机会网络中一种基于兴趣匹配的数据分发方法与流程
本发明属于机会网络领域,特别涉及一种基于兴趣匹配的数据分发方法。
背景技术:
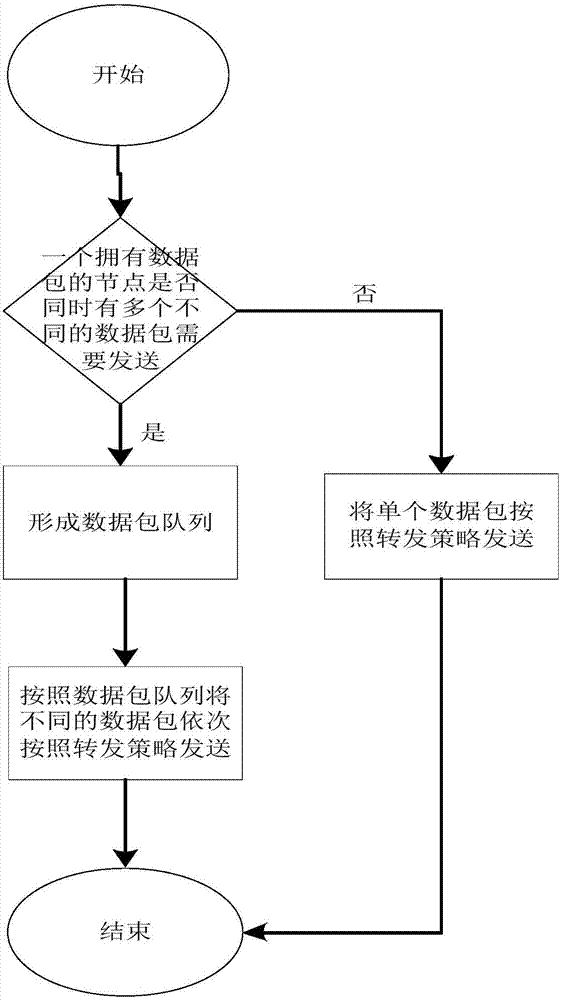
:机会网络是一种通过节点移动带来的相遇机会来实现网络通信的,时延和分裂的可容忍的自组织网络。机会网络节点初始位置和网络的规模都不需要事先设定,不需要源节点和目标节点之间存在完整的路径就可以很好的地应对无线环境中需要面对的间歇性连接、大延迟、高错误率等通信特征。机会网络中,采用“存储-携带-转发”形式的路由协议能够极大地扩大移动互联网的覆盖范围,在网络基础设施缺乏和网络环境恶劣的条件下使得数据的分发成为可能。机会网络的数据包分发与其路由机制密不可分,机会路由的多副本特性使得数据包分发在其传递过程中得以实现。然而,在实际使用的过程中,为保证数据包传输的成功率,网络中会存在大量重复的数据包副本,使得数据包分发过程极大地占用网络存储资源,成为造成网络拥塞的主要原因。大量针对机会网络的路由算法被提出,这些算法大多从数据包复制与拓扑预测2个方面提高机会网络的路由性能。例如:epidemic算法与sprayandwait算法通过增加数据包副本数的方式提高路由效率;而sprayandfocus,prophet,maxprop算法则通过预测选择投递成功率较高的中继节点的方式提高路由效率。根据网络中单个数据包的副本数,经典的机会网络路由方法可以分为单副本路由方法和多副本路由方法两种。一般情况下,单副本路由方法开销率低、网络耗能少,但投递率较低并且时延较大,如:directdelivery路由方法和firstcontact路由方法;多副本路由方法往往能保证较高的投递率和较小的时延,但通常网络开销率和耗能较大,如:epidemic路由方法、sprayandwait路由方法和prophet路由方法。我们还发现,在网络节点能量有限、网络节点的缓存空间有限和被传输的数据包的生存时间有限的条件下,现有的机会网络的研究大多是针对于某一个性能的改进,很少有基于多方面性能同时提升。与此同时,大部分的研究中持有数据包副本的节点分发多副本的个数也是提前规定好的,不能随着网络结构的变化而随之改变,导致网络中会存在较多的冗余副本。经典的路由算法,如epidemic路由方法和sprayandwait路由方法都没有考虑到节点之间属性的关联性,只是盲目地向邻居节点发送之前定义好的数据包个数。prophet路由方法考虑到了节点之间的关联性,但没有动态、合理地给中继节点分配相应个数的数据包。因此,随着移动互联网的迅猛发展,提出一种基于多方面因素考虑的提高数据包的投递率和减少传输延迟的数据分发方法就极为迫切。技术实现要素:本发明的目的在于克服现有方法中的不足,提供一种基于兴趣匹配的数据分发方法,在基于兴趣匹配的基础上,可以在一定程度上减少数据包的冗余、缩短数据包的传输时延和提高数据包投递率。