识别监控信息系统应用的方法及装置与流程
本公开涉及网络安全领域,尤其涉及识别监控信息系统应用的方法及装置。
背景技术:
监控信息系统,例如厂级监控信息系统,主要为发电厂全厂的实时生产过程提供综合优化服务,其能够实现整个电厂范围内信息共享和全厂生产过程的实时信息监控。
监控信息系统的应用对电厂效率提升有显著作用,为了有效保障监控信息系统的运行,安全审计产品必不可少,在行业内,提供监控信息系统的厂家非常多,如何有效识别监控信息系统应用,成为了关键。
相关技术中,主要有两种方式来实现对监控信息系统应用的识别。一种方式是采用三层协议及四层端口的方式来唯一确定一个应用,这种方式不适合私有协议,仅适合公开协议。另一种方式通过分析数据流内容,提取唯一性的特征码来标记应用,这种方式误识别率相对较高,容易造成误报,并且投入大,需要保持更新。
技术实现要素:
为克服相关技术中存在的问题,本公开提供一种识别监控信息系统应用的方法及装置。
根据本公开实施例的第一方面,提供一种识别监控信息系统应用的方法,所述方法可以包括:获取网络中的数据包;提取所述数据包中的多个流量特征值;根据所述多个流量特征值建立特征值向量;对所述特征值向量进行聚类处理以形成多个向量簇;以及通过确定所述多个向量簇中数据密集度最高的向量簇来识别所述监控信息系统应用。
可选地,所述对所述特征值向量进行聚类处理以形成多个向量簇包括:根据所述特征值向量来生成聚类特征;以及对所述聚类特征进行所述聚类处理以形成所述多个向量簇。
可选地,所述根据所述特征值向量来生成所述聚类特征包括使用以下公式来生成所述聚类特征:
其中,表示所述聚类特征,N表示所述特征值向量的元素个数,di表示所述向量中第i个元素的值。
可选地,所述对所述聚类特征进行所述聚类处理以形成所述多个向量簇包括:根据所述聚类特征之间的距离来对所述聚类特征进行所述聚类处理以形成所述多个向量簇。
可选地,所述方法还包括:在形成新的聚类特征之后,根据该新的聚类特征与所述多个向量簇的每一个向量簇的簇中心的距离来确定该新的聚类特征所属的向量簇。
可选地,所述获取网络中的数据包包括:利用网络探针来获取所述网络中的所述数据包。
可选地,所述多个流量特征值至少包括:目的MAC地址、目的IP地址、传输协议以及目的端口。
可选地,所述多个流量特征值还包括以下中的至少一者:源MAC地址、源IP地址、源端口以及数据包净荷长度。
根据本公开实施例的第二方面,提供一种识别监控信息系统的应用的装置,该装置包括:获取单元,用于获取所述网络中的数据包;提取单元,用于提取所述数据包中的多个流量特征值;建立单元,用于根据所述多个流量特征值建立特征值向量;聚类单元,用于对所述向量进行聚类处理以形成多个向量簇;以及识别单元,用于通过确定所述多个向量簇中数据密集度最高的向量簇来识别所述监控信息系统应用。
可选地,所述聚类单元用于:根据所述特征值向量来生成聚类特征;以及对所述聚类特征进行所述聚类处理以形成所述多个向量簇。
本公开的实施例提供的技术方案可以包括以下有益效果:能够有效识别出监控信息系统应用的关键流量,从而为流量保证业务提供基础识别服务并且能够防止一些病毒因占有大量宽带而影响监控信息系统运行。
应当理解的是,以上的一般描述和后文的细节描述仅是示例性和解释性的,并不能限制本公开。
附图说明
此处的附图被并入说明书中并构成本说明书的一部分,示出了符合本发明的实施例,并与说明书一起用于解释本发明的原理。
