固定长度数据的压缩方法与流程
固定长度数据的压缩方法
1.本技术是申请日为2016年7月4日、申请号为201680046321.2(pct申请号pct/ca2016/050780)、名称为“固定长度数据的压缩方法”的发明专利申请的分案申请。
2.与申请相关的交叉引用
3.本技术要求2015年7月3日提交的美国专利申请号62/188,554的优先权,在此通过引用将其内容并入本文。
技术领域
4.本公开大体涉及实时多玩家游戏,并且更具体地涉及一种固定长度数据的压缩方法。
背景技术:
5.在线游戏的流行已经增长多年。越来越多的个人开始参与玩实时多玩家游戏。为了增强玩家对这些游戏的体验,逐渐引入或创新了新的改进和增强。
6.在一些情形中,这些改进涉及玩家根据计算机图形界面或者相对于新的待完成的挑战或任务而与游戏交互。
7.为了完全意识到对于计算机图形界面的改变,可能需要对于玩家不可见的关于游戏的其他改进。例如,更快的互联网连接对于玩家的游戏游玩可以是有益的。
8.因此,提供了一种改进用户对于实时多玩家游戏的体验的方法。
技术实现要素:
9.在本公开的一个特征方面中,提供了一种数据压缩的方法,包括将固定大小的二进制数据结构的集合组合成单一复合数据结构的集合,其中单一复合数据结构结构化由预定数目的固定大小二进制数据结构构成,并且随后将每个单一复合数据结构的位与其他单一复合数据结构中的对应的位对准。随后针对单一复合数据结构的每个位的位置计算位概率,并存储为位概率数据结构。创建基于位概率数据结构的重排序模型,并且基于重排序模型对每个单一复合数据结构的位重排序,以形成每个单一复合数据结构的中间缓冲器。
10.在本公开的另一特征方面中,遍历中间缓冲器。在另一特征方面中,以升序存储中间缓冲器并且随后遍历中间缓冲器的已排序列表。在另一实施例中,遍历中间缓冲器包括针对每个中间缓冲器计算差量(delta)位字串缓冲器,并且对每个差量位字串缓冲器编码。在另一特征方面中,计算差量位字串缓冲器包括检索相邻位对;从较大的位数值减去较小的位数值以计算相邻位对的差量;并且针对中间缓冲器的已排序列表中的每对相邻的中间缓冲器重复这些步骤。
11.在本公开的另一特征方面中,计算差量位字串缓冲器包括检索相邻位对;对每个相邻位对执行逐位异或(xor)计算;并且对中间缓冲器的已排序列表中的每个中间缓冲器对重复这些步骤。在另一特征方面中,遍历中间缓冲器的已排序列表包括从最高有效位至最低有效位遍历每个中间缓冲器;基于遍历产生固定深度二进制树结构的路径和分支。在
二进制树结构的每个叶片处,将最后分支点的位置编码为分支点数据;通过以已知顺序转储树来编码分支点数据;从二进制树结构移除最近编码的分支;跟随已编码数值返回至最后分支;并且针对每个分支重复这些步骤。
12.在本公开的第二特征方面中,提供了一种解压缩方法,包括对非差量第一位缓冲器解码;解码后续的差量位缓冲器;并且将已编码中间缓冲器转换为整型。
13.在本公开的另一特征方面中,提供了将后续差量位缓冲器添加至非差量第一缓冲器以产生已解码中间缓冲器;并且针对相邻的中间缓冲器对重复这些步骤。
14.在又一特征方面中,提供了将后续的差量位缓冲器逐位异或至非差量第一缓冲器,以产生已解码中间缓冲器;并且针对相邻的中间缓冲器对重复这些步骤。
附图说明
15.现在将参照附图仅以示例的方式描述本公开的实施例。
16.图1是32位整型定长数据结构的图表;
17.图2是双整型数据复合结构;
18.图3是由本公开的方法所定义的数据复合结构;
19.图4是关于本公开的方法的数据复合结构的对准的示意图;
20.图5是关于图4的数据结构的基于变化的重排序的示意图;
21.图6是已编码位串的示意图;
22.图7a和图7b是压缩的另一实施例的示意图;
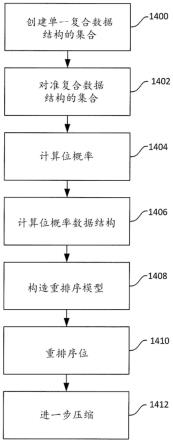
23.图8是关于多玩家游戏系统的系统示意图;
24.图9是图示了图8中所示系统组件的更多细节的示意图;
25.图10示意性地示出了在运行时刻游戏系统如何运作;
26.图11a和图11b是用于压缩的系统的实施例的示意图;
27.图12是用于压缩的系统的另一实施例的示意图;
28.图13是已编码位串的示意图;
29.图14是数据压缩的方法的流程图;
30.图15是另一压缩方法的流程图;
31.图16是遍历已排序列表的第一实施例的流程图;
32.图17是遍历已排序列表的第二实施例的流程图;
33.图18是遍历已排序列表的第三实施例的流程图;以及
34.图19是基于熵的压缩的实施例的流程图。
具体实施方式
35.本公开涉及一种用于固定长度数据的数据压缩的方法和设备。在一个实施例中,本公开公开了一种协调多个固定长度数据字段的方法。这些固定长度数据字段视作是具有固定数目位的数据结构。在一个实施例中,本公开确定固定长度数据字段中的每个位的概率并且产生重排序模型。随后使用重排序模型来重新对准每个固定长度数据字段中的位。随后作为数据压缩进程的一部分遍历每个固定长度数据字段。
36.在优选实施例中,本公开的方法用于实时多玩家游戏中。
37.参照图8,示出了用于多玩家游戏系统的设备或通用多玩家系统100的示意图。该图提供了系统组件的一些但是并非全部的概要图。与系统100的示意图集成的是表示并不形成系统的物理组件但是为了更好理解系统100而包括的数据(诸如虚拟世界数据103或客户端指令108)的方框。
