对视频解码的方法与流程
本申请是向中国知识产权局提交的申请日为2011年7月7日的标题为“通过使用块合并对视频进行编码的方法和设备以及通过使用块合并对视频进行解码的方法和设备”的第201180043660.2号申请的分案申请。
与示例性实施例一致的设备和方法涉及通过使用用于预测编码的块合并对视频进行编码和解码。
背景技术:
为了对当前图像中的块进行编码,视频压缩技术通常使用利用邻近块之中的最相似块的预测信息的运动估计/补偿方法和以下压缩方法:所述压缩方法通过离散余弦变换(dct)对先前图像和当前图像之间的差分信号进行编码来去除冗余数据,从而减小视频数据的大小。
随着用于再现和存储高分辨率或高质量视频内容的硬件被开发和供应,对于用于对高分辨率或高质量视频内容进行有效地编码或解码的视频编解码器的需求有所增加。在现有技术的视频编解码器中,基于具有预定尺寸的宏块,根据有限的编码方法对视频进行编码。此外,现有技术的视频编解码器通过使用均具有相同尺寸的块对宏块执行变换和逆变换,来对视频数据进行编码和解码。
技术实现要素:
技术问题
提供了一种通过使用块合并对视频进行编码的方法和设备以及一种通过使用块合并对视频进行解码的方法和设备。
解决方案
根据示例性实施例的一方面,提供了一种通过使用数据单元合并来对视频进行编码的方法,所述方法包括:确定编码模式,其中,所述编码模式指示用于画面的编码的数据单元和对每个数据单元执行的包括预测编码的编码方法;根据数据单元,基于预测模式和的编码模式中的至少一个确定与至少一个邻近数据单元的合并的发生;根据数据单元,基于与所述至少一个邻近数据单元的合并的发生来确定预测模式信息、合并相关信息和预测相关信息,并确定数据单元的包括预测模式信息、合并相关信息和预测相关信息的编码信息。
附图说明
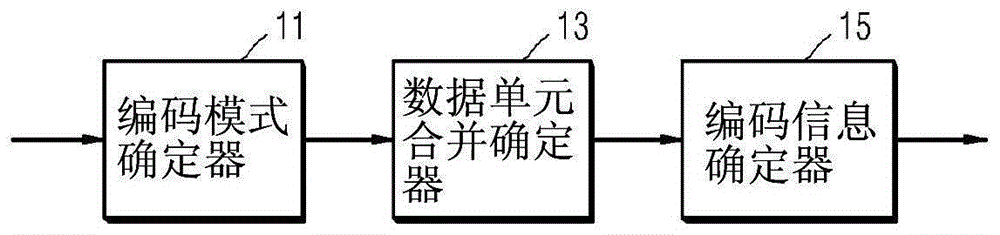
图1是根据示例性实施例的通过使用数据单元合并来对视频进行编码的设备的框图;
图2是根据示例性实施例的通过使用数据单元合并来对视频进行解码的设备的框图;
图3是示出根据现有技术的可与当前宏块合并的邻近宏块的示图;
图4和图5是用于分别解释根据现有技术和示例性实施例的在当前数据单元的邻近数据单元之中选择将与当前数据单元合并的数据单元的方法的示图;
图6和图7是用于解释根据示例性实施例的对预测模式信息、合并相关信息和预测相关信息进行编码和解码的顺序的框图;
图8和图9是用于分别解释根据现有技术和示例性实施例的在当前数据单元的扩展邻近数据单元之中选择将与当前数据单元合并的数据单元的方法的示图;
图10、图11和图12是用于解释根据各个示例性实施例的对预测模式信息、合并相关信息和预测相关信息进行编码和解码的顺序的框图;
图13是示出根据示例性实施例的不与当前分区合并的邻近数据单元的示图;
图14是示出根据示例性实施例的根据当前分区的形状和位置而改变的候选数据单元的示图;
图15是示出根据示例性实施例的可不与作为具有几何形状的分区的当前分区合并的邻近数据单元的示图;
图16是示出根据示例性实施例的使用被确定为与当前数据单元合并的邻近数据单元的示例的示图;
图17是示出根据示例性实施例的通过使用数据单元合并来对视频进行编码的方法的流程图;
图18是示出根据示例性实施例的通过使用数据单元合并来对视频进行解码的方法的流程图;
图19是根据示例性实施例的基于具有树结构的编码单元,通过使用数据单元合并来对视频进行编码的设备的框图;
图20是根据示例性实施例的基于具有树结构的编码单元,通过使用数据单元合并来对视频进行解码的设备的框图;
图21是用于解释根据示例性实施例的编码单元的概念的示图;
图22是根据示例性实施例的基于编码单元的图像编码单元的框图;
图23是根据示例性实施例的基于编码单元的图像解码器的框图;
图24是示出根据示例性实施例的根据深度和分区的编码单元的示图;
图25是用于解释根据示例性实施例的编码单元和变换单元之间的关系的示图;
图26是用于解释根据示例性实施例的与编码深度相应的编码单元的编码信息的示图;
图27是示出根据示例性实施例的根据深度的编码单元的示图;
图28至图30是用于解释根据示例性实施例的编码单元、预测单元和变换单元之间的关系的示图;
图31是用于根据表2的编码模式信息,解释编码单元、预测单元和变换单元之间的关系的示图;
图32是示出根据示例性实施例的基于具有树结构的编码单元,通过使用数据单元合并来对视频进行编码的方法的流程图;
图33是示出根据示例性实施例的基于具有树结构的编码单元,通过使用数据单元合并来对视频进行解码的方法的流程图。
实现本发明的最佳模式
根据示例性实施例的一方面,提供了一种通过使用数据单元合并对视频进行编码的方法,所述方法包括:确定编码模式,其中,所述编码模式指示用于画面的编码的数据单元和对每个数据单元执行的包括预测编码的编码方法;根据数据单元,基于预测模式和编码模式中的至少一个,确定与至少一个邻近数据单元的合并的发生;根据数据单元,基于与所述至少一个邻近数据单元的合并的发生,确定预测模式信息、合并相关信息和预测相关信息,并确定数据单元的编码信息,其中,所述编码信息包括预测模式信息、合并相关信息和预测相关信息。
确定编码信息的步骤可包括:确定指示数据单元的预测模式是否是跳过模式的跳过模式信息,和基于跳过模式信息确定是否将对合并信息进行编码,其中,合并信息指示数据单元和所述至少一个邻近数据单元是否彼此合并。
根据另一示例性实施例的一方面,提供了一种通过使用数据单元合并来对视频进行解码的方法,所述方法包括:对接收的比特流进行解析以提取已编码的视频数据和编码信息,并提取编码信息中的预测模式信息、合并相关信息和预测相关信息;基于预测模式信息和合并相关信息,根据数据单元基于预测模式和编码模式中的至少一个来分析与至少一个邻近数据单元的合并的发生,并通过使用所述至少一个邻近数据单元的预测相关信息对与所述至少一个邻近数据单元合并的数据单元执行帧间预测和运动补偿,以根据基于编码信息确定的数据单元对已编码的视频数据进行解码。
提取和读取的步骤可包括:提取并读取指示数据单元的预测模式是否是跳过模式的跳过模式信息;基于跳过模式信息确定是否提取合并信息,其中,合并信息指示数据单元和所述至少一个邻近数据单元是否彼此合并。
根据另一示例性实施例的一方面,提供了一种通过使用数据单元合并对视频进行编码的设备,所述设备包括:编码模式确定器,确定编码模式,其中,所述编码模式指示用于对画面进行编码的数据单元和用于每个数据单元的包括预测编码的编码方法;数据单元合并确定器,根据数据单元,基于预测模式和编码模式中的至少一个,确定与至少一个邻近数据单元的合并的发生;编码信息确定器,根据数据单元,基于与所述邻近数据单元的合并的发生,确定预测模式信息、合并相关信息和预测相关信息,并确定数据单元的编码信息,其中,所述编码信息包括预测模式信息、合并相关信息和预测相关信息。
根据另一示例性实施例的一方面,提供了一种通过使用数据单元合并对视频进行解码的设备,所述设备包括:解析器和提取器,对接收的比特流进行解析以提取已编码的视频数据和编码信息,并提取编码信息中的预测模式信息、合并相关信息和预测相关信息;数据单元合并器和解码器,基于预测模式信息和合并相关信息,根据数据单元基于预测模式和编码模式中的至少一个来分析与至少一个邻近数据单元的合并的发生,并通过使用所述至少一个邻近数据单元的预测相关信息对与所述邻近数据单元合并的数据单元执行帧间预测和运动补偿,以根据基于编码信息确定的数据单元对已编码的视频数据进行解码。
根据另一示例性实施例的一方面,提供了一种其上包含有用于执行对视频进行编码的方法的程序的计算机可读记录介质。
根据另一示例性实施例的一方面,提供了一种其上包含有用于执行对视频进行解码的方法的程序的计算机可读记录介质。
具体实施方式
在下文中,“图像”不仅可指静止图像,还可指运动图像(诸如视频)。此外,“数据单元”指组成视频的数据之中的预定范围中的一组数据。此外,在下文中,当诸如“……中的至少一个”的表达在一列元素之后时,所述表达修饰整列元素而不是修饰所述列中的单个元素。
在下面将参照图1至图18解释根据一个或多个示例性实施例的使用数据单元合并对视频进行的编码和解码。在下面将参照图19至图33解释根据一个或多个示例性实施例的基于具有树结构的编码单元,使用数据单元合并对视频进行的编码和解码。
在下面将参照图1至图18解释根据一个或多个示例性实施例的通过使用数据单元合并,用于对视频进行编码的设备、用于对视频进行解码的设备、对视频进行编码的方法和对视频进行解码的方法。
图1是根据示例性实施例的通过使用数据单元合并来对视频进行编码的设备10的框图。
设备10包括编码模式确定器11、数据单元合并确定器13和编码信息确定器15。为了便于解释,通过使用数据单元合并对视频进行编码的设备10被称为用于对视频进行编码的设备10。
设备10接收视频数据,通过对视频的画面执行画面之间的帧间预测、画面中的帧内预测、变换、量化和熵编码来对视频数据进行编码,并输出包括关于编码的视频数据的信息和编码模式的编码信息。
编码模式确定器11可确定用于画面的编码的数据单元,并可确定将对每个数据单元执行的编码方法。在视频压缩编码方法中,为了通过去除视频数据中的冗余部分来减少数据的大小,执行使用邻近数据的预测编码方法。编码模式确定器11可将规则的正方块或规则的正方块中的分区确定为用于预测编码的数据单元。
编码模式确定器11可为每个数据单元确定指示预测编码方法的预测模式(诸如帧间模式、帧内模式、跳过模式或直接模式)。此外,编码模式确定器11可根据数据单元的预测模式确定附加项(诸如对预测编码有用的预测方向或参考索引)。
编码模式确定器11可确定包括用于预测编码的预测模式和相关附加项的各种编码模式,并可相应地对视频数据进行编码。
数据单元合并确定器13不仅可确定由编码模式确定器11确定的数据单元之中的预测模式是帧间模式的数据单元是否与至少一个邻近数据单元合并,还可确定由编码模式确定器11确定的数据单元之中的预测模式是跳过模式或直接模式的数据单元是否与至少一个邻近数据单元合并。
如果当前数据单元与邻近数据单元合并,则当前数据单元可共享邻近数据单元的运动矢量信息。尽管当前数据单元的运动矢量差分信息被独立编码,但由于可通过遵守或参照与当前数据单元合并的邻近数据单元的辅助预测信息来获取当前数据单元的辅助预测信息,因此当前数据单元的辅助预测信息不被单独编码。
数据单元合并确定器13可在与当前数据单元邻近的区域中确定包括可与当前数据单元合并的数据单元的至少一个候选数据单元组。数据单元合并确定器13可在所述至少一个候选数据单元组中搜索将与当前数据单元合并的一个数据单元。在这种情况下,可在每个区域中确定包括可与当前数据单元合并的数据单元的一个候选单元组。
根据编码系统和解码系统之间预设的预定规则,可设置一种在与当前数据单元邻近的至少一个区域中确定候选数据单元组的方法以及一种在候选数据单元组中确定一个数据单元的方法。
此外,设备10可对关于在与当前数据单元邻近的所述至少一个区域中确定候选数据单元组的方法的信息以及关于在候选数据单元组中确定一个数据单元的方法的信息中的至少一个进行编码和输出。
例如,数据单元合并确定器13可在候选数据单元组中搜索与当前数据单元具有相同参考索引的数据单元,并可将所述数据单元选为将与当前数据单元合并的候选数据单元。
可选择地,数据单元合并确定器13可在候选数据单元组中搜索预测模式是帧间模式的数据单元,并可将所述数据单元选为将与当前数据单元合并的候选数据单元。可从按这种方式选择的候选数据单元中最终确定一个数据单元作为将与当前数据单元合并的候选数据单元。
数据单元合并确定器13可通过使用按照帧间模式的运动矢量预测的一般方法来确定将与当前数据单元合并的候选数据单元。详细地讲,根据按照帧间模式的运动矢量预测的一般方法,从与当前数据单元的所有边界接触的邻近数据单元之中确定将使用当前数据单元的运动矢量预测的多个候选矢量。也就是说,与当前数据单元的左边界接触的邻近数据单元之中的一个、与当前数据单元的上边界接触的邻近数据单元之中的一个、与当前数据单元的拐角接触的邻近数据单元之中的一个被选择,并且所述三个数据单元的运动矢量之一被确定为候选矢量。
根据按照帧间模式的运动矢量预测的一般方法,数据单元合并确定器13可在包括所有与当前数据单元的左边界接触的多个邻近数据单元的左候选数据单元组中,以及在包括所有与当前数据单元的上边界接触的多个邻近数据单元的上候选数据单元组中,搜索并确定将与当前数据单元合并的一个数据单元。
此外,除了当前数据单元的左候选数据单元组和上候选数据单元组之外,数据单元合并确定器13可在包括与当前数据单元的拐角接触的左上邻近数据单元、右上邻近数据单元和左下邻近数据单元的拐角候选数据单元组中搜索并确定将与当前数据单元合并的一个数据单元。
在这种情况下,在左候选数据单元组中确定一个候选数据单元的方法、在上候选数据单元组中确定一个候选数据单元的方法以及在拐角候选数据单元组中确定一个候选数据单元的方法可被预设。由于在相应的候选数据单元组之中确定一个候选数据单元的每种方法可被预设,因此所述方法可被隐含地用信号发送。
