一种日志管理系统、方法及装置与流程
本发明实施例涉及互联网的技术领域,尤其涉及一种日志管理系统、方法及装置。
背景技术:
过去十年来,随着分布式系统的发展,日志数据管理起来更加复杂。如今,系统中可以容纳数以千计的服务器实例或者微服务容器,而所有这些实例或容器又会生成自己的日志数据。随着以云为基础的系统快速出现并占据主导地位,由机器所生成的日志数据呈爆炸性增长。
目前传统的收集日志方法,在后端生成日志后,通过scp命令上传、下载或通过rsync命令定时同步等方式收集汇总,然后通过机器脚本分析、或者人工观察统计、或者图形绘制等方式来分析,这种方法的实时性较差。而日志管理随之成为现代化IT运营中的重要任务,为包括调试、生产监控、性能监控、支持援助与故障查找之类的许多用例提供辅助支撑。处理这些日志需要特定的日志管理解决方案,一般而言,日志管理解决方案需要解决以下特征:
(1)低耦合:构建应用系统和分析系统的桥梁,并将它们之间的关联解耦;
(2)高吞吐:支持高吞吐、低延迟、近实时数据持久化操作和大量小文件的存储;
(3)具有高可扩展性:即:当系统操作量增加时,可以通过增加节点进行水平扩展;
(4)具有高可用:当节点出现故障时,日志能够被传送到其他节点上而不会丢失。
技术实现要素:
本发明实施例的目的在于提出一种日志管理系统、方法及装置,旨在解决如何快速、准确地收集用户行为日志,并快速、准确地获取与关注用户行为相关的信息。
为达此目的,本发明实施例采用以下技术方案:
第一方面,一种日志管理系统,所述系统包括:Kafka、Flume和Jstorm;
所述K afka,用于根据不同的业务定义日志格式和Hbase表,并根据所述日志格式将日志数据发送到KafkaCluster的Topic中;
所述Flume,用于从所述Topic中读取日志数据,读取所述日志数据并进行HDFS的数据持久化操作;
所述Jstorm,用于从所述Topic中读取日志数据,读取所述日志数据并进行HDFS的数据持久化操作。
第二方面,一种日志管理方法,所述方法包括:
Kafka根据不同的业务定义日志格式和Hbase表,并根据所述日志格式将日志数据发送到KafkaCluster的Topic中;
Flume和Jstorm从所述Topic中读取日志数据;
所述Flume和所述Jstorm读取所述日志数据并进行HDFS的数据持久化操作;
优选地,所述根据不同的业务定义日志格式和Hbase表,包括:
根据不同的业务定义日志格式,并在所述Kafka中定义不同的Topic,所述Topic用于收发日志;
根据业务需要定义所述Hbase表,所述Hbase表用于避免造成热点写\读。
优选地,所述Flume读取所述日志数据并进行HDFS的数据持久化操作,包括:
从所述Flume中读取所述日志数据并传输到Hbase表中,未做ETL的数据需数据持久化操作到HDFS中。
优选地,所述Jstorm读取所述日志数据并进行HDFS的数据持久化操作,包括:
所述JStorm从所述KafkaCluster中获取所述日志数据并通过预设算法计算后将复杂业务逻辑数据持久化操作到RDBMS中;
从所述Jstorm中分析的日志数据持久化操作到所述RDBMS中后,由Sqoop组件进行所述HDFS的数据持久化操作。
优选地,所述Flume和所述Jstorm读取所述日志数据并进行HDFS的数据持久化操作之后,包括:
采用MapReduce进行分析提取数据持久化操作后的数据;
若所述数据持久化操作后的数据量小于预设第一数据量阈值,则采用Sqoop重新提交到RDBMS中;
若所述数据持久化操作后的数据量大于预设第二数据阈值,则采用Solr、ES全文数据库做查询支撑。
第三方面,一种日志管理装置,所述装置包括:
定义模块,用于根据不同的业务定义日志格式和Hbase表;
发送模块,用于根据所述日志格式将日志数据发送到KafkaCluster的Topic中;
读取模块,用于从所述Topic中读取日志数据;