为了达到上述目的,本发明提供以下技术方案:本发明提供了一种基于兴趣匹配的数据分发方法,包括以下步骤:步骤1:判断持有数据包的节点i是否需要发送数据包;步骤2:对要发送的数据包进行队列管理,持有数据包的节点i从队列中取出优先级最高的数据包且待发送;步骤3:持有数据包的节点i根据邻居节点j的兴趣历史记录表及数据包的兴趣向量,计算邻居节点j与数据包的兴趣相似度;步骤3.1:更新持有数据包的节点i与相遇节点的兴趣历史记录表;步骤3.2:计算节点的τj值;步骤3.3:计算邻居节点j和所要发送数据包的兴趣相似度;步骤3.4:判断每个邻居节点j和所发送数据包的相似度值是否超过阈值δ1,如超过,将该邻居节点j加入到候选节点集合,否则计算该节点的转发程度函数步骤3.5:计算邻居节点j的转发程度函数步骤3.6:判断邻居节点j的转发程度值是否大于阈值δ2,大于,则计算转发的副本数k,否则持有数据包的节点不转发数据包给该邻居节点j;步骤4:判断持有数据包的节点i所持有的数据包的副本数是否大于或等于候选节点集合中要发送的数据包总个数;步骤5:持有数据包的节点i构造、广播数据包并更新数据包的副本数;步骤5.1:持有数据包的节点i构造新的数据包;步骤5.2:计算候选节点集合中需要发送的数据包个数γ;步骤5.3:判断数据包副本数k的值是否大于等于γ,若是,则持有数据包的节点构造新数据包;步骤5.4:节点i广播数据包并按照集合s中的各个元素广播数据包;步骤5.5:任意接收到数据包的邻居节点j,判断s中的元素的第一个分量是否含有该节点,若是,则节点j接收数据包,并设置其副本数为包含该节点的元素的第二个分量,否则节点j丢弃该数据包;步骤6:判断数据包队列中是否还有未发送的数据包;步骤7:持有数据包的节点i将所持有的数据包发送给一个邻居节点j后,继续等待和其它节点相遇,并重复执行所述步骤1-6。优选的,所述步骤1-7中,数据包分为a、b两类,a类为节点自身产生的数据包,b类为来自于其它节点的转发数据包;优选的,所述步骤2中,队列管理是由数据包的类型和生存时间共同决定的;优选的,所述步骤2中,数据包优先级的计算方法为:其中t为数据包的生存时间;优选的,所述步骤3中,邻居节点j和所要发送的数据包的兴趣相似度计算公式为:其中,参数τj表示具有某一特征值的邻居节点数在与持有数据包的节点相遇的全部节点的总数中所占的比例,计算式为:更优选的,所述步骤3.4中,邻居节点j的转发程度函数为其中,ei、ej分别表示节点i和节点j的节点的剩余能量,ηi,d、ηj,d分别是节点i与数据包的相似度和节点j与数据包的相似度。α是一个固定的参数,用于调节数据包与节点相似度和节点能量在转发程度函数中各自所占的比例。本发明的有益效果:本发明提出的一种基于兴趣匹配的数据分发方法,可以使数据包的源节点可以快速地选择相似度高和节点能量高的节点来转发数据包,同时计算节点被分配的数据包的副本数。因此,此方法随着网络负载的增加,始终能够保持较高的数据包的成功投递率和较低的投递时延。本发明考虑到节点之间的关联性,采用的兴趣匹配的方法能够保证节点缓存中的大部分数据包都是节点感兴趣的,能够提高节点参与网络协助的积极性,极大减少了节点对自身不感兴趣的数据包的存储耗能。这种转发的策略能够保证节点缓存区中与节点兴趣匹配的数据包所占的空间与总的缓存空间的比值较高。附图说明图1为本发明实施例机会网络中一种基于兴趣匹配的数据分发方法流程图;图2为本发明实施例数据包队列管理示意图;图3为本发明实施例邻居节点与数据包兴趣相似度匹配流程图。具体实施方式下面结合附图对本发明的技术方案做详细描述。