一种全并行高吞吐量LDPC译码方法与流程
本发明涉及数字通信领域,特别涉及一种全并行高吞吐量的ldpc译码方法。
背景技术:
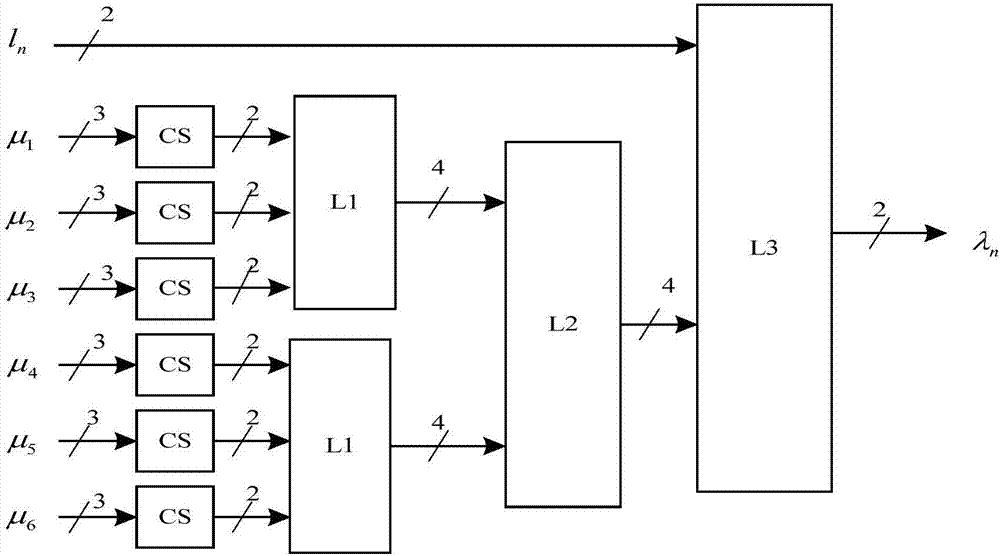
:对于无线通信而言,终端设备一般具有体积小、携带方便、能耗低的特点。无线设备的续航能力正日益为人们所重视,因此如何降低上行通信中的发射功率和下行通信中的接收功率就成了人们当务之急,降低发射功率带来的必然结果是降低接收机的信噪比,使得接收变得异常困难,而因为ldpc(lowdensityparitycheckcode,低密度奇偶校验码)能在接近于香农极限的性噪比条件下正常工作,因此它能够得到广泛的认可。现阶段,信息时代的到来促使无线通信的快速发展。为了满足人们日益增长的文化娱乐需求,wifi联盟提出了无线吉比特通信标准ieee802.11ad,它具有高速率、高容量、低延迟、低功耗等特点。802.11ad标准使用60ghz频谱资源丰富的频段,支持两种调制方案,ofdm方案允许的最大传输速率7gb/s,单载波方案支持的传输速率最高4.6gb/s。面对通信系统传输速率的不断提高,高效的ldpc编解码实现方法也越来越成为研究的重点。现有的文献对高吞吐量ldpc码编码构造方法进行了研究。文献1(易旭,杜昊阳,ldpc码的研究进展和应用展望[j].通信技术,2016,1(49):1-6.)给出了多种标准和场景下的ldpc码的应用,其中一种通过应用高效的比较技术和自动多层处理流程实现高效译码器的吞吐量达到了5.13gb/s,此外,高效多进制半随机译码器设计设计方法(168,84)规则(2,4)nb-ldpcovergf(16)码在时钟速率286mhz的情况下,吞吐量达到了1.13gb/s。文献2(王英喆,王振宇,严伟,时广轶等.高吞吐率ldpc码编译码器的fpga实现[j].微电子学与计算机,2015,11(32):97-100)对比了生成矩阵的不同存储方式以优化编码结构译码算法选用改进的最小和算法,并以移位寄存器作为编译码器基本单元实现了在时钟速率150mhz的情况下,吞吐量达到1.26gb/s。专利1(一种基于多进制ldpc码的高速译码器及其译码方法,cn201710149925.6,2017)提供了一种基于层级全并行的多进制ldpc码的译码器架构,该方法在tsmc90nm的cmos工艺下,频率207.04mhz条件下,逻辑门数量为4.54m,在最大迭代次数为10次时,吞吐量为21.66gbps。该方法吞吐率较高,但占用逻辑资源较多,不利于在fpga实现的场合。专利2(通用型高速ldpc码编码方法及编码器,cn201611136149.8,2016)提出了一种基于优化的高斯消元算法的编码方法,该方法在fpga上可以以270mhz时钟频率工作,吞吐量达到15.1gbps,但是该方法只给出了编码实现,未给出解码方法。专利3(一种基于fpga的高速自适应dvb-s2ldpc译码器及译码方法,cn201610955524.5,2016)提供了多码率兼容译码方法,该方法在xc7vx485t上最大吞吐率可达5gbps,资源消耗为67%,但该方法在资源和吞吐量上仍未能达到最大优化。