基于MapReduce的FTP分布式采集方法与流程
本发明涉及一种远程数据采集方法,尤其涉及一种基于MapReduce的FTP分布式采集方法。
背景技术:
目前常用的FTP下载远程服务器上面的数据有如下几种方式:
1)单线程,使用Apache FTP下载远程服务器的数据;
2)多线程,使用Apache FTP,启用多个线程,多FTP Client下载远程服务器的数据;
3)部署多个服务,使用Apache FTP,启动多个线程,多FTP Client下载远程服务器的数据。
现有技术的主要缺点如下:
1)使用Apache FTP单线程下载远程服务器的数据时,采集速度明显不足,带宽和IO速率都不能发挥出比较高的性能,所以采集速度明显不高。
2)使用Apache FTP多线程下载远程服务器的数据时,采集速度明显提升,带宽和IO速率等都发挥出高性能,采集速度受限于磁盘IO的性能,带宽等因素。
3)部署多个服务,使用Apache FTP多线程下载远程服务器的数据,多个节点同时采集,采集速度应该达到最优。但是要在多台服务部署采集应用,维护起来比较麻烦。
由上可见,现有的采集远程服务器上的数据,在大数据的环境下,每天几十G或者几个T的数据生成速度,没有一个理想的采集速度,肯定是满足不了需求的。传统的单线程采集慢,部署多应用多线程采集,维护比较麻烦。MapReduce是一种编程模型,用于大规模数据集(大于1TB)的并行运算,它极大地方便了编程人员在不会分布式并行编程的情况下,将自己的程序运行在分布式系统上。当前的软件实现是指定一个Map(映射)函数,用来把一组键值对映射成一组新的键值对,指定并发的Reduce(归约)函数,用来保证所有映射的键值对中的每一个共享相同的键组。MapReduce的一个经典实例是Hadoop,用于处理大型分布式数据库。因此,有必要提供一种基于MapReduce的FTP分布式采集方法。
技术实现要素:
本发明所要解决的技术问题是提供一种基于MapReduce的FTP分布式采集方法,,只需要启动一个采集服务即可实现FTP多线程采集,能够提升采集速度并且简化维护工作。
本发明为解决上述技术问题而采用的技术方案是提供一种基于MapReduce的FTP分布式采集方法,包括如下步骤:S1)预先配置好多台FTP服务器信息和日志文件路径,并将配置信息存储到Hadoop的HDFS中作为MapReduce的数据输入;S2)设置MapReduce的输入目录和Reduce任务数;S3)利用MapReduce将不同的日志记录分发到不同的HDFS集群节点进行处理;S4)每个HDFS集群节点读取到FTP服务器信息之后,使用账号密码连接FTP服务器,展开预先配置好的日志文件路径,通过IO流将文件写入到HDFS中,实现多个HDFS集群节点同时采集多台FTP服务器的日志信息。
上述的基于MapReduce的FTP分布式采集方法,其中,所述步骤S1)将配置信息编写成文本信息,每一行对应一台FTP服务器,每一行文本包含FTP服务器IP、端口、账号、密码、日志路径和日志编号,所述日志编号按行依次采用1、2、3、…n等顺序排列,n为自然数。
上述的基于MapReduce的FTP分布式采集方法,其中,所述步骤S2)指定FTP服务器的台数为Reduce任务数,所述步骤S3)先将HDFS集群节点数和整型数的上限值进行与运算,再利用日志编号对Reduce任务数取余,然后采用Hadoop中的分区类HashPartitioner将不同的日志记录分发到不同的HDFS集群节点。
上述的基于MapReduce的FTP分布式采集方法,其中,所述步骤S4)中的每个HDFS集群节点采用Apache FTP客户端连接到FTP服务器。
本发明对比现有技术有如下的有益效果:本发明提供的基于MapReduce的FTP分布式采集方法,利用MapReduce的分布式的工作原理,结合Apache FTP多线程采集,采集速度跟多应用多线程差不多,但是只需要启动一个采集服务即可,从而提升了速度并且也简化了维护工作。
附图说明
图1为本发明基于MapReduce的FTP分布式采集流程图;
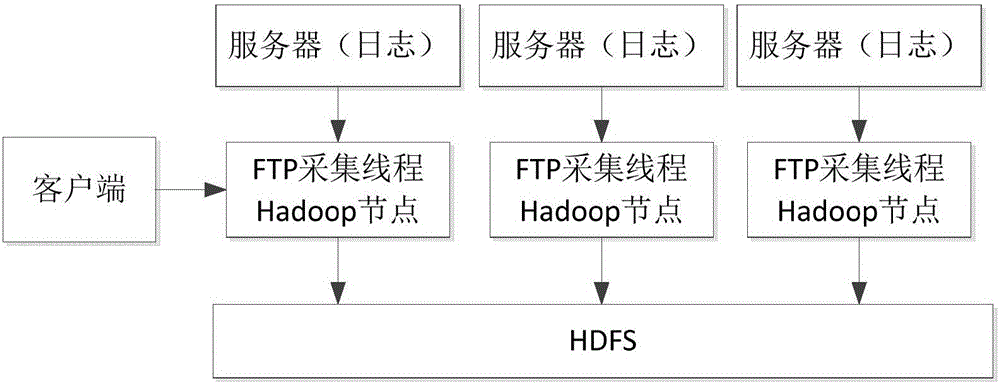
图2为本发明基于MapReduce的FTP分布式采集系统架构示意图。
具体实施方式
下面结合附图和实施例对本发明作进一步的描述。
图1为本发明基于MapReduce的FTP分布式采集流程图。
请参见图1,本发明提供的基于MapReduce的FTP分布式采集方法,包括如下步骤:
S1)预先配置好多台FTP服务器信息和日志文件路径,并将配置信息存储到Hadoop的HDFS中作为MapReduce的数据输入;
S2)设置MapReduce的输入目录和Reduce任务数;
S3)利用MapReduce将不同的日志记录分发到不同的HDFS集群节点进行处理;
S4)每个HDFS集群节点读取到FTP服务器信息之后,使用账号密码连接FTP服务器,展开预先配置好的日志文件路径,通过IO流将文件写入到HDFS中,从而实现多个HDFS集群节点同时采集多台FTP服务器的日志信息。
本发明在基于Hadoop的MapReduce分布式处理架构之上引入Apache FTP;本发明可以跟任意Hadoop版本中的MapReduce整合,利用分布式计算框架的原理。将采集任务分发到集群上的每一台机器上进行采集。这样每台机器的带宽,磁盘IO性能都能得到充分利用。本发明采集性能较高,只需要启动一个采集服务,维护容易,扩展性强,适用跨度广泛,实用性强,没有版本限制,可以无缝隙集成到目前任何版本的Hadoop。
