基于蜂群算法的无线传感执行网络数据汇集方法与流程
本发明涉及无线传感执行网络技术领域,具体地,涉及一种面向节点协同的无线传感执行网络数据汇集方法。
背景技术:
无线传感执行网络(WSAN)由于其泛在性的特点,正逐渐被广泛应用于环境监测、智能家居、军事监控等领域。WSAN中由于执行器节点可移动性特点,监控数据收集的过程变得更具灵活性和扩展性,并且执行器节点的能量更加充足,可以固定充当数据传输簇头,避免网络频繁更换簇头所带来的能量消耗。但是,在WSAN中,传感器节点是静态的,距离执行器节点越近的传感器节点承载的数据转发任务越多,从而节点能量消耗越快,进一步使得网络由于节点能量空洞而过早死亡。近年来,国内外学者提出各种WSAN动态数据汇集算法,使得网络的节点能耗更加均衡,生命周期得到延长。在当前WSAN协同研究领域,如何延长WSAN的生命周期,提高网络MAC层资源利用率已成为设计无线传感执行网络数据汇集方法的重要目标。
技术实现要素:
本发明的目的在于,针对上述问题,提出一种面向传感器-执行器协同的传感执行网络节点数据汇集算法,以实现在节点在数据传输过程中避免出现网络能量空洞问题并进一步提高MAC层资源利用率。
为了实现上述目的,本发明采用的技术方案实现过程包括建立簇立分区模型,根据网络相关节点能耗情况决定执行器节点是否改变数据汇集驻留地点,同时引入诱引因子决定执行器节点移动方向,并利用人工蜂群算法(ABC)求出最佳驻留位置。最后根据节点负载量化参数值选出代理节点作为临时数据存储终端,并自适应调节网络中节点的数据发送速率。
所述基于蜂群算法的无线传感执行网络数据汇集方法包括以下步骤:
步骤一、评判节点是否移动;首先将网络模型簇内环形分区,计算节点度指标,节点度指标kj描述了一个节点的邻居节点的个数,其中当节点j的邻居节点与节点j的距离小于通信距离R时,该邻居节点为节点j的一个度;为了描述节点j与邻居节点的紧密程度和连边情况,进一步计算集聚系数cj:
其中ej表示节点j与其邻居节点之间可以相互形成三角形的节点个数;
根据第一簇区中的节点平均剩余能量状况来决定是否移动执行器节点根据感知数据包所携带的节点信息,计算出第一簇区中节点的平均能量EA和全网落中节点的剩余能量Ew;每隔一个周期T,执行器节点会决定是否进行移动;以X表示执行器节点当前的状态,X=1表示执行器正在执行任务,X=0表示执行器不是正在执行任务,为了避免执行节点正在执行的任务时不能改变运动状态的情况,按如下规则进行移动抉择:
a)周期开始,首先判断此时执行器状态X,若X=1则忽略此次执行器移动操作,否则进入下一步;
b)比较EA和EW,若EA小于EW,执行器节点则开始移动,否则不移动;
步骤二、当执行器节点决定移动后,进一步确定移动地点;
步骤2.1、首先确定移动区域,将节点和其邻节点看成一个节点单元,引入节点单元的诱引因子Bj作为执行器节点移动方向的决定因素,诱引因子由三个部分构成:节点单元的平均剩余能量Ej-cluster,节点单元的集聚系数cj,节点单元中的节点作为源节点的次数fj,表示如下:
Bj=αcj+βfj+θEj-cluster
其中,α,β,θ为权重系数,且α+β+θ=1;当一个移动周期结束后,执行器节点计算自己所在簇中每个节点单元的引诱因子,而后执行器节点选取引诱因子最大的节点单元作为移动目标区域;
步骤2.2、确定移动目标区域后,进一步确定最终执行器节点驻留位置;若执行器节点确定某节点A的节点单元作为目标区域,则最终的驻留位置要使得该节点单元中所有节点都在执行器的第一簇区范围内,并且传感器节点的发射总功率最小;
