一种基于MIMO异构自组织网络的自适应调度优化方法与流程
本发明涉及一种无线网络通信方法,尤其涉及一种MIMO异构自组织网络的通信方法。
背景技术:
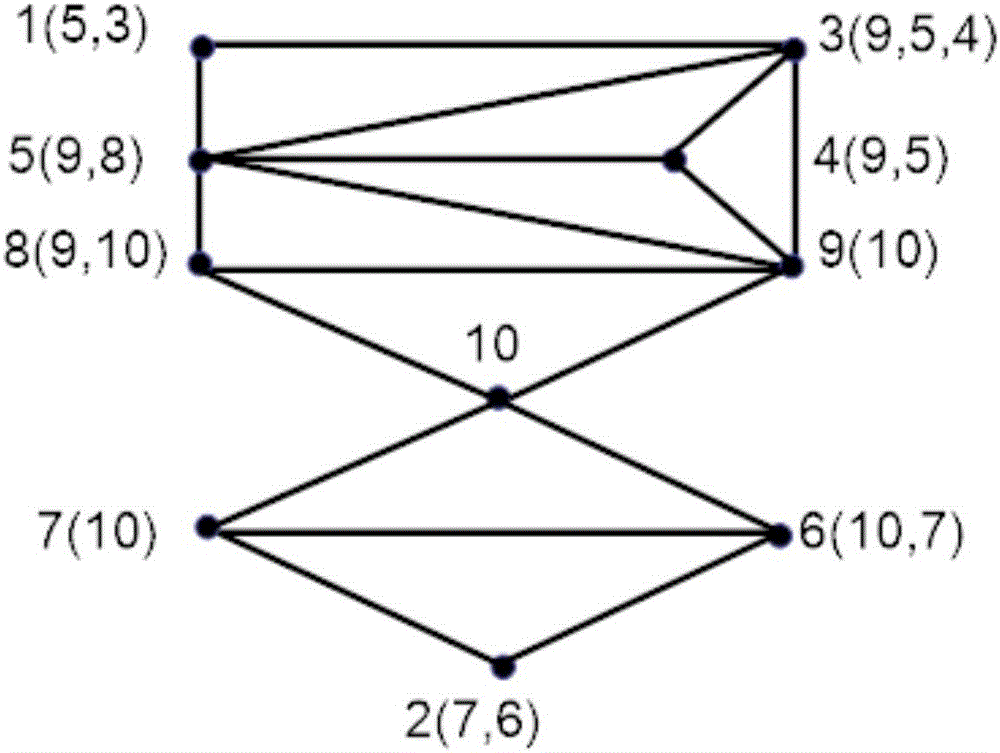
:近年来,人们对于互联网与便携式计算机的需求不断增加,进而推进了对于移动装置需求的增长。然而提供移动用户最迫切需要的网络连接和数据服务的装置之间大多是通过固定基础设施(如基站)连接的,如何在没有固定基础设施的地方进行通信呢?自组织网络在此环境下应运而生。自组织网络不需要任何有线基础设备的支持,可以通过主机自由组网来实现。无线Adhoc网络是一种由若干无线通信设备组合形成的分布式无线分组网络,又称为又称为多跳网(Multi-hopNetwork)、无基础设施网(InfrastructurelessNetwork)或自组织网(Self-organizingNetwork)。网络中的节点既是终端,又是路由器。不在彼此覆盖范围内的无线节点之间的通信可经中间节点的转发来完成。无线Adhoc网络的显著特点是它不需要固定通信设备(如基站)的支持,它不依赖与一个固定的网络节点;同时网络能随着节点的加入,离开以及节点的移动自组织、自管理,因此,无线Adhoc网络具有组网灵活、分布实施、抗毁能力强、可快速组网等特点,可作为野战通信、公安、紧急搜救、会议会场、信息家电等的通信网络,也可作为已有无线、有线网络的多跳扩展(以拓宽网络的覆盖范围)。因此,无线Adhoc网络具有广阔的应用前景,已成为国内外的一个研究热点。虽然自组织网络拥有众多的优势与广泛的应用,但是它也存在一些固有的缺陷:①通信带宽有限:自组织网络中没有基础设施支持,节点间通信通过无线传输完成,由于无线信道本身的物理特性,它提供的网络带宽相对有线信道要低得多。除此之外,考虑到竞争共享无线信道产生的碰撞,信号衰减,噪声干扰等多种因素,移动终端可得到的实际带宽远远小于理论中的最大带宽值。②移动终端的局限性:自组织网络中,移动终端均是一些便携。轻巧设备,如便携计算机或掌上电脑。由于节点一般依靠电池供电,且可能处在不停移动的状态下,因而存在能源受限的问题。③路由协议:多跳路由与动态拓扑的实现需要与其相适应的路由协议设计。相对于以上自组织网络的固有缺陷,多输入多输出(MIMO)技术是移动通信领域的一项重大突破,Telatar和Foschini较为系统地研究了MIMO系统容量问题,在不增加发射功率和系统带宽的条件下MIMO技术可以极大的提高系统容量、频谱利用率以及数据传输速率,同时还能增强系统抗干扰和抗衰落能力。MIMO技术利用了无线信道多径传播的固有特性,即只要在发射端和接收端装置配置多天线,并且各天线单元间距足够大,无线信道的散射环境足够丰富,那么各收发天线对之间就能形成独立的衰落信道。在这样的情况下,接收机可以接受到同一数据的不同传输副本,而多个信号副本同时经历深度衰落的概率远小于单个信号经历深度衰落的概率,接收端通过适合的合并方案,利用衰落较小的信号副本来解调,就可以显著提高信号传输的稳定性,由此而产生分集增益;同时还创造出了多个并行空间信道,通过他们来传输多个独立数据流,由此在不增加带宽的情况下提高数据传输速率。产生复用增益。在MIMO系统中由于每个节点可以带有多副天线,并且只要发射天线不大于接收天线,接受者就可以正确分离从不同的发射节点来的独立的数据流。利用这种新的收发机体系结构,多个独立的数据流可以在相同的信道上同时发送,这为大幅度提高无线Adhoc网络容量性能提供一个崭新而有效途径。由于目前移动Adhoc网络的单信道MAC协议都被设计在同一时刻一跳范围内只能接受一对用户通信,因此很大程度上限制了网络容量和通信能力。而现在可以利用MIMO的空间复用能力突破单信道共享中仅能进行点对点通信模式。另外,利用MIMO空间分集增益(拓展距离)可以获得包含更大通信距离链路的路由,这样可以减小路由发现时间和减少路由的跳数;在BER性能容许的情况下使用更高阶的调制方式以提高传输速率;在速率容许的情况下利用分集增益(降低BER)还可以提高传输质量,同时在短距离通信时还可以控制发射功率以减小对临节点的干扰。因此,在Adhoc网络中引入MIMO技术可以提高其网络容量和通信能力。但是通信系统中存在多径衰落,链路之间干扰等,使得通信质量下降。在考虑对Adhoc网络加入MIMO技术同时,加入优化考虑,不仅仅大大地减少链路之间干扰所带来的吞吐率下降而且可以提高通信可靠性。文献1(Chu,Shan,X.Wang,andY.Yang."AdaptiveSchedulinginMIMO-BasedHeterogeneousAdHocNetworks."IEEETransactionsonMobileComputing13.5(2014):964-978)提出了在异构自组织网络中基于MIMO的调度算法(集中式调度算法与分布式调度算法),集中式算法在调度的时候认为所有的节点都是在同一个信道状态下面进行传输并且传输时始终是以节点的平均数据流最大的标准优先传输;但是,对于分布式算法,每一个节点首先估计其信道状态,天线数,要发送的数据流的数量等的信息,按照每一个节点自身的特点选择传输数据的方式。对于不考虑干扰的情况下,集中式调度算法的吞吐量是比起分布式算法的吞吐量要大,但是,对于分布式算法来讲,其能够保证节点传输的可靠性和质量。但是文献1中没有考虑到链路之间相互干扰和竞争的情况。在自组织网络中,发送节点向接收节点发送数据经过的一段物理路线称为链路,每条链路都是用来传送数据。但是,在实际情况中,链路与链路之间可能会存在竞争的情况,这样就会对数据的传输造成影响,当一条链路与其他链路的竞争情况越大时,对传输数据的干扰就会越大。因此,有必要了解每一条链路与其他链路的竞争情况,才能够对于每个节点发送的情况选择相应更优的接收节点传输数据,这样就能够大大地减少干扰并保证数据传输的可靠性。文献2(Sundaresan,Karthikeyan,etal."MediumAccessControlinAdHocNetworkswithMIMOLinks:OptimizationConsiderationsandAlgorithms."IEEETransactionsonMobileComputing3.4(2004):350-365)提出在传输链路中可能会与其他在传输范围的链路竞争,这样就会影响传输的质量与可靠性,按照这样的问题提出了集中式SCMA(centralizedstream-controlledmediumaccess)算法与分布式SCMA算法从而能够更好地考虑与减少在链路传输数据的过程中链路之间的竞争情况从而保证传输的可靠性。需要说明的是,文献1中的集中式调度算法和分布式调度算法是在发送和接受的过程中,通过选择更优的发送和接收节点,考虑每个节点的天线数,信道状态等的因素关系,选择适合的调度算法从而进一步提高传输的质量。与文献1中的集中式调度算法和分布式调度算法不同,集中式SCMA法与分布式SCMA算法考虑的是链路在传输的过程中在其竞争范围内与其他链路相互竞争的情况,并且对此作出优化从而进一步保证传输质量。其中,集中式SCMA算法利用数据流控制(streamcontrol)和部分干扰抑制技术(partialinterferencesuppression),从而为传输链路之间的干扰提供了优化的考虑。