技术实现要素:本发明的目的是提供一种全并行高吞吐量的ldpc译码方法,其为了克服现有技术中存在的不足,以(2048,1723)rs-ldpc码为例(rs-ldpc码是ldpc码的一种码型),在2bit量化的基础上使用改进的最小和算法,使得译码算法的总时钟数减小,提高信息传输的吞吐量,改善通信系统误码性能,同时减少译码算法fpga实现过程中整体资源的使用率,以此实现全并行译码结构。为了达到上述目的,本发明的一种全并行高吞吐量的ldpc译码方法,包含以下过程:步骤1、将从信道中接收的信息进行量化后进行存储,用于后续的变量节点更新;步骤2、进行变量节点的更新;步骤3、进行校验节点的更新;步骤4、当变量节点信息和校验节点信息更新后,完成第一次更新迭代计算,再进行多次更新迭代,变量节点更新值的符号得到译码输出。优选地,所述步骤1中的量化过程为2bit量化。优选地,所述第一次更新迭代运算中,变量节点的更新值为所述步骤1中经过2bit量化后的信息;该更新迭代运算之后的更新迭代运算中,变量节点更新模块根据校验矩阵中每列1的位置选取与该变量节点相对应的校验节点信息进行信息更新。优选地,当在所述变量节点信息更新后,将更新的信息传输给校验节点;校验节点更新模块根据校验矩阵中每行1的位置选取与该校验节点相对应的变量节点信息进行信息更新。优选地,所述步骤1的具体方法为:先设置门限值t为3/8,将信道信息yn进行量化,得到2bit信息,该2bit信息分别用bs、bc表示:bs=sign(yn)式中,bs表示符号,bc表示幅值。优选地,所述步骤2中,变量节点的更新算法为:式中,mn表示与该变量节点相连的校验节点,修改因子α等于0.5,ln表示接收到的信道信息;f[]为2bit输入x映射为4bit输出,用fs表示输出的1bit符号信息,fc表示输出的3bit幅值信息:fs=sign(x)式中,g[·]表示将输入x映射为2bit输出,用gs表示输出的1bit符号信息,gc表示输出的1bit幅值信息:优选地,所述步骤3中,校验节点的更新算法为:式中,nm\n表示除了第n点与该校验节点相连的变量节点,min表示对应行的绝对值最小值,pos表示对应行最小值的列数,sec表示对应行的绝对值次小值。优选地,所述步骤4中的多次迭代的次数为10次。优选地,所述变量节点的更新算法的结构包含:多个第一逻辑、一个第二逻辑和一个第三逻辑;所述第一逻辑的输出表示多个输入信息相加的结果;所述第二逻辑的输出表示第一逻辑的所有输入信息相加的结果;所述第三逻辑的输出表示信道信息ln和输入校验信息的总和经过g函数映射后的结果当校验节点更新模块的输入为2bit信息,该输入信息的绝对值最小值和次小值的算法进行简化的方法为:式中,sm(k)表示校验节点更新模块输入信息的符号和;当校验节点更新模块的输入为1bit信息,通过逻辑组合方法进行计算最小值和次小值;所述逻辑组合包含有:第五逻辑、第六逻辑和第七逻辑;所述第五逻辑将多个输入值进行逻辑运算得到多个第一最小值和多个第一次小值;所述第六逻辑将所述第五逻辑输出的多个第一最小值和多个第一次小值作为输入,进行逻辑运算得到多个第二最小值和多个第二次小值;所述第七逻辑将所述第六逻辑输出的多个第二最小值和多个第二次小值作为输入,进行逻辑运算得到最终的最小值和次小值。