一种基于区域生长法的WSN数据采集方法与流程
本发明涉及无线传感器网络生存期领域,尤其是一种基于区域生长法的wsn数据采集方法。
背景技术:
无线传感器网络(wsn)是由部署在监测区域内大量廉价的微型传感器节点通过无线通讯的方式形成的多跳自组织网络,主要功能是数据采集及监测,其被广泛的应用于各个领域。一般传感器网络部署区域环境复杂,很难为传感器节点更换电池,在节点电源有限的情况下很容易死亡,尤其是大规模传感器网络需要采集转发大量的数据。但相邻区域的数据具有相似性,因此传感器网络会采集大量的冗余数据,大量数据在网络中多跳传输极易导致传感器网络能量耗尽而过早死亡。针对该问题,本发明提出一种基于区域生长法的wsn数据采集方法(daa-rgm),本发明提出的方法能够保证区域监测正常的情况下减少大量的冗余数据,能够较大幅度的延长传感器网络的生存时间,因此意义明显。
技术实现要素:
为了克服现有传感器网络相邻区域的数据具有相似性导致会采集大量的冗余数据、大量数据在网络中多跳传输极易导致传感器网络能量耗尽而过早死亡的不足,本发明提出一种数据采集时减少了大量冗余数据的采集、延长传感器网络的生存时间的基于区域生长法的wsn数据采集方法(daa-rgm)。
为了解决上述技术问题,本发明采用如下的技术方案:
一种基于区域生长法的wsn数据采集方法,包括如下步骤:
步骤1:传感器网络假设与定义,过程如下:
步骤1.1:传感器网络相关假设;
步骤1.1.1:传感器网络中节点的位置已经获取,且在小范围内,传感器节点采集的数值大小接近;
步骤1.1.2:传感器网络中所有节点同构,每个节点的初始能量相同且都为e0;
步骤1.1.3:假设无线传感器网络拓扑结构变化时,能够自行重新组织路由;
步骤1.1.4:将n个传感器节点均匀部署在一个长为l,宽为h的矩形区域中;
步骤1.2:传感器网络相关定义;
相邻传感器节点的定义,传感器节点的感知半径为r,传感器节点i采集的数据能够代表感知范围内任一数据采样点的数据信息,因此对传感器节点i的相邻传感器节点的定义n(i,j)如公式(1)所示:
公式(1)中n(i,j)为1则表示节点i与节点j相邻,为0则表明节点i与节点j不相邻,ed(i,j)为欧式距离;
步骤2:区域生长法划分相似区域,过程如下:
步骤2.1:区域生长法划分相似区域定义,根据步骤1.1所述,小范围内传感器网络采集的数据趋向一致性,因此通过区域生长算法将数据接近的区域进行划分,然后在该区域内选择一个代表节点,该代表节点采集的数据与该子区域的数值和数据变化趋势最接近,然后将代表节点的数据传输至服务器端,利用代表节点采集的数据代表子区域的数据;
步骤2.2:区域生长法种子节点的选择,种子节点的选取主要考虑分布均匀原则,种子节点在传感器网网络部署区域中分布均匀,才能全面的采集部署区域的信息;采用随机数方法选取种子节点,传感器网络中每个传感器节点k都能生成一个(0,1)之间均匀分布的随机数rand(k),当rand(k)大于阈值t时,则该节点称为种子节点,阈值t如公式(2)所示:
t=1-p(2)
公式(2)中p为传感器网络中需要选取种子节点的百分比;
步骤2.3:区域生长法相似区域生长过程,在wsn网络中并不采用图像中的四邻域或八邻域等,而是采用相邻传感器节点作为区域生长法的邻域,可通过公式(1)判断传感器节点是否相邻;
在初始时刻,传感器网络已经采集了一部分数据,假设节点j采集的数据为dataj={d1,d2,d3......dm},j∈[1,n],且节点j是种子节点i的相邻传感器节点,当节点j满足公式(3)时,区域向节点j方向生长:
