一种候选口令字典的生成方法与装置与流程
本发明涉及信息安全领域,尤其涉及一种候选口令字典的生成方法与装置。
背景技术:
口令是目前最常用、最可靠的认证形式,并且在可以预知的未来,口令仍然是用户身份认证的主要形式。因此,口令是系统安全的第一道防线,选择不易被猜测的口令对于采用口令认证的系统来说至关重要。人们在选择口令时,很多人会选择使用弱口令、或者在多个不同服务之间使用相同的口令,这样就给用户的信息安全带来了潜在的威胁。因此,评估用户口令的安全性就是保护重要系统安全的有效措施之一,破解口令是评估用户口令安全性的有效方法。
除了根本不考虑安全性的系统之外,用户口令被散列或加密处理后将结果保存在系统中。散列是一种使用散列函数将任意长度字符串变换为固定长度值的数学映射。散列函数被设计为单向函数,也就是说,将字符串散列为一个值时很容易,所需计算资源也不太多,但由散列值求取原始字符串时,不存在相应的数学表示,只能使用尝试方法猜测可能的原始字符串,即通过破解散列值得到相应的口令。
破解散列的方法很多,主要包括暴力破解、字典破解两大类。暴力破解尝试密钥空间中的每一个口令,理论上可以破解所有口令,但现实中通常只能破解长度较短的口令,主要原因是计算资源不足和慢速散列算法的广泛采用;字典破解尝试字典中的每一个词条,从中找出其散列值与待破解散列值相同的词条,字典通常词条数量有限,因此破解速度很快。但是,字典破解的成功率严重依赖于字典的优劣。
生成字典的方法有很多,包括收集曾经用过的各种口令、人名、地名、语言字典等。也可以在已有字典的基础上增加一些变换,比如更改大小写、词条末尾添加一些数字、符号等构成新的字典。这样的字典由于覆盖面广,与特定用户关联性不大,因此要么破解成功率不高、要么字典规模过大,近似于达到暴力破解的规模,破解速度慢,效率低。
据统计,用户在创建口令时,47%的人使用名字缩写、朋友或家庭成员的名字;42%的人使用有意义的日期和数字;26%的人使用宠物的名字;21%的人使用生日;14%的人使用家乡的名字;13%的人使用毕业学校的名字和吉祥物的名字。
本发明提出的候选口令生成方案能够综合运用已知用户信息,并与用户语言相关的上万条常用口令结合,以口令选用概率为基础,生成任意规模的候选口令字典。
技术实现要素:
本发明的主要目的在于公开一种候选口令字典的生成方法与装置,以综合运用已知用户信息,并与用户语言相关的上万条常用口令结合,以口令选用概率为基础,生成任意规模的候选口令字典。
为达上述目的,根据本发明的一个方面,公开一种候选口令字典的生成方法,包括:根据目标对象的基础信息构建基本词条库;基于预设算法构建候选口令生成式,并根据所述生成式对所述基本词条库中的每个长度的词条生成相应的全部候选口令;从所述全部候选口令中输出符合预设条件的候选口令作为所述目标对象的候选口令字典。
进一步地,所述根据目标对象的基础信息构建基本词条库包括:获取与目标对象相关联的信息生成目标信息文件;按照预设规则对所述目标信息文件进行划分处理,得到由单词组成的词汇表,按每个单词占据一行进行排练,生成目标信息词汇表;将所述目标信息词汇表与预设常用口令按预设规则进行合并,去除重复词条后得到无重复目标信息表;统计所述无重复目标信息表中符合预设长度的词条,将每一个长度的词条放在一个表中,得到所述基本词条库。
