基于信令数据的用户职住地分析方法与流程
本发明涉及一种基于信令数据的用户职住地分析方法。
背景技术:
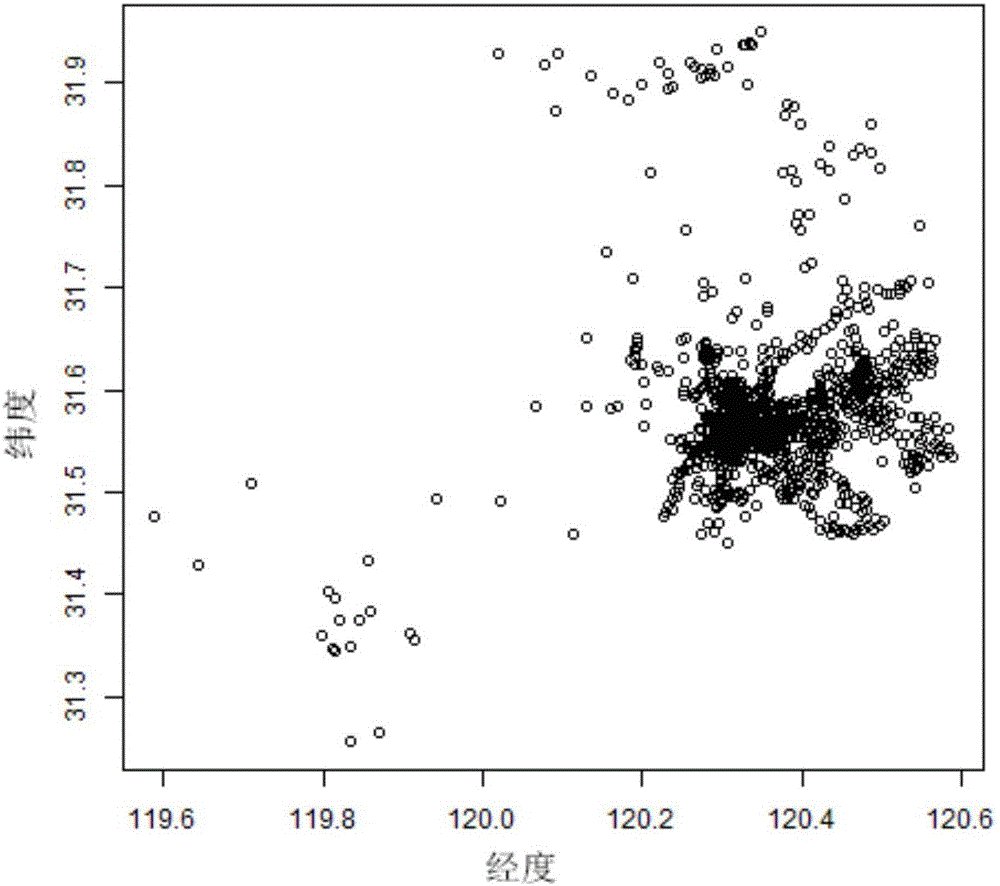
:LTE网络记载了人们出行信息,包括用户一天的位置,在某地驻留时间等,而这些数据一般是有规律的,譬如,对于正常工作日工作的人来说,白天高频出现并且逗留地为工作地,晚上及周末高频出现并逗留地为居住地,甚至可以根据日常高频出现小区绘制出用户日常出行轨迹。对于运营商来说,如何挖掘出用户常驻地信息,甚至进一步挖掘出用户的工作地及居住地或职住地,从而运营商可以有针对性、有目的地开展营销工作,可以对用户进行定点营销或网络测试,这对于宽带业务、手机入网等都是非常有益的。技术实现要素:本发明的目的是提供一种基于信令数据的用户职住地分析方法,借助移动运营商信令数据及基站信息,在实现用户的小区经纬度匹配后,根据基于地理空间位置的聚类和基于频次及时长的小区评分模型实现,实现居民居住地、工作地判定,解决现有技术中存在的如何挖掘出用户常驻地信息,甚至进一步挖掘出用户的工作地及居住地或职住地的问题。本发明的技术解决方案是:一种基于信令数据的用户职住地分析方法,包括:根据用户在设定时间段内的小区驻留信息,利用权重算法清除干扰小区得到用户重要小区后,对得到的用户重要小区进行基于地理位置信息的空间聚类,把聚类中密集出现的区域,划分为常驻地;根据驻留时间对常驻地中各小区设置不同权重,来挖掘用户常驻小区;在得到用户常驻小区后,根据用户常驻地的驻留时间分布,对建立基于频次及时长的常驻小区评分模型,用户的常驻小区进行属性划分,得到用户的居住地和工作地的信息。进一步地,利用权重算法清除干扰小区,具体为,对用户在设定时间段内的驻留小区进行平均驻留时长的计算和排名,把平均驻留时长低于某一阈值的小区进行清洗删除,去除干扰小区,划分出用户重要小区。进一步地,采用有代表性的基于密度的聚类算法即DBSCAN算法对得到的用户重要小区进行基于地理位置信息的空间聚类,具体为:给定数据集D中所有对象都被标记为“未访问”,随机选择一个未访问的对象p,标记p为“已访问”,并检查p的ε-邻域是否至少包含MinPts个对象,如果不是,则对象p被标记为噪声点;否则为p创建一个新的簇C,并且把p的ε-邻域中所有对象都放在候选集合N中;迭代地把候选集合N中不属于其他簇的对象添加到簇C中;在此过程中,对应候选集合N中标记为“未访问”的对象P*,DBSCAN把对象P*标记为“已访问”,并且检查对象P*的ε-邻域,如果对象P*的ε-邻域至少包含MinPts个对象,则对象P*的ε-邻域中的对象都被添加到候选集合N中,DBSCAN继续添加对象到簇C,直到簇C不能扩展,即直到候选集合N为空,此时簇C完成生成并输出;继续找到下一个簇,DBSCAN从剩下的对象中随机选择一个未访问过的对象,聚类过程继续,直到给定数据集D中所有对象都被访问。进一步地,根据驻留时间对常驻地中各小区设置不同权重,来挖掘用户常驻小区,具体为:依据驻留时间设置用户所在常驻地中小区权重情况,加上权重参数,再去除权重小于设定阈值的小区;在以上小区中重新设置小区权重选取设定数量的权重最高的小区,得到用户常驻小区。