一种基于大数据环境下的云计算业务资源计算方法及系统与流程
本发明涉及信息技术领域,尤其涉及一种基于大数据环境下的云计算业务资源计算方法及一种基于大数据环境下的云计算业务资源计算系统。
背景技术:
从市场的渗透情况看,云计算在目前甚至是未来几年内在中国仍是一门新兴产业,其未来的发展一方面有赖于云计算知识的普及以及相关使用者对其的评价和反馈。
基于大数据及云计算的广阔发展前景,各省市也纷纷出台相应的发展规划。推动相关产业发展和应用示范,正成为各地抢占新一轮经济和科技发展制高点的重大战略,积极将大数据作为提升本地发展的重要机遇。
云计算是分布式计算(distributedcomputing)、并行计算(parallelcomputing)、效用计算(utilitycomputing)、网络存储(networkstoragetechnologies)、虚拟化(virtualization)、负载均衡(loadbalance)等传统计算机和网络技术发展的融合产物。它是基于互联网的相关服务增加、使用和交付模式,通常涉及通过互联网来提供动态易扩展且经常是虚拟化的资源。“大数据”是一种规模大到在获取、存储、管理、分析方面大大超出了传统数据库软件工具能力范围的数据集合,具有海量的数据规模、快速的数据流转、多样的数据类型和价值密度低四大特征。云计算与大数据的关系就像一枚硬币的正反面那样密不可分,云计算为大数据提供可靠的分布式处理、分布式数据库和云存储及虚拟化技术;而大数据则为计算提供高效准确的数据服务。
传统模式下,云计算在分配资源时,需要用户根据自身的需求进行资源的申请,申请的资源用量一般是根据用户自身以往的经验作为参考对象,再由管理员进行审核并手动分配;分配完毕之后,承载上层服务的云计算管理平台会对底层资源进行监控,通过不断的监控资源实时的利用率来提高整体资源的使用。管理人员根据其他人申请资源的用量或是自身以往的经验为相同或是相似业务系统的资源建立模板,用户在申请用量时,根据管理员推送的模板进行资源申请;申请表单提交到管理人员处进行审核部署。
但是,由于用户对自身所需要的资源用量缺乏准确的认识,在实际的情况下存在申请用量远远大于实际用量或是远远小于实际用量,导致资源使用不恰当;且管理员在缺少数据及经验支持的情况下,也难以给出合理有效的建议,只能按用户申请的用量来进行分配,因此实际资源使用的需求与容量规划存在较大的偏差,容易造成大量的浪费。
技术实现要素:
本发明所要解决的技术问题在于,提供一种基于大数据环境下的云计算业务资源计算方法及系统,可利用大数据海量的数据存储功能及强大的分析能力为相应业务的虚拟机提供准确的底层资源。
为了解决上述技术问题,本发明提供了一种基于大数据环境下的云计算业务资源计算方法,包括:通过数据收集及数据挖掘,采集业务系统内虚拟机的运行指标;将收集到的运行指标进行分类;对分类后的运行指标进行分析,获取各类的标准资源指标;采集用户的资源申请信息,所述资源申请信息包括业务类型、虚拟机用途及业务规模;根据资源申请信息及标准资源指标,提取最佳的资源配置;根据资源配置申请资源并创建环境。
作为上述方案的改进,通过定类数据的方式将相近功能的运行指标进行分类。
作为上述方案的改进,根据虚拟机用途将相近功能的运行指标进行分类。
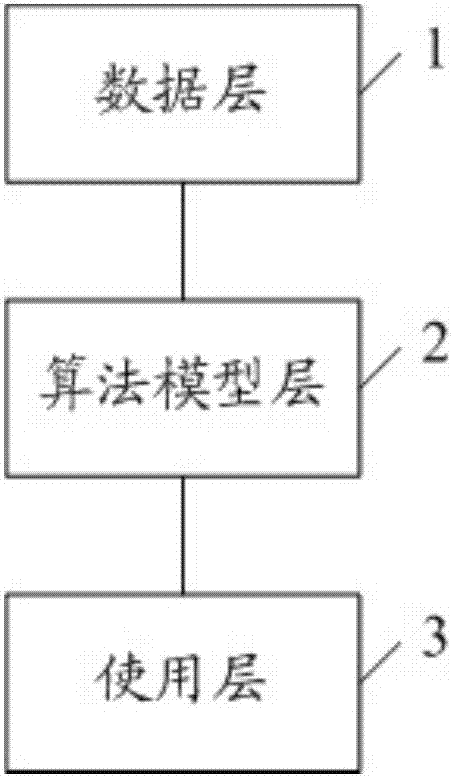
相应地,本发明还提供了一种基于大数据环境下的云计算业务资源计算系统,包括:数据层,用于数据收集及数据挖掘,采集业务系统内虚拟机的运行指标,采集用户的资源申请信息,所述资源申请信息包括业务类型、虚拟机用途及业务规模;算法模型层,用于将收集到的运行指标进行分类,对分类后的运行指标进行分析,获取各类的标准资源指标,根据资源申请信息及标准资源指标,提取最佳的资源配置;使用层,用于根据资源配置申请资源并创建环境。
作为上述方案的改进,算法模型层通过定类数据的方式将相近功能的运行指标进行分类。
作为上述方案的改进,算法模型层根据虚拟机用途将相近功能的运行指标进行分类。
作为上述方案的改进,数据层采用hadoop框架搭建整体的计算、存储框架。