数据流控制(streamcontrol)是CSMA/CA(k)协议上面发展的而来的,其中CSMA/CA(k)利用时分复用的方式进行传输,每一次复用都会有k个数据流复用。当1个相互干扰的链路同时传输时,每个链路的个数据流用于抑制干扰从而提高总体的输出,而剩下的数据流才能够成功传输。部分干扰抑制技术是以数据流控制为基础的,当l个相互干扰的数据流同时传输时,当链路之间的距离在接收范围之外但在感应载波存在的距离之内,链路之间就会产生干扰,而距离越远,干扰越少,此时用于抑制干扰从而提高总体数据流传输的数据流的数目就会越少。分布式算法是以集中式算法的基础上发展的另一个优化算法,同时可以以集中式算法作为一个参考比。总体来说,文献1和文献2中记载的技术存在以下缺陷:文献1的集中式调度算法与分布式调度算法是以节点之间的优先级传输、信道状态、天线数、发送数据流等信息为基础来调度。在CSMA/CA协议中,每一个时隙(timeslot)都只会允许一个载波传送数据,当存在多个载波传送数据时就会存在链路之间相互干扰的情况,而文献1中没有考虑到这一种情况,进而大大地减少了传输数据的可靠性与通信质量。文献2虽然是考虑当存在多个载波传送数据时就会存在链路之间相互干扰的情况,并对这种情况进行了优化的考虑(即每当出现多载波公用信道的情况下怎样使得每一条链路能够找到最优的方案从而使得传输的数据最大)。但文献2没有考虑在文献1调度算法中所考虑到的节点之间的优先级传输、信道状态、天线数、发送数据流等信息,从而使得其调度算法中不能够通过信道状态、天线数、发送数据流等的信息在传输之前选择更优的发送节点与接收节点,这样就会使得总体吞吐量减少。技术实现要素:为了解决上述技术问题,本发明提供了一种通信质量高的基于MIMO异构自组织网络的自适应调度优化方法。本发明所采用的技术方案是:基于MIMO异构自组织网络的自适应调度优化方法,包括以下步骤:步骤S1:输入网络拓扑图G(V,E,K),其中,V是网络中的节点的数量,E是两个节点之间形成的链路的集合,K是每一个节点的天线数;步骤S2:将网络拓扑图G(V,E,K)转变变成数据流竞争图G’=(V’,E’,W),其中V’是在网络中的链路的集合,E’是在G’中任意两个节点之间的边缘,W代表的是一条链路两端的节点相互干扰的情况;步骤S3:通过数据流竞争图识别出所有的最大派别;步骤S4:把数据流竞争图中的每一条链路按照其根据其是否属于多个最大派别分为红色链路或者白色链路,其中,红色链路是属于两个或者两个以上的最大派别的链路,白色链路是只属于一个或不属于任何一个最大派别的链路;步骤S5:按照按比例公平模型,给每一条链路分配一个成功传输数据流的概率;步骤S6:把每一个节点分为贫穷节点和富裕节点,贫穷节点有资格作为发送节点和接收节点,富裕节点只能够作为接收节点;步骤S7:发送节点寻找接收节点,接收节点选择发送节点;步骤S8:选择数据传输方式,当接收节点能够接受的数据流的数量小于要发送的数据流的数量时,发送节点选择P-slot的方式传输数据,否则选择R-slot的方式传输数据;步骤S9:发送节点把数据发送到接收节点处。进一步地,步骤S3具体包括:步骤S31:在数据流竞争图中通过LexBFS找出所有的PEO;步骤S32:根据PEO中的节点数目,识别所有的最大派别。进一步地,步骤S5中,所述成功传输数据流的概率用按比例公平的概率进行表示,步骤S5具体包括:步骤S511:对所有的红色链路j,按照其牺牲出来用于提高总体传输数据量的数据流的多少来进行优先级大小排列,让Pj代表所有能够直接或者间接利用红色链路j牺牲的数据流来发送数据流的链路的集合,而潜力度p(j)代表集合Pj中的所有元素的数量,当p(j)的值越大,红色链路j的优先级越高;步骤S512:给每一个最大派别分配资源;步骤S513:按照优先级大小先后给每一条红色链路分配一个按比例分配概率;步骤S514:给每一条白色链路分配一个按比例分配概率。进一步地,步骤S511至步骤S514具体为:步骤S511:当链路i满足以下的条件时,即成为集合Pj中的元素:C1→∀c∈{M(i)\\M(j)}:L(c)={i}]]>其中,c表示最大派别,M(i)代表链路i所在的最大派别的集合,L(d)代表所有属于竞争区域d中的所有链路的集合;步骤S512:给每一个最大派别分配资源,设开始每一个最大派别的资源为1,即C→setofallmaximalcliquesinG′,∀c∈C,resource(c)=1;]]>步骤S513:按照如下方法给每一条红色链路i配一个按比例分配概率Findk=arg{min(ranki)},wherei∈J,J∈redlinksratek=min(min_resource1p(k),min_resource2)]]>∀c∈M(k),resource(c)=resource(c)-ratek]]>J=J-{k},re-ranki,∀i∈J]]>其中,rank是指链路的优先级,rate是给每一个链路分配的按比例分配概率,M(k)是链路k所在的最大派别的集合;min_resource1=min{resourcec},wherec∈{∪M(i),i∈Pj},min_resource2=min{resourced},whered∈M(j),min_resource1代表的是链路i在其所在的最大派别中的所有链路中分配最小的资源,而min_resource2代表的是Pj中所有的成员的所在最大派别中的所有链路中分配最小的资源;步骤S514:按照如下方法给每一条白色链路j分配一个按比例分配概率ratej=resourcecnum_whitelinks(c),wherec∈M(j)]]>其中,num_whitelinks(c)代表的是白色链路j所在的最大派别c中的所有白色链路的数目。进一步地,步骤S5具体包括:步骤S521:判断链路的状态是否可以从NO_CONTEND状态转变成CONTEND状态,若rand(0,1)>pnew(i),则不能转变成CONTEND状态,并对pold(i)的取值进行调整,使pold(i)=pold(i)(1-β)+α,其中,α=0.1,β=0.5,pold是指不考虑链路与链路之间的干扰但考虑加性噪声的情况下,每条链路能够成功传送数据的概率,当考虑链路之间存在干扰的情况下,pold就会调整成为pnew;否则,并进行下一步;步骤S522:链路的状态从NO_CONTEND状态转变成CONTEND状态并等待B(i)时间;步骤S523:判别信道是否处于忙或者冲突状态,忙的状态是指发送节点的所有可以传输的接收节点或者两跳之内的邻居节点都是处于发送或者接收的状态,冲突的状态是指接收方的邻居节点存在多个传输;如果信道处于忙或者冲突状态,则对成功传输数据流的概率进行调整,使pold(i)=pold(i)(1-β)+α,其中,α=0.1,β=0.5,同时,当链路为白色链路时,对pnew进行调整,使并从CONTEND状态转变成NO_CONTEND状态;如果信道并未处于忙或者冲突状态,则可获得信道进行传输,从CONTEND状态转变成ACQUIRE状态;步骤S524:判断链路i是红色链路还是白色链路;如果是红色链路,则从ACQUIRE状态转变成NO_CONTEND状态;如果是白色链路,则从ACQUIRE状态转变成SCHEDWHITELINKS状态,并进行下一步;步骤S525:对链路i的邻居链路的成功传输数据流的概率进行调整。