一种基于智能终端的音频采集方法、系统及智能终端与流程
本发明涉及智能终端技术领域,尤其涉及一种基于智能终端的音频采集方法、系统及智能终端。
背景技术:
现有技术中当用户在户外嘈杂或者其他环境下通话,传递声音等内容时,不免会夹杂一些不必要的外界杂音信息;且根据电子设备声源位置,可能也会产生嘈杂不清的杂音,容易导致语音采集效率低、采集数据准确性也大大降低,给用户的通话造成很大的不便。
由此可知,现有技术还有待于改进和发展。
技术实现要素:
本发明要解决的技术问题在于,针对现有技术的上述缺陷,提供一种基于智能终端的音频采集方法、系统及智能终端,旨在通过将人脸识别、声纹识别以及传声器阵列声源定位技术相结合进行用户的通话语音采集,使得采集语音信息的过程中的不希望听到的声源忽略掉,只传递和采集用户需要的声源,从而提高用户语音采集效率和采集数据的准确性,给用户带来便利。
本发明解决技术问题所采用的技术方案如下:
一种基于智能终端的音频采集方法,其中,包括步骤:
S1、若检测到智能终端开启用户音频采集功能,则获取用户设置的对比输入条件;
S2、根据获取的所述对比输入条件采集相应的用户信息,并将采集的所述用户信息与预存储的用户信息进行匹配;
S3、若匹配成功,则根据预设的传感器阵列声源定位算法定位当前声源用户,并采集相应声源用户的音频信息进行存储。
所述的基于智能终端的音频采集方法,其中,所述对比输入条件包括:进行人脸信息对比和/或进行声纹信息对比。
所述的基于智能终端的音频采集方法,其中,所述步骤S1之前还包括步骤:
S0、预先在所述智能终端中设置并存储用户的人脸信息和/或与所述人脸信息相对应的声纹信息。
所述的基于智能终端的音频采集方法,其中,所述步骤S2具体包括步骤:
S21、若检测到获取的所述对比输入条件为进行人脸信息对比,则采集当前用户的人脸信息,并与所述智能终端中预存储的人脸信息进行匹配;
S22、若检测到获取的所述对比输入条件为进行声纹信息对比,则采集当前用户的语音信息,并与所述智能终端中预存储的声纹信息进行匹配;
S23、若检测到获取的所述对比输入条件为进行人脸信息对比和/或声纹信息对比,则采集当前用户的人脸信息和语音信息,并与所述智能终端中预存储的人脸信息和相对应的声纹信息进行一一匹配。
所述的基于智能终端的音频采集方法,其中,所述步骤S3具体包括步骤:
S31、若匹配成功,则启动所述智能终端预设的传感器阵列声源定位算法;
S32、根据所述传感器阵列声源定位算法确定当前声源用户;
S33、采集当前声源用户的音频信息,并进行存储。
一种基于智能终端的音频采集系统,其中,包括:
预设值存储模块,用于预先在所述智能终端中设置并存储用户的人脸信息和/或与所述人脸信息相对应的声纹信息;
检测启动模块,用于若检测到智能终端开启用户音频采集功能,则获取用户设置的对比输入条件;
用户信息匹配模块,用于根据获取的所述对比输入条件采集相应的用户信息,并将采集的所述用户信息与预存储的用户信息进行匹配;
用户音频信息采集模块,用于若匹配成功,则根据预设的传感器阵列声源定位算法定位当前声源用户,并采集相应声源用户的音频信息进行存储。
所述的基于智能终端的音频采集系统,其中,所述对比输入条件包括:进行人脸信息对比和/或进行声纹信息对比。
所述的基于智能终端的音频采集系统,其中,所述用户信息匹配模块具体包括:
第一信息匹配单元,用于若检测到获取的所述对比输入条件为进行人脸信息对比,则采集当前用户的人脸信息,并与所述智能终端中预存储的人脸信息进行匹配;
第二信息匹配单元,用于若检测到获取的所述对比输入条件为进行声纹信息对比,则采集当前用户的语音信息,并与所述智能终端中预存储的声纹信息进行匹配;
第三信息匹配单元,用于若检测到获取的所述对比输入条件为进行人脸信息对比和/或声纹信息对比,则采集当前用户的人脸信息和语音信息,并与所述智能终端中预存储的人脸信息和相对应的声纹信息进行一一匹配。
所述的基于智能终端的音频采集系统,其中,所述用户音频信息采集模块具体包括:
声源定位算法启动单元,用于若匹配成功,则启动所述智能终端预设的传感器阵列声源定位算法;
声源用户确定单元,用于根据所述传感器阵列声源定位算法确定当前声源用户;
音频信息采集存储单元,用于采集当前声源用户的音频信息,并进行存储。
一种智能终端,其中,包括以上任一项所述的基于智能终端的音频采集系统。
本发明所提供的一种基于智能终端的音频采集方法、系统及智能终端,所述方法具体包括:若检测到智能终端开启用户音频采集功能,则获取用户设置的对比输入条件;根据获取的所述对比输入条件采集相应的用户信息,并将采集的所述用户信息与预存储的用户信息进行匹配;若匹配成功,则根据预设的传感器阵列声源定位算法定位当前声源用户,并采集相应声源用户的音频信息进行存储。本发明通过将人脸识别、声纹识别以及传声器阵列声源定位技术相结合进行用户的通话语音采集,使得采集语音信息的过程中的不希望听到的声源忽略掉,只传递和采集用户需要的声源,从而提高了用户语音采集效率和采集数据的准确性,给用户带来了极大的便利。
附图说明
图1是本发明基于智能终端的音频采集方法的较佳实施例的流程图。
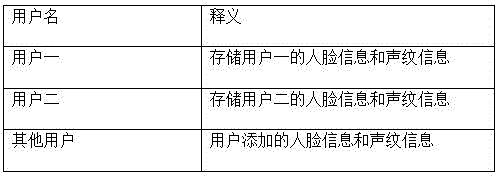
图2是本发明基于智能终端的音频采集方法用户信息存储示意图。
图3是本发明基于智能终端的音频采集方法的应用实施例流程图。
图4是本发明基于智能终端的音频采集系统的较佳实施例的功能模块图。
具体实施方式
本发明公开了一种基于智能终端的音频采集方法、系统及智能终端,为使本发明的目的、技术方案及优点更加清楚、明确,以下参照附图并举实施例对本发明进一步详细说明。应当理解,此处所描述的具体实施例仅仅用以解释本发明,并不用于限定本发明。
请参见图1,图1是本发明基于智能终端的音频采集方法的较佳实施例的流程图。图1所示的基于智能终端的音频采集方法,包括:
步骤S101、若检测到智能终端开启用户音频采集功能,则获取用户设置的对比输入条件。
人脸识别是基于人的脸部特征信息进行身份识别的一种生物识别技术。用摄像机或摄像头采集含有人脸的图像或视频流,并自动在图像中检测和跟踪人脸,进而对检测到的人脸进行脸部的一系列相关技术,通常也叫做人像识别、面部识别。声纹识别也是一种生物识别方式,通过采集人的语音信息进行身份识别。为了提高用户语音采集效率和采集数据的准确性,本发明实施例结合人脸识别技术以及声纹识别技术,因此,在实施之前需要预先在所述智能终端中设置并存储用户的人脸信息和/或与所述人脸信息相对应的声纹信息。
本发明实施例中的智能终端在第一次开启或者使用该音频采集功能时,会提示用户输入人脸信息和声纹信息。如图2所示的用户信息存储示意图。图2中所示的各用户的用户名和相应的人脸信息和声纹信息都可以增加、编辑、和修改。但是在进行编辑、修改、增加之前,设备需要提供生物的和非生物(如密码)的验证方式以验证当前设备持有者是否为设备的合法拥有者。
步骤S102、根据获取的所述对比输入条件采集相应的用户信息,并将采集的所述用户信息与预存储的用户信息进行匹配。
本发明实施例中,所述步骤S102具体包括:
S21、若检测到获取的所述对比输入条件为进行人脸信息对比,则采集当前用户的人脸信息,并与所述智能终端中预存储的人脸信息进行匹配;
S22、若检测到获取的所述对比输入条件为进行声纹信息对比,则采集当前用户的语音信息,并与所述智能终端中预存储的声纹信息进行匹配;
S23、若检测到获取的所述对比输入条件为进行人脸信息对比和/或声纹信息对比,则采集当前用户的人脸信息和语音信息,并与所述智能终端中预存储的人脸信息和相对应的声纹信息进行一一匹配。
本发明实施例中,所述对比输入条件包括:进行人脸信息对比、以及进行声纹信息对比。即,该智能终端将收集到的人脸信息和声纹信息作为对比的输入条件。其中,所述人脸信息和声音信息可以是与、或关系。本发明实施例提供以下几种方式供选择,