与现有技术相比,本发明的有益效果为:本发明可在2bit量化的基础上使用改进的最小和算法,简化变量节点更新结构和校验节点更新结构,既可以减少译码算法fpga实现需要的时钟数又可以减少占用的总资源;提高信息传输的吞吐量、吞吐率和编码增益,提高硬件资源利用率,改善通信系统误码性能,同时减少译码算法fpga实现过程中整体资源的使用率,以此实现全并行译码结构。附图说明图1本发明的变量节点更新算法结构示意图;图2本发明的变量节点更新算法改进结构示意图;图3a-图3c本发明的校验节点更新算法结构示意图;图4本发明的(2048,1723)ldpc码译码性能曲线示意图。具体实施方式本发明提供了一种全并行高吞吐量的ldpc译码方法,为了使本发明更加明显易懂,以下结合附图和具体实施方式对本发明做进一步说明。本发明是一种针对高速通信的全并行高吞吐量的ldpc译码方法,本实施例主要是以rs-ldpc译码算法为例进行说明,但本发明的方法不局限于这一种码型,同样也适用于其他的ldpc码。本发明的全并行高吞吐量的ldpc译码方法的步骤为:步骤1、从信道中接收的信息先进行2bit量化,再存入寄存器中,用于后续的变量节点更新。步骤2、进行变量节点的更新。在第一次更新迭代运算中,变量节点的更新值为步骤1中经过2bit量化后的信息。在之后的更新迭代运算中,变量节点更新模块根据校验矩阵中每列“1”的位置选取与该变量节点相对应的校验节点信息进行信息更新。步骤3、进行校验节点更新。当在变量节点信息更新后,将更新信息传输给校验节点;校验节点更新模块根据校验矩阵中每行“1”的位置选取与校验节点相对应的变量节点信息进行信息更新。步骤4、当变量节点信息和校验节点信息这两个节点信息更新完后,即完成第一次迭代计算。按照上述方法,当迭代次数达到10次后,根据变量节点更新值的符号得到译码输出。其中,步骤1的具体方法如下:设置门限值t为3/8,将信道信息yn进行量化,得到2bit信息,该两bit信息分别由bs、bc表示:式中,bs表示符号,bc表示幅值。步骤2的具体方法如下:变量节点的更新算法为:式中,mn表示与该变量节点相连的校验节点,修改因子α可以等于0.5,ln表示接收到的信道信息,f[]为2bit输入x映射为4bit输出,用fs表示输出的1bit符号信息,fc表示输出的3bit幅值信息:式中,g[]表示将输入x映射为2bit输出,用gs表示输出的1bit符号信息,gc表示输出的1bit幅值信息:如图1所示,变量节点更新算法的结构中,输入为1bit的最小值、1bit的次小值和1bit的符号信息。通过选择和映射可以得到4bit信息d,该信息d仅有4种情况,则3个信息d相加得到的结果有16种可能性,且通过4bit数据便可全部表示出来。其中,μ1、μ2、μ3、μ4、μ5和μ6为输入。所以,变量节点的更新算法结构可以进行改进,改进后的算法结构如图2所示。逻辑l1的输出表示3个信息d相加的结果,则逻辑l2的输出表示6个信息d相加的结果。6个信息d相加共有49种情况,可以用5bit数据表示。由于输入数据的总和需要乘以修改因子α,则逻辑l2的输出表示乘以修改因子后的结果,即相加结果所处的值域如表1所示。表1相加结果所处的值域逻辑l3表示信道信息和输入校验信息的总和经过g函数映射后的2bit输出λn。