图1是根据一示例性实施例示出的一种识别监控信息系统应用的方法的流程图;
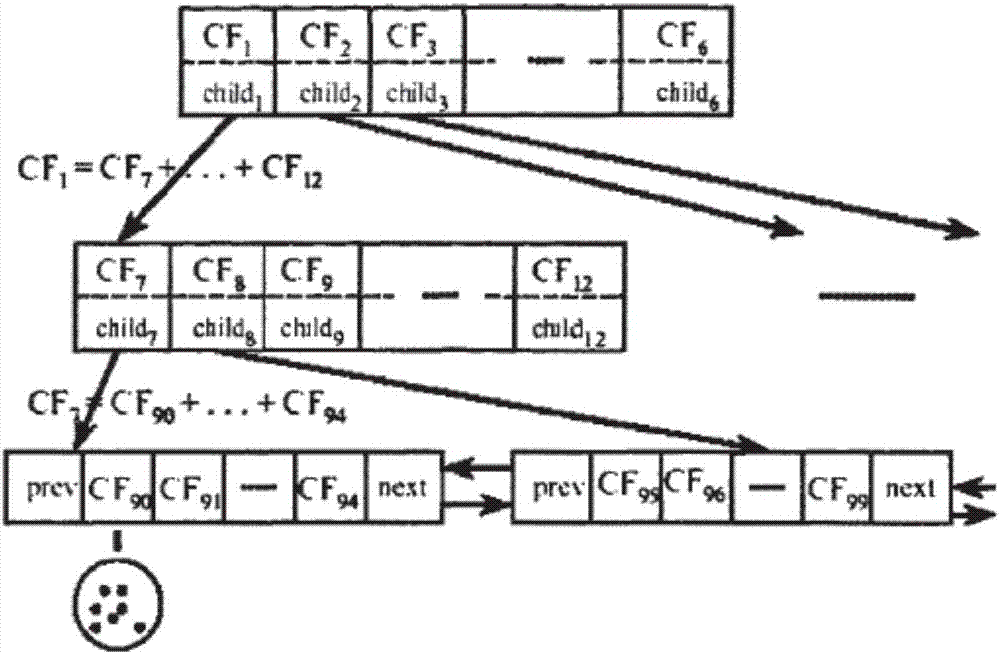
图2是BIRCH算法进行聚类的聚类结果示意图;
图3是根据又一示例性实施例示出的一种识别监控信息系统应用的方法的流程图;以及
图4是根据一示例性实施例示出的一种识别监控信息系统应用的装置的框图。
具体实施方式
这里将详细地对示例性实施例进行说明,其示例表示在附图中。下面的描述涉及附图时,除非另有表示,不同附图中的相同数字表示相同或相似的要素。以下示例性实施例中所描述的实施方式并不代表与本发明相一致的所有实施方式。相反,它们仅是与如所附权利要求书中所详述的、本发明的一些方面相一致的装置和方法的例子。
图1是根据一示例性实施例示出的一种识别监控信息系统应用的方法的流程图,所述监控信息系统例如可以电厂监控信息系统。如图1所示,识别监控信息系统应用的方法可以包括以下步骤。
在步骤S11中,获取网络中的数据包。
可选地,可以利用网络探针来获取网络中的数据包。
在步骤S12中,提取所述数据包中的多个流量特征值。
可选地,可以根据网络中数据流特点设置需要提取的流量特征值。例如,所提取的流量特征值至少可以包括目的MAC地址、目的IP地址、传输协议以及目的端口。除此之外,所提取的流量特征值还可以进一步包括:源MAC地址、源IP地址、源端口以及数据包净荷长度。
在步骤S13中,根据所述多个流量特征值建立特征值向量。
例如,可以将所提取数据包中的多个流量特征值直接组合成特征值向量。
在步骤S14中,对所述特征值向量进行聚类处理以形成多个向量簇。
对网络中的每一个数据包均执行步骤S11至步骤S13的处理,这样针对每一个数据包均可以形成一特征值向量,对所形成的这些特征值向量进行聚类处理后可以形成多个向量簇。
例如可以使用BIRCH(Balanced Iterative Reducing and Clustering using Hierarchies,利用层次方法的平衡迭代规约和聚类)聚类算法来对步骤S13中所建立的特征值向量进行聚类处理,但是本发明实施例并不限制于此,也可以使用任意的其它聚类算法对所述特征值向量进行聚类处理。
BIRCH算法是通过CF-Tree(Cluster Feature-Tree,聚类特征树)来实现的,其包括以下两个执行过程:
(1)生成聚类特征,聚类特征定义如下:CF=<n,LS,SS>,其中聚类特征CF为一个3维向量,n为需要聚类的数据点总数,LS为n个数据点的线性和,SS为n个数据点的平方和。
(2)执行CF聚类。得到CF聚类特征后,通过一个类似于B-树的算法进行聚类,其中B-树算法属于一种公开算法,这里将不再进行介绍。聚类后可以得到类似于图2所示的聚类结果,图2中第一层为聚类树的根节点,第二层为中间节点,第三层为叶节点,叶节点为对应的聚类结果,图2的示意图中,CF90…CF94为一类,而CF95…CF99为另外一类。
在步骤S15中,通过确定所述多个向量簇中数据密集度最高的向量簇来识别所述监控信息系统应用。
例如,可以通过统计所形成的多个向量簇中每个向量簇的元素个数来确定数据密集度最高的向量簇。
