基于深度学习的立体视频质量客观评价方法与流程
本发明涉及视频处理领域,更具体的说,是涉及一种基于深度学习的立体视频质量客观评价方法。
背景技术:
由于3d能够带给观众立体感和更真实的观看体验,因此三维视频技术已经受到工业产品生产商和电子产品消费者的广泛关注。然而,视频的采集、编码压缩、传输、显示以及处理过程中的任何一个环节都有可能引起视频的失真,导致视频质量下降,因此对视频质量评价的研究对推动图像和视频处理技术的发展具有重要意义。
立体视频质量评价方法分为主观质量评价和客观质量评价两种方法,客观评价方法又分为全参考、半参考和无参考型方法。在无参考质量评价方法中,现有的质量评价模型大多是浅层学习网络,如支持向量机、反向传播神经网络等,通过在视频上提取特征并用浅层网络训练和预测视频质量,取得了一定的效果。但是浅层学习网络由单层非线性特征转换层构成,对复杂函数的表征能力有限。由于人类视觉系统感知机理非常复杂,浅层学习网络不能充分表达这一过程,而深度学习网络,如卷积神经网络、深信度网络等,可通过学习深层非线性网络结构实现对复杂函数的表达。因此,近年来越来越多的研究者开始致力于用深度学习网络模型来模拟人类视觉系统的处理机制,从而预测图像和视频的质量。
技术实现要素:
本发明的目的是为了克服现有技术中的不足,提供一种基于深度学习的立体视频质量客观评价方法,结合hog特征、高斯幅度(gm)和高斯拉普拉斯算子(log)的联合分布特征、以及光流特征对立体视频质量的影响,进行立体视频质量评价,提高立体视频客观质量评价的准确性。
本发明的目的是通过以下技术方案实现的。
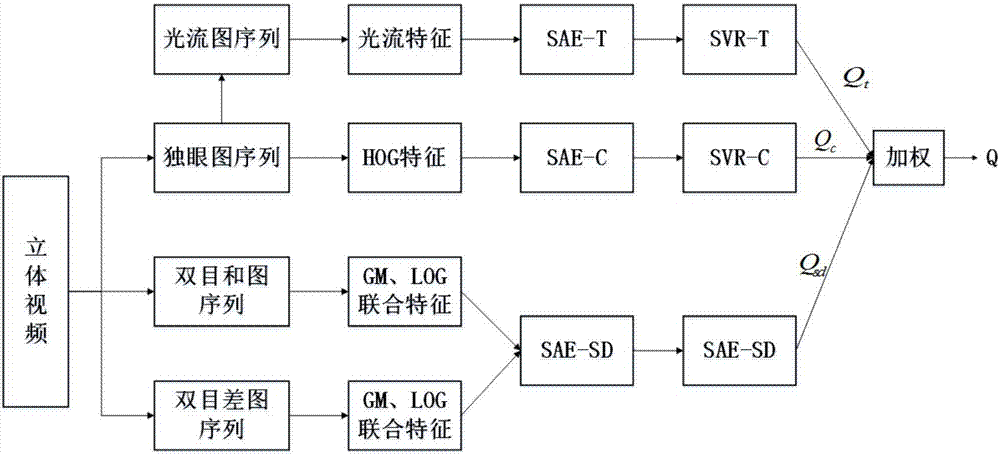
本发明的基于深度学习的立体视频质量客观评价方法,每个失真立体视频对由左视点视频和右视点视频组成,包括以下步骤:
第一步,对组成左视点视频和右视点视频的图像序列分别进行处理,得到独眼图、双目和图及双目差图;
第二步,空域特征提取:在独眼图上提取hog特征,记为
第三步,空域特征提取:分别在双目和图和双目差图上提取高斯幅度(gm)和高斯拉普拉斯算子(log)的联合分布特征,分别记为
第四步,时域特征提取:计算相邻两帧图像的独眼图间的光流场,并在光流场上提取特征作为时域特征ft;
第五步,以上述空域特征、时域特征为基础,对视频的所有图像序列执行第一步到第四步,并在时间方向上求视频每组特征的平均值,分别记为
第六步,在已知主观分数的立体视频库上训练自稀疏编码器模型,通过稀疏自编码器对输入特征进行抽象表达,根据输入的独眼图、双目和图及双目差图、光流场图的特征,分别建立相应的深度学习网络评价模型,分别记为sae-c、sae-sd、sae-t;
第七步,测试阶段:对待测试视频进行第一步到第五步的处理,提取对应的特征,之后利用各自的深度学习网络评价模型分别进行预测,得到视频的独眼图质量客观分数预测值qc、双目和图和双目差图质量客观分数预测值qsd和光流场图质量客观分数预测值qt;