实施本发明,具有如下有益效果:
本发明通过利用大数据针对每一个业务系统及应用资源用量的数据分析,为用户所对应的目标业务系统提供准确的资源用量,使得用户在申请资源或是管理员在分配资源的时候提高资源使用的准确度,降低资源在分配不均或是使用不当的几率,提高用户业务系统的连续性及资源使用率。从而降低客户成本,提高业务连续性,避免了现有技术先分配再调整带来的资源浪费与影响业务连续性的缺点。
附图说明
图1是本发明基于大数据环境下的云计算业务资源计算方法的流程图;
图2是本发明基于大数据环境下的云计算业务资源计算系统的结构示意图。
具体实施方式
为使本发明的目的、技术方案和优点更加清楚,下面将结合附图对本发明作进一步地详细描述。仅此声明,本发明在文中出现或即将出现的上、下、左、右、前、后、内、外等方位用词,仅以本发明的附图为基准,其并不是对本发明的具体限定。
云计算技术的发展和崛起,给传统的it环境及环境下的系统带来了极大的便利性和可用性;云计算的基础特点就是资源进行虚拟化,解除操作系统对底层硬件设备的关联,实现按需所取资源,大大提高硬件设备的使用率,降低硬件设备的采购开销及减轻运维人员的管理负担。但是这也给业务系统的均衡带来了很大的麻烦,一个业务系统有多个操作系统组成,每个系统都属于也业务的一部分,任何一个系统出现问题都会给业务系统带来不小的影响。因此系统的正常运行不仅仅是监控虚拟机软件的运行情况,还要均衡虚拟主机所处硬件设备的运行情况及硬件设备上其他虚拟主机的运行情况。资源的正确使用是保证业务系统运行稳定状态的关键。
参见图1,图1显示了本发明基于大数据环境下的云计算业务资源计算方法,包括:
s101,通过数据收集及数据挖掘,采集业务系统内虚拟机的运行指标;
通过数据收集及数据挖掘,采集业务系统内虚拟机的运行指标,包括:业务类型、用户数量、虚拟机用途、虚拟主机中央处理器cpu利用率(百分比)、cpu使用量(megahertz兆赫,mhz)、cpu等待时间(millisecond,毫秒)、cpu就绪时间(毫秒)、cpu空闲时间(毫秒)、虚拟主机内存使用率(百分比)、内存授权量(kilobyte千字节,kb)、内存活动量(kb)、内存共享量(kb)、内存交换量(kb)、内存回收量(kb)、内存交换量(kb)、内存压缩量(kb)、磁盘io使用率(百分比)、磁盘读取请求数(数字)、磁盘写请求数(数字)、磁盘读速率(kilobytepersecond千字节每秒,kbps)、磁盘写速率(kbps)、磁盘读取滞后时间(毫秒)、磁盘写滞后时间(毫秒)、cpu需求值(mhz)、cpu限额(mhz)、网络数据上行速度(kbps)、网络下行速度(kbps)、网络丢包数(数字)、网络错误包数量(数字)、内存限额(mbyte兆,mb)、存储io限额(数字)、虚拟主机快照空间(mb)等。
s102,将收集到的运行指标进行分类;
具体地,通过定类数据的方式将相近功能的运行指标进行分类。
采用定类数据的方式将底层虚拟机的运行指标进行分类,分析同类虚拟机的运行指标,如:虚拟主机中央处理器cpu利用率(百分比)、cpu使用量(megahertz兆赫,mhz)、cpu等待时间(millisecond,毫秒)、cpu就绪时间(毫秒)、cpu空闲时间(毫秒)、虚拟主机内存使用率(百分比)、内存授权量(kilobyte千字节,kb)、内存活动量(kb)、内存共享量(kb)、内存交换量(kb)、内存回收量(kb)、内存交换量(kb)、内存压缩量(kb)、磁盘io使用率(百分比)、磁盘读取请求数(数字)、磁盘写请求数(数字)、磁盘读速率(kilobytepersecond千字节每秒,kbps)、磁盘写速率(kbps)、磁盘读取滞后时间(毫秒)、磁盘写滞后时间(毫秒)、cpu需求值(mhz)、cpu限额(mhz)、网络数据上行速度(kbps)、网络下行速度(kbps)、网络丢包数(数字)、网络错误包数量(数字)、内存限额(mbyte兆,mb)、存储io限额(数字)、虚拟主机快照空间(mb)等相关信息。
进一步,根据虚拟机用途将相近功能的运行指标进行分类,具体如下表所示:
s103,对分类后的运行指标进行分析,获取各类的标准资源指标;
需要说明的是,采用定类数据的方式将底层虚拟机的运行指标进行分类,分析同类虚拟机的运行指标,得出该类用途虚拟机所对应的标准资源指标。
s104,采集用户的资源申请信息;
所述资源申请信息包括业务类型、虚拟机用途及业务规模;
s105,根据资源申请信息及标准资源指标,提取最佳的资源配置;
当用户为相应的业务系统申请所属的虚拟机时,系统可根据用户申请的虚拟机所属业务系统的业务类型、用户申请的虚拟机在业务系统中的虚拟机用途、用户申请的虚拟机所属业务系统的业务规模为用户推荐最佳的资源配置。
s106,根据资源配置申请资源并创建环境。
需要说明的是,用户可通过事先做好的模板,建立信息匹配资源需求库,根据业务系统及虚拟机的用途选择相应的模板作为资源申请的建议值。当用户为相应的业务系统申请虚拟机时,可从资源需求库中选择相应的模板进行资源申请,管理员通过资源模板的资源信息为其构建环境。
因此,本发明通过利用大数据针对每一个业务系统及应用资源用量的数据分析,为用户所对应的目标业务系统提供准确的资源用量,使得用户在申请资源或是管理员在分配资源的时候提高资源使用的准确度,降低资源在分配不均或是使用不当的几率,提高用户业务系统的连续性及资源使用率。从而降低客户成本,提高业务连续性,避免了现有技术先分配再调整带来的资源浪费与影响业务连续性的缺点。
参见图2,图2显示了本发明基于大数据环境下的云计算业务资源计算系统的具体结构,其包括:
数据层1,用于数据收集及数据挖掘,采集业务系统内虚拟机的运行指标,采集用户的资源申请信息,所述资源申请信息包括业务类型、虚拟机用途及业务规模;
算法模型层2,用于将收集到的运行指标进行分类,对分类后的运行指标进行分析,获取各类的标准资源指标,根据资源申请信息及标准资源指标,提取最佳的资源配置;其中,算法模型层通过定类数据的方式将相近功能的运行指标进行分类。具体地,算法模型层根据虚拟机用途将相近功能的运行指标进行分类。
使用层3,用于根据资源配置申请资源并创建环境。
需要说明的是,本发明为用户提供了一种基于大数据环境下的云计算业务资源计算系统,通过大数据的预测性分析能力,利用预测模型、机器学习、数据挖掘等技术来分析当前及历史的数据,判断出相应需求所对应使用的资源,提高分配资源的准确性,大大降低用户的使用成本,提高业务运行的连续性,让资源正在做到使用率最高化。在大数据的数据挖掘中,将整体分为3个层次:数据层1、算法模型层2、使用层3。具体地:
数据层1,采用hadoop框架搭建整体的计算、存储框架,保证了所收集的业务需求、规模、用途、cpu需求、内存需求、存储空间需求、存储io需求、网络io需求、峰值时间、峰值期间cpu需求、峰值期间内存需求、峰值期间存储空间需求、峰值期间存储io需求及峰值期间网络io需求等数据来源的准确性及系统高效的计算机可靠的存储,运用分布式框架,保证了系统的横向扩展和持久的运行能力。
算法模型层2主要功能在于积累了适合业务系统不同功能以及实现不同计算效果。在整个系统中,所涉及到的业务系统量较为庞大,种类繁多,利用算法准确推荐相应的资源使用。
使用层3主要针对前端业务应用,当数据被数据层所收集、挖掘后,经过算法模型层建立不同的算法库,再由使用层推荐给用户配置。建立的算法库中的数据是长期的数据调研与持续监测获得,不同的业务类型,不同的虚拟机用途,不同业务规模,对应不同的资源需求,同时,每种业务类型都具有相应的业务峰值时间和峰值时资源需求增长比例。
因此,本发明利用大数据海量的存储能力及强大的分析能力来对业务系统下的资源进行分析,得出相应业务的需求信息及使用资源容量的准确率,为相应业务的虚拟机提供准确的底层资源。使得部分系统占用过多硬件设备导致其他系统可使用资源不够的情况就可以大大的降低。
以上所述是本发明的优选实施方式,应当指出,对于本技术领域的普通技术人员来说,在不脱离本发明原理的前提下,还可以做出若干改进和润饰,这些改进和润饰也视为本发明的保护范围。
- 还没有人留言评论。精彩留言会获得点赞!