人工耳蜗智能预测系统和方法与流程
本发明属于信号处理领域,特别涉及一种人工耳蜗智能预测系统和方法。
背景技术:
人工耳蜗是一种可以帮助重度或极重度耳聋患者恢复听力的人造官能。它由体外佩戴的信号处理单元以及体内植入的植入体组成。其中,体外信号处理单元上的麦克风负责收集环境中的声音信号,然后由信号处理器(dsp,digitalsignalprocessor)进行处理和编码,再将编码好的信号通过射频的方式发送给体内的植入体,并在电极阵列产生相应的电脉冲信号来刺激听神经,最终帮助植入者恢复听力。
在不同的生活场景中,人工耳蜗的dsp需要启用不同的算法来处理相应的声音信号。比如在安静的环境中,系统需要进入省电模式来延长电池的续航时间;在复杂的噪声环境中,需要启用降噪算法来消除噪声对语音信号的干扰;在听音乐时,系统则需要加强中高频的信号强度,来提升用户的音乐体验。同时,在不同的场景中,人工耳蜗植入者对于程序和参数的设定,也会有自己的喜好。比如在相同的噪声环境中,有的植入者倾向于听懂声音,所以对言语识别率有更高的要求;而有的植入者更倾向于舒适性,所以更加看重声音信号的舒适度。对于植入者不同的需求,也应该采取不同的程序和参数设置。所以,如果能够学习耳蜗植入者在以往场景中的使用习惯,并据此来预测他们在新的环境中所希望采用的程序与参数,那就可以依靠系统为每一位耳蜗植入者,在每种环境中,智能地选择他们最喜欢的程序及参数设定。
目前只有通过自动的场景识别,帮助人工耳蜗植入者自动选择程序的智能场景识别系统。然而,由于此类系统对所有的病人所推荐的程序及相应参数都是一样的,并不能满足病人个性化的需求。比如,在同样的噪声场景下,有的病人喜欢听得更清楚一些,而有的病人喜欢听得更舒服一些,这样就导致他们不能采用相同的程序,而要根据他们具体的需求,来确定选用什么样的程序。
技术实现要素:
有鉴于此,本发明的目的在于提供一种人工耳蜗智能预测系统和方法,能够学习在不同声音场景中,人工耳蜗植入者对不同程序的使用习惯,并根据其使用习惯来预测,在新的场景中应选择怎样的程序。
为达到上述目的,本发明提供了一种人工耳蜗智能预测系统,一种人工耳蜗智能预测系统,包括手动程序选择键、手动程序选择模块、智能场景识别系统、智能程序预测模块和场景程序输出模块,其中,
所述智能场景识别系统与智能程序预测模块连接,智能场景识别系统判断当前所处声音场景,将识别的场景结果输入给智能程序预测模块;
所述手动程序选择键的输入与手动程序选择模块连接,按动手动程序选择键对当前声音场景所用程序进行选择,同时将选择结果与智能场景识别系统输入的场景识别结果进行配对,在样本积累到预设程度之后,对智能程序预测模块进行基于样本的训练;在手动模式下,选择的结果输出给场景程序输出模块进行程序输出;
在智能模式下,所述智能程序预测模块与场景程序输出模块连接,在训练完成后,根据智能程序预测模块的输出在场景程序输出模块中自动选择程序,进行输出;在某声音场景的样本量不足时,智能程序预测模块选择最接近的声音场景,传给场景程序输出模块进行程序输出;若无接近的声音场景,则选取默认程序进行输出。
优选地,在完成训练所需的样本积累之前,所述手动程序选择键对程序选择的结果反馈给手动程序选择模块,记录声音场景与程序的对应关系,由下式表示:
其中,c为当前声音场景,p为用户所选择的程序,i为样本序号。
优选地,在样本积累到预设程度之后,进行基于样本的训练,所述手动程序选择模块对程序选择的结果输出给智能程序预测模块,统计每种声音场景下所采用的累计次数最多的程序,由下式确定:
pc=findmax{pi|c=ci}
其中,pi为声音场景为ci时,所采用的累计次数最多的程序,并将其设为输出程序pc。
优选地,在训练完成后,智能场景识别系统的输出与智能程序预测模块连接,场景程序输出模块输出的程序由下式确定:
其中,pc为输出程序;pi为声音场景为ci时,所采用的累计次数最多的程序;pj为选择手动模式时,使用频率高于与ci匹配的pi,则由pj代替pi与ci匹配;选择智能模式时,,根据当前的声音场景ci,智能匹配选择pi作为输出程序pc。
优选地,所述在某声音场景的样本量不足时,输出程序pc由下式确定:
其中,c为样本量不足的声音场景,如声音场景ci与c近似,且声音场景ci有与之匹配的所采用的累计次数最多的程序pi,则pi作为输出程序pc;如未发现与c近似的声音场景ci,则默认程序pdefault作为输出程序pc。
基于上述目的,本发明还提供了一种人工耳蜗智能预测方法,包括以下步骤:
智能场景识别系统判断当前所处声音场景,根据用户选择手动或智能模式将场景识别结果输出,在完成训练所需的样本积累之前,只能选择手动模式;
如选择手动模式,则通过按动手动程序选择键对当前声音场景所用程序进行选择;
在样本积累到预设程度之后,进行基于样本的训练,即用手动选择的结果来对场景与程序的对应关系进行训练;
如选择智能模式,则需在训练完成后,根据智能程序预测模块的输出智能选择程序,进行输出;
在某声音场景的样本量不足时,智能程序预测模块选择最接近的声音场景,进行程序输出;若无接近的声音场景,则选取默认程序进行输出;
优选地,所述在完成训练所需的样本积累之前,只能选择手动模式,并记录声音场景与程序的对应关系,由下式表示:
其中,c为当前声音场景,p为用户所选择的程序,i为样本序号。
优选地,所述在样本积累到预设程度之后,进行基于样本的训练,即用手动选择的结果来对场景与程序的对应关系进行训练,统计每种声音场景下所采用的累计次数最多的程序,由下式确定:
pc=findmax{pi|c=ci}
其中,pi为声音场景为ci时,所采用的累计次数最多的程序,并将其设为输出程序pc。
优选地,所述在训练完成后,根据智能程序预测模块的输出智能选择程序,进行输出,用户可选手动或智能模式,输出程序由下式确定:
其中,pc为输出程序;pi为声音场景为ci时,所采用的累计次数最多的程序;pj为选择手动模式时,使用频率高于与ci匹配的pi,则由pj代替pi与ci匹配;选择智能模式时,根据当前的声音场景ci,智能匹配选择pi作为输出程序pc。
优选地,所述在某声音场景的样本量不足时,智能程序预测模块选择最接近的声音场景,进行程序输出;若无接近的声音场景,则选取默认程序进行输出,输出程序pc由下式确定:
其中,c为样本量不足的声音场景,如声音场景ci与c近似,且声音场景ci有与之匹配的所采用的累计次数最多的程序pi,则pi作为输出程序pc;如未发现与c近似的声音场景ci,则默认程序pdefault作为输出程序pc。
本发明的有益效果在于:此智能程序预测系统,在智能场景识别的基础之上,可以满足人工耳蜗或助听器使用者的个性化需求。可以根据他们以往的使用习惯,以及对特定场景的偏好,来预测他们在当前场景所希望采用的程序及参数设置,而不是单一的向所有耳蜗或助听器使用者推荐同样的程序,也不需要他们手动来切换程序。这样可以在降低用户操作量的同时,满足他们的具体需求,最终实现提升用户体验的效果。
附图说明
为了使本发明的目的、技术方案和有益效果更加清楚,本发明提供如下附图进行说明:
图1为本发明实施例的一种人工耳蜗智能预测系统结构示意图;
图2为本发明实施例的一种人工耳蜗智能预测方法的步骤流程图。
具体实施方式
下面将结合附图,对本发明的优选实施例进行详细的描述。
参见图1,所示为本发明实施例的一种人工耳蜗智能预测系统,包括手动程序选择键20、手动程序选择模块30、智能场景识别系统10、智能程序预测模块40和场景程序输出模块50,其中,
所述智能场景识别系统10与智能程序预测模块40连接,智能场景识别系统10判断当前所处声音场景,将识别的场景结果输入给智能程序预测模块40;
所述手动程序选择键20的输入与手动程序选择模块30连接,按动手动程序选择键20对当前声音场景所用程序进行选择,同时将选择结果与智能场景识别系统10输入的场景识别结果进行配对,在样本积累到预设程度之后,对智能程序预测模块40进行基于样本的训练;在手动模式下,选择的结果输出给场景程序输出模块50进行程序输出;
在智能模式下,所述智能程序预测模块40与场景程序输出模块50连接,在训练完成后,根据智能程序预测模块40的输出在场景程序输出模块50中自动选择程序,进行输出;在某声音场景的样本量不足时,智能程序预测模块40选择最接近的声音场景,传给场景程序输出模块50进行程序输出;若无接近的声音场景,则选取默认程序进行输出。