38.在使用中,游戏开发者选择第三方游戏引擎90,用于研发游戏(也描述作为游戏编辑流)。游戏开发者使用第三方游戏引擎90以与系统100交互。第三方游戏引擎90通常包括或提供集成的第三方编辑器110和第三方游戏产品120。
39.当用户正在玩游戏时,(系统100内的)编辑器插件102遵照开发者的工作流程而与第三方编辑器110通信。尽管在图8中以一对一关系示出,单个编辑器插件可以与多于一个第三方编辑器110相关联或通信,由此系统100可以用于不同游戏的创建。当由第三方编辑器110指示时,编辑器插件102可以访问与游戏模拟相关的虚拟对象数据。编辑器插件102从虚拟对象数据产生虚拟世界数据103。虚拟世界数据可以视作产生对于用户的游戏环境所必需的数据。该虚拟世界数据103和虚拟对象数据优选地由游戏开发者在启用在第三方编辑器110和编辑器插件102之间通信之前创建或构造。尽管示出在系统100内,虚拟世界数据103可以存储在他处,诸如但不限于远程数据库。
40.如果虚拟世界数据103存储在远程数据库中,当需要时由系统100对其检索。虚拟世界数据103随后通过网络130传输,网络诸如广域网(wan)、互联网或局域网(lan)、或一些组合,其中虚拟世界数据存储在虚拟世界状态存储器104中。在存储在虚拟世界状态存储器104中之后,可以由模拟服务器101加载虚拟世界数据103以用于向正在玩多玩家游戏的用户显示。
41.在玩游戏期间,模拟服务器101提供离散的世界模拟、分析、压缩和流动。模拟服务器101也发送世界状态更新、或状态更新107至每个相连的游戏插件105(用户由此访问并玩游戏的装置)。游戏插件105可以存储在联网的计算机、膝上型电脑、平板电脑等内。
42.当模拟服务器101产生离散的世界状态时,其可以使用状态记录器106存储它们。在当前实施例中,状态记录器106是可以经由系统总线或其他高速网络附接至模拟服务器101的高性能存储系统。当被启用时,状态记录器106可以存储任意量的世界模拟历史,只要其配置具有足够的存储器。状态记录器106也可以从前一个状态产生可以加载至模拟服务器101中的虚拟世界数据103,以倒带或重播模拟以使得用户可以回顾之前的游戏播放。
43.在优选实施例中,游戏插件105和模拟服务器101通过网络130相互连接。(游戏插件内的)游戏接口与第三方游戏编辑器120接口用于提供允许用户在模拟服务器101上创建任意数目的自定义虚拟化功能的接口。
44.通过开发调用这些虚拟化函数的中一个虚拟化函数的游戏代码(优选地串行化至客户端或用户指令108中),可以发送这些指令或函数至服务器101以使得可以记录、存储和/或执行它们。
45.在一个实施例中,模拟服务器101默认允许所有指令。模拟服务器101也可以允许开发者提供服务器插件109以提供检查规则。照此,不是所有的关于由用户提交的游戏播放可以被系统100接受的指令。
46.在另一实施例中,模拟服务器101是可编辑脚本的,由此开发者可以定义和/或自定义许多服务器侧的函数。例如,当在使用时,可以使用客户端接口来调用这些服务器侧函
数。这也可以视作是典型的远程程序调用系统/软件模式。如果需要的话,可以记录这些函数调用并在稍后时刻“回放”,诸如在重播或另一类型的时移观看期间。
47.图9是图示了图8中所示系统组件的更多细节的示意图。更具体地,图9图示了如何使用编辑器创建虚拟世界。在将本公开的编辑器插件上传至本公开的系统之前,本公开的编辑器插件帮助将虚拟世界数据103转换为公共格式。
48.编辑器插件102包括对于一个第三方编辑器110专用的编辑器适配器层200,并且该编辑器插件102访问与第三方编辑器110相关联的所有虚拟世界数据103。第三方编辑器110自身在一个实施例中是提供了正被组装并实时更新的虚拟世界的虚拟表达的虚拟工具。如应该理解的,虚拟世界表示正在其中玩游戏的场景。为了帮助虚拟世界的研发,开发者定义了一个或多个虚拟对象描述202的集合,其包括图形数据诸如但不限于:几何结构和纹理,由第三方游戏产品120在运行时刻执行的任选的逻辑单元,以及各种物理属性数据诸如质量、速率和力。将一些虚拟对象描述符实例化为一个或多个实例化对象201以便于创建用于虚拟世界的运行时。在运行时,第三方游戏产品120从实例化对象201的列表产生虚拟世界。编辑器适配器层200自动地将虚拟对象运行时组件206附接至每个虚拟对象描述符202,以促进模拟并为开发者提供接口以影响模拟的状态。该接口提供读取并设置模拟专用特性的访问,诸如对象位置和旋转、以及由用户所提供自定义数据、和任选地物理特性诸如质量、阻尼、摩擦、碰撞掩蔽等的访问。编辑器适配器层200在编辑器中语法分析虚拟对象描述符202和实例化对象201两者并且以独立于第三方编辑器110和游戏引擎的公共格式存储相应数据。如上所述,编辑器110产生虚拟世界数据103,该虚拟世界数据103包含了基于其的公共实例化对象203和公共虚拟对象描述符204的两者。该数据通过网络130发送以被存储。编辑器通过连接至提供了对于下层数据读取和写入访问的虚拟世界存储器访问接口205而存储数据。
