基于Gzip硬件实现文本压缩方法与流程
本发明属于通信技术领域,更进一步涉及无损数据压缩技术领域中的一种基于gzip(gunzip)硬件实现文本压缩方法。本发明采用并行处理窗口对文本信息进行处理并且以全流水结构完成文本压缩处理,可用于优化文本压缩编码硬件实现方法,尤其适用于实时文本压缩处理。
背景技术:
随着大数据时代的来临,大量多媒体数据需要在网络上进行传输,需要占用大量的网络资源,因此数据压缩技术方面的研究十分重要。gzip作为目前最流行的无损压缩方法,被广泛应用于网络资料下载和数据备份等领域。
gzip文本压缩方法目前最知名的实现版本存在于由jean-loupgailly和markadler共同开发的开源zlib库中,但是该版本是基于传统的软件实现方法,对数据进行顺序处理。该方法存在的不足之处是:该方法在分析数据和压缩编码的过程都需要进行大量的计算以及查找,这样的顺序执行以及大量的运算量,导致处理速度缓慢。
m.s,abdelfattah、a.hagiescu和d.singh在其发表的论文“gziponachip:highperformancelosslessdatacompressiononfpgasusingopencl”(ininternationalworkshoponopencl.2014:4)中提出了一种基于异构计算实现文本压缩的方法。该方法提供了一种通过异构语言将中央处理器与硬件器件联合处理的文本压缩实现结构。其中包含的适用于硬件实现的文本压缩方法,将原有串行文本压缩结构修改为并行处理结构,相比于原有软件实现方法的处理速度有所提升。该方法存在的不足之处是:该方法使用异构计算进行实现本文压缩,对硬件实现部分没有实现流水结构,导致该方法仍然存在一定的时钟延迟导致处理吞吐率有所降低。而且该算法只适用于文本压缩中固定大小的计算单元,导致适用规模单一,不能满足对不同压缩比以及不同硬件资源规模消耗的需求。
s.rigler、w.bishop和a.kennings在其发表的论文“fpga-basedlosslessdatacompressionusinghuffmanandlz77algorithms”(inproceedingsofthecanadianconferenceonelectricalandcomputerengineering(ccece),pages1235-1238,april2007)中提出了一种基于硬件编码语言vhdl对字典压缩lz77编码以及哈夫曼编码的硬件实现方法。该方法通过对应软件代码的实现方案,将文本压缩中关键两部分:字典压缩部分以及哈夫曼编码部分进行硬件实现。该方法存在的不足之处在于:对字典压缩和哈夫曼编码的硬件实现过程采用顺序执行方法,并没有进行结构的优化,处理过程耗费大量时钟周期。而且该方法只对文本压缩中两个关键步骤进行硬件实现,并没有实现完整的文本压缩硬件实现方法。
中国农业银行股份有限公司申请的专利“文本压缩方法及装置”(专利申请号:201610476295.9,公开号:106202172a)中公开了一种文本压缩方法,该方法应用分布集群中的多个机器节点并行执行该文本压缩方法,该方法从原始文本文件中,提取采样词组,为每个采样词组设置对应的编码,采样词组与编码之间的对应关系作为映射函数,为每个采样词组设置其对应的编码。采样词组与编码之间的对应关系可以作为映射函数,使用映射函数对原始文本进行整体压缩。该专利申请存在的不足之处是:仅仅是利用采样词组构成的映射函数对文本进行整体压缩,文本压缩方法单一,导致压缩比较低。而且文本压缩采样顺序执行方式,在对每个文本采样顺序执行方式,压缩处理过程耗费大量的时钟周期,导致处理速度缓慢。
技术实现要素:
本发明的目的在于针对上述已有技术的不足,提出一种基于gzip硬件实现文本压缩方法。该方法通过字典查找和哈夫曼编码的方式,将文本进行压缩。采取适用于硬件实现的处理结构,将待处理的文本原有的顺序执行方式通过修剪了重叠字符,实现了改为同一窗口中字符串的同时匹配处理,优化了压缩结构,提高处理速度。
为了实现上述目的,本发明的思路是将原有文本压缩结构重新设计,采用并行处理窗口对文本信息进行处理并且以全流水结构完成文本压缩处理。依次进行读入待压缩的文件,进行字典更新,字典查找实现匹配,哈夫曼编码,哈夫曼码流输出,最终输出压缩后的文件,实现了对文件压缩的流水处理。本发明采用字典查找和哈夫曼编码联合压缩的方法,将字典中的历史字符串作为待匹配字符串,对修剪匹配对替换匹配字符串,在完成文本匹配压缩的基础上,再对匹配压缩字符串进行静态哈夫曼编码得到最终的压缩码流。
为实现本发明目的的具体步骤如下:
(1)读入待压缩文本:
(1a)依次将待压缩文本中自定义缓存深度大小的文本块,读入到缓存器1中;
(1b)依次将未读入的自定义缓存深度大小的文本块,读入到缓存器2中的同时,将缓存器1中的文本块读入到文本压缩处理器中;
(1c)用依次读入自定义缓存深度大小的文本块更新缓存器1中存储的文本块,在更新缓存器1的同时,将缓存器2中的文本块读入到文本压缩处理器中;
(1d)重复以上两个步骤,直到将待压缩文本中所有文本块读入到文本压缩处理器中;
(2)计算字典存储地址:
(2a)依次将读入文本块中长度为八字节的自定义个数字符串进行编号,取出每个字符串中的前六个字符作为计算单元,对计算单元同时进行异或运算,得到字符串存放的索引值;
(2b)将索引值按照存放字符串的字典位置数进行取余操作,将得到的余数作为字符串在字典中对应的存储地址标号;
(3)标记存储地址标号有效信息:
(3a)判断同时处理的自定义个数字符串是否存在一样的存储地址标号,若是,执行步骤(3b),否则,执行步骤(3c);
(3b)将存储地址标号一样的字符串中编号最小的字符串对应的存储地址信息标记为有效信息,将其余存储地址信息标记为无效信息;
(3c)将所有字符串的存储地址标号标记为有效信息;
(4)查找历史字符串:
(4a)在字典存储器内查找与有效信息的字典存储地址对应的历史字符串;
(4b)将查找到历史字符串作为待匹配字符串;
(5)更新字典信息:
(5a)将字典存储器内与有效信息的字典存储地址对应的信息更新为当前待压缩的字符串;
(5b)将地址存放存储器内与有效信息的字典存储地址对应的信息更新为当前待压缩字符串的位置信息;
(6)判断在字典存储器查找中是否存在待匹配字符串,若是,则执行步骤(7),否则,直接执行步骤(9);
(7)匹配字符串:
(7a)将查找到的历史字符串作为待匹配字符串;
(7b)将当前待压缩字符串与待匹配字符串两者之间连续相同字符的个数记为匹配长度;
(7c)读出地址存储器内与有效信息的字典存储地址对应的位置信息,作为待匹配位置信息;
(7d)对待压缩字符串的位置信息与待匹配位置信息做差,将其值作为匹配距离;
(7e)找出所有匹配长度大于等于三的待压缩字符串作为匹配成功字符串;
(8)修剪匹配字符串:
(8a)将匹配成功字符串对应编号值与其自身的匹配长度求和,将和值作为匹配延伸距离;
(8b)将同时处理自定义个数的计算单元中,匹配延伸距离最长的匹配成功字符串,作为最长匹配字符串;
(8c)将匹配成功字符串中的字符与最长匹配字符串中字符相互重叠的个数,作为重叠数;
(8d)对重叠数不为零的匹配成功字符串的匹配长度与其重叠数作差,将差值作为修剪匹配长度;
(8e)找出修剪匹配长度大于等于三对应的匹配成功字符串作为压缩字符串;
(8f)将压缩字符串对应的修剪匹配长度和匹配距离组成修剪匹配对;
(8g)用修剪匹配对替换匹配成功字符串,得到修剪后的匹配字符串;
(8h)将修剪后的匹配字符串与未处理字符串组成匹配压缩文本;
(9)将得到的匹配压缩文本输入到哈夫曼编码处理器,进行码流压缩处理;
(10)获得长度哈夫曼码流:
(10a)对未匹配替换的待压缩字符串中的字符,用信息交换标准代码ascii转换为对应的数值,将该数值作为静态哈夫曼长度查找表的字符索引值;
(10b)对修剪后的匹配字符串,将匹配长度值作为静态哈夫曼长度查找表的长度索引值;
(10c)将未匹配替换的待压缩字符串和修剪后的匹配字符串统作为待处理字符串;
(10d)将静态哈夫曼长度查找表中字符索引值的码字,作为待处理字符的长度哈夫曼码字;
(10e)将静态哈夫曼长度查找表中长度索引值的码字,作为待处理字符的长度哈夫曼码字;
(11)获得距离哈夫曼码流:
(11a)将未替换的待压缩字符串中的字符的匹配距离设置为零;
(11b)将待处理字符串的匹配距离值作为静态哈夫曼距离查找表的距离索引值;
(11c)将静态哈夫曼距离查找表中距离索引值对应的码字作为距离哈夫曼码字;
(12)输出压缩码流:
(12a)将待处理字符串的长度哈夫曼码字和距离哈夫曼码字组成匹配压缩文本的压缩码流;
(12b)将压缩码流输出到压缩文件存储器。
本发明与现有技术相比具有如下优点:
第一,本发明采用将得到的匹配压缩文本再输入到哈夫曼编码处理器,进行码流压缩处理的方式,克服了现有技术中文本压缩方法单一的问题,使得本发明优化了文本的压缩过程,提高了压缩比。
第二,本发明采用将待压缩文本中的计算单元同时进行处理方式,克服了现有技术中顺序执行结构处理导致处理速度缓慢的问题,使得本发明合理地安排了数据处理顺序,易于fpga以流水结构完成文本压缩的并行处理。
第三,本发明采用待压缩文本自定义个数的字符串作为计算单元进行处理,克服了现有技术中只适用于固定大小的计算单元处理方式,使得本发明可以适用于不同规模的fpga开发环境。满足对不同压缩比和不同硬件资源规模消耗的需求。
第四,本发明完成从待压缩文件处理到压缩后的将压缩码流输出到压缩文件存储器的结构设计,对文本压缩的整个处理流程进行了实现,克服了现有技术中只对文本压缩中两个关键步骤进行硬件实现,并没有实现完整的文本压缩硬件实现的问题,使得本发明可以实现完整的文本压缩的硬件方案,加快了文本压缩处理速度。
附图说明
图1为本发明的流程图;
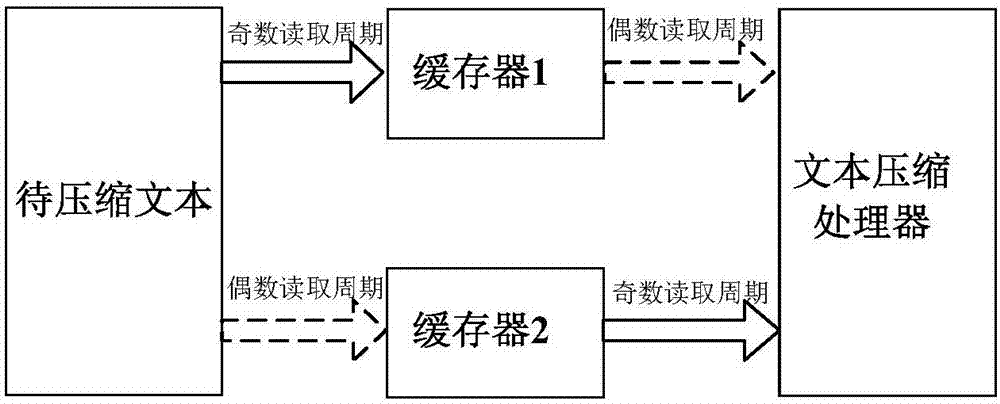
图2为本发明待压缩文件读入示意图;
图3为本发明同时处理待压缩文本中字符串结构示意图。
具体实施方式
下面结合附图对本发明做进一步的描述。
参照图1,本发明的具体实施步骤如下。
步骤1,读入待压缩文本。
下面结合图2对本发明的读入待压缩文本过程作进一步的描述。
图2中的实线和虚线分别表示不同的读取周期,其中实线代表奇数倍的读取周期,虚线代表偶数倍的读取周期,依次将待压缩文本中自定义缓存深度大小的文本块,读入到缓存器1中。
依次将未读入的自定义缓存深度大小的文本块,读入到缓存器2中的同时,将缓存器1中的文本块读入到文本压缩处理器中。
用依次读入自定义缓存深度大小的文本块更新缓存器1中存储的文本块,在更新缓存器1的同时,将缓存器2中的文本块读入到文本压缩处理器中。
重复以上两个步骤,直到将待压缩文本中所有文本块读入到文本压缩处理器中。
步骤2,计算字典存储地址。
下面结合图3对计算单元编号过程作进一步描述。
为了便于说明,图3中将自定义个数设置为8,对8个字符串依次设置为编号1到8的计算单元。依次将读入文本块中长度为八字节的自定义个数字符串进行编号,取出每个字符串中的前六个字符作为计算单元,对计算单元同时进行异或运算,得到字符串存放的索引值。
将索引值按照存放字符串的字典位置数进行取余操作,将得到的余数作为字符串在字典中对应的存储地址标号。
步骤3,标记存储地址标号有效信息。
第一步,判断同时处理的自定义个数字符串是否存在一样的存储地址标号,若是,执行第二步,否则,执行第三步。
第二步,将存储地址标号一样的字符串中编号最小的字符串对应的存储地址信息标记为有效信息,将其余存储地址信息标记为无效信息。
