一种云服务器负载预测方法与流程
本发明涉及一种云服务器负载预测方法,属于云计算应用技术领域。
背景技术:
云计算是一种利用互联网实现随时随地、按需、便捷地访问共享资源池(如计算设施、存储设备、应用程序等)的计算模式,其充分利用虚拟化机制,让客户按需获取需要的资源,由此可以降低中小型企业硬件维护成本等。当前我国各类数据中心总量约43万个,可容纳服务器约500万台,未来5年我国对数据中心流量处理能力的需求将增长7~10倍。然而,云数据中心规模的不断扩大,成千上万的计算节点也带来了高能耗的问题,以一台服务器平均功耗400瓦计算,年耗电总量约为1276亿千瓦时,已然超过三峡电站一年的发电总量(2014年为988亿千瓦时)。导致这种高能耗现象产生的原因不仅仅是因为硬件资源所需能耗高,更多的是因为这些资源的低效率使用。云计算数据中心服务器利用率很少接近10%,而当服务器利用率低于50%时,就会因为过渡供应产生额外的成本。因此,保证服务器高效运作是很有必要的。现有研究提出,云服务器负载的精准预测对于提高云计算系统的资源利用率、降低能耗、提升服务质量、对虚拟机迁移机制具有重要意义。
通过对于服务器的负载预测,云计算系统可以更好的对虚拟机进行有序部署和迁移管理,避免瞬时负载峰值或谷值触发无谓的虚拟机迁移造成的系统开销浪费,减少虚拟机迁移带来的网络通信的压力,在保障服务质量和sla的前提下,提高资源利用率,延长硬件设备寿命,有效降低云计算数据中心的能耗。云数据中心服务器的负载情况,尤其是cpu负载情况,具有以下几种特征:
(1)非线性。监测所得负载数据无法用一次函数进行拟合,数据具有不确定的属性。
(2)强波动性。波动性指的是数据序列在一段短时间内大幅上升或下跌的统计性指标,在负载预测环节中,即指的是一组监测数据在一段短时间内会出现大幅上升或下跌的情况。
由于负载数据的非线性、强波动性的特征,给负载预测方法确保精度高的同时减少方法开销带来了困难。目前已经有不少负载预测解决方案,包括基于非启发式方法和启发式方法的负载预测方法。然而,这些负载预测方法的不足之处有:
(1)非启发式方法预测精度低,对于波动性数据很难预测准确;
(2)启发式方法处理开销大,方法中的多次迭代造成了极大的计算开销,无法适用于要求实时性较强的负载预测;
(3)方法的预测时间粒度、目标粒度均太大,有些负载预测方法以天为时间单位预测整体云环境负载,目的仅仅是预测当日可能的数据中心任务量,以确认当日开启的服务器数量,对于云数据中心实时管理贡献很小,节省能耗有限。
技术实现要素:
本发明所要解决的技术问题是提供一种云服务器负载预测方法,针对负载数据的特点,融合云模型与马尔可夫链优点,实现云模型与马尔可夫链的有机结合,实现针对云服务器负载的预测。
本发明为了解决上述技术问题采用以下技术方案:本发明设计了一种云服务器负载预测方法,用于针对云服务中心进行负载预测,包括如下步骤:
步骤a.获得云服务中心所对应的云模型h,并针对云模型h中的各个子云函数,将彼此重叠大于预设重叠阈值的各个子云函数进行合并,更新云模型h,并进入步骤b;
步骤b.获得云模型h所对应的马尔可夫转移矩阵p'(n),并进入步骤c;
