基于观看行为预测用户在电视上追剧的方法与流程
本发明涉及利用大数据进行用户行为预测技术,具体涉及一种基于观看行为预测用户在电视上追剧的方法。
背景技术:
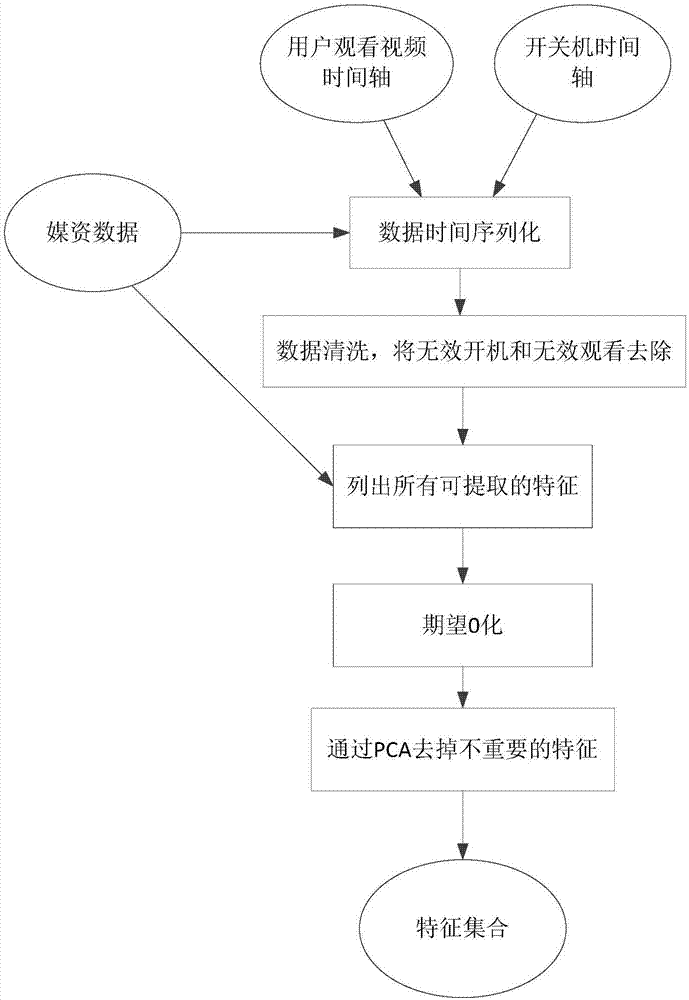
:随着大数据的发展,终端设备厂商手里积累了大量的用户数据,怎样根据这些用户数据来提高产品的用户体验是当下各大终端厂商都在做的事情。智能电视是互联网三大屏之一,目前电视提供的功能早已不再是观看电视台的直播那么单一,各种节目源、各种应用都能在电视上观看和使用。用户的选择更加多样化,其观看行为的个性化就更加明显。但是,对于没有个性化服务的智能电视,开机都将经过同样的过程,进入同样的状态,用户必须手动寻找自己喜欢的视频或者应用。而实际上,用户行为通常是具有一定规律的,这些规律都隐含在其使用电视的行为数据当中。如果可以通过用户的使用行为数据,准确预测用户下一次的行为,使得开机后就直接跳转到用户要观看的内容上,就可以缩短用户寻找喜爱节目的时间;或者当用户观看别的视频时,提醒用户,其正在“追”的视频已经更新,能够提高用户观看效率,增强用户对电视的依赖感。技术实现要素:本发明所要解决的技术问题是:提出一种基于观看行为预测用户在电视上追剧的方法,从而缩短用户寻找偏爱视频的时间,提高开机观看视频的效率,提升用户体验。本发明解决上述技术问题采用的技术方案是:基于观看行为预测用户在电视上追剧的方法,包括以下步骤:a.基于用户对电视的历史观看行为数据进行特征提取;b.利用提取的数据制作数据集;c.将制作的数据集输入至逻辑回归模型进行训练和验证;d.利用训练和验证好的逻辑回归模型对用户的观看行为进行预测。作为进一步优化,步骤d中,还包括:若预测到用户在追剧,则在下次开机后直接跳转至用户所追剧的最新观看进度进行视频播放。作为进一步优化,步骤a中,所述用户对电视的历史观看行为数据包括:视频播放数据:包括用户进入视频播放器的时间轴、开启和退出某部视频的时间轴;电视开关机数据:包括电视开机时间轴和关机时间轴;媒资信息:为播放的视频信息,包括播放的视频名称、视频id、视频系列id、视频类型和简介。作为进一步优化,步骤a中,所述特征提取,具体包括:a1.将电视开机、关机时间轴和视频开启、退出时间轴转化成标准时间戳,并按时间戳升序排序,整合成按照时间序列化的数据;a2.对无效数据进行清洗,所述无效数据包括:开机时间过短、视频播放时间过短的数据;a3.根据清洗后的数据,提取能够计算出来的特征;a4.对数据进行期望化处理,将数据期望值处理为0;a5.采用主成分分析法从期望化处理后的数据中选取主要特征,并进行特征组合。作为进一步优化,步骤a3中,所述能够计算出来的特征包括:通过开关机时间轴计算开机时长、视频开启时间轴计算视频被开机后首先观看的次数;根据视频开启和退出的时间轴计算视频观看时长;根据视频的系列id相同、视频id不同来计算观看视频的集数,以及每天观看视频的部数。作为进一步优化,步骤a4中,所述对数据进行期望化处理,将数据期望值处理为0具体包括:从步骤a3提取的特征数据中,按行随机提取一定数量的特征数据,将抽取出来的特征数据按列为单位,求每一列的期望值,然后将该列中所有元素减去期望值,操作完成后,所有列的期望都为0,则整个特征数据矩阵的期望为0。