进一步地,在步骤S6中,区分贫穷节点和富裕节点的方法是,当成立时,节点i为贫穷节点,否则节点i为富裕节点,其中(1)Si指的是节点i上的数据流的集合,代表的是节点i的优先级,而是i节点上第q个数据流的优先级,代表的是节点i的邻居节点中活跃的节点的集合,代表的是节点i的邻居节点中所有活跃的节点的平均优先级,代表的是节点i中所有用于传输给邻居节点的数据流的平均优先级,γi是在[0,1]上面的一个随机数;(2)其中代表的是节点j中的接收限制,代表的是节点i的邻居节点的集合。进一步地,步骤S7具体包括以下步骤:步骤S71:发送节点将信道信息、发送的数据流的数目、发送节点的ID、接收节点的ID放入RTS中,并发送给接收节点;步骤S72:接收节点选择优先级最高的发送节点;步骤S73:接收节点根据发送节点的RTS信息判断信道质量是否较好,当信道质量较差时,接收节点通知发送节点让其寻找另一个接收节点,当信道质量较好时,则进行下一步。进一步地,步骤S9包括步骤S911,发送节点按照数据流的优先级发送数据,当符合以下条件时,数据流的优先级最高:节点i中用于发送数据流的的优先级最高并且的优先级也是要最高,即:Wij⇐Wij\{W(Amax,Dij(q))|Dij(q)∈{Dij},q=1,...,|{Dij}|∪W(Aires(p),Dmax)|Aires(p)∈{Ai}res,p=1,...,|{Ai}res|}]]>其中,代表的是节点i中第j优先级的数据流的集合,代表的是接收节点i的第j个优先级的第q个元素,代表的是节点i上面剩余的可用的天线数;其中,W代表的是每一个节点的所有数据流的矩阵,代表的是发送节点i和接收节点之间能够成功传送数据流的概率。进一步地,步骤S9包括步骤S921,发送节点按照数据流的优先级发送数据,当符合以下条件时,数据流的优先级最高:节点i中用于发送数据流的的优先级最高并且的优先级也是要最高,即:Wij⇐Wij\{W(Amax,Dij(q))|Dij(q)∈{Dij},q=1,...,|{Dij}|∪W(Aires(p),Dmax)|Aires(p)∈{Ai}res,p=1,...,|{Ai}res|}]]>其中,代表的是节点i中第j优先级的数据流的集合,代表的是接收节点i的第j个优先级的第q个元素,代表的是节点i上面剩余的可用的天线数;max{i,j,k}W=max{i,j,k}W*Pnew(i*,d(s*q*)),其中,W代表的是每一个节点的所有数据流的矩阵,Pnew(i*,d(s*q*))代表的是发送节点i和接收节点d(s*q*)之间能够成功传送数据流的概率。进一步地,步骤S9包括步骤S920,判断接收节点是否处于弱信道,如果是,发送节点减少一条用于发射数据流的发射天线;如果否,发送节点把数据发送到接收节点处。本发明结合文献1与文献2的各自的优点,文献1中的分布式调度算法分别结合文献2中的集中式SCMA算法与分布式SCMA算法,使得分布式调度算法在考虑链路传输数据的过程中不仅仅是考虑节点之间的优先级传输、信道状态、天线数、发送数据流的数目等信息来选择不同的传输方式,尤其,在步骤S9中按照优先级传输数据,并在选择每一个发送节点时都会考虑其节点上面的天线数的数量为多少才进一步确认能够用于传输的数据流,而发送数据流的数目则是先考虑每一个发送节点可用的天线之后,才能够根据每一个节点上面的天线的数目从而决定传输数据流的数目;更进一步的是,能够考虑到链路在选择不同的传输方式之后在传输数据的过程中链路之间的干扰,根据每一条链路在传输的过程中与其他链路的竞争情况不同找到每一条链路传输的最优的方案,即步骤S4和S5,按照按比例公平模型给红色链路和白色链路分配成功传输数据流的概率,从而优化传输,进而更加能够保证传输数据流的可靠性,提高通信质量。为了更好地理解和实施,下面结合附图详细说明本发明。附图说明图1(a)是本发明实施例一的步骤S1的网络拓扑图;图1(b)是本发明实施例一的步骤S2的数据流竞争图;图2是本发明实施例一的步骤S3的LexBFS方法的流程图;图3是本发明实施例一的步骤S8的流程图;图4是本发明实施例一的步骤S9的流程图;图5是本发明实施例二的步骤S5的流程图;图6是本发明实施例二的步骤S9的流程图。具体实施方式本发明的基于MIMO异构自组织网络的自适应调度优化方法,结合了文献1和文献2,的优点构造出了两个新的分布式调度算法,此两个算法在发送数据流之前考虑到收发节点的天线数、发送数据流、信道状态等的信息选择不同的传输方式,在传输的过程中,根据每一条链路与其他链路的竞争情况不同从而选择出最优的传输链路传输数据,进一步提高了传输质量的可靠性。本专利的两个分布式调度算法从开始发送数据流到传输数据流过程最后到接收节点接收数据流这三个状态都考虑不同情况的干扰对于每一条链路传输数据流的影响,并对此作出了不同的优化,进一步提高总体的吞吐量。以下以具体实施例为例,讲解本发明的方法。在本说明书中,如无特别说明,同一字母标号的斜体形式与非斜体形式不作区分,均表示同一意义。实施例一、分布式调度算法与集中式SCMA结合步骤S1:输入网络拓扑图G(V,E,K),其中,V是网络中的节点的数量,E是两个节点之间形成的链路的集合,K是每一个节点的天线数。步骤S2:将网络拓扑图G(V,E,K)转变变成数据流竞争图G’=(V’,E’,W),其中V’是在网络中的链路的集合,E’是在G’中任意两个节点之间的边缘,W代表的是一条链路两端的节点相互干扰的情况。请参阅图1(a),其为本发明实施例的步骤S1的网络拓扑图。在图1中,有7个节点(vertex)随机分布在一定的空间范围内,根据每个节点之间的距离的大小可以得出网络拓扑图G(V,E)(networktopology),若两个节点之间的距离在传输范围内,那个这两个节点才有可能进行数据传输,否则就不能够进行数据传输。在G(V,E)中,V代表的是网络中的节点的数量,而E代表的是两个节点之间形成的链路的集合。一个节点与不同的节点之间会形成不同的链路。用v、w代表节点,若w要成为v的邻居节点的条件是能够与v节点之间成为链路(即两个节点之间的距离要在传输范围内)。请参阅图1(b),其为本发明实施例的步骤S2的数据流竞争图。图1(b)是由图1(a)中的网络拓扑图转变过来的数据流竞争图G’(V’,E’,W)(flowcontentionregion),就像文献3(Nandagopal,Thyagarajan,etal."AchievingMACLayerFairnessinWirelessPacketNetworks."InternationalConferenceonMobileComputing&Networking2000:87--98)中所说的一样,在每个节点的两跳范围内都是会与此节点竞争(在G’(V’,E’,W)中每个节点代表一条链路),而此节点与其竞争的节点就会形成竞争区域(contentionregion)。在G’(V’,E’,W)中,V’代表的是在网络中链路的集合,E’代表的是在G’中任意两个节点之间的边缘(edge),W是每个边缘的权重,代表着两个节点之间的干扰情况。