通过图1和图2的比较可以看出,变量节点更新模块fpga实现过程中图2比图1至少减少了2个时钟,且在变量节点更新模块fpga的flip-flop和lut的消耗上均有减少。步骤3的具体方法如下:校验节点的更新算法为:式中,nm\n表示除了第n点与该校验节点相连的变量节点,min表示对应行的绝对值最小值,sec表示对应行的绝对值次小值,pos表示对应行最小值的列数,n'=pos表示与校验节点相连的列;由此可知,与校验节点相连的pos列取对应行的最小值,其余的列取对应行的次小值。本发明的上述算法具体实现过程中提及的相关数字均是以(2048,1723)ldpc为基础并通过仿真可以得到的。由于校验节点更新模块的输入为2bit信息,所以其绝对值最小值和次小值的算法可以进行简化:式中,sm(k)表示校验节点更新模块输入信息的符号和。1bit信息数据计算最小值和次小值可以通过简单的逻辑组合,如图3a、图3b和图3c所示的部分结构图。其中,在图3a中为4个输入计算最小值和次小值:对于(2048,1723)ldpc码,校验节点更新共有32个输入(例如,图3a中的d1、d2、d3和d4均为检验节点的输入),则共有8个图3a的m1结构,相应输出8个min和8个sec,分别进入两个图3b的m2结构(其中,每个图3b的结构的输入均有四个min和四个sec,例如图3b中的min1、min2、min3、min4以及sec1、sec2、sec3和sec4),此时得到的最小值和次小值为:图3b的m1结构得到2个min和2个sec作为图3c的m3结构的输入,得到最终的最小值和次小值:对于全并行译码算法的变量节点更新模块fpga实现,变量节点和校验节点的更新模块根据校验矩阵中“1”的位置在1个时钟内完成相应数据的读取。另外,在译码实现过程中,校验节点更新和变量节点更新是交替进行的,不能充分利用硬件的资源。为了提高吞吐量和硬件资源利用率,可以将两帧数据同时进行译码,校验节点更新模块和变量节点更新模块交替处理两帧数据。该方法可以在增加较少的硬件资源的情况下将译码吞吐量提升一倍,具体的资源使用率见表2。表2基于本发明的硬件资源使用率变量节点更新结构flip-flopluts图1(优化前)196554114519图2(优化后)11061987641利用matlab仿真平台对本发明提出的全并行rs-ldpc译码算法进行验证,图4给出了迭代10次后的译码性能曲线,在误码率达到10e-6情况下,该方法可以达到5.5db编码增益。根据上述具体实施描述,本发明的每次迭代计算所需要的时钟数量为10次,按照总共迭代10次计算,总共需要100个时钟个数。该方法在xc7k410tfpga上占用资源为34%,在200mhz工作频率下,本发明的信息吞吐量可以达到16gbps,资源消耗具体情况如上表2所示,可以看出相对于同类系统,本发明在有效利用硬件资源的同时,获得了较高的吞吐率和编码增益,实验结果充分证明了本发明的有效性,也体现了本发明的优点。尽管本发明的内容已经通过上述优选实施例作了详细介绍,但应当认识到上述的描述不应被认为是对本发明的限制。在本领域技术人员阅读了上述内容后,对于本发明的多种修改和替代都将是显而易见的。因此,本发明的保护范围应由所附的权利要求来限定。当前第1页12
相关技术
网友询问留言
已有0条留言
- 还没有人留言评论。精彩留言会获得点赞!
1