|avg(dataj)-avg(datai)|≤td(3)
公式(3)中td为阈值,可根据实际情况取值,avg为求集合元素平均值的函数,datai是种子节点采集的历史数据;
通过步骤2.2方法选择的种子节点编号集合s={s1,s2,s3...sk...ssum},传感器网络被分割为sum个子区域,每个子区域中的传感器节点采集的数据信息相似性较高;
步骤3:子区域内代表节点的选取,过程如下:
步骤3.1:曲线相似性描述方法的提出,代表节点的历史数据曲线a与子区域中所有传感器节点历史数据均值曲线b应该满足以下两种情况之一:
1)曲线a与曲线b的变化趋势始终一致,且数值大小最接近;
2)曲线a与曲线b初始时刻趋势不一致,且数值大小也不一定接近,但是到后来两条曲线逐渐逼近,且数值大小也越来越接近;
上述两种情况中,由于随着环境信息的改变,传感器节点采集的数据也会随之改变,因此初始时刻曲线a与曲线b不吻合,但是随着时间的推移,代表节点的历史数据曲线a可能与曲线b吻合程度较好;
假设某个子区域的历史数据均值曲线b可描述为点集合avg_data={y1,y2,y3...yt...ym},m为历史数据数量,子区域中一个传感器节点的历史数据曲线a可描述为点集合data={y1,y2,y3...yt...ym},则曲线a与b的相似度计算方法如公式(4)所示。
公式(4)中h为子区域中传感器节点的数量,g是一个常数,表示误差范围,s表示曲线相似度,s越接近1,表明两条曲线的相似度越高;
步骤3.2:子区域中选择代表节点,过程如下:
步骤3.2.1:求子区域中所有传感器节点每个时刻采集数据的平均值,即计算avg_data;
步骤3.2.2:遍历子区域中所有传感器节点,并利用公式4计算每个传感器节点的历史数据曲线集合data与集合avg_data的相似度,选择相似度最高的传感器节点为代表节点;
步骤4:算法迭代,通过步骤2和步骤3已经完成了相似区域的划分和代表节点的选择,最后传感器网络只需要将代表节点采集的数据传输至服务器即可完成对整个区域的信息采集,该过程是一轮完整的数据采集过程。
进一步,所述步骤4中,为了使代表节点采集的数据能够更准确的代表子区域的信息以及均衡传感器节点能耗,数据采集算法运行一定时间后会重新进行下一轮数据采集过程,即相似区域划分以及代表节点选择。具体daa-rgm算法迭代如下:
步骤4.1:运行整个传感器网络,采集一段时间的数据信息;
步骤4.2:根据算法迭代步骤4.1采集的历史数据,按照步骤2的区域生长法进行相似区域划分;
步骤4.3:按照步骤3的代表节点选择方法为每个子区域选择代表节点;
步骤4.4:被选择的代表节点运行一段时间,采集区域信息;
步骤4.5:返回算法迭代步骤4.1。
再进一步,所述步骤2.3中,wsn相似区域生长算法如下:
步骤2.3.1:将种子点编号集合s压入栈stack中;
步骤2.3.2:从stack中pop出一个种子节点sk,遍历sk的邻居节点;
步骤2.3.3:判断邻居节点j是否在stack中,如果否,判断邻居节点j是否满足公式3;
步骤2.3.4:如果满足,则将该邻居节点push到stack中,并标记该节点所属的种子节点;
步骤2.3.5:判断stack是否为空,如果是,则结束算法,如果否,则重复执行算法的步骤2.3.2~2.3.4。
