从数据流解码具有变换系数级别的多个变换系数的装置的制作方法
本申请是申请号为201380015410.7的中国专利申请的分案申请。本发明涉及变换系数(比如图片的变换系数区块的变换系数)编码。
背景技术:
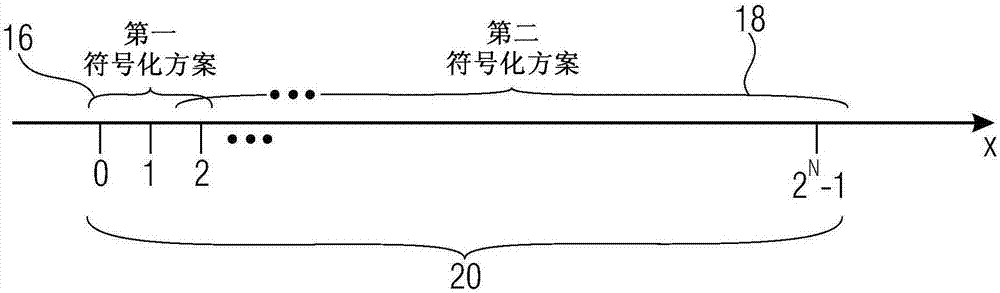
:在基于区块的图像和/或视频编解码器中,图片或帧以区块为单位进行编码。其中,基于变换的编解码器使图片或帧的区块进行变换以便获得变换系数区块。例如,图片或帧可以预测地进行编码,其中预测残差以区块为单位进行变换编码,然后使用熵编码对由此产生的这些变换区块的变换系数的变换系数级别进行编码。为了提高熵编码效率,使用上下文以便精确估计要编码的变换系数级别的符号的概率。然而,近年来,强加到图片和/或图像编解码器上的需求日益增长。除了亮度和色度分量之外,编解码器有时必须传递深度图、透明(transparity)值等。而且,变换系数尺寸在越来越大的区间内是可变的。由于这些多样性,编解码器具有越来越多的具有不同函数的不同上下文,以便根据已经编码的变换系数确定上下文。以更适度的复杂度实现高压缩率的不同可能性是尽可能精确地将符号化方案调整为系数的统计数字。然而,为了执行紧密适应实际统计数字,还强制考虑各种因素,由此需要大量不同的符号化方案。因此,需要保持变换系数编码的复杂度低,然而同时保持实现高编码效率的可能性。技术实现要素:本发明的目的是提供此变换系数编码方案。该目的通过待决独立权利要求的主题实现。根据本发明的一个方面,一种用于将具有变换系数级别的多个变换系数编码成流的装置包括:符号化器,被配置为:如果当前变换系数的变换系数级别在第一级别区间内,则根据第一符号化方案将当前变换系数映射到一个或多个符号的第一集合上,并且如果当前变换系数的变换系数级别在第二级别区间内,则根据第二符号化方案将当前变换系数映射到第一级别区间的最大级别根据第一符号化方案映射到其上的符号的第二集合以及依据第二级别区间内的当前变换系数的变换系数级别的位置的符号的第三集合的组合上,所述第二符号化方案是根据符号化参数可参数化的。进一步地,所述装置包括上下文自适应熵编码器,被配置为如果当前变换系数的变换系数级别在第一级别区间内,则将一个或多个符号的第一集合熵编码成数据流,并且如果当前变换系数的变换系数级别在第二级别区间内,则将一个或多个符号的第二集合熵编码成数据流,其中上下文自适应熵编码器被配置为,在将一个或多个符号的第二集合的至少一个预定符号熵编码成数据流的过程中,经由通过函数参数可参数化的函数依据先前编码的变换系数使用上下文,其中函数参数被设置为第一设定。进一步地,所述装置包括符号化参数确定器,被配置为如果当前变换系数的变换系数级别在第二级别区间内,则经由函数依据先前编码的变换系数确定用于映射到符号的第三集合上的符号化参数,其中函数参数被设置为第二设定。插入器被配置为如果当前变换系数的变换系数级别在第二级别区间内,则将符号的第三集合插入到数据流中。根据本发明的另一个方面,一种用于将不同变换区块的各自具有变换系数级别的多个变换系数编码成数据流的装置包括:符号化器,被配置为根据符号化方案针对当前变换系数将变换系数级别映射到符号的集合上,所述符号化方案是根据符号化参数可参数化的;插入器,被配置为将当前变换系数的符号的集合插入到数据流中;以及符号化参数确定器,被配置为,经由通过函数参数可参数化的函数依据先前处理的变换系数为当前变换系数确定符号化参数,其中插入器、符号化器和符号化参数确定器被配置为依次处理不同变换区块的变换系数,其中函数参数依据当前变换系数的变换区块的尺寸、当前变换系数的变换区块的信息分量类型和/或当前变换系数位于变换区块内的频率部分而改变。本发明的思想是将相同函数用于上下文对先前编码/解码的变换系数的依赖性和符号化参数对先前编码/解码的变换系数的依赖性。在变换系数从空间上排列在变换区块中的情况下,甚至可以相对于变换区块的不同变换区块尺寸和/或频率部分使用利用具有不同函数参数的相同函数。该思想的另一个变型是,针对当前变换系数的变换区块的不同尺寸、当前变换系数的变换区块的不同信息分量类型和/或当前变换系数位于变换区块内的不同频率部分,将相同函数用于符号化参数对先前编码/解码的变换系数的依赖性。附图说明本发明的详细且有利方面是独立权利要求的主题。而且,下面参照图描述本发明的优选实施例,其中:图1示出了根据本发明实施例的包括要编码的变换系数的变换系数区块的示意图并图示了可参数化函数共同用于上下文选择和符号化参数确定;图2示出了使用两个级别区间内的两个不同方案的变换系数级别的符号化概念的示意图;图3示出了在两个不同上下文的可能变换系数级别上限定的两条出现概率曲线的示意图;图4示出了根据实施例的用于编码多个变换系数的装置的框图;图5a和图5b示出了根据不同实施例的产生的数据流结构的示意图;图6示出了根据实施例的图片编码器的框图;图7示出了根据实施例的用于解码多个变换系数的装置的框图;图8示出了根据实施例的图片解码器的框图;图9示出了根据实施例的变换系数区块的示意图以便图示扫描和模板;图10示出了根据进一步实施例的用于解码多个变换系数的装置的框图;图11a和图11b示出了组合整个区间范围的局部区间内的两个或三个不同方案的变换系数级别的符号化概念的示意图;图12示出了根据进一步实施例的用于编码多个变换系数的装置的框图;以及图13示出了变换系数区块的示意图以便根据进一步实施例图示在子区块之间限定的子区块顺序之后的变换系数区块之间的扫描顺序,变换系数区块被划分为子区块,以便图示设计上下文选择和符号化参数确定的可参数化函数的另一个实施例。具体实施方式针对下面的描述,注意,相同参考符号用于不止一个图中出现的元件的图。因此,此元件针对一个图的描述应同样适用于描述出现该元件的另一个图。而且,下面提出的描述初步假设要编码的变换系数二维布置以便形成变换区块比如图的变换区块。然而,本申请不局限于图像和/或视频编码。相反,要编码的变换系数可选地可以是一维变换的变换系数,比如在音频编码等中使用的。为了解释下面进一步描述的实施例面临的问题,以及下面进一步描述的实施例克服这些问题的方式,初步参照图1-3,其示出了变换区块的变换系数的实例及熵编码的一般方式,然后通过随后解释的实施例改善。图1示例性地示出了变换系数12的区块10。在本实施例中,变换系数二维布置。特别地,变换系数示例性地示为规则地布置成列和行,但是也可能存在另一个二维布置。产生变换系数12或变换区块10的变换可以是dct或将图片的(变换)区块,例如空间布置值的一些其他区块分解成不同空间频率的分量的一些其他变换。在图1的实例中,变换系数12二维布置成列i和行j以便对应于沿不同空间方向x,y比如彼此垂直的方向测量的频率fx(i),fy(j)的频率对(fx(i),fy(j)),其中fx/y(i)<fx/y(i+1)并且(i,j)是变换区块10中的各个分量的位置。通常,对应于更低频率的变换系数12与对应于更高频率的变换系数相比具有更高变换系数级别。因此,通常,变换区块10的最高频率分量附近的许多变换系数被量化为零并且不必进行编码。相反,扫描顺序14可以在变换系数12之间限定,其按顺序(即(i,j)→k)将二维布置的变换系数12(i,j)一维布置成系数序列,使得变换系数级别很可能具有沿该顺序单调递减的趋势,即,系数k的系数级别很可能大于系数k+1的系数级别。例如,锯齿或光栅扫描可以在变换系数12之间限定。根据扫描,区块10可以从例如dc分量变换系数(左上系数)至最高频率变换系数(右下系数)或从最高频率变换系数(右下系数)至dc分量变换系数(左上系数)对角线地扫描。可选地,在刚才提及的极端分量变换系数之间的变换系数可以使用逐行或逐列扫描。如下面进一步所述,在编码变换区块的过程中,按照扫描顺序14的最后非零变换系数l的位置可以首先被编码成数据流,然后只编码从dc变换系数沿扫描路径14至最后非零变换系数l(任选在此方向上或在相反方向上)的变换系数。变换系数12具有可以有符号或无符号的变换系数级别。例如,变换系数12可能已经通过前述变换获得,随后量化到可能量化值的集合上,每个量化值都与各个变换系数级别相关联。用于量化变换系数,即将变换系数映射到变换系数级别上的量化函数可以是线性的或可以是非线性的。换句话说,每个变换系数12具有可能级别的区间范围之外的变换系数级别。图2例如示出了变换系数级别x限定在级别范围【0,2n-1】内的实例。根据可选实施例,区间范围可能不存在上限。而且,图2仅图示了正变换系数级别,但是其也可以有符号。关于变换系数12的符号及其编码,应该注意的是,不同可能性相对于下面阐述的所有实施例存在以便编码这些符号,并且所有可能性都应该在这些实施例的范围内。针对图2,这意味着变换系数级别的范围区间可能也不存在下限。在任何情况下,为了编码变换系数12的变换系数级别,使用不同符号化方案以便覆盖范围区间20的不同部分或区间16,18。更确切地说,第一级别区间16内的变换系数级别,等于第一级别区间16的最大级别的除外,可以根据第一符号化方案简单符号化到一个或多个符号的集合上。然而,位于第二级别区间18内的变换系数级别被映射到第一和第二符号化方案的符号集合的组合上。如稍后所注意的,第三和进一步区间因此可以遵循第二区间。如图2中所示,第二级别区间18位于第一级别区间16上方,但在第一级别区间16的最大级别处与后者重叠,在图2的实例中为2。针对位于第二级别区间18内的变换系数级别,将各个级别映射到对应于符合第一符号化方案的第一级别区间的最大级别的第一符号集合和依据符合第二符号化方案的第二级别区间内的变换系数级别的位置的第二符号集合的组合上。