本发明实施例采用连接图g(v,e)来表示机会网络,其中v代表节点的集合,每个节点代表一个用户,eij∈e表示节点i和节点j的连接边。网络中任意一对节点i和节点j之间的相遇服从参数为λij的指数分布,网络中的每个节点具有一定的初始能量,在转发和接收数据包时都会消耗一定的能量。网络中的节点转发和接收数据包具体方法流程如图1所示,包括如下步骤:步骤1:判断节点i是否需要发送数据包。如果有数据包需要发送,则进入发送环节,否则节点i需要等待有发送需求的数据包或者直到与其他节点相遇。步骤2:对要发送的数据包队列进行排序,节点i从队列中取出优先级最高的数据包且待发送。步骤3:节点i根据每个邻居节点j的兴趣历史记录表及数据包的兴趣向量,计算每个邻居节点j与数据包的兴趣相似度,并依据所计算兴趣相似度决定是否将数据包发送给该节点。步骤4:判断节点i持有的数据包的副本数k是否大于或等于集合s中要发送的数据包总个数,如果是大于或等于,进行下一步骤,否则节点i优先选择转发条件好的节点作为中继节点。步骤5:节点i构造、广播数据包并更新数据包的副本数k,进一步包括如下步骤:步骤5.1:节点i构造新的数据包。假设有s和h两个集合,如下表所示:sh其中,s是候选节点二元组的集合,h是候选节点接收数据包的副本数的集合。新数据包包含集合s,集合s中包含有二元组(m,hm),其中m代表的节点的编号,hm代表的是节点m接收的数据包副本数。步骤5.2:计算集合s中需要发送的数据包的个数γ。其中|s|是候选集合s的势,m是指候选节点的编号,hm是编号为m的候选节点接收数据包的个数。步骤5.3:判断数据包副本数k的值是否大于等于γ,若是,则节点i构造新数据包。否则节点i将集合s中二元组中hm为1的二元组保持不变,其他二元组的hm值置为0,构造数据包d'。步骤5.4:节点i广播数据包并按照集合s中的各个元素广播数据包。步骤5.5:任意接收到数据包的邻居节点j,判断s中的元素的第一个分量是否含有该节点,若是,则节点j接收数据包,并设置其副本数为包含该节点的元素的第二个分量,否则节点j丢弃该数据包。进一步的,若节点j的数据包队列已有数据包,则丢弃新接收的数据包。若节点j的数据包队列已满,则节点j比较新到的数据包的优先级(设为α)与队列中所含数据包的最低优先级(设为β)的大小关系,若α大于β,则节点j丢弃优先级为β的数据包,并存优先级为α的数据包,否则节点j放弃对新数据包的存储。步骤6:判断数据包队列中是否还有未发送的数据包。如果数据包队列中还有未发送的数据包,返回执行步骤2,对剩余数据包进行排序,并从队列中取出优先级最高的数据包且计算每个邻居节点j与该数据包的相似度。步骤7:节点i将所持有的数据包发送给一个邻居节点后,继续等待和其它节点相遇,并重复执行步骤1-6。如图2所示,为本发明实施例数据包队列管理示意图。若某个节点同时有多个数据包等待发送,就按照一定的转发策略将所要发送的数据包形成队列进行管理。队列管理就是对节点存储的数据包进行恰当的分类,从而在节点相遇时决策存储队列中数据包的转发顺序,并在存储达到最大值时决策数据包的丢弃规则。机会网络中的数据包主要分为两种类型:(a)节点自身产生的数据,封装为数据包存入数据包队列;(b)来自于其它节点的转发数据包,存入数据包队列。