云系统容错资源分配和代价最小化的方法与流程
本发明属于计算机网络技术领域,特别是一种云系统容错资源分配和代价最小化的方法。
背景技术:
云计算在互联网上成为一个引人注目的范式易用性虚拟环境的部署。云计算的一个典型特征是它方便的虚拟化资源池(如硬件、平台或服务),可以动态地重新配置,以适应可变负荷(规模)。为了避免用户资源的需求过剩,云系统提供的资源都应该满足他们真正的需求。每个任务的工作负载可能是多个维度。
首先,计算资源的需要可能是多属性(如CPU、磁盘读取速度、网络带宽、等),导致多维本质上执行。第二,即使一个任务只取决于一个资源类型,如CPU,它也可以分成多个顺序执行阶段,每个阶段要求不同的计算能力和不同的价格需求,但是同时这也导致了一个潜在的高维执行场景。云计算的资源配置是比其他分布式系统更复杂的,例如网格计算平台。在网格系统,由于他们之间的相互干扰性,这样的不共享计算资源在多个应用程序同时运行是不可避免的。然而,云系统通常不直接向用户提供物理主机,而是利用虚拟资源孤立技术。这样一个弹性资源使用方式不仅能适应用户的特定需求,而且它也可以最大化资源利用率在细粒度和孤立异常环境安全地达到目的。一些成功的平台或云管理工具包括Amazon EC2和OpenNebula利用VM资源隔离技术。
另一方面,科学研究的快速发展,用户可能提出非常复杂的要求。例如,用户可能希望减少保证他们服务水平的还款,这样任务时可以在最后期限之前完成。这样一份关于资源分配与最小化代价的毕业论文很少在文献研究。此外,不可避免的错误预测任务工作量肯定会使问题更加困难。在弹性资源使用模型的基础上,本发明的目标是设计一个高预期耐受能力的资源分配算法,也尽量减少用户支付他们的预计期限。因为可以任意分区空闲的物理资源和分配新任务,基于vm的资源分配有着非常灵活的倍数。这意味着寻找最优解的可行性通过凸优化策略,与传统网格模型相比,依赖于不可分割的资源比如物理处理器的数量。然而,无法找到最优解。
技术实现要素:
本发明的目的在于提供一种高效、可靠的云系统容错资源分配和代价最小化的方法。
实现本发明目的的技术解决方案为:一种云系统容错资源分配和代价最小化的方法,步骤如下:
步骤1,云服务器接收并响应任务和定制的需求;
步骤2,通过网络将所接收的任务和定制需求存储到本地磁盘或公共服务器;
步骤3,在收到用户请求时,检查可用性状态的所有候选节点,并估计最后期限内每个任务的最小代价;
步骤4,将通过一个定制的VM运行任务实例与孤立的资源,得到最低的代价。
进一步地,步骤3所述在收到用户请求时,检查可用性状态的所有候选节点,并估计最后期限内每个任务的最小代价,其中使用到的参数包括:
种群规模大小T,PSO-SFLA算法中PSO种群和SFLA种群各为T/2,将SFLA种群分为i个子群,每个子群规模大小X个,子群内更新迭代次数p,算法的进化迭代次数为r,PSO-SFLA算法中的个体邻域半径为b,根据公式1算出迭代最小化P(r(ti)),
其中,T(ti)的值满足下列式子:
进一步地,步骤4所述将通过一个定制的VM运行任务实例与孤立的资源,得到最低的代价,具体如下:
在步骤3得到最后期限内每个任务的最小代价P(r(ti)),根据公式(2)得到最大代价比的结果这个结果反映在一般情况下,PSO—SFLA算法的相对代价比例值,再由公式(2)的前半部分得到T(ti),即是每种算法产生相应的分配结果要求的最低代价。
本发明与现有技术相比,其显著优点为:(1)基于云环境的促进与VM资源隔离技术,本发明制定一个受截止时间驱使的资源分配问题,并提出一个新颖的解决方案与多项式时间,可以减少用户的付款期限;(2)在通过分析任务执行长度的上限可能是不准确的基础上,进一步提出一个容错方法,保证任务在其最后期限的完成;(3)在一个真正的促进VM集群环境下进行不同层次的竞争来验证其有效性。