换句话说,第一符号化方案16将第一级别区间16覆盖的级别映射到第一符号序列的集合上。请注意,第一符号化方案的符号序列的集合内的符号序列的长度在二进制字母表的情况下并在仅覆盖两个变换系数级别比如0和1的第一级别区间16的情况下甚至可以仅为一个二进制符号。根据本申请的实施例,第一符号化方案是区间16内的级别的截断的一元二值化。在二进制字母表的情况下,符号可以被称为仓(bin)。如下面更详细所述,第二符号化方案将第二级别区间18内的级别映射到不同长度的第二符号序列的集合上,其中第二符号化方案是根据符号化参数可参数化的。第二符号化方案可以将区间18内的级别,即x-第一区间的最大级别,映射到具有莱斯参数(riceparameter)的莱斯码(ricecode)上。特别地,第二符号化方案18可以经配置使得符号化参数改变第二方案的符号序列的长度从第二级别区间18的下限增加至其上限的速率。显然,符号序列的增加长度在变换系数要编码成的数据流内消耗更多的数据速率。一般来说,如果某个级别映射到其上的符号序列的长度与当前要编码的变换系数级别假设各个级别的实际概率相关,则是优选的。自然地,后一说法对第二级别区间18外第一级别区间16内的级别有效或总体来说对第一符号化方案有效。特别地,如图3所示,变换系数通常示出了出现某些变换系数级别的某些统计数字概率。图3示出了使各个变换系数级别实际由讨论中的变换系数假设的概率关联到每个可能变换系数级别x的图。更确切地说,图3示出了两个此相关性或概率曲线,即针对不同上下文的两个系数。也就是说,图3假设根据其上下文区别的变换系数比如相邻变换系数的变换系数值所确定的。根据上下文,图3示出了使概率值与每个变换系数级别相关联的概率曲线可以依据讨论中的变换系数的上下文。根据下述实施例,第一符号化方案16的符号序列的符号以上下文自适应方式进行熵编码。也就是说,上下文与符号相关联,并且与所选上下文相关联的字母概率分布用于对各个符号进行熵编码。第二符号化方案的符号序列的符号直接或使用固定字母概率分布比如字母表的所有成员同样根据其同样可能的相同概率分布插入到数据流中。必须适当选择用于对第一符号化方案的符号进行熵编码的上下文以便允许所估计的字母概率分布很好的适应实际字母的统计数字。也就是说,每当编码/解码具有该上下文的符号时,熵编码方案可以被配置为更新上下文字母概率分布的当前估计,由此逼近实际字母统计数字。如果适当选择上下文,即足够精细,则该逼近更快,但没有太多不同的上下文以便避免符号与某些上下文过于罕见的相关联。同样地,系数的符号化参数应该根据先前编码/解码的系数来选择以便尽可能近地逼近实际字母统计数字。太精细的多样化在这里不是关键问题,因为符号化参数根据先前编码/解码系数直接确定,但是该确定应紧密对应于第二区间18内的概率曲线对先前编码/解码系数的依赖性的相关性。如下面更详细所述,下面进一步所述的编码变换系数的实施例的优点在于使用常用函数以便实现上下文自适应性和符号化参数确定。选择正确上下文如上所述是重要的以便实现高编码效率或压缩率,并且这同样适用于符号化参数。下面描述的实施例允许通过保持实例化对先前编码/解码系数的依赖性的开销较低来实现该目的。特别地,本申请的发明人发现一种发现一方面实现对先前编码/解码系数的依赖性与另一方面减少实例化各个上下文依赖性的专用逻辑的数量之间的良好折中。图4示出了根据本发明实施例的用于将具有变换系数级别的多个变换系数编码成数据流的装置。要注意,在以下描述中,假设符号字母表为二进制字母表,但是该假设如上所述对本发明来说不是关键的,因此所有解释都应解释为扩展到其他符号字母表来说同样是说明性的。图4的装置用于将在输入端30处输入的多个变换系数编码成数据流32。装置包括符号化器34、上下文自适应熵编码器36、符号化参数确定器38和插入器40。符号化器34具有连接至输入端30的输入并被配置为以上文针对图2描述的方式将当前输入其输入的当前变换系数映射到符号上。也就是说,符号化器34被配置为如果当前变换系数的变换系数级别x在第一级别区间16内,则根据第一符号化方案将当前变换系数映射到一个或多个符号的第一集合上,并且如果当前变换系数的变换系数级别在第二级别区间18内,则根据第二符号化方案将当前变换系数映射到第一级别区间16的最大级别根据第一符号化方案映射到其上的符号的第二集合以及依据第二级别区间18内的当前变换系数的变换系数级别的位置的符号的第三集合的组合上。换句话说,符号化器34被配置为,在当前变换系数的变换系数级别在第一级别区间16内而在第二级别区间外的情况下,将当前变换系数映射到第一符号化方案的第一符号序列上,在当前变换系数的变换系数级别在第二级别区间内的情况下,将当前变换系数映射到第一级别区间16的第一符号化方案的符号序列和第二符号化方案的符号序列的组合上。符号化器34具有两个输出端,即第一符号化方案的符号序列的输出端和第二符号化方案的符号序列的输出端。插入器40具有用于接收第二符号化方案的符号序列42的输入端并且上下文自适应熵编码器36具有用于接收第一符号化方案的符号序列44的输入端。进一步地,符号化器34具有用于从符号化参数确定器38的输出端接收符号化参数46的参数输入端。上下文自适应熵编码器36被配置为将第一符号序列44的符号熵编码成数据流32。插入器40被配置成将符号序列42插入到数据流32中。一般来说,熵编码器36和插入器40依次扫描变换系数。显然,插入器40仅针对变换系数操作,其变换系数级别位于第二级别区间18内。然而,如下面更详细所述,存在限定熵编码器36和插入器40的操作之间的顺序的不同可能性。根据第一实施例,图4的编码装置被配置为在单次扫描中扫描变换系数,使得在熵编码器将与相同变换系数有关的第一符号序列44编码成数据流32之后并在熵编码器将与成一条直线的下一个变换系数有关的符号序列44熵编码成数据流32之前,插入器40将变换系数的符号序列42插入到数据流32中。根据可选实施例,装置使用两次扫描,其中在第一次扫描中,上下文自适应熵编码器36针对每个变换系数依次将符号序列44编码成数据流32,插入器40然后插入变换系数级别位于第二级别区间18内的变换系数的符号序列42。甚至可能存在更复杂的方案,例如,上下文自适应熵编码器36据此使用几次扫描以便将第一符号序列44的各个符号编码成数据流32,比如继第二扫描中的序列44的第二符号或仓之后的第一扫描中的第一符号或仓。正如上面已经指出的,上下文自适应熵编码器36被配置为以上下文自适应的方式将符号序列44的至少一个预定符号熵编码成数据流32。例如,上下文自适应性用于符号序列44的所有符号。可选地,上下文自适应熵编码器36可以限制第一位置处与符号的上下文自适应性以及第一符号化方案的符号序列,或第一和第二,或第一至第三位置等。如上所述,对于上下文自适应性,编码器36通过存储并更新每个上下文的字母概率分布估计来管理上下文。每当编码某个上下文的符号时,当前存储的字母概率分布估计使用该符号的实际值更新,由此逼近此上下文的符号的实际字母统计数字。同样地,符号化参数确定器38被配置为依据先前编码的变换系数确定第二符号化方案的符号化参数46及其符号序列42。更确切地说,上下文自适应熵编码器36经配置使得其经由通过函数参数可参数化的函数依据先前编码的变换系数针对当前变换系数使用或选择上下文,其中函数参数被设置为第一设定,同时符号参数确定器38被配置为经由相同函数依据先前编码的变换系数确定符号化参数,所述函数参数被设置为第二设定。所述设定可以不同,但是然而,因为符号化参数确定器38和上下文自适应熵编码器36使用相同函数,所以可以减少逻辑开销。函数参数只可以在一方面熵编码器36的上下文选择与另一方面符号化参数确定器38的符号化参数确定之间不同。就涉及对先前编码的变换系数的依赖性而言,应该注意,该依赖性局限于这些先前编码的变换系数已经被编码成数据流32的程度。例如,想象一下,此先前编码的变换系数位于第一级别区间18内,但其符号序列42尚未插入到数据流中。在此情况下,符号化参数确定器38和上下文自适应熵编码器36仅仅从此先前编码的变换系数的第一符号序列44了解到其位于第二级别区间18内。在此情况下,第一级别区间16的最大级别可以充当该先前编码的变换系数的代表。在这范围内,应广义理解“对先前编码的变换系数”的依赖性为包含“对关于先前编码成/插入到数据流32中的其他变换系数的信息”的依赖性。进一步地,在最后非零系数l位置之外的变换系数可以被推断为零。为了完成图4的描述,熵编码36和插入器40的输出端被示为经由开关50连接至装置的共用输出端48,相同的连接性存在于一方面符号化参数确定器38和上下文自适应熵编码器36的先前插入/编码信息的输入端与另一方面熵编码器36和插入器40的输出端之间。开关50按照上文提及的顺序针对将一次、两次或多次扫描用于编码变换系数的各种可能性连接输出端48与熵编码器36和插入器40的输出端中的任意一个。为了更具体地解释可参数化函数针对上下文自适应熵编码器36和符号化参数确定器38的共同用途,参照图1。被熵编码器36和符号化参数确定器38共同使用的函数在图1中用52表示,即g(f(x))。该函数适用于先前编码的变换系数的集合,如上文所解释的,其可以限定为包含具有相对于当前系数的某空间关系的先前编码系数。该函数的特定实施例将在下面更详细阐述。一般来说,f是将先前编码系数级别的集合结合成标量的函数,其中g是检查标量位于哪个区间中的函数。换句话说,函数g(f(x))适用于先前编码的变换系数的集合x。