49.图10示意性地图示了在运行时刻游戏系统如何作用。状态更新从系统100流至第三方游戏产品120。模拟服务器101启动并从虚拟世界存储访问接口205加载初始模拟数据。虚拟世界存储器访问接口提供对于加载包含了如使用第三方编辑器110所定义的对于世界的初始条件的虚拟世界数据103、或加载来自之前状态的模拟数据的选项。一旦加载了世界模拟数据,模拟服务器101以离散时间步长、称作滴答而模拟世界交互。(模拟服务器101内的)第三方插件306请求对所模拟虚拟对象301的每个单个对象的模拟规则以便于完成一个滴答。更新世界状态并存储为指向两个系统的运行时刻虚拟对象305。两个系统的第一个是自定义状态分析器309。该分析器309使用从所有相连客户端(或用户)接收到的客户端状态数据312,其包含相关信息诸如相机位置、视域截锥、自定义客户端数据、和客户端输入状态(也即按压了哪些键,鼠标位置,触摸屏上触摸位置等)。自定义状态分析器309和对象状态分析器302也提供所有相关联元数据至压缩优化310诸如数据变换、语境、和熵信息。两个系统的第二个是对象状态分析器302,其对运行时刻虚拟对象305执行分析以确定用于压缩的最佳方法和语境。压缩器303提供下一级处理,处理来自自定义状态分析器309、对象状态分析器302的元数据和运行时刻虚拟对象305以产生世界状态更新107,其自身包含从任何客户端状态312产生的紧凑型自定义状态数据308,以及以自定义状态307表示的对象的已压缩选集的紧凑型虚拟对象304。世界状态更新107通过网络130发送并且由游戏插件105接收,其使用解压器311以将更新解压返回为运行时刻虚拟对象305和自定义状态307。压缩器
303也发送运行时刻虚拟对象305的原始或最小压缩版本至状态记录器106,其使用虚拟世界状态存储器104来存储每个世界更新作为历史。世界历史可应用于模拟服务器101以交互的(也即游戏)或非交互(也即记录的游戏或视频)的方式重播。
50.在多玩家游戏系统的执行中,为了改进或加速游戏播放或者改进或加速用户所看显示内容的更新,被发送的数据的一些可以经历压缩以减小由多玩家游戏所需的网络通信的量或大小,并且更具体地用于实时多玩家游戏。在一个实施例中,该压缩可以发生在模拟服务器内,但是可以在系统内他处执行。
51.在一个实施例中,本公开的压缩方法可以用于帮助减少在服务器之间发送的数据量以使得减少的数据允许在这些服务器之间更快的传输。压缩方法优选地允许如下所述固定大小二进制数据结构的压缩。
52.在典型的计算机软件数据结构中,固定大小或固定长度的二进制数据结构的范围从单个位至多个位的子结构的组合。例如,在一些软件中,应用可以使用32位整型结构来存储计数器。参照图1示出了32位整型结构10的示例。在其他实施例中,数据或整型结构可以更复杂并存储在更大的复合数据结构中,其可以包括浮点数值、字串或其他复合数值。
53.本公开涉及一种压缩固定长度二进制数据结构集合的方法。尽管仅参照32位整型结构描述,本公开的方法也可以用于其他(通常更大)大小的复合结构以便于改进传输速度和时间。
54.参照图14,示出了概述数据压缩方法的流程图。初始地,将固定大小二进制数据结构(诸如整型结构10)组合成单一复合数据结构的集合(1400)。这优选地由压缩器执行。
55.每个单一复合数据结构包括预定数目的固定大小二进制数据结构。例如,考虑简单的双整型数据结构12(如图2中所概述)。在图2中,数据结构12包含两个32位整型结构或两个数值10。为了理解的清楚,采用位的相应的整型结构10内的位置来标注他们。将数据结构12内整型结构组合并视作单一复合数据结构14(如图3中示意性示出的)。在本公开的方法中,每个单一复合数据结构14可以视作是单一位串。在正常游戏期间(在多玩家游戏中),规律地发送单一复合数据结构14的集合。单一复合数据结构的集合由多个双整型结构的数据结构构成。
56.当前的压缩方法将复合数据结构的集合处理作为字节的字串并且尝试将当前子字串与之前遇到的一个进行匹配以便于执行压缩。
57.在图3中,采用每个位在单一复合数据结构14内的绝对位置来标注他们。如所示,单一复合数据结构14表示64个连续位的字串,该字串是图2的双整型结构10的组合。
58.随后将每个单一复合结构中的位相互对准(1402)。如图4中示意性示出的,收集单一复合数据结构14的集合并随后相互对准。当第一单一复合数据结构或第一单一复合数据结构实例的第一位直接地与集合中所有其他单一复合数据结构14的第一位相关时,单一复合数据结构被视作逐位相互对准。
59.针对单一复合数据结构14内的每个位的位置计算位概率(或该位被设置的可能性)(1404)。在一个实施例中,通过以按列方式遍历已对准数据结构而计算概率。例如,如果在复合数据结构的集合内存在1000个数据结构,确定或计数所有1000个数据结构中的处于数据结构第一位置的1或0的数目。随后将总数目除以1000(或者集合中数据结构的数目)以确定概率。随后针对复合数据结构内的每个位置来重复此操作。在图4的示例中,重复64次。
60.这些位概率(p1、p2
……
pn,其中n表示数据结构14中位的位置)随后存储在位概率数据结构16中(1406)。在当前示例中,位概率数据结构包括64位概率数值。
61.位概率数据结构16随后用于构造重排序模型(1408)或中间缓冲器18(诸如图5中示意性示出的)。中间缓冲器也可以视作位串。
62.对于给定的概率pn,其具有与其方差的平方直接成正比的数值pn-pn^2。随后通过以递增顺序排序每个概率pn而构造重排序模型。这导致占据最左侧(或最高有效)位的位置的最小方差,而具有最大方差的位占据最右侧(或最低有效)位的位置。随后在中间缓冲器18内从最小(最左侧)至最大(最右侧)列出剩余的方差。该重排序模型或中间缓冲器表示如何重新映射来自单一复合数据结构的集合中的所有单一复合数据结构的位的一个实施例。
