基于生成矩阵的QC_LDPC码编码方法及编码器与流程
本发明涉及编码技术领域,更具体地说,涉及一种基于生成矩阵的qc_ldpc码编码方法及编码器。
背景技术:
目前,由于ldpc码几乎适用于所有的信道,性能逼近香农限,易于进行理论分析和研究,适合硬件实现,因此成为编码界研究热点。根据校验矩阵h每行和每列中非零的个数是否相等,ldpc码可以分为规则码和非规则码,如果校检矩阵h的每行和每列中非零元素的个数都是相同的,则该ldpc码称为规则ldpc码;否则为不规则ldpc码。同等条件下不规则ldpc码性能比规则ldpc码更好,但其编译码相对比较复杂。qc_ldpc码即为规则ldpc码,其生成矩阵g具有准循环结构,这样就可以通过简单的移位器和累加器进行编码。基于生成矩阵g的编码方法有三种:串行编码、全并行编码以及部分并行编码。其中串行编码所需编码时间为信息序列长度的编码周期,速度非常慢,不适用于高速通信的情景;全并行编码虽然速度很快,但需要事先准备好一帧信息序列,这在信息位长度较长时会带来非常大的存储代价,无法应用;因此目前基于生成矩阵的编码多采用部分并行编码方法。
然而传统的部分并行编码方法在硬件实现时耗费资源较多,增大了芯片面积,体现在以下方面:
(一)传统编码器利用子矩阵的第一行的元素进行编码,因此需要存储子矩阵第一行中所有的元素,在硬件实现时耗费资源较多;
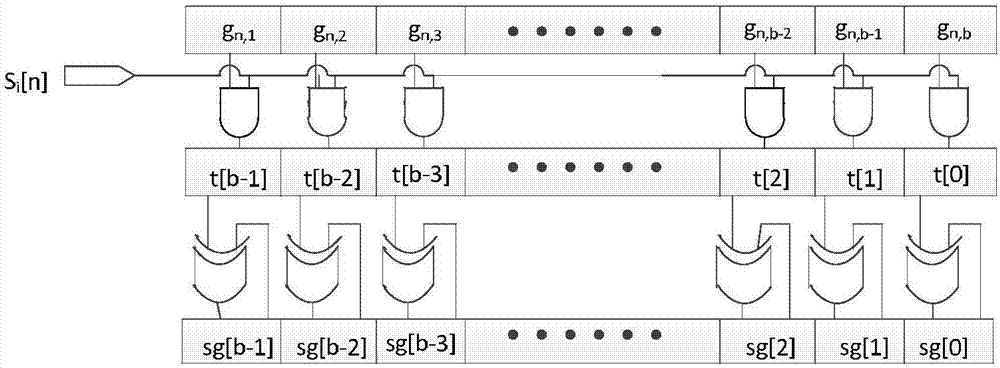
(二)传统编码器在实现信息位与生成矩阵的乘积时,如图1所示,是通过将1比特信息位与生成矩阵g中对应的一行相乘得到乘积结果,再通过累加所有行与对应信息位的乘积结果得到信息位与矩阵的的乘积结果,而硬件实现时分别通过按位相与和按位异或得到乘积和累加结果,当校验位较长时这一过程将消耗大量与门和异或门,从而增大了芯片的面积。
技术实现要素:
为克服现有技术中的缺点与不足,本发明的一个目的在于提供一种基于生成矩阵的qc_ldpc码编码方法。该方法通过对输入信息序列进行转换之后利用生成矩阵的准循环特性进行编码,减少了硬件资源的消耗,使芯片面积得以减小,且可以实现基于此编码方法的码率兼容编码器。本发明的另一个目的在于提供一种可减少存储资源消耗、减少计算资源消耗、实现码率兼容的基于生成矩阵的qc_ldpc码编码器。
为了达到上述目的,本发明通过下述技术方案予以实现:一种基于生成矩阵的qc_ldpc码编码方法,其特征在于:包括如下步骤:
s1步,输入编码信息序列s,将编码信息序列s分成t-c段长度为b比特的信息位si(i=1,2,3,…,t-c),其中,t-c=k/b,k为编码信息序列s的长度;
s2步,从生成矩阵g中获取t-c行c列b阶子矩阵gi,j(j=1,2,3,…,c);设定初始中间校验位pi-1,j为0;
s3步,找出当前信息位si对应的各个子矩阵gi,j;利用各个子矩阵gi,j第一行所有非零元素“1”的地址分别对当前信息位si进行循环移位操作,以分别获得中间乘积结果;将所有中间乘积结果累加得到当前信息位si与各个子矩阵gi,j之间的向量矩阵乘积结果sgi,j;
s4步,将当前向量矩阵乘积结果sgi,j与前一中间校验位pi-1,j按位异或运算得到当前信息位si对应的中间校验位pi,j;
s5步,跳至s3步计算下一信息位si对应的中间校验位pi,j,直至信息位st-c对应的中间校验位pi,j计算完成;得到校验位p:
p={pi=t-c,j=1,pi=t-c,j=2,…,pi=t-c,j=c};
编码信息序列s编码完成。
优选地,所述s1步中,将编码信息序列s分成t-c段长度为b比特的信息位si(i=1,2,3,…,t-c),是指:将编码信息序列s进行串并转换或者进行串并转换和补零操作来分成t-c段长度为b比特的信息位si(i=1,2,3,…,t-c)。
