一种高维核矩阵极化码的低复杂度连续消去译码方法与流程
本发明属于高维核矩阵极化码
技术领域:
,尤其涉及一种高维核矩阵极化码的低复杂度连续消去译码方法。
背景技术:
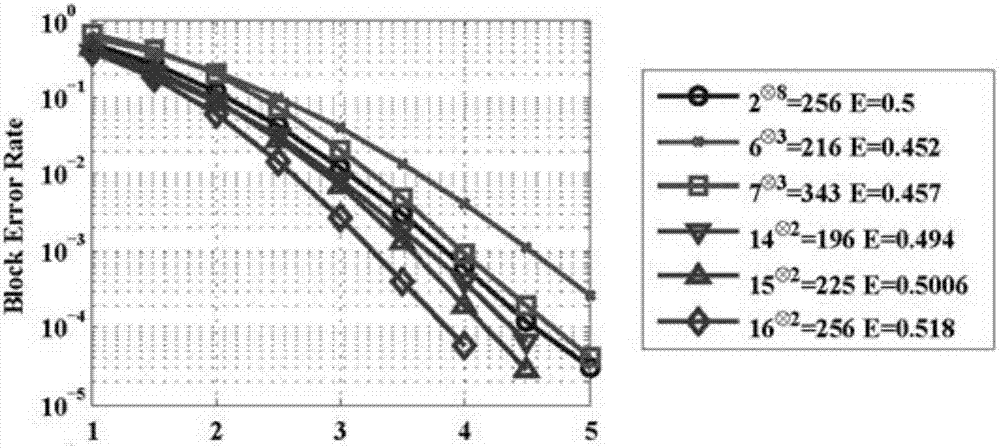
:由arikan发明的极化码(polarcodes),是第一类在二进制输入离散无记忆类信道下,可以达到信道容量,并且有着明确的构造方法和低编/译码复杂度的信道编码。arikan原始的极化码基于核矩阵它的n次克罗内克指数对应一个码长为n=2n的线性码。基于g2核矩阵,sc译码下的误帧率是其中β=0.5。β称为核矩阵的极化因子,对于大的m×m核矩阵gm,极化因子能超过0.5。研究者们已经设计出有着大的极化因子的高维核矩阵。然而,gm生成的极化码的直接sc译码复杂度是o(2mnlogn)。推广g2极化码的sc译码算法的思想到高维核矩阵。但是它的方法只能在维数较小的核矩阵上成立,如m≤5。目前为止对于这些高维核矩阵生成的极化码没有有效(维数的多项式复杂度)的sc译码。综上所述,现有技术存在的问题是:高维核矩阵生成的极化码的高译码复杂度高。技术实现要素:针对现有技术存在的问题,本发明提供了一种高维核矩阵极化码的低复杂度连续消去译码方法。本发明是这样实现的,一种高维核矩阵极化码的低复杂度连续消去译码方法,所述高维核矩阵极化码的低复杂度连续消去(sc)译码方法采用l-表达式和w-表达式方法来简化sc译码的递归计算公式;对于任意线性二进制核矩阵,获得sc译码的以似然比形式表示的简化递归公式,也即l-表达式;类似于l-表达式,再获得sc译码的以转移概率二元组形式表示的简化递归公式;对于一个m×m二进制核矩阵,直接sc译码的复杂度为o(2mnlogn)。进一步,采用w-表达式,利用w-表达式,当m≤16时,将直接sc译码的复杂度降低为o(m2nlogn);所述l-表达式生成方法包括:输入:一个核矩阵gm,位序号i和信道似然比l1,…,lm;输出:作为l1,…,lm的一个函数;//算法开始于预处理过程:对执行隐藏已知量和标准表达式变换;进一步,所述l-表达式生成方法中:1)隐藏已知量:给定一个核矩阵gm,ga和gb是gm的子矩阵,分别为gm的前i-1行和后m-i+1行;令有既然aj,j=1,…,m是已知量,用下式替代:通过算法得到的l-表达式,则真正的l-表达式是2)标准表达式变换:一个标准的似然表达式有以下的形式:即uj=uj,j=i+1,…,m;对于任意似然表达式它能被转化成一个标准表达式;4)给定一个仅有一处不同的似然比表达式,如:u1和um包含ui+1,则有:其中分子中如果uk包含ui+1,那么xk=uk+u1;否则xk=uk,k=2,…,m;在分母中,如果uk包含ui+1,则为否则为xk;4)对称表达式变换:表达式的长度取决于中不同之处的个数,位信道的对称性质。给定一个位信道表达式:和假定仅有u1和ui包含ui+1,有:对称表达式变换:给定一个似然比表达式为在的分母中对的所有子集使用位信道的对称性质,获得2m-i个等价的似然比表达式;假定在这些表达式中lm(i)具有最少的不同之个数,则用lm(i)替代5)两种简化:给定一个似然比表达式如下:有:其中则有给定一个似然比表达式如下:和u2∩uk=φ,k=3,…,m。则有:其中则有进一步,所述w-表达式生成方法包括:输入:一个核矩阵gm,位序号i和信道输出b(y1),…,b(ym);输出:作为b(y1),…,b(ym)的一个函数;//算法开始于预处理:对执行隐藏已知量和标准表达式变换;本发明的另一目的在于提供一种应用所述高维核矩阵极化码的低复杂度连续消去译码方法的高维核矩阵极化码。