一种信道状态不确定条件下分层异构网络的稳健分层博弈学习资源分配方法与流程
本发明涉及5G分层异构网络的资源分配问题解决方案。该发明针对异构无线网络在信道信息不完美条件下的干扰管理问题,提出了一种基于鲁棒双层博弈的离散策略资源分配方案。属于无线通信
技术领域:
。二
背景技术:
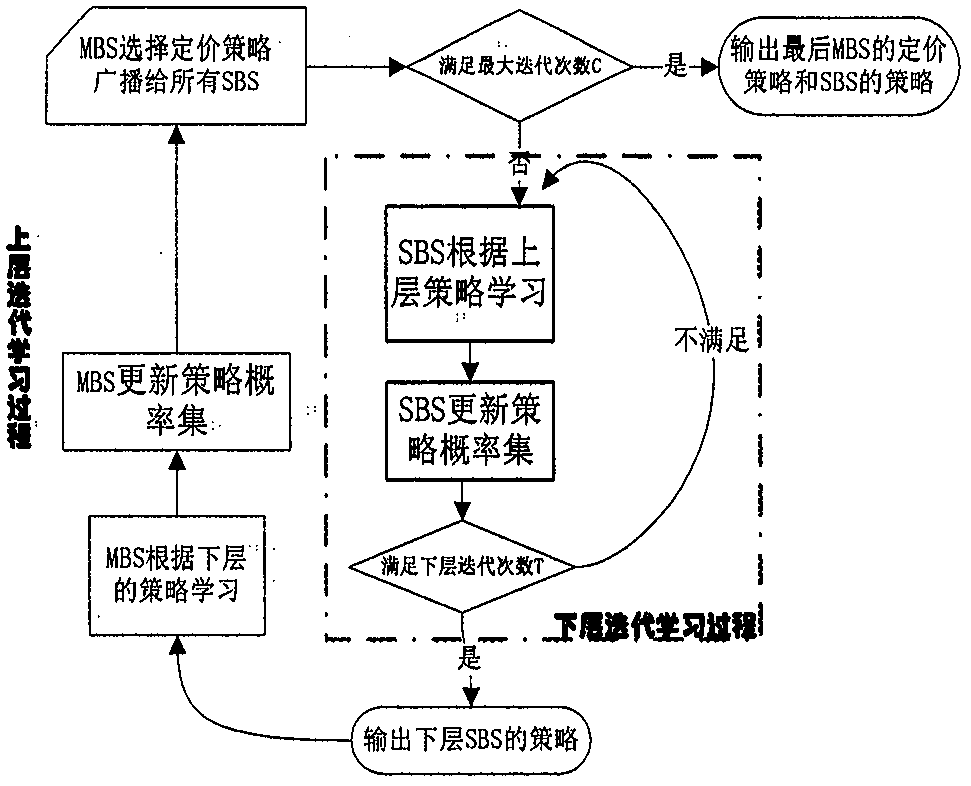
:随着新媒体数据应用需求的不断增长,5G蜂窝网络相对于现在的4G蜂窝网在容量上要提高1000倍,密集组网技术将成为下一代通信的关键技术之一。通过在宏蜂窝基站(Macro-cellBaseStation,MBS)周围布设小蜂窝基站(Small-cellBaseStation,SBS),能够扩展覆盖区域,改善能量效率,提高用户传输速率,以达到提高用户体验的目的。异构双层蜂窝网主要有两种用频方式:(1)正交独享模式(split-spectrum),这种方式各级蜂窝相互之间无干扰,管理简单但是频谱效率很低。(2)分享复用模式(shared-spectrum),这种方法可增加频谱的空间重用效率,更适用于大规模布设的小微蜂窝网络,但会引起小蜂窝与主蜂窝间的跨层干扰以及小蜂窝间的同层干扰,需要干扰的控制协调。如果不进行适当的干扰协调,会带来基站间的严重干扰和发射功率的巨大浪费。因此,干扰控制协调问题成为了现阶段异构无线网资源分配的难点。博弈论是一种用于处理参与者相互间利益决策的方法,适合解决由理性参与者组成的系统优化问题,可广泛应用于解决多用户网络的资源分配问题,如功率和信道的分配。双层斯坦伯格博弈(StackelbergGame)被广泛应用于分析和解决分层无线网的资源分配问题。然而现有的博弈资源分配研究都是假设所有用户和基站间信道状态信息(ChannelStateInformation,CSI)己知,并据此做相应的决策。但是在实际情况下,特别在异构双层网络中,由于基站属于不同的运营商,基站之间的信息交换很难实现,即便可以获得,信道信息也具有时效性。另外,出于个人隐私和安全的考虑,基站在双层网络中并不愿意形成联盟交换信息,这样要求协调所有基站的中心式资源分配模式很难落实。因此,如何分布式处理不完美信道信息条件下的异构双层网络资源分配是个棘手的问题。现有文献大都是基于完美信道信息的假设,所有涉及的参数和目标函数都可以准确获得。由于无线信道的随机动态特性,现有模型中不同层级间的基站用户完美获取相互信息并不实际。但在不确定条件下,使用以往在完美信道信息条件下得到的资源分配策略很可能使实际系统的性能恶化。另外现有工作大都是考虑连续数值的资源分配问题。相比连续的资源分配策略,离散策略的资源分配方式可简化传输设计和数据处理,降低基站之间的信息交换开销,如在3GPPLTE蜂窝网络中就只支持离散功率控制的下行传输,现有的离散策略选择方法运算复杂度普遍较高,无法适应实时变化的环境和用户的决策需要。三技术实现要素:本发明主要目的在于克服现有资源分配方式的上述缺点,提出了一种信道状态不确定模型下分层异构微蜂窝网络中的无线资源双层分配优化框架及一种分布式分层学习算法。提出了方案以实现宏基站和微基站的均衡离散策略搜索。有效抑制由于信道状态不确定引起的收益下降问题。本发明的目的是由以下技术方案实现的:本发明基于下行链路的OFDM分层蜂窝网络,该网络由一个宏基站和N个小蜂窝基站组成,如图1所示。