一种无线信道下基于可译集的喷泉码增量译码算法的制作方法
本发明属于无线通信的技术领域,具体是指一种无线信道下基于可译集的喷泉码增量译码算法。
背景技术:
数字喷泉码是针对大规模网络数据分发和可靠传输而提出的一种新的纠删编码方法。与传统的纠删码不同,数字喷泉码可以按照某种概率分布独立地产生任意数量的码字,具有码率不受限或无码率(rateless)特性。接收者不必关心具体的编码分组及分组的顺序,只要接收到足够多的编码分组,就能实现正确的译码。目前研究喷泉码常用的码型为LT码和Raptor码。2002年Luby提出了第一种实用的数字喷泉码——LT码,并设计了实用的度分布(鲁棒孤波分布),能够在任意删除信道中逼近信道容量,但其译码复杂度是非线性的。2006年Shokrollahi等人将高效的预编码与LT码级联,提出了性能更好的Raptor码,具有线性编译码复杂度。
LT(Luby Transform)码是第一种具有实用意义的数字喷泉码。这类码的主要参数是输出度分布,即对应不同度数的不同概率值常用生成函数的形式来表达假设原始数据包长度为K,LT码的编码方案如下:
(1)在输出度分布Ω(x)中随机选取一个度数i;
(2)再从K个原始数据包符号中均匀随机选取出i个不同的符号,将这i个符号进行异或得到一个编码符号;
(3)重复上面的操作,即可完成LT编码。
在无线信道中,由于噪声的干扰,需要采用可靠的软判决译码。喷泉码常用的软判决译码算法为BP算法。
传统BP译码算法利用生成矩阵Tanner图中的联系,在变量节点和校验节点之间不断地相互传递似然比信息来逐渐收敛到可靠值,节点的对数似然比定义为:
令表示第l次迭代时变量节点xi传递给校验节点yj的似然比信息。表示第l次迭代时校验节点yj传递给变量节点xi的似然比信息。M(i)表示与变量节点xi相连的所有校验节点的集合,M(i)\j表示除校验节点yj外与xi相邻的其他校验节点组成的集合。N(j)表示与校验节点yj相连的所有变量节点构成的集合,N(j)\i表示除变量节点xi外与yj相连的其他变量节点组成的集合。L0表示信道的似然比,计算公式如下:
则变量节点和校验节点的似然比迭代公式如下:
重复进行迭代,达到最大迭代次数后进行硬判决。
应用于喷泉码进行译码时,译码需接收到一定数量的码字后开始译码,迭代至预设最大次数后再对变量节点进行硬判决。若译码失败,需继续接收更多数量的码字重新进行迭代,使得之前迭代的信息没有得到有效利用,效率低下,复杂度较大,计算量庞大。
技术实现要素:
本发明针对现有技术的不足,提出了一种无线信道下基于可译集的喷泉码增量译码算法,基于可译集的喷泉码增量译码算法。该算法减少了传统BP译码算法迭代过程中的计算量,并利用到低开销译码中的有用信息,解决了传统BP译码算法应用于喷泉码时效率较低的问题。
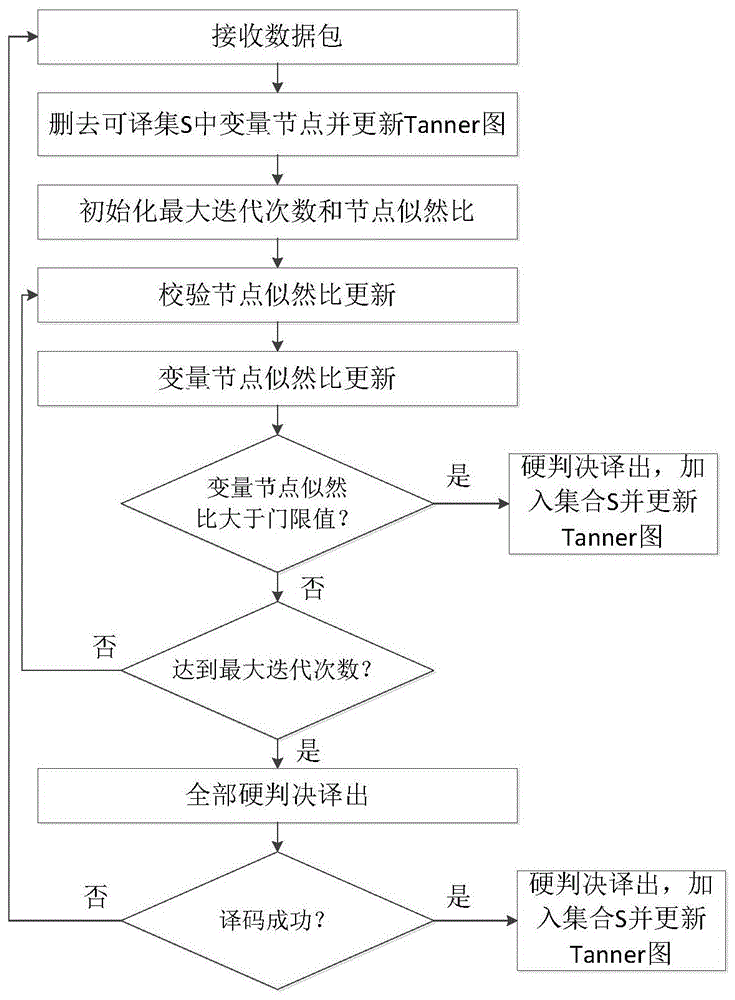
本发明是这样实现的,一种无线信道下基于可译集的喷泉码增量译码算法,具体步骤如下:
步骤1,定义变量节点的似然比门限值Tre的合适取值,在开销固定的一次译码过程中,利用可译集减少传统BP译码算法中的计算量;
步骤2,将门限值Tre作为变量节点加入可译集的判定依据,在开销固定的一次译码过程中,利用可译集减少传统BP译码算法中的计算量,在每次迭代结束后对变量节点的似然比进行一次判定,将似然比大于门限值的变量节点xi提前进行硬判决,并删除xi在Tanner图中的连接,删去与其相连的边,不再继续参与迭代,以减少计算量;
