一种基于模拟退火的分布式纠删码存储系统数据修复方法与流程
本发明属于分布式纠删码存储系统领域,具体涉及一种基于模拟退火的分布式纠删码存储系统数据修复方法。
背景技术:
分布式存储系统凭借较好的可扩展性和较低的成本得到了广泛的关注,这种系统由廉价的存储服务器通过网络互联组成,并采取了一些数据冗余技术以保证数据的可靠性。分布式存储系统中传统的数据冗余技术是副本策略,但是副本策略带来了存储开销大的问题,例如对于三副本策略来说,它会带来三倍的存储开销。纠删码策略是一种比较新型的数据冗余技术,它将原始数据分割成k个块,并对这些数据块进行编码操作以得到m个校验块,最后将数据块和校验块放置在不同的节点上。当系统中某个节点发生故障时,它从剩余存活的数据块和校验块中读取k个即可解码出丢失的块。纠删码策略具有存储开销小的优点,在很多分布式存储系统中得到了广泛的应用。
对于基于异或运算的纠删码来说,它将数据块和校验块分割成w个更小的元素,校验块中的每个元素都是由数据块的元素之间通过异或运算得到。这种纠删码的生成矩阵是一个0-1矩阵,编解码运算通过该矩阵进行调度完成,常见的基于异或运算的纠删码如crs码、liberation码等。纠删码冗余技术在进行数据修复时需要读取和传输存活的数据块和校验块以进行解码操作,这会带来较大的网络开销。单节点故障在所有的系统故障中占据了99.75%以上的比例,所以现有研究主要针对分布式纠删码存储系统中单节点故障进行数据修复的优化,降低网络带宽占用,加快修复速度。
对纠删码数据修复的数据读取和传输进行优化的工作可以分为两类:一是星型数据修复方法,二是树形数据修复方法。对于星型数据修复方法来说,它主要是通过算法改进数据修复时的解码规则,使其可以使用更少的数据量进行解码操作。xiang等人针对rdp码提出了一种数据修复优化算法rdor,xu等人针对x码提出了mdrr算法,其可以达到理论最少的数据读取总量。khan等人提出了一种基于枚举策略的修复算法,在所有可行的修复方案中查找所需要数据量最小的方案。zhu等人提出了多项式级的搜索修复算法,它利用了爬山算法进行矩阵搜索,大大加快了算法执行速度,使得算法可以在多项式时间内查找到修复所需数据总量较小的修复方案。然而,这些优化方法仍然存在各种问题,要么时间复杂度过高,要么无法将修复带宽占用降低到近似最小,而且缺乏集群网络异构特征的考虑。
对于树形数据修复方法来说,它主要是改进传统的纠删码数据修复的数据读取和传输过程,将其设计为树形的数据读取和传输过程,以此来加快数据修复过程。mitra等人设计了ppr(partial-parallel-repair,局部并行传输)技术,它将整个数据修复任务分解成多个子任务以组织出一棵完整的数据修复树。zhang等人提出了一种新的修复树技术,通过分解计算的方式构建修复树,大大加快数据修复速度。li等人提出了带宽感知的树形修复技术,其基本思想是基于节点之间的网络带宽构建修复树。zeng等人和zhang等人提出了拓扑感知的树形数据修复技术,其主要目的是尽可能多地在树形网络拓扑的底层节点之间进行数据传输而减少上层核心交换机的数据量。然而,这些优化方法无法有效地降低数据修复时的网络传输数据量。
技术实现要素:
本发明的目的在于提供一种基于模拟退火的分布式纠删码存储系统数据修复方法,以解决上述问题。
为实现上述目的,本发明采用以下技术方案:
一种基于模拟退火的分布式纠删码存储系统数据修复方法,包括以下步骤:
步骤1:构建一个分布式存储系统,它由多个节点组成,每个节点都是一台独立运行的计算机,它们通过网络互联;该分布式存储系统由两类节点组成,一类是存储节点,它负责存储数据,一类是监控节点,它负责监听分布式存储系统中的存储节点的状态,当存储节点发生故障时,监控节点会触发修复操作;待存入存储系统的数据文件f使用crs纠删码进行编码;
当监控节点在规定的时间内未能接收到某个存储节点发送的心跳信息,则认为该存储节点出现了故障;在对失效的存储节点进行修复时,监控节点将选择一个存储节点ln用来存储失效的数据,ln节点将负责整个的数据修复工作;
步骤2:ln节点获取集群中各个节点之间的网络传输速度bandwidthi,j,其中0≤i≤k+m-1,0≤j≤k+m-1;
步骤3:ln节点获取当前节点编号ln,失效节点编号fn,以及当前纠删码配置下的纠删码生成矩阵g;如果失效节点为校验节点,则直接读取全部的数据块并执行编码操作以得到相应的校验块;如果失效节点为数据节点,则执行矩阵调度算法,查找修复开销最小的数据修复方案;