此外,从在左候选数据单元组中确定的一个候选数据单元、在上候选数据单元组中确定的一个候选数据单元、以及在拐角候选数据单元组中确定的一个数据单元(即,三个候选数据单元)之中最终确定将与当前数据单元合并的一个邻近数据单元的方法可被预设。也就是说,由于确定将与候选数据单元合并的邻近数据单元的每种方法可被预设,因此所述方法可被隐含地用信号发送。
例如,数据单元合并确定器13可从候选数据单元之中搜索预测模式是帧间模式的数据单元,并可将所述数据单元选为将与当前数据单元合并的候选数据单元。可选择地,数据单元合并确定器13可在候选数据单元之中搜索与当前数据单元具有相同参考索引的数据单元,并将所述数据单元选为将与当前数据单元合并的候选数据单元。
尽管为了对一个数据单元进行更准确的帧间预测的目的而划分的分区彼此邻近,但分区可不彼此合并。
由于与当前分区邻近的数据单元之中的可访问的数据单元可根据当前分区的形状和位置而改变,因此包括可被合并的邻近数据单元的合并候选组可被改变。因此,数据单元合并确定器13可基于当前分区的形状和位置搜索可被合并的邻近数据单元。
编码信息确定器15可根据数据单元确定预测模式信息、合并相关信息和预测相关信息。编码信息确定器15可根据数据单元合并确定器13的数据单元合并,在编码模式确定器11确定的编码信息中更新预测相关信息。编码信息确定器15可根据数据单元合并确定器13的数据单元合并对编码信息进行编码以包括合并相关信息。编码信息确定器15可输出由编码模式确定器11编码的视频数据和编码信息。
预测相关信息中的预测模式信息是指示当前数据单元的预测模式是帧间模式、帧内模式、跳过模式还是直接模式的信息。例如,预测模式信息可包括指示当前数据单元的预测模式是否是跳过模式的跳过模式信息和指示当前数据单元的预测模式是否是直接模式的直接模式信息。
合并相关信息包括用于执行数据单元合并或确定数据单元合并是否被执行的信息。例如,合并相关信息可包括指示当前数据单元是否将与邻近数据单元合并的合并信息和指示将被合并的数据单元的合并索引信息。编码信息确定器15可通过关于“邻近数据单元的预测模式和分区类型”的组合和关于“当前数据单元和邻近数据单元是否被合并”的上下文建模来对合并信息进行编码。
预测相关信息还可包括用于对数据单元进行预测编码的辅助预测信息和运动信息。例如,如上所述,预测相关信息可包括参照与预测编码相关的附加信息(包括指示将被参照的数据单元的参考索引等)的辅助预测信息以及运动矢量或运动矢量差分信息。
编码信息确定器15可基于数据单元的预测模式和预测单元被合并的可能性之间的紧密关系,确定合并相关信息是否根据预测模式信息而被设置。
在可对除了跳过模式以外的数据单元执行数据单元合并的第一示例性实施例中,编码信息确定器15可对指示当前数据单元的预测模式是否是跳过模式的跳过模式信息进行编码,并可基于跳过模式信息确定指示当前数据单元和邻近数据单元是否彼此合并的合并信息。
详细地讲,在第一示例性实施例中,如果当前数据单元的预测模式是跳过模式,则编码信息确定器15可将跳过模式信息设置为指示当前数据单元的预测模式是跳过模式,并可不对当前数据单元的合并信息进行编码。
如果当前数据单元的预测模式不是跳过模式,则编码信息确定器15可将跳过模式信息设置为指示当前数据单元的预测模式不是跳过模式,并可对当前数据单元的合并信息进行编码。
编码信息确定器15可基于合并信息对数据单元的运动矢量差分信息进行编码,并可确定所述数据单元的辅助预测信息是否被编码。
也就是说,如果当前数据单元与邻近数据单元合并,则编码信息确定器15可将当前数据单元的合并信息设置为指示当前数据单元与邻近数据单元合并,并可不对当前数据单元的辅助预测信息进行编码。另一方面,如果当前数据单元未与邻近数据单元合并,则编码信息确定器15可将当前数据单元的合并信息设置为指示当前数据单元未与邻近数据单元合并,并可对当前数据单元的辅助预测信息进行编码。
不管当前数据单元是否与邻近数据单元合并,编码信息确定器15都可对当前数据单元的运动矢量差分信息进行编码。
此外,在确定是否对除了跳过模式和直接模式以外的数据单元执行数据单元合并的第二示例性实施例中,编码信息确定器15可对用于指示是否对预测模式是直接模式的数据单元执行数据单元合并的合并相关信息进行编码。
详细地讲,在第二示例性实施例中,编码信息确定器15可将跳过模式信息设置为指示数据单元的预测模式不是跳过模式,并可对直接模式信息进行编码。此外,编码信息确定器15可基于直接模式信息确定合并信息是否被编码。也就是说,如果当前数据单元的预测模式是直接模式,则编码信息确定器15可将直接模式信息设置为指示当前数据单元的预测模式是直接模式,并可不对当前数据单元的合并信息进行编码。如果当前数据单元的预测模式不是直接模式,则编码信息确定器15可将直接模式信息设置为指示当前数据单元的预测模式不是直接模式,并可对当前数据单元的合并信息进行编码。
如果合并信息被编码,则基于合并信息确定当前数据单元的辅助预测信息是否被编码,如以上第一示例性实施例中所描述的对当前数据单元的运动矢量差分信息进行编码。
通过划分画面获得的数据单元可包括作为用于对画面进行编码的数据单元的“编码单元”、用于预测编码的“预测单元”和用于帧间预测的“分区(partition)”。数据单元合并确定器13可针对每个编码单元确定是否执行与邻近数据单元的合并,并且编码信息确定器15可为每个编码单元确定跳过模式信息和合并信息。此外,数据单元合并确定器13可针对每个预测单元确定是否执行与邻近数据单元的合并,并且编码信息确定器15可为每个预测单元确定跳过模式信息和合并信息。
如果跳过模式信息和合并信息两者均被使用,则由于在跳过模式和数据合并两者的情况下不对当前数据单元的唯一预测信息进行编码,因此设备10可将根据跳过模式的预测方法与根据数据合并的预测方法区分开。例如,可根据预设规则确定具有跳过模式的数据单元的参考索引和参考方向,并且与邻近数据单元合并的数据单元可遵守邻近数据单元的运动信息的参考索引和参考方向。由于用于确定具有跳过模式的数据单元的参考索引和参考方向的规则可被预设,因此所述规则可被隐含地用信号发送。
编码信息确定器15可对用于每个预测模式的跳过模式信息进行编码,并可对用于每个分区的合并相关信息进行编码。此外,编码信息确定器15可对用于每个数据单元的合并相关信息和跳过模式信息两者进行编码。可选择地,编码信息确定器15可将合并相关信息设置为仅针对具有预设的预定预测模式的数据单元被编码。
设备10可确定数据单元之间的数据单元合并,或者确定预测单元之间的数据单元合并。此外,设备10可单独对跳过模式信息和直接模式信息进行编码。因此,如果基于数据单元的跳过模式信息,所述数据单元的预测模式不是跳过模式,则编码信息确定器15可对指示数据单元的直接模式信息是否被编码的跳过/直接模式编码信息、指示数据单元之间的合并的发生是否被确定的编码单元合并确定信息、和指示预测单元之间的合并的发生是否被确定的预测单元合并确定信息中的至少一个进行编码。
图2是根据示例性实施例的通过使用数据单元合并来对视频进行解码的设备20的框图。
设备20包括解析器/提取器21和数据单元合并器/解码器23。为了便于解释,通过使用数据单元合并对视频进行解码的设备20被称为“用于对视频进行解码的设备20”。
设备20接收已编码的视频数据的比特流,提取包括关于编码方法的信息的编码信息和已编码的视频数据,并通过熵解码、反量化、逆变换和画面之间的帧间预测/补偿执行解码以恢复视频数据。
解析器/提取器21对接收的比特流进行解析以提取已编码的视频数据和编码信息,并提取编码信息中的预测模式信息、合并相关信息和预测相关信息。解析器/提取器21可将跳过模式信息、直接模式信息等提取为预测模式信息。解析器/提取器21可将包括参考方向和参考索引的辅助预测信息和运动矢量差分信息提取为预测相关信息。
解析器/提取器21可将合并信息、合并索引信息等提取为合并相关信息。解析器/提取器21可读取合并信息并可分析与当前数据单元合并的邻近数据单元的预测模式和分区类型,其中,所述合并信息通过关于“邻近数据单元的预测模式和分区类型”的组合和“当前数据单元和邻近数据单元是否彼此合并”的上下文建模而被编码。
首先,在确定是否对除了跳过模式以外的数据单元执行数据单元合并的第一示例性实施例中,解析器/提取器21可从接收的比特流提取并读取数据单元的跳过模式信息,并可基于跳过模式信息确定数据单元的合并信息是否被提取。也就是说,如果基于跳过模式信息读出当前数据单元的预测模式不是跳过模式,则解析器/提取器21可从接收的比特流提取当前数据单元的合并信息。
解析器/提取器21可基于合并信息提取数据单元的运动矢量差分信息,并可确定数据单元的帧间辅助预测信息是否被提取。也就是说,如果基于合并信息读出当前数据单元未与邻近数据单元合并,则解析器/提取器21可从接收的比特流提取运动矢量差分信息,并可提取当前数据单元的辅助预测信息。另一方面,如果基于合并信息读出当前数据单元与邻近数据单元合并,则解析器/提取器21可从接收的比特流提取运动矢量差分信息,并可不提取当前数据单元的辅助预测信息。
接下来,在确定是否对除了跳过模式和直接模式以外的数据单元执行数据单元合并的第二示例性实施例中,如果数据单元的预测模式不是跳过模式,则解析器/提取器21可提取数据单元的直接模式信息,并可基于直接模式信息确定合并信息是否被提取。
也就是说,如果根据直接模式信息读出当前数据单元的预测模式是直接模式,则解析器/提取器21可不从接收的比特流提取合并信息。另一方面,如果根据直接模式信息读出当前数据单元的预测模式不是直接模式,则解析器/提取器21可从接收的比特流提取合并信息。
解析器/提取器21可基于合并信息提取数据单元的运动矢量差分信息,并可如以上在第一实施例中所述的确定辅助预测信息是否被提取。
数据单元合并器/解码器23基于预测模式信息和合并相关信息,根据数据单元基于预测模式和编码模式中的至少一个分析是否执行与至少一个邻近数据单元的合并。数据单元合并器/解码器23可基于编码信息确定数据单元并根据确定的数据单元对已编码的视频数据进行解码以恢复画面。
例如,数据单元合并器/解码器23可通过使用邻近数据单元的预测相关信息对与邻近数据单元合并的数据单元执行帧间预测和运动补偿,以基于编码信息对视频数据进行解码。
解析器/提取器21可提取并读取用于每个编码单元的跳过模式信息和合并信息,数据单元合并器/解码器23可基于用于每个编码单元的合并信息确定与邻近数据单元的合并是否被执行。
此外,解析器/提取器21可提取并读取用于每个预测单元的跳过模式信息和合并信息,数据单元合并器/解码器23可基于用于每个预测单元的合并信息确定与邻近数据单元的合并是否被产生。
数据单元合并器/解码器23可基于解析器/提取器21提取的合并相关信息读取当前数据单元是否与邻近数据单元合并,并可在邻近数据单元中搜索将被合并的数据单元。
首先,数据单元合并器/解码器23可基于合并相关信息中的合并信息分析当前数据单元是否与邻近数据单元合并。如果读出当前数据单元与邻近数据单元合并,则数据单元合并器/解码器23可基于合并相关信息中的合并索引信息,在与当前数据单元邻近的区域中确定包括可与当前数据单元合并的数据单元的至少一个候选数据单元组。数据单元合并器/解码器23可在所述至少一个候选数据单元组中确定将与当前数据单元合并的一个数据单元。可针对与当前数据单元邻近的至少一个区域中的每一个确定用于当前数据单元的合并的候选数据单元组。
由于确定将与候选数据单元合并的邻近数据单元的每种方法可被预设,因此所述方法可被隐含地用信号发送。数据单元合并器/解码器23可基于根据编码/解码系统之间的预定规则预设的确定候选数据单元组的方法和在候选数据单元组中确定一个数据单元的方法中的至少一个,确定将与当前数据单元合并的一个数据单元。
解析器/提取器21可提取关于在与当前数据单元邻近的至少一个区域之中确定候选数据单元组的方法的信息和关于在候选数据单元组中确定一个数据单元的方法的信息中的至少一个。数据单元合并器/解码器23可基于关于确定提取的候选数据单元组的方法的信息和关于在候选数据单元组中确定一个数据单元的方法的信息中的至少一个,确定将与当前数据单元合并的一个数据单元。
例如,如果数据单元合并器/解码器23根据预设方法设置第一候选数据单元、第二候选数据单元或第三候选数据单元,则数据单元合并器/解码器23可在上层的邻近数据单元的合并候选组中搜索与当前数据单元具有相同参考索引的邻近数据单元,并可将所述邻近数据单元确定为将被合并的一个数据单元。
可选择地,如果数据单元合并器/解码器23根据预设方法确定第一候选数据单元、第二候选数据单元或第三候选数据单元,则数据单元合并器/解码器23可在上层的邻近数据单元的合并候选组中搜索预测模式是帧间模式的邻近数据单元,并可将所述邻近数据单元确定为将与当前数据单元合并的一个数据单元。
由于在相应的候选数据单元组之中确定一个候选数据单元的每种方法可被预设,因此所述方法可被隐含地用信号发送。