步骤3,为保证缩小后的Tanner图可继续正确迭代,需对删除后的信道似然比加以修正;
步骤4,将xi加入到所有已经译出的所有变量节点的集合S中;
步骤5,若似然比不大于门限值的变量节点,则继续迭代,直至所有变量节点全部译出或达到预设最大迭代次数;若迭代次数达到lmax后变量节点未能全部译出,则根据迭代结束后的最终似然比对剩余变量节点进行硬判决。
步骤6,若当前开销下未能成功译码,则增大开销接收更多数据包;接收后,先利用集合S中已经译出的部分变量节点简化Tanner图,再对未译出节点进行译码,减少计算量。
进一步,所述的步骤1具体为:
1.1,根据BIAWGN信道中,BPSK调制模式下,误码率BER和信噪比SNR的关系:
求得:
其中P为信号功率,σ2为噪声功率;
1.2,假设信号功率P=1,则有:喷泉的原始信息比特序列为x=(x1,x2,…,xk),喷泉编码后生成的序列为y=(y1,y2,…,yn);对编码序列y进行BPSK调制后的序列为y';令表示第l次迭代时变量节点xi传递给校验节点yj的似然比信息;表示第l次迭代时校验节点yj传递给变量节点xi的似然比信息;M(i)表示与变量节点xi相连的所有校验节点的集合,M(i)\j表示除校验节点yj外与xi相邻的其他校验节点组成的集合;N(j)表示与校验节点yj相连的所有变量节点构成的集合,N(j)\i表示除变量节点xi外与yj相连的其他变量节点组成的集合;L0表示信道的似然比,计算公式如下:
1.3,经BIAWGN信道传输后,接收端收到的信息序列为r=y'+z;
似然比的均方值
给定期望达到误码率BER,需满足:
将条件放大至:
因此似然比需满足:
求得似然比LLR(r)的译码门限值Tre为:
进一步,所述的步骤2具体为:每次迭代结束后对变量节点的似然比进行
一次判定,将似然比的变量节点xi利用公式提前
进行硬判决,并删除xi在Tanner图中的连接。
进一步,所述的步骤3具体为:
3.1若变量节点xi判决为0,则无需修正;
3.2若变量节点xi判决为1,需对所有与其相连的校验节点所在的信道似然比
进行修正:
L'0j=-L0j,j∈M(i)
进一步,所述的步骤4具体为:
令S表示所有已经译出的所有变量节点的集合,将xi加入集合S;则提前译
出部分节点后的似然比迭代公式变为:
本发明针对现有技术的有益效果在于:本发明分析了二进制加性高斯白噪声(BIAWGN)信道下LT码的BP算法原理,根据理想误码率与信噪比及似然比之间的关系,给出了变量节点加入可译集成功译码时似然比所需达到的门限值Tre。将迭代过程中似然比达到门限值的变量节点加入可译集提前译出,不再继续参与迭代,一方面减少了迭代过程中的计算量。另一方面,即使译码失败,开销增加时也可利用已经达到门限值成功译出的部分变量节点简化Tanner图,只对未达到译码门限的变量节点进行迭代,进一步减少计算量。仿真实验表明,该算法与传统的BP译码算法性能相同,但计算量大大减少,效率显著提高。
附图说明
图1是本发明增量译码算法流程图;
图2是利用本发明可译集简化Tanner图说明;
图3是本发明实施例中增加开销y6y7y8时传统BP译码算法的Tanner图;
图4是本发明实施例中增加开销y6y7y8时增量译码算法的Tanner图;
