一种多数据来源的数据融合、智能搜索的处理方法与流程
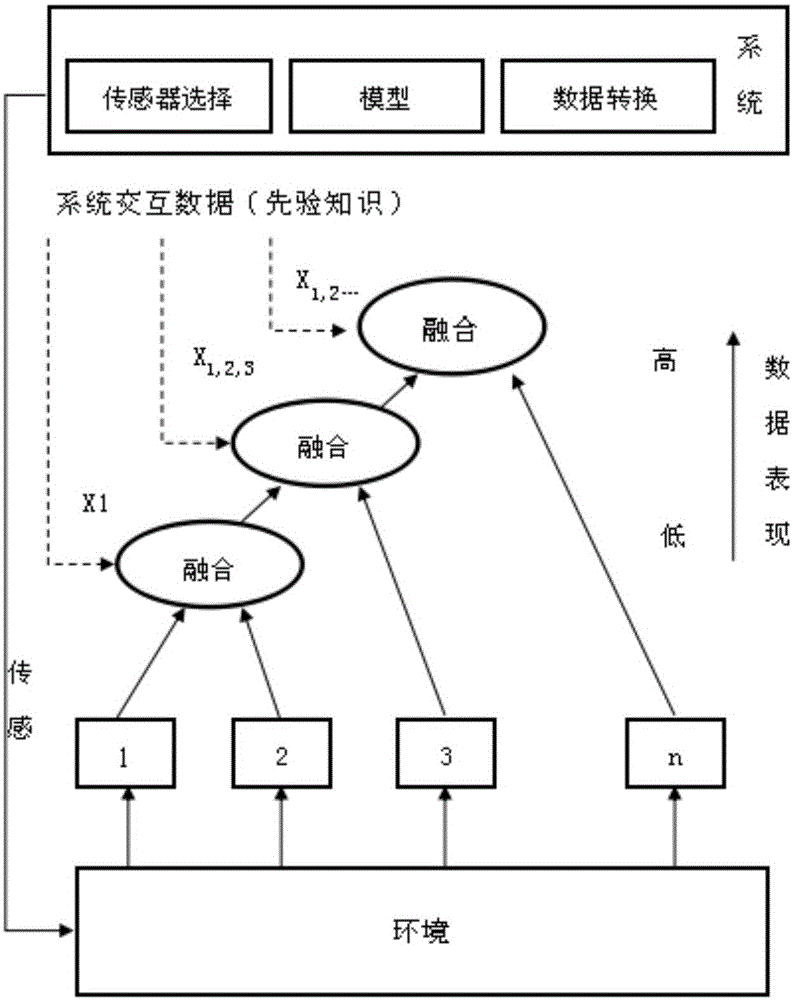
本发明涉及传感器数据处理
技术领域:
,具体来说是一种多数据来源的数据融合、智能搜索的处理方法及应用。[
背景技术:
:]多传感数据融合技术的雏形出现在第二次世界大战末期。在20世纪70年代美国国防部资助的声纳信号理解系统中,正式提出数据融合的概念。多传感数据融合可以将系统中各种类型传感器所提供的同时刻或不同时刻、同形式或不同形式的测量数据进行综合处理和优化,得到各种数据之间内在的联系和规律,去除无用和错误的成分,保留正确和有用的成分,把多个传感器在时间和空间上的互补或冗余数据依据某种准则进行组合,最终实现数据的优化,使之能够准确地反映环境特征,从而使系统获得更优越的性能。多传感器信息融合技术的基本原理就像人的大脑综合处理信息的过程一样,将各种传感器进行多层次、多空间的信息互补和优化组合处理,最终产生对观测环境的一致性解释。在这个过程中要充分地利用多源数据进行合理支配与使用,而信息融合的最终目标则是基于各传感器获得的分离观测信息,通过对信息多级别、多方面组合导出更多有用信息。这不仅是利用了多个传感器相互协同操作的优势,而且也综合处理了其它信息源的数据来提高整个传感器系统的智能化。在无线传感器网络中,釆集的数据一方面由于单个传感器节点在短时间内多次釆集到的数据具有极高的相似度,另一方面,邻近传感器节点在相近时刻采集到的数据同样会具有很高的相似度,所有传感器节点采集到的数据全部传输给汇聚节点,不但没有实际意义,反而会过多消耗传感器节点的能量,影响网络寿命,由于节点资源在处理能力、能量、通信带宽以及存储容量等方面十分有限,传感器节点在收到受到干扰情况下,采集到的数据会产生错误,收集数据时采用各个节点单独传送到汇节点显然不合适。目前,多传感器数据融合还没有一种通用的方法。[技术实现要素:]本发明是根据现有技术数据融合的上述问题,将信息在本地或传输过程中进行处理,通过融合多传感器的数据,提高数据质量和精度,减少冗余,提供一种多数据来源的数据融合、智能搜索的处理方法及应用。为了实现上述目的,设计一种多数据来源的数据融合、智能搜索的处理方法,所述的传感器布局采用平面布局,传感器处于同一个平面上组成传感网,数据融合包含多个同种传感器的数据融合和不同种传感器的数据融合,传感器的数据特征及数据类型采用轮询的方式进行数据采集,采集节点在进行采集时要对数据进行冗余处理,采取基于分批估计的自适应算法,所述的算法如下:Mij=|Xi-Xj|i,j=1,2,…n(1)由Mij的表达形式可知,Mij越小则表明相互信任程度就越大,因此利用传感器中现有数据隐含信息相对距离和模糊集合理论的基础上定义信任度函数Rij,则Rij定义为:其中Max{Mij}表示数据间相对距离的最大值,数据间相对距离表示数据间的信任度,成正比关系,由式(2)可知,数据间的相对距离越小,则数据间的相互信任度就越大;当数据间的相对距离最大,信任度函数的值为零,可认为两数据己经不再相互信任;而