63.在已经重排序了位之后,压缩器使用映射(通过方差排序创建)以一对一的关系将来自每个单一复合数据结构14的位重排序成中间缓冲器18(1410)。换言之,计算方差并随后基于方差排序每个数据复合结构的位的位置。这些新的位置变为用于压缩的映射。采用这些合适的中间缓冲器,可以随后执行进一步数据压缩(1412)。可以以如下所概述的不同方式来执行数据的这种进一步压缩。
64.在进一步压缩的一个实施例中(如图15中示意性示出的),压缩器将每个中间缓冲器18处理作为(64位的)大整型数或为字串。如果中间缓冲器包含64个或更少的位,则压缩器可以使用原生64位(或更小)整型,如果不是,则压缩器可以将位的字串处理作为任意长度的整型数。压缩器随后优选地以降序排序得到的整型(1502)(如由中间缓冲器18的上述映射所确定)。能够唯一地识别每个对象实例对于进一步压缩是有益的。识别(id)信息存在于许多数据结构实施方式中,但是在id信息并非结构内字段的那些情形中,则列表中结构的顺序是重要的。本公开的压缩系统的用户提供该信息以使得压缩系统可以随后自动地包括原始索引,在执行位计算之前具有每个对象实例作为额外的字段。
65.压缩器随后遍历已排序的列表(1504),查找相邻的中间缓冲器对。
66.在遍历已排序的列表的一个示例中(诸如图16中示意性示出的),处理器从较大数值减去较小数值(1600),这产生了差量数值(delta value)。其继续该过程直至已经将位串的中间缓冲器的集合内的位转换为差量(保存为第一)(如图6中示意性示出的)。换言之,如果存在n个中间缓冲器(其中n表示被压缩的中间缓冲器的数目),则在由数值排序中间缓冲器之后,从中间缓冲器2减去中间缓冲器1以提供已编码的差量位串20用于差量位串1。这继续直至差量位串计算达到并且包括第n-1个位串。例如,如果初始地存在1000个复合数据结构,确定1000个中间缓冲器。在排序了中间缓冲器之后,如图以上所公开的,从第二中间缓冲器减去第一中间缓冲器以确定差量位串1。从第三中间缓冲器减去第二中间缓冲器以确定差量位串2。这继续直至从第1000个中间缓冲器减去第999个中间缓冲器。
67.压缩器随后可以通过添加指示每个差量对于存储所需求的位数目的小头来对每个至输出端的差量位串编码(1602)。从每个差量中的第一或最高有效设置位计数位,以使得不明确地编码所有前导零位并且可以如此推断。编码也将开始位缓冲器(已编码位串的位串1)编码为非差量,以使得可以由解压缩器从其开始重新计算所有其他位缓冲器。
68.在遍历已排序列表的第二方法中(如图17中示意性示出的),替代于减去相邻数值,压缩器计算相邻位串或中间缓冲器之间的逐位异或(1700)以确定或计算差量。在针对每个相邻位串对确定了差量之后,压缩器对每个差量进行编码(1702)以包括头,从而包括
需要存储的位数目并且如上所述地编码开始中间缓冲器。解压缩器随后可以使用已编码位串来重新计算已压缩的数据。
69.在以上所公开的每个实施例中,产生输出(视作已编码位串),其中将每个已编码位串编码为在前面加上了短头的一系列位串,诸如图6中示意性示出的。已编码的位串可以包括额外的元数据,诸如但不限于位头长度、模型、以及所使用的压缩方法。
70.在遍历已排序列表的另一实施例中(如图7a、图7b和图18中示意性示出的),从最高有效位逐位遍历每个中间缓冲器至最低有效位(1800)。随后使用这些位以产生二进制树结构中的路径和分支(1802)(诸如图7a中示意性示出的)。当位串被插入二进制树中时,它们的共同位数值形成共用分支。
71.当正遍历每个中间缓冲器时,压缩器产生(或基于中间缓冲器遍历而已经产生)固定深度的二进制树。在二进制树的每个叶片处,压缩器将最后分支点的位置编码为分支点数据。压缩器随后通过将树转储为已知顺序、诸如左侧至右侧或右侧至左侧而对分支点数据进行编码。每次编码器向下编码至叶片时,其从树移除已编码的大部分分支并且随后跟随在叶片处编码的数值返回至最后分支,并且重复该过程。每次其步进返回至最近的分支,其减小或最小化了必须对于新数据结构进行编码的额外数据。该遍历的示例示出在图7b中。在已经执行了压缩之后,创建输出,其将在发送之后可以被解压缩。
72.在另一实施例中,可以通过不同信道提供模型。例如,可以从大数据集合产生模型并将该模型存储在解压缩器中。压缩器随后使用该模型以压缩输入数据,但是无需在输出中对模型进行编码。这通常导致稍微不太理想的压缩,但是可以仍然产生较小的已压缩输出,因为模型不再必须采用输出编码。示意图示出在图13中。
73.以此方式,可以针对数据的采样集合计算一次位重排序(例如第一数个对象或位串),并且随后可以在后续编码中重新使用该映射以使得无需每次采用对象编码映射。
74.在压缩的另一实施例中,其可以与以上所概述的任意方法集成或者可以执行作为单独的压缩函数,压缩方法可以是基于熵的压缩方法。在一个实施例中,基于熵的压缩可以应用作为额外的计算机工作以针对以上任意压缩方法的输出来进一步减小被压缩数据的大小。在另一实施例中,基于熵的压缩可以与以上压缩方法之一集成以增强压缩性能。备选地,基于熵的压缩可以用作对字节流的通用压缩器。
75.在以上基于熵的实施例中,压缩方法针对位串操作。方法包括从源确定位排序;变换得到的位串;并且通过减小了变换输出的大小的多模型熵压缩来放置得到的位串。
76.参照图19,示出了概述了基于熵的压缩的实施例的流程图。首先,确定位排序(1900)。输入数据初始地解释作为位的顺序字串。存在用以解释这些字符位的两种方式。
77.第一种是开始于数据的起点并一次遍历一位直至结束。例如,接下来输入数据的五个(5)字节可以表示作为具有指示了字节边界的空间的位串。换言之,数据的5个字节可以视作5个固定数据字串。
