Miller编码的解码方法以及RFID阅读器与流程
本发明涉及射频识别(rfid,radiofrequencyidentification)技术领域,尤其涉及一种miller编码的解码方法以及rfid阅读器。
背景技术:
rfid是一种非接触式自动识别技术:读写器利用射频信号自动识别电子标签,并与电子标签进行信息交换。目前,rfid技术是物联网的关键技术之一,具有广泛的应用前景。
为了使信号更适于信道传输,通常需要在传输过程中对基带信号进行编码。iso18000-6c(epcc1gen2)和gb/t29768协议都规定fm0和miller编码可以作为反向链路的编码方式,并且miller编码选用的系数m可以是2、4和8。iso18000-6c(epcc1gen2)和gb/t29768协议规定,miller编码包括前导码和数据编码两部分,前导码由固定周期的数字信号以及符合miller编码规则的数字信号组成。本发明中,将这些固定周期的数字信号称为同步时钟信号,将符合miller编码规则的数字信号称为数据信号。
根据iso18000-6c(epcc1gen2)和gb/t29768协议规定,当miller编码的系数m分别为2、4、8时,分别使用2、4、8个副载波周期传输1bit数据。miller编码序列由前导码开始,并由一个冗余符号“1”结束。前导码可由4bit或16bit长度的同步时钟信号和若干比特的数据信号组成。该若干比特的数据信号在iso18000-6c(epcc1gen2)协议中被确定为6bit的“010111”,在gb/t29768协议中被确定为8bit的“00111101”。
iso18000-6c(epcc1gen2)协议规定,由于反向链路频率不同,允许反向链路频率存在±4%~±22%的误差。gb/t29768协议规定,允许反向链路频率存在±20%的误差。在实际的电路中,由于信号传输的不稳定性,部分信号的频率误差会大于上述限定误差。这会导致时钟同步出现困难,并且增加了解码的难度。
信号在传输过程中由于电路或信道干扰等原因会产生畸变和异常跳变,从而导致信号占空比出现偏移,正常信号中混杂干扰信号,甚至出现一些滤波器无法滤除的带外干扰信号、毛刺等。这增加了解码的难度,导致解码率和识别率下降,并且无法通过判断信号宽度等方法对信道输出的数字信号进行解码。
技术实现要素:
根据本发明的一个方面,提供一种miller编码的解码方法,包括以下步骤:
根据链路频率生成miller编码序列模板;
在输入的miller编码序列中查找前导码;
通过所述前导码校准所述编码序列模板,使之符合实际输入的链路频率;
将所述输入的miller编码序列与所述编码序列模板进行匹配以完成数据解码。
如上所述的方法,其中,所述在输入的miller编码序列中查找前导码的步骤包括:在输入的miller编码序列中查找前导码中的同步时钟信号和数据信号的步骤。
如上所述的方法,其中,所述通过前导码校准编码序列模板的步骤包括:通过所述同步时钟信号计算并调整实际链路频率,并根据此实际链路频率调整所述编码序列模板的步骤。
如上所述的方法,其中,所述将输入的miller编码序列与所述编码序列模板进行匹配的步骤包括:找到相似度最大的编码符号,并通过将所述编码序列向前和向后偏移起始比较位置的方式,对所述编码序列模板进行多次匹配,从中选择相似度最大值,并判断该值是否超出门限值,依此方法匹配出符合要求的编码符号,以完成数据解码。
如上所述的方法,其中,所述通过前导码校准编码序列模板的步骤包括使用整个前导码或部分前导码校准所述编码序列模板的符号宽度的步骤,所述校准的步骤包括:先找到正确的前导码再校准所述编码序列模板,或者一边通过已输入的前导码校准所述编码序列模板,一边查找前导码。
如上所述的方法,其中,所述查找前导码中的同步时钟信号的步骤是通过判断编码信号的高电平和低电平宽度是否在同步时钟信号允许的时间范围内的方式进行的。
如上所述的方法,其中,所述查找前导码中的数据信号的步骤是通过判断编码信号的高电平和低电平宽度是否超出同步时钟信号允许的时间范围的方式进行的,包括查找第一个宽电平,并将前导码的数据信号中第一个电平信号作为对齐位置,将输入编码序列与前导码中的数据信号进行匹配,并判断是否在输入编码序列中找到正确的前导码。
如上所述的方法,其中,所述通过同步时钟信号计算实际链路频率的步骤包括通过部分或全部同步时钟信号计算码长的步骤。
如上所述的方法,其中,所述将输入的miller编码序列与所述编码序列模板进行匹配的步骤是根据miller编码特性,根据上一次解码结果和编码符号之间的相关性,只选择下一次可以出现的编码符号进行匹配。
如上所述的方法,其中,所述将输入的miller编码序列与所述编码序列模板进行匹配的步骤,包括对整个编码序列模板进行匹配或者对编码序列模板中的部分进行匹配的步骤。
如上所述的方法,其中,所述将输入编码序列向前和向后偏移起始比较位置的步骤中,其偏移次数和偏移距离是可变的。
如上所述的方法,其中,所述门限值可以使用静态值,也可以根据信道质量进行动态调整。
根据本发明的另一方面,提供一种rfid阅读器,包括采样单元和计算单元,其中,所述采样单元对编码数据进行采样,采样输出为输入编码信号的所有高电平和低电平宽度序列,所述计算单元将输入的电平宽度序列与miller编码符号集中的各编码符号对应的编码序列模板进行匹配,选择相似度最大的编码符号对应的原始二进制数据作为输出的方法进行解码。
如上所述的rfid阅读器,其中,所述计算单元采用以上所述的miller编码的解码方法对miller编码进行数据解码。
根据本发明提出的miller编码的解码方法及采用该方法的rfid阅读器,其中,输入数据为编码序列中各高电平和低电平宽度信息(下文简称为“输入的电平宽度序列”),输出数据为原始二进制序列数据。将输入的电平宽度序列与miller编码符号集中的各编码符号对应的编码序列模板(“编码序列模板”为本申请中的特有名词,指用于匹配编码符号的,由一组表示电平宽度数据组成的一个向量)进行匹配,选择相似度最大的编码符号对应的原始二进制数据作为输出的方法进行解码,解决了正常信号中混杂干扰信号、毛刺等问题。
附图说明