与G(V,E)一样,让v’,w’代表在G’(V’,E’,W)中的两个节点(每个节点代表一条链路),w’若是v’的邻居节点就是必先要w’与v’能够形成一个边缘E’。步骤S3:通过数据流竞争图识别出所有的最大派别,具体包括:步骤S31:在数据流竞争图中通过LexBFS找出所有的PEO;步骤S32:根据PEO中的节点数目,识别所有的最大派别。从数据流竞争图中可以看出每一条链路与其他链路的竞争情况,同时可以通过数据流竞争图可以得出每条链路所在的派别(clique),而每一条链路可能属于多个不同的派别。每个派别的识别如下:首先在数据流竞争图中通过文献4(Rose,DonaldJ.,R.E.Tarjan,andG.S.Lueker."AlgorithmicAspectsofVertexEliminationonGraphs."SiamJournalonComputing5.2(1976):266-283.)公开的LexBFS(LexicographicBreadthFirstSearch,词典广度优先搜索)找出所有的PEO(perfecteliminationordering,完美消除排序),接着通过FulkersonandGross提出的算法(Fulkerson,D.R.,andO.A.Gross."IncidenceMatricesandIntervalGraphs."PacificJournalofMathematics15.3(1965):835-855.)识别所有的最大派别(maximalcliques)。请参阅图2,其为本发明实施例的步骤S3的LexBFS方法的示意图。LexBFS的思想是:如图2所示,首先找出在队列开头的节点,先定义为1,在从这个节点的邻居节点中找出一个节点定义为2(此节点之前还没被定义),接着又从2节点的周围节点中找出一个节点定义为3节点,如此循环下去就可以把所有的节点都定义出来。然后选择最高节点10不变(这里每一个节点都是代表一条链路),再往下一个节点(from10to1),如图2中连接的链路,若每条链路中有连接的,而且大于此节点的节点可以作为PEO(perfecteliminationgraph)中的一位成员(括号里面的是此节点的PEO成员),每一个节点和它的成员都会产生一个PEO,包括本身的节点。FulkersonandGross的算法思想是:根据LexBEX算法的PEO,其中每个PEO中节点数目越多,越先被识别为最大派别(maximalclique),当一个PEO被识别为最大派别之后,再考虑剩下的PEO,用同样的方式就可以把所有的最大派别识别出来。步骤S4:把数据流竞争图中的每一条链路按照其根据其是否属于多个最大派别分为红色链路或者白色链路,其中,红色链路是属于两个或者两个以上的最大派别的链路,白色链路是只属于一个或不属于任何一个最大派别的链路。在数据流竞争图中,每个节点代表的是一条链路,每个链路根据自己的是否属于多个最大派别(maximalclique)可以分为红色链路(redlinksorbottlenecklinks)和白色链路(whitelinks)。红色链路是属于两个或者两个以上的最大派别的链路,反之就是白色链路。这样做的目的就是可以根据每个链路自己与其他链路的竞争情况作出分类从而使得不同特点的链路按照不用的方法进行处理,而红色链路与其他链路的竞争情况比白色链路要严重。步骤S5:按照按比例公平模型,给每一条链路分配一个成功传输数据流的概率,所述成功传输数据流的概率用按比例公平的概率进行表示,具体包括步骤S511至S514:步骤S511:对所有的红色链路j,按照其牺牲出来用于提高总体传输数据量的数据流的多少来进行优先级大小排列,让Pj代表所有能够直接或者间接利用红色链路j牺牲的数据流来发送数据流的链路的集合,而潜力度p(j)代表集合Pj中的所有元素的数量,当p(j)的值越大,红色链路j的优先级越高;当链路i满足以下的条件时,即成为集合Pj中的元素:C1→∀c∈{M(i)\\M(j)}:L(c)={i}]]>其中,c表示最大派别,M(i)代表链路i所在的最大派别的集合,L(d)代表所有属于竞争区域d中的所有链路的集合。步骤S512:给每一个最大派别分配资源,设开始每一个最大派别的资源为1,即C→setofallmaximalcliquesinG′,∀c∈C,resource(c)=1;]]>步骤S513:按照优先级大小先后给每一条红色链路分配一个按比例分配概率;具体是:Findk=arg{min(ranki)},wherei∈J,J∈redlinksratek=min(min_resource1p(k),min_resource2)]]>∀c∈M(k),resource(c)=resource(c)-ratek]]>J=J-{k},re-ranki,∀i∈J]]>其中,rank是指链路的优先级,rate是给每一个链路分配的按比例分配概率,M(k)是链路k所在的最大派别的集合;min_resource1=min{resourcec},wherec∈{∪M(i),i∈Pj},min_resource2=min{resourced},whered∈M(j),min_resource1代表的是链路i在其所在的最大派别中的所有链路中分配最小的资源,而min_resource2代表的是Pj中所有的成员的所在最大派别中的所有链路中分配最小的资源;步骤S514:给每一条白色链路分配一个按比例分配概率,具体是:ratej=resourcecnum_whitelinks(c),wherec∈M(j)]]>其中,num_whitelinks(c)代表的是白色链路j所在的最大派别c中的所有白色链路的数目。当一条链路w与其他n条链路之间存在着竞争的情况,而此链路w与其他每一条链路形成竞争区域(contentionregion)(即链路w属于n个竞争区域)。在这种情况下,链路w的按比例分配概率是而其他每一条与链路w竞争的链路的按比例分配概率是这样,牺牲了链路w一部分要发送出去的数据流,但是能够总体上面提高了数据流的传输,进而进一步提高总体吞吐量。因此,在给每一条链路分配按比例分配概率之前,首先先找出那些属于多个竞争区域的链路(即红色链路)先去分配按比例分配概率,接着再给剩下的链路(即白色链路)分配按比例分配概率。对于所有的红色链路应该按照其牺牲出来的数据流多少来给每一条红色链路进行优先级大小的排列(即最多链路能够利用链路w牺牲出来的数据流来提高其传输数据流的总量的,那链路w就是优先级最高,优先级别为0)。让i,j代表链路,而j代表的是红色链路。M(i)代表的是链路i所在的最大派别的集合,而L(d)代表的是所有属于竞争区域d中所有的链路的集合。让Pj代表的是所有能够直接或者间接利用链路j牺牲的数据流来发送数据流的链路的集合(包括链路j本身),而p(j)称为潜力度(potentialdegree),代表的是集合Pj中所有元素的数量。当p(j)的值越大,代表的是链路j的级别越高(最高为0),也就是说越多链路利用链路j牺牲的数据流来提高发送的数据流。