数据单元合并器/解码器23可通过使用按照帧间模式的运动矢量预测的一般方法来确定将与当前数据单元合并的候选数据单元。详细地讲,数据单元合并器/解码器23可基于合并相关信息中的合并索引信息,在包括所有的与当前数据单元的左边界接触的多个左邻近数据单元的左候选数据单元组和包括所有的与上边界接触的多个上邻近数据单元的上候选数据单元组中确定将与当前数据单元合并的一个数据单元。
此外,除了当前数据单元的左候选数据单元组和上候选数据单元组以外,数据单元合并器/解码器23可基于合并索引信息,在包括与当前数据单元的拐角接触的左上邻近数据单元、右上邻近数据单元和左下邻近数据单元的拐角候选数据单元组中确定将与当前数据单元合并的一个数据单元。
详细地讲,数据单元合并器/解码器23可读取合并索引信息,并可将作为左候选数据单元组中的一个的第一候选数据单元、作为上候选数据单元组中的一个的第二候选数据单元或作为拐角候选数据单元组中的一个的第三候选数据单元确定为将与当前数据单元合并的邻近数据单元。
此外,数据单元合并器/解码器23可在第一候选数据单元被确定的情况下在左邻近数据单元之中搜索并确定一个左邻近数据单元作为将与当前数据单元合并的一个数据单元,在第二候选数据单元被确定的情况下在上邻近数据单元之中搜索并确定一个上邻近数据单元作为将与当前数据单元合并的一个数据单元,并在第三候选数据单元被确定的情况下在与拐角接触的邻近数据单元中搜索并确定一个邻近数据单元作为将与当前数据单元合并的一个数据单元。
在这种情况下,在左邻近数据单元、上邻近数据单元和与拐角接触的邻近数据单元之中搜索并确定将与当前数据单元合并的一个数据单元的方法可被预设。例如,根据预设方法,数据单元合并器/解码器23可在候选数据单元之中搜索预测模式是帧间模式的邻近数据单元,并可将所述邻近数据单元确定为将与当前数据单元合并的一个数据单元。
可选择地,根据预设方法,数据单元合并器/解码器23可在候选数据单元之中搜索与当前数据单元具有相同参考索引的邻近数据单元,并可将所述邻近数据单元确定为将被合并的一个数据单元。
由于确定将与候选数据单元合并的邻近数据单元的每种方法可被预设,因此所述方法可被隐含地用信号发送。
数据单元合并器/解码器23在一个数据单元的分区之间可不执行相互合并。
数据单元合并器/解码器23可在根据当前分区的形状和位置而变化的邻近数据单元的合并候选组中确定将与当前数据单元合并的数据单元。
解析器/提取器21可提取用于每个预测单元的跳过模式信息,并可提取用于每个分区的合并相关信息。可选择地,解析器/提取器21可提取用于每个数据单元的合并相关信息和跳过模式信息。此外,解析器/提取器21可提取仅用于具有预定预测模式的数据单元的合并相关信息。
解析器/提取器21可依次提取预测单元的跳过模式信息、预测单元信息、分区信息和合并信息。分区信息可包括关于预测单元是否被划分为分区的信息和关于分区类型的信息。
设备20可通过在编码单元之间执行数据单元合并或在预测单元之间执行数据单元合并来对视频数据进行解码。此外,设备20可根据编码的跳过模式信息和直接模式信息对视频数据进行选择性地解码。
相应地,如果基于数据单元的跳过模式信息,数据单元的预测模式不是跳过模式,则解析器/提取器21可提取指示数据单元的直接模式信息是否被编码的跳过/直接模式编码信息、指示编码单元的合并的发生是否被确定的编码单元合并确定信息、和指示预测单元之间的合并的发生是否被确定的预测单元合并确定信息中的至少一个。此外,数据单元合并器/解码器23可基于提取的信息,通过使用跳过模式和直接模式两者来执行解码,或者可基于编码单元或预测单元,对经过数据单元合并的视频数据进行解码。
数据单元合并器/解码器23可针对与邻近数据单元合并的数据单元,通过根据预设规则确定具有跳过模式的数据单元的参考索引和参考方向并遵守邻近数据单元的运动信息的参考索引和参考方向,对视频数据进行解码。由于确定具有跳过模式的数据单元的参考索引和参考方向的规则可被预设,因此所述规则可被隐含地用信号发送。
随着视频分辨率的增加,数据量也快速增加,并且数据单元的尺寸增加,冗余数据增加,因此具有跳过模式或直接模式的数据单元增加。然而,由于先前的宏块合并方法确定是否仅预测模式是除了跳过模式和直接模式以外的帧间模式的宏块被合并,并将所述宏块与具有固定尺寸和固定位置的邻近宏块合并,因此先前的宏块合并方法被应用于有限的区域。
设备10和设备20可对具有各种尺寸、各种形状和各种预测模式的数据单元执行数据单元合并,并可将数据单元与具有各种位置的邻近数据单元合并。因此,由于各种数据单元共享更多不同的邻近数据单元的预测相关信息,因此可通过参照更宽范围的外围信息来去除冗余数据,从而提高视频编码效率。
图3是示出根据现有技术的可与当前宏块合并的邻近宏块的示图。
根据依据现有技术的块合并方法,包括在将与当前宏块合并的邻近块的合并候选组中的邻近块应该是具有帧间模式并在当前宏块之前被编码的邻近块。因此,只有与当前宏块的上边界和右边界邻近的块可被包括在合并候选组中。
合并的块可组成一个区域,并且可根据合并的块的区域对编码信息和合并相关信息进行编码。例如,关于块合并是否被执行的合并信息,如果块合并被执行,则指示当前宏块的上邻近块和左邻近块中的哪个块被合并的合并块位置信息可被编码。
根据依据现有技术的块合并方法,尽管多个块接触当前宏块的边界,但只有接触当前块的左上采样的邻近块可被选择以与当前宏块合并。
也就是说,与第一当前宏块31的上边界邻近并与第一当前宏块31的左上采样接触的第一上邻近块32和与第一当前宏块31的左边界邻近并与第一宏块31的左上采样接触的第二左邻近块33之一可被选择以与第一当前宏块31合并。
同样地,与第二当前宏块35的左上采样接触的第二上邻近块36和第二左邻近块37中的一个可选择性地与第二当前宏块35合并。
图4和图5是用于分别解释根据现有技术和示例性实施例的在当前数据单元的邻近数据单元之中选择将与当前数据单元合并的一个数据单元的方法的示图。
参照图4,根据依据现有技术的数据单元合并方法,尽管邻近数据单元42、43和44与当前数据单元41的上边界接触,邻近数据单元45、46、47和48与当前数据单元41的左边界接触,但将与当前数据单元41合并的数据单元被限制为作为上邻近数据单元的数据单元42或作为左邻近数据单元的数据单元45。此外,由于仅与预测模式是帧间模式的邻近数据单元的合并是可能的,因此如果邻近数据单元42和44的预测模式是跳过模式或直接模式,则邻近数据单元42和44不被视为将被合并的数据单元。
根据图5的设备10和设备20的数据单元合并方法,可与当前数据单元41合并的邻近数据单元的合并候选组可包括上邻近数据单元42、43和44以及左邻近数据单元45、46、47和48全部。在这种情况下,即使在当前数据单元41的预测模式是跳过模式或直接模式及帧间模式,也可确定当前数据单元41是否与邻近数据单元合并。
例如,包括当前数据单元41的上邻近数据单元42、43和44的上合并候选组52中的一个可被确定为上合并候选a’。同样地,包括当前数据单元41的左邻近数据单元45、46、47和48的左合并候选组55中的一个可被确定为左合并候选l’。上合并候选a’和左合并候选l’之一可被最终确定为将与当前数据单元41合并的邻近数据单元。
设备10和设备20可根据预设方法确定将上合并候选组52之一确定为上合并候选a’的方法和将左合并候选组55之一确定为左合并候选l’的方法。关于当前方法的信息可被隐含地用信号发送。即使关于当前方法的信息未被单独地编码以在上合并候选组52中搜索上合并候选a’或在左合并候选组55中搜索左合并候选l’,但设备10和设备20可察觉搜索上合并候选a’和左合并候选l’的预设方法。
例如,在上合并候选组52和左合并候选组55中与当前数据单元41具有相同的参考索引信息的邻近数据单元可被确定为上合并候选a’和左合并候选l’。可选择地,在上合并候选组52和左合并候选组55中与预测模式是帧间模式的当前数据单元41的左上采样最接近的邻近数据单元可被确定为上合并候选a’和左合并候选l’。
同样地,设备10和设备2可根据预设方法将上合并候选a’和左合并候选l’之一最终确定为将与当前数据单元41合并的邻近数据单元。
图6和图7是用于解释根据示例性实施例的对预测模式信息、合并相关信息和预测相关信息进行编码和解码的顺序的框图。
首先,图6是用于解释根据考虑当前数据单元的预测模式是否是跳过模式来确定数据单元合并的发生的第一示例性实施例,对预测模式信息、合并相关信息和预测相关信息进行编码和解码的方法的框图。
在操作61,设备10对当前数据单元的跳过模式信息“skip_flag”进行编码。如果当前数据单元的预测模式是跳过模式,则跳过模式信息“skip_flag”可被设置为1,如果当前数据单元的预测模式不是跳过模式,则跳过模式信息“skip_flag”可被设置为0。
如果在操作61确定当前数据单元的预测模式是跳过模式,则所述方法进行到操作62。在操作62,合并信息“merging_flag”可不被编码。如果在操作61确定当前数据单元的预测模式不是跳过模式,则所述方法进行到操作63。在操作63,合并信息“merging_flag”被编码。可根据预设规则来确定预测模式是跳过模式的当前数据单元的预测方向和参考索引信息。对于将与邻近数据单元合并的当前数据单元的预测方向和参考索引信息,可遵守或参照邻近数据单元的运动矢量的参考索引和参考方向。
例如,如果存在以下规则:如果当前条带是p条带,则预测模式是跳过模式的数据单元的预测方向被设置为list0方向,如果当前条带是b条带,则预测模式是跳过模式的数据单元的预测模式被设置为bi方向并且参考索引被设置为0,则根据所述规则,预测模式是跳过模式的数据单元的预测编码是可行的。
如果当前数据单元与邻近数据单元合并,则当前数据单元的合并信息“merging_flag”可被设置为1,并且如果当前数据单元未与邻近数据单元合并,则当前数据单元的合并信息“merging_flag”可被设置为0。在操作64,如果当前数据单元与邻近数据单元合并,则由于用于当前数据单元的预测编码的辅助预测信息可遵守邻近数据单元的信息,或者可从邻近数据单元的信息获取用于当前数据单元的预测编码的辅助预测信息,因此当前数据单元的预测方向和参考索引信息“interdirection/refindex”可不被编码。在操作65,尽管当前数据单元与邻近数据单元合并,但运动矢量差分信息“mvd”被编码。
在操作66,如果当前数据单元未与邻近数据单元合并,则当前数据单元的预测方向和参考索引信息“interdirection/refindex”可被编码,并且在操作67,运动矢量差分信息“mvd”可被编码。例如,当前数据单元的预测方向可包括list0方向、list1方向和bi方向。
如操作61至67的方法,设备20可提取并读取当前数据单元的跳过模式信息,并可基于跳过模式信息提取并读取合并信息和预测相关信息。
图7是用于解释根据考虑当前数据单元的预测模式是否是跳过模式和直接模式来确定数据单元合并的发生的第二示例性实施例,对预测模式信息、合并相关信息和预测相关信息进行编码/解码的方法的框图。
在操作71,设备10对当前数据单元的跳过模式信息“skip_flag”进行编码。如果在操作71确定当前数据单元的预测模式是跳过模式,则所述方法进行到操作72。在操作72,合并信息“merging_flag”可不被编码。
如果在操作71确定当前数据单元的预测模式不是跳过模式,则所述方法进行到操作73。在操作73,直接模式“direct_flag”被编码。如果当前数据单元的预测模式是直接模式,则当前数据单元的直接模式信息“direct_flag”可被设置为1,如果当前数据单元的预测模式不是直接模式,则当前数据单元的直接模式信息“direct_flag”可被设置为0。如果在操作73确定当前数据单元的预测模式是直接模式,则所述方法进行到操作74。在操作74,合并信息“merging_flag”可不被编码。
如果在操作73确定当前数据单元的预测模式不是直接模式,则所述方法进行到操作75。在操作75,合并信息“merging_flag”被编码。在操作76,如果当前数据单元与邻近数据单元合并,则当前数据单元的预测方向和参考索引信息“interdirection/refindex”可不被编码,并且在操作77,运动矢量差分信息“mvd”被编码。在操作78和79,如果当前数据单元未与邻近数据单元合并,则当前数据单元的预测方向和参考索引信息“interdirection/refindex”以及运动矢量差分信息“mvd”可被编码。
如操作71至79的方法,设备20可提取并读取当前数据单元的跳过模式信息或直接模式信息,并可基于跳过模式信息或直接模式信息提取并读取合并信息和预测相关信息。
图8和图9是用于分别解释根据现有技术的方法和示例性实施例的在当前数据单元的扩展邻近数据单元之中选择将与当前数据单元合并的一个数据单元的方法的示图。
根据图8的现有技术的数据单元合并方法,将与当前数据单元81合并的对象被限于与当前数据单元81的左上采样接触的上邻近数据单元82和左邻近数据单元85。也就是说,与当前数据单元81的左上拐角、右上拐角和左下拐角接触的邻近数据单元89、91和93未包括在当前数据单元81的合并候选组中。