附图是为提供对本公开内容的进一步的理解。附图示出了本公开内容的实施例,并与本说明书一起起到解释本公开内容原理的作用。在结合附图并阅读了下面的对特定的非限制性本公开内容的实施例之后,本公开内容的技术方案及其优点将变得显而易见。其中:
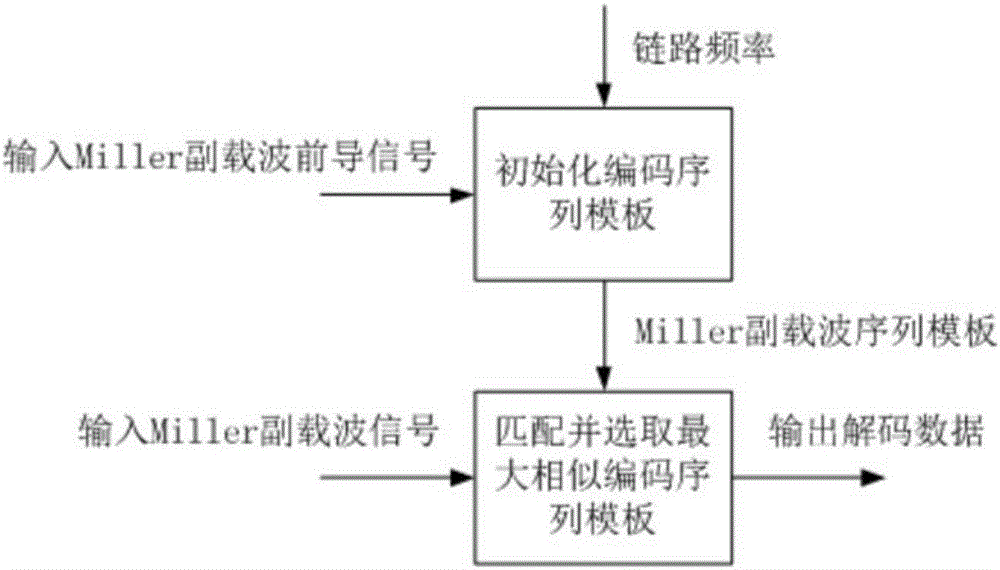
图1a和1b分别示出了根据本发明的miller编码的解码方法的方块示意图和流程示意图。
图2a至2c分别示出了根据本发明的一个实施例的miller编码中各符号的编码序列,图中列举了编码系数m分别为2、4、8时,miller编码中各符号的编码序列。
图3示出了符合gb/t29768协议的编码系数m为2的miller编码副载波序列示例。
图4a示出了根据本发明的一个实施例的miller编码的解码方法中,在输入的miller编码序列中查找前导码的流程图。
图4b示出了根据本发明的一个实施例的miller编码的解码方法中,对数据信号进行解码的流程图。
图5是表示根据本发明另一个实施例的miller编码的解码方法的流程示意图。
图6是表示根据本发明另一个实施例的一个符合gb/t29768协议的具体实例的miller编码的解码方法的示意图。
图7是表示一个rfid阅读器的示意图。
具体实施方式
参考在附图中示出和在以下描述中详述的非限制性实施例,更完整地说明本公开内容的多个技术特征和有利细节。并且,以下描述忽略了对公知的原始材料、处理技术、组件以及设备的描述,以免不必要地混淆本公开内容的技术要点。然而,本领域技术人员能够理解到,在下文中描述本公开内容的实施例时,描述和特定示例仅作为说明而非限制的方式来给出。
在任何可能的情况下,在所有附图中将使用相同的标记来表示相同或相似的部分。此外,尽管本公开内容中所使用的术语是从公知公用的术语中选择的,但是本公开内容的说明书中所提及的一些术语可能是公开内容人按他或她的判断来选择的,其详细含义在本文的描述的相关部分中说明。此外,要求不仅仅通过所使用的实际术语,而是还要通过每个术语所蕴含的意义来理解本公开内容。
本发明提出一种符合iso18000-6c(epcc1gen2)和gb/t29768协议定义的在uhf阅读器上使用的miller编码的解码方法。本领域技术人员可以理解的是,该解码方法也适用于其他类似的miller码的解码。本解码方法的输入数据为编码序列中各高电平和低电平宽度信息(下文简称为“输入的电平宽度序列”),输出数据为原始二进制序列数据。
图1a和1b分别示出了根据本发明的miller编码的解码方法的方块示意图和流程示意图。结合参见图1a和1b,根据本发明的miller编码的解码方法包括:步骤s1:根据链路频率生成miller编码序列模板;步骤s2:在输入的miller编码序列中查找前导码;步骤s3:通过所述前导码校准所述编码序列模板,使之符合实际输入的链路频率;步骤s4:将所述输入的miller编码序列与所述编码序列模板进行匹配以完成数据解码。
图2a至2c分别示出了根据本发明的一个实施例的miller编码中各符号的编码序列,图中列举了编码系数m分别为2、4、8时,miller编码中各符号的编码序列。图3示出了符合gb/t29768协议的编码系数m为2的miller编码副载波序列示例。图4a示出了根据本发明的一个实施例的miller编码的解码方法中,在输入的miller编码序列中查找前导码的流程图;图4b示出了根据本发明的一个实施例的miller编码的解码方法中,对数据信号进行解码的流程图。
结合参见图2a至2c、图3和图4a,步骤s11:根据反向链路频率生成miller编码序列模板,模板内容如图2a至2c所示,miller2、miller4、miller8均有4个编码序列模板,分别表示编码符号a、b、c、d,其中a和b代表二进制数据1,c和d代表二进制数据0,根据miller编码规定:每一个编码序列都和前一个编码序列有关,前导码结束后只能出现编码符号a和c,并且a后面只能出现b和c,b后面只能出现a和d,c后面只能出现b和d,d后面只能出现a和c。步骤s12:在输入的miller编码序列中查找前导码,并在查找前导码时,先查找前导码中的时钟信号,在接收到足够长的前导码后(在本例中miller2为3个链路周期,miller4为6个链路周期,miller8为12个链路周期),再查找前导码中的数据信号。步骤s13:查找前导码中的时钟信号时,需要先判断输入的时钟信号频率是否符合链路频率限定范围,如果判断结果为符合限定范围则流程进入步骤s14:使用这些时钟信号校准miller编码序列模板;如果判断结果为不符合限定范围,则流程返回步骤s12,重新开始查找前导码。接下来,在查找前导码中的数据信号时(iso18000-6c(epcc1gen2)协议中定为6bit的“010111”,gb/t29768协议中定为8bit的“00111101”),步骤s15:先判断输入的编码序列是否仍是时钟信号,如果是时钟信号,则流程返回步骤s13,继续判断输入的时钟信号频率是否符合链路频率限定范围,并继续使用这些时钟信号校准miller编码序列模板;如果步骤s15判断输入的编码序列不是时钟信号,则流程进入步骤s16:判断输入的编码序列是否为数据信号,如果找到正确的完整的前导码数据信号,则流程在步骤s17结束前导码查找过程,并进入数据解码,如果步骤s16判断输入的编码序列既不是时钟信号,也不是前导码数据信号,则认为接收到无法识别的编码符号,流程返回步骤s12,重新开始查找前导码。