每一条红色链路j中所有能够直接或者间接利用链路j牺牲的数据流来发送数据流的链路,都是满足以下的条件才能够成为集合Pj中的元素,即:C1→∀c∈{M(i)\\M(j)}:L(c)={i}]]>上述公式的含义是:对于每一条红色链路j,想要成为Pj中的成员就要满足以下的要求之一:第一,对于任一条链路i,链路i的最大派别包含于链路j的最大派别之中(即),那么链路i必定是其中链路j中的Pj的一个成员。第二,当满足条件时(即链路i的最大派别与链路j的最大派别有交集),只要满足以下C1或者C2中任意的一个条件,那么链路i都是Pj的一个成员。在C1中,M(i)\\M(j)代表的是在M(i)中有,但是在M(j)中没有的一组链路的集合。当这一组链路都能够与链路i形成竞争区域时,那么链路i就能够满足C1的条件从而成为Pj的一个成员。在C2中,M(i)∩M(j)代表的是链路i中的最大派别与链路j之间的最大派别中相同的链路的集合,而这些链路形成了竞争区域c。当Pj中已有的所有成员k都是能够与竞争区域c中的链路相互竞争时(即k与竞争区域c中的链路能够形成竞争区域),当存在k属于的最大派别中的某条链路d,当链路d只与链路i,链路j,以及Pj中的成员k之间相互竞争时,此时的链路i就满足C2的要求成为Pj中的成员。当所有的红色链路j能够找到所有利用链路j牺牲的发送数据流从而提高自己发送数据流的链路i之后,根据每一条链路的Pj的成员的大小不同从而能够给每一条红色链路j排等级(rank)。当Pj的成员越多,p(j)的值越大,等级越高(最高为0)。给每一条红色链路j排等级的目的就是为了下面能够按照等级的大小先后给每一条红色链路分配按比例分配概率,当所有的红色链路j都分配好所有的按比例分配概率之后就开始对所有的白色链路分配按比例分配概率。在给每一条链路分配按比例分配概率之前,首先要给数据流竞争图中所有的最大派别分配资源(设开始每一个最大派别的资源为1),即:C→setofallmaximalcliquesinG′,∀c∈C,resource(c)=1]]>每当给每一个最大派别c中的一条链路分配了按比例分配概率(给链路分配的资源)之后,那么最大派别c的资源都要减去此链路的按比例分配概率(减去已消耗的资源),即:当最大派别c中所有的链路都分配完了按比例分配概率之后,最大派别中的资源也都消耗完。给所有的链路分配按比例分配概率应按照如下条件:(1)当链路i属于红色链路时:Findk=arg{min(ranki)},wherei∈J,J∈redlinksratek=min(min_resource1p(k),min_resource2)]]>∀c∈M(k),resource(c)=resource(c)-ratek]]>J=J-{k},re-ranki,∀i∈J]]>给链路分配按比例分配概率第一步是先找出红色链路中等级最高的链路(即ranki=0),第二步就是给每一条链路分配按比例分配概率,即ratek=min(min_resource1p(k),min_resource2)]]>其中:min_resource1=min{resourcec},wherec∈{∪M(i),i∈Pj}min_resource2=min{resourced},whered∈M(j)min_resource1代表的是链路i在其所在的最大派别中的所有链路中分配最小的资源(即按比例分配概率最小的),而min_resource2代表的是Pj中所有的成员的所在最大派别中的所有链路中分配最小的资源。当每一条链路分配好按比例分配概率之后,那么其链路所在的最大派别c的资源都要减去此链路的按比例分配概率。最后就是再找出其中等级最高的链路(除去已分配的链路),这样下来就会得到每一条红色链路的按比例分配概率(每一条链路的资源)。当所有的红色链路都被分配好按比例分配概率之后,接下来就要给每一条白色链路分配按比例分配概率。(2)当链路j属于白色链路时:其中num_whitelinks(c)代表的是白色链路j所在的最大派别c中的所有白色链路的数目。这样整个过程下来,每一条链路都能够分配按比例分配概率。步骤S6:把每一个节点分为贫穷节点和富裕节点,贫穷节点有资格作为发送节点和接收节点,富裕节点只能够作为接收节点;具体地,区分贫穷节点和富裕节点的方法是,当成立时,节点i为贫穷节点,否则节点i为富裕节点,其中(1)Si指的是节点i上的数据流的集合,代表的是节点i的优先级,而是i节点上第q个数据流的优先级,代表的是节点i的邻居节点中活跃的节点的集合,代表的是节点i的邻居节点中所有活跃的节点的平均优先级,代表的是节点i中所有用于传输给邻居节点的数据流的平均优先级,γi是在[0,1]上面的一个随机数;(2)其中代表的是节点j中的接收限制,代表的是节点i的邻居节点的集合。分布式调度算法与集中式算法不同,集中式算法在调度的时候认为所有的节点都是在同一个信道状态下面进行传输并且传输时始终是以节点的平均数据流最大的标准优先传输;但是,对于分布式算法,每一个节点首先估计其信道状态,天线数,要发送的数据流的数量等的信息,按照每一个节点自身的特点选择传输数据的方式。对于不考虑干扰的情况下,集中式调度算法的吞吐量是比起分布式算法的吞吐量要大,但是,对于分布式算法来讲,其能够保证节点传输的可靠性和质量。在进行分布式算法调度之前,首先要对于所有的节点根据每个节点自身的特点分为“贫穷”节点(poornode)和“富裕”节点(richnode),还有就是根据每一个节点自身的天线数目分配将要发送的数据流的数目。“贫穷”节点是既可以作为发送节点同时又可以作为接收节点,但是对于“富裕”节点就只能够作为接收节点。“贫穷”节点的优先级是大于接收节点的优先级,这样做让发送节点有一个更高的优先级可以减少发送节点在传输的过程中的延时,同时也能够保证传输的有效性和可靠性。对于“贫穷”节点和“富裕”节点的识别可以用一个不等式来识别。当成立时,节点i可以作为发送节点,否则节点i就只能够作为接收节点。其中,代表的是节点i的优先级,而是i节点上第q个数据流的优先级。代表的是节点i的邻居节点中活跃的节点的集合,因此,代表的是节点i的邻居节点中所有活跃的节点的平均优先级。代表的是节点i中所有用于传输给邻居节点的数据流的平均优先级。γi是在[0,1]上面的一个随机数。其中代表的是节点j中的接收限制,代表的是节点i的邻居节点的集合。步骤S7:发送节点寻找接收节点,接收节点选择发送节点,具体包括以下步骤:步骤S71:发送节点将信道信息、发送的数据流的数目、发送节点的ID、接收节点的ID放入RTS中,并发送给接收节点;步骤S72:接收节点选择优先级最高的发送节点;步骤S73:接收节点根据发送节点的RTS信息判断信道质量是否较好,当信道质量较差时,接收节点通知发送节点让其寻找另一个接收节点,当信道质量较好时,则进行下一步。当所有的节点已经被分好是“贫穷”节点还是“富裕”节点之后,让所有的发送节点中所有能够传输的数据流选择相应的天线准备将数据发送出去。上面所有的准备工作完成之后就开始调度算法。发送节点首先把信道信息,发送的数据流的数目,发送节点的ID与接收节点的ID等的信息放入RTS中,并发送给接收节点。ID是用于标识每个节点的,而每个节点的都会有一个不同的ID。