监控信息系统正常运行时,网络中60%至95%以上的流量都是监控信息系统的流量,对应于这些监控信息系统的流量的数据包在所提取的流量特征值上具有非常好的相似性,经过上述步骤S11至步骤S15,相似性很好的数据包可以被聚类在同一个向量簇中,这样,数据密集度最高的向量簇所代表的数据包就对应于监控信息系统的流量,从而实现识别监控信息系统应用的目的。
通过采用上述技术方案,能够有效识别出监控信息系统应用的关键流量,从而为流量保证业务提供基础识别服务并且能够防止一些病毒因占有大量宽带而影响监控信息系统运行。
在一示例性实施例中,所述对所述特征值向量进行聚类处理以形成多个向量簇可以包括:根据所述特征值向量来生成聚类特征;以及对所述聚类特征进行所述聚类处理以形成所述多个向量簇。
可选地,可以根据以下公式来将特征向量生成聚类特征:
在公式(1)中,表示所述聚类特征,N表示所述特征值向量的元素个数,di表示所述向量中第i个元素的值。
例如,在所提取的流量特征值包括源MAC地址、源IP地址、目的MAC地址、目的IP地址、传输协议、源端口、目的端口以及数据包净荷长度的情况下,公式(1)中的N为8,特征向量可以由上述八个特征值组成,di则对应表示上述八个特征值的每一个特征值。每一聚类特征唯一地表示了一个数据包,从而可以增加识别监控信息系统应用准确度。
进一步可选地,可以根据聚类特征之间的距离来对所述聚类特征进行所述聚类处理以形成所述多个向量簇。可选地,计算所述距离的函数可以是欧几里得距离函数、曼哈顿距离函数等。数据包之间的相似度越高其对应的聚类特征之间的距离就越小,根据聚类特征之间的距离可以快速有效地将实现对所述聚类特征进行聚类处理。
下面以所提取的流量特征值包括源MAC地址、源IP地址、目的MAC地址、目的IP地址、传输协议、源端口、目的端口以及数据包净荷长度为例,对本发明的方法进行进一步说明。如图3所示,该方法包括以下步骤:
在步骤S21中,首先利用网络探针获取网络中的数据包。这里可以假定利用网络探针获取了n个数据包,n为大于或等于1的正整数。
在步骤S22中,针对每一数据包提取上述八个流量特征值。
在步骤S23中,使用各自的八个流量特征值为每一数据包建立一特征值向量。
这里,针对每一数据包,可以将其对应的八个流量特征值组成特征值向量其中:
d1=源MAC地址;
d2=源IP地址;
d3=目的MAC地址;
d4=目的IP地址;
d5=传输协议;
d6=源端口;
d7=目的端口;
d8=数据包净荷长度。
在步骤S24中,根据特征值向量生成聚类特征具体地,可以根据以下公式来生成聚类特征,
在公式(2)中,
在公式(3)和公式(4)中i为整数。
这样网络中的每一个数据包经过步骤S22至步骤S24的处理后,先转变为特征值向量然后转化为聚类特征该聚类特征为一个三维向量,并且唯一地表示了一个数据包。
步骤S21中获取的n个数据包,首先经过步骤S22和步骤S23形成了向量其中
dj,1=第j个数据包的源MAC地址;
dj,2=第j个数据包的源IP地址;
dj,3=第j个数据包的目的MAC地址;
dj,4=第j个数据包的目的IP地址;
dj,5=第j个数据包的传输协议;
dj,6=第j个数据包的源端口;
dj,7=第j个数据包的目的端口;
dj,8=第j个数据包的数据包净荷长度。
对每一个向量都利用步骤S23的方法将其转化为一个聚类特征最终n个数据包形成n个聚类特征其中
其中dj,i为特征值向量的第i个值。
在步骤S25中,对步骤S24中生成的聚类特征进行聚类处理以形成向量簇。