接下来,结合参见图2a至2c、图3和图4b,前导码查找结束后,开始解码数据部分,步骤s21,根据上一次接收到的编码符号,选择相应的编码序列模板;步骤s22,将编码序列模板与输入的miller编码序列进行匹配,即,例如在输入的miller编码序列中从上一个编码结束位置开始截取(如果是前导码后的第一个数据信号,则从前导码结束位置开始截取)一段与miller编码序列模板长度一样的编码序列与miller编码序列模板中的部分编码序列模板进行匹配。根据之前的描述,如果上一次接收到的编码符号是a,则本次只需要匹配编码序列符号b和c,如果是b则只需要匹配a和d,如果是c则只需要匹配b和d,如果是d则只需要匹配a和c,因此只需要匹配两个编码序列模板即可。步骤s23,将输入的编码序列与这两个编码序列模板匹配时,将截取的miller编码序列与编码序列模板的相似度作为匹配结果,相似度的计算方法为:s=(l-d)/l,其中s为相似度,l为编码序列模板的编码长度(单位为秒),d为截取的编码序列与编码序列模板电平方向不同的编码长度(单位为秒)。步骤s24,选取相似度较大的匹配结果r1作为本次匹配结果,与其对应的编码序列模板作为本次匹配选取的编码序列模板。步骤s25,再将该编码序列模板与输入的编码序列进行4次比较,分别将编码序列模板在输入的miller编码序列上偏移-0.0625、-0.03125、0.03125、0.0625个链路周期后再进行比较,每一次比较时都将输入的miller编码序列与编码序列模板的相似度作为比较结果,4次的比较结果分别为r2、r3、r4、r5。步骤s26,从r1、r2、r3、r4、r5中选取相似度最大的比较结果作为匹配结果r。步骤s27,流程判断该匹配结果r是否小于0.85,如是,则在步骤29认为本次匹配失败,没有找到合理的编码序列,解码结束;如否,则在步骤s28认为本次匹配成功,本次匹配选取的编码序列模板即为本次成功匹配的结果。流程循环执行以上步骤直至所有输入编码序列解码完毕,或发现无法识别的编码符号,然后结束解码流程。
图5是表示根据本发明另一个实施例的miller编码的解码方法的流程示意图。其中,先根据理想链路频率在输入信号中查找前导码中的同步时钟信号。在接收到足够长的同步时钟信号之后,根据这些同步时钟信号计算实际链路频率。然后,查找前导码中的数据信号。在正确接收前导码之后,再次根据前导码中的所有同步时钟信号计算实际链路频率。然后,对输入的编码信号依次进行数据解码。数据解码的基本方法如下:将输入的电平宽度序列与miller编码符号集中各编码符号所对应的编码序列模板进行匹配,选择相似度最大的编码符号所对应的原始二进制数据作为输出。
具体地,本发明提出的miller编码的解码方法的基本步骤为:根据理想链路频率为miller编码的所有符号生成编码序列模板。通过定时器对编码数据进行采样(整个解码过程中,采样频率为固定值),采样输出为所有输入编码信号的高电平和低电平宽度序列。在输入的电平宽度序列中查找前导码中的同步时钟信号。通过前导码中的同步时钟信号来计算实际链路频率,并据此调整编码序列模板,以使之符合实际链路频率,解决了解码时位同步问题。在输入的电平宽度序列中查找前导码中的数据信号,并对该数据信号进行解码。当前导码中的数据全部接收成功之后,再次用前导码中的同步时钟信号和数据信号计算实际链路频率,并据此调整编码序列模板。在查找前导码结束之后,依次对输入的miller编码的数据编码进行数据解码。其中,将采样输出的电平宽度序列(包含高电平宽度和低电平宽度)与miller编码的符号集中相应符号的编码序列模板进行匹配,并选择相似度最大的编码符号所对应的二进制序列数据作为解码输出。在对应的原始二进制数据与编码序列模板进行匹配时,通过将起始比较位置向前或向后偏移一段距离,从中选择最大相似度值作为此编码符号的本次匹配结果,解决了解码时链路频率时钟累计误差导致的位同步问题。
接下来,结合参见图1a至1b、图2a至2c、图3和图5对本发明另一个实施例的miller编码的解码方法作进一步的详细描述。根据本申请的一个实施例,本发明提出的解码方法具体包括以下步骤:
s51:为miller编码的所有符号生成编码序列模板。根据iso18000-6c(epcc1gen2)和gb/t29768协议规定,miller编码各符号的编码序列如图2所示。miller编码包括4种符号,分别为a、b、c、d。其中,a和b代表输出数据1,c和d代表输出数据0。并且前后两个符号具有相关性,前导码结束后只能出现符号a和c,并且a后面只能出现b和c,b后面只能出现a和d,c后面只能出现b和d,d后面只能出现a和c。
miller2编码符号集中各符号的码字如下(miller2、miller4、miller8分别指系数m为2、4、8的miller编码):
符号a的码字为:“1010”,符号b的码字为:“0101”;符号c的码字为:“1001”;符号d的码字为:“0110”。
miller4符号集的各符号的码字如下:
码字a的码字为:“10101010”;码字b的码字为:“01010101”;码字c的码字为:“10100101”;码字d的码字为:“01011010”。
miller8符号集的各符号的码字如下:
码字a的码字为:“1010101010101010”;码字b的码字为:“0101010101010101”;码字c的码字为:“1010101001010101”;码字d的码字为:“0101010110101010”。
在一个实施例中,根据编码系数和理想链路频率生成编码序列模板。编码序列模板通过向量来表示,由(m×2-1)个或(m×2)个(m为编码系数,取值可为2、4、8)带符号整数组成。在一个优选的实施例中,miller2编码序列模板可表示为p=(a1,a2,a3)或p=(a1,a2,a3,a4),miller4编码序列模板可表示为p=(a1,a2,a3,a4,a5,a6,a7)或p=(a1,a2,a3,a4,a5,a6,a7,a8),miller8编码序列模板可表示为p=(a1,a2,a3,a4,a5,a6,a7,a8,a9,a10,a11,a12,a13,a14,a15)或p=(a1,a2,a3,a4,a5,a6,a7,a8,a9,a10,a11,a12,a13,a14,a15,a16),其中ai表示编码符号的第i个高电平或低电平的宽度,单位为秒,正数表示高电平,负数表示低电平。例如,当理想链路频率为fd(单位为hz)时,miller2编码符号集的各编码符号的编码序列模板可表示为如下:
编码符号a的编码序列模板为:pa=(0.5/fd,-0.5/fd,0.5/fd,-0.5/fd);
编码符号b的编码序列模板为:pb=(-0.5/fd,0.5/fd,-0.5/fd,0.5/fd);
编码符号c的编码序列模板为:pc=(0.5/fd,-1/fd,0.5/fd);
编码符号d的编码序列模板为:pd=(-0.5/fd,1/fd,-0.5/fd)。