本发明的MapReduce结合Apache FTP采集远程服务的整体架构如图2所示,整个采集大致分为如下四个步骤:(1)准备FTP服务器和日志相关信息;(2)编写MapReduce程序;(3)继承Partitioner;4)整合Apache FTP采集日志。
启动服务之后,首先要读取FTP服务器的账号密码和日志存放路径等相关信息,因为本发明是将Apache FTP整合到Hadoop的MapReduce分布式计算框架中的,所以配置的FTP服务器信息就可以编写成文本信息,每一行对应一台FTP服务器,放到Hadoop的HDFS中存储,这样就可以作为MapReduce的数据输入
Partitioner是MapReduce的一个重要组件,它的作用是可以将不同的日志记录分发到不同的reduce中处理;使用者通常会指定Reduce任务和Reduce任务输出文件的数量(R)。用户在中间key上使用分区函数来对数据进行分区,之后在输入到后续任务执行进程。一个默认的分区函数式使用hash方法(比如常见的:hash(key)mod R)进行分区。hash方法能够产生非常平衡的分区,鉴于此,Hadoop中自带了一个默认的分区类HashPartitioner,它继承了Partitioner类,提供了一个getPartition的方法,定义如下:
由上可见,HashPartitoner通过(key.hashCode()&Integer.MAX_VALUE)%numReduceTasks,将key均匀分布在Reduce Tasks上。例如:如果Key为Text的话,Text的hashcode方法跟String的基本一致,都是采用的Horner公式计算,得到一个int整数。但是,如果string太大的话这个int整数值可能会溢出变成负数,所以和整数的上限值Integer.MAX_VALUE(即0111111111111111)进行与运算,然后再对reduce任务个数取余,这样就可以让key均匀分布在reduce上。
了解了Partitioner的作用之后,继续后面的处理。假设现在有3台FTP服务器的日志需要采集,集群大小为10个节点。那么本发明可以设置Reduce任务数为3job.setNumReduceTasks(3),节点资源是足够的;每一行的FTP服务器信息,包含日志路径,还有日志编号。本发明巧妙地设置编号为1、2、3等顺序排列,利用日志编号对reduce数取余数。这样每一行的FTP服务器信息就会均匀的分发到不同节点上面处理,达到了分布式处理的效果。
MapReduce读取到FTP服务器信息之后,使用账号密码连接FTP服务器,展开预先配置好的日志文件路径,通过IO流将文件写入到HDFS中,到此整个过程便实现了多个节点同时采集多台服务器的日志信息,大大提供了采集性能。下面给出每个主要步骤的详细逻辑。
1、准备FTP服务器和日志相关信息
假设现在要采集三台服务器的日志数据,编写文本文件ftp_info.txt,上传到HDFS上,作为MapReduce的输入数据,基本信息如下:
2、编写MapReduce程序
a)设置MapReduce输入目录和reduce任务数
FileInputFormat.addInputPath(job,new Path("/ftp_info.txt"));
假设想利用3台机器去采集,则设置reduceNum为3
job.setNumReduceTasks(3);
b)map阶段,不做任何数据处理,直接输出
3、继承Partitioner
partitioner阶段,也是该技术的核心,将不同编号的日志,分发到不同集群节点去执行
4、整合Apache FTP采集日志
在reduce阶段,可以得到每一行的FTP服务器信息,并通过Apache FTP连接到每一台服务器,将日志采集到HDFS集群上
采集日志就是collectLog方法就是自己做的一些业务处理了,大概如下:1)通过帐号、密码信息,连接到ftp;2)展开日志路径下所有日志;3)做些日志过滤等业务处理;4)打开文件的输入输出流,将文件下载到HDFS上。
本发明利用Hadoop MapReduce分布式的原理,整合Apache FTP采集数据,可配置的方式任意配置需要采集的FTP服务器的日志,兼容0.2x–2.7(目前最高版本)。具体优点如下:1)插件式依附在Hadoop的MapReduce中,是可以通过简单配置文本的方式实现FTP服务器上的日志采集;2)与Hadoop原有的接口完全兼容,做到架构依赖低耦合。3)整合到MapReduce中的,利用MapReduce的分布式计算原理,可以将采集任务分发到不同的节点上进行采集,大大提升了采集性能;4)适用跨度广泛,实用性强,没有版本限制,可以无缝隙集成到目前任何版本的Hadoop;5)植入非常简单轻松,采用配置文件模式,利用Java生产环境中原生态库集成;6)维护容易,扩展性强。
虽然本发明已以较佳实施例揭示如上,然其并非用以限定本发明,任何本领域技术人员,在不脱离本发明的精神和范围内,当可作些许的修改和完善,因此本发明的保护范围当以权利要求书所界定的为准。
- 还没有人留言评论。精彩留言会获得点赞!