一种通过HTML标签识别垃圾邮件的方法与流程
本发明涉及反垃圾邮件
技术领域:
,尤其涉及一种通过HTML标签识别垃圾邮件的方法。
背景技术:
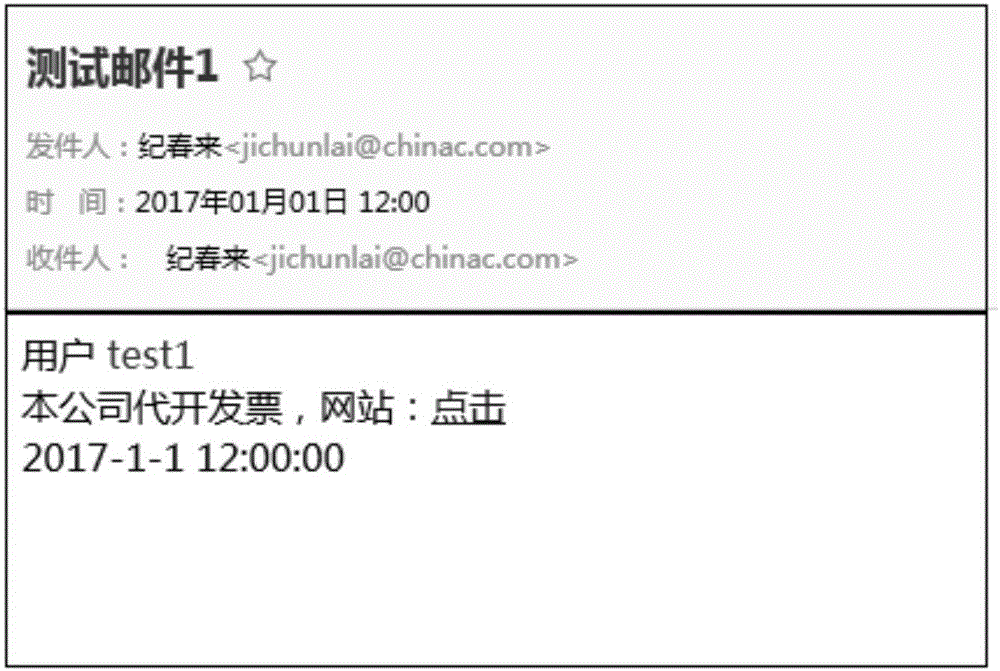
:随着互联网的发展,垃圾邮件对使用者造成的危害愈来愈大。垃圾邮件中通常包括推销邮件或者具有色情或者其他不良信息的邮件。为此,现有技术中出现了多种反垃圾邮件的识别及过滤方法及后台服务器过滤机制。目前主流的反垃圾邮件的方法主要包括:(1)光学字符识别法(OCR),其通过实现对包含广告图片或者纯文本的内容进行提取,通过内容判断是否广告内容,从而实现垃圾邮件的识别,但是这种技术对计算机造成的开销较大。(2)基于MD5校验的邮件检测技术,其通过将任意长度的字符串执行散列运算,转换成较短的固定长度的值。由于任意两个不同字符串的MD5值不相同,因此可通过比较两个字符串的MD5值来判断两个字符串是否相同。但是这种反垃圾邮件技术对邮件内容非严格相同,出现任何变化时都会导致MD5值的不同,从而严重影响对该邮件是否为垃圾邮件的判定并执行过滤及拦截操作。(3)基于贝叶斯分类器对垃圾邮件进行过滤的现有技术,相关专利可参考中国发明专利CN200510135603.3、中国发明专利CN200410063953.9、中国发明专利CN200510087762.0、中国发明专利CN200510082282.5等。但是,在使用贝叶斯分类器在对邮件进行分类时,需要预先对垃圾邮件建模,并依据模型对后续邮件进行分类,因此现有的反垃圾邮件技术存在步骤繁琐且可靠性较低的缺陷。同时,现有技术中的反垃圾邮件技术直接对邮件(其主要为HTML格式的邮件)中包含的预先设定的文字或者图片进行扫描检测,这样势必导致对正常发送的邮件也需要执行上述检验或者过滤操作,因此会增加后台服务器或者网页搜索引擎的计算开销。有鉴于此,有必要对现有技术中的对垃圾邮件的识别方法予以改进,以解决上述问题。技术实现要素:本发明的目的在于公开一种通过HTML标签识别垃圾邮件的方法,用以实现对HTML格式的垃圾邮件进行有效识别,降低后台服务器或者网页搜索引擎的计算开销,简化识别垃圾邮件的步骤。为实现上述发明目的,本发明提供了一种通过HTML标签识别垃圾邮件的方法,包括以下步骤:S1、构建使用字符描述HTML代码中标签的标签描述表;S2、顺序提取垃圾邮件的HTML代码中的标签,并根据标签描述表提取包含多个字符的校验数据;S3、在接收到新邮件后,提取新邮件的HTML代码,并根据标签描述表将新邮件的HTML代码中的标签翻译成描述数据;S4、将描述数据与校验数据进行比较,以至少将命中校验数据的描述数据所对应的新邮件判定为垃圾邮件。作为本发明的进一步改进,将至少匹配校验数据的首部排列顺序或者尾部排列顺序的描述数据所对应的新邮件判定为垃圾邮件。作为本发明的进一步改进,所述标签描述表包括若干条记录,所述记录由校验数据及校验数据的长度信息组成;若使用标签描述表对新邮件的HTML代码中的标签进行翻译后所得的描述数据的长度信息与校验数据的长度信息相等,则将新邮件判定为垃圾邮件。