图9的数据单元合并方法与帧间模式的运动矢量预测方法类似。在图9中,可与当前数据单元81合并的邻近数据单元的合并候选组不仅可包括上邻近数据单元82、83和84以及左邻近数据单元85、86、87和88,还可包括与当前数据单元81的左上拐角、右上拐角和左下拐角接触的邻近数据单元89、91和93。
例如,包括当前数据单元81的上邻近数据单元82、83和84的上合并候选组92之一可被确定为上合并候选a’,并且包括左邻近数据单元85、86、87和88的左合并候选组95之一可被确定为左合并候选l’。此外,包括与当前数据单元81的左上拐角、右上拐角和左下拐角接触的邻近数据单元89、91和93的拐角合并候选组96之一可被确定为拐角合并候选c’。上合并候选a’、左合并候选l’和拐角合并候选c’之一可被最终确定为将与当前数据单元81合并的邻近数据单元。
将上合并候选组92之一确定为上合并候选a’的方法、将左合并候选组95之一确定为左合并候选l’的方法、将拐角合并候选组96之一确定为拐角合并候选c’的方法、以及最终确定上合并候选a’、左合并候选l’和拐角合并候选c’之一的方法可遵守如参照图5描述的预设规则。
在图9中,由于可与当前数据单元81合并的候选数据单元的方向包括上、下和拐角,因此合并位置信息可被表现为合并索引,并不是标志类型0或1。
图10、图11和图12是用于解释根据各种示例性实施例的对预测模式信息、合并相关信息和预测相关信息进行编码和解码的顺序的框图。
参照图10,设备10可对用于每个预测单元的跳过模式信息和合并信息进行编码,其中,所述预测单元是用于预测编码的数据单元。
在操作101,设备10可对预测单元的跳过模式信息“skip_flag”进行编码,在操作102,设备10可对除跳过模式以外的预测单元的合并信息“merging_flag”进行编码。在操作103和104,设备10可对预测模式不是跳过模式并且未与邻近数据单元合并的预测单元的唯一预测模式信息“predictioninfo”和分区信息“partitioninfo”进行编码。
因此,设备20可提取并读取用于每个预测单元的跳过模式信息和合并信息。设备20可提取预测模式不是跳过模式并且未与邻近数据单元合并的预测单元的唯一预测模式信息和分区信息。
参照图11,设备10可对用于每个预测单元的跳过模式信息进行编码,并可对为了更准确的预测编码的目的而划分预测单元获得的每个分区的合并信息进行编码。
在操作111,设备10可对预测单元的跳过模式信息“skip_flag”进行编码,在操作112,设备10可对预测模式不是跳过模式的预测单元的预测模式信息“predictioninfo”进行编码,在操作113,设备10可对分区信息“partitioninfo”进行编码。
在操作114,设备10可对用于预测模式不是跳过模式的预测单元的每个分区的合并信息“merging_flag”进行编码。在操作115,设备10可对预测模式不是跳过模式的预测单元的分区之中未与邻近数据单元合并的分区的唯一运动信息“motioninfo”进行编码。
因此,设备20可提取并读取用于每个预测单元的跳过模式信息,并且可提取并读取用于每个分区的合并信息。设备20可提取预测模式不是跳过模式且未与邻近单元合并的分区的唯一运动信息。
参照图12,设备10可对用于每个预测单元的跳过模式信息进行编码,并可在满足预定条件时对用于每个分区的合并信息进行编码。
在操作121,设备10可对预测单元的跳过模式信息“skip_flag”进行编码,在操作122,设备10可对预测模式不是跳过模式的预测单元的预测模式信息“predictioninfo”进行编码,在操作123,所述设备可对分区信息“partitioninfo”进行编码。
在操作124,设备10针对预测单元的每个分区,确定预定条件是否被满足。在操作125,在预测模式不是跳过模式的预测单元的分区之中,只有满足所述预定条件的数据单元的合并信息“merging_flag”可被编码。在操作126,设备10对预测模式不是跳过模式的预测单元的分区之中的,满足所述预定条件且未与邻近数据单元合并的分区以及不满足所述预定条件的分区的唯一运动信息“motioninfo”进行编码。
用于对合并信息进行编码的分区的预定条件可包括分区的预测模式是预定预测模式的情况。例如,可根据预测模式不是跳过模式而是帧间模式(非跳过模式)的条件、预测模式不是跳过模式和直接模式,而是帧间模式(非跳过帧间模式和非直接帧间模式)的条件、或预测模式是不按分区划分的帧间模式(非分区的帧间模式)的条件,对分区的合并信息进行编码,
详细地讲,在操作124,如果对预测模式不是跳过模式和直接模式,而是帧间模式的数据单元执行数据单元合并,则设备10可确定除跳过模式以外的预测单元的分区的预测模式是否不是直接模式而是帧间模式。在操作125,预测模式不是直接模式的分区的合并信息“merging_flag”可被编码。在操作126,预测模式不是直接模式且未与邻近数据单元合并的分区以及预测模式是直接模式的分区的唯一运动信息“motioninfo”可被编码。
因此,设备20可提取并读取用于每个预测模式的跳过模式信息,并且可提取并读取用于每个分区的合并信息。设备20可提取并读取预测模式不是跳过模式且满足预定条件但是未与邻近数据单元合并的分区以及不满足所述预定条件的分区的唯一运动信息。
图13是示出根据示例性实施例的不与当前分区合并的邻近数据单元的示图。
为了更准确的预测编码,用于预测编码的数据单元(即,预测单元)可被划分为两个或更多个分区。例如,第一预测单元131的宽度可被划分为第一分区132和第二分区133。
由于即使第一分区132和第二分区133包括在第一预测单元131中,第一分区132和第二分区133也具有不同的运动特征,因此在第一分区132和第二分区133之间可不执行数据单元合并。因此,设备10可不确定在同一第一预测单元131的第一分区132和第二分区133之间是否执行数据单元合并。此外,用于第二分区133的合并索引信息可不包括指示左邻近数据单元的索引。
即使在第二预测单元135的高度被划分为第三分区136和第四分区137时,由于在第三分区136和第四分区137之间不应该执行数据单元合并,因此设备10可不确定在第三分区136和第四分区137之间是否执行数据单元合并。此外,用于第四分区137的合并索引信息可不包括指示上邻近数据单元的索引。
图14是示出根据示例性实施例的根据当前分区的形状和位置而改变的候选数据单元的框图。
根据分区的形状和位置,将被合并的邻近数据单元的位置可改变。例如,如果预测单元141被划分为左分区142和右分区143,则可与左分区142合并的邻近数据单元候选可以是与左分区142的上边界邻近的数据单元144、与左分区142的左边界邻近的数据单元145和与左分区142的右上拐角邻近的数据单元146。
尽管右分区153在左边界与左分区142接触,但由于左分区142和右分区143是同一预测单元141的分区,因此在左分区142和右分区143之间可不执行合并。因此,可与右分区143合并的邻近数据单元候选可以是与右分区143的上边界邻近的数据单元146和与右分区143的右上拐角邻近的数据单元147。此外,用于右分区143的合并索引信息可不包括指示左上邻近数据单元的索引。图15是示出根据示例性实施例的可不与作为具有几何形状的分区的当前分区合并的邻近数据单元的示图。
在设备10的预测编码中,预测单元不仅可按照垂直或水平方向被划分,还可按照任意方向被划分为具有各种几何形状的分区。通过按照任意方向执行划分而获得的预测单元148、152、156和160在图15中被示出。
根据具有几何形状的分区的位置和形状,具有几何形状的分区可不与和所述分区的上边界和左边界接触的邻近数据单元合并。例如,在预测单元148的两个分区149和150之中,分区150可与接触左边界的邻近数据单元151合并。然而,由于与上边界接触的邻近数据单元是包括在同一预测单元158中的分区149,因此分区150可不与上邻近数据单元合并。在这种情况下,分区150的合并索引信息可不包括指示作为上邻近数据单元的分区149的索引。
同样地,在预测单元152的两个分区153和154之中,分区164可与左邻近数据单元155合并。然而,由于上邻近数据单元是包括在同一预测单元152中的分区153,因此分区154可不与上邻近数据单元合并。
同样地,在预测单元156的两个分区157和158之中,分区158可与上邻近数据单元159合并。然而,由于左邻近数据单元是包括在同一预测单元156中的分区157,因此分区158可不与左邻近数据单元合并。
同样地,在预测单元160的两个分区161和162之中,由于包括在同一预测单元160中的分区161是分区162的上邻近数据单元和左邻近数据单元,因此分区162可不与上邻近数据单元和左邻近数据单元合并。
如参照图13、14和15所述,如果根据数据单元的形状或位置产生可不被合并的邻近数据单元,则合并索引信息可不包括指示可不被合并的邻近数据单元的索引。
此外,设备10可不执行用于扩展当前数据单元和使当前数据单元与先前存在的另一数据单元重叠的数据单元合并。
例如,如果一个预测单元被划分为两个分区并且第二分区的预定候选数据单元与第一分区具有相同的运动信息,则第二分区与预定候选数据单元之间的合并可能不被允许。
例如,在图13的第一预测单元131的第一分区132和第二分区133之中,如果第二分区133的上预测单元与第一分区132具有相同的运动信息,则第一分区132和第二分区133的上预测单元可从第二分区133的候选数据单元组被排除。这是因为如果数据单元合并被执行以使得第二分区133参照上预测单元的运动信息,则这与参照第一分区132的运动信息的情况相同。
可通过考虑邻近数据单元的预测模式和分区类型的上下文建模来设置合并信息连同数据单元合并是否被执行。通过分析当前数据单元的邻近数据单元的预测模式和分区类型的组合并在当前数据单元和邻近数据单元彼此合并为上下文模型的情况下,上下文模型的索引可被表现为合并信息。
表1示出根据示例性实施例的通过上下文建模的合并信息。为了便于解释,将与当前数据单元合并的对象被限于左邻近数据单元和上邻近数据单元。
表1
[表1]
[表]
这里可选择性地包括具有任意形状的分区,诸如通过根据对称比率划分分区的高度或宽度而获得的对称分区类型2n×2n、2n×n、n×2n和n×n,通过根据诸如1:n或n:1的不对称比率划分预测单元的高度或宽度而获得的不对称分区类型2n×nu、2n×nd、nl×2n和nr×2n,或通过将预测单元的高度或宽度划分为各种几何形状而获得的几何分区类型。通过根据1:3和3:1的比率划分预测单元的高度分别获得不对称分区类型2n×nu和2n×nd,并且通过根据1:3和3:1的比率划分预测单元的宽度分别获得不对称分区类型nl×2n和nr×2n。
根据表1,由于在当前数据单元的左邻近数据单元和上邻近数据单元两者的预测模式是帧内模式时不执行数据单元合并,因此当前数据单元的合并信息被分配给索引0,而不需要根据分区类型区分上下文模型。
此外,假设左邻近数据单元和上邻近数据单元的预测模式是帧间模式,而不是跳过模式或直接模式,当左邻近数据单元和上邻近数据单元中的仅一个与当前数据单元合并时,并且当左邻近数据单元和上邻近数据单元两者与当前数据单元合并时,可根据数据单元合并是否根据邻近数据单元的分区类型而被执行的组合来设置合并信息的上下文模型。在这种情况下,每个合并信息可根据表1被分配给上下文模型索引1至6之一。
此外,假设预测模式是跳过模式和直接模式,当左邻近数据单元和上邻近数据单元中的至少一个是跳过模式或直接模式时,可根据邻近数据单元的分区类型来设置合并信息的上下文模型,并且每个合并信息可根据表1被分配给上下文模型索引7至9之一。
因此,设备20可根据上下文建模读取合并信息,并可分析在当前数据单元和邻近数据单元之间是否执行了合并以及邻近数据单元的预测模式和分区类型。
设备20可通过使用与当前数据单元合并的邻近数据单元的运动信息来推断当前数据单元的运动信息。
此外,如果通过数据单元合并形成的合并的数据单元的形状是规则的正方形,则设备10和设备20可对合并的数据单元执行变换。
此外,在设备10和设备20中,与当前数据单元合并的邻近数据单元可共享关于帧内预测方向的信息。关于用于通过数据单元合并形成的合并的数据单元的预测方向的信息可不根据数据单元而被编码或解码,但可针对合并的数据单元仅被编码或解码一次。
图16是示出根据示例性实施例的使用被确定为与当前数据单元合并的邻近数据单元的示例的示图。
设备10和设备20可扩展将与当前数据单元163合并的邻近数据单元的边界,并可使用扩展的边界来划分当前数据单元164的分区。例如,如果当前数据单元163与左邻近数据单元164、165和166合并,则左邻近数据单元164、165和166的边界可被扩展至达到当前数据单元163。当前数据单元163可根据左邻近数据单元165、165和166的扩展的边界而被划分为分区167、168和169。