第八步,整合阶段:将独眼图、双目和图及双目差图看作空域质量,将光流场图看作时域质量;将视频的独眼图质量客观分数预测值qc、双目和图和双目差图质量客观分数预测值qsd和光流场图质量客观分数预测值qt按以下公式进行加权整合:
q=α·qs+β·qt(α+β=1)
qs=u·qc+v·qsd(u+v=1)
第一步中:
(1)独眼图定义如下:
ci(x,y)=wl(x,y)·il(x,y)+wr(x+d,y)·ir(x+d,y)
il和ir分别为左视点视频图像和右视点视频图像,d为双目视差值,wl和wr分别为左视点视频图像权重和右视点视频图像权重;左视点视频图像权重和右视点视频图像权重通过gabor滤波器的能量响应幅度得到:
gel和ger分别为左视点视频图像和右视点视频图像的能量响应值;
(2)双目和图的定义如下:
(3)双目差图的定义如下:
di(x,y)=il(x,y)-ir(x,y)
第二步中独眼图的hog特征提取方法为:
(1)首先对图像进行归一化处理:
i(x,y)=i(x,y)γ
i是待处理图像,(x,y)是图像中像素的坐标,γ为归一化参数;
归一化后的独眼图水平方向梯度ghor(x,y)和垂直方向梯度gver(x,y)表示为:
ghor(x,y)=i(x+1,y)-i(x-1,y)
gver(x,y)=i(x,y+1)-i(x,y-1)
独眼图的梯度表示为:
其中,g(x,y)和
(2)将图像的梯度图分解为互不重叠的6×6子块,并统计每个子块的梯度直方图,这里将梯度方向按照公式分为z个部分(z个方向,共z个特征);
其中,sp是角度间的间隔,z是角度间隔的总数量;
随后,将4个相邻的子块组成较大的块,并统计较大的块内的归一化梯度直方图(共4z个特征),最后对一幅图像的所有块的特征求其平均值,即为hog特征:
fhi是每个角度的hog特征,nb是一幅图像中分块的总数量。
第三步中双目和图和双目差图的gm和log的联合分布特征均以下方法提取:
一幅图像i的gm图表示为:
*为卷积符号,σ为尺度参数;
一幅图像i的log图表示为:
li=i*hlog
随后,gm和log联合归一化为
计算每一像素位置的自适应归一化因子
ωx,y是像素(x,y)的局部邻域,w(l,k)是局部邻域每个像素点的权重系数;
最后,gm和log特征图归一化为:
c为常数,设置为0.2,将归一化后的gm和log特征分别量化为m和n个等级,双目和图上提取(m+n)个特征,双目差图上提取(m+n)个特征,总共得到(2m+2n)个特征。
第四步中:
(1)相邻两帧图像的独眼图间的光流场计算公式如下:
根据光流场理论,每个像素都有一个运动矢量,反映相邻帧之间的运动关系,计算视频相邻帧之间的光流场作为运动信息,
光流方程为:
ixvx+iyvy+it=0
其中,ix表示水平方向梯度,iy表示垂直方向梯度,it表示时间方向梯度,u=(vx,vy)t表示光流;
(2)光流场特征提取方法如下:
对于相邻两帧图像之间的矢量光流场,计算以下五个变量:
div(v)=ixvx+iyvy,sha(v)=ixvx-iyvy,
rot(v)=ixvy-iyvx,shb(v)=ixvy+iyvx.