miller4编码符号集的各编码符号的编码序列模板可表示为如下:
编码符号a的编码序列模板为:pa=(0.5/fd,-0.5/fd,0.5/fd,-0.5/fd,0.5/fd,-0.5/fd,0.5/fd,-0.5/fd);
编码符号b的编码序列模板为:pb=(-0.5/fd,0.5/fd,-0.5/fd,0.5/fd,-0.5/fd,0.5/fd,-0.5/fd,0.5/fd);
编码符号c的编码序列模板为:pc=(0.5/fd,-0.5/fd,0.5/fd,-1/fd,0.5/fd,-0.5/fd,0.5/fd);
编码符号d的编码序列模板为:pd=(-0.5/fd,0.5/fd,-0.5/fd,1/fd,-0.5/fd,0.5/fd,-0.5/fd)。
miller8编码符号集的各编码符号的编码序列模板可表示为如下:
编码符号a的编码序列模板为:pa=(0.5/fd,-0.5/fd,0.5/fd,-0.5/fd,0.5/fd,-0.5/fd,0.5/fd,-0.5/fd,0.5/fd,-0.5/fd,0.5/fd,-0.5/fd,0.5/fd,-0.5/fd,0.5/fd,-0.5/fd);
编码符号b的编码序列模板为:pb=(-0.5/fd,0.5/fd,-0.5/fd,0.5/fd,-0.5/fd,0.5/fd,-0.5/fd,0.5/fd,-0.5/fd,0.5/fd,-0.5/fd,0.5/fd,-0.5/fd,0.5/fd,-0.5/fd,0.5/fd);
编码符号c的编码序列模板为:pc=(0.5/fd,-0.5/fd,0.5/fd,-0.5/fd,0.5/fd,-0.5/fd,0.5/fd,-1/fd,0.5/fd,-0.5/fd,0.5/fd,-0.5/fd,0.5/fd,-0.5/fd,0.5/fd);
编码符号d的编码序列模板为:pd=(-0.5/fd,0.5/fd,-0.5/fd,0.5/fd,-0.5/fd,0.5/fd,-0.5/fd,1/fd,-0.5/fd,0.5/fd,-0.5/fd,0.5/fd,-0.5/fd,0.5/fd,-0.5/fd)。
当编码系数m=2、理想链路频率fd=320khz时,编码序列模板pa=(0.5/fd,-0.5/fd,0.5/fd,-0.5/fd)=(0.5/(320khz),-0.5/(320khz),0.5/(320khz),-0.5/(320khz))=(1.5625us,-1.5625us,1.5625us,-1.5625us,),pb=(-1.5625us,1.5625us,-1.5625us,1.5625us,),pc=(1.5625us,-3.125us,1.5625us,),以及pd=(-1.5625us,3.125us,-1.5625us,)。在本发明中,编码长度l表示一段编码信号序列的总长度,单位为秒。那么,la、lb、lc、ld分别表示编码序列模板pa、pb、pc、pd的编码长度。lx=|a1|+|a2|+|a3|+……+|an|(n为编码序列模板的向量长度),lx取值于{la、lb、lc、ld},则当p=(a1,a2,a3)时,lx=|a1|+|a2|+|a3|;当p=(a1,a2,a3,a4)时,lx=|a1|+|a2|+|a3|+|a4|。当编码系数m和链路速率固定不变时,pa、pb、pc、pd的编码长度均相等,即la、lb、lc、ld四个值均相等。
s52:通过定时器对编码数据进行采样,采样输出为输入编码信号的所有高电平和低电平宽度序列。
s53:在输入的电平宽度序列中查找前导码中的同步时钟信号。
在一个优选的实施例中,使用以下方法来查找前导码中的同步时钟信号:依次判断输入的电平宽度序列中的各电平(高电平或低电平)宽度是否在允许的时间范围内。
同步时钟信号的电平宽度允许的时间范围为:(1+rd-50%)/(fd×2×(1+rf)),fd为理想链路频率(单位为hz),rf为频率允许误差的上下限,rd为占空比上下限。根据iso18000-6c(epcc1gen2)和gb/t29768协议规定,rd通常为45%~55%。在一个实施例中,当fd为320khz且rf为-20%~20%时,允许的时间范围为(1+45%-50%)/(0.32×2×(1+20%))~(1+55%-50%)/(0.32×2×(1-20%))微秒,即≈1.237~2.051微秒。
当找到一段连续的、足够长并且高电平和低电平宽度均在允许的时间范围内的编码信号时,认为该段编码信号为同步时钟信号。在一个实施例中,当编码系数m分别取2、4、8时,查找到的连续同步时钟信号必须分别至少满足6个、12个和24个电平信号(高电平与低电平信号个数的总和),才认为找到有效的同步时钟信号。
s54:通过前导码中的同步时钟信号来计算实际链路频率,并据此调整编码序列模板。通过前导码中的同步时钟信号计算实际链路频率,解决了解码时位同步问题(解码过程中,采样频率为固定值)。
如果查找到的同步时钟信号的电平信号(高电平与低电平信号个数的总和)个数为n(n取偶数,如果找到奇数个符合要求的电平信号,则n=电平信号个数-1),并且n个电平信号的总长度为tc(单位为秒),则实际链路频率fr=n/(tc×2)。在一个优选的实施例中,当编码系数m分别取2、4、8时,n的取值范围可以分别为:3-8、6-16、12-32。
接下来,根据实际链路频率fr来调整编码序列模板,以使之符合实际链路频率。调整后的编码序列模板如下:
miller2的编码序列模板如下:
编码符号a的编码序列模板为:pa'=(0.5/fr,-0.5/fr,0.5/fr,-0.5/fr);
编码符号b的编码序列模板为:pb'=(-0.5/fr,0.5/fr,-0.5/fr,0.5/fr);
编码符号c的编码序列模板为:pc'=(0.5/fr,-1/fr,0.5/fr);
编码符号d的编码序列模板为:pd'=(-0.5/fr,1/fr,-0.5/fr)。
miller4的编码序列模板如下:
编码符号a的编码序列模板为:pa'=(0.5/fr,-0.5/fr,0.5/fr,-0.5/fr,0.5/fr,-0.5/fr,0.5/fr,-0.5/fr);