每一个接收节点可能会收到很多来自不同节点的RTS,而接收节点就会根据每个节点的优先级选择优先级最高的发送节点,当优先级相同的时候,接收节点就会选择ID更高级别的发送节点,之后,接收节点就会根据发送节点中RTS所包含的信息进行分析,当接收节点发现与发送节点之间存在很长的距离或者接收节点与接收节点之间的信道是严重衰落信道,那么接收节点会通过CTS发送给发送节点让其寻找一个更可靠的接收节点。步骤S8:选择数据传输方式,当接收节点能够接受的数据流的数量小于要发送的数据流的数量时,发送节点选择P-slot的方式传输数据,否则选择R-slot的方式传输数据。当信道质量是较好的时候,就要考虑发送节点与接收节点之间的选择P-slot还是R-slot的进行传输。代表的是发送节点传输给接收节点k的数据流的数量,而代表的是节点k接受数据流的数目的最大限制。若时,证明接收节点k能够接收所有的发送节点发送的数据流,那就是能够用R-slot的方式传输数据流,否则就只能够使用P-slot(即接收节点k不能够全部接收发送节点传输的数据流)。当传输方式确定好了之后,接收节点就会把传输方式,接收节点的接收限制,还有接收节点的ID等的信息放入CTS中并发送给发送节点。当发送节点接收了接收节点的CTS之后,确定能够与发送节点进行数据传输和传输的方式之后就会开始给接收节点传输数据。请参阅图3,其为本发明实施例的步骤S8的流程图。如图3所示,框图①中刚开始时候每个节点剩余的天线数与剩余的数据流的数目都是等于刚开始分配的节点的天线数和数据流的数目,其中{Ai}res代表节点i剩余的可用的天数数,{Ai}代表的就是节点i所有天线数的集合。是节点i中还没有被发送出去的剩余的数据流的数目,是节点i被分配到所有要发送出去的数据流的数目。框图②是确认节点i是否还有剩余的数据流没有被发送如果还有没有被发送的数据流就要被发送出去,框图③是用来确定其中节点i中还没有被发送出去的数据流选择的是P-slot的方式传输还是R-slot的方式传输。当节点i的接收节点不能够全部接受发送节点i的剩余未发送出去的数据流的时候,此时就会选择P-slot方式传输数据,否则就会选择R-slot的方式传输数据。代表的是节点i的接收节点在第j个优先级能够接收到数据流的集合(j=1是最高级别),这个是由于每一个节点i的所有的数据流都会有其自己的优先级,可能不同的数据流的优先级大小一样。例如:节点t有个数据流,而所有的数据流可以划分为lt个等级,而节点t的接收节点i的接收数据流就会被分为个集合,而接收节点i上面第j个优先级第q个元素可以写成框图④与框图⑤分别就是P-slot的传输方式和R-slot的传输方式,从这个两个传输方式上面来看,它们的过程都是都用子程序-OPPORTUNITICTIC_ALLOCATION来实现的,只是两个传输方式的参数不同。在P-slot的传输方式中,接收节点i不能够全部接收发送节点传输的所有的数据流,因此发送节点还有剩余的数据流还没有发送出去。但是,在R-slot的传输方式中的情况与P-slot的传输方式情况恰好相反,即发送节点中所有传输的数据流能够全部地给接收节点i接收,并且接收节点i可能还有剩余的天线数去接收其他发送节点的传输的数据流。步骤S9:发送节点把数据发送到接收节点处,具体包括以下步骤:步骤S911,发送节点按照数据流的优先级发送数据,当符合以下条件时,数据流的优先级最高:节点i中用于发送数据流的的优先级最高并且的优先级也是要最高,即:Wij⇐Wij\{W(Amax,Dij(q))|Dij(q)∈{Dij},q=1,...,|{Dij}|∪W(Aires(p),Dmax)|Aires(p)∈{Ai}res,p=1,...,|{Ai}res|}]]>其中,代表的是节点i中第j优先级的数据流的集合,代表的是接收节点i的第j个优先级的第q个元素,代表的是节点i上面剩余的可用的天线数;max{i,j,k}W=max{i,j,k}W*Pnew(i*,d(s*q*)),其中,W代表的是每一个节点的所有数据流的矩阵,Pnew(i*,d(s*q*))代表的是发送节点i和接收节点d(s*q*)之间能够成功传送数据流的概率。步骤S920,判断接收节点是否处于弱信道,如果是,发送节点减少一条用于发射数据流的发射天线;如果否,发送节点把数据发送到接收节点处。请参阅图4,其为本发明实施例的步骤S911和S920的流程图。在图4中,框图①-②中,中,代表的是节点i中第j优先级的数据流的集合,其中k是代表节点i中用于发送第j优先级的数据流的天线的数目,代表的是接收节点i的第j个优先级的第q个元素,代表的是节点i上面剩余的可用的天线数,而l代表的是当前已经发送出去的数据流的数量,代表的是数据流的容量,用计算出来,其中ps代表的是数据流s的发射功率(transmissionpower),当发射功率越大的时候,发送信号的质量就越好,但是,发射功率增大就会涉及到能量消耗的问题,这就需要有一个折衷。hs是一个信道向量,其取值是信道矩阵中的每一列。N0代表的是噪声系数。代表的是在接收节点处对接受数据流造成干扰的一组数据流的集合。框图④是用于在第i个节点上面第j优先级中所有的数据流选择最优的先发送出去,其中最优的条件就是节点i中用于发送数据流的的优先级最高并且的优先级也是要最高,此时的数据流是处于最高级别,优先发送,但是在寻找最优的数据流时要排除两种情况:的优先级最高但的优先级不是最高还有的优先级不是最高但的优先级最高,即Wij⇐Wij\{W(Amax,Dij(q))|Dij(q)∈{Dij},q=1,...,|{Dij}|∪W(Aires(p),Dmax)|Aires(p)∈{Ai}res,p=1,...,|{Ai}res|}]]>每条链路与其邻居链路之间存在竞争的情况就是使得其传输包裹成功的概率降低,而每一条链路根据自己竞争的情况不同,传输数据成功的概率也会是不同。因此,在框图④中,选择了最优的数据流发送出去之后,由于链路在传输的过程中与其他链路之间存在干扰的情况,根据不同的干扰情况成功传输数据流的概率也是不一样的,以下是分布式调度算法分别与集中式SCMA结合后考虑链路之间干扰的处理方式:当分布式调度算法与集中式SCMA结合时:其中,W代表的是每一个节点的所有数据流的矩阵,代表的是发送节点i和接收节点之间能够成功传送数据流的概率。框图⑤-⑧中,k代表的是天线数,l代表的是已经发送出去的数据流的数目,代表的是节点i上剩余的还没有发送出去的数据流的数目。框图⑤中,判断信道是否是弱信道,若发现信道是弱信道的时候,接下来判断发送节点i上面是否还存在着剩下的没有发送出去的数据流(如框图⑥所示),当还有剩下的没有发送出去的数据流时,天线的数目k减少一条,剩余的还没有发送出去的数据流的数目减少1,同时已经发送出去的数据流的数目l加上1(如框图⑧);若当没有剩下的没有发送出去的数据流时,天线的数目k减少一条(如框图⑦)。当发现接收节点处于弱信道(weakchannel)时,减少一条发射天线使得剩下能够用于发送数据流的每一条天线的发射功率增大,即能够使得通信质量提高,减少包裹丢失的概率。发送完最高级别的数据流之后接着寻找下一个最优的数据流发送出去,如此循环能够把每一个节点上面的每一个数据流都能够调度,同时也考虑到信道环境等的问题,对信道环境差的情况最初相应的处理,进一步提高通信质量。