在图1中,用小十字表示的变换系数12,例如当前变换系数,和带阴影线的变换系数12表示函数52适用的变换系数的集合x以便获得符号化参数46和对当前变换系数x的上下文进行索引的熵上下文索引54。如图1中所示,可以使用限定当前变换系数周围的相对空间布置的局部模板以便确定所有先前编码的变换系数范围之外的相关先前编码的变换系数的集合x。如在图1中可以看出,模板56可以包含当前变换系数下方和右边的紧密相邻的变换系数。通过如此选择模板,扫描410的一个对角线上的变换系数的符号序列42和44可以并行编码,因为对角线上的变换系数都没有落入相同对角线上的另一个变换系数的模板56中。自然地,可以发现类似模板用于逐行和逐列扫描。为了提供共同使用的函数g(f(x))和对应函数参数的更具体实例,在下文中,使用各个公式提供这些实例。特别地,图4的装置可以经配置使得限定一方面先前编码的变换系数的集合x与另一方面对上下文和符号化参数46进行索引的上下文索引编号54之间的关系的函数52可以为:g(f(x)),其中且其中且其中t和以及任选wi形成函数参数,x={x1,...,xd},xi中i∈{1...d}表示先前解码的变换系数i,wi是加权值,其中每一个可以等于一或不等于一,并且h是常数或xi的函数。因此,g(f(x))位于[0,df]内。如果g(f(x))用于限定与至少一个基本上下文索引偏移量数ctxbase一起总计的上下文索引偏移量数ctxoffset,则由此产生的上下文索引ctx=ctxbase+ctxoffset的值范围为[ctxbase;ctxbase+df]。每当提出上下文的不同集合用于对符号序列44的符号进行熵编码时,以不同方式选择ctxbase使得[ctxbase,1;ctxbase+df]不与[ctxbase,2;ctxbase+df]重叠。例如,针对以下项为真·属于不同尺寸的变换区块的变换系数;·属于不同信息分量类型比如深度、亮度、色度等的变换区块的变换系数;·属于相同变换区块的不同频率部分的变换系数。如前所述,符号化参数可以是莱斯参数k。也就是说,区间16内的(绝对)级别,即x,其中x+m=x(其中m是区间16的最大级别,x是(绝对)变换系数级别),可以映射到具有前缀和后缀的仓串上,前缀是的一元码,后缀是x·2-k的余数的二进制码。df还可以形成函数参数的一部分。d也可以形成函数参数的一部分。比如上下文选择与符号化参数确定之间的函数参数的差只需要t、df(如果形成函数参数的一部分)、或d(如果形成函数参数的一部分)中的任意一个的一个差。如上所述,索引i可以对模板56内的变换系数12进行索引。在各个模板位置位于变换区块外的情况下,xi可以设为零。进一步地,上下文自适应熵编码器36可以经配置使得来自先前编码的变换系数的上下文的依赖性经由函数:使得在变换系数级别在第一级别区间16内的情况下,xi等于先前编码的变换系数i的变换系数级别,并在先前编码的变换系数i的变换系数级别在第二级别区间18内的情况下等于第一级别区间16的最大级别,或者使得xi等于先前编码的变换系数i的变换系数级别,与先前编码的变换系数i的变换系数级别在第一或第二级别区间内无关。就涉及符号化参数确定器而言,同样可以经配置使得,在确定符号化参数的过程中,xi等于先前编码的变换系数i的变换系数级别,与先前编码的变换系数i的变换系数级别在第一或第二级别区间内无关。装置还可以经配置使得适用于任何情况。装置还可以经配置使得h=|xi|-t。在进一步实施例中,装置可以被配置为依据所述变换系数相对于当前变换系数的相对空间布置从空间上确定先前编码的变换系数,即基于当前变换系数的位置周围的模板。装置还可以被配置为沿预定扫描顺序14确定变换系数区块10的变换系数之中的最后非零变换系数l的位置,并将关于位置的信息插入到数据流32中,其中多个变换系数包含从最后非零变换系数l至预定扫描顺序的开始的变换系数,即dc分量变换系数。在进一步实施例中,符号化器34可以被配置为使用用于符号化最后变换系数l的修改后的第一符号化方案。根据修改后的第一符号化方案,仅可以映射第一级别区间16内的非零变换系数级别,同时推定零级别不应用于最后变换系数l。例如,截断的一元二值化的第一仓可以针对系数l抑制。上下文自适应熵编码器可以被配置为使用独立于用于对不同于最后非零变换系数的一个或多个符号的第一集合进行熵编码的上下文的用于对最后非零变换系数的一个或多个符号的第一集合进行熵编码的上下文的单独集合。上下文自适应熵编码器可以按照从变换系数区块的最后非零变换系数至dc变换系数的相反扫描顺序遍历多个变换系数。这同样可以或不可以应用于第二符号序列42。装置还可以被配置为在两次扫描中将多个变换系数编码成数据流32,其中上下文自适应熵编码器36可以被配置为按照对应于变换系数的第一扫描的顺序将变换系数的符号序列44熵编码成数据流32,其中插入器40被配置为随后按照对应于在变换系数的第二扫描内出现具有第二级别区间18内的变换系数级别的变换系数的顺序将具有第二级别区间18内的变换系数级别的变换系数的符号序列42插入到数据流32中。由此产生的数据流32的实例在图5a中示出:其可以包括任选在关于l的位置的信息57中,继呈熵编码形式的符号序列42(呈上下文自适应熵编码形式的至少一些)之后以及进一步继直接或使用例如旁通模式(相等的概率字母)插入的符号序列44之后。在进一步实施例中,装置可以被配置为在一次扫描中依次将多个变换系数编码成数据流32,其中上下文自适应熵编码器36和插入器40被配置为,针对按照一次扫描的扫描顺序的每个变换系数,在继上下文自适应熵编码器将符号序列44熵编码成数据流32之后立即将具有第二级别区间18内的变换系数级别的各个变换系数的符号序列42插入到数据流32中,同时形成相同的变换系数映射到其上的组合,使得符号序列42被穿插入变换系数的符号序列44之间的数据流32。结果在图5b中示出。插入器40可以被配置为直接或使用利用固定概率分布的熵编码将符号序列42插入到数据流中。第一符号化方案可以是截断的一元二值化方案。第二符号化方案可以使得符号序列42为莱斯码。正如上面已经提到的,图4的实施例可以在图像/视频编码器内实现。此图像/视频编码器或图片编码器的实例在图6中示出。图片编码器一般用参考符号60表示并且包括例如对应于图4中所示的装置的装置62。编码器60被配置为在编码图片64的过程中,将图片64的区块66变换成然后由装置62处理的变换系数区块10以便按照变换区块10编码其多个变换系数。特别地,装置62逐变换区块地处理变换区块10。在这样做的过程中,装置62可以将函数52用于不同尺寸的区块10。例如,可以使用分层多树细分以便将其图片64或树根区块分解成不同尺寸的区块66。从将变换应用于这些区块66产生的变换区块10因此具有不同尺寸,并且虽然函数52可以针对不同区块尺寸通过使用不同函数参数的方式进行优化,但是提供一方面符号化参数和另一方面上下文索引的不同依赖性的整体开销保持较低。图7示出了用于从数据流32解码具有变换系数级别的多个变换系数的装置,其适合上文针对图4概述的装置。特别地,图7的装置包括上下文自适应熵解码器80、解符号化器82和提取器84以及符号化参数确定器86。上下文自适应熵解码器80被配置为针对当前变换系数,从数据流32对一个或多个符号的第一集合,即符号序列44,进行熵解码。解符号化器82被配置为根据第一符号化方案将一个或多个符号的第一集合,即符号序列44,映射到第一级别区间16内的变换系数级别上。更确切地说,上下文自适应熵解码器80和解符号化器82以交互的方式操作。解符号化器82经由符号从数据流32依次通过解码器80解码的信号88通知上下文自适应熵解码器80已经完成第一符号化方案的有效符号序列。提取器84被配置为如果一个或多个符号的第一集合(即符号序列44)根据第一符号化方案映射到其上的变换系数级别是对级别区间16的最大级别,则从数据流32提取符号的第二集合,即符号序列42。再者,解符号化器82和提取器84可以协同操作。也就是说,当完成第二符号化方案的有效符号序列之后,解符号化器82可以通过信号90通知提取器84,因此提取器84可以完成符号序列42的提取。解符号化器82被配置为根据第二符号化方案将符号的第二集合,即符号序列42,映射到第二级别区间18内的位置上,该第二符号化方案,正如上面已经提到的,根据符号化参数46是可参数化的。上下文自适应熵解码器80被配置为,在对第一符号序列44的至少一个预定符号进行熵解码的过程中,经由函数使用依据先前解码的变换系数的上下文。符号化参数确定器86被配置为如果第一符号序列44根据第一符号化方案映射到其上的变换系数级别是第一级别区间16的最大级别,则经由函数52依据先前解码的变换系数确定符号化参数46。为此,熵解码器80和符号化参数确定器86的输入端经由开关92连接至解符号化器82的输出端,在此解符号化器82输出变换系数的值xi。如上所述,对于上下文自适应性,解码器80通过存储并更新每个上下文的字母概率分布估计来管理上下文。每当解码某个上下文的符号时,使用该符号的实际/解码值来更新当前存储的字母概率分布估计,由此逼近此上下文的符号的实际字母统计数字。同样地,符号化参数确定器86被配置为依据先前解码的变换系数确定第二符号化方案的符号化参数46及其符号序列42。一般来说,上文针对编码描述的所有可能修改和进一步详情也可转移到图7的用于解码的装置。图8示出了图6的补充。也就是说,图7的装置可以在图片解码器100内实现。图7的图片解码器100包括根据图7的装置,即装置102。