基于隐马尔可夫模型的调频广播信号报时特征识别方法与流程
本发明涉及无线电监测领域,具体涉及基于隐马尔可夫模型的调频广播信号报时特征识别方法。
背景技术:
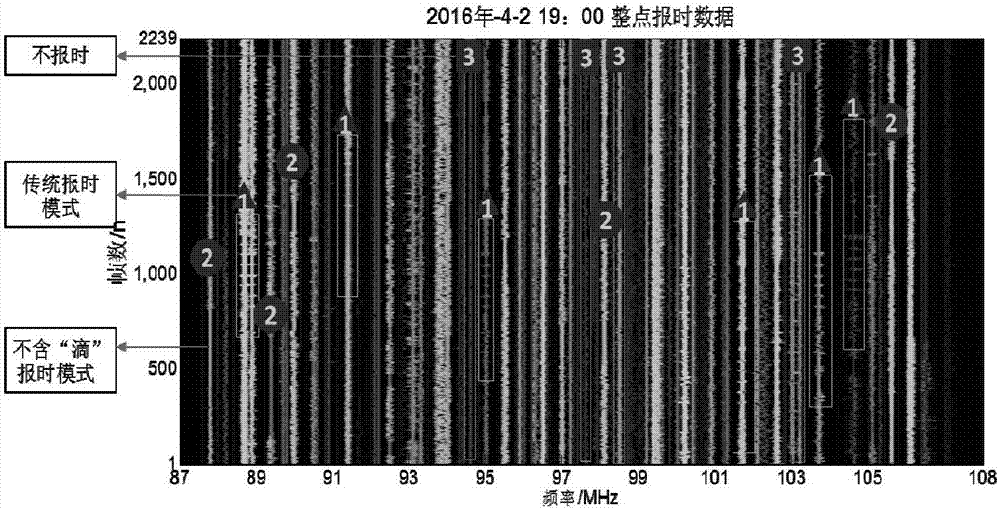
:无线电广播是许多地区和人群获得信息的便利途径。然而,一些不法商贩私设电台广播不科学、虚假、低俗的“黑广播”。“黑广播”会干扰正常无线电秩序,侵犯公众合法权益,诱骗科学意识不强的人群(如老年人),甚至可能干扰航空频段引发重大事故。由于“黑广播”是不法商贩的一种违法行为,因此“黑广播”的播放频率、播放时间和播放地点都极具隐蔽性和不确定性,这给实际确定“黑广播”的播放频率、播放时间和播放地点带来极大困难,依靠人工排查不仅费时费力,而且无法及时发现“黑广播”。目前对“黑广播”的查处主要依靠集中整治或投诉等被动方式。本发明实现了将报时特征作为合法广播的标志,减少了疑似“黑广播”的频点数量,提高了对“黑广播”自动监测的识别率。广播整点报时是指广播电台在整点通过鸣“嘀”并播报时间的一种报时方式。在文件GBT4961-1999《广播报时信号》和GYT219-2006《广播信号嵌入时间码规范》中对广播报时有着规范的要求。将全国广播电台的报时模式总结为传统报时法、提前报时法和其他报时法。本发明根据整点报时是否含“嘀”将报时模式分为传统报时模式和不含“嘀”的报时模式。由于“黑广播”多以录播形式播出,不存在整点报时,而多数合法广播在整点时刻进行报时。因此可通过识别整点报时,识别合法广播,减少“黑广播”的判断数量。通过频段扫描数据的光谱图可观察到各个调频广播的报时模式(见图1)。实际监测过程中可使用频段扫描数据同步分析所有信号。本发明用频段扫描数据识别报时特征。在实际监测过程中识别整点报时存在以下难点:1)由于报时模式的多样性,各频点报时开始和结束不同步,报时持续时间长度不同(见图1);2)由于设备原因,在采集过程中数据丢失不可避免,相同时间无法获得相同的频段扫描数据帧数;3)数据采集速度很快(15~40ms一帧数据),如果在数据采集过程中产生偏差会使两个序列产生较大差异;4)相邻的两个信号频点可能对彼此产生干扰。综上所述,包含整点报时的整点时刻频段扫描数据具有以下特点:序列长度不固定;序列之间有错位;序列包含噪声。由于欧式距离对噪声十分敏感,不具备对时间轴伸缩处理的能力,不能很好地处理模式相似性度量。因此,传统的模式匹配方法误差较大。隐马尔可夫模型(HiddenMarkovModel,HMM)是一种统计模型,拥有牢固的统计学基础和训练方法,适合时序建模,可有效处理上述问题中的随机性和不确定性。隐马尔可夫模型是一个双重随机过程,由隐藏的随机过程和观察的随机过程构成。隐藏的随机状态蕴含在观察的随机状态中,通过观察状态概率矩阵和转移概率矩阵,隐藏的随机过程规律可通过观察的随机过程规律发现。隐马尔可夫模型可形式描述为λ=(S,Ω,P,Φ,π),其中,S={si|i=1,…N}为隐藏状态集合,Ω={ok|k=1,…,M}为观察状态集合,P={pij}N×N为隐藏状态转移矩阵,pij表示系统由状态si转移到状态sj(i=1,…,N,j=1,…,N),Φ={φi(ok)}N×M为观察概率矩阵,φi(ok)表示系统处于状态si时产生观察状态ok的概率(i=1,…,N,k=1,…,M),π={πi|i=1,…N}为初始状态概率分布,πi表示初始时si的概率。隐马尔可夫模型已广泛应用于图像处理、人体识别、手写字体识别、文本分类、语音识别、动作识别、经济学、分子生物学等众多研究领域。