一种基于中垂面特性的虚拟声像近似获取方法与流程
本发明涉及3d虚拟声技术领域,具体涉及一种基于中垂面特性的虚拟声像近似获取方法,其生成为满足个体听觉特性的虚拟声像。
背景技术:
相对于真实声源产生的感知声像而言,虚拟声像指通过信号处理的方法,模拟声波从声源到双耳的物理传播过程,从而使听者产生的感知声像。虚拟声像技术往往只需要一副耳机,对重放硬件设备的依赖性小,故在三维(3d)电视、电影以及虚拟现实(virtualreality,vr)技术等领域具有较大的应用前景。头相关传输函数(head-relatedtransferfunction,hrtf)是虚拟声像合成的核心部分;它表征声波到耳的传播过程中,人体生理器官(主要是头部)对声波的作用,包括绕射、反射等物理现象。和真实声像相同,虚拟声像可以位于听者周围三维空间的任意方位。为了合成任意方位的虚拟声像,通常需要在计算机等重放硬件设备中存储大量的hrtf数据,其中每一对hrtf(左耳和右耳)对应一个具体的空间方位。另一方面,hrtf和听者的生理形态有关,例如头部偏大听者的hrtf和头部偏小听者的hrtf存在差异。可见,hrtf是一个因人而异的个性化函数。已有研究表明,为了得到逼真的虚拟声像感知效果,需要采用听者自己的个性化hrtf数据进行虚拟声像合成。可以设想,如果一套虚拟声像重放系统有一百个潜在的使用者(即听者),原则上就需要存储一百组个性化hrtf数据,且每组数据包括所有可能的空间方位。可见,为了实现任意空间方位、高质量虚拟声像的重放效果,在重放硬件设备中预先存储的hrtf数据量是非常巨大的。因此有必要采用适当的数据简化和压缩方法,降低hrtf数据的存储量,减轻对各类重放设备的硬件需求。
技术实现要素:
本发明为解决上述现有虚拟声重放中hrtf的存储量问题,提供了一种基于中垂面特性的虚拟声像近似获取方法。发明利用了中垂面hrtf和混乱锥纵截面hrtf的幅度谱相似性,以及混乱锥上任意方位的双耳时间差相同的特性;只需要已知中垂面和水平面的hrtf数据,就可以近似获取任意空间方位的hrtf,从而实现任意空间方位虚拟声像的合成和重放。本发明可有效减少虚拟声像合成中所需存储的hrtf的数量,减轻虚拟声像重放系统的负担。
本发明的目的通过以下技术方案实现。
一种基于中垂面特性的虚拟声像近似获取方法,包括如下步骤:
步骤1、确定目标虚拟声像所处的混乱锥纵截面和水平面的交点坐标;
步骤2、选取交点处的双耳头相关传输函数hrtf,计算双耳时间差;
步骤3、在中垂面上,确定和目标声像同仰角的空间方位,用该方位的hrtf幅度谱代替目标声像方位hrtf的幅度谱;
步骤4、根据最小相位近似方法,将目标声像方位的双耳hrtf幅度谱和双耳时间差进行合成,得到目标声像方位hrtf的近似结果;
步骤5、将单通路信号和目标声像方位hrtf进行时间域卷积处理或等价地频率域滤波处理,得到合成的双耳虚拟声信号,输出到耳机进行重放。
进一步地,所述步骤1中以双耳连线的中点为坐标原点,建立双耳极坐标系统;通常,需要采用角度和距离共同表征一个特定的声像方位,考虑到本发明涉及的远场hrtf与距离无关,因此一个特定的声像方位仅需偏侧角θ和仰角φ表征,所述偏侧角-90°≤θ≤90°表示空间声像与原点构成的方向矢量和中垂面的夹角;而仰角-90°≤φ≤270°表示空间声像在中垂面的投影与水平面的夹角。
进一步地,所述步骤1中,假设目标虚拟声像处于空间点(θ,φ),则它决定了一个偏侧角为θ的混乱锥;过虚拟声像的空间方位,做一个平行于中垂面的混乱锥纵截面,交水平面于点(θ,φ=0°)。
进一步地,所述步骤2具体包括:
步骤201、根据步骤1的结果,从已知hrtf数据库中提取水平面(θ,φ=0°)双耳hrtf的时间域数据,即hl和hr;
步骤202、将hl和hr代入公式(1),计算两者的相关系数:
步骤203、取公式(1)相关系数c达到最大值时所对应的τmax为双耳时间差。由于混乱锥上各点的双耳时间差一样,所以公式(1)得到的双耳时间差τmax即为目标虚拟声像处的双耳时间差。
进一步地,所述已知hrtf数据库,有些采用双耳极坐标系统(θ,φ),例如美国加利福尼亚大学戴维斯分校cipic数据库;而有些采用顺时针球坐标系统(θ',φ'),例如中国华南理工大学中国人样本hrtf数据库、美国麻省理工学院mithrtf数据库。所述顺时针球坐标系统(θ',φ')通过下面的公式(2)转换为双耳极坐标系统(θ,φ):
进一步地,步骤3中具体包括:
假设目标虚拟声像处于空间点(θ,φ),则中垂面上和目标声像同仰角的空间方位为(θ=0°,φ);接着从已知hrtf数据库中提取中垂面(θ=0°,φ)的双耳hrtf,将其幅度谱(即|h(l,median)|、|h(r,median)|)作为目标虚拟声像处hrtf的幅度谱。
进一步地,所述步骤4中,根据最小相位近似,将目标声像方位的双耳hrtf幅度谱和双耳时间差进行合成,公式为:
其中t0为声源到双耳的延迟时间,可根据应用场景进行设定。
本发明的原理是:混乱锥定义为到双耳的距离差为常数的点所构成的曲面,因此混乱锥上所有点到双耳的时间差异(即双耳时间差)是相同的。由于目标声像方位决定了一个混乱锥纵截面,因此可以计算该混乱锥纵截面和水平面交点的双耳时间差,进而得到目标声像方位的双耳时间差。另一方面,hrtf幅度谱特征起源于入射声波和生理结构(包括头部和耳廓等)的相互作用。当声源从中垂面(即前方)逐渐向侧向偏移时,声波入射角将发生变化,然而其大体的物理过程仍是相似的,因此中垂面hrtf和混乱锥纵截面hrtf的幅度谱具有较高的相似性。考虑到人耳有限的分辨能力,可以采用中垂面hrtf幅度谱近似代替混乱锥纵截面hrtf的幅度谱,而不引起听觉误差。
本发明与现有技术相比,具有如下优点和有益效果:
1.本发明只需要已知中垂面和水平面的hrtf数据,就可以近似获取任意空间方位的hrtf,从而实现任意空间方位虚拟声像的合成和重放。
2.本发明可有效减少虚拟声像合成中所需存储的hrtf的数量,减轻虚拟声像重放系统的负担。
3.本发明可采用算法语言编制的软件在多媒体计算机上实现,也可以采用通用信号处理芯片(dsp硬件)电路或专用的集成电路实现,用于各种便携式播放设备包括智能手机、虚拟现实等方面的声音重放。
附图说明
图1是本发明实施例的原理图;
图2是空间方位示意图;
图3是本发明实施例的多媒体计算机实现的信号流程图。
具体实施方式
下面结合附图对本发明作进一步的说明,但本发明要求保护范围并不局限于实施例表示的范围。
图1是本发明的一种基于中垂面特性的虚拟声像近似获取方法的原理方框图。它利用了中垂面hrtf和混乱锥纵截面hrtf的幅度谱相似性,以及混乱锥上任意方位的双耳时间差相同的特性;只需要已知中垂面和水平面的hrtf数据,就可以近似获取任意空间方位的hrtf,从而实现任意空间方位虚拟声像的合成和重放。本发明可有效减少虚拟声像合成中所需存储的hrtf的数量,减轻虚拟声像重放系统的负担。
一种基于中垂面特性的虚拟声像近似获取方法,包括如下步骤:
步骤1、确定目标虚拟声像所处的混乱锥纵截面和水平面的交点坐标;
步骤2、选取交点处的双耳头相关传输函数hrtf,计算双耳时间差;
步骤3、在中垂面上,确定和目标声像同仰角的空间方位,用该方位的hrtf幅度谱代替目标声像方位hrtf的幅度谱;
