LDPC码的自适应最小和译码方法与流程
技术领域:
本发明属于电子通信领域,具体涉及一种ldpc码的自适应最小和译码方法。
背景技术:
:
传统置信传播(beliefpropagation,bp)译码算法虽然拥有优秀的译码性能,但其本省需要大量的乘法运算,造成较高的复杂度,不利于在硬件上实现。随着对数域bp(log-likelihoodratiobeliefpropagation,llr-bp)译码算法的提出,将原算法中乘法运算替换成了加法运算,并引入了双曲正切函数,虽然降低了运算量,但难以在工程中实现的问题依旧没有得到彻底解决。后来通过对llr-bp算法的校验节点更新运算进行了近似处理,得到了最小和(minimumsum,ms)译码算法,该算法极大地降低了运算复杂度,使其成为ldpc码在硬件上常规使用的译码方法。虽然ms算法降低了复杂度,并便于在硬件上实现,但其译码性能有较大的下降,因为tanh函数范围为(-1,1),arctanh函数范围为(-∞,∞),在llr-bp算法中,变量节点信息首先经过tanh函数运算,其结果的范围为(-1,1),然后是多次乘法运算,其结果的范围变为(0,1),最后由arctanh函数将其恢复到(-∞,∞)范围。经过此过程后,其结果小于
技术实现要素:
:
为解决上述问题,本发明提出一种ldpc码的自适应最小和译码方法,其技术方案如下:
一种ldpc码的自适应最小和译码方法,包括如下具体步骤:
1)设定迭代次数l=0,以及最大迭代次数imax;对接收到的长度为n的待译码序列yi,i=1,2,…,n,进行bpsk调制和高斯信道传输,结果记为
2)更新变量节点边信息,其中,第i变量节点vi传递给第j校验节点cj的边信息l(l)(vij)更新公式如下:
式中,n(i)/j为除第j校验节点cj外,所有与第i变量节点vi相邻的校验节点集合;
3)更新校验节点边信息,其中,第j校验节点cj传递给第i变量节点vi的边信息l(l)(cji)更新公式如下:
其中,
n(j)/i为第i除变量节点vi外,所有与第j校验节点cj相邻的变量节点集合;
4)计算变量节点后验概率l(l)(qi):
式中,n(i)为所有与第i变量节点vi相邻的校验节点集合;
5)译码判决:
通过硬判决生成判决码字
6)校验方程计算:
如果
优选地,所述最大迭代次数imax为50次。
本发明相比于现有技术具有如下有益效果:
本发明的ldpc码的自适应最小和译码方法,通过引入自适应乘性因子