本发明的优点及积极效果为:设计了一种l-表达式方法,对于任意线性二进制核矩阵,可以获得sc译码的以似然比形式表示的简化递归公式,这些公式可以降低相应的sc译码的复杂度;通过分别考虑位信道转移概率和本发明提出一种w-表达式方法,进一步降低了sc译码的复杂度。对于一个m×m二进制核矩阵,直接sc译码的复杂度为o(2mnlogn);利用w-表达式,当m≤16时,本发明将直接sc译码的复杂度降低为o(m2nlogn)。仿真结果表明在sc和lsc译码下,相比于2×2核矩阵生成的极化码,16×16核矩阵生成的极化码在纠错性能方面有明显的提升。附图说明图1是本发明实施例提供的高维核矩阵极化码的低复杂度连续消去译码方法流程图。图2是本发明实施例提供的核矩阵为g2,g6,g7,g14,g15,g16的极化码在sc译码算法下的误帧率示意图。图3是本发明实施例提供的核矩阵为g2,g16的极化码在列表sc(l为列表长度)译码算法下的误帧率示意图。具体实施方式为了使本发明的目的、技术方案及优点更加清楚明白,以下结合实施例,对本发明进行进一步详细说明。应当理解,此处所描述的具体实施例仅仅用以解释本发明,并不用于限定本发明。下面结合附图对本发明的应用原理作详细的描述。如图1所示,本发明实施例提供的高维核矩阵极化码的低复杂度连续消去译码方法包括以下步骤:s101:执行隐藏已知量和标准表达式变换;s102:执行两种简化;s103:执行对称表达式变换;s104:执行扩展方法;s105:执行基本步骤。下面结合附图对本发明的应用原理作进一步的描述。本发明针对任意二进制线性核矩阵提出一个低复杂度的sc译码。对于g2,有(被称为l-表达式),导致g2极化码的一个低复杂度sc译码算法。像g2一样,是去获得针对任意二进制线性核矩阵gm的l-表达式。图2为核矩阵为g2,g6,g7,g14,g15,g16的极化码在sc译码算法下的误帧率。所有码的构造都是基于高斯近似的密度进化方法;图3核矩阵为g2,g16的极化码在列表sc(l为列表长度)译码算法下的误帧率,其中码通过文献[i.talanda.vardy,``howtoconstructpolarcodes,”ieeetrans.inf.theory,vol.59,no.10,pp.6562-6582,oct.2013.]中的方法构造,码有蒙特卡罗方法构造。所有码的码率都为0.5,信道配置为bpsk调制和高斯白噪声信道,构造极化码时的信噪比为eb/n0=2db。图2表明了不同核矩阵的极化码通过awgn信道在sc和lsc译码下的错误性能。从图中可以看出相比于g2极化码,g16极化码有明显的译码性能提升。下面结合具体实施例对本发明的应用原理作进一步的描述。实施例1:一个g6核矩阵的l-表达式:给出一个6×6的最优核矩阵的l-表达式,在所有的6×6核矩阵中,该矩阵有着最大的极化因子。对于g6生成的极化码,直接的sc译码复杂度为o(26nlogn)。利用这些l-表达式,本发明降低该复杂度为o(7nlogn),其中7是l-表达式的长度(稍后被定义)。核矩阵为:l1,…,l6定义为li=w(yi|0)w(yi|1)(是信道),它们是信道似然比。是位信道似然比。lilj指li×lj。对于通过连接的两部分叫做子表达式。操作是类似于×,它是特别用来分离子表达式。三个操作符的优先级是通过分析,当核矩阵维数m≤10时,基于l-表达式的sc算法的复杂度是可以接受的。然而,对于较大的核矩阵,如m=16它变得不实际。因此,类似于l-表达式,通过分别考虑位信道转移概率和本发明进一步提出了一个w-表达式方法,对于较大维数的核矩阵进一步降低了其sc译码的复杂度。本发明的主要的贡献是:利用w-表达式方法,对于给定的最优核矩阵,当m≤16,gm极化码的sc译码复杂度为o(m2nlogn)。