78.10001011 10111010 11101110 11001010 10011001
79.解释数据的第二种方式是将数据视作固定大小结构的列表。使用来自以上示例的输入数据,输入数据可以视作8位固定大小的结构。可以对准位以通过查找作为列的位而表示共同的信息,其中行是8位固定数据结构的实例:
80.10001011
81.10111010
82.11101110
83.11001010
84.10011001
85.当每个数据结构的8位形成列时,列可以解释为包含了共同的信息以及转置用于产生按列解释的位。列(从左侧开始至右侧)变为:
86.11111
87.00110
88.01100
89.01001
90.00100
91.11110
92.10001
93.位流的列对准解释允许压缩相互相关的位的选项。如以上可见,存在实例1比0更多的两列。该关系在位解释的第一方法中并不明显。使用第二方法执行位解释允许使用不同统计模型来编码不同列。
94.为了确定可以优选位解释的哪个方法,可以观测或观察预测的压缩率。采用结构化数据,更可能的是存在几乎很少或从不改变状态的列。在那些情形中,可以不同地编码输入数据—因为可以不需要用于所有数值为1的行的熵编码器。替代地,仅编码列数目和数值。
95.在已经解释了输入数据之后,变换位串以便于将位串转换为符号(1902)。符号可以表示指示位串长度的数目。考虑了变换位的不同方法。
96.在位串变换的一个方法中(其可以视作是位状态长度实施例)将处于单一状态(0或1)的一连串位视作完整的字串。该完整字串可以表示作为数字。例如,行中的一系列1(诸如11111)可以表示为5。在每次存在位改变状态时定义新字串。000111视作2个字串,每个长度为3。考虑一系列输入位,诸如100111010111110010000001110101101001010101101111110001101010111
97.这可以转换或变换为一系列符号:
98.12311152163111211211111121632111113
99.因此,变换产生了一系列数字{1,2,3,1,1,1,5,2,1,6,3,1,1,1,2,1,1,2,1,1,1,1,1,2,1,6,3,2,1,1,1,1,1,3},其可以进一步处理和压缩。
100.在另一个位串变换的实施例中(其可以视作零终结位串的实施例)可以解释位串并转换成一系列长度。该变换的变量寻找1的字串并将第一个0位视作终止。因此,当考虑一系列位诸如11001110时,其可以分解为{110,0,1110}。长度可以计数为{3,1,4}。在输入位串全是1或者并不以0终结的事件中,最后的结尾0视作是暗示的。为了减小或防止数据讹误,任何最终已编码输出应该优选地包括所编码位的数目以使得解码器不在其输出中产生默示的结尾0。
101.另一告诫是诸如0000000000
…
000的输入位编码为{1,1,1,
…
1}的较长系列,而诸如1111111111
…
1的输入编码为单一数值。通常这不是问题,因为这些情形容易检测并且可
以使用备选方法而编码。
102.在另一位串变换的实施例中(其可以视作是1终结的位串实施例)该变换完全类似0终结的位串实施例,只不过其寻找以1位终结的一连串0。因此字串11001110编码为{1,1,3,1,1,1}。0终结实施例引起的类似的问题存在于1终结实施例,而位状态相反。
103.在变换了位串之后,随后对它们编码(1904)。采用所创建的一系列数字,需要对它们高效地编码。考虑用于对已变换位串编码的数个方式。
104.在一个实施例中,其可以视作自然的实施例,使用标准算术编码器的自然应用。当该编码器可以编码小部分位时,如果数据集合包含大量1长度,编码器可以编码为单个位或更少(尽管有时更多)。该压缩的自然形式使用单个语境或概率模型,其可以视作“主语境”。
105.在另一编码位串的实施例中(其可以视作游程长度实施例)可以通过添加游程长度编码的概念而改进压缩的整体方法。当正使用逐位压缩器时,在算术编码器中特殊符号用于指示游程。考虑以下示例:{1,3,4,1,5,1,1,1,5,3,1,1,4,5,5,1,1,2,3,4,1,4,4,2,1,5,6,6,1,3,3,3,1,1,1,1,1}。
106.如可见,存在数个重复的序列。当游程长度定义为符号“r”时,接着是用于重复的数值“v”,接着是重复计数“n”(r{v,n}),r的这些参数每个使用相应的编码语境压缩,使得语境计数上升至3。每次编码器对“r”编码时,其切换至包含用于重复符号的模型的语境。在其编码了符号之后,其再次切换至包含重复计数的语境以编码计数,在该点处且切换回至主语境。
107.使用该方法,将以上数字转换为:
108.1,3,4,1,5,r{1,3},5,3,r{1,2},4,r{5,2},r{1,2},2,3,4,1,r{4,2},2,1,5,r{6,2},1,r{3,3},r{1,5}
109.如可见,游程长度频繁地出现。因此,如果考虑上述概率模型,上述数据的游程长度编码语境(每个包含熵模型)被计算作为(每个符号的位是标准的熵计算,其可以视作:-log2(计数/总数)):
110.[0111][0112]
原始的数据长度为94位,已编码的数据长度少于85位。
[0113]
注意在一些情形中,诸如r{1,2},使用游程长度可能没有意义。在该示例中可以看到两个1编码为少于4.52位,而r{1,2}编码为超过4.58位。这通过计算r{v,n}语句的总大小并且将其与使用主语境的对数值简单编码相比来减轻。