图片解码器100被配置为,在解码或重构图片104的过程中,从变换系数区块10重新变换图片104的区块106,装置102从数据流32解码多个变换系数,该数据流32然后输入图片解码器100。特别地,装置102逐区块地处理变换区块10并且,正如上文已经表示的,可以将函数52共同用于不同尺寸的区块106。应该注意,图片编码器和解码器60和100分别可以被配置为使用预测编码,其中将变换/重新转换应用于预测残差。而且,数据流32可以具有其中编码的细分信息,其向图片解码器100表明细分成分别进行变换的区块。在下文中,换句话说,再次对上述实施例进行描述,并提供关于特定方面的更多详情,这些详情可以分别转移到上述实施例。也就是说,上述实施例与上下文建模的特定方式有关以便编码与变换系数有关的语法元素,比如在基于区块的图像和视频编码器中,并且其方面在下面进一步描述并突出显示。实施例可以涉及数字信号处理的领域,并且特别地,涉及用于图像和视频解码器和编码器的方法和装置。特别地,根据所描述的实施例可以执行基于区块的图像和视频编解码器中的变换系数及其相关联语法元素的编码。在这个范围内,一些实施例表示用于编码与变换系数有关的语法元素的改进上下文建模,利用采用概率建模的熵编码器。进一步地,如上所述针对符号化参数可以进行用于剩余绝对变换系数的自适应二值化的莱斯参数的推导。统一、简化、友好的并行处理及上下文存储器的适度内存使用情况与简单的上下文建模相比是实施例的好处。甚至换句话说,本发明的实施例可以揭示用于对与编码基于区块的图像和视频编码器中的变换系数有关的语法元素进行上下文模型选择的新方法。进一步地,描述了控制绝对变换系数的剩余值的二值化的符号化参数(比如莱斯参数)的推导规则。基本上,上述实施例使用规则的简单和共用集合对与编码变换系数有关的所有或部分语法元素进行上下文模型选择。上文提及的第一符号化方案可以是截断的一元二值化。如果是这样的话,coeff_significant_flag、coeff_abs_greater_1及coeff_abs_greater_2可以被称为二进制语法元素或语法,其形成由变换系数的截断的一元二值化产生的第一、第二和第三仓。如上所述,截断的一元二值化只可以表示前缀,其在变换系数的级别落在第二级别区间18内的情况下通过后缀(其本身是莱斯码)来完成。另一个后缀可以属于指数哥伦布码(exp-golombcode)比如属于0阶,由此形成继图2中的第一和第二区间16和18之后的另一个级别区间(图2中未示出)。如上所述,可以基于如用于上下文模型选择的规则52的相同集合来进行用于剩余绝对变换系数的自适应二值化的莱斯参数的推导。针对扫描顺序,要注意,与上述描述相比同样可以改变。而且,不同区块尺寸和形状然而可以利用规则的相同集合,即利用相同函数52由图4和图6的装置支持。因此,可以实现对与编码变换系数有关的语法元素进行上下文模型选择的统一和简化方案,该上下文模型选择与推导符号化参数的和谐化组合。因此,上下文模型选择和符号化参数推导可以使用可以硬接线的相同逻辑、编程硬件或软件子程序等。为了实现符号化参数(比如莱斯参数)的上下文模型选择和推导的共同且简单的方案,如上所述可以评估区块或形状的已经编码的变换系数。为了评估已经编码的变换系数,在编码coeff_significant_flag(其是由二值化产生的第一仓)(其可以被称为编码有效图),以及变换系数级别的剩余绝对值的过程中的分离使用共用函数52执行。编码标志信息可以以交织的方式,即通过在编码绝对变换系数之后直接编码标志来进行。因此,整个变换系数可以只在一遍扫描中进行编码。可选地,标志信息可以在单独的扫描路径中进行编码,只要评估值f(x)只依赖绝对级别信息即可。如上所述,变换系数可以在单遍扫描中或在多遍扫描中进行编码。这可以通过截止集合c来启用或描述,该集合的系数ci表示在扫描i中处理的变换系数(第一和第二)符号化的符号数量。在空截止集合的情况下,可使用一次扫描。为了获得上下文模型选择和符号化参数推导的改善结果,截止集合c的第一截止参数c0应该大于1。注意,截止集合c可以选择为c={c0;c1},其中c0=1且c1=3且|c|=2,其中c0表示第一扫描中包含的第一二值化的仓/符号的数量,c1=3表示第一二值化内的符号位置,第一二值化的符号覆盖的符号位置是第二扫描。当该方案编码第一遍扫描中的整个区块或形状的由二值化产生的第一仓,接下来编码第二遍扫描中的整个区块或形状的第二仓时,给出另一个实例,其中c0等于1,c1等于2,等等。可以设计用于编码coeff_significant_flag,即由二值化过程产生的第一仓的局部模板56,如图1所示或如图9所示。作为统一和简化,局部模板56可以用于所有区块尺寸和形状。以xi的形式将整个变换系数输入到函数52,而不只是评估不等于零的变换系数的邻居数量。注意,可以固定局部模板56,即与当前变换系数的位置或扫描索引无关并与先前编码的变换系数无关,或自适应的,即依赖当前变换系数的位置或扫描索引和/或先前编码的变换系数,并且尺寸可以是固定的或自适应的。进一步地,当调整模板尺寸和形状从而允许覆盖区块或形状的所有扫描位置时,所有已经编码的变换系数或所有已经编码的变换系数直到特定限制用于评估过程。作为实例,图9示出了可以用于对角线扫描14的8x8变换区块10的局部模板56的另一个实例。l表示最低有效扫描位置和标有x的扫描位置,x表示当前扫描位置。注意,对于其他扫描顺序,可以修改局部模板以符合扫描顺序14。例如,在正向对角线扫描的情况下,局部模板56可以沿对角线翻动。上下文模型选择和符号化参数推导可以基于由已经编码的邻居xi产生的不同评估值f(x)。该评估针对具有由局部模板56覆盖的已经编码的邻居的所有扫描位置进行。局部模板56具有可变或固定尺寸并且可以依据扫描顺序。然而,模板形状和尺寸仅自适应扫描顺序,因此推导值f(x)与扫描顺序140和模板56的形状和尺寸无关。注意,通过设置模板56的尺寸和形状使得允许针对每个扫描位置覆盖区块10的所有扫描位置,从而实现当前区块或形状的所有已经编码的变换系数的使用。如前所述,选择上下文模型索引和推导符号化参数使用评估值f(x)。一般来说,映射函数的一般集合将由此产生的评估值f(x)映射到上下文模型索引和特定符号化参数上。除此之外,额外信息作为变换区块或形状10内侧的当前变换系数的当前空间位置或最低有效扫描位置l可以用于选择与编码变换系数有关的上下文模型并且可以用于推导符号化参数。注意,可以组合由评估和空间位置产生的信息或最后信息,因此可能存在特定加权。在评估和推导过程之后,所有参数(上下文模型索引、符号化参数)都可用于编码整个变换系数级别或达到特定极限的变换系数。作为所呈现的发明的实例配置,截止设置尺寸为空。这意味着,在沿扫描顺序处理接下来的变换系数之前,完全传输每个变换系数。评估值f(x)可以由局部模板56覆盖的已经编码的邻居xi的评估产生。特定映射函数ft(x)将输入矢量映射到用于选择上下文模型和莱斯参数的评估值。输入矢量x可以由局部模板56覆盖的邻居的变换系数值xi组成并依据交织方案。例如,如果截止集合c为空并且标志在单独一遍扫描中进行编码,则矢量x仅由绝对变换系数xi组成。一般来说,输入矢量x的值可以有符号或无符号。映射函数可以利用尺寸d的输入矢量x建立如下(假设t作为常数输入)。更具体地,映射函数ft(x)可以利用尺寸d的输入矢量x定义如下(假设t作为常数输入)。也就是说,gt(xt)可以是(|xt|-t)。在后一个公式中,函数δ定义如下(假设t作为常数输入)。另一种评估值是大于或小于特定值t的相邻绝对变换系数级别的数量,定义如下。注意,对于这两种评估值,额外的加权因子控制特定邻近的重要性是可能的。例如,加权因子wi对具有更短空间距离的邻居来说比对具有更大空间距离的邻居来说更高。进一步地,当将所有wi设为1时,忽略加权。作为所呈现的发明的实例配置,f0、f1、f2和f3是评估值,其中{0,1,2,3}和δ(xi)的各个t如(1)定义。对于该实例,f0用于推导第一仓的上下文索引,f1用于第二仓,f2用于第三仓,并且f3用于莱斯参数。在另一个实例配置中,f0用于对第一仓进行上下文模型选择,同时f1用来对第二仓、第三仓和莱斯参数进行上下文模型选择。这里,莱斯参数充当同样用于其他符号化参数的代表。对熵编码过程中的所有语法元素或仓索引以及符号化参数进行上下文模型选择通过采用评估值f(x)而使用相同的逻辑。一般来说,特定评估值f(x)通过另一个映射函数g(x,n)映射到上下文模型索引或符号化参数。特定映射函数定义如下,其中d作为输入矢量n的尺寸。针对该映射,函数δ(x,n)可以定义如下。输入矢量n的尺寸d和矢量n的值可能是可变的并依据语法元素或仓索引。进一步地,变换区块或形状内侧的空间位置可以用于使所选的上下文模型索引相加或相减(或移动)。当编码/解码的变换系数时,在对其进行扫描的过程中,第一扫描位置可以是当应用从dc指向最高频率的图1的扫描方向时的最后扫描位置l。也就是说,用于遍历系数以便对其进行编码/解码的扫描中的至少第一扫描可以从系数l指向dc。对于该扫描位置l,第一仓索引可以忽略,因为最后信息已经表明该扫描位置由不等于零的变换系数组成。对于该扫描位置,单独的上下文模型索引可以用于编码由变换系数的二值化产生的第二仓和第三仓。作为本发明的实例配置,由此产生的评估值f0与输入矢量n={1,2,3,4,5}一起被用作输入,并且由此产生的值是第一仓的上下文模型索引。注意,在评估值等于零的情况下,上下文索引为零。