每个蜂窝间通过数字用户线(DigitalSubscriberLine,DSL)链接,作为控制信道用来交换信息。每个基站以时分复用的方式服务多个用户。宏基站和小蜂窝基站分享复用网络频谱资源。为便于分析,假设每个小蜂窝基站在一个时隙只服务一个小蜂窝用户。因为小蜂窝基站与宏基站使用相同的频谱,就不可避免的发生不同基站间的跨层和同层干扰。为了保护宏基站内用户的通信质量,我们使用干扰价格对下层小蜂窝基站的发射功率加以约束,并限定小蜂窝基站对宏基站的累积干扰必须小于门限值Z。这样以来,如果下层小蜂窝基站的通信对宏基站造成影响,它就要为对宏基站带来的干扰付出代价,所以小蜂窝基站需要优化自己的功率策略。而上层宏基站希望在对其用户的干扰限定在满足服务约束的条件下,尽可能提高对下层小蜂窝基站干扰收费的总收益。我们采用基于斯坦伯格博弈的双层构架。上层博弈参与者作为leader,具有强势地位,首先做出决策并向下层广播。下层参与者follower是跟随关系,根据上层的决策被动做出回应,从可能的策略集中选择对自己最有利的策略。本发明采用单leader多follower形式。MBS作为leader首先行动,发布单位干扰定价。SBS作为follower,根据上层MBS的定价,选择最优功率分配策略来最大化其效用。该效用体现博弈参与者对选择策略的收益,可通过基于策略的函数来表示。该方法的具体步骤如下:1.下层小蜂窝效用分析和表示在异构的无线网络中,出于理性自私,SBS间不会协商,都是独立的选择使自己收益最大的策略,从而构成了非合作博弈关系。我们定义下层用户SBS的效用函数由速率容量收益、付出的能量代价和对上层的干扰代价组成。由于是否考虑MBS对SBS干扰,并不影响问题的分析过程。为便于处理,本发明不涉及宏蜂窝的功率控制问题。所以,下层用户的收益与自己的发射功率、邻居SBS对其的干扰和信道状态有关。对于下层小微蜂窝,SBSi接收到的信干噪比可写为:γi(pi,p-i)=pihiiΣj≠ipjhji+σ0,∀i∈{1,2,...,N},---(1)]]>式(1)中σ0代表接收的高斯噪声功率,pi表示下层SBSi的发射功率,p-i表示除了SBSi外的其他SBS的功率策略,hji表示SBSj对SBSi用户干扰的信道增益,i,j∈{1,2,...,N},N为SBS的总数,则代表使用同频信道的其他基站对SBSi带来的干扰。下层SBSi的效用函数可以定义为:ui(pi,p-i,ui,λ0)=Wlog(1+γi(pi,p-i))-uipi-λ0gi0pi(2)式(2)由3部分组成,分别表示SBS的容量收益,功耗代价和SBS对MBS带来的干扰,其中W表示带宽,gi0表示SBSi对MBS用户的信道增益,ui是能耗单位定价,λ0单位干扰定价,相当于SBS要为对MBS的干扰付费。2.上层宏蜂窝效用分析和表示对于上层MBS,其目标是在自身能够容忍干扰的条件下(比如所有SBS对MBS宏蜂窝用户的累积干扰不超过门限Z),最大化下层SBS对其干扰的累加付费收益。所以上层MBS的效用函数可以定义为:U0(λ0,pi)=ΣiNλ0gi0pi---(3)]]>式(3)中pi可以表示为关于干扰定价的函数。它也是上下双层策略选择的博弈焦点,暗示了下层SBS发射多少功率与上层的干扰定价有关。3.