编码符号b的编码序列模板为:pb'=(-0.5/fr,0.5/fr,-0.5/fr,0.5/fr,-0.5/fr,0.5/fr,-0.5/fr,0.5/fr);
编码符号c的编码序列模板为:pc'=(0.5/fr,-0.5/fr,0.5/fr,-1/fr,0.5/fr,-0.5/fr,0.5/fr);
编码符号d的编码序列模板为:pd'=(-0.5/fr,0.5/fr,-0.5/fr,1/fr,-0.5/fr,0.5/fr,-0.5/fr)。
miller8的编码序列模板如下:
编码符号a的编码序列模板为:pa'=(0.5/fr,-0.5/fr,0.5/fr,-0.5/fr,0.5/fr,-0.5/fr,0.5/fr,-0.5/fr,0.5/fr,-0.5/fr,0.5/fr,-0.5/fr,0.5/fr,-0.5/fr,0.5/fr,-0.5/fr);
编码符号b的编码序列模板为:pb'=(-0.5/fr,0.5/fr,-0.5/fr,0.5/fr,-0.5/fr,0.5/fr,-0.5/fr,0.5/fr,-0.5/fr,0.5/fr,-0.5/fr,0.5/fr,-0.5/fr,0.5/fr,-0.5/fr,0.5/fr);
编码符号c的编码序列模板为:pc'=(0.5/fr,-0.5/fr,0.5/fr,-0.5/fr,0.5/fr,-0.5/fr,0.5/fr,-1/fr,0.5/fr,-0.5/fr,0.5/fr,-0.5/fr,0.5/fr,-0.5/fr,0.5/fr);
编码符号d的编码序列模板为:pd'=(-0.5/fr,0.5/fr,-0.5/fr,0.5/fr,-0.5/fr,0.5/fr,-0.5/fr,1/fr,-0.5/fr,0.5/fr,-0.5/fr,0.5/fr,-0.5/fr,0.5/fr,-0.5/fr)。
s55:在输入的电平宽度序列中查找前导码中的数据信号,并对该数据信号进行解码。
在一个实施例中,可以使用以下方法来查找前导码中的数据信号:
根据gb/t29768协议定义,前导码中的数据信号为8bit的二进制数“00111101”。在找到同步时钟信号之后,依次判断输入的电平宽度序列中的各电平(高电平或低电平)宽度是否超出同步时钟信号允许的时间范围上限。如果电平宽度没有超出同步时钟信号允许的时间范围上限,则认为该信号仍然是同步时钟信号。
如果电平宽度超出同步时钟信号允许的时间范围上限,则将该电平作为数据信号中的第一个宽电平。根据iso18000-6c(epcc1gen2)和gb/t29768协议规定,miller2的第一个宽电平(也是前导码数据信号的第一个宽电平)在同步时钟信号结束后的第四个电平,并且为低电平。即miller2同步时钟信号的最后一个电平后面第四个电平是一个宽电平,并且是前导码数据信号的第一个宽电平。miller4的第一个宽电平在同步时钟信号最后一个电平后的第八个电平,miller8的第一个宽电平在同步时钟信号最后一个电平后的第十六个电平。
接下来输入的信号是前导码中的数据信号,继续对输入的电平宽度序列进行解码。解码方法为:在输入的电平宽度序列中,从上一个编码结束位置(如果是第一个数据编码,则从同步时钟信号的结束位置)开始依次截取一段长度为la'(la'为编码序列模板pa'的编码长度)的电平宽度序列数据,与前导码中数据信号的编码符号(符合iso18000-6c(epcc1gen2)和gb/t29768协议规定)进行匹配,将该电平宽度序列与该编码符号对应的编码序列模板进行匹配,根据前导码中编码符号对应编码序列模板,计算该电平宽度序列与编码序列模板的相似度。本领域技术人员可以理解的是,匹配时只需要将电平宽度序列与有前后相关性的编码符号的编码序列模板进行匹配即可(编码符号的前后相关性具体在s1中已详细说明,例如前面一个符号是b,则本次需要进行匹配的符号只有a和d),不需要对所有编码序列模板都进行匹配。如果电平宽度序列与编码序列模板之间的相似度大于指定门限值,则认为匹配数据信号成功。在一个实施例中,该门限值为:85%×la'(la'为编码序列模板pa'的编码长度)。如果匹配失败,则继续判断下一个输入的电平宽度数据,直到找到正确的数据信号或者匹配失败的次数达到阈值。在一个实施例中,如果匹配失败的次数达到4次,则认为本次解码失败。
在一个优选的实施例中,输入的电平宽度序列与编码序列模板的相似度计算方法如下:从输入的电平宽度序列中截取一段电平宽度序列数据。截取起始位置为上一次编码结束位置(如果是前导码中的第一个数据信号,则截取起始位置为同步时钟信号的结束位置),截取的数据长度为la',la'为编码序列模板pa'的编码长度。根据所截取的电平宽度序列数据生成一个向量,将其表示为vc=(b1,b2…bn),其中bi表示输入编码符号的电平宽度序列中第i个高电平或低电平的宽度,单位为秒,正数表示高电平,负数表示低电平。待匹配的编码序列模板表示为px,px取值于{pa',pb',pc',pd'}。
计算向量vc与向量px之间的距离dv,dv单位为秒,以统计两个编码信号序列中极性不一致的电平总宽度,则电平宽度序列与编码序列模板之间的相似度s=(la'-dv)/la',相似度取值范围为:0~100%。
在一个优选的实施例中,向量vc与向量px之间的距离dv的计算方法为:将向量vc与向量px中的数据映射到同一个一维坐标系中,映射方法为:将向量中的数据从一维坐标系的原点沿着正方向依次排列;计算在此坐标系中,两个向量的正负符号不一致的数据长度总和,单位为秒。
在另一个优选的实施例中,在对输入的电平宽度序列和编码序列模板进行匹配时,可以进行多次匹配。在每次匹配的过程中,当截取用于匹配的电平宽度序列数据时,截取的位置可以向前或向后偏移一小段距离。在一个实施例中,如果上一次的匹配失败,则可将截取的位置先向前移动两次la'/16的距离,再向后移动两次la'/16(以当前截取位置为基准)的距离,la'为编码序列模板pa'的编码长度,每次移动后都进行一次匹配,直至匹配成功。在对应的原始二进制数据与编码序列模板进行匹配时,通过将起始比较位置向前或向后偏移一段距离,从中选择最大相似度值作为此编码符号的本次匹配结果,解决了解码时链路频率时钟累计误差导致的位同步问题。