步骤c.针对云服务中心当前时刻t的负载数据at,以及云服务中心上一时刻(t-1)的负载数据at-1,进行归一化处理,获得at所对应的归一化数据xt,然后计算获得xt分别相对云模型h中各个子云函数hn的隶属度μ(xt)n,并进入步骤d,其中,n={1、…、n},n表示云模型h中子云函数的数量;
步骤d.针对xt相对云模型h中各个子云函数hn隶属度μ(xt)n,判断是否所有隶属度μ(xt)n均低于隶属度阈值μlimit,是则保留最大隶属度值,其余隶属度值设为0,更新xt相对云模型集合h中各个子云函数hn隶属度为μ'(xt)n,并进入步骤f;否则进入步骤e;
步骤e.针对xt相对云模型h中各个子云函数hn隶属度μ(xt)n,判断是否存在低于隶属度阈值μlimit的隶属度,是则将该隶属度值设为0,更新xt相对云模型集合h中各个子云函数hn隶属度为μ'(xt)n,并进入步骤f;否则直接将xt相对云模型h中各个子云函数hn隶属度μ(xt)n设为μ'(xt)n,并进入步骤f;
步骤f.针对xt相对云模型h中各个子云函数hn的隶属度μ'(xt)n,构成初始矩阵p(0),并根据p(n)=p(0)p'(n),获得一步转移隶属矩阵p(n),然后进入步骤g;
步骤g.分别针对云模型h中的各个子云函数hn,生成以enn为期望、以hen为熵的正态随机数yn,作为子云函数hn所对应的权值,进而获得云模型h中各个子云函数hn分别所对应的权值yn,然后进入步骤h;其中,enn表示云模型h中第n个子云函数hn所对应的数学期望,hen表示云模型h中第n个子云函数hn所对应的超熵;
步骤h.针对一步转移隶属矩阵p(n)中xt相对云模型h中各个子云函数hn的隶属度μ”(xt)n,以及云模型h中各个子云函数hn分别所对应的权值yn,进行加权平均处理,所获结果即为云服务中心下一时刻的负载预测值。
作为本发明的一种优选技术方案,所述步骤c中,采用如下公式:
计算获得xt分别相对云模型h中各个子云函数hn的隶属度μ(xt)n,并进入步骤d,其中,n={1、…、n},n表示云模型集合h中子云函数的数量;exn表示云模型集合h中第n个子云函数hn所对应的熵。
作为本发明的一种优选技术方案:所述步骤d中,对于隶属度阈值μlimit的获取方式为,针对各个隶属度μ(xt)n所逆推的期望值,判断期望值是否落在[-∞,exn-3enn]∪[exn+3enn,+∞],是则将该期望值所对应的隶属度值设为0;否则不做操作;其中,exn表示云模型h中与期望值相对应的子云函数所对应的熵,enn表示云模型h中与期望值相对应的子云函数所对应的数学期望。
作为本发明的一种优选技术方案:所述步骤g中,分别针对云模型h中的各个子云函数hn,根据如下模型:
生成以enn为期望、以hen为熵的正态随机数yn,作为预测数值序列{y1,…,yn},分别作为各子云函数hn所对应的权值。
作为本发明的一种优选技术方案,所述步骤b,按如下设计,获得云模型集合h所对应的马尔可夫转移矩阵p'(n);
将已构建的两个云模型
将其每行衔接成为一个一维向量t:
(ja(1)jb(1),ja(1)jb(2),…,ja(1)jb(lb),ja(2)jb(1),…,ja(la)jb(lb))