进一步地,建立基于频次及时长的常驻小区评分模型,判定居民居住地,具体为:抽取连续历史数据中每日的23:00-次日6:00时段的所有数据,得到用户在期间所有驻留小区信息,假设用户在小区c出现的频次为fc_home,驻留总时长为dc_home,对每个用户在所有小区的出现总频数及驻留总时长进行如下0-1标准化处理:其中max为样本数据的最大值,min为样本数据的最小值;从而得到所有用户驻留时长及总频数的0-1标准化后的值,分别为则居住地小区重要性评分即为:其中wf和wd分别表示频数和驻留时长的权重;使用倍数环比法对权重进行设定:将各个考评因素随机排列,然后按照顺序对各项因素进行比较,得出各因素重要度之间的倍数关系,即环比比率,再将环比比率进行统一转换为基准值,最后进行归一化处理,确定其最终权重;根据以上权重算法,对所有小区评分进行排序,选取评分最高的小区,并且投射到附近地图上,即为挖掘出用户居住地。进一步地,建立基于频次及时长的常驻小区评分模型,判定工作地,具体为:提取历史数据中所有的工作日数据,得到用户在期间所有驻留小区信息,假设用户在小区c出现的频次为fc_work,驻留总时长为dc_work,进行0-1标准化处理得到用户所有小区驻留时长及总频数的0-1标准化后的值,分别为fc_work、dc_work,对每个用户在所有小区的出现总频数及驻留总时长进行如下0-1标准化处理:其中max为样本数据的最大值,min为样本数据的最小值;从而得到所有用户驻留时长及总频数的0-1标准化后的值,分别为则工作地小区重要性评分即为:其中wf和wd分别表示频数和驻留时长的权重;使用倍数环比法对权重进行设定:首先将各个考评因素随机排列,然后按照顺序对各项因素进行比较,得出各因素重要度之间的倍数关系,即环比比率,再将环比比率进行统一转换为基准值,最后进行归一化处理,确定其最终权重;根据以上权重算法,对所有小区评分进行排序,选取评分最高的小区,并且投射到地图上,即为用户工作地。本发明的有益效果是:该种基于信令数据的用户职住地分析方法,根据用户某段时间内的驻留信息,利用权重算法清除干扰小区后,基于地理位置信息进行空间聚类,并且进一步根据时间限制对常驻小区常驻重要性进行打分,从而得到用户常驻地信息。进一步地,在得到用户常驻地信息后,根据用户常驻地的驻留时间分布,对常驻地信息进行打标签分类,从而得到用户的居住地和工作地的信息。该方法能够挖掘出用户的用户常驻地信息包括工作地及居住地,从而方便运营商有针对性、有目的地开展营销工作,对用户进行定点营销或网络测试,这对于宽带业务、手机入网等都是非常有益的。附图说明图1是实施例中基于经纬度信息的一段时间内的驻留分布示意图。图2是实施例中基于密度的聚类中的密度可达和密度相连性的说明示意图。图3是实施例中聚类算法的说明示意图。图4是某个用户的基于密度的地理聚类效果示意图。图5是实施例中用户停留小区分布示意图。图6是实施例中去除干扰小区后的用户小区停留分布示意图。图7是实施例中用户常驻小区分布示意图。具体实施方式下面结合附图详细说明本发明的优选实施例。实施例一种基于信令数据的用户职住地分析方法,具体包括以下步骤:根据用户在设定时间段内的小区驻留信息,利用权重算法清除干扰小区得到用户重要小区后,对得到的用户重要小区进行基于地理位置信息的空间聚类,把聚类中密集出现的区域,划分为常驻地;根据驻留时间对常驻地中各小区设置不同权重,来挖掘用户常驻小区;在得到用户常驻小区后,根据用户常驻地的驻留时间分布,对建立基于频次及时长的常驻小区评分模型,用户的常驻小区进行属性划分,得到用户的居住地和工作地的信息。实施例通过小区驻留信息包括运营商信令数据及工参表地理位置数据,意在通过用户驻留2/3/4G小区记录如小区标识ECGI/ECI、驻留时长等,关联小区工参,如小区标识ECGI/ECI、经度、维度等,形成宽表,据此宽表,通过算法建模,识别用户常驻地,包括用户居住地和工作地。