令w:{0,1}→y表示一个b-dmc信道,其中{0,1}表示输入集合、y表示输出集合、w(y|x),x∈{0,1},y∈y表示转移概率。本发明使用符号表示一个行向量(a1,…,an)。对于一个一般的核矩阵,定义为:位信道定义为:对于sc译码,需要计算如下值:其中指为了简化符号,本发明用下面的简单符号替代(3)其中和(如果gik=1,则分母中它是)。在公式(4)中,本发明看到分子中的信道表达式w(y1|u1)是不同于分母中的本发明称这个为的一处不同。需要注意的是:ui是被视作二进制变量的一个表达式。例如,在的定义中u1=u4+u5+u6。令si表示包含在ui中变量的集合。所以在之前的例子中si={u4,u5,u6}。ui∩uj=φ意味着si∩sj=φ。意味着在本发明中的所有操作将会是在二进制领域gf(2)上。因此,如果u1=u4+u5和u2=u5+u6,则u1+u2=u4+u6。本发明写表示等式u1=0的指示函数;即如果u1=0,那么否则等于0。在实施例1中,是由两个子表达式用×连接起来的。本发明称的长度是2。其他l-表达式的长度都是1。因此这个例子的总长度是7。利用公式(3)计算的复杂度是o(m2m)。本发明称这些计算为核矩阵内部计算。通过定义的码长为n=mn的极化码在sc译码下需要递归地完成次的核矩阵内部计算。所以对于一个通常的的核矩阵gm,sc译码复杂度是它随着核矩阵维数的大小呈指数级增长。因此,本发明的根本任务就是降低(3)式的计算复杂度。实施例2:gm的l-表达式,对于一个任意给定核矩阵gm,本发明将给出其l-表达式的生成方法。本发明用去阐述l-表达式的生成算法。根据定义(3),本发明得到(5)。事实上,本发明在(5)中忽略已知量a1=u1+u2+u3,a2=u2,a3=u3。本发明将会在(11)中添加它们。起初忽略已知量,然走在最后的步骤中加入它们的这个操作是称作隐藏已知量。在(6)和(7)中定义w(y3,y5|u5)=w(y3|u5)w(y5|u5)。然后有这个函数是称作零变量结合。通过添加一个中间项,本发明从(5)得到(6)和(7)。和普通的乘法×一样。很显然,本发明把(6)和(7)称作子表达式。特别被用来分离子表达式。就可以看出(6)和(7)中都仅有一处不同。本发明把从(5)获得的这个函数称为扩展方法。利用(6)中有一处不同的性质,本发明得到(8)的左部分。这是算法的关键步骤,被称为基本步骤。首先,在(7)中定义这是零变量结合。然后,定义本发明得到(8)的右部分。本发明称这个函数为1变量结合。然后本发明有通过对(8)的左部分中的分子和分母中各自的每一个信道表达式做u5=u6和u5=u6+1替换,获得(9)的左部分。通过在(8)的右部分做零变量结合和基本步骤获得(9)的右部分。对(9)的左部分执行基本步骤,然后对(9)的左右两部分中都做u6=0和u6=1替换,本发明得到(10)。在(10)中替换本发明得到(11)。实例3:对于l-表达式生成算法的一个高层次描述,在上述表述的函数基础上,本发明还需要标准表达式变换和对称表达式变换两个函数。这两个函数不是必要的,但是它能简化最终的l-表达式。为了表述简介,本发明使用两种简化去表示零变量结合和1变量结合。根据这些函数,在算法1中本发明给出了l-表达式生成算法的一个高层次描述。算法1:l-表达式生成程序输入:一个核矩阵gm,位序号i和信道似然比l1,…,lm输出:作为l1,…,lm的一个函数//算法开始于预处理过程:对执行隐藏已知量和标准表达式变换在算法1中,每一步都在其上一步的结果上执行。在一个while循环完成后,求和的开始值至少减少1(如(8)到(9),到u6)。因此,这个算法至多进行m-i+1次while循环后停止。函数的细节:1)隐藏已知量:给定一个核矩阵gm,ga和gb是gm的子矩阵,分别为gm的前i-1行和后m-i+1行。