本发明申请将隐马尔可夫模型用于调频广播信号报时特征识别。本发明人的在先申请“一种调频广播信号的监测方法(2016103698315)”用于本发明的静音数据预处理过程,下面统一以“在先申请”为代词作相关陈述。技术实现要素:针对上述现有技术,本发明目的在于提供基于隐马尔可夫模型的调频广播信号报时特征识别方法,解决根据频谱特征如何识别广播整点报时的新技术问题。为达到上述目的,本发明采用的技术方案如下:基于机器学习模型的调频广播信号特征识别方法,包括以下步骤:步骤1、使用信号模板将频谱数据转换为机器码序列;步骤2、定义机器码序列中每个信号的滑动边界、相对滑动边界的重叠边界,在滑动边界和重叠边界内找出信号模板的属性,构建出关于属性的特征向量;步骤3、量化已知类的信号特征为隐藏层,将特征向量作为机器学习模型的输入层,训练出输出层;步骤4、获取实时频谱数据,调用步骤1和步骤2,获得实时特征向量,根据实时特征向量与输出层的匹配特性判断出是否归属已知类的信号特征。基于隐马尔可夫模型的调频广播信号报时特征识别方法,包括以下步骤:步骤1、在广播频段内获取整点时刻邻域内各个调频广播信号预设带宽的数据帧集合,通过静音模板匹配方法,对每个数据帧作静音标记,将该数据帧集合标记为静音数据和剩余数据(非静音数据)的0-1序列,在0-1序列上计算每个滑动区间内的属性,对每个属性进行离散化处理并对离散化处理的结果进行编号,获得编号集,再对编号集进行特征组合(串行融合策略)后,获得第一特征向量;步骤2、将整点时刻邻域内一个完整的整点报时分为若干过程,将若干过程作为隐马尔可夫模型的隐藏状态集合,将步骤1中的编号集作为隐马尔可夫模型的观察状态集合并将第一特征向量作为隐马尔可夫模型观察序列,然后获得初始化或更新的状态转移矩阵、观察概率矩阵和初始概率分布;步骤3、将预先采集的整点报时和不报时两类数据分别作为两个训练集,每个训练集分别作为步骤1的数据帧集合,然后利用隐马尔可夫模型参数学习算法在步骤1和步骤2内构建关于每个训练集的循环迭代训练,在循环迭代训练结束后,,对应两个训练集分别获得报时隐马尔可夫模型和不报时隐马尔可夫模型;步骤4、将实时数据(检测集)作为步骤1的数据帧集合,利用步骤1滑动区间对0-1序列进行统计和离散化处理并进行编号,经过特征组合(串行融合策略)后获得第二特征向量(与第一特征向量中的属性特征相同);步骤5、将第二特征向量分别代入报时隐马尔可夫模型和不报时隐马尔可夫模型,对应获得报时匹配概率和不报时匹配概率,当最大匹配概率等于报时匹配概率时,当前整点时刻信号识别结果为报时。上述方案中,所述的步骤1,在广播频段内获取整点时刻前后数秒到数十秒内各个调频广播信号上预设带宽的数据帧集合。上述方案中,所述步骤1,利用滑动区间对0-1序列进行统计、离散化处理、编号和特征组合(串行融合策略),具体包括以下步骤:步骤①、对调频广播的0-1序列,设置滑动区间和重叠区间的长度;步骤②、对步骤①中的0-1序列从开始至结束,依次统计每一滑动区间内静音持续出现次数以及静音持续长度的平均值、方差和总量;步骤③、将每个滑动区间静音持续出现次数以及静音持续长度的平均值、方差和总量进行离散化处理并对离散化处理的结果进行编号,获得编号集,再对编号集进行特征组合(串行融合策略)后,获得第一特征向量。上述方案中,所述的步骤2,其中:将整点报时分为5个过程:报时前播出的节目(节目1),报时前期(多为停顿),整点报时,报时后期(多为停顿)和报时后播出的节目(节目2),作为5个隐藏状态,构建出隐藏状态集合。