已知信道状态信息时的上下层蜂窝的优化问题对于下层小蜂窝而言,如果SBS要增加其传输功率,虽然提高了信号传输速率的收益,但将会引起对MBS的干扰和自身能量的消耗而付出更多的代价。所以下层用户必须选择合适的功率策略最大化自己的效用,以达到收益和代价的平衡。对于每个SBS用户而言,问题可建模为:问题1:MBS要在其干扰可承受的范围内最大化自身收益,所以上层的目标可建立为带约束优化问题,即:问题2:4.干扰信道状态信息不完全可知时的鲁棒性优化问题由于SBS和MBS隶属不同的私人或运营商,回程链路容量十分有限的,通常无法得到完美的CSI。另外SBS间也缺乏相应机制分享CSI。因此,本发明考虑更加实际的不完美信道信息条件,引入信道不确定模型描述无线信道的随机动态性。假设基站只知道自己的信道增益hii,但并不确切知道同层干扰的信道增益hji和跨层干扰的信道增益gi0。我们把信道增益表示为标称估计值和不确定值的求和形式,即本文从信道信息不确定引起的最差情况出发,将斯坦伯格博弈问题转化为双层的最大最小化问题。下层SBS的效用函数可转化为:maxminUi(pi,p-i,ui,λ0)=Wlog(1+pihiiΣj≠ipj(hji‾+Δhji)+σ0)-uipi-λ0(gi0‾+Δgi0)pi---(6)]]>类似的,上层MBS的效用函数转化为:maxminU0(λ0,pi)=ΣiNλ0(gi0‾+Δgi0)pis.t.ΣiN(gi0‾+Δgi0)pi≤Z---(7)]]>利用柱形模型(column-wise)和柯西不等式,信道增益不确定分量的上界及由不确定所带来的最大干扰可分别表征为:|Δgi0|≤εi0(8-1)Σj≠ipjΔhji≤[Σj≠i|pj|2Σj≠i|Δhji|2]12≤ϵjiΣj≠ipj2---(8-2)]]>其中ε表示不确定上界。利用公式(8),原问题可转化为在考虑信道最大不确定情况下的鲁棒双层博弈问题,即式(6)和式(7)的最大最小化问题可被简化为:问题3:问题4:5.分布式双层Q学习算法在发明所提的双层博弈框架中,每个参与博弈的用户都有有限离散策略集合。本发明将利用强化Q学习算法来找到均衡解。我们假设所有博弈参与人都是理性的,会选择使其效用最大的最优策略。定义用户i的可用策略集为|Si|表示策略集的个数。具体到上下层用户,下层SBS用户的策略集为上层MBS用户的策略集为所有用户的策略空间可表示为代表笛卡尔积。定义其在第t次迭代时,各策略概率矢量为需满足每个用户的策略集概率和这样,用户i的期望效用就可以表示为:ui(πit,π-it)=E[Ui|πit,π-it]=Σs′∈SUi(s′)Πi∈N∪{0}πi,ait---(11)]]>其中表示用户i基于目前的策略概率集选出的策略。那么对于上层MBS的最大化效用目标可写为:问题5:相似的,对于下层SBS最大化其效用可写为:问题6:通过上述分析,我们给出双层强化学习算法的SE定义。定义2:当任意策略选择同时满足上下层基站效用和时,则策略选择是双层学习的稳定策略解。定理2:在上层MBS给定π0的情况下,下层SBS一定存在一个混合策略解(πi,π-i,π0)满足从而得到下层的纳什均衡。在Q学习过程中,用户的策略被参数化为Q函数,它表示每个特定策略的相对效用。定义用户i在第t次迭代时基于策略概率所选的策略的Q函数为通过用户之间的策略和环境交互,得到每个策略的相应回报奖励,更新Q函数。