相同的方案运用评估值f1和输入矢量n={1,2,3,4}并且由此产生的值为二值化的第二仓和第三仓的上下文模型索引。对于莱斯参数,使用f3和n={0,5,19}。注意,最大莱斯参数为3,因此通过所呈现的发明不对与最先进技术相比最大的莱斯参数进行改变。可选地,f1可以用于推导莱斯参数。对于此配置,输入矢量应该修改为n={3,9,21}。注意,规则的底层集合对所有语法元素或仓索引以及莱斯参数来说是相同的,只有参数或阈值集合(输入矢量n)不同。进一步地,依据当前扫描位置的对角线,可以修改上下文模型索引,如前所述,通过使特定量相加或相减。对此的等效描述是选择另一个不相交的上下文模型集合。在实例实现中,如果当前扫描位置位于前两条对角线上,则由此产生的用于第一仓的上下文模型索引移动2*|ctx0|。如果当前扫描位置位于第三和第四对角线上,则用于第一仓的上下文模型索引移动|ctx0|,其中|ctx0|是由关于产生不相交的上下文模型集合的评估值的推导基础产生的最大上下文模型的数量。该概念仅用于亮度平面以便实例实现,同时在色度避免上下文稀释的情况下(即,没有利用自适应上下文模型编码足够的仓并且统计数字不能被上下文模型跟踪)没有添加另一个偏移量。相同的技术可以应用于第二仓和第三仓的上下文模型索引。这里,在所呈现的发明的实例配置中,阈值对角线为3和10。再者,该技术仅应用于亮度信号。注意,还可以将该技术扩展到色度信号。进一步地,注意,依据对角线的额外索引偏移量可以建立如下。ctxoffset=dj*idxinc在该公式中,dj表示当前扫描位置的对角线的加权,idxinc表示步长。进一步地,注意,偏移量索引可以反向以便用于实际实现。对于所陈述的实例实现,反向可以将额外索引设为零,如果当前扫描位置位于第一和第二对角线上,则针对第三和第四对角线移动|ctx0|,否则移动2*|ctx0|。通过使用给出的公式,当将d0和d1设为2,将d3和d4设为1并将所有剩余的对角线因子设为0时,实现针对实例配置的相同行为。即使上下文模型索引对于不同区块尺寸或平面类型(例如,亮度和色度)来说是相同的,基本上下文模型索引也可以不同,从而导致上下文模型的集合不同。例如,可以使用在亮度方面大于8x8的区块尺寸的相同基本索引,同时基本索引在亮度方面对4x4和8x8来说可以是不同的。为了获得有意义数量的上下文模型,该基本索引然而可以以不同方式进行分组。作为实例配置,用于4x4区块和剩余区块的上下文模型在亮度方面可以不同,同时相同的基本索引可以用于色度信号。在另一个实例中,相同的基本索引可以用于亮度和色度信号这两者,同时用于亮度和色度的上下文模型是不同的。此外,用于第二仓和第三仓的上下文模型可以被分组,从而导致更少的上下文内存。如果用于第二仓和第三仓的上下文模型索引推导相同,则相同的上下文模型可以用于传输第二仓和第三仓。通过正确组合基本索引分组和加权,可以实现有意义数量的上下文模型,从而节省上下文内存。在本发明的优选实施例中,截止集合c为空。也就是说,只使用一次扫描。对于该优选实施例,标志信息可以使用相同相同的一遍扫描进行交织或可以在单独的一遍扫描中进行编码。在另一个优选实施例中,集合尺寸c等于1和c0,截止集合c的第一且仅值等于3。这对应于上文通过使用两次扫描示出的实例。在该优选实施例中,上下文模型选择可以针对由截断的一元二值化产生的全部三个仓进行,同时符号化参数推导比如莱斯参数选择可以使用相同的函数52进行。在优选实施例中,局部模板的尺寸为5。局部模板的尺寸可以为4。对于该优选实施例,与图8相比,可以除去在垂直方向上具有为2的空间距离的邻居。在另一个优选实施例中,模板尺寸是自适应的并被调整为扫描顺序。对于该优选实施例,之前在处理步骤中编码的邻居不包括在模板中,仅如图1和图8中的情况。通过这样做,缩短了依赖或延迟,从而导致更高的处理顺序。在另一个优选实施例中,模板尺寸和形状被调整为足够大(例如,当前区块或形状的相同区块或形状尺寸)。在另一个优选实施例中,可以使用两个局部模板并且其可以通过加权因子组合。对于该优选实施例,局部模板在尺寸和形状方面可以不同。在优选实施例中,f0可以用于选择用于第一仓的上下文模型索引并且f1用于第二仓、第三仓和莱斯参数。在该优选实施例中,输入矢量n={0,1,2,3,4,5}产生6个上下文模型。用于第二和第三仓索引的输入矢量n可以是相同的并且n={0,1,2,3,4},同时用于莱斯参数的输入矢量n可以为n={3,9,21}。此外,在优选实施例中,在其内可以使用单独的上下文集合的变换区块的前述频率部分可以由对角线(光栅)扫描的对角线(或线)的不相交的集合形成。例如,不同的上下文基本偏移量数对第一和第二对角线来说可以存在,当从dc分量看时对第二和第三对角线以及第四和第五对角线可以存在,使得在上下文不相交的集合内发生这些对角线中的系数的上下文选择。注意,第一对角线为1。对于第二和第三仓索引,位于[0,2]范围内的对角线具有加权因子2,位于[3,9]范围内的对角线具有加权因子1。在亮度信号的情况下使用这些额外的偏移量,同时色度的加权因子全部等于零。同样对于该优选实施例,用于第一扫描位置(其是最低有效扫描位置)的第二和第三仓索引的上下文模型与剩余的上下文模型分离。这意味着评估过程不可以选择该单独的上下文模型。在优选实施例中,4x4亮度区块或形状使用用于第一仓的上下文的单个集合,同时用于剩余区块尺寸或形状的上下文模型是相同的。在该优选实施例中,用于色度信号的区块尺寸或形状之间没有分离。在本发明的另一个优选实施例中,区块尺寸或形状之间没有分离,从而导致用于区块尺寸和形状的相同基本索引或上下文模型集合。注意,对于这两个优选实施例,上下文模型的不同集合用于亮度和色度信号。在下文中,示出了使用根据上述实施例的修改莱斯参数二值化,但没有上下文自适应熵编码的实施例。根据该可选编码方案,只使用莱斯二值化方案(任选添加指数哥伦布后缀)。因此,不需要自适应上下文模型来编码变换系数。对于该可选编码方案,莱斯参数推导针对上述实施例使用相同规则。换句话说,为了降低复杂性和上下文内存并改善编码流水线的延迟,描述一种基于规则或逻辑的相同集合的可选编码方案。对于可选编码方案,禁止对由二值化产生的前三个仓进行上下文模型选择,并且由截断的一元二值化,即第一符号化方案产生的前三个仓可以利用固定相同的概率(即,利用0.5的概率)进行编码。可选地,省略截断的一元二值化方案并调整二值化方案的区间界限。在该使用过程中,莱斯区间,即区间18,的左侧界限为0而不是3(区间16消失)。用于该用途的右侧/上部界限可以不加修改或可以减去3。推导莱斯参数可以根据评估值并根据输入矢量n进行修改。因此,根据刚才概述的修改实例,可以构造用于从数据流32解码不同变换区块的各自具有变换系数级别的多个变换系数的装置并且该装置如图10中所示并针对图10所述进行操作。图10的装置包括提取器120,被配置为从当前变换系数的数据流32中提取符号的集合或符号序列122。如上文针对图7的提取器84所述,执行该提取。解符号化器124被配置为根据符号化方案将符号的集合122映射到当前变换系数的变换系数级别上,所述符号化方案是根据符号化参数可参数化的。该映射只可以使用可参数化符号化方案比如莱斯二值化,或者只可以使用该可参数化符号化方案作为当前变换系数的整体符号化的前缀或后缀。就图2而言,例如,可参数化符号化方案,即第二符号化方案,相对于第一符号化方案的符号序列形成后缀。为了呈现更多实例,参照图11a和图11b。根据图11a,将变换系数的区间范围20细分成三个区间16,18和126,一起覆盖区间范围20并按照各个更低区间的各个最大级别彼此重叠。如果系数级别x在最高区间126内,则整体符号化是符号化区间16内的级别的第一符号化方案128的符号序列44、形成继第一后缀之后的前缀的符号序列,即符号化区间18内的级别的第二符号化方案130的以及进一步继第二后缀之后的符号序列42,即符号化区间126内的级别的第三符号化方案134的符号序列132的组合。后者可以是指数哥伦布码比如阶0。如果系数级别x在中间区间18内(而不在区间126内),则整体符号化仅仅是继第一后缀42之后的前缀44的组合。如果系数级别x在最低区间16内(而不在区间18内),则整体符号化仅仅由前缀44组成。整体符号化经组成使得其是无前缀的。在没有第三符号化的情况下,根据图11a的符号化可以对应于图2的符号化。第三符号化方案134可以是哥伦布莱斯二值化。第二符号化方案130可以形成可参数化的符号化方案,但是其也可以是第一128。可选整体符号化在图1中示出。这里,仅仅组合两个符号化方案。与图11a相比,留下了第一符号化方案。依据方案134的区间136,或方案130的区间138(区间136外)内的x,x的符号化包括前缀140和后缀142,或仅仅包括前缀140。进一步地,图10的装置包括连接在解符号化器的输出端与解符号化器124的参数输入端之间的符号化参数确定器144。确定器144被配置为经由函数52依据先前处理的变换系数为当前变换系数确定符号化参数46(可从解符号化片段或目前为止解符号化的/处理的/解码的部分推导)。提取器120、解符号化器124和符号化参数确定器144被配置为依次处理不同变换区块的变换系数,如上文所述。也就是说,扫描140可以在变换区块10内在相反的方向上遍历。几次扫描例如可以用于不同符号化片段,即前缀和后缀。函数参数依据当前变换系数的变换区块的尺寸、当前变换系数的变换区块的信息分量类型和/或当前变换系数位于变换区块内的频率部分而改变。