通过测试可知,当对码长为155的ldpc码译码时,本发明译码方法从信噪比2db到4db一直优于ms译码算法,当信噪比处于3.5db时,本发明译码方法开始达到llr-bp译码算法的性能,并从3.5db到4db,本发明译码方法优越于llr-bp译码算法的译码效果,算法性能得到很大的提高,得到了更突出的译码效果。当对码长为576的ldpc码译码时,本发明译码方法一直优于ms译码算法,从2.3db到2.8db时,本发明译码方法性能优于llr-bp译码算法,且比llrbp算法性能提升了0.2db。
附图说明:
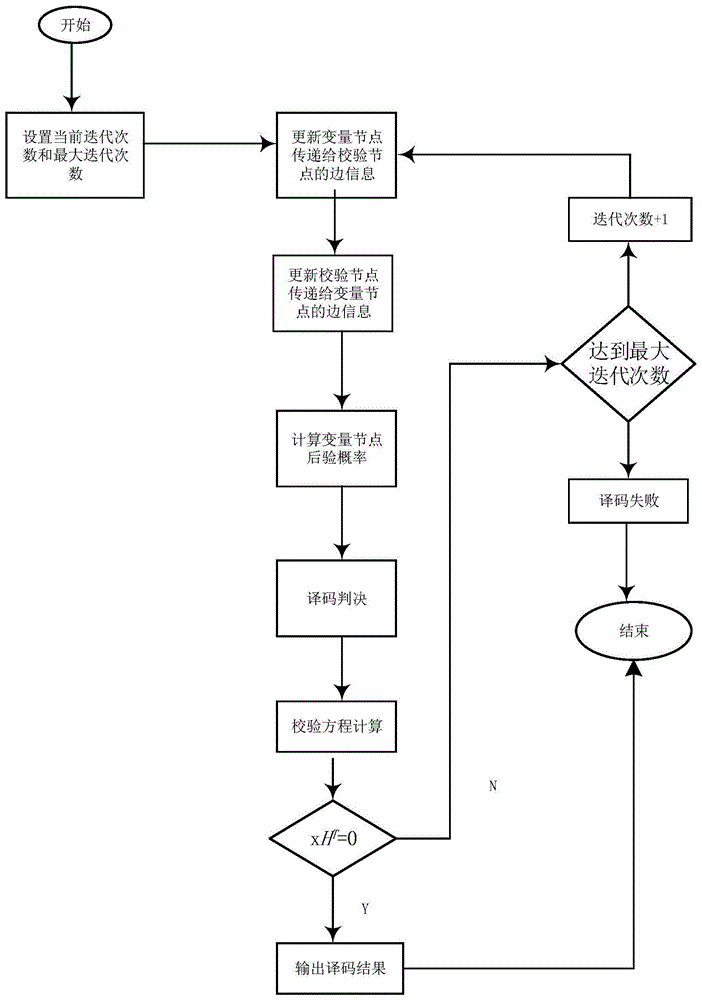
图1为实施例中译码方法流程图;
图2为本发明译码方法、传统置信传播译码算法以及传统最小和译码算法译码结果对比图之一;
图3为本发明译码方法、传统置信传播译码算法以及传统最小和译码算法译码结果对比图之二。
具体实施方式:
下面结合具体实施例及对应附图对本发明作进一步说明。
实施例一:
本实施例采用本发明的ldpc码的自适应最小和译码算法,如图1所示,该方法包括如下步骤:
1)设定迭代次数l=0,以及最大迭代次数imax=50;对接收到的长度为n的待译码序列yi,i=1,2,…,n,进行bpsk调制和高斯信道传输,结果记为
2)更新变量节点边信息,其中,第i变量节点vi传递给第j校验节点cj的边信息l(l)(vij)更新公式如下:
式中,n(i)/j为除第j校验节点cj外,所有与第i变量节点vi相邻的校验节点集合;
3)更新校验节点边信息,针对ms算法中存在校验节点信息过高估计的问题本发明在校验节点边信息的更新中引入了自适应乘性因子
式中,n(j)/i为第i除变量节点vi外,所有与第j校验节点cj相邻的变量节点集合;
4)计算变量节点后验概率l(l)(qi):
式中,n(i)为所有与第i变量节点vi相邻的校验节点集合;
5)译码判决:
通过硬判决生成判决码字
6)校验方程计算:
如果
应用实施例一:
本应用实施例分别运用本发明译码方法、传统置信传播译码算法(llr-bp译码算法)以及传统最小和译码算法(ms算法)在高斯白噪声信道环境下对码长为155和576的ldpc码进行译码。在本发明译码方法中设置的最大迭代次数为50次,误帧数为10000次,译码结果如图2和图3所示。根据图2和图3,当对码长为155,码率为0.4的ldpc码译码时,ms译码算法和llr-bp译码算法相差0.3db左右,本发明译码方法从信噪比2db到4db一直优于ms译码算法,当信噪比处于3.5db时,本发明译码方法开始达到llr-bp译码算法的性能,并从3.5db到4db,本发明译码方法优越于llr-bp译码算法的译码效果,算法性能得到很大的提高,得到了更突出的译码效果。当对码长为576,码率为0.5的ldpc码译码时,本发明译码方法一直优于ms译码算法,从2.3db到2.8db时,本发明译码方法性能优于llr-bp译码算法,且比llrbp算法性能提升了0.2db。
- 还没有人留言评论。精彩留言会获得点赞!