上述方案中,所述的步骤2,其中:将第一特征向量作为隐马尔可夫模型中训练集的观察序列;令初始观察概率矩阵的初始值为训练集中每个隐藏状态产生各个观测符号的概率;令初始状态转移矩阵为隐藏状态的平均长度为训练集各序列的平均长度,N为隐藏状态的个数5;令初始概率分布为π={1,0,0,0,0}T。上述方案中,所述的步骤①中的滑动区间和重叠区间长度按以下规则设置:相对每个整点时刻,每个滑动区间和每个重叠区间的长度至少包含5个隐藏状态,并且每个重叠区间的长度大于每个滑动区间长度的一半。与现有技术相比,本发明的有益效果:通过静音模板匹配方法对输入数据的进行预处理,训练出隐马尔可夫模型,对实时广播进行监测,识别出广播频谱数据中通常情况极其容易忽视的、短暂的整点报时特征,并用来作为区分“黑广播”的指标之一,对本领域技术影响和启示是深远的;本发明通过滑动区间、重叠区间方式找出了信号的属性,关联了前后信号数据,让信号间体现出预测特性,通过信号属性的特征向量实现了机器学习模型的输入层,而现有技术正是存在输入层难以构建的技术壁垒;相对于在先申请需要实时全天候的数据采集,本发明能够仅仅采集多个整点时段的数据用以训练模型,然后仅需要对整点时刻进行监测即能完成报时特征识别并作出指标判断,显著并实质地,降低了数据处理量,加快了“黑广播”发现速度;本发明不受地区和时间的限制,节省人力,有助于提高查找黑广播效率;由于整点报时是区分合法广播与“黑广播”的重要指标之一,因此本发明可用减少“黑广播”的频点的查找数量,增加对“黑广播”自动识别的准确率。附图说明图1是本发明一个实施例训练集中用以发现整点报时调频广播频谱信号的光谱图(时间2016/5/416:00);图2是本发明一个实施例实测数据用以发现整点报时调频广播频谱信号的光谱图(时间2016/4/219:00);图3是本发明一个实施例中FM103.7MHz传统报时模式的整点数据示意图;图4是本发明一个实施例中FM94MHz不含“嘀”的报时模式的整点数据示意图;图5是本发明一个实施例中FM92MHz不报时的整点数据示意图;图6是本发明一个实施例整点时刻信号的一维HMM模型结构示意图;图7是本发明一个实施例中获得观察序列的滑动区间和重叠区间示意图(FM103.7MHz传统报时模式);图8是本发明基于隐马尔可夫模型识别调频广播整点报时信号流程图。具体实施方式本说明书中公开的所有特征,或公开的所有方法或过程中的步骤,除了互相排斥的特征和/或步骤以外,均可以以任何方式组合。利用在先申请方法对原始数据进行预处理,将该频段上每一信号的频谱数据处理为由静音和非静音组成的序列,将静音和非静音分别由1和0表示的0-1序列,该序列称为整点数据。通过采集并积累一定数量的整点数据作为训练集,人工标注训练集的调频广播信号类型,即整点报时或不报时。第二步获得整点数据的特征向量。通过设定滑动区间和重叠区间,从整点数据的起点滑动到终点,依次计算每一滑动区间内静音持续出现的次数,静音持续长度的平均值,静音持续长度的方差和静音总量。通过对连续的特征值进行离散化处理,对离散区间进行编号,特征组合获得整点数据的特征向量。将该特征向量作为隐马尔可夫模型的观察序列。第三步学习整点报时和不报时调频广播信号的隐马尔可夫模型参数。利用隐马尔可夫模型的参数学习算法训练上述两类训练集获得相应的隐马尔可夫模型的参数,建立整点报时和不报时调频广播信号的隐马尔可夫模型;第四步识别调频广播整点报时信号。