作为本发明的进一步改进,所述方法还包括:所述校验数据的长度信息的取值范围为[m,n],若使用标签描述表对新邮件的HTML代码中的标签进行翻译后所得的描述数据的长度信息位于校验数据的长度信息的取值范围内,则将新邮件判定为垃圾邮件。作为本发明的进一步改进,所述校验数据的长度信息的取值范围的上限n取100,取值范围的下限m取20。作为本发明的进一步改进,所述字符为数字、字母、或者ASCⅡ码中的一种或者两种以上任意组合的计算机可读数据。作为本发明的进一步改进,所述字符的字节长度固定。作为本发明的进一步改进,所述方法还包括将与校验数据重合度高于80%的描述数据所对应的新邮件判定为垃圾邮件。作为本发明的进一步改进,所述方法还包括将新邮件的描述数据扫描校验数据,若描述数据与校验数据相重合的片段中所包含的字符数高于描述数据所包含的字符数量的80%,则将所述新邮件判定为垃圾邮件;其中,所述描述数据与校验数据相重合的片段的长度大于或者等于10个字符。与现有技术相比,本发明的有益效果是:在发明中,仅需要通过将新邮件的HTML代码所组成的描述数据与事先设定的垃圾邮件中的HTML代码所所组成的校验数据进行比较,以判定新邮件是否为垃圾邮件,由于整个过程中仅需要对字节数非常小的字符进行比对,因此显著地降低了后台服务器或者网页搜索引擎的计算开销,简化了识别垃圾邮件的步骤;同时,垃圾邮件发送者无论对垃圾邮件的文本内容作何种干扰,最终从该垃圾邮件中提取出的HTML代码均具有一致性,因此可高效率地对邮件是否为垃圾邮件作出准确判断。附图说明图1为本发明一种通过HTML标签识别垃圾邮件的方法流程图;图2为在计算机中所预先输入的一封垃圾邮件样本图;图3为图2所示的垃圾邮件所对应的HTML代码;图4为图2所示出的垃圾邮件发送者对另一个邮件接受者所发送发的拟被判定为垃圾邮件的新邮件的样本图;图5为图4所示的拟被判定为垃圾邮件的新邮件的HTML代码;图6为正常邮件的样本图;图7为图6所示出的正常邮件的HTML代码图;图8为另一封待判定的新邮件的HTML代码中的标签经过标签描述表翻译所形成的描述数据中的头部、中部及尾部与预先输入的垃圾邮件的校验数据分别相似的示意图;图9为再一封待判定的新邮件的HTML代码中的标签经过标签描述表翻译所形成的描述数据中的头部、中部及尾部与预先输入的垃圾邮件的校验数据全部相似的示意图。具体实施方式下面结合附图所示的各实施方式对本发明进行详细说明,但应当说明的是,这些实施方式并非对本发明的限制,本领域普通技术人员根据这些实施方式所作的功能、方法、或者结构上的等效变换或替代,均属于本发明的保护范围之内。请参图1所示的本发明一种通过HTML标签识别垃圾邮件的方法的一种具体实施方式。本发明所示出的方法主要用于对HTML格式的邮件进行垃圾邮件的判定。在本说明书中,术语“邮件”等同于术语“电子邮件”。用户在电脑或者接入互联网的设备的网页或者邮件应用软件中接收到对端发送的邮件,并在本地计算机或者邮件服务器中对接收到的新邮件进行判定。本发明一种通过HTML标签识别垃圾的方法包括以下步骤。首先,构建使用字符描述HTML代码中的标签的描述表。HTML(超文本标记语言)是目前网络上应用最为广泛的语言,也是构成网页文档的主要语言。HTML文本是由HTML命令组成的描述性文本,HTML命令可以说明文字、图形、动画、声音、表格、链接等。