步骤4:根据数据修复方案确定数据修复所需要的数据读请求;
步骤5:将修复操作对应的数据读请求发送到具体的存储节点;
步骤6:各个存储节点接受到数据读请求后,根据相应的数据读操作的偏移量,读取本地磁盘数据,并发送回修复节点;
步骤7:修复节点接受到全部的返回数据后,执行解码操作,将丢失的数据重构出来;
步骤8:修复节点完成编码块修复之后,将编码块修复情况发送给监控节点,如果修复成功,将修复节点上编码块相关的元数据信息发送给监控节点;如果修复失败,修复节点对失效编码块进行重新修复。
进一步的,步骤1中,存储节点的存储方法为:待存入存储系统的数据文件f使用crs纠删码进行编码,crs纠删码用k,m,w表示;数据文件f被分割为k个数据块,记做d0,d1,…,dk-1,每个数据块包含w个数据元素,数据块di(0≤i≤k-1)的w个元素记作di,0,di,1,…,di,w-1;接下来,调用crs纠删码编码方法,得到k+m个编码块,包含k个原始数据块和m个校验块,校验块记作c0,c1,…,cm-1,每个校验块包含w个元素,校验块cj(0≤j≤m-1)的w个元素记作cj,0,cj,1,…,cj,w-1。k+m个编码块组成了一个条带,编码块被分别存储在不同的存储节点上。
进一步的,步骤3中,根据纠删码生成矩阵g、故障节点编号fn、存储集群中各节点之间的网络带宽,执行调度算法,该算法将获取一个k-v集合,每组k-v表示从对应的节点k读取的元素编号集合v。
进一步的,在步骤4中,获取每个数据块和校验块的元数据信息,如块的位置、块的大小等。根据步骤三获取的k-v数值以及上述元数据信息,确定每个节点上块的数据读操作的偏移量,以此来确定数据修复时对应的数据读请求。
进一步的,在步骤3中,纠删码调度算法的具体执行步骤如下:
(1):初始化参数,令k=0.97,t=m=l=k*m2*w2;
(2):根据纠删码生成矩阵g的后m*w行得到m*w个译码方程,每个译码方程包含了一个校验元素与若干个数据元素,表明该校验元素由上述若干数据元素进行异或运算得到,即该校验元素与上述若干数据元素进行异或运算的结果为0;
(3):将所述m*w个译码方程分成w组,第i组中的每个译码方程均覆盖了待修复数据块中的第i个元素,0≤i≤w-1,每组负责修复1个失效的数据元素;
(4):从每个分组中随机地选取1个译码方程,组成包含w个译码方程的修复方案;
(5):修复方案有效则需要同时满足以下2个条件:1)修复方案中的译码方程覆盖了所有的w个丢失的数据元素,2)译码方程关于丢失元素是线性独立的;如果所述修复方案是有效的,则将该修复方案赋值给solution,solutionbest=solution,设置count=0,否则转上一步;
(6):计算solutionbest的修复代价;
(7):数据修复方案solution的修复代价与solutionbest的修复代价相等,cost=costbest;
(8):从solution包含的w个译码方程中随机地选取1个译码方程ei,获取其所在分组,从该分组中随机地选取一个译码方程ej(ej≠ei),用ej替换掉solution中的ei;
(9):如果新的修复方案是有效的,则将该修复方案赋值给solutionnew,否则跳转执行上一步;
(10):计算solutionnew的修复代价,记做costnew;
(11):根据模拟退火的思想判断是否接受新的修复方案;
(12):设置count=count+1,如果count<m*l并且t>0.001,跳转执行第八步;
(13):根据solutionbest,计算从每个编码块d0,d1,d2,…,dk-1,c0,c1,c2,…,cm-1读取的元素编号,这些编号即表示了从哪些节点读取哪些元素;
进一步的,计算solutionbest的修复代价的具体步骤如下:
6.1通过遍历的方式统计solutionbest从每个节点读取的元素数量,记做ni,0≤i≤k+m-1;
6.2根据ni*1/bandwidthi,ln计算从每个节点上下载数据所需要的代价;
6.3根据∑ni*1/bandwidthi,ln计算出solutionbest所需要的数据修复总代价,记做costbest。
进一步的,根据模拟退火的思想判断是否接受新的修复方案的具体步骤如下:
11.1计算solution和新解solutionnew的修复代价差值,记做δ=cost-costnew;