在上述两种类型的数据包中,a类数据包刚刚产生,还没有经过传输,而b类数据包已经被传输过了。因此,令a类数据包比b类数据包先发送,即a类数据包的类别高于b类数据包。对于网络中的数据包,其生存时间越久,副本数目就可能越多,成功递交到目标节点的概率也越大,因此生存时间也可以用来表示数据包在网络中的重要性和冗余程度。假设在数据包的首部设有一个生存时间域,用来记录数据包在网络中的存活时间,此外,每个节点均有一个本地计时器。对于数据包的生存时间,按照如下的规则进行计算和更新:①刚生成的数据包,其生存时间被赋于0,并被存入数据包队列。②当数据包被转发到某个邻居节点时,此节点直接将其存入数据包队列,而对数据包的生存时间不做任何修改。同样,当数据包被传送给其它节点并重新放回数据包队列后,其生存时间同样不变。之所以这么做是由于数据包在节点间的传输时间非常短,几乎可以忽略。③数据包在被放入节点的数据包队列之后,其生存时间会在计时器超时片刻被自动增加。队列管理是由数据包的类型和生存时间共同决定的。数据包队列中的所有数据包按照先发送a类数据包后发送b类数据包的顺序排列并发送,而对于类别相同的数据包,则依据各自的生存时间长短来排序,生存时间越小的数据包,其排列顺序越前。最后数据包队列中数据包按照优先级从大到小排序。当节点的数据包队列已满,又有新数据包需要被入列时,节点比较新到的数据包和队尾的数据包的类别,并参照二者的生存时间做出数据包丢弃决定。规则如下:①若新数据包的优先级和队尾数据包的类别相同,且新数据包的生存时间较长,则直接丢弃新数据包;②若新数据包的和队尾数据包的类别相同,且新消时息的生存时间较短,则队尾数据包被丢弃,而新数据包会按照上述的数据包类别和生存时间的规则被插入到数据包队列中;③若新数据包的类别高于队尾数据包的类别,新数据包也会按照上述的数据包的类别和生存时间的规则被插入到数据包队列中。数据包d的优先级pd计算方法如下:其中t为数据包的生存时间。如图3所示,为本发明实施例邻居节点与数据包兴趣相似度匹配流程图,具体步骤如下:步骤3.1:更新持有数据包的节点i与相遇节点的兴趣历史记录表。兴趣向量f表示用户对各种兴趣的喜好程度,也表示内容在各个兴趣上的相关程度:f=<f1,f2,...,fi,...,fr>f是一个兴趣向量,具有r个分量:f1到fr,fi代表第i个兴趣。如兴趣表(表1)所示:表1每个兴趣具有多个可能的值。例如,f4表示影视,其值可能是“韩剧”或者“古装剧”。网络中任意一对节点相遇后会交换各自的兴趣形成各自的兴趣历史记录。本方法采用表格来记录节点的兴趣历史记录,如兴趣历史记录表(表2)所示:表2特征值1值2...饮食中餐(3)西餐(3)...音乐古典乐(6)流行乐(2)...阅读看报(6)读书(2)...影视韩剧(2)美剧(5)...书籍文学(5)哲学(1)...棋类围棋(6)象棋(2)............网络中有如下的兴趣列表:(饮食,音乐,阅读,影视,书籍,棋类)。节点i的兴趣向量fi=<f1,f2,f3,f4,f5,f6>,代表的是(“中餐”,“古典乐”,“看报”,“韩剧,美剧”,“文学”,“围棋”)。节点i和邻居交换兴趣后,邻居节点和节点i的兴趣历史记录表会相对应地更新。例如,如果节点i已经更新了f2的值为“古典乐=2”,则说明它曾经遇到两个对古典乐感兴趣的节点。