HTML的结构包括头部(Head)、主体(Body)两大部分,其中头部描述浏览器所需的信息,而主体则包含所要说明的具体内容。为了实现对垃圾邮件的判定,首先需要定义垃圾邮件。相对于传统的垃圾邮件判定方法,本发明不提取邮件的文本信息或者图形数据,而基于HTML格式的邮件的中的HTML代码中的标签的出现次数、顺序或者排列规律进行统计并形成用于表征及描述该垃圾邮件的垃圾属性。本发明所示出的方法可运行于邮件服务器中,邮件服务器连接数据库,用于保存描述表等信息。对于图形化的邮件其均由文本(Text)与HTML代码组成。而HTML代码对于文本的描述具有特有的规格与顺序。在邮件服务器或者接收邮件的本地服务器中对邮件进行解码后,即可示出该邮件的HTML代码。在实施方式中,所述字符为数字、字母、或者ASCⅡ码中的一种或者两种以上任意组合的计算机可读数据。优选的,在本实施方式中,字符的字节长度固定,该字符字节长度小于或者等于3个标准字节长度。由此形成如下表1所示的标签描述表。标签描述表可保存于本地邮件服务器所关联的数据库中,并通过管理员对标签描述表中的标签与字符的对应关系及字符种类作修改。对于数据库中所预先输入的垃圾邮件的HTML代码中标签数量过多的话,将与标签具对应关系的字符位数统一为2个标准字节长度,并最高不超过3个标准字节长度。标签字符标签字符标签字符标签字符A/AREAaFRAMEkOBJECTuSUP5BbFRAMESETlOLvTABLE6BRcH1-H6mPwTD7CENTERdHRnPRExTEXTAREA8DDeIFRAMEoSCRIPTyTR9DIVfIMGpSELECTzUL0DLgINPUTqSPAN1DThLABELrSTRONG2FONTiLEGENDsSTYLE3FORMjMAPtSUB4表1-标签描述表由于,垃圾邮件的发送行为通常具有一定的规律性。例如同一发送者对不同收件人发送的内容相同或者不同的邮件内容的邮件中,其邮件的HTML代码中的标签往往具有同一性或者基本保持相同。因此,对于标签的描述可对邮件是否为垃圾邮件作快速且准确的判定。在后续对垃圾邮件进行描述以及后续对新邮件的判定过程中,通过与该标签描述表中对应的字符、字符顺序及匹配度进行比较,以判断新邮件是否为垃圾邮件。接下来,顺序提取垃圾邮件的HTML代码中的标签,并根据标签描述表提取包含多个字符的校验数据。参图2所示,图2示出了预先输入的一封垃圾邮件,图2所示出的垃圾邮件的HTML代码如图2所示。“<>”中内容为标签。由此,将图2中的HTML代码中的标签按照HTML代码的顺序(参图3所示),顺序地提取多个标签后进行记录。图3中的垃圾邮件的标签为“div、span、div、a、div”。然后,将上述标签与表1所示的标签描述表中标签与字符的关系,将上述垃圾邮件的标签进行替换为“f、1、f、a、f”,从而将根据标签表述表提取由多个具有排列顺序字符所组成的校验数据,可将校验数据存入与本地邮件服务器所关联的数据库中。该数据库包括MySQL数据库、Oracle数据库或者DB2数据库。