数据对自身的相对距离为零,则数据对自身的信任度为1,由于Rij分布在[0,Max{Rij}]之间,信任度函数量化定义与实际工作环境的真实性相一致,融合的数值结果更加精确和稳定,由此建立数据融合信任度矩阵K,信任度矩阵K的数据成员Rij表示两数据间的相互信任度,单个距离差数据成员值不能代表所有数据总体信任程度,每个距离差数据在K矩阵全部成员数据中可视为是权系数所有数据信息量之和与最优融合估计的信息量之和相等,即而是全部成员数据Ri1,Ri2,…Rin总和,根据概率源合并定义数组注意数组值都非负,可得等式(4):等效为矩阵表达方式如下:W=KV(5)其中V=[V1,V2,…Vn]T,信任度矩阵K是所有成员值都大于或等于0,K的特征值λ>>0,通过λV=KV得特征向量V=[V1,V2,…Vn]T,则得n个采集数据点融合计算公式:上式T值就是同意区域不在同一簇内簇头节点在协调器的自适应加权估算结果。通过对监测同一对象的多个节点采集的数据进行综合处理提高所获得信息的准确性和精确度是有效手段之一,由于监测同一区域的邻近节点,获得的信息差异小,如果个别节点采集了误差比较大的或错误的信息,在本地处理中通过简单的算法排除,通过数据融合减少传输数据、降低网络拥塞、减少传输延迟、减少数据分组个数、减少冲突碰撞现象、提高无线信道的利用率。传感器数据需利用分布图法剔除疏失误差,首先对N个监测量结果从小到大进行排序,得到测量序列:X1,X2,X3……XN定义中值:上四分位数Fμ为区间[XM,XN]的中位数,下四分位数Fl为区间[Xl,XM]的中位数,四分位离散度为:δF=Fμ-Fl认定与中位数的距离大于βδF的数据为奇异数据,即无效数据的判断区间为[ρ1,ρ2]式中的β为常数,其大小取决于系统的测量精度,与实际情况有关,需现场实验测定、修正。由数量众多的传感器节点组成的传感网中,每个节点的可靠性和监测范围是有限的,在部署时需要加大传感器节点的密度来增强网络的监测信息的准确性和鲁棒性,根据监测任务的不同,有时需要部署互相交叠的网络,这种情况下会产生监测区域的一定程度的冗余信息,把这些节点的冗余信息报告的数据全部发送给汇聚节点会消耗网络更多的能量,在汇聚节点会接收大量无用信息,为降低网络能耗损失和冗余数据传输,在节点聚集数据时、节点转发数据前、应利用节点对数据进行异常去除、去冗、融合操作,在满足应用需求的前提下尽量减小传输量,降低能耗。传感器节点需采取分批估计算法,将删除了疏失误差之后的数据分成两个组,按照空间位置相邻传感器不在一组的原则进行分组,对两组测量数据的平均值釆用分批估算法对组内每个结点的测量数据进行处理,每个结点在某一时刻测得多组一致性测量数据,估计出接近真实值的融合值T+,得到准确的测量结果,消除测量过程中的不确定性,设第一组一致性测量数据为:设第二组一致性测量数据为:两组测量数据的算术平均值分别为:相应的标准误差分别为在此之前没有任何有关测量结果的方差则根据分批估计理论,得到分批估计后的融合值得方差为:式中,H为测量方程的系数矩阵,且R为测量噪声的协方差,且由分批估计到处的数据融和值T+为:将上面几个式子整理得:上式即为基于多传感器算术平均值与分批估计的数据融合方法得到的估计值。