假设数据包d具有兴趣列表f=(“中餐”,“古典乐”,“看报”,“韩剧,美剧”,“文学”,“围棋”),在节点i的历史相遇记录中,对于兴趣“饮食”,存在两个喜欢“中餐”的节点,三个喜欢“西餐”的节点。因此,类似地,对于兴趣“影视”,我们可以得到因此,我们得到:假设αj=1,对于所有j=1,2,3,...,r,可得节点i和数据包d的兴趣相似性是0.5202。步骤3.2:计算节点的τj值,计算公式为:参数τj表示具有某一特征值的邻居节点数在与持有数据包的节点相遇的全部节点的总数中所占的比例,njk表示的是兴趣j的值。持有数据包d的节点i会收到所有邻居节点发来的历史相遇记录表,数据包d的兴趣向量节点i根据数据包d和它的邻居节点们的历史相遇记录表来计算它们的兴趣相似度。步骤3.3:计算邻居节点j和所要发送的数据包的兴趣相似度ηj,d,计算公式为:其中,r是指整个网络共有不同兴趣总数,αj是兴趣j的权重,并且相似度ηj,d值越高,表示该邻居节点与所要发送的数据包的兴趣更相关。因此,如果采用该邻居节点作为中继节点,那么就更可能遇到对该数据包感兴趣的其它节点,这在一定程度上提高了数据包d的投递率。步骤3.4:判断每个邻居节点j和所发送数据包的相似度值是否超过阈值δ1,如果超过,则将二元组(j,1)加入到候选节点集合,否则计算节点i与节点j之间的转发程度函数步骤3.5:计算邻居节点j的转发程度值通过计算邻居节点j和持有数据包的节点i的转发程度函数来判断邻居节点j是否有能力帮助节点i转发数据包,转发程度函数计算公式为:其中,ei、ej分别表示节点i和节点j的节点的剩余能量,ηi,d,ηj,d分别是节点i与数据包的相似度和节点j与数据包的相似度。α是一个固定的参数,用于调节数据包与节点相似度和节点能量在转发程度函数中各自所占的比例。步骤:3.6:判断节点j的转发程度值是否大于阈值δ2。如果节点j的转发程度值大于阈值δ2,计算转发的副本数εj,并将二元组(j,εj)加入到集合s中,否则节点i不转发数据包给节点j。副本数εj的计算公式为:其中,k表示节点i持有的数据包的副本数,n表示符合转发条件邻居结点的个数,σi表示节点i的度,公式为:1/λij表示节点i和节点j之间的相遇时间间隔,1/λij越小,表明节点i和节点j之间的相遇频繁度越大,它们之间传输的数据包时会有更少的传输延迟。以下,对为了确认本发明得到的效果而实施的实验例进行说明。实验例1,持有数据包的节点具有多个数据包需要发送,且当前邻居节点有多个:设节点a有三个数据包据需要发送,持有的数据包d1是a类型数据包,生存时间为0,数据包d2是b类型数据包,生存时间为3h,数据包d3是b类型数据包,生存时间为1h,生存时间的单位是小时。节点a的当前邻居有:节点b,节点c和节点e,节点a的度是20,节点b的度是30,节点c的度是50,节点e的度是60,单位是个/秒。按照本发明数据包的分发方式,具体实施方式如下:1)节点a判断自身是否有数据包需要发送,如果有数据包需要发送,则进行下一步,否则,节点a等待直到与其他节点相遇;2)计算得节点a的数据包d1的优先级是2,数据包d2的优先级是0.25,数据包d2的优先级是0.5。节点a按照优先级的大小排序数据包形成数据包队列。