图17是示出根据示例性实施例的通过使用数据单元合并来对视频进行编码的方法的流程图。
在操作171,指示用于画面的编码的数据单元和对每个数据单元执行的包括预测编码的编码方法的编码模式被确定。
在操作172,根据数据单元,基于预测模式和编码模式中的至少一个来确定与至少一个邻近数据单元的合并的发生。数据单元可包括用于预测编码的预测单元和用于预测单元的准确预测编码的分区。
可在与当前数据单元的上边界接触的多个上邻近数据单元和与当前数据单元的左边界接触的多个左邻近数据单元之中搜索将与当前数据单元合并的数据单元。此外,可在与当前数据单元的左上拐角、右上拐角和左下拐角接触的邻近数据单元之中搜索将与当前数据单元合并的数据单元。
在操作173,可根据数据单元,基于与邻近数据单元的合并的发生来确定预测模式信息、合并相关信息和预测相关信息,并对包括预测模式信息、合并相关信息和预测相关信息的编码信息进行编码。
可对预测模式是跳过模式和直接模式的数据单元的合并相关信息进行编码。因此,可在对跳过模式信息或直接模式信息进行编码之后对被确定为将与预定的邻近数据单元合并的数据单元的合并相关信息进行编码。合并相关信息可包括指示在当前数据单元和邻近数据单元之间是否执行合并的合并信息以及指示邻近数据单元的合并索引信息。
如果预测单元的跳过模式信息和合并相关信息两者均被编码,则可在跳过模式信息和合并相关信息被编码之后对预测单元的预测模式信息和分区类型信息进行编码。
如果预测单元的跳过模式信息被编码并且分区的合并相关信息被编码,则可在预测单元的跳过模式信息、预测模式信息和分区类型信息被编码之后,根据分区对合并相关信息进行编码。
图18是示出根据示例性实施例的通过使用数据单元合并来对视频进行解码的方法的流程图。
在步骤181,对接收的比特流进行解析,从所述比特流提取已编码的视频数据和编码信息,并从编码信息提取预测模式信息、合并相关信息和预测相关信息。
可基于读取当前数据单元的跳过模式信息或直接模式信息的结果来提取合并相关信息。例如,可提取预测模式不是跳过模式的数据单元的合并相关信息。可选择地,可提取预测模式是帧间模式,而不是跳过模式和直接模式的数据单元的合并相关信息。可从合并相关信息读取指示在当前数据单元和邻近数据单元之间是否执行合并的合并信息以及指示邻近数据单元的合并索引信息。
如果针对每个预测单元提取跳过模式信息和合并相关信息,则可在跳过模式信息和合并相关信息被提取之后提取预测单元的预测模式信息和分区类型信息。
如果以预测单元级提取跳过模式信息并以分区级提取合并相关信息,则可在预测单元的跳过模式信息、预测模式信息和分区类型信息被提取之后,根据分区提取合并相关信息。
在操作182,基于预测模式信息和合并相关信息,根据数据单元基于预测模式和编码模式中的至少一个来分析与至少一个邻近数据单元的合并的发生。通过使用邻近数据单元的预测相关信息来对与邻近数据单元合并的数据单元执行帧间预测和运动补偿,并基于编码信息,根据确定的编码单元对已编码的视频数据进行解码。
可基于合并信息和合并索引信息,在与上边界接触的多个上邻近数据单元和与左边界接触的多个左邻近数据单元之中确定将与当前数据单元合并的数据单元。此外,可在与当前数据单元的左上拐角、右上拐角和左下拐角接触的邻近数据单元之中确定将与当前数据单元合并的数据单元。
可通过使用与当前数据单元合并的数据单元的运动相关信息来重构当前数据单元的运动相关信息。通过使用运动相关信息对当前数据单元执行的运动补偿,可恢复当前数据单元并可恢复画面。
现在将参照图19至图33解释根据一个或多个示例性实施例的基于具有树结构的编码单元,通过使用数据单元合并来对视频进行编码的设备和方法以及对视频进行解码的设备和方法。
图19是根据示例性实施例的基于具有树结构的编码单元,通过使用数据单元合并来对视频进行编码的设备100的框图。
设备100包括最大编码单元划分器110、编码单元确定器120和输出单元130。为了便于解释,基于具有树结构的编码单元,通过使用数据单元合并对视频进行编码的设备100被称为“用于对视频进行编码的设备100”。
最大编码单元划分器110可基于用于图像的当前画面的最大编码单元对所述当前画面进行划分。如果当前画面大于最大编码单元,则当前画面的图像数据可被划分为至少一个最大编码单元。最大编码单元可以是具有32×32、64×64、128×128、256×256等尺寸的数据单元,其中,数据单元的形状是宽和高为2的平方的方形。图像数据可根据所述至少一个最大编码单元被输出到编码单元确定器120。
编码单元可由最大尺寸和深度来表征。深度表示编码单元从最大编码单元被空间划分的次数,并且随着深度加深,根据深度的更深编码单元可从最大编码单元被划分为最小编码单元。最大编码单元的深度是最高深度,最小编码单元的深度是最低深度。由于与每个深度相应的编码单元的尺寸随着最大编码单元的深度加深而减小,因此,与更高深度相应的编码单元可包括多个与更低深度相应的编码单元。
如上所述,当前画面的图像数据根据编码单元的最大尺寸被划分为最大编码单元,所述最大编码单元中的每一个可包括根据深度被划分的更深编码单元。由于最大编码单元根据深度被划分,因此包括在最大编码单元中的空间域的图像数据可根据深度被分层分类。
可预先确定编码单元的最大深度和最大尺寸,所述最大深度和最大尺寸限定最大编码单元的高度和宽度被分层划分的总次数。
编码单元确定器120对通过根据深度划分最大编码单元的区域而获得的至少一个划分区域进行编码,并确定用于输出根据所述至少一个划分区域的最终编码的图像数据的深度。换句话说,编码单元确定器120通过根据当前画面的最大编码单元,按照根据深度的更深编码单元对图像数据进行编码,并选择具有最小编码误差的深度,以确定编码深度。因此,与确定的编码深度相应的编码单元的已编码的图像数据被最终输出。此外,与编码深度相应的编码单元可被视为被编码的编码单元。确定的编码深度和根据确定的编码深度的已编码的图像数据被输出到输出单元130。
基于与等于或低于最大深度的至少一个深度相应的更深编码单元对最大编码单元中的图像数据进行编码,并基于更深编码单元中的每一个来比较对图像数据进行编码的结果。在比较更深编码单元的编码误差之后,可选择具有最小编码误差的深度。可为每个最大编码单元选择至少一个编码深度。
随着编码单元根据深度被分层划分,并随着编码单元的数量增加,最大编码单元的尺寸被划分。此外,即使是一个最大编码单元中与相同深度相应的编码单元,也通过分别测量每个编码单元的图像数据的编码误差来将与相同深度相应的编码单元中的每一个划分至更低的深度。因此,即使当图像数据被包括在一个最大编码单元中时,图像数据也根据深度被划分到多个区域,并且在一个最大编码单元中编码误差可根据区域而不同,因此,编码深度可根据图像数据中的区域而不同。因此,在一个最大编码单元中可确定一个或多个编码深度,并可根据至少一个编码深度的编码单元来划分最大编码单元的图像数据。
因此,编码单元确定器120可确定包括在最大编码单元中的具有树结构的编码单元。“具有树结构的编码单元”包括最大编码单元中所包括的所有更深编码单元之中与被确定为编码深度的深度相应的编码单元。在最大编码单元的相同区域中,编码深度的编码单元可根据深度被分层地确定,在不同的区域中,编码深度的编码单元可被独立地确定。类似地,当前区域中的编码深度可独立于另一区域中的编码深度被确定。
最大深度是与从最大编码单元到最小编码单元的划分次数相关的索引。第一最大深度可表示从最大编码单元到最小编码单元的总划分次数。第二最大深度可表示从最大编码单元到最小编码单元的深度级的总数。例如,当最大编码单元的深度为0时,最大编码单元被划分一次的编码单元的深度可被设置为1,最大编码单元被划分两次的编码单元的深度可被设置为2。这里,如果最小编码单元是最大编码单元被划分四次的编码单元,则存在深度0、1、2、3和4的5个深度级,并且因此,第一最大深度可被设置为4,第二最大深度可被设置为5。
可根据最大编码单元执行预测编码和变换。还可根据最大编码单元,基于根据等于最大深度的深度或小于最大深度的深度的更深编码单元来执行预测编码和变换。被执行用于对视频进行编码的变换可包括频率变换、正交变换、整数变换等。
由于每当最大编码单元根据深度被划分时更深编码单元的数量增加,因此对随着深度加深而产生的所有更深编码单元执行包括预测编码和变换的编码。为了便于描述,在最大编码单元中,现在将基于当前深度的编码单元来描述预测编码和变换。
设备100可不同地选择用于对图像数据进行编码的数据单元的尺寸或形状。为了对图像数据进行编码,执行诸如预测编码、变换和熵编码的操作,此时,可针对所有操作使用相同的数据单元,或者可针对每个操作使用不同的数据单元。
例如,设备100不仅可选择用于对图像数据进行编码的编码单元,还可选择与编码单元不同的数据单元以对编码单元中的图像数据执行预测编码。
为了在最大编码单元中执行预测编码,可基于与编码深度相应的编码单元(即,基于不再被划分为与更低深度相应的编码单元的编码单元)执行预测编码。在下文中,不再被划分并且变成用于预测编码的基本单元的编码单元现将被称为“预测单元”。通过对预测单元进行划分所获得的分区(partition)可包括通过对预测单元的高度和宽度中的至少一个进行划分所获得的数据单元。
例如,当2n×2n(其中,n是正整数)的编码单元不再被划分,并且变成2n×2n的预测单元时,分区的尺寸可以是2n×2n、2n×n、n×2n或n×n。分区类型的示例包括通过对预测单元的高度或宽度进行对称划分所获得的对称分区、通过对预测单元的高度或宽度进行不对称划分(诸如1:n或n:1)所获得的分区、通过对预测单元进行几何划分所获得的分区以及具有任意形状的分区。
预测单元的预测模式可以是帧内模式、帧间模式和跳过模式中的至少一个。例如,可对2n×2n、2n×n、n×2n或n×n的分区执行帧内模式或帧间模式。此外,可仅对2n×2n的分区执行跳过模式。对编码单元中的一个预测单元独立地执行编码,从而选择具有最小编码误差的预测模式。
设备100还可不仅基于用于对图像数据进行编码的编码单元,还基于不同于编码单元的数据单元,对编码单元中的图像数据执行变换。
为了在编码单元中执行变换,可基于具有小于或等于编码单元的尺寸的变换单元来执行变换。例如,变换单元可包括用于帧内模式的数据单元和用于帧间模式的变换单元。
与具有树结构的编码单元类似地,编码单元中的变换单元可被递归地划分为更小尺寸的区域,使得可以以区域为单位来独立确定变换单元。因此,可根据变换深度,依据具有树结构的变换来对编码单元中的残差数据进行划分。
用作变换的基础的数据单元现将被称为“变换单元”。还可在变换单元中设置指示通过对编码单元的高度和宽度进行划分以达到变换单元的划分次数的变换深度。例如,在2n×2n的当前编码单元中,当变换单元的尺寸也为2n×2n时,变换深度可以是0,在当前编码单元的高度和宽度中的每一个被划分为两个相等部分,总共被划分为4^1个变换单元,从而变换单元的尺寸是n×n时,变换深度可以是1,在当前编码单元的高度和宽度中的每一个被划分为四个相等部分,总共被划分为4^2个变换单元,从而变换单元的尺寸是n/2×n/2时,变换深度可以是2。例如,可根据分层树结构来设置变换单元,其中,根据变换深度的分层特性,更高变换深度的变换单元被划分为四个更低变换深度的变换单元。
根据与编码深度相应的编码单元的编码信息不仅需要关于编码深度的信息,还需要与预测编码和变换有关的信息。因此,编码单元确定器120不仅确定具有最小编码误差的编码深度,还确定预测单元中的分区类型、根据预测单元的预测模式和用于变换的变换单元的尺寸。
稍后将参照图21至图31详细描述根据示例性实施例的最大编码单元中的具有树结构的编码单元以及确定分区的方法。
编码单元确定器120可通过使用基于拉格朗日乘子的率失真优化来测量根据深度的更深编码单元的编码误差。
输出单元130在比特流中输出最大编码单元的图像数据以及关于根据编码深度的编码模式的信息,其中,所述图像数据基于由编码单元确定器120确定的至少一个编码深度被编码。
可通过对图像的残差数据进行编码来获得已编码的图像数据。
关于根据编码深度的编码模式的信息可包括关于编码深度的信息、关于预测单元中的分区类型、预测模式和变换单元的尺寸的信息。
可通过使用根据深度的划分信息来定义关于编码深度的信息,关于编码深度的信息指示是否对更低深度而不是当前深度的编码单元执行编码。如果当前编码单元的当前深度是编码深度,则当前编码单元中的图像数据被编码并被输出,因此,划分信息可被定义为不将当前编码单元划分至更低深度。可选择地,如果当前编码单元的当前深度不是编码深度,则对更低深度的编码单元执行编码,因此,划分信息可被定义为划分当前编码单元以获得更低深度的编码单元。
如果当前深度不是编码深度,则对被划分为更低深度的编码单元的编码单元执行编码。由于在当前深度的一个编码单元中存在至少一个更低深度的编码单元,因此对每个更低深度的编码单元重复执行编码,因此,可针对具有相同深度的编码单元递归地执行编码。