第一处理模块,用于读取所述日志数据并进行HDFS的数据持久化操作;
优选地,所述定义模块,具体用于:根据不同的业务定义日志格式,并在所述Kafka中定义不同的Topic,所述Topic用于收发日志;
根据业务需要定义所述Hbase表,所述Hbase表用于避免造成热点写\读。
优选地,所述第一处理模块,具体用于:
从Flume中读取所述日志数据并传输到Hbase表中,未做ETL的数据需数据持久化操作到HDFS中;
所述第一处理模块,还具体用于:
从所述KafkaCluster中获取所述日志数据并通过预设算法计算后将复杂业务逻辑数据持久化操作到RDBMS中;从Jstorm中分析的日志数据持久化操作到所述RDBMS中后,由Sqoop组件进行所述HDFS的数据持久化操作。
优选地,所述装置还包括:
第二处理模块,用于在所述Flume和所述Jstorm读取所述日志数据并进行HDFS的数据持久化操作之后,采用MapReduce进行分析提取数据持久化操作后的数据;若所述数据持久化操作后的数据量小于预设第一数据量阈值,则采用Sqoop重新提交到RDBMS中;若所述数据持久化操作后的数据量大于预设第二数据阈值,则采用Solr、ES全文数据库做查询支撑。
本发明实施例提供一种日志管理方法、装置及系统,Kafka根据不同的业务定义日志格式和Hbase表,并根据所述日志格式将日志数据发送到KafkaCluster的Topic中;Flume和Jstorm从所述Topic中读取日志数据;所述Flume和所述Jstorm读取所述日志数据并进行HDFS的数据持久化操作。本发明采用了Kafka这一高吞吐量的分布式发布订阅消息系统与Flume海量日志采集、聚合和传输的系统;当系统操作量增加时,可以通过增加节点进行水平扩展;采用的所有组件都采用了Master/Slave模式保证了当有个别节点宕机的情况下不会影响业务的正常运行,并且Flume与Kafka都有Wal机制,保证日志不会丢失。
附图说明
图1是本发明实施例提供的一种日志管理系统的结构示意图;
图2是本发明实施例提供的另一种日志管理系统的结构示意图;
图3是本发明实施例提供的一种日志管理方法的流程示意图;
图4是本发明实施例提供的另一种日志管理方法的流程示意图;
图5是本发明实施例提供的一种日志管理装置的功能模块示意图。
具体实施方式
下面结合附图和实施例对本发明实施例作进一步的详细说明。可以理解的是,此处所描述的具体实施例仅仅用于解释本发明实施例,而非对本发明实施例的限定。另外还需要说明的是,为了便于描述,附图中仅示出了与本发明实施例相关的部分而非全部结构。
参考图1,图1是本发明实施例提供的一种日志管理系统的结构示意图。
如图1所示,所述日志管理系统包括:Kafka、Flume和Jstorm;
Kafka,用于根据不同的业务定义日志格式和Hbase表,并根据所述日志格式将日志数据发送到KafkaCluster(Apache Kafka Cluster)的Topic中;
Flume,用于从所述Topic中读取日志数据,读取所述日志数据并进行HDFS的数据持久化操作;
Jstorm,用于从所述Topic中读取日志数据,读取所述日志数据并进行HDFS的数据持久化操作。
本发明实施例提供一种日志管理系统,所述Kafka,用于根据不同的业务定义日志格式和Hbase表,并根据所述日志格式将日志数据发送到KafkaCluster的Topic中;所述Flume,用于从所述Topic中读取日志数据,读取所述日志数据并进行Hadoop分布式文件系统(Hadoop Distributed file system,HDFS)的数据持久化操作;所述Jstorm,用于从所述Topic中读取日志数据,读取所述日志数据并进行HDFS的数据持久化操作。本发明采用了Kafka这一高吞吐量的分布式发布订阅消息系统与Flume海量日志采集、聚合和传输的系统;当系统操作量增加时,可以通过增加节点进行水平扩展;采用的所有组件都采用了Master/Slave模式保证了当有个别节点宕机的情况下不会影响业务的正常运行,并且Flume与Kafka都有预写日志(Write-Ahead Logging,WAL)机制,保证日志不会丢失。