在选择策略后,相应的Q值通过式(21)更新,Qit+1(si,ait+1)=(1-κit)Qit(si,ait)+κitui(si,ait,π-it),---(14)]]>其中代表学习速率,满足是用户i在第t次迭代选择策略的期望回报,如式(15)所示。ui(si,ait,π-it)=Σa-it∈S-iUi(si,ait,S-it)Πj∈N∪{0}/iπj,ajt,---(15)]]>其中且每个BS用户根据式(15)的玻尔兹曼分布来更新其策略。πit(si,ai)=exp[Qit(si,ait)/ψi]Σai∈Sexp[Qit(si,ait)/ψi],---(16)]]>其中ψi>0是温度系数,用来控制策略选择是倾向探测还是利用。当ψi趋于0,表示用户只利用,会选择相应的策略去最大化Q值。相对地,当ψi趋于∞,表示用户只探测,用户的策略选择是完全随机的,用户的策略概率分布满足均匀分布。根据式(14)和(16),上层MBS通过迭代更新对应Q函数。假设上层MBS每c时段更新一次定价策略。在双层学习迭代算法中,作为唯一的公共信息,上层的MBS首先向下层所有SBS发布定价。下层接收到干扰价格后,通过学习算法找到各自的最优响应功率策略,然后在每个时间段终点反馈回上层MBS,以便上层MBS根据下层上报的功率策略信息更新自己的出价策略。算法是嵌套迭代循环方式。下层SBSi的Q函数通过式(17)更新,Qit+1(si,ait+1)=(1-κit)Qit(si,ait)+κitu‾i(si,ait,s0,a0),---(17)]]>其中估计的期望效用可表示为:其中表示在一个时间段内上下层合并选择为的次数。我们可看到上层MBS和下层SBS的更新是基于不同的时间单位的,下层用户每T时隙更新迭代完成一次,而上层用户c个时间段更新迭代完成一次,上下层用户策略的更新都是基于对方迭代更新后的结果通过Q学习得到的。下层在每个时隙结束时执行式(17),完成其Q函数的更新。类似的,上层MBS用户在每个时间段c结束时执行式(19),完成其Q函数的更新:Q0c+1(s0,a0)=(1-κ0)Q0c(s0,a0)+κ0u0c(s0,a0,π-icT)---(19)]]>在实际算法运行过程中,当用户的策略集相对较大时,收敛的速度将指数增加,成为很大的短板。本发明所提算法充分利用每次的环境信息,在一次迭代更新所有策略的Q值,算法能很快收敛到一个纯策略均衡点,具体步骤如表1所示。表1改进型双层Q学习算法本发明的有益效果如下:在保护宏基站内用户的通信质量的前提下,提出的异构双层鲁棒模型能有效抑制由于不确定度变化带来的用户收益减少的问题。所提算法能够在较短时间收敛并获取优越的策略选择结果。四附图说明图1为下行链路的OFDM蜂窝网络的系统示意图;图2为双层Q学习算法流程图;图3为所建框架性能说明示意图;五具体实施方式本发明实施例如图1所示,该网络由一个宏基站和2个小蜂窝基站组成。每个基站以时分复用的方式服务多个用户。宏基站和小蜂窝基站分享复用网络频谱资源。为便于分析,假设每个小蜂窝基站在一个时隙只服务一个小蜂窝用户。