(1)仅声纹识别:当选择声纹识别时,设备只收集当前设备所处环境中的语音信息与预设的信息数据库中的声纹进行一一对比,然后收集通过声纹对比匹配到的用户即进行收集,其余用户不进行收集,且不再需要对比人脸信息。
(2)仅人脸信息识别:当选择人脸信息识别时,设备只收集当前的设备周围的人脸信息与信息数据库中的人脸信息进行一一对比,然后收集人脸信息识别到的用户即进行收集,其余用户不进行收集,且不再需要对比声纹信息。
(3)声纹识别+人脸信息识别:选择两者都对比时,则需要采集声纹信息和人脸信息都与信息数据库中的信息对比,当两者都匹配到时候,才收集语音信息。
(4)声纹识别或人脸信息识别:选择这种的情况下,需要采集声纹信息和人脸信息都与信息数据库中的信息对比,但只要其中之一匹配到后,即进行语音信息收集。
步骤S103、若匹配成功,则根据预设的传感器阵列声源定位算法定位当前声源用户,并采集相应声源用户的音频信息进行存储。
进一步地,所述步骤S103具体包括步骤:
S31、若匹配成功,则启动所述智能终端预设的传感器阵列声源定位算法;
S32、根据所述传感器阵列声源定位算法确定当前声源用户;
S33、采集当前声源用户的音频信息,并进行存储。
即,本发明实施例将实时采集到的人脸信息、声纹信息进行匹配处理。如果对比到与标准库匹配的对象,则调用内置的传声器阵列声源定位算法进行方向调整,收集相应方向的用户声音信息。
传声器阵列声源定位技术是指若干个传声器按照一定的几何结构排列组成传声器阵列,通过阵列信号处理的方法对该阵列接收到的声源信号进行处理,根据所得数据确定出声源的几何位置。该传声器阵列是指按一定距离排列放置的一组麦克风,通过声波抵达阵列中每个麦克风之间的微小时差的相互作用,麦克风阵列可以得到比单个的麦克风更好地指向性。通过对所有麦克风信号的综合处理,麦克风阵列可以组合成为所要求的强指向性麦克风,形成被称为“波束”的指向特性。麦克风阵列的波束可以经由特殊电路或程序算法软件控制,使其指向声源方向而加强音频采集效果。传声器阵列声源定位算法处理后的指向性波束形成技术能精确的形成一个锥状窄波束,只接受说话人的声音同时抑制环境中的噪音与干扰。
具体地,可以通过以下两种方法获得麦克风阵列单元之间相对位置的信息:
(1)把一对麦克风同步采集到的信号进行互相关,寻找互相关信号的最大值,得到两信号之间的延时τ,再乘以声波传播速度C0 得到相对位置间距d = C0τ;
(2)测量一对麦克风同步采集信号相位差Δφ,根据频率f 和声传播速度C0 得到这一对麦克风的位置间隔 d = C0Δφ/ (2πf ) 。
本发明实施例通过以上方式精确地采集相应对象的声音,并将采集的对象声音进行存储、输出。
以下将通过具体的应用实施例对本发明做进一步说明。图3是本发明基于智能终端的音频采集方法的应用实施例流程图。如图3所示,包括:
S201、开始流程;
S202、查询是否开启只采集需要对象的音源功能,如果开启进入步骤S203,如果未开启结束流程则进入步骤S212;
S203、获取用户设置的对比输入条件;
S204、根据对比条件获取相应的信息进行对比;所述对比输入条件包括:进行人脸信息对比、以及进行声纹信息对比。具体地,包括:
(1)若检测到获取的所述对比输入条件为进行人脸信息对比,则采集当前用户的人脸信息,并与所述智能终端中预存储的人脸信息进行匹配;
(2)若检测到获取的所述对比输入条件为进行声纹信息对比,则采集当前用户的语音信息,并与所述智能终端中预存储的声纹信息进行匹配;
(3)若检测到获取的所述对比输入条件为同时进行人脸信息对比和声纹信息对比,则采集当前用户的人脸信息和语音信息,并与所述智能终端中预存储的人脸信息和相对应的声纹信息进行一一匹配;
(4)若检测到获取的所述对比输入条件为进行人脸信息对比或者声纹信息对比,则采集当前用户的人脸信息和语音信息,并与所述智能终端中预存储的人脸信息和声纹信息进行一一匹配。
S205、判断是否匹配到相应的对象,如果匹配到相应对象,进入步骤S206,如果未匹配到相应的对象进入步骤S208;