这里根据聚类特征之间的距离来对聚类特征进行所述聚类处理,聚类特征之间的距离越近,所对应的数据包的相似度也越高。这里,可以设置一阈值,将聚类特征之间的距离小于该阈值的聚类特征归为一类进而形成向量簇,可选地,可以选用欧几里得距离函数来计算聚类特征之间的距离,其计算公式如下:
或者可以选用曼哈顿距离函数来计算聚类特征之间的距离,其计算公式如下:
d(k,j)=|(Xk-Xj)+(Yk-Yj)| (6)
这里,公式(5)和(6)中,(Xj,Yj)为聚类特征的第二个和第三个元素,参见公式(2)的第二个和第三个元素即为聚类特征的LS和SS,其中(Xk,Yk)为聚类特征的第二个和第三个元素,参见公式(2)的第二个和第三个元素即为聚类特征的LS和SS。
利用公式(5)或(6)计算出n个聚类特征之间的距离,然后将对应的距离小于预先设置的阈值的聚类特征归到一个向量簇中,从而完成对聚类特征的聚类处理。
在步骤S26中通过确定步骤S25中所形成的多个向量簇中数据密集度最高的向量簇来识别所述监控信息系统应用。可以通过统计所形成的多个向量簇中每个向量簇的元素个数来确定数据密集度最高的向量簇,数据密集度最高的向量簇所代表的数据包就对应于监控信息系统的流量,从而可以实现对监控信息系统应用的识别。
此外,在确定出对应于监控信息系统应用的数据密集度最高向量簇之后,对于获取的新的数据包,首先根据步骤S21至步骤S24生成新的聚类特征,该新的聚类特征对应于所获取的新的数据包,然后可以根据该新的聚类特征与所述多个向量簇的每一个向量簇的簇中心的距离来确定该新的聚类特征所属的向量簇。
可以根据以下公式来计算具有m个聚类特征的向量簇的簇中心C:
公式(7)中,LSi和SSi为向量簇中第i个聚类特征的第二个和第三个元素,其分别可以根据公式(2)和(3)计算获得。
类似地,可以根据公式(5)或(6)来计算新的聚类特征与簇中心之间的距离d,然后可以将该距离d与簇半径R进行比较,来确定该新的聚类特征是否属于该簇,其中簇半径R为向量簇中各个聚类特征与簇中心的距离的平均值,可以用以下公式来表示簇半径R:
其中,m为正整数,表示向量簇中聚类特征的个数,d(j,c)为向量簇中第j个聚类特征与簇中心的距离。
如果新的聚类特征与簇中心之间的距离d小于簇半径R,则可以表示该新的聚类特征与该向量簇中的聚类特征相似,可以归为同一类。否则可以继续遍历其它向量簇,知道找到该新的聚类特征所属的向量簇。如果遍历完全部的向量簇之后,依然没有找到该新的聚类特征所属的向量簇,则可以为该新的聚类特征建立一个新的向量簇。
如果采用BIRCH算法的话,则每一个向量簇对应于一个叶子节点,对于新的聚类特征,判断其所属向量簇就是判断该新的聚类特征属于哪个叶子节点,判断过程如下:
(1)计算新的聚类特征与BIRCH算法的聚类特征树中的每一个叶子节点的簇中心C距离d;
(2)如果d≤当前叶子节点半径R,则将新的聚类特征加入当前叶子节点中;
(3)如果d>当前叶子节点半径R,则继续计算新的聚类特征与下一个叶子节点的半径R的距离d;
(4)如果遍历完所有的叶子节点,仍然未找到合适的叶子节点,则新建一个叶子节点,将所述新的聚类特征加入新建的叶子节点中。