所述的传感器包括土壤PH值传感器、土壤电导率传感器、土壤温度传感器、土壤湿度传感器、环境光照度传感器、二氧化碳浓度传感器、大气温湿度传感器、风向风速传感器、大气辐射度传感器、雨量传感器及地表温度传感器。所述的处理方法应用于大棚环境监测及农田环境监测。本发明同现有技术相比,其优点在于:本数据融合方法通过动态采集各传感器数据,延长系统对传感器数据的识别时间,提高了数据精度,增大数据的准确率,从而提高系统识别的可靠性;基于分批估计的自适应数据融合算法,适用于同类传感器较多、数据量较大、同种传感器布局在同一平面的场景,能实现种植环节种植小环境、农田气候监测多传感器等环境的数据融合;传感器数据利用分布图法剔除疏失误差,可减少数据分组个数、减少冲突碰撞现象、提高无线信道的利用率;传感器各节点采取分批估计算法,有效分散网络的数据聚合流向,减少传输的数据,从而降低网络拥塞、减少传输延迟,降低传感器节点的能耗,延长无线传感器网络的寿命。[附图说明]图1是本发明的数据融合层次图。[具体实施方式]下面结合附图对本发明作进一步说明,这种装置的结构和原理对本专业的人来说是非常清楚的。应当理解,此处所描述的具体实施例仅仅用以解释本发明,并不用于限定本发明。本发明是关于多传感器数据融合技术,在传感网中,一般数据采集和发送以固定的时间间隔进行,这些节点所发送的数据在语义上具有很多相关性。但由于节点资源在处理能力、能量、通信带宽以及存储容量等方面十分有限,传感器节点在收到受到干扰情况下,采集到的数据会产生错误,收集数据时采用各个节点单独传送到汇节点显然不合适。如果能将网络中具有语义相关性的数据合并成一条更有效的数据、将错误的信息删除掉,就能降低在网络中数据的传输量,避免浪费能量和通信带宽,提高数据聚集的效率,从而达到节约功耗的目的,延长网络寿命。本发明具体可应用在在农产品安全追溯系统中。农产品质量安全追溯管理系统是追踪农产品进入市场各个阶段质量的整体系统,有助于农产品质量安全控制以及在发生安全问题查找源头和召回问题产品。在农产品种植过程监测中,主要包括种植小环境(温室内部或具体地块范围内)监测,农田气候环境监测。种植小环境监测,主要有土壤PH值、土壤电导率、土壤温度、土壤湿度、环境光照度、二氧化碳浓度、大气温湿度;农田环境监测,主要有大气温湿度、风向风速、大气辐射度、雨量及地表温度等。在农田或大棚内安装有土壤PH值、土壤电导率、土壤温度、土壤湿度、环境光照度、二氧化碳浓度、大气温湿度等传感器,这些传感器实时采集各项指标数据,并通过wifi或4G信号,将采集数据传输到农产品安全追溯系统平台,平台获取并接收存储数据。平台基于采集数据进行分析,实时监控农产品的生长状况和对产品进行品质分析。本系统主要研究实时采集各传感器数据,并将各传感器数据格式化,然后对各传感器数据融合,传输到监控平台。由于传感网的固有特点、无线传输的数据易受干扰特性、传感网要部署的环境一般比较恶劣,导致传感器件失效概率加大,获得的信息不可靠性很高。