如图2所述,预先输入的垃圾邮件的发件人邮件地址为“jichunlai@chinac.com”,收件人邮件地址为“jichunlai@chinac.com”,邮件内容为“用户test1,本公司代开发票,网址:点击”,2017-1-112:00:00。其中,“点击”为一个超链接,并可能链接至恶意网址、黄色网址或者销售网址。参图4及图5所示,如果预先输入的垃圾邮件的发件人在不同时间向同一个收件人发送了内容相同的邮件,则可被认定为垃圾邮件。但是,在本发明中无需对疑似垃圾邮件的文本内容进行判定,而是基于邮件的HTML代码中的标签与标签描述表中所对应的描述数据与垃圾邮件的HTML代码中的标签与标签描述表中所对应的校验数据进行比对来确定新邮件(参图4所示)是否为垃圾邮件。如图4所示,新邮件的发件人邮件地址为“jichunlai@chinac.com”,收件人邮件地址为“jichunlai@chinac.com”,邮件内容为“用户zhangsan,本公司代开发票,网址:点击”,2017-1-218:00:00。其中,“点击”为一个超链接,并可能链接至恶意网址、黄色网址或者销售网址。参图5所示,该新邮件的HTML代码的标签依然为“div、span、div、a、div”。接下来,将上述邮件的HTML代码的标签与表1的标签描述表中标签与字符的关系,将上述垃圾邮件的标签进行翻译并替换为“f、1、f、a、f”,从而得到描述数据。由于垃圾邮件发送者发送的垃圾邮件具有格式的固定性与一定的规律。因此,同一垃圾邮件的发送者在不同时间发送的内容相同的垃圾邮件或者同一垃圾邮件发送者在相同或者不同时间向不同收件人所发送的内容相同的垃圾邮件的HTML代码的标签在表1所示出的标签描述表进行翻译后所形成的描述数据与预先输入的垃圾邮件的校验数据具有同一性或者基本保持相同。因此,在本实施方式中,可在接收到新邮件后,提取新邮件的HTML代码,并根据标签描述表将新邮件的HTML代码中的标签翻译成描述数据,然后将描述数据与校验数据进行比较,以至少将命中校验数据的描述数据所对应的新邮件判定为垃圾邮件。在本实施方式中,所述“命中”的含义为:校验数据与描述数据中的字符类型及字符排列顺序相同。参图6与图7所示的一封非垃圾邮件(另一封新邮件),及其该非垃圾邮件的HTML代码。在图7中,该新邮件的HTML代码中的标签为“div、div、div”,其通过与表1进行对标签进行替换或者翻译后所形成的描述数据为“f、f、f”。该描述数据与图2所示出的预先输入的垃圾邮件的校验数据“f、1、f、a、f”在字符的长度、字符的排布顺序均不同,因此可将图6所示出的新邮件判定为非垃圾邮件。基于垃圾邮件发送者通常会对垃圾邮件的邮件内容进行伪装或由于垃圾邮件发送时间的不同而导致邮件内容中时间属性或者发送时间存在差异,例如,在垃圾邮件中插入与推销内容无关的图片、音频文件等干扰信息或者如图2与图4中所显示的邮件内容中发送时间的不同。但是由于垃圾邮件中需要向邮件接受者发送的推销内容是相同或者类似的。因此,垃圾邮件的HTML代码中的标签根据标签描述表进行翻译后所形成的描述数据中会呈现出全部相同或者部分相似性。只要待判定的新邮件的HTML代码的标签经过表一所示出的标签描述表进行翻译后所形成的描述数据中一段段连续的数据片段与数据库中预先输入的垃圾邮件所对应的校验数据基本相匹配,即可将该新邮件判定为垃圾邮件。