令本发明有既然aj,j=1,…,m是已知量,本发明能够用以下的式子替代(3)命题1(隐藏已知量):假定本发明通过算法使用(12)得到的l-表达式。则真正的l-表达式是2)标准表达式变换:定义1(标准表达式):一个标准的似然表达式有以下的形式:即uj=uj,j=i+1,…,m。引理1(标准表达式变换):对于任意似然表达式它能被转化成一个标准表达式。5)基本步骤:引理2(基本步骤):给定一个仅有一处不同的似然比表达式,如:假定u1和um包含ui+1,则本发明有:其中在(14)式的分子中如果uk包含ui+1,那么xk=uk+u1;否则xk=uk,k=2,…,m。在(14)的分母中,如果uk包含ui+1,则为否则为xk。确保表达式只有一处不同是实现引理2的关键。下面命题提供了一种方法去实现它。命题2(扩展方法):给定有两处不同之处的似然比表达式例如:本发明有:很容易可以看出扩展方法可以是被推广到有任意个数的不同之处。4)对称表达式变换:最终表达式的长度取决于中不同之处的个数。利用位信道的对称性质,对于一个给定的可以减少其不同处的个数。位信道的对称性质。给定一个位信道表达式:和假定仅有u1和ui包含ui+1,本发明有:在以上的例子中,本发明把ui+1变为实际上,本发明能改变的所有可能的子集。令表示的一个子集。本发明把它变为对于一个uk,如果它包含子集中的奇数个元素,那么uk变为否则它不变。对称表达式变换:给定一个似然比表达式为(3)的在的分母中本发明对的所有子集使用位信道的对称性质,获得2m-i个等价的似然比表达式。假定在这些表达式中lm(i)具有最少的不同之个数,则用lm(i)替代5)两种简化:命题3(零变量结合):给定一个似然比表达式如下:我们有其中则有命题4(1变量结合):给定一个似然比表达式如下:假定u2=ui+1,和u2∩uk=φ,k=3,…,m。则有其中则有表1对于不同核矩阵的cl(m)m2345678极化因子0.50.420.50.430.4510.4570.5cl(m)1.01.01.01.01.22.03.69101112131415160.4610.4690.4770.4920.4880.4940.50080.5183.861749952787932487实例4通过w-表达式降低复杂度:a.l-表达式的复杂度分析:对于一个核矩阵gm,令cl(m)表示其l-表达式平均长度。实际上gm是子表达式的平均个数。对于一个核矩阵gm,计算一个子表达式的复杂度是o(m)。对于核矩阵的内部计算需要计算mcl(m)个子表达式。那么核矩阵内部计算的复杂度是o(m2·cl(m))。因为sc译码算法需要递归地执行次核矩阵内部计算,所以对于一个核矩阵gm的sc译码算法的复杂度为表1给出了不同的核矩阵cl(m)(m≤16)。容易看出l-表达式方法是对于维数较小的核矩阵(如m≤10),复杂度是可以接受的。然而,cl(m)随着核矩阵维数m迅速的增长。事实上,就错误性能而言g16与g2相比是第一个获得明显优势的核矩阵。但是cl(16)大约是cl(2)的2487倍,其意味着基于g16的极化码的sc译码的复杂度大约是基于g2的极化码的复杂度2487*16/(2*log216)=4974倍。显然这个复杂度是不能被接受的。b.通过w-表达式降低复杂度:对于维数较大的核矩阵,在前一小节中表明l-表达式sc译码算法复杂度是不可接受的。其中一个原因是由于的分子和分母之间的联系是的本发明不能在一些情况中实现两种简化。为了解决这个问题,本发明提出一种称为w-表达式的方法,其通过分别考虑的分子和分母,可以进一步降低sc译码算法的复杂度。在w-表达式中,本发明考虑如下式子的简化计算:首先,本发明给出一些定义。然后本发明叙述如何使用w-表达式来简化(17)式的计算。