采集调频广播的频段扫描数据,通过预处理获得整点数据并提取特征向量,分别代入整点报时和不报时调频广播信号的隐马尔可夫模型中,获得与两种模型的匹配概率,根据最大匹配概率原则,判断调频广播是否进行整点报时。由于整点报时是区分合法广播与“黑广播”的重要指标之一,因此本发明可用于减少“黑广播”频点的查找数量,增加对“黑广播”识别的准确率。为了实现上述发明目的,本发明采用的技术方案是:基于隐马尔可夫模型识别调频广播整点报时信号的方法包括以下步骤:1)在调频广播频谱信号的光谱图中(图1),截取若干频率整点时刻前后20秒的频段扫描数据并标注其信号类型(整点报时,不报时),如图1为2016年5月4日16:00前后20秒在西华大学采集的87MHz-108MHz的频段扫描数据的光谱图,约2282帧频段扫描数据,其中,有1、2和3数字标号的矩形框中注了在16:00具有不同的报时模式的调频广播,具体表现为,1号矩形框为传统的报时模式,2号矩形框为不含“嘀”的报时模式;3号矩形框的调频广播在16:00不报时。利用在先申请方法,可以分析每一个调频广播频谱信号的“静音状态”或“非静音状态”特点,如对图1中103.7MHz调频广播频谱信号用在先申请方法处理,其对应的“静音状态”或“非静音状态”如图3,其中,黑色部分为“静音状态”,白色部分表示为“非静音状态”。类似地,调频广播94MHz和92MHz的“静音状态”或“非静音状态”特点分别如图4和图5。直观地,若将“静音状态”记为1,“非静音状态”记为0,则利用在先申请方法,每一个调频广播整点时刻前后20秒的频段扫描数据均可处理为一个0和1的序列码,即调频广播的整点数据。如图3调频广播103.7MHz的整点数据为一个长度为2282的0和1序列码,可以直观地观察传统报时模式有节奏的静音分布规律。类似的,从调频广播94MHz的0和1序列码中,可以直观地观察不含“嘀”的报时模式,由于传统的整点报时被其他创新形式的报时内容替换,静音含量较少;从调频广播92MHz的0和1序列码,可以直观地观察不报时的静音分布。根据调频广播信号是否报时,可以将信号分为整点报时调频广播信号和不报时调频广播信号两类。积累上述两种类型的整点数据集构成训练集。通过设定的滑动区间和重叠区间,提取训练集的特征向量作为隐马尔可夫模型的观察序列;2)一个完整的整点报时过程可以分解成5部分,报时前播出的节目(节目1),报时前期(多为停顿),整点报时,报时后期(多为停顿)和报时后播出的节目(节目2),见图3和图4。由于整点报时具有时序性,本文采用左右型隐马尔可夫模型,信号在整点时刻的一维HMM模型结构如图6所示。结合隐马尔可夫模型,在调频广播的整点数据中,计算训练集中各隐藏状态中静音持续的次数,静音持续长度的平均值,静音持续长度的方差和静音总量。采用等频离散化的方法将各个特征离散为5个数值,依次标记为1~5,6~10,11~15,16~20,记观察状态集合Ω={1,2,…,20};s1=报时前节目、s2=报时前期和s3=整点报时,s4=报时后期、s5=报时后节目为λ=(S,Ω,P,Φ,π)的隐藏状态,即S={s1,s2,s3,s4,s5}。通过这5个隐藏状态产生的观察序列可识别整点报时的调频广播信号。因此,调频广播信号的隐马尔可夫模型表示为:λ=({s1,s2,s3,s4,s5},{1,0,…,20},P,Φ,π)其中,隐藏状态转移矩阵P={pij}5×5,观察概率矩阵Φ={φi(ok)}5×20初始状态概率分布π需要根据训练集训练学习获得。利用隐马尔可夫模型的参数学习算法,本发明采用Baum-Welch算法训练学习P={pij}5×5,Φ={φi(ok)}5×20和π={πi}5×1的过程如下:1.