作为进一步优化,步骤a5中,采用主成分分析法从期望化处理后的数据中选取主要特征,并进行特征组合,具体包括:对特征数据矩阵做特征分解后得到矩阵的特征值列表,每个特征值对应一维特征向量,特征值越大,该维特征向量越重要,反之,特征值越小,该维特征向量越次要,取特征值最大的n维特征,作为主要特征,然后根据选取的主要特征之间的线性相关关系进行特征组合,从而确定最终的特征维度。作为进一步优化,步骤b中,利用提取的数据制作数据集,具体包括:b1.遍历所有电视在观测时间段内的所有数据,将每个电视观看的每部总集数大于10集的视频的所有主特征列出来,并按时间轴升序排列;b2按照观看次数大于3次,观看集数大于5集,下一次开机观看了该视频定义为追剧,制作标签,若标签值为1,表明下一次开机继续观看了该视频,若标签值为0,表明下一次开机未观看该视频,将特征数据和标签数据对应关联;b3.将特征数据归一化:求出每维特征的最大值,每维特征均除以最大值;b4.调用sklearn库中的特征多项式扩展模块,将特征数据进行多项式扩展,扩展成多阶且相互关联的特征集合;b5.构建空的训练数据集和验证数据集,然后将所有特征数据和标签数据按照7:1的比例随机分到训练数据集和验证数据集中。b6.分别将训练特征数据、训练标签数据、验证特征数据、验证标签数据对应输出到4文本文件中。作为进一步优化,步骤c中,所述将制作的数据集输入至逻辑回归模型进行训练时,在所述逻辑回归模型加入了二阶范数正则,二阶范数正则将模型中的参数沿着特征数据的hessian矩阵中各特征向量方向进行缩放,特征越主要,缩放比例越大,特征越次要,缩放比例越小。本发明的有益效果是:本发明通过云端智能预测用户的视频观看行为,为终端实现个性化开机提供了实时有力的数据保障。同时,也可用作视频的个性化推荐,在用户开机时,直接跳转至用户的偏好的视频上进行播放,提高开机查找视频播放的效率,提升用户体验。附图说明图1为本发明的建立预测模型的流程图;图2为特征提取的流程图;图3为数据集制作流程图。具体实施方式本发明旨在提出一种基于观看行为预测用户在电视上追剧的方法,从而缩短用户寻找偏爱视频的时间,提高开机观看视频的效率,提升用户体验。本发明通过从终端大数据中提取每个用户观看视频的特征,例如观看同一部剧的次数、连续观看天数、观看集数、时长等,建立特征工程,通过机器学习的方法来建立预测模型,通过预测模型判断用户是否追剧。其中建立预测模型的步骤如图1所示,其包括:特征提取、数据集制作、模型的训练和验证三个部分,最终生成用于对用户行为进行预测的模型:1、特征提取:即基于用户对电视的历史观看行为数据进行特征提取;本发明在具体实现上,使用的历史观看行为数据如下表所示:由于能拿到的数据不是图像、文本这种抽象的数据,而是用户操作的日志数据,例如开机的时间轴、开启视频的时间轴这种。用户操作行为是分时进行的,可以将数据时间序列化,然后再从序列化后的数据中提取特征。由于原数据量太大,因此采用随机方式抽取n个电视10天的观看行为数据,将开机、视频开启、视频退出、关机这4种行为按照时间序列化,在序列化后的数据中存在一些无效数据,为了提高数据处理效率,避免无效数据处理时间的浪费,可以将开机时间过短、视频播放过短等数据清洗掉,在具体实现时,通过设置阈值,如:一次开机时间少于10分钟的清洗掉,一次视频播放时间少于5分钟的清洗掉。