定义2:令b(yi)=(b(yi|0),b(yi|1))=(w(yi|0),w(yi|1)),定义:引理3(w-表达式的基本步骤):给定一个信道表达式为(17),并假定u1和um包含u1,本发明有:其中在(18)的左部分中如果uk包含ui+1,则xk=uk+u1;否则xk=uk,k=2,…,m。在(18)式的右部分中,如果uk包含ui+1,那么否则xk=xk。从(17)式到(18)式,本发明从(17)中分解出b(y1),然后剩余的两部分是和(17)式有着同样的形式。因此,本发明能重复地使用引理3,获得作为(b(y1),…,b(ym))的一个函数。对于w-表达式,隐藏已知量和标准函数表达式变换是和l-表达式一样的。在最终的w-表达式中,对于零变量结合本发明有和对于1变量结合有对于w-表达式,不需要对称表达式变换和扩展方法。根据上面的函数描述,本发明在算法2中给出w-表达式生成算法。算法2:w-表达式产生程序输入:一个核矩阵gm,位序号i和信道输出b(y1),…,b(ym)输出:作为b(y1),…,b(ym)的一个函数//算法开始于预处理:对执行隐藏已知量和标准表达式变换c.w-表达式的复杂度分析在实施例1对于的算法中,l3l5仅需要计算一次。本发明把这个称为内部表达式简化。对于l-表达式的复杂度分析,本发明没有考虑内部表达式简化,这是因为它没有使复杂度明显地降低。然而,对于w-表达式,考虑内部表达式简化可以使得复杂度明显地降低。例如,的长度是512。但是本发明仅需要计算16个子表达式,因为其它子表达式都是这16个子表达式的重复。令cw(m)表示一个核矩阵gm生成的w-表达式的平均长度。表2给出了最优的核矩阵的cw(m),2≤m≤16。它表明当m≤16时基于w-表达式的sc译码算法的复杂度是o(m2nlogn)。表2对于不同核矩阵的cw(m)下面结合具体实施例对本发明作进一步描述。实施例5:一个g6核矩阵的w-表达式:w6(1)(·|0)=s(b(y1)◇b(y2)◇b(y3)◇b(y4)◇b(y5)·b(y6))w6(1)(·|1)=s(b(y1)-1◇b(y2)◇b(y3)◇b(y4)◇b(y5)·b(y6))w6(2)(·|0)=s(b(y1)◇b(y3)·b(y4))·s(b(y2)◇b(y5)·b(y6))w6(2)(·|1)=s(b(y1)-1◇b(y3)·b(y4))·s(b(y2)-1◇b(y5)·b(y6))w6(3)(·|0)=s(b(y2)◇(b(y1)◇b(y4)·b(y3)·b(y5))·b(y6))w6(3)(·|1)=s(b(y2)◇(b(y1)-1◇b(y4)·b(y3)-1·b(y5))·b(y6))w6(4)(·|0)=s((b(y1)·b(y2))◇(b(y3)·b(y5))·b(y4)·b(y6))w6(4)(·|1)=s((b(y1)-1·b(y2))◇(b(y3)·b(y5))·b(y4)-1·b(y6))w6(5)(·|0)=l(b(y3)◇b(y5))·s(b(y1)·b(y2)·b(y4)·b(y6))w6(5)(·|1)=r(b(y3)◇b(y5))·s(b(y1)-1·b(y2)-1·b(y4)·b(y6))w6(6)(·|0)=s(b(y1)·b(y2)·b(y3)·b(y4)·b(y5)·b(y6))w6(6)(·|1)=s(b(y1)-1·b(y2)-1·b(y3)·b(y4)-1·b(y5)·b(y6)-1)。以上所述仅为本发明的较佳实施例而已,并不用以限制本发明,凡在本发明的精神和原则之内所作的任何修改、等同替换和改进等,均应包含在本发明的保护范围之内。当前第1页12
相关技术
网友询问留言
已有0条留言
- 还没有人留言评论。精彩留言会获得点赞!
1