步骤三、找到执行器节点驻留位置后,执行器节点开始移动到目标位置,为了保证在执行器节点移动期间,感知节点的数据传输的连续性,选取执行器节点的第一簇区中的一个节点作为代理节点作为执行器节点移动期间的临时数据终端;为了减少代理节点在数据接收状态的能量消耗和数据队列长度,同时增加网络路由MAC层资源的利用率,使用节点数据汇集频率自适应方法,具体步骤如下:
步骤3.1、代理节点监测当前子层邻节点数据传输状态,若当前有节点在传输数据,则代理节点反馈一个数据发送速率控制信息,子层邻节点收到信息后将数据发送速率控制为:
其中ns为当前代理节点子层邻节点正在发送数据的节点数目,并进入步骤3.2;若没有节点在传输数据,则代理节点进入数据接收等待状态,并进入步骤3.4;
步骤3.2、第二层节点继续监测它的子层邻节点的数据传输状态,若存在数据传输节点,则发送数据速率控制信息,第二层节点的子层邻节点的数据发送速率由第二层节点的空余队列长度和当前发送数据的子层邻节点的数目以及自身的数据发送速率有关,即
[(Qi-1-qi-1)-(ni-1×Mi-1-1_send-Mi-1_send)×T]=0
其中T为传感器节点采样周期,依此策略,得出最后一层节点的数据发送速率;
步骤3.3、如果初始时一个节点的父层邻节点没有分配数据传输速率配额给它,而在周期T内它的子层邻节点需要向它传送监测数据,那么它所反馈的子层邻节点的数据发送速率为:
其中T1表示为周期T内该节点保持数据接收等待状态的时间;
步骤3.4、经过采样周期T后,由代理节点逐层分配节点数据发送速率配额,直至最后一层节点;
步骤3.5经过时间tm后,即执行器节点移动目标驻留位置后,以执行器节点为簇头,执行步骤一的环形分区操作。
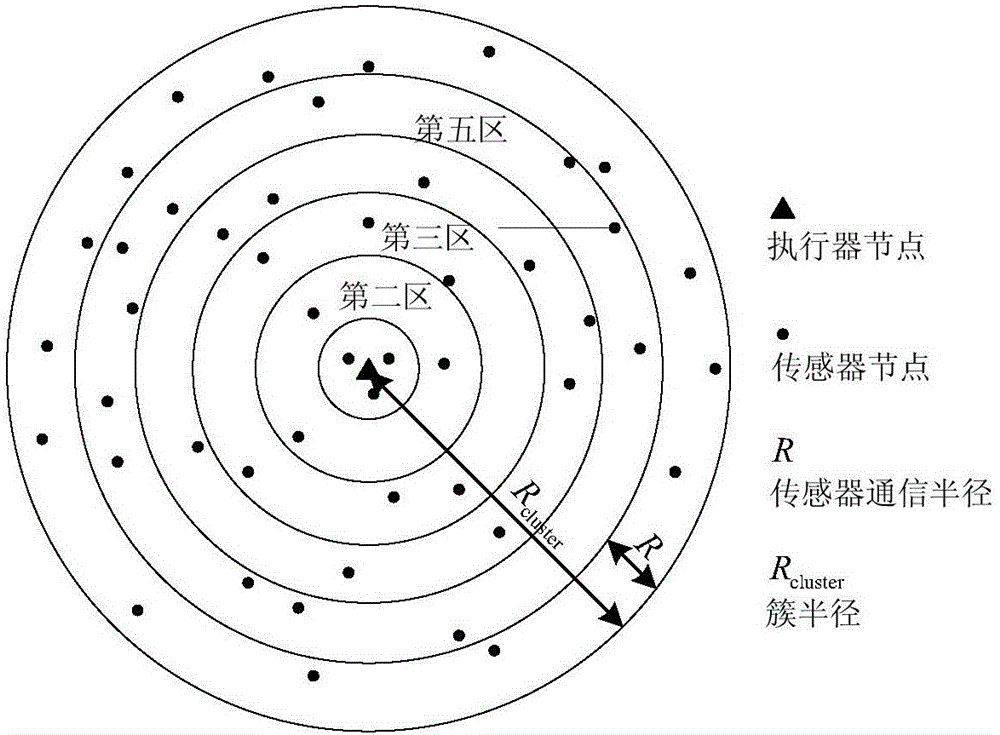
具体的,步骤一所述环形分区,是将某一执行器节点簇划分成n个环形区域,Rcluster为簇的最大半径,R为传感器节点最大通信距离;传感器节点分布在不同的区域内,离圆心最近的区域为第一区,次近的为第二区,直至划分到第n区结束;执行器节点在进行初始分簇的时候,分别以通信距离为的发射功率依次发送数据发射完毕后,各个传感器根据自身的所接收的最小数据,即为该传感器节点的所在的区数。
步骤一中,
平均能量
式中表示距离执行节点跳数为1的节点,即执行器节点的第一簇区节点,Eresi是节点i的剩余能量;
剩余能量
式中m为该簇中的传感器节点总数目。
具体的,步骤2.2中,以执行器节点的第一簇区中的传感器节点发射总功率作Pall为目标函数,建立关于执行器节点坐标(xa,ya)的优化模型:
min Pall=f[(xa,ya)],
其中是移动后执行器节点与传感器节点si的欧氏距离;是节点si的坐标,是约束条件;采用人工蜂群算法来寻找执行器节点最优驻留位置。
所述人工蜂群算法具体步骤如下:
步骤2.2.1、根据轮盘赌策略随机生成SN个可行解即蜜源位置(Xi,Yi)(i=1,2,…,SN),且采蜜蜂和观察蜂的数量都为SN,SN根据精度要求确定;
步骤2.2.2、计算每个蜜源的适应度函数其中(xa,ya)=(Xi,Yi);
步骤2.2.3、根据公式得到新的解(X′i,Y′i),其中(k=1,2,…,SN,k≠i),φi是区间[0,1]的随机数;并将新生成的解与原来的解(Xi,Yi)比较,采用贪婪策略保留较好的解;每个观察蜂根据概率pi选择蜜源,