进一步地,所述预设算法为:长度为n的词条的候选口令生成式构建方法为:从所述基本词条库中选择长度不超过n的词条,使得所选择的长度不超过n的词条的长度和为n,所述候选口令生成式的数量为:2(n-1)。
进一步地,所述预设条件包括:候选口令的长度阈值;每次输出候选口令的个数;以及当前待输出候选口令长度。
进一步地,在所述从所述全部候选口令中输出符合预设条件的候选口令作为所述目标对象的候选口令字典之前,所述生成方法还包括:判断是否输出完符合所述长度阈值的全部候选口令,若是,输出所述候选口令字典,若否,继续判断当前候选看来长度是否超出所述长度阈值,若是,执行如下步骤:获取当前口令个数:当前需要输出的候选口令个数m=每次输出候选口令个数乘以当前候选口令长度的概率;使用当前候选口令长度生成式生成m个候选口令,记录生成式中生成最后一个候选口令的位置,并令当前候选口令长度加1。
根据本发明的另外一个方面,提供一种候选口令字典的生成装置,并采用如下技术方案:
该候选口令字典的生成装置包括:构建模块,用于根据目标对象的基础信息构建基本词条库;第一生成模块,用于基于预设算法构建候选口令生成式,并根据所述生成式对所述基本词条库中的每个长度的词条生成相应的全部候选口令;输出模块,用于从所述全部候选口令中输出符合预设条件的候选口令作为所述目标对象的候选口令字典。
进一步地,所述构建模块包括:第一获取模块,用于获取与目标对象相关联的信息生成目标信息文件;处理模块,用于按照预设规则对所述目标信息文件进行划分处理,得到由单词组成的词汇表,按每个单词占据一行进行排练,生成目标信息词汇表;合并模块,用于将所述目标信息词汇表与预设常用口令按预设规则进行合并,去除重复词条后得到无重复目标信息表;统计模块,用于统计所述无重复目标信息表中符合预设长度的词条,将每一个长度的词条放在一个表中,得到所述基本词条库。
进一步地,所述预设算法为:长度为n的词条的候选口令生成式构建方法为:从所述基本词条库中选择长度不超过n的词条,使得所选择的长度不超过n的词条的长度和为n,所述候选口令生成式的数量为:2(n-1)。
进一步地,所述预设条件包括:候选口令的长度阈值;每次输出候选口令的个数;以及当前待输出候选口令长度。
进一步地,所述的生成装置还包括:判断模块,用于判断是否输出完符合所述长度阈值的全部候选口令,若是,输出所述候选口令字典,若否,继续判断当前候选口令长度是否超出所述长度阈值,若是,启动如下模块:第二获取模块,用于获取当前候选口令个数:当前需要输出的候选口令个数m=每次输出候选口令个数乘以当前候选口令长度的概率;第二生成模块,用于使用当前候选口令长度生成式生成m个候选口令,记录生成式中生成最后一个候选口令的位置,并令当前候选口令长度加1。