11.2如果δ>0,则接受新解,即solution=solutionnew,cost=costnew,并判断是否costbest>costnew,如果成立,则solutionbest=solutionnew,costbest=costnew;
11.3如果δ≤0,则产生(0,1)之间的一个随机数,将该随机数赋值给random_probability。如果,则接受新解solution,即solution=solutionnew,cost=costnew。
与现有技术相比,本发明有以下技术效果:
本发明综合考虑了纠删码数据修复时的网络带宽占用问题和分布式存储系统中的网络异构特性。该发明对传统的crs纠删码的解码过程进行改进,使得crs码可以使用较少的数据量进行解码,并保证从网络传输速度快的节点上读取更多的数据,从网络传输速度慢的节点上读取更少的数据,这可以降低纠删码数据修复时的网络带宽占用,加快数据修复速度。
本发明基于模拟退火设计了纠删码解码调度算法,该算法可以以一定概率收敛于全局最优解,这保证了该算法可以得到修复代价最小的修复方案,而且该算法的时间复杂度是多项式级,这保证了该算法的执行时间较短,计算不会成为整个数据修复过程的瓶颈。
附图说明
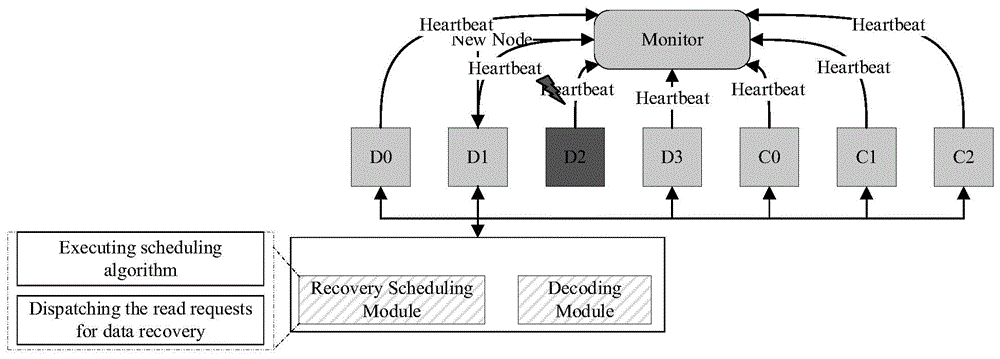
图1为本发明提供的分布式存储系统中纠删码数据修复过程示意图;
图2为本发明提供的crs纠删码的解码调度算法示意图。
具体实施方式
以下结合附图对本发明进一步说明:
一种基于模拟退火的分布式纠删码存储系统数据修复方法主要针对分布式存储系统中纠删码数据修复时的数据读取和传输过程,对该过程进行改进,使其可以读取更少的数据、传输更少的数据并使用较少的数据完成解码操作,降低数据修复的网络开销,并利用系统的网络带宽异构特性来加快数据修复的速度。
附图一为分布式存储系统中纠删码数据修复过程示意图,该分布式存储系统包含两种节点:监控节点负责监听各个存储节点的心跳信息,并以此判断存储节点是否发生故障;存储节点负责存储实际的文件数据,发送心跳信息给监控节点以表明自己可以提供正常的存储服务并发送块的元数据信息,这些元数据信息包括块的位置、块的大小等。
即将写入到分布式存储系统中的文件被分割成k份,记做d0,d1,…,dk-1,每个数据块又被分割成w个小的数据元素,第i(0≤i≤k-1)个数据块中的数据元素记做di,0,di,1,…,di,w-1。使用crs码对这些数据块执行编码操作,得到m个校验块,记做c0,c1,…,cm-1,每个校验块又被分割成w个小的校验元素,第i(0≤i≤m-1)个数据块中的数据元素记做ci,0,ci,1,…,ci,w-1。
当监控节点在规定的时间内没有接收到某个节点的心跳信息时,监控节点判断该节点发生故障,并选择出一个新的存储节点用于存储丢失的数据,这个新的存储节点被称为修复节点,它将负责数据修复操作。
修复节点执行数据修复时的具体步骤如下:
步骤一:修复节点获取故障节点的编号、当前节点的编号以及当前纠删码配置下的纠删码生成矩阵。
步骤二:判断故障节点是数据节点还是校验节点。如果故障节点是校验节点,则读取全部的数据块并执行编码操作,将丢失的校验数据重新编码出来。如果故障节点是数据节点,则通过纠删码调度算法进行数据修复操作。具体步骤如下所示:
2.1根据纠删码生成矩阵g、故障节点编号fn、存储集群中各节点之间的网络带宽,执行调度算法,该算法将获取一个k-v集合,每组k-v表示从对应的节点(k)读取的元素编号集合(v)。
2.2根据上述算法获取的k-v集合,确定修复操作对应的数据读请求。具体步骤如下:
2.2.1获取每个数据块和校验块的元数据信息,如块的位置、块的大小等。
2.2.2根据每组k-v数值(从每个节点读取的元素编号集合)以及上述元数据信息,确定每个节点上块的数据读操作的偏移量,以此来确定数据修复对应的读请求。
2.3将修复操作对应的数据读请求发送到具体的存储节点。
2.4各个存储节点接受到数据读请求后,根据相应的数据读操作的偏移量,读取本地磁盘数据,并发送回修复节点。
2.5修复节点接受到全部的返回数据后,执行解码操作,将丢失的数据重构出来。
2.6修复节点完成编码块修复之后,将编码块修复情况发送给监控节点,如果修复成功,将修复节点上编码块相关的元数据信息发送给监控节点;如果修复失败,修复节点对失效编码块进行重新修复。