确定λ=(P,Φ,π)的初始值1)初始的隐藏状态转移矩阵P记序列的平均长度为则各状态的平均长度本文中N=5,可认为各个状态均匀分布在长度为的区间上,在某一时间点由当前状态转移到下一状态的概率为转移到自身的概率为初始的隐藏状态转移矩阵P如下:由于P中为0的参数在迭代过程中一直为0,为提高模型的泛化能力,将其中的0用2.2204e-18替换;2)观察概率矩阵Φ计算训练集中各隐藏状态的静音的区间数,静音持续的平均长度,静音持续的方差和静音总量,采用等频离散化的方法将各个特征离散为5个数值,进行编号后统计各隐藏状态产生每个观察值的概率,作为观察概率矩阵的初始值;3)初始状态概率分布π本文采用左右型的HMM模型,初始状态概率分布π设为π={1,0,0,0,0}T。2.基于Baum-Welch算法进行迭代训练确定初始的模型参数后,采用Baum-Welch算法进行迭代训练;迭代时,两次对数似然概率值的差小于1×10-4时终止迭代,输出模型参数,分别获得整点报时和不报时这两类信号的模型参数;获得模型参数后,采集整点时刻前后20s的频段扫描数据,经过预处理获得各调频广播信号的整点数据即0-1序列码;对于每一个0-1序列码,计算每个滑动区间内的4个特征值并进行离散化处理后进行编号,获得调频广播信号的观察序列;将观察序列分别代入整点报时和不报时调频广播信号的隐马尔可夫模型中,获得与两种模型的匹配概率,根据最大匹配概率原则,判断调频广播是否进行整点报时。本发明基于隐马尔可夫模型识别调频广播整点报时信号的方法具体伪代码如下:获得训练集伪代码如下:输入:N个整点时刻ti的频段扫描数据相应的信号列表输出:训练集TS1,TS2,Whilei≤Ndo利用在先申请方法,从中调频广播信号的频谱数据处理为由静音和非静音组成的序列,用1表示静音,0表示非静音,得到0-1序列码,即该频点的整点数据那么If调频广播信号整点报时将整点数据放入训练集TS1中else将整点数据放入训练集TS2中endifendwhileendwhile输出训练集TS1,TS2;2、获得观察状态集合,伪代码如下:输入:训练集TS1;输出:观察状态集合Ω={o1,o2,…,o20};1)计算每个样本隐藏状态的特征值whilei≤|TS1|do按照播出前节目(节目1),报时前期(多为停顿),整点报时,报时后期(多为停顿)和报时后播出的节目(节目2)过程,分解为5个子序列,si1,si2,si3,si4,si5;whilej≤5do计算sij中静音持续的次数,赋值给计算sij中静音持续长度的平均值,赋值给计算sij中静音持续长度的方差,赋值给计算sij中静音总量,赋值给endwhileendwhile;2)对每组连续的特征值vw进行离散化处理,w=1,2,3,4,各得到5个区间,记录区间的端点whilew≤4do对离散化为5个区间,whilei≤|TS1|dowhilej≤5doom+5(w-1)=m+5(w-1)endifendwhileendwhileendwhile;输出观察状态集合Ω={o1,o2,…,o20},获得调频广播信号的观察序列,伪代码如下:输入:整点时刻ti前后20s的频段扫描数据和信号列表输出:每个调频广播信号的观察序列;1)利用在先申请方法,从中得到频点整点数据2)设置滑动区间IL和重叠区间RL,计算每一滑动区间IL中的特征值,离散化后得到ti时刻频点的观察序列endwhile输出每个调频广播的观察序列训练学习整点报时和不报时调频广播信号的隐马尔可夫模