对于以上每个矩阵变量,将其分成不重叠的k×l块,分别计算每个块的熵和二范数,并对一幅光流图的所有块的熵和二范数求平均值,即为时域特征。
第六步中稀疏自编码器的原理为:
c维的输入矢量通过稀疏自编码器为可以转换为c'位的隐层矢量:
h=fθ(r)=s(wr+b)
fθ(r)为编码器,θ={w,b}是编码器设置参数,w是c'×c的权重矩阵,b是c'的偏移矢量,s是输入函数,r是输入矢量;
隐层的输出再通过解码器反向传播到输入层,形成重建输入层:
其中,gθ'(h)为解码器,θ′={w′,b′}是解码器设置参数;通过比较原输入层h和重建输入层
重建误差表示为:
i表示第i个样本,n表示样本的总数量,l2为均方损失函数:
与现有技术相比,本发明的技术方案所带来的有益效果是:
本发明综合考虑独眼图的hog特性、双目和图和双目差图的高斯幅度(gm)和高斯拉普拉斯算子(log)的联合分布特征和基于光流算法的时域特征,将提取的特征向量输入到包含三个隐层的稀疏自编码器中,建立特征和主观分数的回归模型,根据已建立的回归模型,预测输入视频的各部分质量分数,最后对各部分质量分数进行加权作为最终的质量分数;将深度学习应用于立体视频质量客观评价方法之中,得到的立体视频质量客观评价结果与主观结果具有很高的一致性,极大的提高立体视频客观质量评价的性能。
附图说明
图1是本发明基于深度学习的立体视频质量客观评价方法的流程图。
具体实施方式
下面结合附图对本发明作进一步的描述。
本发明主要包括特征提取和训练测试两个阶段。首先在特征提取阶段,主要提取独眼图(cyclopeanimage,ci)的hog特征、双目和图(summationimage,si)和双目差图(differenceimage,di)的高斯幅度(gm)和高斯拉普拉斯算子(log)的联合分布特征,和基于光流算法的时域特征;在训练预测阶段,首先将提取的特征向量输入到包含3个隐层的稀疏自编码器中,建立特征和主观分数的回归模型;根据已建立的回归模型,预测输入视频的各部分质量分数。最后对各部分质量分数进行加权作为最终的质量分数。具体技术方案如下:
如图1所示,基于深度学习的立体视频质量客观评价方法,每个失真立体视频对由左视点视频和右视点视频组成,设失真视频对为(tl,tr),包括以下步骤:
第一步,对组成左视点视频和右视点视频的图像序列il和ir分别进行处理,得到独眼图、双目和图及双目差图。
(1)独眼图定义如下:
ci(x,y)=wl(x,y)·il(x,y)+wr(x+d,y)·ir(x+d,y)(1)
il和ir分别为左视点视频图像和右视点视频图像,d为双目视差值,wl和wr分别为左视点视频图像权重和右视点视频图像权重;左视点视频图像权重和右视点视频图像权重通过gabor滤波器的能量响应幅度得到:
gel和ger分别为左视点视频图像和右视点视频图像的能量响应值;
(2)双目和图的定义如下:
(3)双目差图的定义如下:
di(x,y)=il(x,y)-ir(x,y)(5)
第二步,空域特征提取:在独眼图上提取hog特征,记为
独眼图的hog特征提取方法为:
(1)首先对图像进行归一化处理:
i(x,y)=i(x,y)γ(6)
i是待处理图像,(x,y)是图像中像素的坐标,γ为归一化参数。
归一化后的独眼图水平方向梯度ghor(x,y)和垂直方向梯度gver(x,y)可表示为:
ghor(x,y)=i(x+1,y)-i(x-1,y)(7)
gver(x,y)=i(x,y+1)-i(x,y-1)(8)
独眼图的梯度可表示为:
其中,g(x,y)和
(2)将图像的梯度图分解为互不重叠的6×6小子块,并统计每个小子块的梯度直方图,这里将梯度方向按照公式分为z个部分(z个方向,共z个特征);
其中,sp是角度间的间隔,z是角度间隔的总数量;
随后,将4个相邻的子块组成较大的块,并统计较大的块内的归一化梯度直方图(共4z个特征),最后对一幅图像的所有块的特征求其平均值,即为hog特征:
fhi是每个角度的hog特征,nb是一幅图像中分块的总数量。若z=9,则hi=1,2,3,...,36。