信息的正确性仅利用少数几个分散的传感器节点的数据较难确保得到,因此通过对监测同一对象的多个节点采集的数据进行综合处理提高所获得信息的准确性和精确度是有效手段之一。另外由于监测同一区域的邻近节点,获得的信息差异很小,如果个别节点采集了误差比较大的或错误的信息,在本地处理中很容易通过简单的算法排除。通过数据融合减少传输数据、降低网络拥塞、减少传输延迟;通过数据融合可以减少数据分组个数、减少冲突碰撞现象、提高无线信道的利用率。不同的传感器相互接收、处理各自接收的数据,因此数据在发送到汇聚节点的各个阶段和时间段内进行融合,保证信息在尽可能大的范围内进行融合。由于传感网固有特点,不能保证网内节点的电源持续供给、高速处理能力、大存储容量和高速数据传输,导致网内节点采集数据后传送数据到汇聚节点效率很低,为提高传感网各节点效率、降低消耗,需要釆用网内融合机制处理。在传感网中数据融合作用表现在提高信息精度和准确性、降低网络节点能耗、有效分散网络的数据聚合流向三个方面。下面以种植环节种植小环境监控中的温度监测为例说明该算法的实现。实施例11)利用分布图法剔除疏失误差首先对N个温度监测量结果从小到大进行排序,得到测量序列:X1,X2,X3……XN定义中值:上四分位数Fμ为区间[XM,XN]的中位数,下四分位数Fl为区间[Xl,XM]的中位数,四分位离散度为:δF=Fμ-Fl认定与中位数的距离大于βδF的数据为奇异数据,即无效数据的判断区间为[ρ1,ρ2],式中的β为常数,其大小取决于系统的测量精度,与实际情况有关,需现场实验测定、修正。(2)将删除了疏失误差之后的数据分成两个组,按照空间位置相邻传感器不在一组的原则进行分组,对两组测量数据的平均值釆用分批估算法对组内每个结点的测量数据进行处理。每个结点在某一时刻测得多组一致性测量数据,估计出接近真实值的融合值T+,得到准确的测量结果,消除测量过程中的不确定性。设第一组一致性测量数据为:设第二组一致性测量数据为:两组测量数据的算术平均值分别为:相应的标准误差分别为在此之前没有任何有关测量结果的方差则根据分批估计理论,得到分批估计后的融合值得方差为:式中,H为测量方程的系数矩阵,且R为测量噪声的协方差,且由分批估计到处的数据融和值T+为:将上面几个式子整理得:上式即为基于多传感器算术平均值与分批估计的数据融合方法得到的估计值。(3)由于各传感器的精度差异,每个传感器的可信度不能完全一致,为获得更优的融合的结果,可自适应地寻找各传感器所得到的测量值对应的权数,即自适应加权融合算法。该算法中各传感器节点都有各自的加权因子,寻找适用于各节点的融合所需的权数成为自适应加权融合的首要工作。实际测量采集数据会遇到实际测量数据微偏离正态分布;少数分布的异常数值无法被清除,误用为有效数据两个问题。釆用自适应加权估算法对同一监测区域不在同一组内的簇头节点的采集结点数据在协调器进行处理,估计出接近测量真实值的融合值T,从而得到测量值的准确结果,消除测量过程因为簇头节点失效或其他外界因数导致的不确定性。