优选地,所述s2步中,从生成矩阵g中获取t-c行c列b阶子矩阵gi,j,是指:
从生成矩阵g中获取对应矩阵q,对应矩阵q包括各个子矩阵gi,j:
g=[iq]
其中i为k阶单位矩阵。
优选地,所述s3步中,找出当前信息位si对应的各个子矩阵gi,j;利用各个子矩阵gi,j第一行所有非零元素“1”的地址分别对当前信息位si进行循环移位操作,以分别获得中间乘积结果;将所有中间乘积结果累加得到当前信息位si与各个子矩阵gi,j之间的向量矩阵乘积结果sgi,j,是指包括以下步骤:
s31步,通过当前信息位si确定i,找出i对应的子矩阵gi,j;i对应的子矩阵gi,j包括gi,1gi,2gi,3…gi,c;
s32步,获取当前子矩阵gi,j第一行所有非零元素“1”的数量n和地址;
s33步,针对当前子矩阵gi,j,根据当前非零元素“1”对应的地址将当前信息位si循环移动n位,其中,n为当前非零元素“1”的地址;得到当前非零元素“1”对应的中间乘积结果;
s34步,跳至s33步以进行下一个非零元素“1”对应的中间乘积结果计算,直至当前子矩阵gi,j第一行所有非零元素“1”对应的中间乘积结果均计算完成;
s35步,将当前子矩阵gi,j对应的所有中间乘积结果累加得到当前信息位si与当前子矩阵gi,j之间的向量矩阵乘积结果sgi,j;
当前信息位si与各个子矩阵gi,j之间的向量矩阵乘积结果sgi,j计算,采用并行计算或串行计算或并行与串行结合计算。
优选地,所述s5步之后还包括s6步:校验位p通过串并转换,并进行输出。
一种基于生成矩阵的qc_ldpc码编码器,其特征在于:包括:
输入串并转换模块,用于将输入信息序列s分成t-c段长度为b比特的信息位si(i=1,2,3,…,t-c),其中,t-c=k/b,k为编码信息序列s的长度;
存储模块,用于存储生成矩阵g的所有子矩阵中第一行所有非零元素“1”的地址;
编码模块,用于根据子矩阵中第一行所有非零元素“1”的地址对信息位si进行循环移位操作以计算出向量矩阵乘积结果,从而获取校验位;
以及输出串并转换模块,用于将信息序列和编码模块得出的校验位通过串并转换,输出码字。
优选地,所述输入串并转换模块中,用于将输入信息序列s分成t-c段长度为b比特的信息位si(i=1,2,3,…,t-c),是指:用于将编码信息序列s进行串并转换或者进行串并转换和补零操作来分成t-c段长度为b比特的信息位si(i=1,2,3,…,t-c)。
优选地,所述编码模块中,用于根据子矩阵中第一行所有非零元素“1”的地址对信息位si进行循环移位操作以计算出向量矩阵乘积结果,从而获取校验位,是指:包括如下步骤:
y1步,从输入串并转换模块中获取信息位si(i=1,2,3,…,t-c);
y2步,从存储模块中获取生成矩阵g中对应的t-c行c列b阶子矩阵gi,j(j=1,2,3,…,c);设定初始中间校验位pi-1,j为0;
y3步,找出当前信息位si对应的各个子矩阵gi,j;利用各个子矩阵gi,j第一行所有非零元素“1”的地址分别对当前信息位si进行循环移位操作,以分别获得中间乘积结果;分别将所有中间乘积结果累加得到当前信息位si与各个子矩阵gi,j之间的向量矩阵乘积结果sgi,j;
y4步,将当前向量矩阵乘积结果sgi,j与前一中间校验位pi-1,j按位异或运算得到当前信息位si对应的中间校验位pi,j;
y5步,跳至y3步计算下一信息位si对应的中间校验位pi,j,直至信息位st-c对应的中间校验位pi,j计算完成;得到校验位p:
p={pi=t-c,j=1,pi=t-c,j=2,…,pi=t-c,j=c}。
与现有技术相比,本发明具有如下优点与有益效果:
1、本发明编码方法减少了存储资源的消耗,利用生成矩阵子矩阵中第一行的非零元素“1”的地址进行编码,因此只需要存储生成矩阵子矩阵中第一行非零元素的地址,由于ldpc码的稀疏特性,非零元素很少;而传统编码器利用生成矩阵中子矩阵的第一行的元素进行编码,因此当校验位长度较长时,本发明编码方法相对于传统编码器可以节省大量存储资源;
2.本发明方法减少了计算资源的消耗,在实现向量与矩阵的乘积时,充分利用了生成矩阵的准循环特性,简化了向量矩阵乘积过程,只利用生成矩阵中的非零元素进行编码;而传统编码器实现信息位与生成矩阵的乘积时利用生成矩阵中所有的元素进行编码,资源消耗较大,尤其是对于校验位较长的ldpc码,本发明编码方法相对于传统编码方法可以节省大量计算资源;
3.本发明编码方法实现了码率兼容,可以适应多种码率,且其中各码率的生成矩阵对应的子矩阵大小可以不一致;
4、本发明编码器减少了存储资源的消耗,减少了计算资源的消耗,实现了码率兼容。
附图说明
图1是传统编码器编码过程示意图;
图2是本发明编码方法的流程图;
图3是本发明编码方法编码过程示意图之一;
图4是本发明编码方法编码过程示意图之二;
图5是本发明编码器的架构图。
具体实施方式
下面结合附图与具体实施方式对本发明作进一步详细的描述。
实施例
本实施例一种基于生成矩阵的qc_ldpc码编码方法,其流程如图2所示;包括如下步骤:
s1步,输入编码信息序列s,将编码信息序列s分成t-c段长度为b比特的信息位si(i=1,2,3,…,t-c),其中,t-c=k/b,k为编码信息序列s的长度;
具体地说,是指:将编码信息序列s进行串并转换或者进行串并转换和补零操作来分成t-c段长度为b比特的信息位si(i=1,2,3,…,t-c);
s2步,从生成矩阵g中获取t-c行c列b阶子矩阵gi,j(j=1,2,3,…,c);设定初始中间校验位pi-1,j为0;
具体地说,是指:
从生成矩阵g中获取对应矩阵q,对应矩阵q包括各个子矩阵gi,j:
g=[iq]
其中i为k阶单位矩阵;
s3步,找出当前信息位si对应的各个子矩阵gi,j;利用各个子矩阵gi,j第一行所有非零元素“1”的地址分别对当前信息位si进行循环移位操作,以分别获得中间乘积结果;将所有中间乘积结果累加得到当前信息位si与各个子矩阵gi,j之间的向量矩阵乘积结果sgi,j;
具体地说,是指包括以下步骤:
s31步,通过当前信息位si确定i,找出i对应的子矩阵gi,j;i对应的子矩阵gi,j包括gi,1gi,2gi,3…gi,c;
s32步,获取当前子矩阵gi,j第一行所有非零元素“1”的数量n和地址;
s33步,针对当前子矩阵gi,j,根据当前非零元素“1”对应的地址将当前信息位si循环移动n位,其中,n为当前非零元素“1”的地址;得到当前非零元素“1”对应的中间乘积结果;
s34步,跳至s33步以进行下一个非零元素“1”对应的中间乘积结果计算,直至当前子矩阵gi,j第一行所有非零元素“1”对应的中间乘积结果均计算完成;
s35步,将当前子矩阵gi,j对应的所有中间乘积结果累加得到当前信息位si与当前子矩阵gi,j之间的向量矩阵乘积结果sgi,j;
当前信息位si与各个子矩阵gi,j之间的向量矩阵乘积结果sgi,j计算,采用并行计算或串行计算或并行与串行结合计算;
下面对s3步举例说明:
如图3所示,假设子矩阵大小为10*10,则信息位si的长度为10,子矩阵中未注明元素均为0。si与gi,j相乘,其中si与子矩阵左上角上侧斜列及左下角上侧斜列的乘积可以由gi,j的第一个非零元素“1”的地址“3”对si进行循环右移3位得到,即temp1[9:0];而si与子矩阵另外两斜列的乘积则由gi,j的第二个非零元素“1”的地址“6”对si进行循环右移6位得到,即temp2[9:0];中间乘积结果temp1与temp2的和sgi,j即为信息位si与gi,j的乘积。当各码率对应的生成矩阵子矩阵大小均相等时,中间乘积结果可以直接利用桶形移位器进行循环移位操作得到;如果各码率对应的生成矩阵子矩阵大小不一致,则需要利用类似桶形移位器的结构实现这一步骤,根据“1”的地址addr将b比特的信息位si赋值给2b比特的寄存器temp得到中间循环移位结果,即
