基于图像局部分割的虚拟视点合成方法与流程
本发明属于数字图像处理技术领域,涉及图像增强方法,尤其涉及一种通过图像局部区域分割进行虚拟视点合成的方法,可用于视频监控系统和图像处理软件等。
背景技术:
裸眼三维技术(threedimensions,3d)和虚拟现实技术随着相应硬件市场的发展已经开始大范围普及,这种新型媒体相比传统媒体可以为用户提供更强的沉浸感,但是,新型媒体内容并没有催生与之匹配的采集设备。以裸眼3d为例,市场上的裸眼3d电视通常需要多路视点(8/9/27/64)输入,在仅有数量较少的相机的情况下,拍摄裸眼3d内容就需要对已有的真实视点进行扩充,比如由两路的立体相机拍摄的内容合成8路的视频流。这种通过已知视点的内容以及场景的深度信息对已知视点附近的一些虚拟的视点进行合成的技术就是虚拟视点合成技术。
现有传统的虚拟视点合成方法采用基于稠密深度图的虚拟视点合成技术,该方法对深度图的准确度依赖很大,深度图中的噪声和误差会对合成视点的质量造成很大的影响。而深度图的采集往往受限于场景的纹理复杂度和是否存在非漫反射的物体,无法做到非常精确。因此,现有虚拟视点合成方法对于深度图中的误差不够鲁棒,造成在深度图存在比较大的瑕疵的情况下视点合成的主观质量下降显著,难以保持场景的几何信息以产生真实的沉浸感。
技术实现要素:
为了克服上述现有技术的不足,本发明提供一种基于图像局部分割的虚拟视点合成方法,本方法能够在深度图存在比较大的瑕疵的情况下保证视点合成的主观质量不会显著下降,并最大可能地保持场景的几何信息以产生真实的沉浸感,改善现有方法在场景深度信息存在误差、噪声的情况下合成质量显著下降问题的不足,对于场景深度图信息中的误差有较强鲁棒性。
本发明提供的技术方案是:
一种基于图像局部分割的虚拟视点合成方法,将输入的左右图像映射到虚拟视点进行融合得到合成的图像;通过利用场景的物体分割信息对粗糙的、有噪声的深度图进行平滑去噪,并且在进行视点合成的过程中通过局部区域的切分来解决遮挡问题,对于场景深度信息中的误差有较强鲁棒性;包括如下步骤:
第一步,对输入的左右图像进行立体匹配并去除噪声;
首先使用立体匹配算法sgm(semiglobalmatching,半全局匹配算法)得到初始的视差图。对得到的左右视点的视差图进行左右一致性检验和比率测试,将每个像素位置的视差相应地标记为“可靠”,“不可靠”和“遮挡”,对标记为“遮挡”的视差可以通过周围的背景视差进行替换。
第二步,对初始的视差图切分成规则的网格,进行下采样;对得到的视差图中标记为“不可靠”的视差,通过场景的色彩信息进行替换;具体地,首先将视差图切分成规则的网格,并对每个格点周围的色彩信息使用lab颜色直方图进行记录。对于周围一定范围内有可靠视差的格点,进行平面拟合估计出一个视差。对于周围仅有不可靠深度的格点,通过在规则网格上利用动态规划算法求解最有可能与其位于同一物体上的格点,利用格点上的深度对其进行替换。
第三步,对于视差图上每个矩形网格,根据其四个角点的视差信息,判断该网格内是否存在深度断层;
由于位于深度断层上的矩形网格的内容在新合成的视点上会产生遮挡,因此需要将其中的前景物体和背景物体区域切分开分别进行映射。根据四个角度的视差信息还可以将需要切分的网格划分为“横向切分”、“纵向切分”、“对角线切分”,并以此确定分割线的起始边和终止边。寻找切分线的问题可以相应地转化为在网格寻找从初始边到终止边的最短路径问题,并通过动态规划求解。