装置可以经配置使得限定一方面先前解码的变换系数与另一方面符号化参数之间的关系的函数为g(f(x)),该函数已经在上文进行了描述。同样如上文所讨论的,可以使用依据相对于当前变换系数的相对空间布置的先前处理的变换系数的空间确定。装置可以非常容易且快速地操作,因为提取器120可以被配置为直接或使用利用固定概率分布的熵解码从数据流中提取符号的集合。可参数化符号化方案可以使得符号的集合是莱斯码,并且符号化参数是莱斯参数。换句话说,解符号化器124可以被配置为将符号化方案限制为在变换系数的范围区间20范围外的级别区间比如18或138,使得符号的集合相对于当前变换系数比如44和132或142的整体符号化的其他部分表示前缀或后缀。针对其他符号,其也可以直接或使用利用固定概率分布的熵解码从数据流中提取,但图1至图9示出还可以使用利用上下文自适应性的熵编码。图10的装置可以被用作图8的图片解码器102中的装置102。为了完整起见,图12示出了用于将不同变换区块的各自具有变换系数级别的多个变换系数编码成数据流32的装置,装配至图10的装置。图12的装置包括符号化器,被配置为根据符号化方案针对当前变换系数将变换系数级别映射到符号的集合或符号序列上,所述符号化方案是根据符号化参数可参数化的。插入器154被配置为将当前变换系数的符号的集合插入到数据流32中。符号化参数确定器156被配置为,经由通过函数参数可参数化的函数52依据先前处理的变换系数为当前变换系数确定符号化参数46,为此,其可以连接在插入器152的输出端与符号化器150的参数输入端之间,或可选择地在符号化器150的输出端与输入端之间。插入器154、符号化器150和符号化参数确定器156可以被配置为依次处理不同变换区块的变换系数,并且函数参数依据当前变换系数的变换区块的尺寸、当前变换系数的变换区块的信息分量类型和/或当前变换系数位于变换区块内的频率部分而改变。如上文针对图10的解码装置所述,图12的装置可以经配置使得限定一方面先前解码的变换系数与另一方面符号化参数之间的关系的函数为g(f(x)),并且先前处理的变换系数可以依据相对于当前变换系数的相对空间布置从空间上确定。插入器可以被配置为直接或使用利用固定概率分布的熵编码将符号的集合插入到数据流中,并且符号化方案可以使得符号的集合是莱斯码,并且符号化参数是莱斯参数。符号化器可以被配置为将符号化方案限制为在变换系数的范围区间20范围外的级别区间18,使得符号的集合表示关于当前变换系数的整体符号化的其他部分的前缀或后缀。如上所提及的,对于图10至图12实施例的优选实现,用于前三个仓的上下文模型选择与图1至图9的实施例相比被禁用。对于该优选实施例,由截断的一元二值化128产生的仓利用0.5的固定概率进行编码。在另一个优选实施例中,如图11b所示省略截断的一元二值化128并调整莱斯区间的界限,从而产生如与本领域状态相同的区间范围(即,左侧和右侧界限减去3)。对于该优选实施例,与图1至图9的实施例相比,修改莱斯参数推导规则。例如可以使用f0来代替作为评估值的f1。进一步地,输入矢量可以被调整为n={4,10,22}。下文描述的另一个实施例示出了实际上具有用于一方面上下文选择/依赖性且另一方面用于符号化参数确定的不同模板的可能性。也就是说,系数xi的模板对上下文选择/依赖性和符号化参数确定都保持不变,但要影响f(x)的系数xi通过适当设置wi而在上下文选择/依赖性和符号化参数确定之间有效地呈现不同:加权wi为零的所有系数xi因此不影响f(x),从而设计wi为零的模板的部分,一方面上下文选择/依赖性与另一方面符号化参数确定之间不同,有效导致上下文选择/依赖性和符号化参数确定的不同“有效模板”。换句话说,通过针对上下文选择/依赖性和符号化参数确定之一的某些模板位置i将一些wi设为零,同时针对上下文选择/依赖性和符号化参数确定的另一个将某些模板位置i处的wi设为非零值,上下文选择/依赖性和符号化参数确定的首先提及的一个的模板有效地小于上下文选择/依赖性和符号化参数确定的后一者的模板。再者,正如上面已经表示的,模板可以包含区块的所有变换系数,而不管当前编码变换系数的位置。例如参见图13,其示出了示例性地由16x16变换系数12的阵列组成的变换系数区块10。变换系数区块10分别被细分成4x4变换系数12的子区块200。因此,子区块200按4x4阵列规则排列。根据本实施例,对于编码变换系数区块10,有效图在数据流32内进行编码,该有效图表示有效变换系数级别12的位置,即变换系数级别不等于0。然后,变换系数级别减去这些有效变换系数之一可以在数据流内进行编码。如上所述可以进行对后面的变换系数级别进行编码,即通过混合上下文自适应熵编码和使用共用可参数化函数的可变长度编码以便选择上下文并确定符号化参数。可以使用某个扫描顺序以便使有效变换系数序列化或给其排序。此扫描顺序的一个实例在图13中示出:子区块200从最高频率(右下)至dc(左上)进行扫描,并且在每个子区块200内,变换系数12在访问按照子区块顺序的下一个子区块的变换系数之前进行扫描。这由表示子区块扫描的箭头202和示出了实际系数扫描的一部分的204示出。扫描索引可以在数据流32内传输以便允许在几条扫描路径之间选择,从而分别扫描子区块200和/或子区块内的变换系数12。在图13中,针对子区块扫描202和每个子区块内的变换系数12扫描示出了对角线扫描。因此,在解码器处可以解码有效图,并且有效变换系数的变换系数级别可以使用刚才提及的扫描顺序并使用利用可参数化函数的上述实施例进行解码。在下面更详细概述的描述中,xs和ys表示从dc位置(即区块10的左上角)起测量的子区块列和子区块行,当前编码/解码的变换系数定位在该位置内。xp和yp表示从当前子区块(xs,ys)的左上角(dc系数位置)测量的当前编码/解码的变换系数的位置。在图13中这针对右上的子区块200示出。xc和yc表示从dc位置起在变换系数中测量的当前解码/编码变换系数位置。进一步地,因为图13中的区块10的区块尺寸,即16x16,仅出于说明目的进行了选择,所以下面进一步概述的实施例使用log2trafosize作为表示区块10的尺寸的参数,假设其是二次的。log2trafosize表示区块10的变换系数的每行内的变换系数的数量的底为2的对数,即变换系数中测量的区块10的边缘的长度的log2。ctxidxinc最终选择上下文。进一步地,在下面概述的特定实施例中,假设前述有效图表明coded_sub_block_flag,即二进制语法元素或标志,对于区块10的子区块200以便逐子区块地表明在各个子区块200内是否定位有任何有效变换系数,即是否只有无效变换系数位于各个子区块200内。如果标志为零,则只有无效变换系数位于各个子区块内。因此,根据该实施例,以下通过上下文自适应熵解码器/编码器执行以便选择significant_coeff_flag,即标志(其是有效图的一部分和子区块的某个变换系数的信号)的上下文,coded_sub_block_flag针对各个系数是否有效,即是否非零表明各个子区块200包含非零变换系数。至该过程的输入是颜色分量索引cidx、当前系数扫描位置(xc,yc)、扫描顺序索引scanidx、变换区块尺寸log2trafosize。该过程的输出是ctxidxinc。变量sigctx依据当前位置(xc,yc)、颜色分量索引cidx、变换区块尺寸和语法元素coded_sub_block_flag的先前解码仓。对于sigctx的推导,以下情况适用。-如果log2trafosize等于2,则sigctx使用如下表1中指定的ctxidxmap[]进行推导。sigctx=ctxidxmap[(yc<<2)+xc]-否则,如果xc+yc等于0,则sigctx推导如下。sigctx=0-否则,sigctx使用coded_sub_block_flag的先前值推导如下。-水平和垂直子区块位置xs和ys分别被设为等于(xc>>2)和(yc>>2)。-变量prevcsbf被设为等于0。-当xs小于(1<<(log2trafosize-2))-1,则以下情况适用。prevcsbf+=coded_sub_block_flag[xs+1][ys]-当ys小于(1<<(log2trafosize-2))-1,则以下情况适用。prevcsbf+=(coded_sub_block_flag[xs][ys+1]<<1)-内部子区块位置xp和yp被分别设为等于(xc&3)和(yc&3)。-变量sigctx推导如下。-如果prevcsbf等于0,则以下情况适用。sigctx=(xp+yp==0)?2:(xp+yp<3)?1:0-否则,如果prevcsbf等于1,则以下情况适用。sigctx=(yp==0)?2:(yp==1)?1:0-否则,如果prevcsbf等于2,则以下情况适用。sigctx=(xp==0)?2:(xp==1)?1:0-否则,(prevcsbf等于3),则以下情况适用。sigctx=2-变量sigctx修改如下。-如果cidx等于0,则以下情况适用。-当(xs+ys)大于0时,以下情况适用。sigctx+=3-变量sigctx修改如下。-如果log2trafosize等于3,则以下情况适用。sigctx+=(scanidx==0)?9:15-否则,以下情况适用。sigctx+=21-否则,(cidx大于0),以下情况适用。-如果log2trafosize等于3,则以下情况适用。sigctx+=9-否则,以下情况适用。sigctx+=12上下文所有增量ctxidxinc使用颜色分量索引cidx和sigctx进行如下推导。