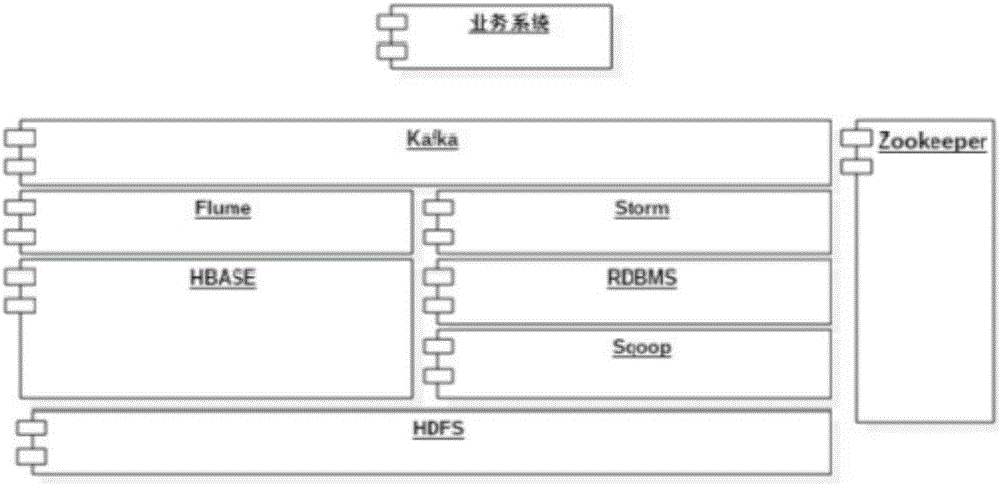
参考图2,图2是本发明实施例提供的另一种日志管理系统的结构示意图。
如图2所示,所述日志管理系统包括:Kafka、Flume、Jstorm、HBASE、关系数据库管理系统(Relational Database Management System,RDBMS)、Sqoop、HDFS以及Zookeeper;
低耦合:该解决方案采用组件化的设计思想,由于采用的组件都为Apache、Cloudera等国际上知名开源机构。在业务系统与分析系统的整合上起到了解耦的作用。
高吞吐:因本发明采用了Kafka这一高吞吐量的分布式发布订阅消息系统与Flume海量日志采集、聚合和传输的系统。这两大系统都为现今业界公认的高吞吐系统,这样保证了不管是业务系统日志还是RPC服务日志在吞吐量上没有了后顾之忧。
具有高可扩展性:即当系统操作量增加时,可以通过增加节点进行水平扩展:不管是如何优秀的解决方案都有在设计之初考虑不足的地方,本发明为了保证系统的高扩展性,不管是业务方面还是性能方面的,都将与之考虑进来,在设计之初,考虑使用Flume与JStorm的原因不仅仅是为了高吞吐一点才采用这两种日志分析系统,如果系统吞吐量达到瓶颈时,那么仅仅需要扩展Flume与JStorm节点即可,如果当后期因业务的新增或改变,也可以通过增加不同的agent或者Topology来实现业务上的扩展性。而考虑到业务上存在复杂关系,本发明采用了Sql与Nosql两种存储方式来满足不同的查询业务。
具有高可用:本发明采用的所有组件都采用了Master/Slave模式保证了当有个别节点宕机的情况下不会影响业务的正常运行,并且Flume与Kafka都有Wal机制,保证日志不会丢失。
参考图3,图3是本发明实施例提供的一种日志管理方法的流程示意图。
如图3所示,所述日志管理方法包括:
步骤301,Kafka根据不同的业务定义日志格式和Hbase表,并根据所述日志格式将日志数据发送到KafkaCluster的Topic中;
具体的,依照本方案进行相关的组件安装
(Zookeeper-Hadoop-Hbase-Kafka-JStorm-Oracle、Mysql、-Sqoop)按照上述顺序安装。
优选地,所述根据不同的业务定义日志格式和Hbase表,包括:
根据不同的业务定义日志格式,并在所述Kafka中定义不同的Topic,所述Topic用于收发日志;
根据业务需要定义所述Hbase表,所述Hbase表用于避免造成热点写\读。
步骤302,Flume和Jstorm从所述Topic中读取日志数据;
步骤303,所述Flume和所述Jstorm读取所述日志数据并进行HDFS的数据持久化操作。
优选地,所述Flume读取所述日志数据并进行HDFS的数据持久化操作,包括:
从所述Flume中读取所述日志数据并传输到Hbase表中,未做ETL的数据需数据持久化操作到HDFS中。
优选地,所述Jstorm读取所述日志数据并进行HDFS的数据持久化操作,包括:
所述JStorm从所述KafkaCluster中获取所述日志数据并通过预设算法计算后将复杂业务逻辑数据持久化操作到RDBMS中;
从所述Jstorm中分析的日志数据持久化操作到所述RDBMS中后,由Sqoop组件进行所述HDFS的数据持久化操作。
本发明实施例提供一种日志管理方法,Kafka根据不同的业务定义日志格式和Hbase表,并根据所述日志格式将日志数据发送到KafkaCluster的Topic中;Flume和Jstorm从所述Topic中读取日志数据;所述Flume和所述Jstorm读取所述日志数据并进行HDFS的数据持久化操作。本发明采用了Kafka这一高吞吐量的分布式发布订阅消息系统与Flume海量日志采集、聚合和传输的系统;当系统操作量增加时,可以通过增加节点进行水平扩展;采用的所有组件都采用了Master/Slave模式保证了当有个别节点宕机的情况下不会影响业务的正常运行,并且Flume与Kafka都有Wal机制,保证日志不会丢失。