第四步,将输入的左右图像映射到虚拟视点进行融合得到合成的图像;
对于内部没有深度断层的矩形网格,可以直接通过其角点上的视差信息映射到虚拟视点上;对于内部有深度断层的矩形网格,可以沿着切分线将它分成两部分,分别按照前景,背景的视差映射到虚拟视点上。合成的虚拟视点需要维护一个视差缓存区z-buffer,即在每个像素位置需要记录映射到这个位置上的像素对应的视差,具有更高视差值的像素会遮挡视差值较低的像素。
通过上述步骤,获得虚拟视点合成的图像。
与现有技术相比,本发明的有益效果是:
本发明提供一种基于图像局部分割的虚拟视点合成方法,能够在深度图存在比较大的瑕疵的情况下保证视点合成的主观质量不会显著下降,并最大可能地保持场景的几何信息以产生真实的沉浸感,改善现有方法在场景深度信息存在误差、噪声的情况下合成质量显著下降问题的不足,对于场景深度图信息中的误差有较强鲁棒性。本发明具有以下优点:
一,针对基于深度图的视点合成进行了改进,对含有噪声的深度图通过场景的纹理和分割信息进行平滑去噪,降低深度估计噪声对视点合成质量的影响。
二,利用场景的颜色信息和几何位置信息,使用视差图中可靠的视差来替换不可靠视差,提升了视差图的完整性。
三,利用场景的深度和颜色信息对图像的中含有深度断层的局部区域进行切分,解决了虚拟视点合成中的遮挡问题。
附图说明
图1是本发明提供的虚拟视点合成方法的流程框图。
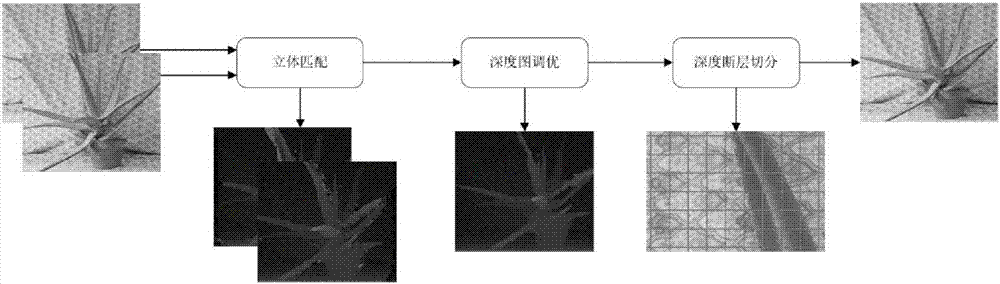
图2本发明实施例进行虚拟视点合成实施步骤的示意图。
图3是本发明实施例中虚拟视点合成效果的对比图。
其中,(a)为采用基于图像域形变的视点合成方法的合成结果;(b)为采用基于深度图的视点合成方法的合成结果;(c)为使用本发明提供的虚拟视点合成方法进行虚拟视点合成的结果。
具体实施方式
下面结合附图,通过实施例进一步描述本发明,但不以任何方式限制本发明的范围。
本发明提供一种基于图像局部分割的虚拟视点合成方法,通过利用场景的物体分割信息对粗糙的、有噪声的深度图进行平滑去噪,并且在进行视点合成的过程中通过局部区域的切分来解决遮挡问题,从而获得虚拟视点图像;图1是本发明提供的虚拟视点合成方法的流程框图。本发明对于场景深度信息中的误差有较强鲁棒性。
图2表示了本发明实施例进行虚拟视点合成的实施步骤,实施例输入的左、右图像为middlebury立体匹配数据集中的一组测试图片aloe,首先经过立体匹配得到初始视差图,对初始视差图进行下采样和调优得到规则网格上的稀疏视差,将所有含有深度断层的网格进行切分开,最终将输入的左右图像映射到虚拟视点进行融合得到合成的图像,具体包括如下步骤:
第一步:对输入的左右图像进行立体匹配并去除噪声。首先使用sgm立体匹配算法得到初始的视差图。对得到的左右视点的视差图进行左右一致性检验和比率测试。
第二步:对初始视差图进行下采样,得到稀疏的深度图。首先将视差图切分成规则的网格,并对格点位置上的稀疏视差进行估计,具体步骤分为两轮。