本发明的技术构思为:首先采集整个传感器网络的数据,然后随机选取节点为种子节点,接着利用区域生长法将传感器网络部署区域进行划分,划分后每个子区域中的传感器节点采集的数据相似,最后根据子区域采集的历史数据选择一个代表节点,代表节点采集的数据与该子区域的历史数据的变化趋势相似性最高。本发明提出的方法能够保证区域监测正常的情况下减少大量的冗余数据,因此能够较大幅度的延长传感器网络的生存时间。
本发明的有益效果主要表现在:(1)本发明的区域生长法在wln数据采集时减少了大量冗余数据的采集;(2)发明提出的数据采集算法能够较大幅度的延长传感器网络的生存时间。
附图说明
图1是本发明的无线传感器感知范围图。
图2是区域生长法区域生长原理图。
图3是本发明的区域生长法的区域生长图。
图4是本发明的历史数据曲线图。
图5是一种基于区域生长法的wsn数据采集方法的流程图。
具体实施方式
下面结合附图进一步说明本发明。
参照图1~图5,一种基于区域生长法的wsn数据采集方法,包括如下步骤:
步骤1:传感器网络假设与定义,过程如下:
步骤1.1:传感器网络相关假设;
步骤1.1.1:传感器网络中节点的位置已经通过gps、wsn定位等方法获取,且在小范围内,传感器节点采集的数值大小接近。如无线传感器网络采集树林中的温度,在小范围内温度值都是非常接近的。
步骤1.1.2:传感器网络中所有节点同构,每个节点的初始能量相同且都为e0。
步骤1.1.3:本发明提出的数据采集算法需要变更路由,但这不是本发明的重点,假设无线传感器网络拓扑结构变化时,能够自行重新组织路由。
步骤1.1.4:本发明将n个传感器节点均匀部署在一个长为l,宽为h的矩形区域中。
步骤1.2:传感器网络相关定义;
相邻传感器节点的定义,传感器节点的感知半径为r,如图1所示,传感器节点i采集的数据能够代表感知范围内任一数据采样点的数据信息,因此本发明对传感器节点i的相邻传感器节点的定义n(i,j)如公式(1)所示:
公式(1)中n(i,j)为1则表示节点i与节点j相邻,为0则表明节点i与节点j不相邻,ed(i,j)为欧式距离。
步骤2:区域生长法划分相似区域,过程如下:
步骤2.1:区域生长法划分相似区域定义,根据步骤1.1所述,小范围内传感器网络采集的数据趋向一致性,因此本发明通过区域生长算法将数据接近的区域进行划分,然后在该区域内选择一个代表节点,该代表节点采集的数据与该子区域的数值和数据变化趋势最接近,然后将代表节点的数据传输至服务器端,利用代表节点采集的数据代表子区域的数据;
步骤2.2:区域生长法种子节点的选择,种子节点的选取主要考虑分布均匀原则,种子节点在传感器网络部署区域中分布均匀,才能全面的采集部署区域的信息。本发明采用随机数方法选取种子节点,传感器网络中每个传感器节点k都能生成一个(0,1)之间均匀分布的随机数rand(k),当rand(k)大于阈值t时,则该节点称为种子节点,阈值t如公式(2)所示:
t=1-p(2)
公式(2)中p为传感器网络中需要选取种子节点的百分比。
由于本发明的随机数满足均匀分布,因此选择的种子节点能够均匀分布在部署区域中,保证了监测区域的完整性。
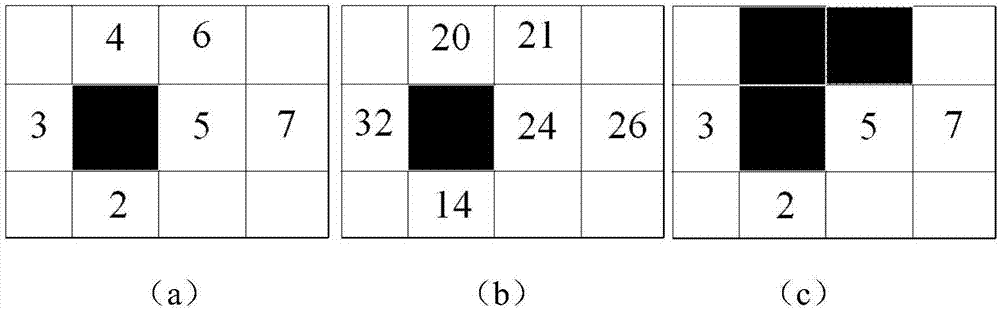
步骤2.3:区域生长法相似区域生长过程,传统的区域生长法一般用于图像分割,如图2所示,图2(a)为像素点编号,图2(b)为像素点对应的像素值,首先从种子点1开始生长,判断种子点四领域(2、3、4、5号像素点)的像素点与种子点像素值之差的绝对值是否小于一定阈值(这里阈值为1),如果小于阈值,则往该像素点方向生长,最终结果如图2(c)所示,区域第一步向4号像素点生长,接着以4号节点为种子节点,向6号像素点生长,直到达到区域生长结束条件,算法停止迭代,完成区域生长。区域生长后,同一片区域的像素值大小非常接近。