-如果cidx等于0,则ctxidxinc推导如下。ctxidxinc=sigctx-否则,(cidx大于0),ctxidxinc推导如下。ctxidxinc=27+sigctx表1-ctxidxmap[i]的规格i01234567891011121314ctxidxmap[i]014523456688778如上所述,对于每个有效变换系数,进一步语法元素或符号的集合可以在数据流内传递以便表明其级别。根据下面概述的实施例,对于一个有效变换系数,传输以下语法元素或变换系数的集合:coeff_abs_level_greaterl_flag、coeff_abs_level_greater2_flag(任选)、及coeff_abs_level_remaining,使得当前编码/解码的有效变换系数级别transcoefflevel为:transcoefflevel=(coeff_abs_level_remaining+baselevel)*(1-2*coeff_sign_flag])其中baselevel=1+coeff_abs_level_greater1_flag+coeff_abs_level_greater2_flag请注意,significant_coeff_flag根据定义对于有效变换系数为1,因此,可以被视为编码变换系数的一部分,即其熵编码符号的一部分。上下文自适应熵解码器/编码器例如可对coeff_abs_level_greater1_flag执行上下文选择,如下。例如,当前子区块扫描索引i可沿扫描路径202向dc的方向增加,并且当前系数扫描索引n可在各个子区块内沿扫描路径204增加,当前编码/解码的变换系数位置位于各个子区块内,其中,如上文概述,不同可能性对于扫描路径202和204来说存在,并且其根据索引scanidx实际上是可变的。至选择coeff_abs_level_greater1_flag的上下文的过程的输入是颜色分量索引cidx、当前子区块扫描索引i和当前子区块内的当前系数扫描索引n。该过程的输出是ctxidxinc。变量ctxset指定当前上下文集合并且对于其推导,以下情况适用。-如果该过程在第一时间内针对当前子区块扫描索引i调用,则以下情况适用。-变量ctxset初始化如下。-如果当前子区块扫描索引i等于0或cidx大于0,则以下情况适用。ctxset=0-否则(i大于0且cidx等于0),以下情况适用。ctxset=2-变量lastgreater1ctx推导如下。-如果具有扫描索引i的当前子区块对当前变换区块来说是该节中要处理的第一子区块,则变量lastgreater1ctx被设为等于1.-否则,变量lastgreater1ctx被设为等于greater1ctx的值,其在针对具有扫描索引i+1的先前子区块的语法元素coeff_abs_level_greater1_flag最后调用该节中指定的过程期间进行推导。-当lastgreater1ctx等于0时,ctxset递增1如下。ctxset=ctxset+1-变量greater1ctx被设为等于1。-否则(在第一时间内不针对当前子区块扫描索引i调用该过程),以下情况适用。-变量ctxset被设为等于已经在最后调用该节中指定的过程期间推导的变量ctxset。-变量greater1ctx被设为等于已经在最后调用该节中指定的过程期间推导的变量greater1ctx。-当greater1ctx大于0时,变量lastgreater1flag设为等于在最后调用该节中指定的过程期间使用的语法元素coeff_abs_level_greater1_flag并且greater1ctx修改如下。-如果lastgreater1flag等于1,则greater1ctx被设为等于0。-否则(lastgreater1flag等于0),greater1ctx递增1。上下文索引增量ctxidxinc使用当前上下文集合ctxset和当前上下文greater1ctx推导如下。ctxidxinc=(ctxset*4)+min(3,greater1ctx)当cidx大于0时,ctxidxinc修改如下。ctxidxinc=ctxidxinc+16可以使选择coeff_abs_level_greater2_flag的上下文的过程与coeff_abs_level_greater2_flag相同,区别如下:上下文索引增量ctxidxinc被设为等于变量ctxset,如下。ctxidxinc=ctxset当cidx大于0时,ctxidxinc修改如下。ctxidxinc=ctxidxinc+4对于符号化参数选择,由符号化参数确定器执行以下情况以便确定在这里包括clastabslevel和clastriceparam的符号化参数。至该过程的输入是语法元素coeff_abs_level_remaining[n]二值化和baselevel的请求。该过程的输出是语法元素二值化。变量clastabslevel和clastriceparam推导如下。-如果n等于15,则clastabslevel和clastriceparam被设为等于0。-否则(n小于15),clastabslevel被设为等于baselevel+coeff_abs_level_remaining[n+1]并且clastriceparam被设为等于在针对相同变换区块的语法元素coeff_abs_level_remaining[n+1]最后调用该节中指定的二值化过程期间推导的criceparam的值。变量criceparam从clastabslevel和clastriceparam推导为:criceparam=min(clastriceparam+(clastabslevel>(3*(1<<clastriceparam))?1:0),4)变量ctrmax从criceparam推导为:ctrmax=4<<criceparamcoeff_abs_level_remaining二值化可以由前缀部分(存在时)和后缀部分组成。二值化的前缀部分通过调用例如前缀部分min(ctrmax,coeff_abs_level_remaining[n])的莱斯二值化过程进行推导。当前缀仓串等于长度4的比特串时,例如所有比特等于1,仓串可以由前缀仓串和后缀仓串组成。后缀仓串可以使用后缀部分(coeff_abs_level_remaining[n]-ctrmax)的指数哥伦布k阶二值化进行推导,其中指数哥伦布k阶例如设为等于criceparam+1。应该注意,可以改变上述实施例。例如,可以留下对颜色分量索引cidx的依赖性。例如仅仅应考虑一个颜色分量。进一步地,可以改变所有确切值。在这个范围内,刚才概述的实例将从广义上解释以便同样并入变型。在上述实例中,上文概述的实施例可以有利地以下列方式使用。特别地,一方面确定coeff_abs_level_greater1_flag的ctxidxinc及coeff_abs_level_remaining的符号化参数确定利用上述函数f和g通过以下列方式设置函数参数来进行协调。为此,图13示例性地示出了用十字206示出的“当前变换系数”。其是随后提及的任何语法元素与之相关联的任何变换系数的代表。其定位在当前子区块(xs,ys)=(0,1)内的(xp,yp)=(1,1)和(xc,yc)=(1,5)处。右侧相邻子区块在(xs,ys)=(1,1)处,底部相邻子区块在(xs,ys)=(0,2)处并且先前编码子区块依据扫描路径202。这里,示例性地,示出了对角线扫描202,并且紧位于当前子区块之前的所编码/解码的子区块在(xs,ys)=(1,0)处。我们再次改写常用可参数化函数的公式f(x)=∑iwi×h(xi)×δ(xi,t)(2)针对选择当前系数206的significant_coeff_flag的上下文,以下情况可以通过熵编码/解码装置计算。也就是说,其可使用函数(1),其中(2)具有设置如下的函数参数t,h和w:针对函数(2),对于当前子区块右边和下面的相邻子区块中的所有xi,wi=1,并且在区块10的其他地方wi=0;对于当前子区块右边的相邻子区块中的所有xi,h(xi)=1;如果存在,则同样事先在子区块扫描202中进行扫描;如果一次以上的扫描202是可用的,则全部可以使得(独立于scanidx)右边的相邻子区块具有在当前子区块之前编码/解码的系数;对于先前在子区块扫描中扫描的当前子区块下面的相邻子区块中的所有xi,h(xi)=24+1(独立于scanidx);否则h(xi)=0;t=1;如果f的值等于0,则表明当前子区块nachbarn右边和下面的相邻子区块都不包括任何有效变换系数的情况;如果f的值介于1和16(包括两个端点)之间,则这对应于coded_sub_block_flag在右边相邻子区块中等于1的事实;如果f的值是24+1的倍数(没有余数),则这对应于coded_sub_block_flag在底部相邻子区块中等于1的事实;如果f的值是24+1的倍数(但有余数),则这意味着coded_sub_block_flag针对两个相邻子区块等于1的事实,即一个在当前子区块右边,一个在当前子区块下面;针对函数(1),n设置如下,其中df为3:n=(0,24,m)其中通过这种措施,上下文索引的可变分量使用g(f)确定,其中上述函数参数基于已经编码/解码的系数。针对选择coeff_abs_greater1_flag的上下文,以下情况可以通过熵编码/解码装置计算。