当接收节点全部接受发送节点传输的数据流之后,就会把接收节点的ID,接收数据流的数量,丢失包裹的数目等的信息放入ACK中再发送给发送节点。实施例二、分布式调度算法与分布式SCMA结合实施例二和实施例一大体相同,仅在步骤S5和S9存在区别。步骤S521:判断链路的状态是否可以从NO_CONTEND状态转变成CONTEND状态,若rand(0,1)>pnew(i),则不能转变成CONTEND状态,并对pold(i)的取值进行调整,使pold(i)=pold(i)(1-β)+α,其中,α=0.1,β=0.5,pold是指不考虑链路与链路之间的干扰但考虑加性噪声的情况下,每条链路能够成功传送数据的概率,当考虑链路之间存在干扰的情况下,pold就会调整成为pnew;否则,并进行下一步;步骤S522:链路的状态从NO_CONTEND状态转变成CONTEND状态并等待B(i)时间;步骤S523:判别信道是否处于忙或者冲突状态,忙的状态是指发送节点的所有可以传输的接收节点或者两跳之内的邻居节点都是处于发送或者接收的状态,冲突的状态是指接收方的邻居节点存在多个传输;如果信道处于忙或者冲突状态,则对成功传输数据流的概率进行调整,使pold(i)=pold(i)(1-β)+α,其中,α=0.1,β=0.5,同时,当链路为白色链路时,对pnew进行调整,使并从CONTEND状态转变成NO_CONTEND状态;如果信道并未处于忙或者冲突状态,则可获得信道进行传输,从CONTEND状态转变成ACQUIRE状态;步骤S524:判断链路i是红色链路还是白色链路;如果是红色链路,则从ACQUIRE状态转变成NO_CONTEND状态;如果是白色链路,则从ACQUIRE状态转变成SCHEDWHITELINKS状态,并进行下一步;步骤S525:对链路i的邻居链路的成功传输数据流的概率进行调整。在按比例公平模型(modelingproportionalfairness)中,若不考虑链路与链路之间干扰但考虑加性噪声的情况下,每条链路能够成功传送数据有一定的概率,这个概率称为pold(persistencevalue)。当考虑链路之间存在竞争的情况下(即信道处于忙或者冲突的情况),而pold就会调整成为pnew。在文献3(Nandagopal,Thyagarajan,etal."AchievingMACLayerFairnessinWirelessPacketNetworks."InternationalConferenceonMobileComputing&Networking2000:87--98)中,在比例公平模型下(proportionalfairnessmodel)的调整的机制如下:其中ri是信道分配率(channelallocationrate),pi代表的是链路i竞争损失概率(contentionlossprobability)。α与β分别是“utilityconstant”和“penaltyconstant”。α与β都是常量,但是α与β的取值是最大化利用率和最小化损失概率之间的折衷。当α变大,β变小的时候,就会使得输出更大;当α变小,β变大的时候就会越接近公平分配的实现。代表的是信道分配率的变化率,这个是调整机制中的主体部分,当的时候,此时的信道信道分配率达到最优,此时是传输数据最大。若信道处于忙或者冲突的情况下,每条链路的pold在原有的基础下就会对于本身有一个的调整(即)。K代表数据流的集合,每当pold转变成pnew时,Kold转变成Knew且满足等式Kold=K≥Knew。对于不同“颜色”的链路,pold与pnew、Kold与Knew的关系是不一样的。在红色链路中,pold=pnew以及Kold=Knew.在白色链路中,以及其中white_count是链路i所在最大派别中白色链路的数量。请参阅图5,其为本发明实施例二的步骤S5的流程图,具体是分布式SCMA算法的步骤。有一定数量的节点随机分布在一定的空间中,他们由于没有中心节点所以相互之间的地位平等,而且在自组织网络中没有基站,所有节点之间可以相互传输信息。在相互传输信息的同时可以具有移动性。两个节点之间的传输形成一条链路,两个节点之间传输的过程是:发送方就会先发送RTS给接收方,接收方收到发送方发送的RTS后就会发送CTS确认发送方可以发送数据给接收方。因此,发送方就会开始与接收方传输信息,当信息传输完毕之后,接收方就会给发送方发送ACK确认数据已经接收完毕。这个过程所持续的时间叫slot。在本专利的算法中,每条链路可能会经历四个状态:NO_CONTEND,CONTEND,ACQUIRE,SCHEDWHITELINKS。所有的链路都是先从NO_CONTEND状态(如框图②)开始。在本实施例的算法中,框图③判别链路的状态是否可以从NO_CONTEND状态转变成CONTEND状态。链路想要传输数据的时候,就会想要获得信道进行传输,此时,状态应该是从NO_CONTEND状态转变成CONTEND状态,但是,状态转变成功的概率就只有pold。在红色链路中,pold=pnew以及Kold=Knew,在白色链路中,以及其中whitecount是链路i所在最大派别中白色链路的数量。Kold=K≥Knew,K代表的是数据流的集合。rand(0,1)代表的是在[0,1]区间之内随机选择的一个数,当这个数不大于pold时,此时候的状态才能够从NO_CONTEND状态转变成CONTEND状态。框图④代表的是从NO_CONTEND状态转变成CONTEND之前,更新一下pold的值加上α,而pnew的更新则是按照上述的进行更新,其中α=0.1,β=0.5。框图⑤表示,当状态从NO_CONTEND状态转变成CONTEND状态之后整个过程先延迟B(i)个等待时间,这样做的目的可以防止有些链路传输延时从而导致下面判别是否有载波时候(有没有其他链路暂用信道)发生错误。当进入CONTEND状态并等待B(i)时间之后,接下来先去判别信道是否是处于忙(busy)和冲突(collision)的状态。忙(busy)的状态就是发送方的所有可以传输的接收方或者两跳之内的邻居节点都是处于发送或者接收的状态。冲突(collision)就是在接收方的邻居节点存在多个传输就会引起冲突。框图⑥就是判别是否存在忙和冲突两种情况。当出现busy或者collision的两种情况中的一种时,要对其中的链路的persistencevalue进行一个调整,这个调整是整个persistencevalue加上信道分配率的变化率(therateofchangeofcontentionallocationrate),即按照公式:进行更新,然后状态就会从CONTEND状态转重新变成NO_CONTEND状态。如框图⑦所示,当出现信道忙或者冲突的情况的时候,则对pold的取值进行调整,pold(i)=pold(i)(1-β)+α,其中pold(i)代表的是成功传送的数据流的概率,α=0.1,β=0.5,同时当链路i为白色链路的时候,此时要更新pnew,按照公式:进行更新。当链路的没有存在和冲突时,此时就可以证明信道是空闲的状态,可以获得信道进行传输。此时的状态应该是从CONTEND状态转变成ACQUIRE状态从而可以获得信道。当进入ACQUIRE状态之后,先去判别其中的链路i是白色链路还是红色链路。