节点a要发送的数据包队列中取出优先级最高的数据包d1,计算周围邻居节点中含有数据包d1的个数在总的邻居节点中的比例为0.3,没有超过阈值δ3,δ3的值为0.8,将d1的副本数初始值为k=10;3)节点a根据当前邻居的兴趣历史记录表及数据包d1的兴趣向量,计算每个邻居与数据包d1的相似度。节点a的当前邻居有节点b,节点c和节点e,节点a分别计算数据包d1和它们的相似度的值,即ηb,d1,ηc,d1,ηe,d1,计算得ηa,d=0.80,ηb,d1=0.55,ηc,d1=0.50,ηe,d1=0.32;4)对于当前所有的邻居节点和数据包d1的相似度的值ηb,d1,ηc,d1,ηe,d1,节点a判断它们是否超过阈值δ1,δ1的值为0.55。比较过后发现只有节点b满足条件,对于节点b,节点a则将二元组(b,1)加入到候选节点集合s中;节点a对于节点c和节点e的转发程度函数值为节点a判断转发程度函数值是否超过阈值δ2,δ2的值为0.45,比较过后发现只有节点b满足条件,计算得节点b的副本数值εb=3,并将二元组(c,3)加入到集合s中;5)节点a判断候选节点集合s是否为空,若集合s不为空,广播数据包d1。其方式为节点a先构造数据包d1’,d1’中包含的二元组有(b,1)和(c,3)。二元组的前一个分量代表的是节点的编号,后一个分量代表的是该编号的节点接收数据包的副本数。节点a的当前邻居节点们收到数据包d1'后,判断s中的元素的第一个分量是否含有该节点,节点b接收数据包d1,并设置其副本数为d1;则节点c接收数据包1,并设置其副本数为3;节点e丢弃该数据包d1;6)节点a更新数据包1的副本数k=6的值;7)判断数据包队列中是否还有未发送的数据包,本实例中还有数据包没发送,故跳转至步骤2。实验例2,持有数据包的节点具有1个数据包需要发送,且当前邻居节点有多个:设节点a持有数据包d1,节点a的当前邻居有:节点b,节点c和节点e,节点a的度是20,节点b的度是30,节点c的度是50,节点e的度是60,单位是个/秒。则按照本发明的数据包的分发方式,具体实施方式如下:1)节点a判断自身是否有数据包需要发送,如果有数据包需要发送,则进行下一步,否则,节点a等待直到与其他节点相遇;2)节点a要发送数据包为数据包d1,计算周围邻居节点中含有数据包d1的个数在总的邻居节点中的比例为0.2,没有超过阈值δ3,δ3的值为0.8,将d1的副本数初始值为k=10;3)节点a根据当前邻居的兴趣历史记录表及数据包d1的兴趣向量,计算每个邻居与数据包d1的相似度。节点a的当前邻居有节点b,节点c和节点e,节点a分别计算数据包d1和它们的相似度的值,即ηb,d1,ηc,d1,ηe,d1,计算得ηa,d=0.80,ηb,d1=0.55,ηc,d1=0.50,ηe,d1=0.32;4)对于当前所有的邻居节点和数据包d1的相似度的值ηb,d1,ηc,d1,ηe,d1,节点a判断它们是否超过阈值δ1,δ1的值为0.55。比较过后发现只有节点b满足条件,对于节点b,节点a则将二元组(b,1)加入到候选节点集合s中;对于节点c和节点e,计算节点a和节点c和节点e的转发程度函数值节点a判断转发程度函数值是否超过阈值δ2,δ2的值为0.45,比较过后发现只有节点b满足条件,则根据公式(5)和公式(6)计算节点c的副本数值εb=3,并将二元组(c,3)加入到集合s中。