一种适用于入侵检测的分类方法与流程
本发明属于网络安全技术领域,涉及入侵检测数据均衡化预处理的混合采样技术及支持向量机集成学习方法,公开了一种适用于入侵检测的分类方法。
背景技术:
在网络安全领域,入侵检测作为一种主动防御技术,通过收集并分析系统、用户及网络数据包的信息,监测用户和系统的活动。为了使检测系统能够从收集到的信息中自动检测到异常,机器学习技术被引入到入侵检测系统。
支持向量机作为机器学习领域的一个重要研究分支,因为自身完善的数学理论和良好的实际应用效果,因此在入侵检测领域获得了应用。但是在传统的入侵检测标准训练集中,训练样本分布是极端不均衡的,单个支持向量机对类别不平衡的样本集较为敏感。因此将支持向量机应用到入侵检测中,训练出来的检测模型存在对入侵数据的检测率较低及对正常数据的误判率较高等难以让人满意的缺点。
本发明针对svm应用在入侵检测中的上述缺陷,提出了在训练样本集上首先采用基于核空间混合采样技术的样本均衡化预处理方法,在分类算法上采用支持向量机集成的学习方法,该方案可以改善支持向量机检测模型对入侵数据的检测率较低及误判率较高的缺点,并且适合大规模并行计算。
技术实现要素:
本发明的目的是针对现有的svm方案用于入侵检测的不足,提供了一种适用于入侵检测的分类方法,提高svm在入侵检测中应对入侵数据的检测率及降低对正常数据的误判率,并且使算法适合大规模并行计算。
本发明为解决上述技术问题所采用的技术方案如下:
1)数据集规范化预处理:针对入侵检测标准数据集进行样本特征参数归一化处理,实现所有文本属性信息数值化转换,并使所有的特征属性得到规格化处理,统一属性的度量。
2)对训练数据集在核空间混合采样改善类别均衡度:针对svm在核空间进行训练的特点,将训练样本集映射到特征空间,对少数类样本集采取k-smote算法进行过采样得到新的少数类样本集,同时对多数类样本集采用基于核聚类的欠采样方法得到新的多数类样本集,然后将得到的少数类样本集与多数类样本集合并产生新的训练用均衡样本集。
3)分类器训练:在分类器训练阶段,基于上述步骤2)产生的新样本集中采用bagging方法构建多个训练集,并分别对每个训练集用svm基分类器进行学习,得到集成分类器。
4)分类器识别:在识别阶段,通过由步骤3)产生的基分类器来加权投票决定分类结果。
本发明根据svm算法在核空间进行分类的特点,通过对少数类采用核smote的过采样与对多数类采用基于核聚类的欠抽样的混合采样方式对不均衡训练数据集进行均衡化预处理,然后在得到的新训练集上采用bagging集成学习方法得到基于svm的集成分类器。该方法不仅可以有效改善svm针对入侵检测中的入侵数据识别效果不理想及对正常数据的误判率较高的缺点,并且采用的bagging集成算法适合大规模并行计算。
附图说明
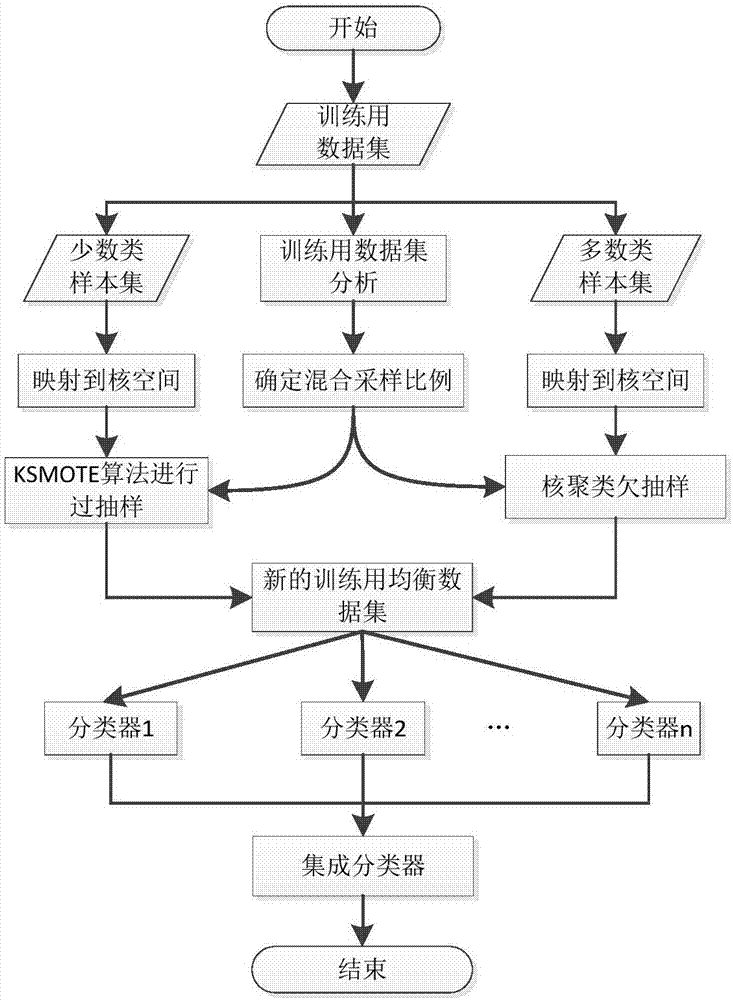
图1是工作流程示意图;
图2是算法流程图。
具体实施方式
下面结合附图详细说明下本发明的实现过程,如图1所示,本发明方法的工作流程主要分为4个部分:
1)数据预处理:针对入侵检测标准数据集kddcup99进行样本特征参数归一化处理,实现所有文本属性信息数值化转换,并使所有的特征属性得到规格化处理,统一属性的度量。