型,伪代码如下:输入:训练集TS1和TS2,隐马尔可夫模型的初始值λ0=(S,Ω,P0,Φ0,π0);输出:整点报时和不报时调频广播信号的隐马尔可夫模型;whilec≤2do1)从训练集TSc中得到观察序列2)给定隐藏状态转移矩阵P,观察概率矩阵Φ,初始概率分布矩阵π初始值P0,Φ0,π0;3)对训练集TSc的观察序列采用隐马尔可夫参数训练算法对参数P0,Φ0,π0进行迭代训练;endwhile输出λ1=(S,Ω,P1,Φ1,π1),λ2=(S,Ω,P2,Φ2,π2)。5、识别整点报时的调频广播信号,伪代码如下:输入:隐马尔可夫模型λ1和λ2,整点时刻ti前后20s的频段扫描数据信号列表输出:每个调频广播是否整点报时的识别结果1)获得每个调频广播的观察序列2)观察序列与两种模型的匹配概率,识别整点报时调频广播信号whilek≤|F|do计算调频广播的观察序列与模型λ1和λ2的匹配概率该频点在整点时刻ti整点报时,thenelse该频点在整点时刻ti不报时endifendwhile输出对每个调频广播是否整点报时的识别结果下面结合附图对本发明做进一步说明:图1和图2所示是本发明的一个实施例示出的整点时刻调频广播前后20秒的频段扫描数据,从中可以观察出传统的报时模式、不含“嘀”的报时模式和不报时的调频广播信号。图3、图4和图5所示是本发明的一个实施例使用在先申请方法将调频广播信号的频谱数据处理为由静音和非静音组成的整点数据。用1表示静音,用0表示非静音,该整点数据是一个1和0构成的序列码。图6所示是本发明的一个实施例示出的整点时刻调频广播信号的一维HMM模型结构。由于一个完整的调频广播报时过程可以分解为报时前播出的节目(节目1),报时前期(多为停顿),整点报时,报时后期(多为停顿)和报时后播出的节目(节目2),见图3和图4。由于整点报时具有时序性,本发明采用左右型隐马尔可夫模型。图7所示是本发明的一个实施例示出的通过设定滑动区间和重叠区间,从整点数据的起点滑动到终点,依次计算每一滑动区间内静音持续出现的次数,静音持续长度的平均值,静音持续长度的方差和静音总量。通过对连续的特征值进行离散化处理,进行编号和特征组合后获得整点数据的特征向量。将该特征向量作为隐马尔可夫模型的观察序列。图8所示是本发明的一个实施例示出的基于隐马尔可夫模型识别调频广播整点报时信号的整体流程图。包括以下步骤:第一步获得训练集。使用接收设备获得整点时刻前后20秒的频段扫描数据,利用在先申请方法对原始数据进行预处理,将该频段上每一信号的频谱数据处理为由静音和非静音组成的序列,将静音和非静音分别由1和0表示的0-1序列,该序列称为整点数据。通过采集并积累一定数量的整点数据作为训练集,人工标注训练集的调频广播信号类型,即整点报时或不报时。第二步获得整点数据的特征向量。通过设定滑动区间和重叠区间,从整点数据的起点滑动到终点,依次计算每一滑动区间内静音持续出现的次数,静音持续长度的平均值,静音持续长度的方差和静音总量。通过对连续的特征值进行离散化处理,进行编号和特征组合后获得整点数据的特征向量。将该特征向量作为隐马尔可夫模型的观察序列。第三步学习整点报时和不报时调频广播信号的隐马尔可夫模型参数。利用隐马尔可夫模型的参数学习算法训练上述两类训练集获得相应的隐马尔可夫模型的参数,建立整点报时和不报时调频广播信号的隐马尔可夫模型;第四步识别调频广播整点报时信号。采集调频广播的频段扫描数据,通过预处理获得整点数据并提取特征向量,分别代入整点报时和不报时调频广播信号的隐马尔可夫模型中,获得与两种模型的匹配概率,根据最大匹配概率原则,判断调频广播是否整点报时。