实施例的数据源为设定时间段内运营商用户的驻留2/3/4G数据及某地理小区基站的工参表,包括小区和地理位置经纬度的匹配信息。对此,首先根据用户驻留小区的ECI,根据工参表匹配上小区的经纬度信息以后。对某个用户来说,先画出基于经纬度信息的一段时间内的驻留分布图,如图1。从图1中来看,一段时间内用户出现的地理位置大都比较集中,为了挖掘用户常驻地,首先需要清除掉用户的干扰信息。清洗干扰小区,划分用户重要小区。为了消除大部分用户在常驻地小区之间往返所经过小区的干扰及一些销售推销人员小区频繁切换变更的非常驻地情况,首先,对用户一段时间内的驻留小区进行平均驻留时长的计算和排名,把平均驻留时长低于某一阈值的小区进行清洗删除,去除干扰小区,划分出用户重要小区。基于空间距离进行小区聚类。鉴于用户小范围不定时移动及外力风向等造成的小区偏移都可能造成用户小区变更,因此找出用户常驻地理位置更具有意义。为了实现这点,可以首先根据用户的驻留小区信息,对筛选后得到的重要小区进行基于密度的空间距离的聚类,结果一般为3类以内。实施例采用DBSCAN算法对用户的驻留位置进行聚类,以下是关于DBSCAN算法的描述:首先基于密度的聚类算法,简单的说就是根据一个根据对象的密度不断扩展的过程的算法。一个对象O的密度可以用靠近O的对象数来判断。实施例中概念如下:ε-邻域:是以对象O为中心,ε为半径的空间,参数ε>0,是用户指定每个对象的领域半径值。MinPts即领域密度阀值:对象的ε-邻域的对象数量。核心对象:如果对象O的ε-邻域的对象数量至少包含MinPts个对象,则该对象是核心对象。直接密度可达:如果对象p在核心对象q的ε-邻域内,则对象p是从核心对象q直接密度可达的。密度可达:在DBSCAN中,对象p是从核心对象q密度可达的,如果存在对象链P1,P2,P3,...,Pn,使得P1=q,Pn=p,Pi+1是Pi从关于ε和MinPts直接密度可达的,即Pi+1在Pi的ε-邻域内,则P1到Pn密度可达。密度相连:如果存在对象q∈D,使得对象P1和P2都是从q关于ε和MinPts密度可达的,则称P1和P2是关于ε和MinPts密度相连的。密度可达和密度相连的描述如图2,半径为ε,MinPts=3;由图2可看出m,p,o.r都是核心对象,因为他们的内都只是包含3个对象。1、对象q是从m直接密度可达的。对象m从p直接密度可达的。2、对象q是从p间接密度可达的,因为q从m直接密度可达,m从p直接密度可达。3、r和s是从o密度可达的,而o是从r密度可达的,所有o,r和s都是密度相连的。DBSCAN聚类过程,如图3:初始,给定数据集D中所有对象都被标记为“未访问”,DBSCAN随机选择一个未访问的对象p,标记对象p为“已访问”,并检查对象p的ε-邻域是否至少包含MinPts个对象。如果不是,则对象p被标记为噪声点。否则为对象p创建一个新的簇C,并且把对象p的ε-邻域中所有对象都放在候选集合N中。DBSCAN迭代地把候选集合N中不属于其他簇的对象添加到簇C中。在此过程中,对应候选集合N中标记为“未访问”的对象P*,DBSCAN把它标记为“已访问”,并且检查它的ε-邻域,如果对象P*的ε-邻域至少包含MinPts个对象,则对象P*的ε-邻域中的对象都被添加到候选集合N中。DBSCAN继续添加对象到簇C,直到簇C不能扩展,即直到候选集合N为空。此时簇C完成生成,输出。为了找到下一个簇,DBSCAN从剩下的对象中随机选择一个未访问过的对象。聚类过程继续,直到所有对象都被访问。