s56:当前导码中的数据全部接收成功之后,再次用前导码中的同步时钟信号和数据信号计算实际链路频率,并据此调整编码序列模板pa”,pb”,pc”,pd”,具体生成方法见s4中的说明。
如果本次前导码接收完毕后,查找到的前导码信号占链路周期的个数为n(编码系数m取2、4、8时,n的取值范围分别为:19-24、38-48、76-96),并且n个链路周期的前导码信号总长度为tc(单位为秒),则实际链路频率fr=n/tc。
根据实际链路频率调整编码序列模板的方法在s4中已详述,在此不再赘述。通过前导码中的同步时钟信号和数据信号计算实际链路频率,解决了解码时位同步问题(解码过程中,采样频率为固定值)。
s57:在查找前导码结束之后,依次对输入的miller编码的数据编码进行数据解码。
在一个实施例中,数据解码方法为:在输入的电平宽度序列中,从上一个编码结束位置开始截取一段长度为la”(la”为编码序列模板pa”的编码长度)的电平宽度序列数据,将该电平宽度序列与前导码中数据信号对应的编码序列模板进行匹配,计算该电平宽度序列与编码符号集中各编码序列模板的相似度(具体相关性规则见步骤s5中的描述),并从中选取相似度最大的编码序列模板,将其对应的编码符号的原始二进制数据作为输出。如果最大相似度小于指定门限值,则认为解码失败。在一个实施例中,该门限值为:85%×la”,la”为编码序列模板pa”的编码长度。将输入的电平宽度序列与miller编码符号集中的各编码符号对应的编码序列模板(“编码序列模板”为本申请中的特有名词,指用于匹配编码符号的,由一组表示电平宽度数据组成的一个向量)进行匹配,选择相似度最大的编码符号对应的原始二进制数据作为输出的方法进行解码,解决了正常信号中混杂干扰信号、毛刺等问题。
图6是表示根据本发明另一个实施例的一个符合gb/t29768协议的具体实例的miller编码的解码方法的示意图。参见图6,设编码系数m=2、理想链路频率fd=320khz,链路频率允许误差rf为-20%~20%,占空比上下限rd为45%~55%,实际接收到的编码宽度序列表示为vw,单位为微秒,vw=(1.4225,1.5425,1.6325,1.5325,1.6625,1.4825,1.6125,1.4525,1.5025,1.5225,1.6625,1.4925,1.5725,1.4925,1.5525,1.5725,1.5225,1.6225,1.6025,3.005,1.5025,1.4825,1.6825,1.5025,3.665,1.4725,1.6025,2.985,1.6225,1.4725,3.225,1.4825,1.5425,3.025,1.5225,1.6625,1.4225,1.6925,1.4825,1.6025,3.015,1.5825,1.6425,2.965,1.5825,1.4825,1.6325,1.5125,3.215,1.5825,1.4925,1.6425,1.4725,3.165,1.5025),vw中数据个数为55个。
设查找同步码时,同步时钟信号的连续电平信号个数必须大于等于6个,查找前导码数字信号时,相似度门限为≥80%,数据编码部分解码时,相似度门限为≥85%。所述miller编码的解码方法包括如下步骤:
s61:为miller编码的所有符号生成编码序列模板。
miller2的编码序列模板如下:
编码符号a的编码序列模板为:pa=(0.5/fd,-0.5/fd,0.5/fd,-0.5/fd)=(1.5625us,-1.5625us,1.5625us,-1.5625us);
编码符号b的编码序列模板为:pb=(-0.5/fd,0.5/fd,-0.5/fd,0.5/fd)=(-1.5625us,1.5625us,-1.5625us,1.5625us);
编码符号c的编码序列模板为:pc=(0.5/fd,-1/fd,0.5/fd)=(1.5625us,-3.125us,1.5625us);
编码符号d的编码序列模板为:pd=(-0.5/fd,1/fd,-0.5/fd)=(-1.5625us,3.125us,-1.5625us)。
s62:通过定时器对编码数据进行采样,采样输出为输入编码信号的所有高电平和低电平宽度序列。将定时器采集到的数据表示为vw。
s63:在输入的电平宽度序列中查找前导码中的同步时钟信号。
同步时钟信号的电平宽度允许的时间范围为:(1+rd-50%)/(fd×2×(1+rf)),其中fd为320khz,rf为-20%~20%,rd为45%~55%,则电平宽度允许的时间上限=(1+45%-50%)/(0.32×2×(1+20%))≈1.237微秒,电平宽度允许的时间下限=(1+55%-50%)/(0.32×2×(1-20%))≈2.051微秒。
在vw中依次查找宽度在1.237~2.051微秒之间的连续数据,可找到19个数据,依次为:1.4225,1.5425,1.6325,1.5325,1.6625,1.4825,1.6125,1.4525,1.5025,1.5225,1.6625,1.4925,1.5725,1.4925,1.5525,1.5725,1.5225,1.6225,1.6025,单位为微秒。19个数据满足对同步时钟信号的最小6个连续电平信号的要求,认为成功到同步时钟信号。
s64:通过前导码中的同步时钟信号来计算实际链路频率,并据此调整编码序列模板。
实际链路频率fr=n/(tc×2),n取值为18(由于找到的前导码同步信号为19个,是奇数,因此需要减1),tc=1.4225+1.5425+1.6325+1.5325+1.6625+1.4825+1.6125+1.4525+1.5025+1.5225+1.6625+1.4925+1.5725+1.4925+1.5525+1.5725+1.5225+1.6225微秒=27.855微秒=0.000027855秒,fr=18/(0.000027855×2)hz≈323.1018khz。
根据实际链路频率fr≈323.1018khz来调整编码序列模板,调整后的miller2的编码序列模板如下:
编码符号a的编码序列模板为:pa'=(0.5/fr,-0.5/fr,0.5/fr,-0.5/fr)≈(1.5475us,-1.5475us,1.5475us,-1.5475us);
编码符号b的编码序列模板为:pb'=(-0.5/fr,0.5/fr,-0.5/fr,0.5/fr)≈(-1.5475us,1.5475us,-1.5475us,1.5475us);
编码符号c的编码序列模板为:pc'=(0.5/fr,-1/fr,0.5/fr)≈(1.5475us,-3.095us,1.5475us);
编码符号d的编码序列模板为:pd'=(-0.5/fr,1/fr,-0.5/fr)≈(-1.5475us,3.095us,-1.5475us)。
s65:在输入的电平宽度序列中查找前导码中的数据信号,并对该数据信号进行解码。
在vw中找到第一个绝对值超出1.237~2.051微秒范围的数据,为-3.005微秒(在vw中第20个数据),将其作为作为数据信号中的第一个宽电平,根据gb/t29768协议定义,miller2的第一个宽电平(也是前导码数据信号的第一个宽电平)在同步时钟信号的最后一个电平后面的第四个电平是前导码数据信号的第一个宽电平,据此在vw中找到前导码同步时钟信号的最后一个电平为1.4925微秒(在vw中第16个数据),前导码数据信号的第一个电平为1.5225微秒(在vw中第17个数据)。
根据gb/t29768协议定义,miller2前导码数据信号的第一个电平为高电平。从编码宽度序列vw中将前导码数据信号和其后所有编码数据提取出来,并进行添加正负号处理,用表示编码序列的向量vc表示,vc中各项数据的数值表示编码序列的各电平宽度,单位为微秒,正负符号表示编码序列的各电平方向,正数表示高电平,负数表示低电平,则vc=(1.5225,-1.6225,1.6025,-3.005,1.5025,-1.4825,1.6825,-1.5025,3.665,-1.4725,1.6025,-2.985,1.6225,-1.4725,3.225,-1.4825,1.5425,-3.025,1.5225,-1.6625,1.4225,-1.6925,1.4825,-1.6025,3.015,-1.5825,1.6425,-2.965,1.5825,-1.4825,1.6325,-1.5125,3.215,-1.5825,1.4925,-1.6425,1.4725,-3.165,1.5025)。
根据实际链路速率fr≈323.1018khz,编码符号a的编码长度la'=2/fr≈6.19微秒(编码符号a、b、c、d的长度均相等)。
从vc中截取la'(6.19微秒)长度的数据,生成向量vd=(1.5225us,-1.6225us,1.6025us,-1.4425us),单位为微秒,剩余的待解码数据为vc'=(-1.5625,1.5025,-1.4825,1.6825,-1.5025,3.665,-1.4725,1.6025,-2.985,1.6225,-1.4725,3.225,-1.4825,1.5425,-3.025,1.5225,-1.6625,1.4225,-1.6925,1.4825,-1.6025,3.015,-1.5825,1.6425,-2.965,1.5825,-1.4825,1.6325,-1.5125,3.215,-1.5825,1.4925,-1.6425,1.4725,-3.165,1.5025)其中-3.005微秒(vc中第4个数据)被截成了两段,分别为-1.4425微秒和-1.5625微秒(-3.005=-1.4425-1.5625),其中前-1.4425微秒为前导码同步时钟信号的电平,后-1.5625微秒为前导码数字信号的电平。
将vd和pa'进行匹配,计算vd和pa'相似度,vd=(1.5225us,-1.6225us,1.6025us,-1.4425us),pa'=(1.5475us,-1.5475us,1.5475us,-1.5475us),计算时将两个向量依次映射到一维坐标上,先将pa'数据从一维坐标系的原点沿着正方向依次排列,形成一条宽度为6.19微秒的直线,再将vd数据也从一维坐标系的原点沿着正方向依次排列,形成另一条宽度为6.19微秒的直线,求取这个一维坐标中vd和pa'符号不一致的数据的总长度,结果为0.18微秒,则认为向量vd和向量pa'之间的距离da=0.18微秒,向量vd和向量pa'相似度sa=(la'-da)/la'=(6.19-0.18)/6.19≈97.1%,向量vd和向量pa'相似度97.1%满足相似度门限≥80%的要求,vd和pa'匹配成功,然后再从vc'中继续截取la'(6.19微秒)长度的数据,生成向量vd',继续后续匹配。
根据gb/t29768协议定义,前导码中的数据信号为8bit的二进制数“00111101”,对应编码符号匹配模板依次为(pa,pb,pd,pc,pd,pc,pb,pd),将vc中各数据按上述方法依次与(pa',pb',pd',pc',pd',pc',pb',pd')进行匹配,通过前导码数字部分的匹配。
前导码数字部分的最后一个电平是-1.5825微秒(在vc中第26个数据)。剩余的待解码数据vc”全部为编码数据,vc”=(-0.48,1.6425,-2.965,1.5825,-1.4825,1.6325,-1.5125,3.215,-1.5825,1.4925,-1.6425,1.4725,-3.165,1.5025)其中-1.5825微秒(vc中第26个数据)被截成了两段,分别为-0.48微秒和-1.1025微秒(-1.5825=-0.48-1.1025),其中前-1.1025微秒为前导码数字信号的电平,后-0.48微秒为数据编码部分的电平。
s66:当前导码中的数据全部接收成功之后,再次用前导码中的同步时钟信号和数据信号计算实际链路频率,并据此调整编码序列模板。
