st=i);π={πi}:初始状态分布,其中πi=P(s1=i)。前向算法的目的是计算观察序列概率P(z1,...,zt|λ),已知观察值{z1,...,zt}和模型λ。定义αt(i)是观察序列{z1,...,zt}的局部概率,状态st用i表示,即αt(i)=P(Z1,...,ZtSt=i|,(3)开始时,当t=1时有a1(i)=πibi(z1).(4)当t>1时,αt(i)可以通过迭代来得出即因此,在实际应用中,αt(i)通常用下面的公式进行归一化,其中在这种情况下,可以得到有本发明的具体实施过程为:第一步、相关信源的产生:对于两个统计相关的信源X和Y,分布式信源编码通常假设在序列X和序列Y之间有一个虚拟的相关信道,其中将信源X作为信道的输入,信源Y作为信道的输出,通过信道来描述X和Y之间的相关性,而它们之间的相关性可以用条件熵H(X|Y)来衡量,而条件熵H(X|Y)又可以使用隐状态序列与观察值序列来计算获得,在发明中,信源X和边信息Y是通过相关联的,其中Z是由一个使用参数λ的隐马尔科夫模型得到的,X通过一个有四个参数{p,γ,M,T}的DAC编码器进行编码,在编码时,信源X作为待编码的信源,信源Y作为边信息在解码端辅助解码,在发明中,定义了HMM格式的文件,其中包含观察值个数M,状态个数N,状态转移概率矩阵A,观察概率分布B和初始概率分布π,相关信源的产生过程为:(1)读取HMM文件,确定隐马尔科夫模型,(2)应用隐马尔科夫模型计算观察值序列O,一个隐马尔科夫模型主要包括两个信息序列,一个是可以直接观察得到的观察值序列,另一个是不可直接获取的隐状态序列,由步骤(1)得到的隐马尔科夫模型,可以计算观察值序列O,(3)根据偏差概率p,生成信源X,(4)将信源X与观察值序列O进行异或运算,生成边信息Y。第二步、隐马尔科夫相关信源的编码过程:设p是二元信源X的偏差概率,即p=P(xt=1),在经典的算术编码中,信源符号xt被迭代的映射到[0,1)的子区间中,这个子区间的长度与(1-p)和p成比例,在分布式算术编码中,分配的子区间会有重叠,即符号xt=0和xt=1分别对应于区间[0,(1-p)γ)和[1-pγ,1),需要注意的是,对于一个有限长度序列X[5],对最后的一些符号进行度量是不可靠的,因此,对最后T个符号的编码,其概率区间不重叠,即采用传统的算术编码,在1≤t≤(N-T)这个范围内,xt被映射到[0,(1-p)γ)和[1-pγ,1)这两个区间中;而对于(N-T+1)≤t≤N这个范围内,xt映射到区间[0,1-p)和[1-p,1),在编码的具体实现过程中,子区间的划分还要注意上溢和下溢的问题,定义low和high表示编码区间,range表示整个区间长度,half_range表示区间的一半,first_quarter表示整个区间的四分之一大小,third_quarter表示整个区间的四分之三大小,在对区间进行更新后,子区间的大小会不断收缩,如果不进行合适的处理会导致区间越来越小,当区间过小时就会超出计算机能够处理的精度范围从而溢出,为了不出现这种情况,必须对区间端点low和high进行比例放大操作,以使计算机能够保持足够的精度,具体的区间放大操作如下:(1)当high<half_range时,这时子区间完全处在上半区,该区间的上下端点的最高有效位都是0,此时输出相同的最高有效位0,然后将区间的上界和下界分别扩大2倍,即:low=2*low,high=2*high,(2)当low>half_range时,这时子区间完全处在下半区,该区间的上下端点的最高有效位都是1,此时输出相同的最高有效位1,然后将区间的上界和下界分别扩大,即:low=2*(low-half_range),high=2*(high-half_range),(3)当first_quarter≤low≤high≤third_quarter,如果还是按照上述的方法对low和high进行更新,由于子区间不断缩小,所以子区间总是会处在first_quarter≤low≤high≤third_quarter这个区间里,而始终没有相同的最高比特位可以输出,所以在这种情况下就用新的方法进行子区间更新:low=2*(low-first_quarter),high=2*(high-first_quarter)+1。第三步、利用前向算法进行的解码过程:假设二进制信源X和边信息Y通过相关联,其中Z是由一个使用参数λ的隐马尔科夫模型得到的,解码符号和边信息yt取异或得到的zt,即符合隐马尔科夫模型,可以使用前向算法计算其局部概率,解码的过程和在[4]中描述的非常相似,本发明的创新之处就是在解码的过程中,每条分支的度量用P(z1,...,zt|λ)来表示,本发明提出的解码方法主要利用了前向算法,前向算法的具体实施过程如下:本发明在实施过程中,定义了一个结构体node,结构体包括low,high,用来表示概率区间,metric用来表示每个分支的重要程度即分支中各个结点度量的总和,alpha用来记录局部概率αt(i),path用来保存解码出的字符,另外定义数组scale[2],其中scale[0]表示当前解码符号为0或1时,边信息对应位置符号为0的总概率,scale[0]=alpha[0][0]+alpha[0][1];scale[1]表示当前解码符号为0或1时,边信息对应位置符号为1的总概率,scale[1]=alpha[1][0]+alpha[1][1],利用前向算法进行DAC解码的过程为:(1)根据原始信源X的长度N,分配解码所需的结点空间,并初始化分布式算术码的解码缓冲区,(2)在第i次解码过程中(0<i≤N),读取边信息当前位置的字符si,(3)使用前向算法,对每个结点,计算第i次解码时,产生0分支和1分支的概率,当i=1即在状态处于初始时刻时,局部概率用公式(4)来计算并用alpha数组记录,当i>1时,局部概率用公式(5)计算,公式中变量αt-1(j)由结构体node内取得,每次计算后,得到本次迭代的alpha[0],alpha[1],scale[0]和scale[1],scale[0]表示当前解码符号为0或1时,边信息对应位置符号为0的总概率,scale[0]=alpha[0][0]+alpha[0][1];scale[1]表示当前解码符号为0或1时,边信息对应位置符号为1的总概率,scale[1]=alpha[1][0]+alpha[1][1],(4)计算第i次解码的符号ci,如果码字没有落在重叠区域内,则把当前的符号写入node.path,并将解码符号ci和边信息si进行异或运算,当前点的度量就用到达该点的所有路径的概率之和来表示,也就是scale[0]或者scale[1],如果边信息和当前解码符号相同,当前点的度量就用scale[0]表示,如果边信息和当前解码符号不同,就用scale[1]表示,并将结点中的局部alpha更新为更新整条分支的重要性,对于第k条分支,如果码字落在重叠区域内,则产生两个分支m和n,这时候node[m].metric表示的是与边信息相同的分支的度量,即当边信息为1时,node[m].metric表示1分支的度量,当边信息为0时,node[m].metric表示0分支的度量,而node[n].metric则相反,表示与边信息相反的分支的度量,对于m分支,其存储的符号与边信息相同,此时所以m分支的整体重要性就用node[m].metric+=log(scale[0])表示,即m分支上当前所有点的scale值的乘积,而n分支的整体重要性就用node[n].metric+=log(scale[1])表示,即n分支上当前所有点的scale值的乘积,并用新的概率alpha[0]更新原node点中node[m].alpha,用新的alpha[1]更新原node点中的node[n].alpha,(5)由于解码一次就会产生新的解码区间,所以计算完分支的度量并更新了局部概率后,要更新概率区间和相关的信息,(6)对所有分支按照metric值从大到小进行排序,如果分支数大于我们所设定的阈值M,则将多余的分支剪掉,如果i<N,则返回步骤(2);否则,解码结束,将分支排序后的第一条分支中path保存的数据作为解码输出。如图2所示的一个的解码树,假设边信息是10111,每条分支的度量都是用当前分支上所有点的scale值的乘积来表示的,比如分支1,那么分支1的度量就是其中5个点的scale值的乘积,即metric=scale[1]*scale[0]*scale[0]*scale[0]*scale[1],而每个点的scale是根据局部概率alpha来计算的,并且局部概率是不断更新的,计算方法scale[0]=alpha[0][0]+alpha[0][1],scale[1]=alpha[1][0]+alpha[1][1],alpha的计算方法是根据前面介绍的前向算法来计算的,可以由公式(4)和(5)计算得到,本发明的实验结果:实验中验证了一个16位的DAC编解码器系统,X的偏差概率是p=0.5,设置M=2048和T=15,实验中模拟了与[9]中相同的两个状态(0和1)和两个输出信源(0和1)(见表1),每次实验中所用的数据块长度是N=1024,为了实现无损压缩,每次实验都从γ=H(X|Y)开始(见表2),如果解码失败,以0.01的幅度增加γ,这个过程一直迭代到解码成功,对于每个模型,运行了100次试验,100次试验结果的平均值记录在表2中,表1仿真模型模型{a00,a11,b0(0),b1(1)}1{0.01,0.03,0.99,0.98}2{0.01,0.065,0.95,0.925}3{0.97,0.967,0.93,0.973}4{0.99,0.989,0.945,0.9895}表2实验结果为了进行比较,表2中也记录了有着相同设置的[9]的实验结果,在[9]的每次试验中,N=16384的信源符号用LDPC码来进行编码,另外,为了要与隐马尔科夫模型同步,Nα个原始信源符号在没有压缩的情况下直接被送到解码器,实验结果表明DAC的执行结果与基于LDPC的方法[9]的执行结果相似或者略好一点(模型1和模型2),此外,对于隐马尔科夫相关,DAC在两个方面优于以LDPC为基础的方法:(1)基于LDPC的方法需要较长的码字来达到较好的执行结果,而DAC对码字的长度并不敏感[4],(2)为了与隐马尔科夫模型保持同步,基于LDPC的方法必须发送一定比例的原始信号到解码端作为种子,然而,很难确定种子的最佳比例α,在[9]中报告的结果是通过穷举搜索得到,这限制了它在实际中的应用。以上所述仅为本发明的较佳实施例而已,并不用以限制本发明,凡在本发明的精神和原则之内所作的任何修改、等同替换和改进等,均应包含在本发明的保护范围之内。
相关技术
网友询问留言
已有0条留言
- 还没有人留言评论。精彩留言会获得点赞!
1