由于针对一个最大编码单元确定具有树结构的编码单元,并且针对编码深度的编码单元确定关于至少一个编码模式的信息,因此,可针对一个最大编码单元确定关于至少一个编码模式的信息。此外,由于图像数据根据深度被分层划分,因此最大编码单元的图像数据的编码深度可根据位置而不同,因此,可针对图像数据设置关于编码深度和编码模式的信息。
因此,输出单元130可将关于相应的编码深度和编码模式的编码信息分配给包括在最大编码单元中的编码单元、预测单元和最小单元中的至少一个。
最小单元是通过将构成最低深度的最小编码单元划分为4份所获得的矩形数据单元。可选择地,最小单元可以是最大矩形数据单元,其中,所述最大矩形数据单元可包括在最大编码单元中所包括的所有编码单元、预测单元、分区单元和变换单元中。
例如,通过输出单元130输出的编码信息可被分为根据编码单元的编码信息和根据预测单元的编码信息。根据编码单元的编码信息可包括关于预测模式和关于分区的尺寸的信息。根据预测单元的编码信息可包括关于帧间模式的估计方向、关于帧间模式的参考图像索引、关于运动矢量、关于帧内模式的色度分量和关于帧内模式的插值方法的信息。此外,关于根据画面、条带或gop定义的编码单元的最大尺寸的信息以及关于最大深度的信息可被插入比特流的头或sps(序列参数集)中。
在设备100中,更深编码单元可以是通过将更高深度的编码单元的高度或宽度划分为二所获得的编码单元。换句话说,在当前深度的编码单元的尺寸为2n×2n时,更低深度的编码单元的尺寸是n×n。此外,具有2n×2n的尺寸的当前深度的编码单元可包括最多4个更低深度的编码单元。
因此,设备100可通过基于考虑当前画面的特征所确定的最大编码单元的尺寸和最大深度,针对每个最大编码单元确定具有最佳形状和最佳尺寸的编码单元,来形成具有树结构的编码单元。此外,由于可通过使用各种预测模式和变换中的任意一个来对每个最大编码单元执行编码,因此可考虑各种图像尺寸的编码单元的特征来确定最佳编码模式。
设备100可另外地执行数据单元合并方法以在彼此邻近并具有相似的预测相关信息的数据单元之间共享预测相关信息。设备100的编码单元确定器120可包括设备10的编码单元确定器11和数据合并确定器13,并且设备100的输出单元130可包括设备10的编码信息确定器15。
因此,设备100的编码单元确定器120可确定是否对具有树结构的编码单元、预测单元和分区执行邻近数据单元之间的数据单元合并,输出单元130可执行包括关于编码单元的编码信息中的合并相关信息的编码。
输出单元130可将合并相关信息以及关于编码单元的编码信息和关于当前画面的编码单元的最大尺寸的信息插入到关于当前画面的头、pps或sps中。
编码单元确定器120可分析即使在具有树结构的编码单元的当前分区或当前预测单元的预测模式是跳过模式或直接模式的情况下,与邻近数据单元共享预测相关信息的数据单元合并的可能性。
编码单元确定器120可包括将与当前数据单元或当前分区合并的邻近数据单元的候选组中的所有与当前预测单元或当前分区的左边界邻近的多个左邻近数据单元和所有与上边界邻近的多个上邻近数据单元。
还可基于具有树结构的编码单元,根据扫描顺序或解码顺序来参考与当前预测单元或当前分区的左下拐角邻近的左下邻近数据单元。因此,除了当前预测单元或当前分区的合并候选组中的所有的多个左邻近数据单元和上邻近数据单元之外,编码单元确定器120还可包括与左上拐角、右上拐角和左下拐角邻近的数据单元。
此外,由于基于当前预测单元或当前分区的预测模式来确定数据单元合并的可能性,因此预测模式信息和合并信息的编码紧密相关。例如,输出单元130可对编码信息进行编码,使得基于用于具有树结构的编码单元的当前预测单元或当前分区的跳过信息或直接信息来设置合并相关信息。
由于由设备100构成的具有树结构的编码单元包括具有各种预测模式和各种形状的预测单元和分区,因此具有各种预测模式和各种形状的预测单元或分区可能与当前预测单元或当前分区的上边界和左边界接触。编码单元确定器120可搜索在当前数据单元和与当前预测单元或当前分区的上边界和左边界接触的多个各种邻近预测单元或邻近分区之间执行数据单元合并的可能性,并可确定将被合并的对象。
因此,由于当前预测单元或当前分区基于具有树结构的编码单元与具有各种尺寸、形状和位置的邻近数据单元共享预测相关信息,因此可通过使用更宽范围的外围信息来去除冗余数据,并可提高视频编码效率。
图20是根据示例性实施例的基于具有树结构的编码单元,通过使用数据单元合并来对视频进行解码的设备200的框图。
设备200包括接收器210、图像数据和编码信息提取器220以及图像数据解码器230。为了便于解释,基于具有树结构的编码单元,通过使用数据单元合并来对视频进行解码的设备200被称为“用于对视频进行解码的设备200”。
用于设备200的各种操作的各种术语(诸如编码单元、深度、预测单元、变换单元)的定义和关于各种编码模式的信息与以上参照图19和设备100描述的那些相同。
接收器210接收并解析已编码的视频的比特流。图像数据和编码信息提取器220从解析的比特流提取每个编码单元的已编码的图像数据,并将提取的图像数据输出到图像数据解码器230,其中,所述编码单元具有根据最大编码单元的树结构。图像数据和编码信息提取器220可从关于当前画面的头、pps或者sps中提取关于当前画面的编码单元的最大尺寸的信息。
此外,图像数据和编码信息提取器220从解析的比特流提取关于具有根据最大编码单元的树结构的编码单元的编码深度和编码模式的信息。提取的关于编码深度和编码模式的信息被输出到图像数据解码器230。换句话说,比特流中的图像数据被划分为最大编码单元,从而图像数据解码器230针对每个最大编码单元对图像数据进行解码。
可针对关于与编码深度相应的至少一个编码单元的信息来设置关于根据最大编码单元的编码深度和编码模式的信息,并且关于编码模式的信息可包括关于与编码深度相应的相应编码单元的分区类型、关于预测模式和变换单元的尺寸的信息。此外,关于编码深度和编码模式的编码信息还可包括关于当前预测单元或当前分区的合并相关信息。
由图像数据和编码信息提取器220提取的关于根据最大编码单元的编码深度和编码模式的信息是关于以下编码深度和编码模式的信息:所述编码深度和编码模式被确定为当编码器(诸如设备100)根据最大编码单元对根据深度的每个更深编码单元重复执行编码时产生最小编码误差。因此,设备200可通过根据产生最小编码误差的编码深度和编码模式对图像数据进行解码来恢复图像。
由于关于编码深度和编码模式的编码信息可被分配给相应编码单元、预测单元和最小单元中的预定数据单元,因此图像数据和编码信息提取器220可根据预定数据单元提取关于编码深度和编码模式的信息。被分配有相同的关于编码深度和编码模式的信息的预定数据单元可被推断为是包括在相同最大编码单元中的数据单元。
图像数据解码器230通过基于关于根据最大编码单元的编码深度和编码模式的信息对每个最大编码单元中的图像数据进行解码,来恢复当前画面。换句话说,图像数据解码器230可基于提取的关于包括在每个最大编码单元中的具有树结构的编码单元之中的每个编码单元的分区类型、预测模式和变换单元的信息,来对已编码的图像数据进行解码。解码处理可包括预测(所述预测包括帧内预测和运动补偿)和逆变换。
图像数据解码器230可基于关于根据编码深度的编码单元的预测单元的分区类型和预测模式的信息,根据每个编码单元的分区和预测模式执行帧内预测或运动补偿。
此外,为了根据最大编码单元执行逆变换,图像数据解码器230可通过读取包括关于根据编码深度的编码单元的变换单元的尺寸的信息的具有树结构的变换单元,基于用于每个编码单元的变换单元来执行逆变换。
图像数据解码器230可通过使用根据深度的划分信息来确定当前最大编码单元的至少一个编码深度。如果划分信息指示图像数据在当前深度不再被划分,则当前深度是编码深度。因此,图像数据解码器230可通过使用关于与编码深度相应的每个编码单元的预测单元的分区类型、预测模式和变换单元的尺寸的信息,对当前最大编码单元中与每个编码深度相应的至少一个编码单元的已编码的数据进行解码,并输出当前最大编码单元的图像数据。
换句话说,可通过观察为编码单元、预测单元和最小单元中的预定数据单元分配的编码信息集来收集包含包括相同划分信息的编码信息的数据单元,收集的数据单元可被视为是将由图像数据解码器230以相同的编码模式进行解码的一个数据单元。
此外,设备200可通过使用数据单元合并方法,通过使用当前预测单元或当前分区的外围数据单元的预测相关信息来恢复当前预测单元或当前分区。为此,设备200的接收器210及图像数据和编码信息提取器220可包括设备20的解析器/提取器21,并且设备200的图像数据解码器230可包括设备20的数据单元合并确定器23。
图像数据和编码信息提取器220可从关于编码模式的信息提取预测模式信息和合并相关信息。图像数据和编码信息提取器220可基于预测模式信息和合并相关信息之间的紧密关系,确定根据关于编码模式的信息中的预测模式信息提取并读取合并相关信息的可能性。例如,图像数据和编码信息提取器220可基于用于具有树结构的编码单元的当前预测单元或当前分区的跳过模式信息或直接信息,提取合并相关信息。此外,合并信息和合并索引信息可被提取为合并相关信息。
设备200的图像数据解码器230可基于关于编码模式和编码深度的信息形成具有树结构的编码单元,并且具有树结构的编码单元之中的每个编码单元包括具有各种预测模式和各种形状的预测单元和分区。
设备200的图像数据解码器230可搜索在当前数据单元和与当前预测单元或分区的上边界和左边界接触的各种邻近预测单元或邻近分区之间是否可执行合并,并可确定将被合并的对象。可通过参照合并的邻近预测单元或分区的预测相关信息来确定或推断当前预测单元或当前分区的预测相关信息。
设备200可获得关于当针对每个最大编码单元递归执行编码时产生最小编码误差的至少一个编码单元的编码信息,并可使用所述信息来对当前画面进行解码。也就是说,可对每个最大编码单元中被确定为最佳编码单元的具有树结构的编码单元进行解码。
根据基于紧密关系设置的预测相关信息和合并相关信息,可通过参照邻近数据单元的预测相关信息,对通过基于根据树结构的编码单元共享具有各种尺寸和形状的邻近数据单元的预测相关信息而编码的数据进行准确解码。
现在将参照图21至图31描述根据示例性实施例的确定具有树结构的编码单元、预测单元和变换单元的方法。
图21是用于解释根据示例性实施例的编码单元的概念的示图。
编码单元的尺寸可被表示为宽度×高度,并且可以是64×64、32×32、16×16和8×8。64×64的编码单元可被划分为64×64、64×32、32×64或32×32的分区,32×32的编码单元可被划分为32×32、32×16、16×32或16×16的分区,16×16的编码单元可被划分为16×16、16×8、8×16或8×8的分区,8×8的编码单元可被划分为8×8、8×4、4×8或4×4的分区。
在视频数据310中,分辨率为1920×1080,编码单元的最大尺寸为64并且最大深度为2。在视频数据320中,分辨率为1920×1080,编码单元的最大尺寸为64并且最大深度为3。在视频数据330中,分辨率为352×288,编码单元的最大尺寸为16并且最大深度为1。图11中示出的最大深度表示从最大编码单元到最小解码单元的划分总次数。
如果分辨率高或数据量大,则编码单元的最大尺寸可以较大,从而不仅提高编码效率,还精确地反映出图像的特征。因此,具有比视频数据330更高分辨率的视频数据310和视频数据320的编码单元的最大尺寸可以是64。
由于视频数据310的最大深度是2,因此,由于通过对最大编码单元划分两次,深度被加深到两层,因此视频数据310的编码单元315可包括长轴尺寸为64的最大编码单元以及长轴尺寸为32和16的编码单元。同时,由于视频数据330的最大深度是1,因此,由于通过对最大编码单元划分一次,深度被加深到一层,因此视频数据330的编码单元335可包括长轴尺寸为16的最大编码单元和长轴尺寸为8的编码单元。
由于视频数据320的最大深度为3,因此,由于通过对最大编码单元划分三次,深度被加深到3层,因此视频数据320的编码单元325可包括长轴尺寸为64的最大编码单元以及长轴尺寸为32、16和8的编码单元。随着深度加深,可精确地表现细节信息。图22是根据示例性实施例的基于编码单元的图像编码器400的框图。
图像编码器400执行设备100的编码单元确定器120的操作以对图像数据进行编码。换句话说,帧内预测器410在帧内模式下对当前帧405中的编码单元执行帧内预测,运动估计器420和运动补偿器425在帧间模式下通过使用当前帧405和参考帧495,对当前帧405中的编码单元执行帧间估计和运动补偿。
从帧内预测器410、运动估计器420和运动补偿器425输出的数据通过变换器430和量化器440被输出为量化的变换系数。量化的变换系数通过反量化器460和逆变换器470被恢复为空间域中的数据,恢复的空间域中的数据在通过去块单元480和环路滤波单元490进行后处理之后被输出为参考帧495。量化的变换系数可通过熵编码器450被输出为比特流455。