本发明将目标信息文件拆分为由独立词条组成的目标信息词汇表;与常用口令字典组合并去除,构成无重复目标信息表;生成概率表示的目标语言口令长度分布表;生成按词条长度分类的基本词条库;构造候选口令生成式,给出使用较短词汇生成较长口令的规则;依据所给算法生成用于渗透测试及用户口令安全性评估的字典。通过分析目标信息生成用于评估用户口令安全性字典的方案,解决较长口令的密码破解问题。
附图说明
为了更清楚地说明本申请实施例或现有技术中的技术方案,下面将对实施例中所需要使用的附图作简单地介绍,显而易见地,下面描述中的附图仅仅是本发明中记载的一些实施例,对于本领域普通技术人员来讲,还可以根据这些附图获得其他的附图。
图1为本发明实施例一所述的一种候选口令字典的生成方法的流程图;
图2为本发明实施例二所述的一种候选口令字典的生成方法的流程图;
图3为本发明实施例三所述的一种候选口令字典的生成装置的结构示意图。
具体实施方式
以下结合附图对本发明的实施例进行详细说明,但是本发明可以由权利要求限定和覆盖的多种不同方式实施。
实施例一:
图1为本发明所提供的一种候选口令字典的生成方法的流程图。
参见图1所示,
一种候选口令字典的生成方法包括:
S101:根据目标对象的基础信息构建基本词条库;
S103:基于预设算法构建候选口令生成式,并根据所述生成式对所述基本词条库中的每个长度的词条生成相应的全部候选口令;
S105:从所述全部候选口令中输出符合预设条件的候选口令作为所述目标对象的候选口令字典。
在步骤S101中,根据目标对象的基础信息构建基本词条库具体可以通过如下方法实现:
步骤一,信息预收集。通过多种手段获取目标对象的基础信息,包括但不限于:姓名、单位、生日、电话、身份识别号码、邮编、驾照号码、先前使用的口令、邮件、用户名、个人爱好,比如球队名称、球星姓名、生日、电影名称、演员姓名、宠物名称、美食名称、亲属朋友信息等所有与目标关联性强的信息。将这些信息组织成文本文件,称作目标信息文件。
步骤二,处理目标信息文件,将其划分为由单词组成的词汇表,例如将邮件名称拆分为用户名及域名。每个单词占据一行,形成目标信息词汇表。
步骤三,扩充目标信息词汇表。得到与目标所用语言匹配的常用1万个口令组成的字典,该字典通过数据收集及分析预先做出,称作语言相关常用口令字典,该常用口令字典与目标信息词汇表拼接起来,去除重复词条,构成无重复目标信息表。
步骤四、统计目标语言口令长度分布,剔除长度超过32字符部分,保留1-32字符口令长度分布,计算每一个长度口令的频率,该频率=该长度口令总数/1-32字符口令总数,以这个频率分布作为该语言的口令长度的概率分布,构成目标语言口令长度概率分布表。
步骤五、按长度排序无重复目标信息表,每一个长度的词条放在一个表中,得到基本词条库。比如:
长度为1的词条a放在表1中;
长度为1的词条f放在表1中;
长度为3的词条the放在表3中;
长度为4的词条1234放在表4中;
长度为4的词条test放在表4中;
长度为4的词条pass放在表4中;
长度为10的词条1234567890放在表10中;
长度为10的词条qwertyuiop放在表10中;
长度为10的词条basketball放在表10中;