如此,通过该状态集合求解马尔可夫状态转移矩阵,进而云模型集合h所对应的马尔可夫转移矩阵p'(n)。
本发明所述一种云服务器负载预测方法采用以上技术方案与现有技术相比,具有以下技术效果:
(1)本发明设计的云服务器负载预测方法,针对负载数据的特点,融合云模型与马尔可夫链优点,提出一种云服务器负载预测方法,该方法沿用云模型的历史数据样本训练方法,在预测数值的计算隶属度环节通过马尔科夫预测思想求得预测隶属度向量,再根据预测隶属度向量,对云模型采用预测值加权求和方式,实现云模型与马尔可夫链的有机结合,并且给出了该方法多维化的方法;
(2)本发明设计的云服务器负载预测方法中,保留了云模型预测方法中通过历史数据建立云模型的方法,提出以云模型中的每一个云作为一个状态,以当前数据对云的隶属度建立马尔可夫初始矩阵,以历史数据的状态转移情况建立马尔可夫转移矩阵,以此求得一步转移隶属度结果,通过此隶属度加权法求得预测值;
(3)本发明设计的云服务器负载预测方法中,对于需要综合考虑多种因素负载预测情况,提出在多维变量时建立状态转移矩阵,以此进行负载预测;
(4)本发明设计的云服务器负载预测方法,减少了负载预测计算开销,提高实时预测性能。
附图说明
图1是本发明所设计云服务器负载预测方法的流程示意图;
图2a是实施例中云的示意图;
图2b是实施例中云模型的示意图;
图3是云模型的预测方法流程示意。
具体实施方式
下面结合说明书附图对本发明的具体实施方式作进一步详细的说明。
基于非启发式的负载预测方法包括马尔可夫链预测方法。马尔可夫过程指的是一种无后效性的随机过程,可以用于离散时间序列的预测。马尔可夫链是满足马尔可夫性质的随机过程。
基于启发式方法的负载预测主要思路是通过对历史数据的学习,训练得出预测模型,然后对该模型输入当前数值,得到预测数值。云模型预测方法是启发式方法的一种,其做法是将大量历史数据进行提炼得出体现数据分布特征的云函数集合,称为云模型,然后根据当前数据判断其下一步隶属的云模型,通过撒点法获得下一个预测值。基于云模型的预测方法优势具体体现在不确定性上,该方法对于波动性较大的数据预测有优势。
定义1:云与云滴.设u为定量论域,c是u上的定性概念,x是定义于u上的随机变量x的一次随机实现,x对c的隶属度μc(x)∈[0,1]是一随机且有稳定倾向,则x在论域u上的分布称为云(cloud),x称为云滴。
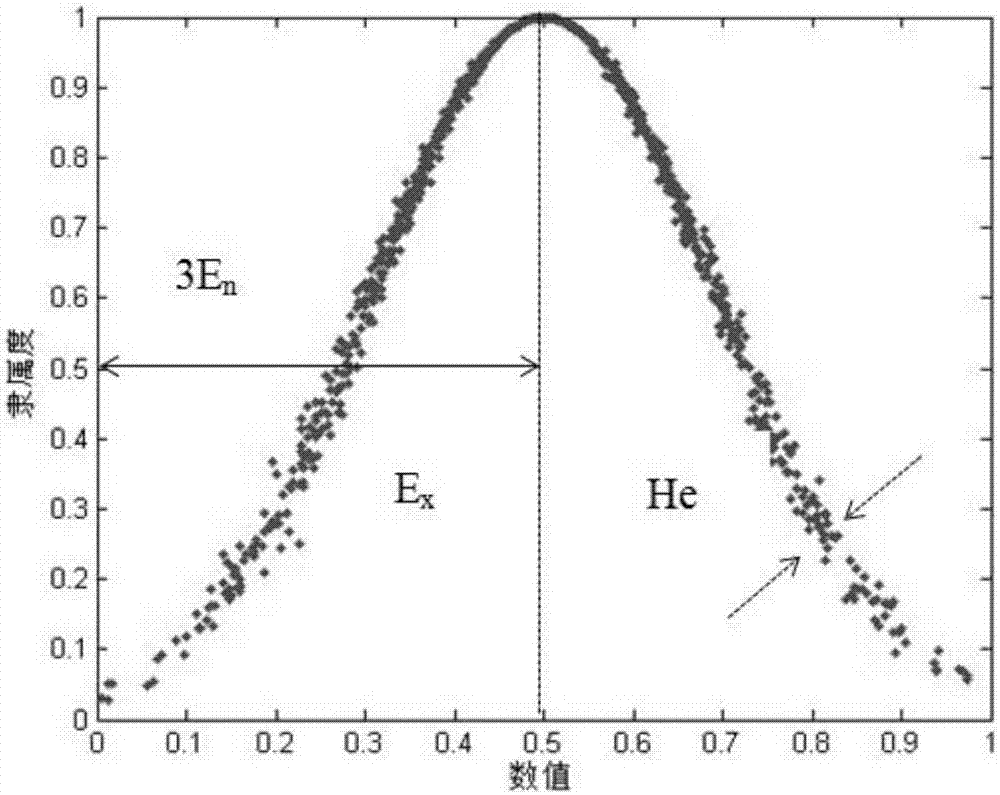
云模型集合中一个典型的云如图2a所示,图2a中的每一个点都是一个云滴。一个云可以记为c(ex,en,he),其中ex表示云的数学期望,即整个云当中最有可能表述该定性概念的值;en表示云的熵,表示该数学期望的离散程度;另有概念he表示云的超熵,即熵的离散程度。一个预测集合的数值波动范围越大,就是模糊性越大,这个可以由熵表示出来;而预测结果的随机性,由超熵的大小来表示。对一组数据整体描述的云的集合,就称为云模型,一个典型的云模型如图2b所示,图2b中数值为0和1时,表示的云是半云,半云是为了削弱边际条件对预测结果的影响,只取边际条件云的一半计入预测数值的过程。