具体实施例中,在完成训练所需的样本积累之前,所述手动程序选择键20对程序选择的结果反馈给手动程序选择模块30,记录声音场景与程序的对应关系,由下式表示:
其中,c为当前声音场景,p为用户所选择的程序,i为样本序号。
在样本积累到预设程度之后,进行基于样本的训练,所述手动程序选择模块30对程序选择的结果输出给智能程序预测模块40,统计每种声音场景下所采用的累计次数最多的程序,由下式确定:
pc=findmax{pi|c=ci}
其中,pi为声音场景为ci时,所采用的累计次数最多的程序,并将其设为输出程序pc。
在训练完成后,智能场景识别系统10的输出与智能程序预测模块40连接,场景程序输出模块50输出的程序由下式确定:
其中,pc为输出程序;pi为声音场景为ci时,所采用的累计次数最多的程序;pj为选择手动模式时,使用频率高于与ci匹配的pi,则由pj代替pi与ci匹配;选择智能模式时,,根据当前的声音场景ci,智能匹配选择pi作为输出程序pc。
所述在某声音场景的样本量不足时,输出程序pc由下式确定:
其中,c为样本量不足的声音场景,如声音场景ci与c近似,且声音场景ci有与之匹配的所采用的累计次数最多的程序pi,则pi作为输出程序pc;如未发现与c近似的声音场景ci,则默认程序pdefault作为输出程序pc。
与上述系统对应的,还提供了一种人工耳蜗智能预测方法,其流程图参见图2为本发明实施例的一种人工耳蜗智能预测方法的步骤流程图;
包括以下步骤:
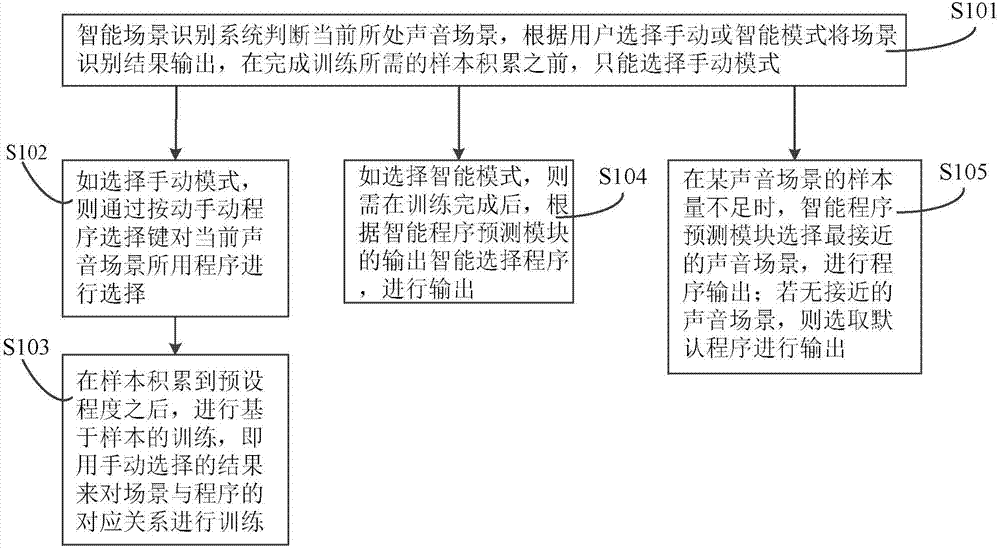
s101,智能场景识别系统判断当前所处声音场景,根据用户选择手动或智能模式将场景识别结果输出,在完成训练所需的样本积累之前,只能选择手动模式;
s102,如选择手动模式,则通过按动手动程序选择键对当前声音场景所用程序进行选择;
s103,在样本积累到预设程度之后,进行基于样本的训练,即用手动选择的结果来对场景与程序的对应关系进行训练;
s104,如选择智能模式,则需在训练完成后,根据智能程序预测模块的输出智能选择程序,进行输出;
s105,在某声音场景的样本量不足时,智能程序预测模块选择最接近的声音场景,进行程序输出;若无接近的声音场景,则选取默认程序进行输出;
进一步地,s101中,在完成训练所需的样本积累之前,只能选择手动模式,并记录声音场景与程序的对应关系,由下式表示:
其中,c为当前声音场景,p为用户所选择的程序,i为样本序号。
进一步地,s103中,在样本积累到预设程度之后,进行基于样本的训练,即用手动选择的结果来对场景与程序的对应关系进行训练,统计每种声音场景下所采用的累计次数最多的程序,由下式确定:
pc=findmax{pi|c=ci}
其中,pi为声音场景为ci时,所采用的累计次数最多的程序,并将其设为输出程序pc。
进一步地,s104中,在训练完成后,根据智能程序预测模块的输出智能选择程序,进行输出,用户可选手动或智能模式,输出程序由下式确定:
其中,pc为输出程序;pi为声音场景为ci时,所采用的累计次数最多的程序;pj为选择手动模式时,使用频率高于与ci匹配的pi,则由pj代替pi与ci匹配;选择智能模式时,根据当前的声音场景ci,智能匹配选择pi作为输出程序pc。
进一步地,s105中,在某声音场景的样本量不足时,智能程序预测模块选择最接近的声音场景,进行程序输出;若无接近的声音场景,则选取默认程序进行输出,输出程序pc由下式确定:
其中,c为样本量不足的声音场景,如声音场景ci与c近似,且声音场景ci有与之匹配的所采用的累计次数最多的程序pi,则pi作为输出程序pc;如未发现与c近似的声音场景ci,则默认程序pdefault作为输出程序pc。
具体实施例参照上述系统实施例,在此不赘述。
最后说明的是,以上优选实施例仅用以说明本发明的技术方案而非限制,尽管通过上述优选实施例已经对本发明进行了详细的描述,但本领域技术人员应当理解,可以在形式上和细节上对其作出各种各样的改变,而不偏离本发明权利要求书所限定的范围。
- 还没有人留言评论。精彩留言会获得点赞!