参考图4,图4是本发明实施例提供的另一种日志管理方法的流程示意图。
如图4所示,所述日志管理方法包括:
步骤401,Kafka根据不同的业务定义日志格式和Hbase表,并根据所述日志格式将日志数据发送到KafkaCluster的Topic中;
步骤402,Flume和Jstorm从所述Topic中读取日志数据;
步骤403,所述Flume和所述Jstorm读取所述日志数据并进行HDFS的数据持久化操作;
步骤404,采用MapReduce(映射/归纳)进行分析提取数据持久化操作后的数据;若所述数据持久化操作后的数据量小于预设第一数据量阈值,则采用Sqoop重新提交到RDBMS中;若所述数据持久化操作后的数据量大于预设第二数据阈值,则采用Solr、ES全文数据库做查询支撑。
参考图5,图5是本发明实施例提供的一种日志管理装置的功能模块示意图。
如图5所示,所述装置包括:
定义模块501,用于根据不同的业务定义日志格式和Hbase表;
发送模块502,用于根据所述日志格式将日志数据发送到KafkaCluster的Topic中;
读取模块503,用于从所述Topic中读取日志数据;
第一处理模块504,用于读取所述日志数据并进行HDFS的数据持久化操作;
优选地,所述定义模块501,具体用于:根据不同的业务定义日志格式,并在所述Kafka中定义不同的Topic,所述Topic用于收发日志;
根据业务需要定义所述Hbase表,所述Hbase表用于避免造成热点写\读。
优选地,所述第一处理模块504,具体用于:
从Flume中读取所述日志数据并传输到Hbase表中,未做抽取-转换-加载(Extract-Transform-Load,ETL)的数据需数据持久化操作到HDFS中;
所述第一处理模块504,还具体用于:
从所述KafkaCluster中获取所述日志数据并通过预设算法计算后将复杂业务逻辑数据持久化操作到RDBMS中;从Jstorm中分析的日志数据持久化操作到所述RDBMS中后,由Sqoop组件进行所述HDFS的数据持久化操作。
优选地,所述装置还包括:
第二处理模块,用于在所述Flume和所述Jstorm读取所述日志数据并进行HDFS的数据持久化操作之后,采用MapReduce进行分析提取数据持久化操作后的数据;若所述数据持久化操作后的数据量小于预设第一数据量阈值,则采用Sqoop重新提交到RDBMS中;若所述数据持久化操作后的数据量大于预设第二数据阈值,则采用Solr、ES(Elasticsearch)全文数据库做查询支撑。
本发明实施例提供一种日志管理装置,Kafka根据不同的业务定义日志格式和Hbase表,并根据所述日志格式将日志数据发送到KafkaCluster的Topic中;Flume和Jstorm从所述Topic中读取日志数据;所述Flume和所述Jstorm读取所述日志数据并进行HDFS的数据持久化操作。本发明采用了Kafka这一高吞吐量的分布式发布订阅消息系统与Flume海量日志采集、聚合和传输的系统;当系统操作量增加时,可以通过增加节点进行水平扩展;采用的所有组件都采用了Master/Slave模式保证了当有个别节点宕机的情况下不会影响业务的正常运行,并且Flume与Kafka都有Wal机制,保证日志不会丢失。
以上结合具体实施例描述了本发明实施例的技术原理。这些描述只是为了解释本发明实施例的原理,而不能以任何方式解释为对本发明实施例保护范围的限制。基于此处的解释,本领域的技术人员不需要付出创造性的劳动即可联想到本发明实施例的其它具体实施方式,这些方式都将落入本发明实施例的保护范围之内。
- 还没有人留言评论。精彩留言会获得点赞!