为了将图像编码器400应用在设备100中,图像编码器400的所有元件(即,帧内预测器410、运动估计器420、运动补偿器425、变换器430、量化器440、熵编码器450、反量化器460、逆变换器470、去块单元480和环路滤波单元490)在考虑每个最大编码单元的最大深度的同时,基于具有树结构的编码单元之中的每个编码单元来执行操作。
具体地,帧内预测器410、运动估计器420和运动补偿器425在考虑当前最大编码单元的最大尺寸和最大深度的同时,确定具有树结构的编码单元之中的每个编码单元的分区和预测模式,变换器430确定具有树结构的编码单元之中的每个编码单元中的变换单元的尺寸。
图23是根据示例性实施例的基于编码单元的图像解码器500的框图。
解析器510从比特流505中解析将被解码的已编码的图像数据以及解码所需的关于编码的信息。已编码的图像数据通过熵解码器520和反量化器530被输出为反量化的数据,反量化的数据通过逆变换器540被恢复为空间域中的图像数据。
帧内预测器550针对空间域中的图像数据,在帧内模式下对编码单元执行帧内预测,运动补偿器560通过使用参考帧585在帧间模式下对编码单元执行运动补偿。
经过帧内预测器550和运动补偿器560的空间域中的图像数据可在通过去块单元570和环路滤波单元580进行后处理之后被输出为恢复的帧595。此外,通过去块单元570和环路滤波单元580进行后处理的图像数据可被输出为参考帧585。
为了在设备200的图像数据解码器230中对图像数据进行解码,图像解码器500可执行在解析器510之后执行的操作。
为了将图像解码器500应用在设备200中,图像解码器500的所有元件(即,解析器510、熵解码器520、反量化器530、逆变换器540、帧内预测器550、运动补偿器560、去块单元570和环路滤波单元580)针对每个最大编码单元基于具有树结构的编码单元执行操作。
具体地,帧内预测器550和运动补偿器560基于具有树结构的编码单元中的每一个的分区和预测模式执行操作,逆变换器540基于每个编码单元的变换单元的尺寸执行操作。
图24是示出根据示例性实施例的根据深度的更深编码单元以及分区的示图。
设备100和设备200使用分层编码单元以考虑图像的特征。可根据图像的特征自适应地确定编码单元的最大高度、最大宽度和最大深度,或可由用户不同地设置编码单元的最大高度、最大宽度和最大深度。可根据编码单元的预定最大尺寸来确定根据深度的更深编码单元的尺寸。
在根据示例性实施例的编码单元的分层结构600中,编码单元的最大高度和最大宽度均为64,并且最大深度为3。在这种情况下,最大深度表示从最大编码单元到最小编码单元的划分总次数。由于深度沿分层结构600的纵轴加深,因此更深编码单元的高度和宽度均被划分。此外,沿分层结构600的横轴示出作为用于每个更深编码单元的预测编码的基础的预测单元和分区。
换句话说,编码单元610是分层结构600中的最大编码单元,其中,深度为0,尺寸(即,高度乘宽度)为64×64。深度沿纵轴加深,存在尺寸为32×32且深度为1的编码单元620、尺寸为16×16且深度为2的编码单元630、尺寸为8×8且深度为3的编码单元640。尺寸为8×8且深度为3的编码单元640是最小编码单元。
编码单元的预测单元和分区根据深度沿横轴排列。换句话说,如果尺寸为64×64且深度为0的编码单元610是预测单元,则预测单元可被划分为包括在编码单元610中的分区,即,尺寸为64×64的分区610、尺寸为64×32的分区612、尺寸为32×64的分区614或尺寸为32×32的分区616。
类似地,尺寸为32×32且深度为1的编码单元620的预测单元可被划分为包括在编码单元620中的分区,即,尺寸为32×32的分区620、尺寸为32×16的分区622、尺寸为16×32的分区624和尺寸为16×16的分区626。
类似地,尺寸为16×16且深度为2的编码单元630的预测单元可被划分为包括在编码单元630中的分区,即,包括在编码单元630中的尺寸为16×16的分区、尺寸为16×8的分区632、尺寸为8×16的分区634和尺寸为8×8的分区636。
类似地,尺寸为8×8且深度为3的编码单元640的预测单元可被划分为包括在编码单元640中的分区,即,包括在编码单元640中的尺寸为8×8的分区、尺寸为8×4的分区642、尺寸为4×8的分区644和尺寸为4×4的分区646。
为了确定构成最大编码单元610的编码单元的至少一个编码深度,设备100的编码单元确定器120针对包括在最大编码单元610中的与每个深度相应的编码单元执行编码。
随着深度加深,包括相同范围中和相同尺寸的数据的根据深度的更深编码单元的数量增加。例如,需要四个与深度2相应的编码单元来覆盖包括在一个与深度1相应的编码单元中的数据。因此,为了比较相同数据的根据深度的编码结果,与深度1相应的编码单元和四个与深度2相应的编码单元均被编码。
为了针对深度之中的当前深度执行编码,可通过沿分层结构600的横轴,针对与当前深度相应的编码单元中的每个预测单元执行编码,来针对当前深度选择最小编码误差。可选择地,可通过随着深度沿分层结构600的纵轴加深针对每个深度执行编码来比较根据深度的最小编码误差,从而搜索最小编码误差。编码单元610中具有最小编码误差的深度和分区可被选为编码单元610的编码深度和分区类型。
图25是用于解释根据示例性实施例的编码单元710和变换单元720之间的关系的示图。
设备100或设备200针对每个最大编码单元,根据具有小于或等于最大编码单元的尺寸的编码单元来对图像进行编码或解码。可基于不大于相应编码单元的数据单元来选择编码期间用于变换的变换单元的尺寸。
例如,在设备100或设备200中,如果编码单元710的尺寸是64×64,则可通过使用尺寸为32×32的变换单元720来执行变换。
此外,可通过对小于64×64的尺寸为32×32、16×16、8×8和4×4的变换单元中的每一个执行变换,来对尺寸为64×64的编码单元710的数据进行编码,然后可选择具有最小编码误差的变换单元。
图26是用于解释根据示例性实施例的与编码深度相应的编码单元的编码信息的示图。
设备100的输出单元130可对与编码深度相应的每个编码单元的关于分区类型的信息800、关于预测模式的信息810和关于变换单元的尺寸的信息820进行编码和发送,作为关于编码模式的信息。
信息800指示关于通过对当前编码单元的预测单元进行划分而获得的分区的形状的信息,其中,所述分区是用于对当前编码单元进行预测编码的数据单元。例如,尺寸为2n×2n的当前编码单元cu_0可被划分为尺寸为2n×2n的分区802、尺寸为2n×n的分区804、尺寸为n×2n的分区806和尺寸为n×n的分区808中的任意一个。这里,关于分区类型的信息800被设置为指示尺寸为2n×n的分区804、尺寸为n×2n的分区806和尺寸为n×n的分区808之一。
信息810指示每个分区的预测模式。例如,信息810可指示对由信息800指示的分区执行的预测编码的模式,即,帧内模式812、帧间模式814或跳过模式816。
信息820指示当对当前编码单元执行变换时所基于的变换单元。例如,变换单元可以是第一帧内变换单元822、第二帧内变换单元824、第一帧间变换单元826或第二帧内变换单元828。
设备200的图像数据和编码信息提取器220可提取和使用信息800、810和820以进行解码。
尽管在图26中没有示出,但关于编码模式的信息可包括合并相关信息,可基于关于预测模式(诸如帧间模式、帧内模式、跳过模式或直接模式)的信息810来设置合并相关信息。例如,如果关于预测模式的信息810是关于跳过模式的信息,则合并相关信息可被选择性地设置。仅当关于预测模式的信息810是关于帧间模式而不是跳过模式和直接模式的信息时,合并相关信息可被设置。
图27是根据示例性实施例的根据深度的更深编码单元的示图。
划分信息可被用于指示深度的改变。划分信息指示当前深度的编码单元是否被划分为更低深度的编码单元。
用于对深度为0且尺寸为2n_0×2n_0的编码单元900进行预测编码的预测单元910可包括以下分区类型的分区:尺寸为2n_0×2n_0的分区类型912、尺寸为2n_0×n_0的分区类型914、尺寸为n_0×2n_0的分区类型916、和尺寸为n_0×n_0的分区类型918。图9仅示出通过对预测单元910进行对称划分而获得的分区类型912至918,但分区类型不限于此,预测单元910的分区可包括不对称分区、具有预定形状的分区和具有几何形状的分区。
根据分区类型,对一个尺寸为2n_0×2n_0的分区、两个尺寸为2n_0×n_0的分区、两个尺寸为n_0×2n_0的分区和四个尺寸为n_0×n_0的分区重复执行预测编码。可对尺寸为2n_0×2n_0、n_0×2n_0、2n_0×n_0和n_0×n_0的分区执行帧内模式和帧间模式下的预测编码。仅对尺寸为2n_0×2n_0的分区执行跳过模式下的预测编码。
比较包括分区类型912至918中的预测编码的编码的误差,在分区类型中确定最小编码误差。如果在分区类型912至916之一中编码误差最小,则预测单元910可不被划分到更低深度。
如果在分区类型918中编码误差最小,则深度从0改变到1以在操作920对分区类型918进行划分,并对深度为1且尺寸为n_0×n_0的编码单元930重复执行编码,以搜索最小编码误差。
用于对深度为1且尺寸为2n_1×2n_1(=n_0×n_0)的编码单元930进行预测编码的预测单元940可包括以下分区类型的分区:尺寸为2n_1×2n_1的分区类型942、尺寸为2n_1×n_1的分区类型944、尺寸为n_1×2n_1的分区类型946和尺寸为n_1×n_1的分区类型948。
如果在分区类型948中编码误差最小,则深度从1改变到2以在操作950对分区类型948进行划分,并对深度为2且尺寸为n_2×n_2的编码单元960重复执行编码,以搜索最小编码误差。
当最大深度为d-1时,根据深度的划分操作可被执行,直到深度变为d-1时,并且划分信息可被编码,直到深度为0到d-2中的一个时。换句话说,当编码被执行,直到在操作970中与深度d-2相应的编码单元被划分之后深度为d-1时,用于对深度为d-1且尺寸为2n_(d-1)×2n_(d-1)的编码单元980进行预测编码的预测单元990可包括以下分区类型的分区:尺寸为2n_(d-1)×2n_(d-1)的分区类型992、尺寸为2n_(d-1)×n_(d-1)的分区类型994、尺寸为n_(d-1)×2n_(d-1)的分区类型996和尺寸为n_(d-1)×n_(d-1)的分区类型998。
可对分区类型992至998之中的一个尺寸为2n_(d-1)×2n_(d-1)的分区、两个尺寸为2n_(d-1)×n_(d-1)的分区、两个尺寸为n_(d-1)×2n_(d-1)的分区、四个尺寸为n_(d-1)×n_(d-1)的分区重复执行预测编码,以搜索具有最小编码误差的分区类型。
即使在分区类型998具有最小编码误差时,由于最大深度为d-1,因此深度为d-1的编码单元cu_(d-1)不再被划分到更低深度,构成当前最大编码单元900的编码单元的编码深度被确定为d-1,并且编码单元900的分区类型可被确定为n_(d-1)×n_(d-1)。此外,由于最大深度为d-1,并且具有最低深度d-1的最小编码单元980不再被划分到更低深度,因此不设置用于编码单元980的划分信息。
数据单元999可以是针对当前最大编码单元的“最小单元”。最小单元可以是通过将最小编码单元980划分为4份而获得的矩形数据单元。通过重复执行编码,设备100可通过比较根据编码单元900的深度的编码误差来选择具有最小编码误差的深度,以确定编码深度,并将相应的分区类型和预测模式设置为编码深度的编码模式。
这样,在1至d的所有深度中比较根据深度的最小编码误差,具有最小编码误差的深度可被确定为编码深度。编码深度、预测单元的分区类型和预测模式可作为关于编码模式的信息而被编码和发送。此外,由于编码单元从深度0被划分到编码深度,因此仅编码深度的划分信息被设置为0,除了编码深度之外的深度的划分信息被设置为1。
设备200的图像数据和编码信息提取器220可提取并使用关于编码单元900的编码深度和预测单元的信息,以对分区912进行解码。设备200可通过使用根据深度的划分信息来将划分信息为0的深度确定为编码深度,并使用关于相应深度的编码模式的信息以进行解码。
图28至图30是用于解释根据示例性实施例的编码单元1010、预测单元1060和变换单元1070之间的关系的示图。
编码单元1010是最大编码单元中与由设备100确定的编码深度相应的、具有树结构的编码单元。预测单元1060是编码单元1010中的每一个的预测单元的分区,变换单元1070是编码单元1010中的每一个的变换单元。
当在编码单元1010中最大编码单元的深度是0时,编码单元1012和1054的深度是1,编码单元1014、1016、1018、1028、1050和1052的深度是2,编码单元1020、1022、1024、1026、1030、1032和1048的深度是3,编码单元1040、1042、1044和1046的深度是4。