长度为12的词条unbelievable放在表12中;
长度为12的词条businessbabe放在表12中;
以此类推。
在步骤S103中,基于预设算法构建候选口令生成式,并根据所述生成式对所述基本词条库中的每个长度的词条生成相应的全部候选口令。
所述的基于预设算法构建候选口令生成式,长度为n的候选口令可以这样生成:从基本词条库中选择有限个词条(每个词条的长度不超过n),它们的长度和等于n。每一个选择方法就是一个生成式。对于长度为n的候选口令来说,这样的生成式数量为2(n-1)。比如,候选口令长度为1的生成式个数为1,候选口令长度为2的生成式个数为2,候选口令长度为3的生成式个数为4,以此类推。表1给出了部分候选口令长度对应的生成式的个数。
表1
在步骤S105中,从所述全部候选口令中输出符合预设条件的候选口令作为所述目标对象的候选口令字典。首先要设置预设条件,即得到用户希望输出的候选口令的最小长度(记为pw-len-min)和最大长度(pw-len-max),例如,默认值分别为1和32。其次,设置每次输出候选口令个数n,例如默认值为10000。输出全部符合预设条件的候选口令,完成候选口令生成,构成用于渗透测试及用户口令安全性评估的概率候选口令字典。
实施例二
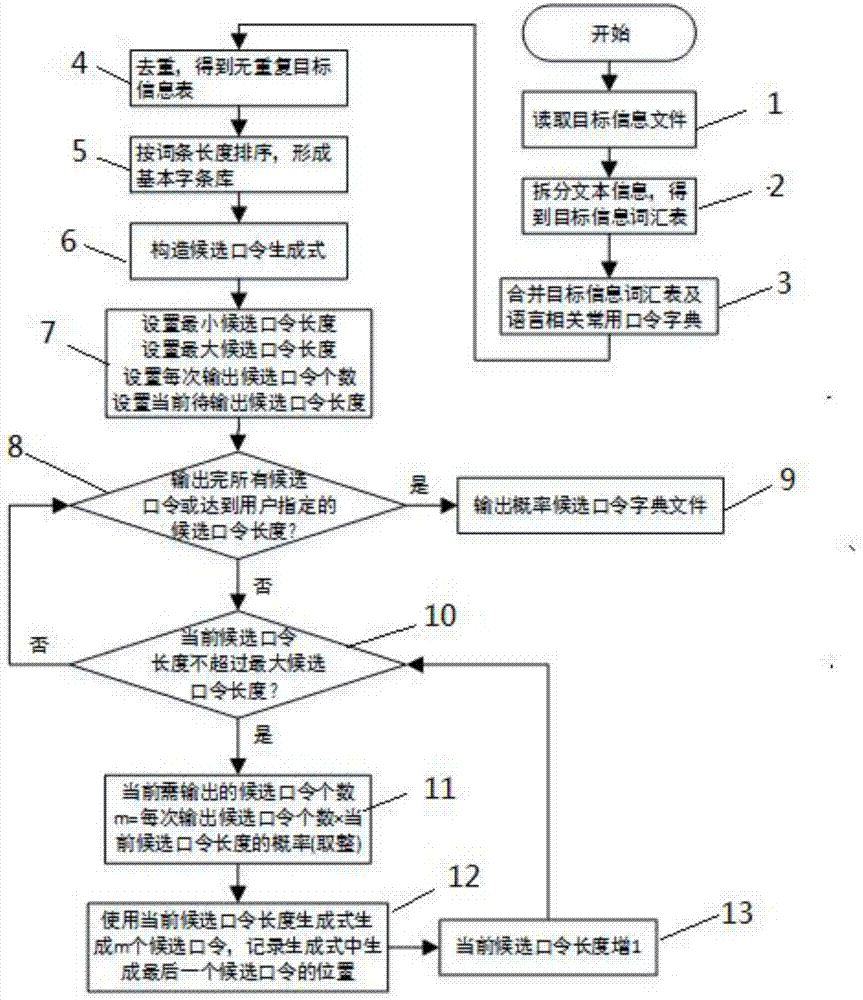
图2为本发明实施例二所述的一种候选口令字典的生成方法的流程图。
参见图2所示,一种候选口令字典的生成方法包括如下步骤:
步骤1:读取目标信息文件;
目标信息文件为与目标对象紧密度高的信息。
步骤2:拆分文本信息,得到目标信息词汇表;
在本步骤中,对步骤1中获取的文本信息进行拆分,拆分时需要注意目标语言习惯,汉语的拆分根据一个语义的词为单位,英语以单词为单位等等,拆分后组成目标信息词汇表。
步骤3:合并目标信息词汇表及语言相关常用口令字典;
在本步骤中,对目标信息词汇表进行扩充,即与常用上万个口令组成的字典进行合并,该常用字典通过数据收集及分析预先做出,称作语言相关常用口令字典,与目标信息词汇表拼接起来。
步骤4:去重,得到无重复目标信息表。
步骤5:按词条长度排序,形成基本字条库,可参见实施例一。
步骤6:构建候选口令生成式;
长度为n的候选口令可以这样生成:从基本词条库中选择有限个词条(每个词条的长度不超过n),它们的长度和等于n。每一个选择方法就是一个生成式。对于长度为n的候选口令来说,这样的生成式数量为2(n-1)。
比如,候选口令长度为1的生成式个数为1,候选口令长度为2的生成式个数为2,候选口令长度为3的生成式个数为4,以此类推。表1给出了部分候选口令长度对应的生成式的个数。
步骤7:设置最小候选口令长度,设置最大候选口令长度,设置每次输出候选口令个数,设置当前待输出候选口令长度。
在本步骤中,设置预设条件,根据预设条件输出候选口令。
步骤8:判断是否输出完所有候选口令或达到用户指定的候选口令长度。
在本步骤中,若是,执行步骤9,若否,执行步骤10.
步骤9:输出概率候选口令字典文件;
步骤10:判断当前候选口令长度不超过最大候选口令长度?