在本例中,前导码信号占链路周期的个数为n=24,n个链路周期的前导码信号总长度为tc=1.4225+1.5425+1.6325+1.5325+1.6625+1.4825+1.6125+1.4525+1.5025+1.5225+1.6625+1.4925+1.5725+1.4925+1.5525+1.5725+1.5225+1.6225+1.6025+3.005+1.5025+1.4825+1.6825+1.5025+3.665+1.4725+1.6025+2.985+1.6225+1.4725+3.225+1.4825+1.5425+3.025+1.5225+1.6625+1.4225+1.6925+1.4825+1.6025+3.015+1.5475(最后一个数据由于宽度不明确,用0.5/fr替换)微秒=74.675微秒=0.000074675秒,fr=n/tc=24/0.000074675hz≈321.39270khz。
根据实际链路频率fr≈321.39270khz来调整编码序列模板,调整后的miller2的编码序列模板如下:
编码符号a的编码序列模板为:pa”=(0.5/fr,-0.5/fr,0.5/fr,-0.5/fr)≈(1.55573us,-1.55573us,1.55573us,-1.55573us);
编码符号b的编码序列模板为:pb”=(-0.5/fr,0.5/fr,-0.5/fr,0.5/fr)≈(-1.55573us,1.55573us,-1.55573us,1.55573us);
编码符号c的编码序列模板为:pc”=(0.5/fr,-1/fr,0.5/fr)≈(1.55573us,-3.11146us,1.55573us);
编码符号d的编码序列模板为:pd”=(-0.5/fr,1/fr,-0.5/fr)≈(-1.55573us,3.11146us,-1.55573us)。
根据实际链路速率fr≈321.39270khz,调整后编码符号a的编码长度la”=2/fr≈6.22292微秒。
s67:在查找前导码结束之后,依次对输入的miller编码的数据编码进行数据解码。
前导码解码完成后,此时剩余的待解码数据vc”=(-0.48,1.6425,-2.965,1.5825,-1.4825,1.6325,-1.5125,3.215,-1.5825,1.4925,-1.6425,1.4725,-3.165,1.5025)。
从vc”中截取la”(6.22292微秒)长度的数据,生成向量vd=(-0.48us,1.6425us,-2.965us,1.1354us),单位为微秒,剩余的待解码数据为vc”'=(0.447,-1.4825,1.6325,-1.5125,3.215,-1.5825,1.4925,-1.6425,1.4725,-3.165,1.5025),其中1.5825微秒(vc”中第4个数据)被截成了两段,分别为1.1354微秒和0.4471微秒(1.5825=1.1354+0.4471)。
根据gb/t29768协议定义,前导码中最后一个符号为编码符号d,根据miller2编码规则,编码符号d后面只能出现编码符号a和c,分别计算向量vd与向量pa”、pc”之间的距离da、dc,本申请中向量距离计算方法见s5,计算结果为da=3.7379微秒,dc=1.46708微秒,根据相似度计算公式s=(la”-dv)/la”,向量vd与向量pa”、pc”之间的相似度计算结果为sa≈40%、sc≈76.4%,40%、76.4%都无法满足数据编码部分解码时相似度门限为≥85%的要求,因此需要移动vd的截取位置。
将截取的位置先向后移动la”/16的距离,即移动0.38893125微秒的距离,从vc”中重新截取la”(6.22292微秒)长度的数据,生成新向量vd'=(-0.09107us,1.6425us,-2.965us,1.52435us),0.48-0.38893125≈0.09107。重新计算向量vd'与向量pa”、pc”之间的距离da'、dc',计算结果为da'=3.34899微秒,dc'=0.30029微秒,并计算向量vd'与向量pa”、pc”之间的相似度计算结果为sa'≈46.2%、sc'≈95.2%,95.2%满足相似度门限为≥85%的要求,因此本次截取的编码序列与编码符号c匹配成功,解码输出结果为编码符号c对应的1bit原始二进制数据“1”,然后从上次截取结束位置重新截取la”长度的数据,生成新向量进行下一次解码。
按上述方法对vc”进行解码,输出的原始二进制数据为“1001”。
图7是表示一个rfid阅读器的示意图。参见图7,本发明提供一种rfid阅读器,所述rfid阅读器使用上述解码方法对miller编码进行解码。rfid阅读器100包括采样单元110和计算单元120,其中,采样单元110对编码数据进行采样,采样输出为输入编码信号的所有高电平和低电平宽度序列,所述采样单元110可以为定时器。计算单元120为miller编码的所有符号生成编码序列模板,通过判断编码信号的高电平和低电平宽度是否在同步时钟信号允许的时间范围内的方法进行查找。在找到足够长的同步时钟信号后,通过同步时钟信号计算并调整实际链路频率,并据此调整编码序列模板(“编码序列模板”是本申请中的特有名称,指用于匹配编码符号的,由一组表示电平宽度数据组成的一个向量)。查找前导码数据信号时,通过判断编码信号的高电平和低电平宽度是否超出同步时钟信号允许的时间范围的方法查找第一个宽电平,并将前导码的数据信号中第一个电平信号作为对齐位置,将输入编码序列与前导码中的数据信号进行匹配,判断是否在输入编码序列中找到正确的前导码。在前导码查找完成后,再次通过前导码中的所有同步时钟信号计算实际链路频率,并据此调整编码序列模板。解码数据时,通过将输入编码序列与候选编码序列模板进行匹配,找到相似度最大的编码符号,并通过将输入编码序列向前和向后偏移起始比较位置的方式,对该编码序列模板多次匹配,从中选择相似度最大值,并判断该值是否超出门限值,依此方法匹配出符合要求的编码符号,并据此进行数据解码。最终,计算单元120输出解码数据。
虽然本发明的一些实施方式已经在本申请文件中予以了描述,但是对本领域技术人员显而易见的是,这些实施方式仅仅是作为示例示出的。本领域技术人员可以想到众多的变型方案、替代方案和改进方案而不超出本发明的范围。所附权利要求书旨在限定本发明的范围,并藉此涵盖这些权利要求本身及其等同变换的范围内的方法和结构。
- 还没有人留言评论。精彩留言会获得点赞!