[0114]
可以视作是一个的游程的实施例的备选编码实施例将是仅重复1数值的游程长度编码。在该情形中,无需额外的“v”语境,并且每个“r”符号之后接着1的计数。这可以提供改进的压缩而也更快地编码/解码。以下示出应用游程1变换的简单示例。
[0115]
{2,3,1,1,1,3,5,7,2,1,1,2,7,4,1,1,1,1,3,4,4,4}{2,3,r{3},3,5,7,2,r{2},2,7,4,r{4,},3,4,4,4}
[0116]
在另一可以视作图形匹配实施例的编码的实施例中,更复杂的编码器可以以类似于lempel-ziv/lempel-ziv-markov类编码器(lz*,lzm*)的方式而使用图形匹配。替代于使用特殊代码“r”来指示游程长度,可以使用特殊代码“p”以指示图形。图形代码接着是偏移“o”,该“o”表示往回寻找多少个符号,接着是长度“l”,表示用于构造该图形(p{o,l})的后续符号的数目。
[0117]
考虑一下示例:
[0118][0119]
图形可以确定诸如以下所列出的示例
[0120]
{1,2,3,1,1,2,3,4,2,2,1,1,1,1,3,5,4,3,2,1}{1,2,3,1,p{4,3},4,2,2,p{7,2},p{1,2},3,5,4,p{9,2}
[0121]
从该数据,可以产生3个语境的模型:
[0122]
主语境
ꢀꢀ
符号计数每个的位数122.807355232.222392
322.807355422.807355513.807355p41.807355
[0123]“o”语境
ꢀꢀ
符号计数每个的位数110.60206410.60206710.60206910.60206
[0124]“l”语境
ꢀꢀ
符号计数每个的位数310.60206230.124939
[0125]
在该示例中,输入数据的43位压缩为少于38位的输出数据。
[0126]
可能会参照编码以上概述的所有方法组合成单个算法,然而在压缩期间可以需要更多的逻辑以便于选择待使用哪个技术或实施例。这可以产生整体改进的压缩。
[0127]
当接着用于编码或解码时,在每个语境中修改模型的规则时获得额外的效率。该技术是广泛已知的,并且产生改进的压缩性能以及可以视作是自适应编码和解码。
[0128]
在通过产生并计数符号来对数据编码之前创建模型。一旦对所有符号计数,可以由算术/范围编码器一次一个对它们进行编码。随着特定符号被编码,从可应用模型的计数移除该符号。
[0129]
解码器遵循相同的规则。其使用与编码器相同的模型,并且随着其解码特定符号,其使用与编码器相同的规则从可应用模型递减该符号的计数。
[0130]
也可以存储额外的元数据,诸如每个已编码差量的头位的数目。在一些情形中可以使用算术或范围编码器对重复的头(诸如位串头)进行编码以减少开销。如果使用算术或范围编码器,那些模型也可以包括在头中,可以是静态的,或者它们可以校正至之前共用的模型(诸如差量模型)。
[0131]
通常,在已经压缩了数据之后,将解压缩数据。现在描述用于与以上所公开压缩方法一起使用的解压缩的实施例。在根据输出流语法分析任意元数据之后(模型选择和额外的头),解压缩器随后反转由压缩器所执行的步骤。解压缩器优选地包括帮助对已编码位串进行解码的解码器。
[0132]
解压缩器首先对非差量第一位缓冲器(或来自图6的位字串缓冲器)解码,并且随后对后续的差量位缓冲器解码。随后将已编码的中间缓冲器转换为整型,并且解压缩器增加(如果通过减法压缩)或使用逐位异或(如果采用逐位异或而压缩)第二已编码位串(或已解码差量)至第一位串。其随后获得新近解码的中间缓冲器,合计为整型,并且以相同方式使用其来解码第三数值等等,直至已经解码或解压缩了所有整个数据结构。
[0133]
如果已经使用二进制树结构遍历了已排序列表,解码器或解压缩器将第一数值解码作为二进制树的最左侧或最右侧分支。随着元数据编码树的深度,解码器自动地知晓其
何时到达叶片。一旦其解码了分支,其解码叶片,叶片包含倒退树至下一个已编码分支顶部的距离。解码器将位的下一个集合解码作为下一个分支,直至其再次已经解码至树的深度,在此解码下一个叶片,并且重复该过程直至该解码器已经解码了整个树。数据可以随后视作已解压缩。
[0134]
图11a和图11b是其中可以执行压缩方法的另一环境的示意图。
[0135]
在图11a和图11b的系统1000中,开发者或用户提供自定义编程语言1101和状态配置信息或数据1102以开发或自定义至少一个服务器堆栈1110。服务器堆栈1110包括第三方引擎1111(诸如第三方物理模拟库)和第三方运行时模块1112。第三方运行时模块编译自定义编程数据1101。开发者1100也可以定义由第三方运行时模块1112所管理并修改的外部数据的集合1114。由开发者以状态配置数据1102的形式提供固有数据1113至服务器堆栈1110。
[0136]
提供固有数据1113和外部数据1114至状态复合模块1114,该状态复合模块1114与视图过滤器1123连接,视图过滤器转而提供客户端透视数据1126或者状态的视图1124。可以将客户端透视数据1126返回至开发者以帮助自定义编程数据1101。状态的视图1124连接至压缩器1130,该压缩器1130接着将数据经由网络1130发送至客户端装置1140。客户端装置1140包括解压缩器1127,客户端分析器/解释器1141,以及包括展示引擎1148的第三方引擎1111。客户端分析器/解释器1141和第三方引擎1111两者均返回数据或信息至服务器堆栈1110内的客户端透视数据模块1126。客户端装置1140也可以由形式为终端用户输入1150的终端用户访问。