步骤2.2.4、对于被选择的蜜源,观察蜂根据下式搜寻新的可能解;当所有的采蜜蜂和观察蜂都搜索完解空间后,如果一个蜜源的适应值在给定的步骤内没有被提高,则丢弃该蜜源,而与该蜜源相对应的采蜜蜂变成侦查蜂,侦查蜂通过公式搜索新的可能解,
其中r是区间[0,1]上的随机数,Xmin,Xmax,Ymin,Ymax分别是x,y维的上下界,并转至步骤2.2.2。
步骤三中,当执行器节点准备移动到驻留位置时,以通信半径R发送一个代理选取信号agent_selection,通信半径涵盖了执行器节点的第一簇区;收到信号的传感器节点回复一个agent_reply信号,信号中包含了传感器节点ID,已占用队列长度以及节点剩余能量;执行器节点收到回复信息后,尽可能选择剩余能量大且空闲队列长度长的节点作为代理节点,代理节点概率选择公式如下:
式中,ei是节点i的剩余能量;Ei是节点i的初始能量;qi是已占用队列长度;Qi是节点总队列长度。λe和λq分别是能量和队列的权重参数,且λe+λq=1;执行器节点选择好代理节点后,以的发射距离向簇内的传感器节点发送一个agent_selection_notification信息,信息中包含代理节点的ID号,代理时间tm,即执行器节点移动到驻留位置的时间,移动位置坐标;代理节点i接收到执行器节点的声明信息后,计算自身的数据接收速率:
其中是执行器节点的初始位置,v是执行器节点的移动速度。
与现有技术相比,本发明是一种面向传感器-执行器协同的传感执行网络节点数据汇集方法,有效的平衡了WSAN中节点的能量,提高了网络的稳定性,并提升了网络资源的综合利用效率。
附图说明
图1是本发明簇内n个区域均匀划分结构图。
图2是本发明寻找执行器节点驻留位置过程图。
图3是本发明节点数据汇集方法流程图。
具体实施方式
以下将结合附图对本发明的构思、具体结构及产生的技术效果作进一步说明,以充分了解本发明的目的、特征和效果。本发明是一种面向传感器-执行器协同的传感执行网络节点数据汇集方法,主要包括以下三个步骤:
1节点移动评断
1.1网络模型簇内分区
为了便于分析网络节点的交流特点,可以将某一执行器节点簇划分成n个环形区域,其中Rcluster为簇的最大半径,R为传感器节点最大通信距离。传感器节点分布在不同的区域内,如图1所示。离圆心最近的区域为第一区,次近的为第二区,直至划分到第n区结束。执行器节点在进行初始分簇的时候,分别以通信距离为的发射功率依次发送数据发射完毕后,各个传感器根据自身的所接收的最小数据,即为该传感器节点的所在的区数。
1.2节点度指标计算
同时为了分析网络节点之间的联系,引入节点度指标。节点度指标描述了一个节点的邻居节点的个数,表示为kj,其中当节点j的邻居节点与节点j的距离小于通信距离R时,该邻居节点为节点j的一个度。为了描述节点j与邻居节点的紧密程度和连边情况,进一步引入集聚系数cj,其表达式如下式所示:
其中ej表示节点j与其邻居节点之间可以相互形成三角形的节点个数。
1.3节点移动轮询
在WSAN中,可以根据第一簇区中的节点平均剩余能量状况来决定是否移动执行器节点根据感知数据包所携带的节点信息,计算出第一簇区中节点的平均能量EA和全网落中节点的剩余能量Ew。
式中表示距离执行节点跳数为1的节点,即执行器节点的第一簇区节点,Eresi是节点i的剩余能量。
式中m为该簇中的传感器节点总数目。每隔一个周期T,执行器节点会决定是否进行移动。以X表示执行器节点当前的状态,X=1表示执行器正在执行任务,X=0表示执行器不是正在执行任务,为了避免执行节点正在执行的任务时不能改变运动状态的情况,按如下规则进行移动抉择:
a)周期开始,首先判断此时执行器状态X,若X=1则忽略此次执行器移动操作,否则进入下一步;
b)比较EA和EW,若EA小于EW,执行器节点则开始移动,否则不移动。当执行器节点决定移动后,进一步确定移动地点成了一个关键问题。
2执行器节点的移动策略
2.1确定移动区域
在WSAN数据收集方法中,执行器节点的移动策略是一个关键问题。可以将节点和其邻节点看成一个节点单元。在这里引入节点单元的诱引因子Bj作为执行器节点移动方向的决定因素。诱引因子由三个部分构成:节点单元的平均剩余能量Ej-cluster,节点单元的集聚系数cj,节点单元中的节点作为源节点的次数fj。
节点单元的平均剩余能量越大,表明执行器节点在此位置进行数据汇集的时间越长,从而减少了频繁移动执行器节点所带的网络分簇能量消耗和时间消耗。节点单元的集聚系数表示当执行器节点移动到该单元附近时,执行器节点的第一簇区中的节点越多,从而直接与执行器节点直接进行单跳传输的节点越多,避免由于节点过少导致的能量快速衰竭进而出现路由中断的情况。节点单元中的节点作为源节点的次数表明在本次移动周期时间内,某个节点单元中节点作为源节点的次数越多,表明该节点单元成为监测热点区域的可能性越大。当执行器节点移动此区域时,由于监测数据传输距离减小,提高了该区域的监测实时性,并且减少了节点传输能耗。结合上述影响执行器节点移动方向的引诱因子可以表示如下:
Bj=αcj+βfj+θEj-cluster
其中,α,β,θ为权重系数,且α+β+θ=1。当一个移动周期结束后,执行器节点计算自己所在簇中每个节点单元的引诱因子,而后执行器节点选取引诱因子最大的节点单元作为移动目标区域。
2.2确定移动地点
确定移动目标区域后,进一步确定最终执行器停留位置成了关键问题。如图2所示,若执行器节点确定节点A的节点单元作为目标区域,则最终的驻留位置要使的节点单元中所有节点都在执行器的第一簇区范围内,并且传感器节点的发射总功率最小。
根据图2所示A为目标节点,B,C,D,E是A的邻居节点。根据无限传播模型可知,传感器节点的发射功率:
其中Pr节点是接收功率门限值,d是传输距离;L为天线长度;ht为发送天线高度;hr为接收天线高度;Gr为接收天线增益。其中,Pr,L,ht,hr,Gr是固定值。可知传感器节点的发送功率与传感器节点到执行器节点的距离有关。以执行器节点的第一簇区中的传感器节点发射总功率作Pall为目标函数,建立关于执行器节点坐标(xa,ya)的优化模型:
min Pall=f[(xa,ya)],
其中是移动后执行器节点与传感器节点si的欧氏距离;是节点si的坐标,
是约束条件,在这里采用人工蜂群算法来寻找执行器节点最优驻留位置。蜂群算法主要是模拟蜜蜂采蜜机理,三种蜜蜂根据各自的分工进行采蜜活动,通过对蜜源信息的交流与共享寻找到最好的蜜源。具有多角色分工机制,协同工作机制,鲁棒性强的优点等优点。具体步骤如下:
(1)根据轮盘赌策略随机生成SN个可行解即蜜源位置(Xi,Yi)(i=1,2,…,SN),且采蜜蜂和观察蜂的数量都为SN,SN根据精度要求确定;
(2)计算每个蜜源的适应度函数其中(xa,ya)=(Xi,Yi)。
(3)根据公式得到新的解(X′i,Y′i),其中(k=1,2,…,SN,k≠i),φi是区间[0,1]的随机数。并将新生成的解与原来的解(Xi,Yi)比较。采用贪婪策略保留较好的解。每个观察蜂根据概率pi选择蜜源。其中pi由下式表示:
(4)对于被选择的蜜源,观察蜂根据公式(3.8)搜寻新的可能解。当所有的采蜜蜂和观察蜂都搜索完解空间后,如果一个蜜源的适应值在给定的步骤内(定义为控制参数“limit”)没有被提高,则丢弃该蜜源,而与该蜜源相对应的采蜜蜂变成侦查蜂,侦查蜂通过公式搜索新的可能解。