上述介绍了区域生长法在图像分割中的应用,发现区域生长经过后同样可以应用于wsn相似区域生长问题,在wsn网络中并不采用图像中的四邻域或八邻域等,而是采用相邻传感器节点作为区域生长法的邻域,可通过公式1判断传感器节点是否相邻。
在初始时刻,传感器网络已经采集了一部分数据,假设节点j采集的数据为dataj={d1,d2,d3......dm},j∈[1,n],且节点j是种子节点i的相邻传感器节点,当节点j满足公式(3)时,区域向节点j方向生长。
|avg(dataj)-avg(datai)|≤td(3)
公式(3)中td为阈值,可根据实际情况取值,avg为求集合元素平均值的函数,datai是种子节点采集的历史数据。
通过步骤2.2方法选择的种子节点编号集合为s={s1,s2,s3...sk...ssum},最终传感器网络被分割为sum个子区域,如图3所示,每个子区域中的传感器节点采集的数据信息相似性较高。
步骤3:子区域内代表节点的选取,过程如下:
步骤3.1:曲线相似性描述方法的提出,在步骤2中了传感器网络节点相似区域划分方法,本步骤主要在子区域中选择一个代表节点,该代表节点采集的数据能够代表整个子区域的数据信息,因此代表节点采集的数据应该与整个子区域的传感器节点采集的数据大小最接近且数据变化趋势也最符合。
代表节点的历史数据曲线a与子区域中所有传感器节点历史数据均值曲线b应该满足以下两种情况之一:
1)曲线a与曲线b的变化趋势始终一致,且数值大小最接近。
2)曲线a与曲线b初始时刻趋势不一致,且数值大小也不一定接近,但是到后来两条曲线逐渐逼近,且数值大小也越来越接近。
上述两种情况如图4所示,由于随着环境信息的改变,传感器节点采集的数据也会随之改变,因此初始时刻曲线a与曲线b不吻合,但是随着时间的推移,代表节点的历史数据曲线a可能与曲线b吻合程度较好。
针对上述两种曲线相似情况,提出了一种适宜的曲线相似性描述方法,假设某个子区域的历史数据均值曲线b可描述为点集合avg_data={y1,y2,y3...yt...ym},m为历史数据数量,子区域中一个传感器节点的历史数据曲线a可描述为点集合data={y1,y2,y3...yt...ym},则曲线a与b的相似度计算方法如公式(4)所示。
公式(4)中h为子区域中传感器节点的数量,g是一个常数,表示误差范围,s表示曲线相似度,s越接近1,表明两条曲线的相似度越高,而且该相似度计算公式为较后面的历史数据分配的权重值越大,因此能够较好的适用于本发明中曲线相似度的描述。
步骤3.2:子区域中选择代表节点,过程如下:
步骤3.2.1:求子区域中所有传感器节点(h个节点)每个时刻采集数据的平均值,即计算avg_data;
步骤3.2.2:遍历子区域中所有传感器节点,并利用公式4计算每个传感器节点的历史数据曲线集合data与集合avg_data的相似度,选择相似度最高的传感器节点为代表节点。
步骤4:算法迭代,通过步骤2和步骤3已经完成了相似区域的划分和代表节点的选择,最后传感器网络只需要将代表节点采集的数据传输至服务器即可完成对整个区域的信息采集,该过程是一轮完整的数据采集过程。为了使代表节点采集的数据能够更准确的代表子区域的信息以及均衡传感器节点能耗,本发明的数据采集算法运行一定时间后会重新进行下一轮数据采集过程,即相似区域划分以及代表节点选择。
- 还没有人留言评论。精彩留言会获得点赞!