优选地,对于新的聚类特征可以直接通过上述方式判断该新的聚类特征是否属于上述步骤S26中确定出的数据密集度最高的向量簇,如果是的话,则判断该新的聚类特征所代表的数据包属于监控信息系统应用,否则,判断该新的聚类特征所代表的数据包不属于监控信息系统应用,而无需进行其它计算,从而可以减少计算量。
本发明实施例提供的识别方法属于一种通用识别方法,适用于采用任意网络协议的监控信息系统。监控信息系统网络中常用的网络协议有HSRP/VRRP(Hot Standby Router Protocol/Virtual Router Redundancy Protocol,热备份路由协议/虚拟路由冗余协议),IEC104规约,SIS(Supervisory Information System,监控信息系统)协议,其中HSRP/VRRP、IEC104规约为公开的互联网协议,对采用这两种通信协议的监控信息系统应用进行识别时,可以采用协议和端口的方式。而SIS协议属于私有协议,对采用SIS协议的监控信息系统应用进行识别时,可以使用上述实施例提供的通用识别方法。
图4是根据一示例性实施例示出的一种识别监控信息系统应用的装置40的框图。参照图4,该装置40可以包括:获取单元41,用于获取所述网络中的数据包;提取单元42,用于提取所述数据包中的多个流量特征值;建立单元43,用于根据所述多个流量特征值建立特征值向量;聚类单元44,用于对所述向量进行聚类处理以形成多个向量簇;以及识别单元45,用于通过确定所述多个向量簇中数据密集度最高的向量簇来识别所述监控信息系统应用。能够有效识别出监控信息系统应用的关键流量,从而为流量保证业务提供基础识别服务并且能够防止一些病毒因占有大量宽带而影响监控信息系统运行。
其中,可选地,获取单元41可以利用网络探针来获取所述网络中的所述数据包。所述多个流量特征值至少可以包括:目的MAC地址、目的IP地址、传输协议以及目的端口。可选地,该多个流量特征值还可以包括源MAC地址、源IP地址、源端口以及数据包净荷长度。
可选地,聚类单元44可以用于根据所述特征值向量来生成聚类特征,具体地,可以根据以下公式来生成所述聚类特征:
其中,表示所述聚类特征,N表示所述特征值向量的元素个数,di表示所述向量中第i个元素的值。
然后聚类单元44可以根据所述聚类特征之间的距离来对所述聚类特征进行所述聚类处理以形成所述多个向量簇。
如上文所述,监控信息系统正常运行时,网络中60%至95%以上的流量都是监控信息系统的流量,对应于这些监控信息系统的流量的数据包在所提取的流量特征值上具有非常好的相似性,相似性很好的数据包可以被聚类在同一个向量簇中,这样,数据密集度最高的向量簇所代表的数据包就对应于监控信息系统的流量,从而可实现识别监控信息系统应用的目的。
关于上述实施例中的装置,其中各个模块执行操作的具体方式已经在有关该方法的实施例中进行了详细描述,此处将不做详细阐述说明。
本领域技术人员在考虑说明书及实践这里公开的发明后,将容易想到本发明的其它实施方案。本申请旨在涵盖本发明的任何变型、用途或者适应性变化,这些变型、用途或者适应性变化遵循本发明的一般性原理并包括本公开未公开的本技术领域中的公知常识或惯用技术手段。说明书和实施例仅被视为示例性的,本发明的真正范围和精神由所附的权利要求指出。
应当理解的是,本发明并不局限于上面已经描述并在附图中示出的精确结构,并且可以在不脱离其范围进行各种修改和改变。本发明的范围仅由所附的权利要求来限制。
- 还没有人留言评论。精彩留言会获得点赞!