Mij=|Xi-Xj|i,j=1,2,…n由Mij的表达形式可知,Mij越小则表明相互信任程度就越大,因此利用传感器中现有数据隐含信息相对距离和模糊集合理论的基础上定义信任度函数Rij,则Rij定义为:其中Max{Mij}表示数据间相对距离的最大值,数据间相对距离表示数据间的信任度,成正比关系,由上式可知,数据间的相对距离越小,则数据间的相互信任度就越大;当数据间的相对距离最大,信任度函数的值为零,可认为两数据己经不再相互信任;而数据对自身的相对距离为零,则数据对自身的信任度为1,由于Rij分布在[0,Max{Rij}]之间,信任度函数量化定义与实际工作环境的真实性相一致,融合的数值结果更加精确和稳定,由此建立数据融合信任度矩阵K,信任度矩阵K的数据成员Rij表示两数据间的相互信任度,单个距离差数据成员值不能代表所有数据总体信任程度,每个距离差数据在K矩阵全部成员数据中可视为是权系数所有数据信息量之和与最优融合估计的信息量之和相等,即而是全部成员数据Ri1,Ri2,…Rin总和,根据概率源合并定义数组注意数组值都非负,可得如下等式:等效为矩阵表达方式如下:W=KV其中V=[V1,V2,…Vn]T,信任度矩阵K是所有成员值都大于或等于0,K的特征值λ>>0,通过λV=KV得特征向量V=[V1,V2,…Vn]T,则得n个采集数据点融合计算公式:上式T值就是同意区域不在同一簇内簇头节点在协调器的自适应加权估算结果。(4)为测试该算法的有效性,于2014年3月在崇明某种植基地对空气温度数据进行了采集,利用该数据进行数据融合试验。将20个温湿度传感器分为4组,每组5个温度传感节点,节点间距从20米到0.5米不等,每个节点采集2组数据,数据单位为℃。采集数据如下表1所示:表1将这两组数据进行数据融合后,数据融合结果传送给网络协调器对节点群进行数据融合。对两组测量数据的算术平均值采用分批估计算法,估计出接近真实值的融和值T+。5个测量数据与实际温度15℃相比测量绝对误差为0.28℃。10个采集节点分两组,每组5个数据,分别计算2组量量数据的算术平均值及方差分别为:通过分批估算法得出10个测量数据的融和值是X=15.002℃,与实际温度真实值差0.002℃。由此邮件数据融合的测量结果比算术平均值测量结果更接近设计值,原因是分批估计数据融合方法在获得两组测量数据基础上对方差进行加权处理,方差与权数成正比关系。在此埃及节点进行数据融合的基础上进行不在同组内簇头节点融合处理实验。将不在同组内的4个簇头节点采集的数据融合值在组头网关进行第二次数据融合。每组4个数据,数据分为2组,如下表2所示:表2簇头节点1簇头节点2簇头节点3簇头节点4第一组15.00215.00315.00215.002第二组15.00415.00215.00315.001每组数据由公式Mij=|xi-xj|得到MAX{Mij}值,进而得到Rij值,建立数据间的支持度矩阵K,得出特征向量V后,通过计算得出该组测量数据值,最终得到融合结果T。当前第1页1 2 3
相关技术
网友询问留言
已有0条留言
- 还没有人留言评论。精彩留言会获得点赞!
1