将生成云滴与云模型的过程称为云发生器,云发生器分为正向云发生器与逆向云发生器两种。云模型的预测方法流程图见图3所示,通过逆向云发生器提炼历史数据的核心信息,统计得出数据符合的云模型集合,然后根据当前数据选择符合预测预期的对应云模型,再用正向云发生器获取预测数值。
定义2:正向云发生器.正向云发生器指的是依据云模型的数字特征生成满足条件的点{x,μ},从而获取预测值的过程。
正态云隶属函数γ(x)具体定义为:
其中ex表示云的数学期望,即整个云当中最有可能表述该定性概念的值;en表示云的熵,表示该数学期望的离散程度;另有概念he表示云的超熵,即熵的离散程度。一个预测集合的数值波动范围越大,就是模糊性越大,这个可以由熵表示出来;而预测结果的随机性,可以由超熵表示出来。
定义3:逆向云发生器.逆向云发生器指的是从相当数量的云滴中确定这些特征值的数学期望、熵和超熵的过程。
逆向云发生器完成的是由定量数值到定性概念的变迁。通过统计分析等技术将一定数量的定量值有效转换成以云模型的三个数字特征所表述的定性概念。要逆向建立一个云模型,首先需要对原始数据进行数据归一化的处理,然后进行拟合、云变化、跃升,得到一个定性的概念。大部分的逆向云模型拟合采用取峰值法,对于定量值即每个zi(x)中的x序列,c(ex,en,he)即为通过逆向云发生器所求得的对应数值区间的一个原始云模型,提取原始云模型信息的计算方法为:
step1:计算xi的数据样本的均值
step2:找到负载数据的频率分布统计中的各个峰值所在的位置,将其对应的横坐标定义为云的期望;
step3:熵
step4:超熵
云模型的建立会涉及到相似度的问题,即两个云之间重叠部分过大。所以对于初步建立好了的数据云模型,需要进行云概念的跃升,即将相似的云模型进行比较以及合并,从两个云的接近程度以及两个云之间重叠的大小进行考虑。将原始云模型集合进行跃升后即可得到云模型集合。
另外需要明确一个正态云的3en准则,定义为:论域u中的云滴对概念c有贡献的主要位于区间[ex-3en,ex+3en],而区间[ex-3en,ex+3en]外云滴的贡献微乎其微,可以忽略。主要贡献度入下表1所示,所以在讨论云模型预测得出的值的时候,无需考虑区间[ex-3en,ex+3en]以外可能产生的值。
表1
所设计云服务器负载预测方法的贡献在于:根据云计算负载数据特征,提出了一种马尔可夫链和云模型的混合预测方法。该方法保留了云模型预测方法中通过历史数据建立云模型的方法,提出以云模型中的每一个云作为一个状态,以当前数据对云的隶属度建立马尔可夫初始矩阵,以历史数据的状态转移情况建立马尔可夫转移矩阵,以此求得一步转移隶属度结果,通过此隶属度加权法求得预测值。并且对于需要综合考虑多种因素负载预测情况,该方法进一步提出多维化的方法,提出在多维变量时建立状态转移矩阵,以此进行负载预测。该方法方法减少负载预测计算开销,提高实时预测性能。
具体如图1所示,本发明设计了一种云服务器负载预测方法,用于针对云服务中心进行负载预测,实际应用过程当中,具体包括如下步骤:
步骤a.获得云服务中心所对应的云模型h,并针对云模型h中的各个子云函数,将彼此重叠大于预设重叠阈值的各个子云函数进行合并,更新云模型h,并进入步骤b。