S206、调用传声器阵列声源定位算法获取匹配对象的声源信息;
S207、采集此声源用户的语音信息,并进行如储存,发送等;
S208、提示用户未匹配到相应的声源对象;
S209、提供给用户是否需要关闭只采集对象音源的功能,如果用户选择关闭,则进入步骤S212结束流程;如果用户不选择关闭,选择继续收集,则进入步骤S210;
S210、提示用户是否新增匹配对象,如果用户不新增匹配对象,则进入步骤S212结束流程;如果用户新增匹配对象,则进入步骤S206;
S211、采集、存储用户新增匹配对象的相应信息并更新用户信息库,返回步骤S206;
S212、结束流程。
由上可见,本发明通过将人脸识别、声纹识别以及传声器阵列声源定位技术相结合进行用户的通话语音采集,实现了用户在录制视频的时候,只会捕捉到想要录入对象的声源信息,或者需要发送语音信息时,也只会发送需要发送对象的声源信息,从而摒弃掉了一些非需要采集对象的杂音,提高了音源的准确率,也提高了用户语音采集效率和采集数据的准确性,给用户带来了极大的便利。
基于上述实施例,本发明还提供一种基于智能终端的音频采集系统,如图4所示,包括:
预设值存储模块100,用于预先在所述智能终端中设置并存储用户的人脸信息和/或与所述人脸信息相对应的声纹信息;具体如上所述。
检测启动模块200,用于若检测到智能终端开启用户音频采集功能,则获取用户设置的对比输入条件;具体如上所述。
用户信息匹配模块300,用于根据获取的所述对比输入条件采集相应的用户信息,并将采集的所述用户信息与预存储的用户信息进行匹配;具体如上所述。
用户音频信息采集模块400,用于若匹配成功,则根据预设的传感器阵列声源定位算法定位当前声源用户,并采集相应声源用户的音频信息进行存储;具体如上所述。
进一步地,所述对比输入条件包括:进行人脸信息对比和/或进行声纹信息对比。
进一步地,所述用户信息匹配模块300具体包括:
第一信息匹配单元,用于若检测到获取的所述对比输入条件为进行人脸信息对比,则采集当前用户的人脸信息,并与所述智能终端中预存储的人脸信息进行匹配;具体如上所述。
第二信息匹配单元,用于若检测到获取的所述对比输入条件为进行声纹信息对比,则采集当前用户的语音信息,并与所述智能终端中预存储的声纹信息进行匹配;具体如上所述。
第三信息匹配单元,用于若检测到获取的所述对比输入条件为进行人脸信息对比和/或声纹信息对比,则采集当前用户的人脸信息和语音信息,并与所述智能终端中预存储的人脸信息和相对应的声纹信息进行一一匹配;具体如上所述。
进一步地,所述用户音频信息采集模块400具体包括:
声源定位算法启动单元,用于若匹配成功,则启动所述智能终端预设的传感器阵列声源定位算法;具体如上所述。
声源用户确定单元,用于根据所述传感器阵列声源定位算法确定当前声源用户;具体如上所述。
音频信息采集存储单元,用于采集当前声源用户的音频信息,并进行存储;具体如上所述。
进一步地,本发明还提供一种智能终端的实施例,本实施例所述的智能终端包括上述所述的基于智能终端的音频采集系统。
综上所述,本发明所提供的一种基于智能终端的音频采集方法、系统及智能终端,所述方法具体包括:若检测到智能终端开启用户音频采集功能,则获取用户设置的对比输入条件;根据获取的所述对比输入条件采集相应的用户信息,并将采集的所述用户信息与预存储的用户信息进行匹配;若匹配成功,则根据预设的传感器阵列声源定位算法定位当前声源用户,并采集相应声源用户的音频信息进行存储。本发明通过将人脸识别、声纹识别以及传声器阵列声源定位技术相结合进行用户的通话语音采集,使得采集语音信息的过程中的不希望听到的声源忽略掉,只传递和采集用户需要的声源,从而提高了用户语音采集效率和采集数据的准确性,给用户带来了极大的便利。
应当理解的是,本发明的应用不限于上述的举例,对本领域普通技术人员来说,可以根据上述说明加以改进或变换,所有这些改进和变换都应属于本发明所附权利要求的保护范围。
- 还没有人留言评论。精彩留言会获得点赞!