图5是本发明实施例中仿真了码为2000时两种译码算法的性能比较;
图6是本发明实施例中仿真了码为5000时两种译码算法的性能比较;
具体实施方式
下面结合附图对发明的技术方案进行详细说明。下面通过参考附图描述的实施方式是示例性的,仅用于解释本发明,而不能解释为对本发明的限制。
本领域的技术人员可以理解,除非另外定义,这里使用的所有术语(包括技术术语和科学术语)具有与本发明所属领域中的普通技术人员的一般理解相同的意义。还应该理解的是,诸如通用字典中定义的那些术语应该被理解为具有与现有技术的上下文中的意义一致的意义,并且除非像这里一样定义,不会用理想化或过于正式的含义来解释。
如图1所示,根据BIAWGN信道中,BPSK调制模式下,误码率BER和信噪比SNR的关系:
求得:
假设期望达到的译码误码率为BER,根据下式求得可提前译码时变量节点似然比需达到的门限值Tre
其中将该门限值作为变量节点加入可译集的判定依据。BP译码步骤为:
初始化:由于没有先验信息,变量节点是0和1的概率相同,因此变量节点的初始似然比为零,即
校验节点信息更:根据公式计算校验节点的似然比信息并更新。
变量节点信息更新:在校验节点已更新的基础上,根据公式计算变量节点的似然比信息并更新。
每次迭代结束后对变量节点的似然比进行一次判定,将似然比Lxi≥Tre的变量节点xi利用公式提前进行硬判决,并删除xi在Tanner图中的连接。例如图2中,若x2、x4的似然比达到译码门限值,则加入可译集并删去与其相连的边,不再继续参与迭代,以减少计算量。
为保证缩小后的Tanner图可继续正确迭代,需对删除后的信道似然比加以修正:
1)若变量节点xi判决为0,则无需修正;
2)若变量节点xi判决为1,需对所有与其相连的校验节点所在的信道似然比进行修正:
L'0j=-L0j,j∈M(i)
令S表示所有已经译出的所有变量节点的集合,将xi加入集合S。则提前译出部分节点后的似然比迭代公式变为:
继续迭代,直至所有变量节点全部译出或达到预设最大迭代次数。若迭代达到最大次数后变量节点未能全部译出,则根据迭代结束后的最终似然比对剩余变量节点直接进行硬判决。
若当前开销下未能成功译码,需增大开销接收更多数据包,先利用可译集简化Tanner图,再对未译出节点进行译码。如图3所示,为传统BP算法在开销增大时需进行译码的Tanner图。而图4中所示的基于可译集的增量译码算法可利用集合S中已经成功译出的部分变量节点x2、x4简化Tanner图,只对未译出的变量节点按照上述步骤进行迭代及提前译出,进一步减少计算量。
最后,本发明对提出的基于可译集的增量译码算法和传统BP译码算法进行了仿真比较。考虑了LT码在BIAWGN信道中,BPSK调制下,取不同码长时的性能和时间效率比较。仿真次数取1000次,最大迭代次数lmax=30,实际信道的信噪比SNR'取3dB,期望误码率取BER=10-6,计算得到的译码门限值Tre=23.57。
图5和图6分别仿真了码长(K)为2000和5000时两种算法的误码率曲线。可以看出,新提出的译码算法与传统BP译码算法性能几乎相同,改进的算法并没有造成性能的下降。
表1为不同码长下两种译码算法的运行时间比较
表1给出了相同仿真条件下基于可译集的增量译码算法和传统BP译码算法的执行时间。可以看出基于可译集的增量译码算法执行效率大大提高,约为传统BP算法的5倍。
- 还没有人留言评论。精彩留言会获得点赞!