步骤4、根据最小相位近似方法,将目标声像方位的双耳hrtf幅度谱和双耳时间差进行合成,得到目标声像方位hrtf的近似结果;
步骤5、将单通路信号和目标声像方位hrtf进行时间域卷积处理或等价地频率域滤波处理,得到合成的双耳虚拟声信号,输出到耳机进行重放。
具体而言,所述步骤1中以双耳连线的中点为坐标原点,建立双耳极坐标系统;通常,需要采用角度和距离共同表征一个特定的声像方位,考虑到本发明涉及的远场hrtf与距离无关,因此一个特定的声像方位仅需偏侧角θ和仰角φ表征,所述偏侧角-90°≤θ≤90°表示空间声像与原点构成的方向矢量和中垂面的夹角;而仰角-90°≤φ≤270°表示空间声像在中垂面的投影与水平面的夹角。
具体而言,所述步骤1中,假设目标虚拟声像处于空间点(θ,φ),则它决定了一个偏侧角为θ的混乱锥;过虚拟声像的空间方位,做一个平行于中垂面的混乱锥纵截面,交水平面于点(θ,φ=0°)。
具体而言,所述步骤2具体包括:
步骤201、根据步骤1的结果,从已知hrtf数据库中提取水平面(θ,φ=0°)双耳hrtf的时间域数据,即hl和hr;
步骤202、将hl和hr代入公式(1),计算两者的相关系数:
步骤203、取公式(1)相关系数c达到最大值时所对应的τmax为双耳时间差。由于混乱锥上各点的双耳时间差一样,所以公式(1)得到的双耳时间差τmax即为目标虚拟声像处的双耳时间差。
具体而言,所述已知hrtf数据库中,有些采用双耳极坐标系统(θ,φ),例如美国加利福尼亚大学戴维斯分校cipic数据库;而有些采用顺时针球坐标系统(θ',φ'),例如中国华南理工大学中国人样本hrtf数据库、美国麻省理工学院mithrtf数据库。顺时针球坐标系统(θ',φ')可以通过下面的公式(2)转换为双耳极坐标系统(θ,φ):
θ=arcsin(sinθ'×cosφ');(2)
具体而言,步骤3中,假设目标虚拟声像处于空间点(θ,φ),则中垂面上和目标声像同仰角的空间方位为(θ=0°,φ),接着从已知hrtf数据库中提取中垂面(θ=0°,φ)的双耳hrtf,将其幅度谱(即|h(l,median)|、|h(r,median)|)作为目标虚拟声像处hrtf的幅度谱。
具体而言,步骤4中,根据最小相位近似,将目标声像方位的双耳hrtf幅度谱和双耳时间差进行合成,公式为:
其中t0为声源到双耳的延迟时间,可根据应用场景进行设定。
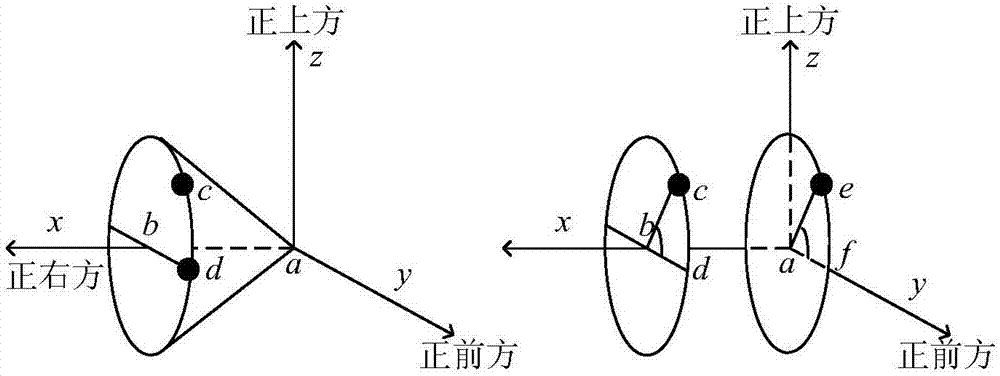
图2是本发明涉及的空间方位示意图。图中,xyz表征三维空间,zy表征中垂面,xy表征水平面,a点代表坐标原点,c点代表目标虚拟声像方位。左图中,c点和a点共同决定了一个以a为顶点的混乱锥,ab为锥体的中垂线;进一步,过c点做混乱锥纵截面,交水平面于点d。右图中,目标虚拟声像c的仰角为∠cbd,中垂面上的e点为和目标声像同仰角的空间方位,有∠eaf=∠cbd。本发明中,采用e的hrtf幅度谱作为目标虚拟声像c的hrtf幅度谱;同时,采用d的双耳时间差作为目标虚拟声像c的双耳时间差。
图3是本发明实施例的多媒体计算机实现的信号流程图。在实际的应用中,需要合成的虚拟声像方位可能不止一个,可以反复采用本发明的方法逐个进行目标虚拟声像的hrtf的获取。
本发明的上述实施例仅仅是为清楚地说明本发明所作的举例,而并非是对本发明的实施方式的限定。对于所属领域的普通技术人员来说,在上述说明的基础上还可以做出其它不同形式的变化或变动。这里无需也无法对所有的实施方式予以穷举。凡在本发明的精神和原则之内所作的任何修改、等同替换和改进等,均应包含在本发明权利要求的保护范围之内。
- 还没有人留言评论。精彩留言会获得点赞!