temp[2b-1-addr∶b-addr]=si
temp其他位则赋值为0。如图3所示,为便于理解,将左侧子矩阵gi,j复制一个到右侧,将两个子矩阵合并则原子矩阵的4斜列合并成两列(图中虚线标示的两斜列),信息位与两斜列的乘积分别为temp3和temp4,将其高10比特与低10比特异或即可分别得到temp1和temp2。不同码率对应temp有效位与该码率生成矩阵子矩阵大小相关,如果子矩阵大小为bo*bo,则对应有效位为temp[2b-1:2b-2bo],通过将有效位高bo比特和低bo比特按位异或即可得到si与子矩阵相乘的一个中间乘积结果。利用该子矩阵第一行所有“1”的地址对si进行上述操作得到的所有中间乘积结果进行累加即可得到信息位si与该子矩阵的乘积结果;
s4步,将当前向量矩阵乘积结果sgi,j与前一中间校验位pi-1,j按位异或运算得到当前信息位si对应的中间校验位pi,j;
s5步,跳至s3步计算下一信息位si对应的中间校验位pi,j,直至信息位st-c对应的中间校验位pi,j计算完成;得到校验位p:
p={pi=t-c,j=1,pi=t-c,j=2,…,pi=t-c,j=c};
编码信息序列s编码完成。
s6步:校验位p通过串并转换,并进行输出。
本发明编码方法具有如下优点:
1、本发明编码方法减少了存储资源的消耗,利用生成矩阵子矩阵中第一行的非零元素“1”的地址进行编码,因此只需要存储生成矩阵子矩阵中第一行非零元素的地址,由于ldpc码的稀疏特性,非零元素很少;而传统编码器利用生成矩阵中子矩阵的第一行的元素进行编码,因此当校验位长度较长时,本发明编码方法相对于传统编码器可以节省大量存储资源;
2.本发明方法减少了计算资源的消耗,在实现向量与矩阵的乘积时,充分利用了生成矩阵的准循环特性,简化了向量矩阵乘积过程,只利用生成矩阵中的非零元素进行编码;而传统编码器实现信息位与生成矩阵的乘积时利用生成矩阵中所有的元素进行编码,因此当校验位较长时,本发明编码方法相对于传统编码方法可以节省大量计算资源;
3.本发明编码方法实现了码率兼容,可以适应多种码率,且其中各码率的生成矩阵对应的子矩阵大小可以不一致。
为实现上述编码方法,可采用基于生成矩阵的qc_ldpc码编码器,其结构如图5所示,包括:
输入串并转换模块,用于将输入信息序列s分成t-c段长度为b比特的信息位si(i=1,2,3,…,t-c),其中,t-c=k/b,k为编码信息序列s的长度;
存储模块,用于存储生成矩阵g的所有子矩阵中第一行所有非零元素“1”的地址;
编码模块,用于根据子矩阵中第一行所有非零元素“1”的地址对信息位si进行循环移位操作以计算出向量矩阵乘积结果,从而获取校验位;
以及输出串并转换模块,用于将信息序列和编码模块得出的校验位通过串并转换,输出码字。
所述输入串并转换模块中,用于将输入信息序列s分成t-c段长度为b比特的信息位si(i=1,2,3,…,t-c),是指:用于将编码信息序列s进行串并转换或者进行串并转换和补零操作来分成t-c段长度为b比特的信息位si(i=1,2,3,…,t-c)。
所述编码模块中,用于根据子矩阵中第一行所有非零元素“1”的地址对信息位si进行循环移位操作以计算出向量矩阵乘积结果,从而获取校验位,是指:包括如下步骤:
y1步,从输入串并转换模块中获取信息位si(i=1,2,3,…,t-c);
y2步,从存储模块中获取生成矩阵g中对应的t-c行c列b阶子矩阵gi,j(j=1,2,3,…,c);设定初始中间校验位pi-1,j为0;