其中r是区间[0,1]上的随机数,Xmin,Xmax,Ymin,Ymax分别是x,y维的上下界,并转至步骤(2)。
3节点数据汇集频率自适应策略
3.1寻找代理节点
根据蜂群算法找到执行器节点最佳驻留位置后,执行器节点开始移动到目标位置。为了保证在执行器节点移动期间,感知节点的数据传输的连续性,有必要选取一个代理节点作为执行器节点移动期间的临时数据终端。为了防止数据传输路由的变动性最小,应选取执行器节点的第一簇区中的某个节点作为代理节点。
当执行器节点准备移动到驻留位置时,以通信半径R发送一个代理选取信号agent_selection,通信半径涵盖了执行器节点的第一簇区。收到信号的传感器节点回复一个agent_reply信号,信号中包含了传感器节点ID,已占用队列长度以及节点剩余能量。执行器节点收到回复信息后,尽可能选择剩余能量大且空闲队列长度长的节点作为代理节点,代理节点概率选择公式如下:
式中,ei是节点i的剩余能量;Ei是节点i的初始能量;qi是已占用队列长度;Qi是节点总队列长度。λe和λq分别是能量和队列的权重参数,且λe+λq=1。执行器节点选择好代理节点后,以的发射距离向簇内的传感器节点发送一个agent_selection_notification信息,信息中包含代理节点的ID号,代理时间tm(执行器节点移动到驻留位置的时间),移动位置坐标。代理节点i接收到执行器节点的声明信息后,计算自身的数据接收速率:
其中是执行器节点的初始位置,v是执行器节点的移动速度。
3.2自适应利用MAC层资源
为了减少代理节点在数据接收状态的能量消耗和数据队列长度,同时增加网络路由MAC层资源的利用率,设计节点数据汇集频率自适应策略,具体步骤如下:
1)代理节点监测当前子层邻节点数据传输状态,若当前有节点在传输数据,则代理节点反馈一个数据发送速率控制信息,子层邻节点收到信息后将数据发送速率控制为:
其中ns为当前代理节点子层邻节点正在发送数据的节点数目,并进入步骤2);若没有节点在传输数据,则代理节点进入数据接收等待状态,并进入步骤4)。
2)第二层节点继续监测它的子层邻节点的数据传输状态。若存在数据传输节点,则发送数据速率控制信息,第二层节点的子层邻节点的数据发送速率由第二层节点的空余队列长度和当前发送数据的子层邻节点的数目以及自身的数据发送速率有关,即
[(Qi-1-qi-1)-(ni-1×Mi-1-1_send-Mi-1_send)×T]=0
其中T为传感器节点采样周期,依此策略,得出最后一层节点的数据发送速率。
3)如果初始时一个节点的父层邻节点没有分配数据传输速率配额给它,而在周期T内它的子层邻节点需要向它传送监测数据,那么它所反馈的子层邻节点的数据发送速率为:
其中T1表示为周期T内该节点保持数据接收等待状态的时间。
4)经过采样周期T后,由代理节点逐层分配节点数据发送速率配额,直至最后一层节点。
5)经过时间tm后,即执行器节点移动目标驻留位置后,以执行器节点为簇头,执行上文模型提出的环形分区操作,本发明流程图如图3所示。
以上内容详细阐述了本发明的算法实现过程。应当理解,本领域的普通技术无需创造性劳动就可以根据本发明的构思做出诸多修改和变化。因此,凡本技术领域中技术人员依本发明的构思在现有技术的基础上通过逻辑分析、推理或者有限的实验可以得到的技术方案,皆应在由权利要求书所确定的保护范围内。
- 还没有人留言评论。精彩留言会获得点赞!