具体的,新邮件的描述数据与预定义的垃圾邮件的校验数据的相似性或者部分相似性具体如下所述。该部分相似性可以是描述数据中的位于头部的部分描述数据与校验数据相匹配(参图8中所示),该部分相似性也可以是描述数据中的位于中部的部分描述数据与校验数据相匹配(参图8中所示),该部分相似性也可以是描述数据中位于尾部的部分描述数据与校验数据相匹配(参图8中所示),从而实现将至少匹配校验数据的首部排列顺序或者尾部排列顺序的描述数据所对应的新邮件判定为垃圾邮件。具体的,如果一封新邮件的HTML代码的标签根据标签描述表进行翻译后所形成了如图8所示的描述数据“a、b、…、h、i…、e、q、q、…、q、6、0、0、…、f、…、f、5”。如果上述描述数据的头部“a、b、…、h、i”与预先设定的一封垃圾邮件的校验数据相同或相似,则可认定该新邮件为垃圾邮件。同理所示,如果新邮件的描述数据的中部“e、q、q、…、q、6、0、0”与另一封垃圾邮件的校验数据相同或相似,则可认定该新邮件为垃圾邮件;如果新邮件的描述数据的尾部“f、…、f、5”与预先设定的另一封垃圾邮件的校验数据相同或相似,则可认定该新邮件为垃圾邮件。当然,只要图8所示出的描述数据所对应的待判定的新邮件中呈连续的字符所组成的子描述数据(相对于整个描述数据的单元)与预先在数据库或者服务器中所输入的垃圾邮件的校验数据相同或者相似的话,就可将该新邮件判定为垃圾邮件。因此,通过上述方式,可有效地对克服垃圾邮件发送者人为加入各种干扰信息在应用本发明所示出的方法进行垃圾邮件的判定过程中所造成的各种干扰,在保证判定准确性的同时,尽可能的提高对伪装或者封装干扰信息的垃圾邮件进行精确地识别与判定,显著地降低了后台服务器或者网页搜索引擎的计算开销。在本实施方式中,该标签描述表包括若干条记录,所述记录由校验数据及校验数据的长度信息组成。若使用标签描述表对新邮件的HTML代码中的标签进行翻译后所得的描述数据的长度信息与校验数据的长度信息相等,则将新邮件判定为垃圾邮件。具体的,参图2至图5所示,预先设定的垃圾邮件的HTML代码的标签的校验数据(即“f、1、f、a、f”)的长度信息为5,图4与图5所示出的新邮件的HTML代码的标签的描述数据(即“f、1、f、a、f”)的长度信息为也为5。因此,通过上述校验数据与描述数据的长度信息的对比,即可将图4所示的新邮件判定为垃圾邮件。在上述比较过程中,计算机仅需要对字节数非常少的描述数据与校验数据进行对比,可显著减少计算机的计算开销,提高了对垃圾邮件的判定效率。在本实施方式中,该通过HTML标签识别垃圾邮件的方法还包括:所述校验数据的长度信息的取值范围为[m,n],若使用标签描述表对新邮件的HTML代码中的标签进行翻译后所得的描述数据的长度信息位于校验数据的长度信息的取值范围内,则将新邮件判定为垃圾邮件。其中,该校验数据的长度信息的取值范围的上限n取100,取值范围的下限m取20。需要说明的是,如果一封邮件是非垃圾邮件,则该邮件的HTML代码经过表一所示出的标签描述表翻译而成的描述数据不可能过长。因此,结合实际情况,在本实施例中,校验数据的长度信息的上限n取100;如果过长,则会导致描述数据在扫描校验数据这一过程的计算开销。