也就是说,其可使用函数(1),其中(2)具有设置如下的函数参数:针对函数(2),参数设置如下:对于前面紧接着的子区块和当前子区块中的所有xi,wi=1,并且针对所有其他为零。对于当前子区块中的所有xi,h(xi)=1,其中|xi|=1对于当前子区块中的所有xi,h(xi)=24,其中|xi|>1对于前面紧接着的子区块中的所有xi,h(xi)=216t=2针对函数(1),n设定如下,df为8:n=(0,1,2,24,216,216+1,216+2,216+24)针对选择coeff_abs_greater2_flag的上下文,以下情况可以通过熵编码/解码装置计算。特别地,其可使用函数(1),其中(2)具有设置上文针对coeff_abs_greater2_flag所述的函数参数,但df为1:n=(216)针对确定coeff_abs_level_remaining的符号化参数,符号化参数确定器可使用常见函数(1),其中函数参数设定如下:针对函数(2),参数设定如下:对于当前子区块中的所有xi,wi=1,但在其他地方为零对于最近根据内部系数扫描204访问的系数xi(coeff_abs_level_remaining已经针对其进行编码),即其级别落入与符号化方案对应的区间内,h(xi)=1;在模板其他地方h(xi)=0t=0针对函数(1),n设置如下:对于最近提及的根据内部系数扫描204访问的系数,n=(2m),其中其中k是符号化参数,例如莱斯参数。使用由此产生的g(f),来确定当前系数206的符号化参数。以下语法可用于传递刚才概述的语法元素。语法表示变换系数的级别由coeff_abs_level_remaining和baselevel组成,其中baselevel由1+coeff_abs_level_greater1_flag[n]+coeff_abs_level_greater2_flag[n]组成。使用1,因为在该位置(或在级别在解码器中重构时),语法元素为significant_coeff_flag=1。“第一集合”然后是tu码(参数化等于0的莱斯码),据此形成前3个语法元素。“第二集合”然后形成语法元素coeff_abs_level_remaining。因为边界在“第一集合”与“第二集合”之间移位,所以最大值由coeff_abs_greater1_flag、coeff_abs_greater2_flag或由significant_coeff_flag限定,因此分支取决于表中的语法元素。函数参数的上述设定在下文中仍然是有点目的的。g(f)形成相邻系数之和并使用推导上下文和解符号化参数的结果,其中稍后的修改可以依据空间位置执行。g(x)获取一个单一的值。该值对应于函数f(x)的结果。了解这个之后,可以推导上下文选择和莱斯参数的参数化。significant_coeff_flag:因为h本身可以是x的函数,所以f(x)或任何其他函数可以一次再一次地链接。对于右边4x4子区块中的所有位置,函数f(x),其中wi=1,t=1和h,是配置向f(x)一样配置但不反向的函数,使得最后得到值0或1,即h(x)=min(1,f(x))。等效地,对于第二条目,这适用于底部4x4子区块。然后,prevcsbf=h0+2×h1,其中prefcsbf也可以是f(x)内的函数h。如果设置t=∞,则可以推导语法元素coded_sub_block_flag的值。因此,获得0与3之间的值作为最外面f(x)的结果。g(x)的参数n然后可以是(xp+yp),xp,yp或(0,0)。如果得到f(x)=0,则n=(xp+yp,xp+yp+3),对于f(x)=1得到n=(yp,yp+1),对于f(x)=2得到n=(xp,xp+1),并且对于f(x)=3得到n=(0,0)。可以说,f(x)可以直接评估以便确定n。上文剩余的公式仅仅描述依据亮度/色度的自适应和对全局位置和扫描的进一步依赖性。就纯粹的4x4区块而言,f(x)可以经配置使得可以再现prevcsbf=4的值(也可以不同)并因此再现映射表。coeff_abs_level_greater1_flag:这里,子区块的评估类似,其中只评估先前的子区块。结果是,例如1或2(其只能是两个不同的值),其中t=2。这对应于依据先前子区块中的已经解码的级别的基础索引的选择。因此可以获得对位于子区块内的级别的直接依赖性。有效地,当解码0时执行一个索引的接通(从1开始,限制到3)并且一解码1就将其设为0。如果不考虑该布置,则参数化可以执行如下,从0开始。对于相同子区块中的所有级别wi=1并且t=3,即f(x)提供coeff_abs_greater1_flag=1的级别数量。对于进一步函数f(x),t=2,即编码语法元素coeff_abs_greater1_flag的位置数量。第一函数要受限制,即h0=f(x)=min(f0(x),2),并且第二函数要受限制,其中h1=f(x)=max(f1(x),1)。所有都与delta函数有关联(如果h1=1,则为0,否则为h0)。对于coeff_abs_greater2_flag,只使用集合的推导(对于链接的内部函数,将wi设为0)。coeff_abs_level_remaining:选择仅限于当前子区块并且n推导如上所述。针对刚才概述的实施例,注意以下情况。特别地,根据上述描述,针对模板的定义存在不同可能性:模板可以是移动模板,其位置依据当前系数206的位置来确定。此示例性移动模板的概述在图13中用虚线208描述。模板由当前系数206位于其内的当前子区块、当前子区块右边和下面的相邻子区块、以及一个或多个子区块组成,如果具有其中的几个(其中之一可使用如上解释的扫描索引选择),则一个或多个子区块在子区块扫描202或任意子区块扫描202中仅位于当前子区块之前。作为替代方案,模板208可以简单包含区块10的所有变换系数12。在上述实例中,具有选择h和n的值的进一步不同的可能性。这些值因此可以以不同方式进行设置。针对wi这同样有点是真的,一直到涉及这些加权,其被设为1。同样可以被设为另一个非零值。甚至不必彼此相等。因为wi乘以h(xi),所以相同的积值可以通过以不同方式设置非零wi来实现。而且,符号化参数没有必要是莱斯参数,或不同的说,符号化方案不限于莱斯符号化方案。至于上下文索引选择,参照上述描述,其中已经注意到,最终上下文索引可以通过将使用函数g(f)获得的上下文索引与一些偏移量索引相加而获得,该偏移量索引例如对语法元素的各个类型是特定的,即对significant_coeff_flag、coeff_abs_level_greater1_flag和coeff_abs_level_greater2_flag是特定的。虽然已经就装置的上下文描述了若干方面,但显然这些方面也表示对应的方法的描述,其中,方框或装置是与方法步骤或方法步骤的特征对应的。同理,在方法步骤的上下文中描述的方面也表示对应的方框或对应的装置的项目或特征结构的描述。部分或全部方法步骤可通过(或使用)硬件装置执行,类似例如微处理器、可编程计算机或电子电路。在某些实施例中,最重要方法步骤中的某一者或多者可通过这种装置执行。根据某些实现的要求,本发明的实施例已经在硬件或软件中实现。实现可使用数字存储介质进行,例如软盘、dvd、蓝光盘、cd、rom、prom、eprom、eeprom或闪存,其上存储有电子可读取控制信号,其与可编程计算机系统协作(或可协作),从而执行各个方法。因此数字存储介质可为计算机可读介质。根据本发明的某些实施例包括具有电子可读控制信号的数据载体,其可与可编程计算机系统协作,以便执行本文所述方法中的一者。通常情况下,本发明的实施例可实现为具有程序代码的计算机程序产品,当该计算机程序产品在计算机上运行时,该程序代码可操作用来执行该等方法中的一者。该程序代码例如可存储在机器可读载体上。其它实施例包括用于执行本文所述方法中的一者且存储在机器可读载体上的计算机程序。换句话说,因此本发明方法的实施例为具有程序代码的一种计算机程序,用于当该计算机程序在计算机上运行执行本文所述方法中的一者。因此,本发明方法的进一步实施例为一种数据载体(或数字存储介质或计算机可读介质)包括于其上记录的用于执行本文所述方法中的一者的计算机程序。数据载体、数字存储介质或记录介质典型地是有形的和/或非转变的。因此,本发明方法的进一步实施例为表示用于执行本文所述方法中的一者的计算机程序的数据流或信号序列。数据流或信号序列例如可配置来经由数据通讯连接例如通过互联网传送。进一步实施例包括一种处理构件,例如计算机或可编程逻辑设备,被配置来或适用于执行本文所述方法中的一者。进一步实施例包括其上安装有用于执行本文所述方法中的一者的计算机程序的计算机。根据本发明的进一步实施例包括一种装置或系统,其配置为(例如电子地或光学地)将用于执行本文描述方法的其中之一的计算机程序传递到接收器。接收器可以例如是计算机、移动设备、存储器设备等等。该装置或系统可以例如包括用于将计算机程序传递到接收器的文件服务器。在某些实施例中,可编程逻辑设备(例如现场可编程门阵列)可用来执行本文所述方法的一部分或全部功能。在某些实施例中,现场可编程门阵列可与微处理器协作以执行本文所述方法中的一者。通常情况下,该等方法优选由硬件装置执行。上述实施例仅用于举例说明本发明的原理。应理解,本文所述的配置及细节的修改及变化对本领域的技术人员来说是显而易见的。因此,意图仅受随附的专利权利要求的范围所限制,而不受由本文实施例的描述及解说所呈现的特定细节所限制。当前第1页12
相关技术
网友询问留言
已有0条留言
- 还没有人留言评论。精彩留言会获得点赞!
1