步骤b,按如下设计,获得云模型集合h所对应的马尔可夫转移矩阵p'(n),并进入步骤c。
将已构建的两个云模型
将其每行衔接成为一个一维向量t:
(ja(1)jb(1),ja(1)jb(2),…,ja(1)jb(lb),ja(2)jb(1),…,ja(la)jb(lb))
如此,通过该状态集合求解马尔可夫状态转移矩阵,进而云模型集合h所对应的马尔可夫转移矩阵p'(n)。
步骤c.针对云服务中心当前时刻t的负载数据at,以及云服务中心上一时刻(t-1)的负载数据at-1,进行归一化处理,获得at所对应的归一化数据xt,然后采用如下公式:
计算获得xt分别相对云模型h中各个子云函数hn的隶属度μ(xt)n,并进入步骤d,其中,n={1、…、n},n表示云模型集合h中子云函数的数量;exn表示云模型集合h中第n个子云函数hn所对应的熵。
步骤d.针对xt相对云模型h中各个子云函数hn隶属度μ(xt)n,判断是否所有隶属度μ(xt)n均低于隶属度阈值μlimit,是则保留最大隶属度值,其余隶属度值设为0,更新xt相对云模型集合h中各个子云函数hn隶属度为μ'(xt)n,并进入步骤f;否则进入步骤e。
上述步骤d中,对于隶属度阈值μlimit的获取方式为,针对各个隶属度μ(xt)n所逆推的期望值,判断期望值是否落在[-∞,exn-3enn]∪[exn+3enn,+∞],是则将该期望值所对应的隶属度值设为0;否则不做操作;其中,exn表示云模型h中与期望值相对应的子云函数所对应的熵,enn表示云模型h中与期望值相对应的子云函数所对应的数学期望。
步骤e.针对xt相对云模型h中各个子云函数hn隶属度μ(xt)n,判断是否存在低于隶属度阈值μlimit的隶属度,是则将该隶属度值设为0,更新xt相对云模型集合h中各个子云函数hn隶属度为μ'(xt)n,并进入步骤f;否则直接将xt相对云模型h中各个子云函数hn隶属度μ(xt)n设为μ'(xt)n,并进入步骤f。
步骤f.针对xt相对云模型h中各个子云函数hn的隶属度μ'(xt)n,构成初始矩阵p(0),并根据p(n)=p(0)p'(n),获得一步转移隶属矩阵p(n),然后进入步骤g。
步骤g.分别针对云模型h中的各个子云函数hn,根据如下模型:
生成以enn为期望、以hen为熵的正态随机数yn,作为预测数值序列{y1,…,yn},分别作为各子云函数hn所对应的权值;进而获得云模型h中各个子云函数hn分别所对应的权值yn,然后进入步骤h;其中,enn表示云模型h中第n个子云函数hn所对应的数学期望,hen表示云模型h中第n个子云函数hn所对应的超熵。
步骤h.针对一步转移隶属矩阵p(n)中xt相对云模型h中各个子云函数hn的隶属度μ”(xt)n,以及云模型h中各个子云函数hn分别所对应的权值yn,进行加权平均处理,所获结果即为云服务中心下一时刻的负载预测值。
上面结合附图对本发明的实施方式作了详细说明,但是本发明并不限于上述实施方式,在本领域普通技术人员所具备的知识范围内,还可以在不脱离本发明宗旨的前提下做出各种变化。
- 还没有人留言评论。精彩留言会获得点赞!