同时,校验数据的长度信息的下限m也不可能太短。太短则会导致在对新邮件造成误判,从而将非垃圾邮件判定为垃圾邮件。重新结合图8所示,为了进一步提高对新邮件的识别效率,在本发明中,该方法还包括将与校验数据重合度高于80%的描述数据所对应的新邮件判定为垃圾邮件。具体的,既可以将新邮件的HTML代码中的标签经过翻译后所形成的描述数据作为一个整体与预先输入的垃圾邮件的校验数据的整体进行比较,并将整体重合度高于80%的描述数据所对应的新邮件判定为垃圾邮件;也可将预先输入的垃圾邮件的校验数据的作为扫描单元,以对较长的描述数据进行扫描,如果命中描述数据中的一段描述数据或者一段描述数据的80%的字符与预先输入的垃圾邮件的校验数据相匹配或者命中,则将该新邮件判定为垃圾邮件。参图9所示,进一步的,在本实施方式中,还包括将新邮件的描述数据扫描校验数据,若描述数据与校验数据相重合的片段中所包含的字符数高于描述数据所包含的字符数量的80%,则将所述新邮件判定为垃圾邮件;其中,所述描述数据与校验数据相重合的片段的长度大于或者等于10个字符。于此情形中,图9中所示出的用三个虚线框标识的三个描述数据与校验数据相重合的片段(即“子描述数据”)。每个片段中均包含至少10个字符,且字符的字节数相同。本说明书中,为了简化表示,统一将字符的字节长度设定为1个标准字节长度。其中,三个片段中均与预先输入的垃圾邮件的校验数据中的字符的长度及排列顺序一致。假设,校验数据包含100个字符,且这100个字符具有特定的排列顺序。当本地邮件服务器接收到一份待判定的新邮件时,通过标签描述表所翻译得到的描述数据的长度为90个字符。将描述数据顺序扫描校验数据;如果描述数据中的一段字符(字符数量大于或者等于10)命中校验数据中的一个连续片段,且描述数据命中校验数据中的片段中所包含的字符的数量与预先输入的垃圾邮件所对应的校验数据中所包含的字符的数量重合度在80%以上,则可将该待判定的新邮件判定为垃圾邮件。从而实现了在保证较低的计算开销的前提下,又能够提高对垃圾邮件进行判定的准确率,防止出现误判。上文所列出的一系列的详细说明仅仅是针对本发明的可行性实施方式的具体说明,它们并非用以限制本发明的保护范围,凡未脱离本发明技艺精神所作的等效实施方式或变更均应包含在本发明的保护范围之内。对于本领域技术人员而言,显然本发明不限于上述示范性实施例的细节,而且在不背离本发明的精神或基本特征的情况下,能够以其他的具体形式实现本发明。因此,无论从哪一点来看,均应将实施例看作是示范性的,而且是非限制性的,本发明的范围由所附权利要求而不是上述说明限定,因此旨在将落在权利要求的等同要件的含义和范围内的所有变化囊括在本发明内。不应将权利要求中的任何附图标记视为限制所涉及的权利要求。此外,应当理解,虽然本说明书按照实施方式加以描述,但并非每个实施方式仅包含一个独立的技术方案,说明书的这种叙述方式仅仅是为清楚起见,本领域技术人员应当将说明书作为一个整体,各实施例中的技术方案也可以经适当组合,形成本领域技术人员可以理解的其他实施方式。当前第1页1 2 3
相关技术
网友询问留言
已有0条留言
- 还没有人留言评论。精彩留言会获得点赞!
1