[0137]
服务器可以要求插件库嵌入在所有相连的1140上运行的应用程序内。
[0138]
在一个实施例中,第三方引擎1111可以集成至解压缩器1127背后的系统中。解压缩器1127被设计为覆盖与2d和3d物理引擎库两者交互的所有特征方面。解压缩器1127进一步影响并且可以变异对象的选集,每个包含固有数据1113,其由位置信息以及诸如质量、静/动摩擦、角阻尼、形状、规模、约束、角和线加速度、角和线速率的物理特性等等构成。
[0139]
第三方运行时模块1112是可以进一步变异固有数据1113并且采用外部数据1114扩增的过程的第二集合。服务器堆栈1110通过顺序计算离散时间步长来执行模拟。
[0140]
参照图12,示出了与至少一个客户端装置1140通信的服务器堆栈1110的示意图。服务器堆栈1110通过网络1130与至少一个客户端装置1140通信。
[0141]
服务器堆栈1110包括模型状态复合/适配器1115,其自身包括固定函数容器1116和自定义运行时容器1119。服务器容器组件的集合存储在两个容器1116和1119内。这些服务器容器组件是数据的用户或开发者所定义的容器。这些数据容器可以包含数据游戏专用数据诸如玩家得分、玩家项目、游戏动作等以辅助玩游戏。固定函数容器1116包括存储固有数据1118的第一服务器容器组件1117,而自定义运行时容器1119包括自定义运行时服务器容器组件的剩余部分,视作两个服务器容器组件1120至n个服务器容器组件1121。自定义运行时容器1119内的服务器容器组件每个包括自定义数据。
[0142]
客户端装置1140包括客户端分析器/解释器1141,其包括固定函数容器1142,具有与服务器容器组件1117对应的服务器容器组件1143(包括固有数据1144)。客户端装置进一步包括自定义运行时容器1145,其包括服务器容器组件1146,与服务器堆栈1110中自定义运行时容器的服务器容器组件构成一对一对应关系。
[0143]
使用本公开方法的一个示例可以是快速浮点数据预处理。
[0144]
单精度浮点数据(ieee754)是使用32位存储3个数值的特殊类型数据结构:1位用于存储符号信息,8位用于存储指数(适用于2的底数),以及剩余的23位存储尾数。由浮点数值表示的数字则是《符号》1.《尾数》
×2指数
。当表示浮点数时,希望数据结构中具有尽可能少的位变化。
[0145]
第一步是减少或消除指数位的可变性。为此,确定被压缩的数值集合是否具有可以以一范围而散布的绝对值,例如数值{17,29,27.7,30.322},所有落在16和32之间并且存在于在24(16)的散差内。应该注意的是大多数数值并不能如此方便地构造。考虑集合{5.5,-1.3,4.1,-7.2}。该集合的绝对值散布在2的3个不同幂(21,22,和23)之间。由于此,浮点数据结构将在它们的指数和尾数中具有不同的数值。
[0146]
如果获得了高(或最大)绝对值和低(或最小)绝对值,整个范围可以在幂=极限(log2(最大值—最小值))的范围内。计算对于2
幂
的数值并且随后添加至集合中所有正数,并且从集合中所有负值减去。例如,当集合{5.5,-1.3,4.1,-7.2}跨越23=8的范围时,因此我们加上(或减去)8以产生新集合{13.5,-9.3,12.1,-15.2}。这些新浮点数均共用共同的指数。因为指数位具有零方差,压缩器将自动地仅对所需位编码一次。
[0147]
符号信息将要保留,因此对符号位不操作。可以取决于所需精度进一步调节尾数信息。尾数的位表示分数1/2n,其中n是尾数中位的位置,因此第一位表示1/2,下一位表示1/4等等。尾数类似定点整型,该整型表示能够在给定指数下归一化至数值范围的比率。因为尾数长度为23位,其精确至8百万分之1。通常需要远远较小的精度,诸如对于旋转,其中1000分之1通常足够。为了减小尾数至可应用的精度,遮蔽去掉合适数目的最低有效位。对于1000分之1精度,保留23位的10个最高有效位。遮蔽去掉的位设置为0,并且具有0方差,因此压缩器可以防止对它们编码。
[0148]
当截取去掉尾数的位时,要特别关注取整。截取的动作可能移除还算重要的详细信息。例如,当遮蔽以超过第10位时1.599和1.501将均改变数值至1.500。在遮蔽之前执行取整变得重要。如果选择两个ieee754尾数,也即1.0110b(1.3725),并且将它们截取至两位,需要回顾第三位(.001b),这是因为该第三位表示最终数值的最低有效位的恰好一半的数值。如果设置第三位,通过在遮蔽之前将其添加至目标而取整型值:因此1.0110b+.001b=1.100b(1.5)。随后对1.100b应用遮蔽以获得1.10b。存在尾数数学的限制,其中每个位表示分数(1/2n),其中n是位的位置。这使其对于开发者稍微更难以确定误差容限,这是因为开发者以十进制思考,但是尾数的遮蔽位去除产生1/2n的误差值(也即,为了增大n,每个位的位置的误差值是0.5、0.25、0.125、0.0625、0.03125、0.015625、0.0078125、0.00390625等)。这使得误差预测非直觉。
[0149]