聚类效果如图4,把聚类中密集出现的区域,划分为常驻地。挖掘用户常驻小区。为了更高级别地识别用户常驻小区,尝试根据驻留时间对常驻地中的小区设置不同权重,来挖掘用户常驻小区。根据用户每个小区不同权重设置算法来挖掘用户常驻小区,具体为:首先打点出用户所在常驻地中小区权重情况,以某一用户为例,加上权重参数,如图5。进一步地,为了更清晰发掘用户常驻小区及常驻小区间的距离,尝试在上步基础上去除权重特别小的小区,得到如下图6,图6为去除干扰小区后的用户小区停留分布图。可以看出,图6中两个比较大的小区应该是实施例比较关心的用户常驻小区。为了进一步挖掘以上两个小区,在以上小区中重新设置小区权重选取权重比较高的小区,得到常驻小区,如图7。然后,挖掘用户居住地/工作地。为了判定居民居住地和工作地,需对用户的常驻小区进行属性划分,建立基于频次及时长的常驻小区评分模型,评分模型具体如下:抽取连续历史数据中每日的23:00-次日6:00时段的所有数据,得到用户在期间所有驻留有小区信息,假设用户在小区c出现的频次为fc_home,驻留总时长为dc_home,对每个用户在所有小区的出现总频数及驻留总时长进行如下0-1标准化(0-1normalization)处理:其中max为样本数据的最大值,min为样本数据的最小值。从而得到所有用户驻留时长及总频数的0-1标准化后的值,分别为则居住地小区重要性评分即为:其中wf和wd分别表示频数和驻留时长的权重。使用倍数环比法对权重进行设定:倍数环比法首先将各个考评因素随机排列,然后按照顺序对各项因素进行比较,得出各因素重要度之间的倍数关系,又称环比比率,再将环比比率进行统一转换为基准值,最后进行归一化处理,确定其最终权重。这种方法需要对考评因素有客观的判断依据,需要有客观准确的历史数据作为支撑。以上述四个因素为例,如下表1。表1实施例使用倍数环比法对权重进行设定权重结果考评因素ABCD合计环比比率0.320.551基准值0.331.10.5512.98最终权重0.11070.36910.18460.33561其中,表1中第二行,0.3表示A的重要性是B的0.3倍;2表示B的重要性是C的2倍,0.55表示C的重要性是D的0.55倍;1表示D本身。第三行,是以D为基准进行的比率归一化,因C的重要性是D的0.55倍,因此取值为0.55*1=0.55;B是C的2倍,所以取值为0.55*2=1.1;以下类推。最终权重则以合计数为分母,各基准值为分子算出。这种倍数环比法决定权重的方法较为实用,计算也简单,由于有准确的历史数据作支撑,因此具有较高的客观科学性。根据以上权重算法,对所有小区评分进行排序,选取评分最高的小区,并且投射到附近地图上,即为挖掘出用户居住地。提取历史数据中所有的工作日数据,得到用户在期间所有驻留小区信息,假设用户在小区c出现的频次为fc_work,驻留总时长为dc_work,同上,进行0-1标准化(0-1normalization)处理得到用户所有小区驻留时长及总频数的0-1标准化后的值,分别为fc_work、dc_work,对每个用户在所有小区的出现总频数及驻留总时长进行如下0-1标准化处理:其中max为样本数据的最大值,min为样本数据的最小值;从而得到所有用户驻留时长及总频数的0-1标准化后的值,分别为则工作地小区重要性评分即为:根据以上权重算法,对所有小区评分进行排序,选取评分最高的小区,并且投射到地图上,即为用户工作地。当前第1页1 2 3
相关技术
网友询问留言
已有0条留言
- 还没有人留言评论。精彩留言会获得点赞!
1