经过清洗后的数据可以计算出用户观看视频的时长、集数、观看天数等多维特征数据。对于这些特征哪些与追剧强相关,哪些弱相关或无关,并不能直观的得到。因此,对提取到的所有特征采用主成分分析方法(pca)将变化并不明显的特征剔除掉。主成分分析方法的原理是对特征矩阵做特征分解后得到矩阵的特征值列表,特征矩阵等同于整个输入特征数据的协方差矩阵,每个特征值对应一维特征向量,特征值越大,该维特征向量越重要,反之,特征值越小,该维特征向量越次要。可以取特征值最大的n维特征,作为主要特征。2、数据集的制作:本部分是利用提取的数据制作用于数据训练和数据验证的数据集,以便于下一步进行模型的训练和验证。需要说明的是,在本部分除了利用提取的特征数据制作数据训练和数据验证的数据集之外,还涉及到标签数据的制作,以对特征数据进行标记,标签为1表示在满足一定条件时(比如:观看次数和/或观看集数等)的下一次开机仍然在观看该剧,标签为0表示下一次开机未观看该剧;将标签数据与特征数据关联起来,便于特征数据的训练和验证。3、模型的训练和验证:本发明采用逻辑回归作为预测模型。而采用一般的逻辑回归训练特征数据拟合的效果很差。于是对特征数据引入了特征多项式扩展。特征多项式n阶扩展可以将三维特征(a,b,c)扩展成各元素的1-n阶幂次,并相互组合。例如,(a,b,c)做2阶扩展,扩展成(1,a,a*a,b,b*b,c,c*c,ab,ac,bc)。用扩展后的特征数据来训练逻辑模型。为了防止过拟合,本发明还给逻辑模型加入了一个二阶范数正则,二阶范数正则有将模型中的参数沿着特征数据的hessian矩阵中各特征向量方向缩放的能力,特征越主要,缩放比例越大,特征越次要,缩放比例越小。因此,这样可以将扩展后的次要特征的影响缩小到很小,而主要特征的大小几乎保持不变。采用经过训练和验证后的逻辑回归模型作为最后的预测模型,可以对用户的行为进行预测,以提供个性化的开机服务。实施例:本实施例中基于观看行为预测用户在电视上追剧的方法,包括以下步骤:a.基于用户对电视的历史观看行为数据进行特征提取;本步骤中的特征提取流程如图2所示,其包括:a1.数据时间序列化:将开机、关机时间轴和视频开启、退出时间轴转化成标准时间戳,并按时间戳升序排序,将开机数据和视频数据一起整合成按照时间序列化的数据。a2.数据清洗:按照开机后至少观看10分钟才算一次有效开机,按照开启一部视频至少观看5分钟算一次有效视频有效观看来清理数据,并将视频按照“部”为单位(coverid为单位)整理数据。a3.全部特征提取:根据数据清洗后的数据,将所有能计算出来的特征全部提取出来。例如,通过开关机时间轴计算开机时长、视频开启时间轴计算视频被开机后首先观看的次数;根据视频开启和退出的时间轴计算视频观看时长;根据视频的coverid相同、videoid不同计算观看视频的集数,以及每天观看视频的部数等。总的来说,能提取的所有特征如下表,所有特征都按照一个电视终端看一部视频为索引:特征特征编号(该视频)连续开机首先被观看次数①(该视频)观看天数②(观看该视频的当天)观看视频的“部”数③(该视频)被观看次数④(该视频)已观看集数⑤(该视频)已观看总时长⑥(该视频)还剩下的集数⑦(该视频)的总集数⑧a4.