备选的方法是重新归一化尾数。为了归一化尾数至给定数目的位b,尾数它乘以2b。例如,如果需要b=16(因此归一化尾数至16位),尾数乘以2
16
。通过将乘积除以2
23
而执行归一化(对于23位的尾数)。
[0150]
反转操作恢复尾数。数值乘以2
23
,随后除以2
16
。更快的方案是可应用的,但是并非总是产生确切相同的结果,因为其并未执行任何取整。该方案可以视作将数值乘以2
(n-m)。然而,这将与左移或右移(n-m)位起到的作用没有差别,这转而与上述遮蔽技术没有差别。
[0151]
随后将偏移量信息发送至解码侧或解压缩器以使其可以用于重构建所需的数据。
偏移可以作为浮点数发送,但是如果2的幂次偏移量限定于仅整型指数,其将更加紧凑。
[0152]
使用对4个四元数值中的3个数值、以及第四个符号位进行编码的公共最小3(common smallest-3)技术而编码的归一化四元数来发送面对数据(facing data)。四元数分量是在-1
…
1范围内的浮点数。使用以上技术的修改,替代于1而使用2的偏移,导致数值偏移至-3
…‑
2,2
…
3的范围。如上所述,虽然量化了尾数,但是少进位量化了1位(也即,对于1000分之1精度替代于10而使用11位),这是因为所有数值仅散布在2
…
4范围的一半之上。
[0153]
压缩可以是有益的另一示例为游戏数据流。用于许多游戏的游戏数据包括将世界状态从服务器传输至客户端。世界状态中大批数据是用于该世界中对象的身份识别(id)、位置和旋转信息。
[0154]
考虑三维(3d)射击类型游戏。玩家控制虚拟化身,其在包括平台、斜坡、走廊和开放区域的活动场所周围行走或奔跑。每个化身由id编号、笛卡尔坐标中的位置、以及编码为归一化四元数的面对数值而描述。位置和旋转一起是化身变换的一部分。
[0155]
玩家通过运行连接至共同服务器(或权威游戏客户端)的游戏客户端而参与游戏。服务器执行游戏模拟。游戏客户端从玩家接收输入并发送命令至服务器,其随后选择执行哪些命令,并且对游戏模拟应用有效输入。
[0156]
服务器具有模拟数据对其渲染的网络堆栈。在该特别的示例中,玩家输入导致虚拟世界中化身的运动,当它们在水平面周围移动时改变了每个的变换。服务器将世界状态编码为每秒数次网路数据包,并且将得到的数据包发送至所有客户端。编码数据包的过程包括扫描模拟中所有对象(化身和其他对象,诸如项目,或人工智能(ai)控制的实体),并且将每人的相应变换串行化至缓冲器中。该缓冲器写入一个或多个数据包中,并且随后使用网络协议诸如udp或tcp发送至相连的游戏客户端。
[0157]
可以对数据应用压缩以使其最小化了发送所需的数据包的数目。在优选的实施例中,本公开的压缩方法用于该压缩。在模拟步骤的结束处,服务器迭代遍及模拟中所有对象。其选择将要串行化的那些。对于每个化身,其将串行化id和变换信息。对于其他游戏对象,其可以串行化变换数据,或者其可以串行化一些其他相关联数据。例如,可以在水平面中存在并未具有改变的变换的项目对象—相连的游戏客户端已经知晓它们的位置。这些项目对象可以具有其他数据,其可以替代地串行化,诸如点数或虚拟货币,或者如果项目是可收藏的则或许是能见度数值。
[0158]
如果考虑具有变换的对象,压缩仅发生在构造了数据包之前。使用如上所述技术预处理每个化身的变换。基于游戏客户端精确地重新创建所需多少精度而选择量子化的水平。如果水平面是100
×
100米,并且需要位置精确度至1cm,位置部分可以量子化至第1/10000,其可以使用尾数精度的14位来表示。面对数值可以类似的量子化。量子化过程包括复制变换和id数据至发生量子化的新结构。当该过程完成时,创建了可以由如上所述压缩系统处理的量子化变换的列表。
[0159]
压缩的结果产生了编码至一个或多个数据包中作为连续位串的一系列大整型类型,每个与描述了它们的相应长度的元数据相关联。可以首先以额外的数据包有效载荷大小而编码重新映射数据,如果客户端尚未具有的话。随后通过网络发送数据包至相连的客户端,并且服务器在重复过程之前继续计算下一个模拟步骤。
[0160]
在之前的说明中,为了解释的目的,阐述数个细节以便于提供实施例的全面理解。
然而,对于本领域技术人员应该明显的是可以不需要这些具体细节。在其他情形中,可以以方框图形式示出广泛已知的结构以便于不模糊理解。例如,并未提供关于在此所述实施例的元件是否实施作为软件例行程序、硬件电路、固件、或其组合的具体细节。
[0161]
本公开的实施例或其组员可以提供作为或者表现作为存储在机器可读媒介(也称作计算机刻度媒介,处理器刻度媒介,或具有具体化在其中的计算机刻度程序代码的计算机可用媒介)中的计算机程序产品。机器可读媒介可以是任何合适的有形、非临时媒介,包括磁性、光学、或点血存储媒介,包括软盘、小型盘只读存储器(cd-rom)、存储器器件(易失性或非易失性)、或类似存储机制。机器可读媒介可以包含当被执行时使得处理器或控制器执行根据本公开实施例的方法中的步骤的指令、代码列表、配置信息或其他数据的各种集合。本领域技术人员将知晓,对于实施所述实施方式必需的其他指令和操作也可以存储在机器可读媒介上。存储在机器可读媒介上的指令可以由处理器、控制器或其他合适的处理装置执行,并且可以与用于执行所述任务的电路接口。
[0162]
上述实施例有意设计为仅是示例。可以由本领域技术人员对特别的实施例实现变形、修改和改变而并未脱离如单独由所附权利要求所限定的范围。
相关技术
网友询问留言
已有0条留言
- 还没有人留言评论。精彩留言会获得点赞!
1