y3步,找出当前信息位si对应的各个子矩阵gi,j;利用各个子矩阵gi,j第一行所有非零元素“1”的地址分别对当前信息位si进行循环移位操作,以分别获得中间乘积结果;将所有中间乘积结果累加得到当前信息位si与各个子矩阵gi,j之间的向量矩阵乘积结果sgi,j;
y4步,将当前向量矩阵乘积结果sgi,j与前一中间校验位pi-1,j按位异或运算得到当前信息位si对应的中间校验位pi,j;
y5步,跳至y3步计算下一信息位si对应的中间校验位pi,j,直至st-c对应的中间校验位pi,j计算完成;得到校验位p:
p={pi=t-c,j=1,pi=t-c,j=2,…,pi=t-c,j=c}。
以下用(16848,2016)和(17640,1120)两种码率的qc_ldpc码编码为例对本发明所提供基于生成矩阵的ldpc码编码方法和编码器进行详细的说明。两种码率对应生成矩阵的子矩阵大小分别为504*504和280*280。
编码器包括输入串并转换模块、存储模块、编码模块、输出串并转换模块。输入信息序列一路送至编码模块进行编码获取校验位,另一路送至输出串并转换模块将信息位输出;当信息序列完成输出,此时编码模块将获取的校验位送至输出串并转换模块继续输出。
基于生成矩阵的qc_ldpc码编码方法,包含以下步骤:
步骤1:信息位si由64位并行输入的信息位经过串并转换和补零操作以504位并行输出送至编码模块。其中(16848,2016)码率的信息序列经由串并转换以504位并行输出,无需补零操作;而(17640,1120)码率的在信息序列经由串并转换得到的280位信息位之后低位补零224位后以504位并行输出;
步骤2:根据生成矩阵g的特点,本实施列利用四个编码单元并行编码,每个编码单元对应矩阵q中的一列子矩阵。编码时从存储模块获取四个子矩阵第一行中非零元素“1”的地址,根据“1”的地址addr将504比特的信息位si赋值给temp[2*504-1-addr:504-addr],并对temp剩余位赋零。对于(16848,2016)码率,temp[2*504-1:0]为有效位,其高504比特与低504比特异或即为信息位si与该子矩阵的一个中间乘积结果;对于(17640,1120)码率,temp[2*504-1:2*504-2*280]为有效位,其高280比特与低280比特异或即为信息位si与该子矩阵的一个中间乘积结果。将这一中间结果与前一个“1”的地址得到的中间结果异或得到一个新的中间乘积结果,当所有“1”对应的地址均完成上述操作时即可得到信息位si与该子矩阵的乘积结果;
步骤3:将信息位si与该子矩阵的乘积结果和前一次获取的校验位pi-1,j异或得到校验位pi,j;
步骤4:当一帧信息序列的最后一段信息位si=t-c与生成矩阵g一列中的最后一个子矩阵gi=t-c,j完成乘积操作时,对于(16848,2016)码率即可得到一段504比特的校验位pi=33,j,四个并行编码单元同时完成对一帧信息序列的编码,获得2016比特的校验位p={pi=33,j=1,pi=33,j=2,pi=33,j=3,pi=33,j=4};对于(17640,1120)码率即可得到一段280比特的校验位pi=59,j,四个并行编码单元同时完成对一帧信息序列的编码,获得1120比特的校验位p={pi=59,j=1,pi=59,j=2,pi=59,j=3,pi=59,j=4};
步骤5:当信息序列经由输出串并转换模块完成输出后,编码模块获取的校验位也送至输出串并转换模块继续输出,当校验位输出完成时即一帧信息序列完成编码和输出。
上述实施例为本发明较佳的实施方式,但本发明的实施方式并不受上述实施例的限制,其他的任何未背离本发明的精神实质与原理下所作的改变、修饰、替代、组合、简化,均应为等效的置换方式,都包含在本发明的保护范围之内。
- 还没有人留言评论。精彩留言会获得点赞!