基于稀疏表示的无参考立体视频质量客观评价方法与流程
本发明涉及视频处理领域,更具体的说,是涉及一种基于稀疏表示的无参考立体视频质量客观评价方法。
背景技术:
在人类感知世界的过程中,视觉信息扮演着很重要的角色。近年来,随着立体拍摄技术和立体显示技术的迅猛发展,越来越多的人开始观看3d电影,立体视频能够带给观众更加真实生动的立体场景,因此具有广阔的发展前景。但是,在立体视频的采集、压缩、传输和显示等过程中,诸多因素会导致视频质量下降。因此,十分有必要提出一种有效的立体视频质量评价算法,这对于提高立体视频处理系统的性能和提升人们的观看体验具有重要意义。
和图像质量评价方法一样,根据对参考视频的依赖程度,立体视频质量客观评价方法可以分为全参考型、半参考型和无参考型。全参考型需要参考视频的原始立体视频信息进行质量评价;半参考型只需要参考原始视频的部分信息;而无参考型不需要参考原始视频的任何信息就可以对立体视频的质量进行评价。并且,多数视频的获取具有随机性,质量评价过程中大多数无法得到无失真的原始立体视频。因此,不依赖于原始视频的无参考立体视频质量评价方法更有研究价值。
技术实现要素:
本发明的目的是为了克服现有技术中的不足,提高立体视频质量评价的鲁棒性,提供一种基于稀疏表示的无参考立体图像质量客观评价方法,以稀疏表示为基础,又充分考虑双视点特性的立体视频质量客观评价方法,具体来说,就是根据人类视觉系统特性模拟大脑中形成的视觉感知图像,以稀疏表示作为工具,对立体视频质量做出更加全面、准确的客观评价。
本发明的目的是通过以下技术方案实现的。
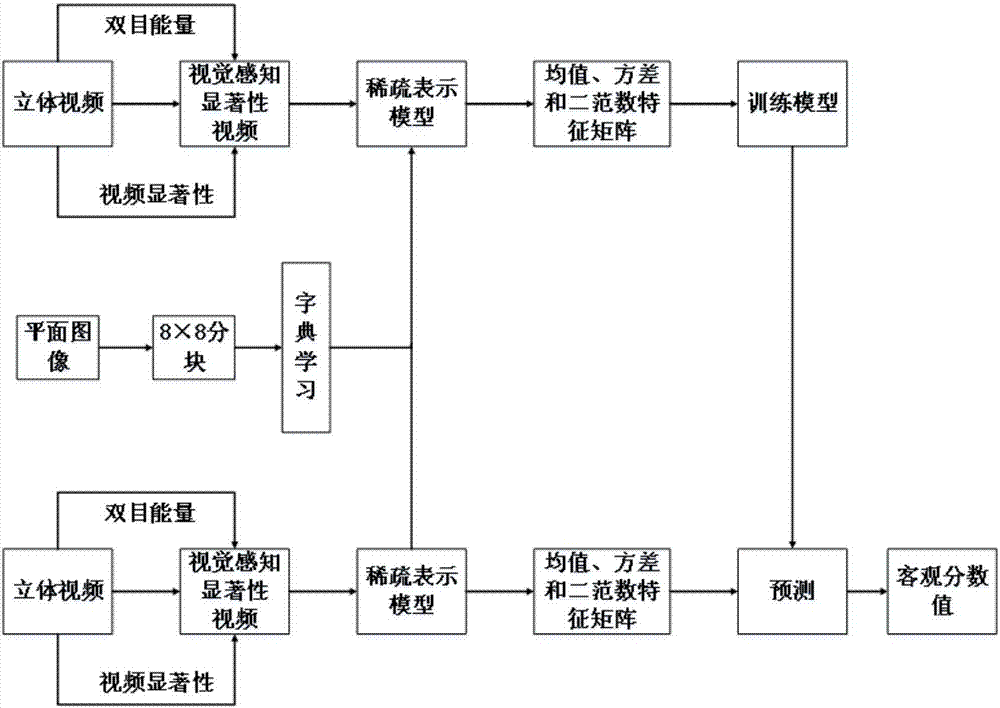
本发明的基于稀疏表示的无参考立体视频质量客观评价方法,每个失真立体视频对由左视点和右视点组成,包括以下步骤:
第一步,对立体视频进行降采样处理,每隔一定帧数取一帧,得到总帧数为l的立体视频对;
第二步,模拟人类视觉特性,对第一步得到的立体视频对的左视点和右视点分别求其单目能量幅度图,得到左视图和右视图的加权因子wl(x,y,n)和wr(x+d,y,n);
第三步,将第一步得到的立体视频对的双视点(tl,tr)进行加权运算,得到一段视频的第n对图像的视觉感知图v(x,y,n),计算公式如下所示:
v(x,y,n)=wl(x,y,n)×tl(x,y,n)+wr(x+d,y,n)×tr((x+d),y,n)
第四步,在合成的视觉感知图v(x,y)上计算视觉感兴趣区域,得到视觉感知显著性图sm(x,y);
第五步,用图像进行字典学习;
第六步,对视觉感知显著性图sm(x,y)进行稀疏表示:首先对视频对的一幅图像进行稀疏表示,得到相应的系数矩阵c,随后对系数矩阵c进行求熵,得到其熵e;
第七步,对帧长为l的sm(x,y)视频的所有图像序列执行第六步,得到稀疏表示后的系数矩阵l×k,最后对系数矩阵在时间方向上进行求均值,方差和二范数操作,得到该视频处理后的系数矩阵(3×k);
第八步,对立体视频库中的每一组失真立体视频对进行第一步至第七步操作,并利用支持向量机(svm)对视频库中的视频的稀疏矩阵及相应的主观评价值(mos)进行训练;具体如下,在视频库中随机选择80%视频对的系数矩阵和mos用于训练,得到相应的训练模型;利用该训练模型对任一立体视频进行质量预测,得到最终的客观预测值。
第二步中左视点能量图和右视点能量图的加权因子wl(x,y,n)和wr(x+d,y,n)的求解过程:
(1)左视点图像中的点p(x,y),在右视点图像中匹配点为p'(x+d,y),d表示对右视点图像进行视差补偿的像素点横坐标差值,这两个像素点的能量分别为:
pi为p周围相邻点,p′i为p′周围相邻点;
最终,依照上式,得到左视图的能量图为gel(x,y)和对应右视图的能量图ger((x+d),y)
(2)左视图和右视图的加权因子wl(x,y)和wr((x+d),y)表示为:
第四步中立体视频的视觉感知显著性图按以下公式获得:
sm(x,y,n)=λ·sm3d(x,y,n)+(1-λ)·smmo(x,y,n)
其中,sm3d(x,y,n)为第n幅图像的3d显著性图,smmo(x,y,n)为运动显著性图,λ为权重系数。
第五步中用图像进行字典学习的方法如下:
选取p幅p×q尺寸无失真的平面参考图像,每个图像分割为8×8的图像块,共有m=[p/8]×[q/8]个小块,其中[k]表示不大于k的最大整数;并将每个8×8的图像块按列排成一列,标记为ri(64×1);这样每个无失真参考图像都转换为(64×1)×m的二维矩阵;p幅无失真平面参考图像通过上述处理,得到一个64×(m×p)的矩阵;根据如下公式,求得相应的字典d。
其中,d是超完备字典矩阵,ai是对应于ri的系数矢量,在求解的过程中,字典的求解利用k-svd算法,迭代次数设置为40次,字典稀疏基(原子)的数目为256。
第六步中对一帧图像进行稀疏表示的方法如下:
(1)利用第五步中得到的字典d,求解一帧图像的稀疏表示系数;此过程中,采用的算法是omp算法,迭代次数为14次;每一图像系数矩阵的大小为256×([p/8]×[q/8])×14的三维矩阵;
(2)对每一次迭代的稀疏系数结果进行求熵操作,得到1×14的一维矩阵;
具体操作如下:
用
对应概率分布函数如下:
根据香农公式,其熵如下:
其中,k是稀疏基的个数,本发明中k=256,按照上述操作,求得一幅图像的稀疏系数熵e,e为1×14的行向量。
与现有技术相比,本发明的技术方案所带来的有益效果是:
本发明所提出的立体视频质量客观评价方法涉及人脑中视觉感知图像序列的合成、3d感兴趣区域的计算,稀疏表示的计算;提出了利用稀疏表示系数表征视觉感知图像,并通过求均值、方差和二范数的方式对稀疏系数进行处理,最终利用训练的方法得到评价结果;以双目视觉特性为基础,通过稀疏表示的方式建立了无参考立体视频质量客观评价模型,利用该模型得到的立体视频质量客观评价结果与主观评价结果具有很高的一致性,能够较为准确的反映立体视频的质量。
附图说明
图1是本发明基于稀疏表示的无参考立体视频质量客观评价方法的流程图。
具体实施方式
下面结合附图对本发明作进一步的描述。
本发明涉及人脑中视觉感知图像序列的合成、3d感兴趣区域的计算,稀疏表示的计算。提出了利用稀疏表示系数表征视觉感知图像,并通过求均值、方差和二范数的方式对稀疏系数进行处理,最终利用训练的方法得到评价结果。
如图1所示,基于稀疏表示的无参考立体视频质量客观评价方法,每个失真立体视频对由左视点和右视点组成,设立体视频对为(tl,tr),包括以下步骤:
第一步:对立体视频进行降采样处理,每隔一定帧数取一帧,得到总帧数为l的立体视频对;其中,可以每八帧取一帧。
第二步:研究双目理论,能量较高的区域包含较多的视觉信息,在视觉感知中占有主导地位。模拟人类视觉特性,对第一步得到的立体视频对的左视点和右视点分别求其单目能量幅度图,得到左视图和右视图的加权因子wl(x,y,n)和wr(x+d,y,n)。
(1)左视点图像中的点p(x,y),在右视点图像中匹配点为p'(x+d,y),d表示对右视点图像进行视差补偿的像素点横坐标差值,这两个像素点的能量分别为:
其中,
pi为p周围相邻点,p′i为p′周围相邻点;
最终,依照上式(1)和(2),得到左视图的能量图为gel(x,y)和对应右视图的能量图ger((x+d),y)。
(2)左视图和右视图的加权因子wl(x,y)和wr((x+d),y)表示为:
第三步:将第一步得到的立体视频对的双视点(tl,tr)进行加权运算,得到一段视频的第n对图像的视觉感知图v(x,y,n),计算公式如下所示:
v(x,y,n)=wl(x,y,n)×tl(x,y,n)+wr(x+d,y,n)×tr((x+d),y,n)(7)
第四步:立体视频信息量较大,人眼很难在较短的时间内捕捉到全部信息,因此提取感兴趣区域十分必要。本步骤在合成的视觉感知图v(x,y)上计算视觉感兴趣区域,得到视觉感知显著性图sm(x,y)。
立体视频的视觉感知显著性图按以下公式获得:
sm(x,y,n)=λ·sm3d(x,y,n)+(1-λ)·smmo(x,y,n)(8)
其中,sm3d(x,y,n)为第n幅图像的3d显著性图,smmo(x,y,n)为运动显著性图,λ为权重系数。
第五步:用图像进行字典学习。选取p幅p×q尺寸无失真的平面参考图像,每个图像分割为8×8的图像块,共有m=[p/8]×[q/8]个小块,其中[k]表示不大于k的最大整数;并将每个8×8的图像块按列排成一列,标记为ri(64×1);这样每个无失真参考图像都可以转换为(64×1)×m的二维矩阵;p幅无失真平面参考图像通过上述处理,可以得到一个64×(m×p)的矩阵;随后,根据如下公式,可以求得相应的字典d。
其中,d是超完备字典矩阵,ai是对应于ri的系数矢量,在求解的过程中,字典的求解利用k-svd算法,迭代次数设置为40次,字典稀疏基(原子)的数目为256。
第六步:对视觉感知显著性图sm(x,y)进行稀疏表示。首先对视频对的一幅图像进行稀疏表示,得到相应的系数矩阵c,随后对系数矩阵c进行求熵,得到其熵e。
对一帧图像进行稀疏表示的方法如下:
(1)利用第五步中得到的字典d,求解一帧图像的稀疏表示系数;此过程中,采用的算法是omp算法,迭代次数为14次;每一图像系数矩阵的大小为256×([p/8]×[q/8])×14的三维矩阵;
(2)对每一次迭代的稀疏系数结果进行求熵操作,得到1×14的一维矩阵;
具体操作如下:
用
对应概率分布函数如下:
根据香农公式,其熵如下:
其中,k是稀疏基的个数,本发明中k=256,按照上述操作,求得一幅图像的稀疏系数熵e,e为1×14的行向量。
第七步,对帧长为l的sm(x,y)视频的所有图像序列执行第六步,得到稀疏表示后的系数矩阵l×k(l×14),最后对系数矩阵在时间方向上进行求均值,方差和二范数操作,得到该视频处理后的系数矩阵(3×k=3×14)。最终,该视频可以表示为的3×14的稀疏系数矩阵。
第八步,对立体视频库中的每一组失真立体视频对进行第一步至第七步操作,并利用支持向量机(svm)对视频库中的视频的稀疏矩阵及相应的主观评价值(mos)进行训练;具体如下,在视频库中随机选择80%视频对的系数矩阵和mos用于训练,得到相应的训练模型;利用该训练模型对任一立体视频进行质量预测,得到最终的客观预测值。
尽管上面结合附图对本发明的功能及工作过程进行了描述,但本发明并不局限于上述的具体功能和工作过程,上述的具体实施方式仅仅是示意性的,而不是限制性的,本领域的普通技术人员在本发明的启示下,在不脱离本发明宗旨和权利要求所保护的范围情况下,还可以做出很多形式,这些均属于本发明的保护之内。
- 还没有人留言评论。精彩留言会获得点赞!