数据期望化为0:从所有特征数据中,按行随机提取十分之一(原数据量较大),将抽取出来的特征数据按列为单位,求每一列的期望值,然后将该列中所有元素减去期望值。操作完成后,所有列的期望都为0,整个特征数据矩阵的期望也就为0了。a5.通过主成分分析提取主要特征,并进行特征组合:将期望化为0后的数据集采用主成分分析方法,留下5维重要数据。其中,pca方法按照通用原理,通过python调用numpy库中的协方差类和特征分解类完成程序,然后数据集矩阵化后输入到算法中,求其中特征值最大的五维数据,其对象的特征就是要保留的主要特征。经过运算,保留下来的特征为③、④、⑤、⑥、⑧根据常识判断,⑤、⑥这两维特征在追剧的大多数情况下(少部分人观看某集会快进)是线性相关的,即y=ax,其中,y为观看时长,x为集数,a为每集时长。如果确实存在这种线性相关,那么这两维特征选1维就可以了,集数是自变量,总时长是因变量,因此,选集数。实际数据的集数和时长的分布可以看出,集数和时长确实存在这样的线性关系,只是a不是一个值,而是一个取值范围。这里依然去掉⑥号特征。由于⑤和⑧特征都是集数,一个是观看集数,一个是总集数,⑤除以⑧组合成观看视频的进度,同时,这个特征成立的条件为总集数至少大于10集。这样一来,整个特征工程包含3维特征:观看次数、观看进度、当天观看视频的总部数。b.利用提取的数据制作数据集;根据步骤a中最后确定的主要特征维度和提取的特征数据制作用于训练和验证的数据集,制作流程如图3所示,其包括以下步骤:b1.遍历所有电视在观测时间段内的所有数据,将每个电视观看的每部总集数大于10集的视频的所有主特征列出来,并按时间轴升序排列;b2.按照观看次数大于3次,观看集数大于5集,下一次开机观看了该视频定义为追剧,制作标签,若标签值为1,表明下一次开机继续观看了该视频,若标签值为0,表明下一次开机未观看该视频,将特征数据和标签数据对应关联;b3.将特征数据归一化:求出每维特征的最大值,每维特征均除以最大值;b4.调用sklearn库中的特征多项式扩展模块,将特征数据进行多项式扩展,扩展成多阶且相互关联的特征集合;b5.构建空的训练数据集和验证数据集,然后将所有特征数据和标签数据按照7:1的比例随机分到训练数据集和验证数据集中。b6.分别将训练特征数据、训练标签数据、验证特征数据、验证标签数据对应输出到4文本文件中。c.将制作的数据集输入至逻辑回归模型进行训练和验证;用python语言调用sklearn中的logisticregression类编写逻辑回归模型,选择随机平均梯度下降‘sag’为优化方法,为避免过度拟合,选择二阶范数正则(l2正则)将训练数据集(包括训练特征数据和训练标签数据)中的数据输入逻辑回归模型中进行训练;将验证数据集(包括验证特征数据和验证标签数据)中的数据输入逻辑回归模型中进行验证,使其精度达标。d.利用训练和验证好的逻辑回归模型对用户的观看行为进行预测。经过不断训练和验证后的逻辑回归模型基本处于稳定状态,可以将其作为预测模型对用户的观看行为进行预测,从而为用户提供个性化的开机服务或者个性化推荐服务。当前第1页12
相关技术
网友询问留言
已有0条留言
- 还没有人留言评论。精彩留言会获得点赞!
1