1)下层小蜂窝效用分析和表示ui(pi,p-i,ui,λ0)=Wlog(1+pihiiΣj≠ipjhji+σ0)-uipi-λ0gi0pi]]>由3部分组成,分别表示SBS的容量收益,功耗代价和SBS对MBS带来的干扰,其中W表示带宽,σ0代表接收的高斯噪声功率,pi表示下层SBSi的发射功率,p-i表示除了SBSi外的其他SBS的功率策略,hji表示SBSj对SBSi用户干扰的信道增益,则代表使用同频信道的其他基站对SBSi带来的干扰。gi0表示SBSi对MBS用户的信道增益,ui是能耗单位定价,λ0单位干扰定价,相当于SBS要为对MBS的干扰付费。下层用户必须选择合适的功率策略最大化自己的效用,以达到收益和代价的平衡。对于每个SBS用户而言,问题可建模为:问题1:2)上层宏蜂窝效用分析和表示u0(λ0,pi)=ΣiNλ0gi0pi]]>MBS要在其干扰可承受的范围内最大化自身收益,所以上层的目标可建立为带约束优化问题,即:问题2:3)干扰信道状态信息不完全可知时的鲁棒性优化问题本发明利用信道不确定模型描述无线信道的随机动态性。基站可通过信道测量技术(channel-qualityindicatormeasure)获得自己的信道增益hii,但并不确切知道同层干扰的信道增益hji和跨层干扰的信道增益gi0。我们把信道增益表示为标称估计值和不确定值的求和形式,即本文从信道信息不确定引起的最差情况出发,将斯坦伯格博弈问题转化为双层的最大最小化问题。并利用柱形模型(column-wise)和柯西不等式,信道增益不确定分量的上界及由不确定所带来的最大干扰可分别表征为:|Δgi0|≤εi0Σj≠ipjΔhji≤[Σj≠i|pj|2Σj≠i|Δhji|2]12≤ϵjiΣj≠ipj2]]>其中ε表示不确定上界。利用以上公式,原问题可转化为在考虑信道最大不确定情况下的鲁棒双层博弈问题,建模问题1,2的最大最小化问题可被简化为:问题3:问题4:4)分布式双层Q学习算法假设SBS1和SBS2对MBS用户的标称信道增益分别为g10=0.2,g20=0.3,归一化SBS对其自身用户的信道增益为h1,1=h2,2=1,下层SBS间的标称干扰信道增益分别是h1,2=h2,1=0.1。噪声功率σ0=0.01dBmW。设MBS的干扰价格策略集为π0=[2.5,3,3.5,4,4.5],SBS的功率分配策略集为其中SBS的最大传输功率pmax=100dBmW。设置每个时间段由T=100个时隙组成,上层迭代时间段数C=100。步骤1:开始上层循环,直到c=C最大时间段数。(初始化所有用户Q函数为各策略等概率分布。)(1)在每个时间段开始,MBS根据其策略概率集π0,选择一个定价策略并广播给所有的下层SBS。步骤2:下层学习过程t=1:T(1)每个SBSi根据自己的策略概率集选择各自功率策略si,ai。(2)每个SBSi根据反馈信息计算其效用并根据式更新其估计期望效用(3)每个SBSi根据式计算其他|Si|-1个策略的效用(4)每个SBSi根据式和式更新其Q值和策略概率集。(5)所有SBS把最后策略传给MBS在T时隙结束。完成下层策略的迭代更新。步骤3:MBS计算其第c个时间段的效用步骤4:MBS根据式和式更新其Q值和策略概率集。步骤5:MBS根据其已更新的策略概率集选择上层策略。完成上层策略的迭代更新。c=c+1,跳回到步骤1。迭代结束,输出1个宏蜂窝和2个小蜂窝基站的相应最佳策略。当前第1页1 2 3
相关技术
网友询问留言
已有0条留言
- 还没有人留言评论。精彩留言会获得点赞!
1