如果是红色链路那么直接从ACQUIRE状态直接转变成NO_CONTEND状态,但是如果是白色链路的时候,就要进行下一步的处理。那就是对链路i的邻居链路的persistencevalue进行调整,即按照公式:进行调整。如果其邻居链路是白色链路的时候,就要对其persistencevalue进行一个调整,这个调整就是整个persistencevalue加上信道分配率的变化率(therateofchangeofcontentionallocationrate)。经过整个状态的转变就可以得到每一条链路的persistencevalue,而persistencevalue就是每一条链路传输数据的传输概率。此算法与集中式调度的算法和分布式调度的算法的结合就可以得出在存在干扰的情况下集中式调度和分布式调度的节点之间传输的情况并可以根据相关的结果和情况进行对算法的改进。步骤S9:发送节点把数据发送到接收节点处,具体包括以下步骤:步骤S921:发送节点按照数据流的优先级发送数据,当符合以下条件时,数据流的优先级最高:节点i中用于发送数据流的的优先级最高并且的优先级也是要最高,即:Wij⇐Wij\{W(Amax,Dij(q))|Dij(q)∈{Dij},q=1,...,|{Dij}|∪W(Aires(p),Dmax)|Aires(p)∈{Ai}res,p=1,...,|{Ai}res|}]]>其中,代表的是节点i中第j优先级的数据流的集合,代表的是接收节点i的第j个优先级的第q个元素,代表的是节点i上面剩余的可用的天线数;max{i,j,k}W=max{i,j,k}W*Pnew(i*,d(s*q*)),其中,W代表的是每一个节点的所有数据流的矩阵,Pnew(i*,d(s*q*))代表的是发送节点i和接收节点d(s*q*)之间能够成功传送数据流的概率。步骤S920,判断接收节点是否处于弱信道,如果是,发送节点减少一条用于发射数据流的发射天线;如果否,发送节点把数据发送到接收节点处。请参阅图6,其为本发明实施例的步骤S921和S920的流程图。在图6中,框图①-②中,中,代表的是节点i中第j优先级的数据流的集合,其中k是代表节点i中用于发送第j优先级的数据流的天线的数目,代表的是接收节点i的第j个优先级的第q个元素,代表的是节点i上面剩余的可用的天线数,而l代表的是当前已经发送出去的数据流的数量,代表的是数据流的容量,用计算出来,其中ps代表的是数据流s的发射功率(transmissionpower),当发射功率越大的时候,发送信号的质量就越好,但是,发射功率增大就会涉及到能量消耗的问题,这就需要有一个折衷。hs是一个信道向量,其取值是信道矩阵中的每一列。N0代表的是噪声系数。代表的是在接收节点处对接受数据流造成干扰的一组数据流的集合。框图④是用于在第i个节点上面第j优先级中所有的数据流选择最优的先发送出去,其中最优的条件就是节点i中用于发送数据流的的优先级最高并且的优先级也是要最高,此时的数据流是处于最高级别,优先发送,但是在寻找最优的数据流时要排除两种情况:的优先级最高但的优先级不是最高还有的优先级不是最高但的优先级最高,即Wij⇐Wij\{W(Amax,Dij(q))|Dij(q)∈{Dij},q=1,...,|{Dij}|∪W(Aires(p),Dmax)|Aires(p)∈{Ai}res,p=1,...,|{Ai}res|}]]>每条链路与其邻居链路之间存在竞争的情况就是使得其传输包裹成功的概率降低,而每一条链路根据自己竞争的情况不同,传输数据成功的概率也会是不同。因此,在框图④中,选择了最优的数据流发送出去之后,由于链路在传输的过程中与其他链路之间存在干扰的情况,根据不同的干扰情况成功传输数据流的概率也是不一样的,以下是分布式调度算法分别与集中式SCMA结合后考虑链路之间干扰的处理方式:当分布式调度算法与分布式SCMA结合:max{i,j,k}W=max{i,j,k}W*Pnew(i*,d(s*q*))。W代表的是每个节点的所有的数据流的一个矩阵,Pnew(i*,d(s*q*))代表的是发送节点i和接收节点d(s*q*)之间能够成功传送数据流的概率。框图⑤-⑧中,k代表的是天线数,l代表的是已经发送出去的数据流的数目,代表的是节点i上剩余的还没有发送出去的数据流的数目。框图⑤中,判断信道是否是弱信道,若发现信道是弱信道的时候,接下来判断发送节点i上面是否还存在着剩下的没有发送出去的数据流(如框图⑥所示),当还有剩下的没有发送出去的数据流时,天线的数目k减少一条,剩余的还没有发送出去的数据流的数目减少1,同时已经发送出去的数据流的数目l加上1(如框图⑧);若当没有剩下的没有发送出去的数据流时,天线的数目k减少一条(如框图⑦)。当发现接收节点处于弱信道(weakchannel)时,减少一条发射天线使得剩下能够用于发送数据流的每一条天线的发射功率增大,即能够使得通信质量提高,减少包裹丢失的概率。发送完最高级别的数据流之后接着寻找下一个最优的数据流发送出去,如此循环能够把每一个节点上面的每一个数据流都能够调度,同时也考虑到信道环境等的问题,对信道环境差的情况最初相应的处理,进一步提高通信质量。当接收节点全部接受发送节点传输的数据流之后,就会把接收节点的ID,接收数据流的数量,丢失包裹的数目等的信息放入ACK中再发送给发送节点。本发明实现了以下有益的技术效果:在现有技术中,Chu,Shan,X.Wang,Y.Yang等人的分布式算法在调度之前考虑了收发节点的天线数、节点的优先级、信道状态、发送的数据流等的信息,再根据这些信息选择不同的数据传输方式传输数据流,但是,并没有考虑链路在传输的过程中因为链路之间的距离等因素的关系,链路之间会产生干扰,进而大大地减少了传输数据的可靠性与通信质量。Sundaresan,Karthikeyan等人的集中式SCMA算法与分布式SCMA算法考虑了链路在传输数据过程中链路之间的干扰并对于每一个链路在不同干扰下选择一条最优的链路传输方式。本发明结合文献1与文献2的各自的优点,文献1中的分布式调度算法分别结合文献2中的集中式SCMA算法与分布式SCMA算法,使得分布式调度算法在考虑链路传输数据的过程中不仅仅是考虑节点之间的优先级传输、信道状态、天线数、发送数据流的数目等信息来选择不同的传输方式,尤其,在步骤S9中按照优先级传输数据,并在选择每一个发送节点时都会考虑其节点上面的天线数的数量为多少才进一步确认能够用于传输的数据流,而发送数据流的数目则是先考虑每一个发送节点可用的天线之后,才能够根据每一个节点上面的天线的数目从而决定传输数据流的数目;更进一步的是,能够考虑到链路在选择不同的传输方式之后在传输数据的过程中链路之间的干扰,根据每一条链路在传输的过程中与其他链路的竞争情况不同找到每一条链路传输的最优的方案,即步骤S4和S5,按照按比例公平模型给红色链路和白色链路分配成功传输数据流的概率,从而优化传输,进而更加能够保证传输数据流的可靠性,提高通信质量。本发明并不局限于上述实施方式,如果对本发明的各种改动或变形不脱离本发明的精神和范围,倘若这些改动和变形属于本发明的权利要求和等同技术范围之内,则本发明也意图包含这些改动和变形。当前第1页1 2 3
相关技术
网友询问留言
已有0条留言
- 还没有人留言评论。精彩留言会获得点赞!
1