在预测单元1060中,某些编码单元1014、1016、1022、1032、1048、1050、1052和1054被划分为用于预测编码的分区。换句话说,编码单元1014、1022、1050和1054中的分区类型具有2n×n的尺寸,编码单元1016、1048和1052中的分区类型具有n×2n的尺寸,编码单元1032的分区类型具有n×n的尺寸。编码单元1010的预测单元和分区小于或等于每个编码单元。
按照小于编码单元1052的数据单元对变换单元1070中的编码单元1052的图像数据执行变换或逆变换。此外,变换单元1070中的编码单元1014、1016、1022、1032、1048、1050和1052在尺寸和形状方面与预测单元1060中的编码单元1014、1016、1022、1032、1048、1050和1052不同。换句话说,设备100和设备200可对相同编码单元中的数据单元分别执行帧内预测、运动估计、运动补偿、变换和逆变换。
因此,对最大编码单元的每个区域中具有分层结构的编码单元中的每一个递归地执行编码,以确定最佳编码单元,从而可获得具有递归树结构的编码单元。编码信息可包括关于编码单元的划分信息、关于分区类型的信息、关于预测模式的信息和关于变换单元的尺寸的信息。表2示出可由设备100和设备200设置的编码信息。
表2
[表2]
设备100的输出单元130可输出关于具有树结构的编码单元的编码信息,设备200的图像数据和编码信息提取器220可从接收的比特流提取关于具有树结构的编码单元的编码信息。
划分信息指示当前编码单元是否被划分为更低深度的编码单元。如果当前深度d的划分信息为0,则当前编码单元不再被划分到更低深度的深度是编码深度,因此可针对编码深度定义关于分区类型、预测模式和变换单元的尺寸的信息。如果当前编码单元根据划分信息被进一步划分,则对划分的四个更低深度的编码单元独立地执行编码。
预测模式可以是帧内模式、帧间模式和跳过模式中的一个。可在所有分区类型中定义帧内模式和帧间模式,仅在尺寸为2n×2n的分区类型中定义跳过模式。
关于分区类型的信息可指示通过对预测单元的高度或宽度进行对称划分而获得的尺寸为2n×2n、2n×n、n×2n和n×n的对称分区类型,以及通过对预测单元的高度或宽度进行不对称划分而获得的尺寸为2n×nu、2n×nd、nl×2n和nr×2n的不对称分区类型。可通过按照1:3和3:1对预测单元的高度进行划分来分别获得尺寸为2n×nu和2n×nd的不对称分区类型,并可通过按照1:3和3:1对预测单元的宽度进行划分来分别获得尺寸为nl×2n和nr×2n的不对称分区类型。
变换单元的尺寸可被设置为帧内模式下的两种类型和帧间模式下的两种类型。换句话说,如果变换单元的划分信息是0,则变换单元的尺寸可以是2n×2n,这是当前编码单元的尺寸。如果变换单元的划分信息是1,则可通过对当前编码单元进行划分来获得变换单元。此外,如果尺寸为2n×2n的当前编码单元的分区类型是对称分区类型,则变换单元的尺寸可以是n×n,如果当前编码单元的分区类型是不对称分区类型,则变换单元的尺寸可以是n/2×n/2。
关于具有树结构的编码单元的编码信息可包括与编码深度相应的编码单元、预测单元和最小单元中的至少一个。与编码深度相应的编码单元可包括:包含相同编码信息的预测单元和最小单元中的至少一个。
因此,通过比较邻近数据单元的编码信息来确定邻近数据单元是否包括在与编码深度相应的相同编码单元中。此外,通过使用数据单元的编码信息来确定与编码深度相应的相应编码单元,从而可确定最大编码单元中的编码深度的分布。
因此,如果基于邻近数据单元的编码信息来预测当前编码单元,则可直接参照和使用与当前编码单元邻近的更深编码单元中的数据单元的编码信息。
可选择地,如果基于邻近数据单元的编码信息来预测当前编码单元,则使用数据单元的编码信息来搜索与当前编码单元邻近的数据单元,可参照搜索到的邻近编码单元来预测当前编码单元。
图31是用于根据表2的编码模式信息解释编码单元、预测单元或分区、和变换单元之间的关系的示图。
最大编码单元1300包括编码深度的编码单元1302、1304、1306、1312、1314、1316和1318。这里,由于编码单元1318是编码深度的编码单元,因此划分信息可被设置为0。关于尺寸为2n×2n的编码单元1318的分区类型的信息可被设置为以下分区类型之一:尺寸为2n×2n的分区类型1322、尺寸为2n×n的分区类型1324、尺寸为n×2n的分区类型1326、尺寸为n×n的分区类型1328、尺寸为2n×nu的分区类型1332、尺寸为2n×nd的分区类型1334、尺寸为nl×2n的分区类型1336和尺寸为nr×2n的分区类型1338。
变换单元的划分信息(tu尺寸标记)是变换索引,因此与变换索引相应的变换单元的尺寸可根据编码单元的预测单元类型或分区类型而改变。
例如,当分区类型被设置为对称(即,分区类型1322、1324、1326或1328)时,如果tu尺寸标记为0,则设置尺寸为2n×2n的变换单元1342,如果tu尺寸标记为1,则设置尺寸为n×n的变换单元1344。
另一方面,当分区类型被设置为不对称(即,分区类型1332、1334、1336或1338)时,如果tu尺寸标记为0,则设置尺寸为2n×2n的变换单元1352,如果tu尺寸标记为1,则设置尺寸为n/2×n/2的变换单元1354。
参照图18,tu尺寸标记是具有值0或1的标记,但tu尺寸标记不限于1比特,在tu尺寸标记从0增加的同时,变换单元可被分层划分以具有树结构。tu尺寸标记可被用作变换索引的示例。
在这种情况下,可通过一起使用变换单元的tu尺寸标记以及变换单元的最大尺寸和最小尺寸来表示实际上已使用的变换单元的尺寸。设备100可对最大变换单元尺寸信息、最小变换单元尺寸信息和最大tu尺寸标记进行编码。对最大变换单元尺寸信息、最小变换单元尺寸信息和最大tu尺寸标记进行编码的结果可被插入sps。设备200可通过使用最大变换单元尺寸信息、最小变换单元尺寸信息和最大tu尺寸标记来对视频进行解码。
例如,如果当前编码单元的尺寸是64×64并且最大变换单元尺寸是32×32,则当tu尺寸标记为0时,变换单元的尺寸可以是32×32,当tu尺寸标记为1时,变换单元的尺寸可以是16×16,当tu尺寸标记为2时,变换单元的尺寸可以是8×8。
作为另一示例,如果当前编码单元的尺寸是32×32并且最小变换单元尺寸是32×32,则当tu尺寸标记为0时,变换单元的尺寸可以是32×32。这里,由于变换单元的尺寸可能不能小于32×32,因此tu尺寸标记可能不能被设置为除了0以外的值。
作为另一示例,如果当前编码单元的尺寸是64×64并且最大tu尺寸标记为1,则tu尺寸标记可以是0或1。这里,tu尺寸标记可能不能被设置为除了0或1以外的值。
因此,如果定义在tu尺寸标记为0时最大tu尺寸标记为“maxtransformsizeindex”,最小变换单元尺寸为“mintransformsize”,并且变换单元尺寸为“roottusize”,则随后可通过等式(1)来定义可在当前编码单元中确定的当前最小变换单元尺寸“currmintusize”:
currmintusize=max(mintransformsize,roottusize/(2^maxtransformsizeindex))……(1)
与可在当前编码单元中确定的当前最小变换单元尺寸“currmintusize”相比,当tu尺寸标记为0时的变换单元尺寸“roottusize”可指示可在系统中选择的最大变换单元尺寸。在等式(1)中,“roottusize/(2^maxtransformsizeindex)”表示当tu尺寸标记为0时,变换单元尺寸“roottusize”被划分了与最大tu尺寸标记相应的次数时的变换单元尺寸,“mintransformsize”表示最小变换尺寸。因此,“roottusize/(2^maxtransformsizeindex)”和“mintransformsize”中较小的值可以是可在当前编码单元中确定的当前最小变换单元尺寸“currmintusize”。
最大变换单元尺寸roottusize可根据预测模式的类型而改变。
例如,如果当前预测模式是帧间模式,则随后可通过使用以下的等式(2)来确定“roottusize”。在等式(2)中,“maxtransformsize”表示最大变换单元尺寸,“pusize”表示当前预测单元尺寸。
roottusize=min(maxtransformsize,pusize)……(2)
也就是说,如果当前预测模式是帧间模式,则当tu尺寸标记为0时的变换单元尺寸“roottusize”可以是最大变换单元尺寸和当前预测单元尺寸中较小的值。
如果当前分区单元的预测模式是帧内模式,则可通过使用以下的等式(3)来确定“roottusize”。在等式(3)中,“partitionsize”表示当前分区单元的尺寸。
roottusize=min(maxtransformsize,partitionsize)……(3)
也就是说,如果当前预测模式是帧内模式,则当tu尺寸标记为0时的变换单元尺寸“roottusize”可以是最大变换单元尺寸和当前分区单元的尺寸中较小的值。
然而,根据分区单元中的预测模式的类型而改变的当前最大变换单元尺寸“roottusize”仅是示例,并且不限于此。
图32是示出根据示例性实施例的基于具有树结构的编码单元,通过使用数据单元合并来对视频进行编码的方法的流程图。
在操作1210,视频的当前画面被划分为最大编码单元。在操作1220,针对当前画面的每个最大编码单元,图像数据可被编码为根据深度的编码单元,可根据编码深度选择并确定产生最小编码误差的深度,并且可确定由被确定为编码深度的深度的编码单元组成的具有树结构的编码单元。根据确定的编码单元的根据已编码的最大编码单元的图像数据可被输出。
在操作1230,可确定是否对具有树结构的编码单元的预测单元或分区执行邻近数据单元之间的数据单元合并。可在合并的数据单元之间共享预测相关信息。即使在具有树结构的编码单元的当前预测单元或当前分区的预测模式是跳过模式或直接模式的情况下,也可分析用于与邻近数据单元共享预测相关信息的数据单元合并的必要性。
在操作1230,关于具有树结构的编码单元的编码模式的信息可被编码为包括合并相关信息,其中,所述合并相关信息包括合并信息和合并索引信息。基于具有树结构的编码单元编码的关于编码模式的信息和最大编码单元的图像数据可在比特流中被输出。
图33是示出根据示例性实施例的基于具有树结构的编码单元,通过使用数据单元合并来对视频进行解码的方法的流程图。
在操作1310,接收并解析已编码的视频的比特流。在操作1320,根据最大编码单元从解析的比特流提取针对根据具有树结构的编码单元的每个编码单元而编码的当前画面图像数据的已编码的图像数据,并提取关于编码深度和编码模式的信息。可从关于编码深度和编码模式的信息提取合并相关信息。可基于预测模式信息确定提取并读取合并相关信息的可能性。例如,可基于具有树结构的编码单元的当前预测单元或当前分区的跳过模式信息或直接信息来提取合并相关信息。此外,合并信息和合并索引信息可被提取为合并相关信息。
在操作1330,关于具有树结构的编码单元的预测单元的分区类型、预测模式和变换单元的信息可基于关于最大编码单元的编码深度和编码模式的信息而被读取,并且可被用于对最大编码单元的图像数据进行解码。
此外,可从与当前数据单元邻近的多个邻近数据单元之中搜索将被合并的对象,并且可基于合并相关信息来确定数据单元合并。可通过共享或参照合并的邻近预测单元或分区的预测相关信息推断当前预测单元或当前分区的预测相关信息,来执行当前预测单元或当前分区的运动估计和补偿。通过根据具有树结构的编码单元的包括运动估计和补偿的解码,可恢复最大编码单元的图像数据并可恢复当前画面。
在设备100和设备200中,由于可根据树结构对具有各种预测模式、各种尺寸和形状的预测模式和分区执行用于共享相互的预测相关信息的数据单元合并的可能性被检查,因此在具有各种位置的邻近数据单元之间执行合并,从而使得可共享预测相关信息。因此,由于可通过使用更宽范围的外围信息来去除冗余数据,因此可提高对图像数据进行编码的效率。
此外,由于考虑合并的可能性和各种预测模式之间的紧密关系来对预测模式信息和合并相关信息进行分层和连续的编码和解码,因此可提高对信息进行编码的效率。
一个或多个示例性实施例可被编写为计算机程序并可在使用计算机可读记录介质运行所述程序的通用数字计算机上实现。计算机可读记录介质的示例包括磁存储介质(例如,rom、软盘、硬盘等)和光学记录介质(例如,cd-rom或dvd)。
虽然以上已具体示出并描述了示例性实施例,但是本领域的普通技术人员将理解,在不脱离由所附权利要求限定的本发明构思的精神和范围的情况下,可在此进行形式和细节上的各种改变。示例性实施例应被视为仅是说明的意义,而不是为了限制的目的。因此,本发明构思的范围不是由示例性实施例的详细描述来限定,而是由所附权利要求来限定,并且在所述范围内的所有差别将被解释为包括在本发明中。
- 还没有人留言评论。精彩留言会获得点赞!