若是,说明没有输出完所有候选口令,执行步骤11和步骤12。
步骤11:当前需要输出的候选口令个数m=每次输出候选口令个数乘以当前候选口令长度的概率,然后取整。
步骤12:使用当前候选口令长度生成式生成m个候选口令,记录生成式中生成最后一个候选口令的位置
步骤13:当前候选口令长度增1。
上述步骤11-步骤13,从最小候选口令长度pw-len-min开始,直到最大候选口令长度pw-len-max为止(记录当前候选口令长度为k),重复下述步骤:
(i)、得到当前需要输出的候选口令个数m(=[n*当前候选口令长度的概率],[]表示取整);
(ii)、使用候选口令长度k的生成式,从基本词条库中依次获取对应长度的词条,并将这些词条拼接起来,生成m个候选口令,并输出这些候选口令;
(iii)、k的值增加1。
本发明将目标信息文件拆分为由独立词条组成的目标信息词汇表;与常用口令字典组合并去除,构成无重复目标信息表;生成概率表示的目标语言口令长度分布表;生成按词条长度分类的基本词条库;构造候选口令生成式,给出使用较短词汇生成较长口令的规则;依据所给算法生成用于渗透测试及用户口令安全性评估的字典。通过分析目标信息生成用于评估用户口令安全性字典的方案,解决较长口令的密码破解问题。
实施例三
图3为本发明实施例三所述的一种候选口令字典的生成装置的结构示意图。
参见图3所示,该候选口令字典的生成装置包括:构建模块301,用于根据目标对象的基础信息构建基本词条库;第一生成模块303,用于基于预设算法构建候选口令生成式,并根据所述生成式对所述基本词条库中的每个长度的词条生成相应的全部候选口令;输出模块305,用于从所述全部候选口令中输出符合预设条件的候选口令作为所述目标对象的候选口令字典。
优选地,所述构建模块301包括:第一获取模块(图中未示),用于获取与目标对象相关联的信息生成目标信息文件;处理模块(图中未示),用于按照预设规则对所述目标信息文件进行划分处理,得到由单词组成的词汇表,按每个单词占据一行进行排练,生成目标信息词汇表;合并模块(图中未示),用于将所述目标信息词汇表与预设常用口令按预设规则进行合并,去除重复词条后得到无重复目标信息表;统计模块(图中未示),用于统计所述无重复目标信息表中符合预设长度的词条,将每一个长度的词条放在一个表中,得到所述基本词条库。
优选地,所述预设算法为:长度为n的词条的候选口令生成式构建方法为:从所述基本词条库中选择长度不超过n的词条,使得所选择的长度不超过n的词条的长度和为n,所述候选口令生成式的数量为:2(n-1)。
优选地,所述预设条件包括:候选口令的长度阈值;每次输出候选口令的个数;以及当前待输出候选口令长度。
优选地,所述的生成装置还包括:判断模块(图中未示),用于判断是否输出完符合所述长度阈值的全部候选口令,若是,输出所述候选口令字典,若否,继续判断当前候选口令长度是否超出所述长度阈值,若是,启动如下模块:第二获取模块(图中未示),用于获取当前口令个数:当前需要输出的候选口令个数m=每次输出候选口令个数乘以当前候选口令长度的概率;第二生成模块(图中未示),用于使用当前候选口令长度生成式生成m个候选口令,记录生成式中生成最后一个候选口令的位置,并令当前候选口令长度加1。
本发明属将目标信息文件拆分为由独立词条组成的目标信息词汇表;与常用口令字典组合并去除,构成无重复目标信息表;生成概率表示的目标语言口令长度分布表;生成按词条长度分类的基本词条库;构造候选口令生成式,给出使用较短词汇生成较长口令的规则;依据所给算法生成用于渗透测试及用户口令安全性评估的字典。通过分析目标信息生成用于评估用户口令安全性字典的方案,解决较长口令的密码破解问题。
以上只通过说明的方式描述了本发明的某些示范性实施例,毋庸置疑,对于本领域的普通技术人员,在不偏离本发明的精神和范围的情况下,可以用各种不同的方式对所描述的实施例进行修正。因此,上述附图和描述在本质上是说明性的,不应理解为对本发明权利要求保护范围的限制。
- 还没有人留言评论。精彩留言会获得点赞!