在第一轮中,对格点位置(p,q),采集其周围大小为δx×δy窗口内部所有的可靠视差值并构建一个大小为max_disparity+1的视差直方图h。记h中具有最多数量的视差级为d*,s为窗口内可靠视差的总数量。如果满足式1表示的约束条件,则标记当前格点位置为“可靠”:
其中,阈值参数取值可τ1=0.5;τ2=0.8。
以集合
π(x,y)=πax+πby+πc(式2)
式2中,πa,πb,πc为拟合的平面系数。
并据此计算当前格点的视差值disp(p,q)为:
disp(p,q)=πaδxp+πbδyq+πc(式3)
p、q为路径上相邻两个节点
在第二轮中,对于没有标记为“可靠”的格点位置(“不可靠”的格点位置)的视差进行估计。具体地对每个格点位置,收集其周围δx×δy窗口内的lab颜色信息(lab为一种颜色空间)并构建一个直方图。记当前“不可靠”的格点位置为ns,对其周围w/6×h/6范围内的所有“可靠”格点
其中,d(.,.)表示两个lab直方图之间的χ2距离,γ代表一条路径经过的节点,c(.,.)表示两个节点间路径的代价,
第三步:对于每个矩形网格,根据其四个角点的视差信息,判断该网格内是否存在深度断层。由于位于深度断层上的矩形网格的内容在新合成的视点上会产生遮挡,因此需要将其中的前景物体和背景物体区域切分开分别进行映射。
对于一个矩形网格q(p,q),将其四个角点上的视差值{d1,d2,d3,d4}根据式5分为子集s1、s2、…sk…:
以n表示分割后子集的总个数,如果n=1,那么该网格内不存在深度断层,不需要进行切分。如果n=2,那么该网格内存在深度断层,需要进行切分。如果n≥3,那么当前网格的角点视差不一致,舍弃当前的网格。对于n=2的情况,我们还可以根据角点的视差分布将其分为“横向切分”,“纵向切分”或“对角线切分”。
以“横向切分”为例,记该网格内竖直方向的左右两个边分别为起始边和终止边,寻找切分线的问题可以转化为求解所有从起始边上某个节点到终止边上某个节点的路径中花费最小的一条,其中路径上相邻两个节点p,q的花费定义为p点上的边缘强度。
第四步:对于内部没有深度断层的矩形网格,可以直接通过其角点上的视差信息映射到虚拟视点上。对于内部有深度断层的矩形网格,可以沿着切分线将它分成两部分,分别按照前景、背景的视差映射到虚拟视点上,用视差缓存区(z-buffer)消除遮挡的像素。
对左右视图il,ir分别进行上述视点映射后,需要通过式6对得到的虚拟视点图像进行融合,得到最终的合成视点im:
其中,0<α<1,表示虚拟视点到左视点il的归一化距离;im为最终的合成视点,
图3是本实施例最终的输出结果,并经本发明方法得到的结果与传统的方法的进行比较,如图3所示,其中,(a)为采用基于图像域形变的视点合成方法的合成结果;(b)为采用基于深度图的视点合成方法的合成结果;(c)为使用本发明提供的虚拟视点合成方法进行虚拟视点合成的结果。图3表明,本发明方法能有效减少传统方法合成产生的瑕疵。
需要注意的是,公布实施例的目的在于帮助进一步理解本发明,但是本领域的技术人员可以理解:在不脱离本发明及所附权利要求的精神和范围内,各种替换和修改都是可能的。因此,本发明不应局限于实施例所公开的内容,本发明要求保护的范围以权利要求书界定的范围为准。
- 还没有人留言评论。精彩留言会获得点赞!