节点a放弃让节点e转发数据包d1;5)节点a判断候选节点集合s是否为空,若集合s不为空,广播数据包d1。其方式为节点a先构造数据包d1’,d1’中包含的二元组有(b,1)和(c,3)。二元组的前一个分量代表的是节点的编号,后一个分量代表的是该编号的节点接收数据包的副本数。节点a的当前邻居节点们收到数据包d1'后,判断s中的元素的第一个分量是否含有该节点,节点b接收数据包d1,并设置其副本数为1;则节点c接收数据包d1,并设置其副本数为3;节点e丢弃该数据包d1;6)节点a更新数据包d1的副本数k=6的值;7)节点a暂时停止发送数据包,等待与其他节点相遇。实验例3,持有数据包的节点具有多个数据包需要发送,且当前邻居节点有1个:设节点a当前时刻三个数据包据需要发送,持有数据包d1是a类型数据包,生存时间0,数据包d2是b类型数据包,生存时间3h和数据包d3是b类型数据包,生存时间1h,生存时间的单位是小时,节点a的当前邻居节点只有节点c,节点a的度是20,节点c的度是50,单位是个/秒。则按照本发明的数据包的分发方式,具体实施方式如下:1)节点a判断自身是否有数据包需要发送,如果有数据包需要发送,则进行下一步,否则,节点a等待直到与其他节点相遇;2)节点a的数据包d1的优先级是2,数据包d2的优先级是0.25,数据包d2的优先级是0.5,节点a按照优先级的大小排序数据包形成数据包队列。节点a要发送的数据包队列中取出优先级最高的数据包d1,计算周围邻居节点中含有数据包d1的个数在总的邻居节点中的比例为0.3,没有超过阈值δ3,δ3的值为0.8。将d1的副本数初始值为k=10;3)节点a根据当前邻居的兴趣历史记录表及数据包d1的兴趣向量,计算邻居节点c与数据包d的相似度。节点a的当前邻居只有节点c,节点a分别计算数据包1和节点c的相似度的值,即ηc,d1,计算得ηa,d=0.80,ηc,d1=0.50;4)对于当前邻居节点c和数据包d1的相似度的值ηc,d1,节点a判断它们是否超过阈值δ1,δ1的值为0.55。比较过后发现只有节点c不满足条件,节点a和节点c的转发程度函数值节点a判断转发程度函数值是否超过阈值δ2,δ2的值为0.45,比较过后发现节点c满足条件,计算得节点b的副本数值εb=3,并将二元组(c,3)加入到集合s中;5)节点a判断候选节点集合s是否为空,若集合s不为空,广播数据包d1,其方式为:节点a先构造数据包d1’,d1’中包含的二元组(c,3),二元组的前一个分量代表的是节点的编号,后一个分量代表的是该编号的节点接收数据包的副本数;节点a的当前邻居节点c收到数据包d1'后,判断s中的元素的第一个分量是否含有该节点,节点b接收数据包d1,并设置其副本数为1,则节点c接收数据包d1,并设置其副本数为3;6)节点a更新数据包d1的副本数k=6的值;7)判断数据包队列中是否还有未发送的数据包,本实例中还有数据包没发送,故跳转至步骤2)。实验例4,持有数据包的节点a具有1个或者多个数据包需要发送,且当前无邻居节点,则节点a等待直到和其他节点相遇。当前第1页12
相关技术
网友询问留言
已有0条留言
- 还没有人留言评论。精彩留言会获得点赞!
1