附图二为基于异或运算的纠删码的解码调度算法示意图。解码调度算法主要负责计算出从每个存储节点读取的元素编号集合,以用于数据修复的数据读请求的构建。其具体步骤如下:
步骤一:修复节点获取集群中各个节点之间的网络传输速度bandwidthi,j(0≤i≤k+m-1,0≤j≤k+m-1)。
步骤二:初始化参数,令k=0.97,t=m=l=k*m2*w2。
步骤三:根据纠删码生成矩阵g的后m*w行得到m*w个译码方程,每个译码方程包含了一个校验元素与若干个数据元素,表明该校验元素由上述若干数据元素进行异或运算得到,即该校验元素与上述若干数据元素进行异或运算的结果为0。
步骤四:将所述m*w个译码方程分成w组,第i组中的每个译码方程均覆盖了待修复数据块中的第i个元素(0≤i≤w-1),每组负责修复1个失效的元素。具体步骤如下:
4.1遍历所有的m*w个译码方程,检查每个译码方程中w个位置(fn*w~fn*w+w-1)的0/1数值。
4.2判断各个译码方程应该加入哪个修复组中,如果某个译码方程中fn*w+x(0≤x≤w-1)的位置等于1,则将其加入到修复组x中,表示该译码方程可以修复第x个丢失的数据元素。
步骤五:从每个分组中随机地选取1个译码方程,组成包含w个译码方程的修复方案。
步骤六:修复方案有效则需要同时满足以下2个条件:1)修复方案中的译码方程覆盖了所有的w个丢失的数据元素,2)译码方程关于丢失元素是线性独立的。如果所述修复方案是有效的,则将该修复方案赋值给solution,solutionbest=solution,设置count=0,否则转步骤五。
步骤七:计算solutionbest的修复代价。具体步骤如下:
7.1通过遍历的方式统计solutionbest从每个节点读取的元素数量,记做ni(0≤i≤k+m-1)。
7.2根据ni*1/bandwidthi,ln计算从每个节点上下载数据所需要的代价。
7.3根据∑ni*1/bandwidthi,ln计算出solutionbest所需要的数据修复总代价,记做costbest。
步骤八:数据修复方案solution的修复代价与solutionbest的修复代价相等,cost=costbest。
步骤九:从solution包含的w个译码方程中随机地选取1个译码方程ei,获取其所在分组,从该分组中随机地选取一个译码方程ej(ej≠ei),用ej替换掉solution中的ei。
步骤十:如果新的修复方案是有效的,则将该修复方案赋值给solutionnew,否则跳转执行步骤九。
步骤十一:计算solutionnew的修复代价,记做costnew。具体步骤如步骤七所示。
步骤十二:根据模拟退火的思想判断是否接受新的修复方案。具体步骤如下:
12.1计算solution和新解solutionnew的修复代价差值,记做δ=cost-costnew。
12.2如果δ>0,则接受新解,即solution=solutionnew,cost=costnew,并判断是否costbest>costnew,如果成立,则solutionbest=solutionnew,costbest=costnew。
12.3如果δ≤0,则产生(0,1)之间的一个随机数,将该随机数赋值给random_probability。如果eδt>random_probability,则接受新解solution,即solution=solutionnew,cost=costnew。
步骤十三:设置count=count+1,如果count<m*l并且t>0.001,跳转执行步骤九。
步骤十四:根据solutionbest,计算从每个编码块d0,d1,d2,…,dk-1,c0,c1,c2,…,cm-1读取的元素编号,这些编号即表示了从哪些节点读取哪些元素。
以上所述为本发明的技术方案,本发明基于分布式存储系统中网络带宽的异构特性,结合基于异或运算的纠删码的解码理论,通过模拟退火算法,使用搜索的方法查找单数据节点失效时修复代价最小的修复方案,以此来降低修复带宽占用,加快数据修复速度。该方法可行性高,对于crs纠删码的数据节点失效有着较好的优化效果,可以有效加快数据修复的速度,降低数据修复给系统带来的不良影响。
上述具体实施方式仅是本发明的具体个案,本发明的专利保护范围包括但不限于上述具体实施方式,任何符合本发明的权利要求书的且任何所属技术领域的普通技术人员对其所做的适当变化或替换,皆应落入本发明的专利保护范围。
- 还没有人留言评论。精彩留言会获得点赞!