2)对不均衡训练数据集在核空间混合采样改善类别均衡度,如下为混合采样新样本集的生成过程,如图2描述所示,分为两个部分:
步骤2.1:对少数类样本在核空间进行smote过采样。
设待处理的少数类样本集为:f={x1,x2,...xn},xi∈rh,i=1,2,···,n,核函数k(·)和非线性映射
步骤2.1.1:首先根据训练样本集中的多数类样本与少数类样本的样本差值,确定需要生成的人工样本的数目d。
步骤2.1.2:在特征向量空间中生成人工少数类样本:
步骤2.1.3:按照排列的序号顺序从中选取一个少数类样本xi∈rh,i=1,2,···,n,求出该样本在特征向量空间中的k个少数类最近邻,最近邻求法如下:
对少数类样本按照di的值从小到大进行排列,选择排列前k个少数类样本,这k个样本就是xi的k个最近邻
步骤2.1.4:随机在这k个少数类最近邻中选择一个样本xj,并且生成一个数值范围在(0,1)内的随机数λi。
步骤2.1.5:在特征向量空间中利用距离法生成新的样本fi:
步骤2.1.6:如果生成的人工少数样本数目不足,则重复步骤
2.1.3到步骤2.1.5的过程,直到人工少数类样本的数目满足要求,至此少数类样本在核空间的过抽样算法结束。
步骤2.2:对多数类样本在核空间进行基于模糊c均值聚类的欠采样。
设待处理的多数类样本集为:m={y1,y2,...ym},yi∈rm×l,m为多数类样本数目,l为样本维数。
步骤2.2.1:采用与步骤2.1中相同的核函数,计算多数类样本同少数类样本的相似矩阵wm×p,其中m为多数类样本数目,p为少数类样本数目。
步骤2.2.2:计算每一个多数类样本与所有少数类的平均相似度向量lm×1。
步骤2.2.3:根据平均相似度向量lm×1的从大到小排序得到m′。
步骤2.2.4:取m′中的前α×m个多数类样本g∈rα×m×l作为待聚类样本进行聚类分析,其中α为边界样本的选取比例。
步骤2.2.5:通过对g={g1,g2,...gα×m}矩阵中的gi利用核模糊c均值聚类算法进行聚类形成c1,c2,…,cq,其中q为聚类的个数。然后对每一个聚类,根据所确定的样本数,结合各个聚类的大小按照其占q个聚类总和大小的权值,从各个聚类中随机选取相应数量的样本,得到多数类欠抽样样本集。
将上述步骤2.1与步骤2.2生成的样本集合并生成新的训练用均衡样本集s。
3)采用bagging算法进行集成分类器训练,步骤如下:
输入:训练样本集s,含有s={(x1,y1),(x2,y2),...(xn,yn)},采样次数为k;
步骤3.1:通过bootstrap重采样,从s中得到训练样本集sk;
步骤3.2:在数据集sk上利用svm算法进行训练,获得基分类器hk;
重复以上步骤k次,建立k个分类器;
4)分类器识别:在识别阶段,通过由步骤(3)产生的k个基分类器对测试集进行分类,最终预测结果采取等权值投票得出;
输出:
该算法不仅可以改善传统svm模型在入侵检测应用中对入侵数据检测率不高及对正常数据误判率较高的缺点,而且采用的bagging集成算法适合大规模并行计算。
以上所述仅为本发明的具体实施方式,并不用以限制本发明,任何本发明所属领域内的技术人员,在本发明揭露的技术范围内,所作的修改或替换,都应涵盖在本发明的保护范围之内。
- 还没有人留言评论。精彩留言会获得点赞!