实施例,实验设备:HE600天线,R&S公司生产的EM100接收机,电脑,馈线(连接天线与接收机),网线(连接接收机与电脑)。硬件参数设置:起始频率87MHz,终止频率108MHz,步长25kHz,每帧数据包含841个采样点。2016年4月2日室外采集11:00、14:00、15:00、16:00、18:00、19:00、20:00整点时刻前后20秒的频段扫描数据,利用在先申请方法,将调频广播信号的频谱数据处理为由静音和非静音组成的序列,用1表示静音,0表示非静音,得到1和0的序列码,即整点数据。从中挑选整点报时调频广播信号123组,“不报时”序列116组。观察状态个数为20,隐藏状态个数为5,最大迭代次数为1000,迭代误差为1×10-4,利用隐马尔可夫模型的参数学习算法,本发明申请采用Baum-Welch算法训练学习隐藏状态转移矩阵,观察概率矩阵和初始状态概率分布的过程如下:一、确定λ=(P,Φ,π)的初始值1)初始的隐藏状态转移矩阵P记序列的平均长度为则各状态的平均长度本发明中N=5,可认为各个状态均匀分布在长度为的区间上,在某一时间点由当前状态转移到下一状态的概率为转移到自身的概率为初始的隐藏状态转移矩阵P如下:由于P中为0的参数在迭代过程中一直为0,为增加模型的稳定性,将0用2.2204e-18替换;2)观察概率矩阵Φ计算训练集中各隐藏状态的静音的区间数,静音持续的平均长度,静音持续的方差和静音总量。采用等频离散化的方法将各个特征离散为5个离散区间,依次标为1,2,…,20。统计各隐藏状态产生每个观察值的概率,作为观察概率矩阵的初始值;3)初始状态概率分布π本发明采用左右型的HMM模型,初始状态概率分布π设为π={1,0,0,0,0}T。将0用2.2204e-18替换;二、训练后得到隐马尔可夫模型λ1=(S,Ω,P1,Φ1,π1),λ2=(S,Ω,P2,Φ2,π2)。使用训练后得到隐马尔可夫模型识别实测数据中的整点报时调频广播,步骤如下:1.使用相同的设备和参数,于2016年4月2日采集19:00前后20秒的频段扫描数据,相应的光谱图见图1;2.利用在先申请方法,将调频广播信号的频谱数据处理为由静音和非静音组成的序列,用1表示静音,0表示非静音,得到1和0的序列码,即整点数据。3.设置滑动区间长度为800,重叠区间为700,对每一信号的整点序列从起点滑动到终点,以此计算每个滑动区间内的4个特征值并进行离散化处理进行编号,特征组合后得到观察序列;4.计算每个调频广播信号与隐马尔可夫模型λ1和λ2的匹配概率5.根据最大概率匹配原则识别整点报时调频广播信号。表1给出了对该整点时刻调频广播整点报时信号的识别结果。该整点时刻共有68个信号,其中有31个调频广播信号进行整点报时,37个调频广播信号不报时。采用本发明方法,识别出28个整点报时信号,识别率为90.32%;将3个不报时信号误判为整点报时信号;识别出35个不报时信号,识别率为94.59%;将2个调频广播信号误判为整点报时信号。综合识别率为92.65%。表1类型整点报时信号不报时信号识别率整点报时信号28390.32%不报时信号23594.59%以上所述,仅为本发明的具体实施方式,但本发明的保护范围并不局限于此,任何属于本
技术领域:
的技术人员在本发明揭露的技术范围内,可轻易想到的变化或替换,都应涵盖在本发明的保护范围之内。当前第1页1 2 3
相关技术
网友询问留言
已有0条留言
- 还没有人留言评论。精彩留言会获得点赞!
1