第三步,将所有字符串的存储地址标号标记为有效信息。
步骤4,查找历史字符串。
在字典存储器内查找与有效信息的字典存储地址对应的历史字符串。
将查找到历史字符串作为待匹配字符串。
步骤5,更新字典信息。
将字典存储器内与有效信息的字典存储地址对应的信息更新为当前待压缩的字符串。
将地址存放存储器内与有效信息的字典存储地址对应的信息更新为当前待压缩字符串的位置信息。
步骤6,判断在字典存储器查找中是否存在待匹配字符串,若是,则执行步骤7,否则,直接执行步骤9。
步骤7,匹配字符串。
将查找到的历史字符串作为待匹配字符串。
将当前待压缩字符串与待匹配字符串两者之间连续相同字符的个数记为匹配长度。
读出地址存储器内与有效信息的字典存储地址对应的位置信息,作为待匹配位置信息。
对待压缩字符串的位置信息与待匹配位置信息做差,将其值作为匹配距离。
找出所有匹配长度大于等于三的待压缩字符串作为匹配成功字符串。
步骤8,修剪匹配字符串。
将匹配成功字符串对应编号值与其自身的匹配长度求和,将和值作为匹配延伸距离。
将同时处理自定义个数的计算单元中,匹配延伸距离最长的匹配成功字符串,作为最长匹配字符串。
将匹配成功字符串中的字符与最长匹配字符串中字符相互重叠的个数,作为重叠数。
对重叠数不为零的匹配成功字符串的匹配长度与其重叠数作差,将差值作为修剪匹配长度。
找出修剪匹配长度大于等于三对应的匹配成功字符串作为压缩字符串。
将压缩字符串对应的修剪匹配长度和匹配距离组成修剪匹配对。
用修剪匹配对替换匹配成功字符串,得到修剪后的匹配字符串。
将修剪后的匹配字符串与未处理字符串组成匹配压缩文本。
步骤9,将得到的匹配压缩文本输入到哈夫曼编码处理器,进行码流压缩处理。
步骤10,获得长度哈夫曼码流。
对未匹配替换的待压缩字符串中的字符,用信息交换标准代码ascii转换为对应的数值,将该数值作为静态哈夫曼长度查找表的字符索引值。
对修剪后的匹配字符串,将匹配长度值作为静态哈夫曼长度查找表的长度索引值。
将未匹配替换的待压缩字符串和修剪后的匹配字符串统作为待处理字符串。
将静态哈夫曼长度查找表中字符索引值的码字,作为待处理字符的长度哈夫曼码字。
将静态哈夫曼长度查找表中长度索引值的码字,作为待处理字符的长度哈夫曼码字。
步骤11,获得距离哈夫曼码流。
将未替换的待压缩字符串中的字符的匹配距离设置为零。
将待处理字符串的匹配距离值作为静态哈夫曼距离查找表的距离索引值。
将静态哈夫曼距离查找表中距离索引值对应的码字作为距离哈夫曼码字。
步骤12,输出压缩码流。
将待处理字符串的长度哈夫曼码字和距离哈夫曼码字组成匹配压缩文本的压缩码流。
将压缩码流输出到压缩文件存储器。
下面结合仿真实验对本发明的效果做进一步的描述。
1.仿真条件:
本发明的仿真实验是采用xilinx公司的vivadohls2016.1作为综合工具,首先创建工程项目,在xilinxvivadohls2016.1的工具栏中点击file->openproject,按照保存路径打开工程;其次在工具栏中点击csynthesis,启动硬件编译。
2.仿真内容:
对本发明设计的基于gzip硬件实现文本压缩方法对不同的自定义个数处理单元进行仿真。
3.仿真结果分析:
表1为本发明仿真不同窗口大小文本压缩实现性能比较一览表。由下表可以看出,当计算单元的个数等于8时,吞吐率等于1.73gb/s,文本压缩后的压缩比为1.75倍,当计算单元个数扩大一倍为16时,吞吐率增加到3.46gb/s,文本的压缩比提高到2.14倍。由此可见,当窗口大小较大时,吞吐率和压缩比均得到提高,其中,窗口大小的变化与吞吐率的提高成比例增长关系。因此,本发明可以适用于不同吞吐率和压缩比的需求背景。
表1不同窗口大小文本压缩实现性能比较
- 还没有人留言评论。精彩留言会获得点赞!