附图说明
图1是云系统的资源配置图。
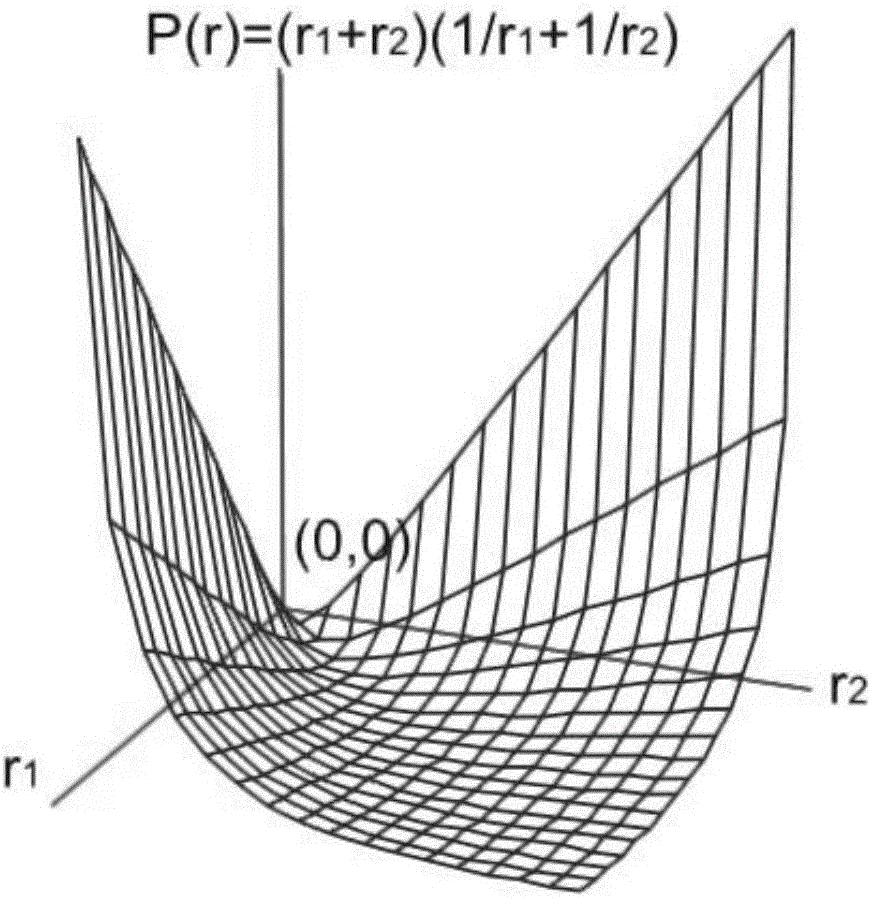
图2是本发明一个简单案例的曲线图。
图3是任务数量的分布图。
图4是任务数量的公平性指数图。
具体实施方式
本发明基于云系统容错资源分配和代价最小化的方法,包括以下步骤:
步骤1,云服务器不断地接收并响应用户请求(或任务)和定制的需求
步骤2,通过网络将这些任务的计算结果存储到本地磁盘或公共服务器。
步骤3,在收到请求时,调度程序检查可用性状态的所有候选节点,并估计最后期限内每个任务的最小代价。具体过程如下:
步骤3中使用到的参数有:种群规模大小T,PSO-SFLA算法中PSO种群和SFLA种群各为T/2,将SFLA种群分为i个子群,每个子群规模大小X个,子群内更新迭代次数p,算法的进化迭代次数为r,PSO-SFLA算法中的个体邻域半径为b,根据公式(1)算出迭代最小化P(r(ti)),
步骤4,将通过一个定制的VM运行任务实例与孤立的资源要求最低的代价。
根据步骤3中的一般过程算出云系统容错资源分配的代价最小化,护体实施步骤如下:
在步骤3中得到最后期限内每个任务的最小代价P(r(ti)),根据公式(2)得到最大代价比的结果这个结果反映了在一般情况下,PSO—SFLA算法的相对代价比例值,再由公式(2)的前半部分得到T(ti)即是每种算法产生相应的分配结果要求的最低的代价
步骤5,计算结果(或反馈)将被返回给用户。
我们需要求的代价最小化即P(r(ti)),其表达式如下:
其中,T(ti)的值满足下列式子:
先将云系统中的资源分成两部分,根据PSO-SFLA混合算法,先用基本PSO算法对其中一部分进行计算,再用SFLA对另一部分进行优化,然后找到最优解。
在Min P(r(ti))的条件下。还有如下两个判定:
T(ti)≤D(ti) (3)
r(ti)≤a(ps) (4)
实施例1
结合图1~4,本发明云系统容错资源分配和代价最小化的方法,步骤如下:
步骤1,云服务器不断地接收并响应用户请求(或任务)和定制的需求收集网络中可用的带宽资源中无线频率资源的总流量带宽,在本实例中我们使用的无线频率资源的总流量带宽为20M。
步骤2,通过网络将这些任务的计算结果存储到本地磁盘或公共服务器。
步骤3,在收到请求时,调度程序检查可用性状态的所有候选节点,并估计最后期限内每个任务的最小代价。具体过程如下:
步骤3中使用到的参数有:种群规模大小T=200,PSO-SFLA算法中PSO种群和SFLA种群各为100个,将SFLA种群分为20个子群,每个子群规模大小X=10个,子群内更新迭代次数30次,算法的进化迭代次数为r,PSO-SFLA算法中的个体邻域半径为b,根据公式1算出迭代最小化P(r(ti)),
步骤4,将通过一个定制的VM运行任务实例与孤立的资源要求最低的代价。
在第三步中得到最后期限内每个任务的最小代价,根据公式二得到最大代价比的结果,这个结果反映了在一般情况下,PSO—SFLA算法的相对代价比例值,再由公式二的前半部分得到T(ti)即是每种算法产生相应的分配结果要求的最低的代价。
步骤5,计算结果(或反馈)将被返回给用户。
根据步骤4中得到的结果发现最小迭代次数是378,最大迭代次数499的而改进后的最小迭代次数为376,最大迭代次数为478。结果进行比较得出方法比以前的方法是有所改进的。
综上所述,本发明是一种高效、可靠的云系统容错资源分配,能够充分利用网络带宽资源,使得云系统容错资源分配代价最小化。
- 还没有人留言评论。精彩留言会获得点赞!