第三步,空域特征提取:分别在双目和图和双目差图上提取高斯幅度(gm)和高斯拉普拉斯算子(log)的联合分布特征,分别记为
双目和图和双目差图的gm和log的联合分布特征均以下方法提取:
一幅图像i的gm图可表示为:
*为卷积符号,σ为尺度参数。
一幅图像i的log图可表示为:
li=i*hlog(16)
随后,gm和log联合归一化为:
计算每一像素位置的自适应归一化因子:
ωx,y是像素(x,y)的局部邻域,w(l,k)是局部邻域每个像素点的权重系数。
最后,gm和log特征图可归一化为:
c为常数,设置为0.2,将归一化后的gm和log特征分别量化为m和n个等级,双目和图上提取(m+n)个特征,双目差图上提取(m+n)个特征,总共得到(2m+2n)个特征。这里可设置m=n=5,因此,双目和图上提取10个特征,双目差图上提取10个特征,总共得到20个特征。
第四步,时域特征提取:计算相邻两帧图像的独眼图间的光流场,并在光流场上提取特征作为时域特征ft。
(1)相邻两帧图像的独眼图间的光流场计算公式如下:
根据光流场理论,每个像素都有一个运动矢量,可以反映相邻帧之间的运动关系,计算视频相邻帧之间的光流场作为运动信息。
光流方程为:
ixvx+iyvy+it=0(22)
其中,ix表示水平方向梯度,iy表示垂直方向梯度,it表示时间方向梯度,u=(vx,vy)t表示光流。随后在光流场上提取时域统计特征,用来估计时域特性失真程度。
(2)光流场特征提取方法如下:
对于相邻两帧图像之间的矢量光流场,计算以下五个变量:
div(v)=ixvx+iyvy(24)
rot(v)=ixvy-iyvx(25)
sha(v)=ixvx-iyvy(26)
shb(v)=ixvy+iyvx(27)
对于以上每一个矩阵变量,将其分成不重叠的k×l块,分别计算每个块的熵和二范数,并对一幅光流图的所有块的熵和二范数求平均值,即为时域特征。
第五步,以上述空域特征、时域特征为基础,对一段视频的所有图像序列执行第一步到第四步,并在时间方向上求视频每组特征的平均值,分别记为
其中,uj为第j个特征在一段视频的所有图像序列上的平均值,b为视频的总帧数,di,j为第j个特征的在第i帧图像上的值。
第六步,在已知主观分数的立体视频库上训练自稀疏编码器模型,通过稀疏自编码器对输入特征进行抽象表达,根据输入的独眼图、双目和图及双目差图、光流场图的特征,分别建立相应的深度学习网络评价模型,分别记为sae-c、sae-sd、sae-t。
稀疏自编码器的原理为:
c维的输入矢量通过稀疏自编码器为可以转换为c'位的隐层矢量:
h=fθ(r)=s(wr+b)(29)
fθ(r)为编码器,θ={w,b}是编码器设置参数,w是c'×c的权重矩阵,b是c'的偏移矢量,s是输入函数,r是输入矢量。
隐层的输出再通过解码器反向传播到输入层,形成重建输入层:
其中,gθ'(h)为解码器,θ′={w′,b′}是解码器设置参数;通过比较原输入层h和重建输入层
重建误差可表示为:
i表示第i个样本,n表示样本的总数量,l2为均方损失函数:
第七步,测试阶段:对待测试视频进行第一步到第五步的处理,提取对应的特征,之后利用各自的深度学习网络评价模型分别进行预测,得到视频的独眼图质量客观分数预测值qc、双目和图和双目差图质量客观分数预测值qsd和光流场图质量客观分数预测值qt。
第八步,各部分质量分数的整合阶段:将独眼图、双目和图及双目差图看作空域质量,将光流场图看作时域质量,因此,将视频的独眼图质量客观分数预测值qc、双目和图和双目差图质量客观分数预测值qsd和光流场图质量客观分数预测值qt按以下公式进行加权整合:
q=α·qs+β·qt(α+β=1)(33)
其中,
qs=u·qc+v·qsd(u+v=1)(34)
α,β,u,v均为权重系数。
尽管上面结合附图对本发明的功能及工作过程进行了描述,但本发明并不局限于上述的具体功能和工作过程,上述的具体实施方式仅仅是示意性的,而不是限制性的,本领域的普通技术人员在本发明的启示下,在不脱离本发明宗旨和权利要求所保护的范围情况下,还可以做出很多形式,这些均属于本发明的保护之内。
- 还没有人留言评论。精彩留言会获得点赞!