一种云环境下抗访问模式泄露的盲存储方法与流程
本发明涉及互联网技术,具体涉及一种云环境下抗访问模式泄露的盲存储方法。
背景技术:
面对移动互联、大数据以及物联网等应用环境中的多元化需求,数据的产生速度和流转速度明显加快,信息技术已进入了大数据时代。大数据具有数据规模大、数据种类多、速度要求高和价值密度低等特点,数据不再像传统信息系统一样采用集中式的存储,云存储等新模式被广泛应用,吸引了越来越多企业和个人用户的关注和使用。越来越多的用户选择将自己的数据及业务迁移到云端中,由云服务器代为存储,以此来节省数据管理开销和系统维护开支。为了能够让用户放心地将数据存储在云服务器,加密成为确保数据存储安全的隐私保护手段。然而,加密虽然可以保护数据内容不被泄露,但是却不能保护云存储中数据的访问模式,即用户访问的数据在云存储中的位置和大小等信息。而访问模式通常也蕴含了用户的隐私信息,已成为泄露用户隐私的一种潜在途径。更重要的是,服务器通过对于文件的访问模式进行频率分析并融合对于文件中敏感信息的公开研究,服务器能够概率性判断出数据库中特定文件是否包含某些特定信息。
由此可见,在云存储环境中,隐藏用户的访问模式对于保护用户数据隐私是十分必要的。目前能够实现隐藏访问模式存储方法中最主要的技术为隐私信息检索(pir,privateinformationretrieval)和不经意随机存储技术(oram,obliviousrandomaccessmemory)oram。pir协议一方面计算复杂度较高,服务提供者通常需要做大量复杂的运算,开销很大,因此不适用云存储应用场景;基于oram的隐私保护方法其高昂的存储代价以及频繁的交互访问过程导致其效率仍然很低,导致将其应用到现实中较不理想。
云存储环境为海量数据的存储和共享提供方便的同时也带了安全隐患。为保证数据安全,用户将自己的隐私数据加密后存储在开放的云存储环境中,如何防止云存储环境下的数据访问模式泄露是亟待解决的问题。
技术实现要素:
针对现有技术中的问题,本发明提供一种云环境下抗访问模式泄露的盲存储方法,该方法可降低存储代价和访问交互次数,且保证了动态数据的安全存储。
第一方面,本发明实施例提供一种云环境下抗访问模式泄露的盲存储方法,包括:
步骤101、客户端接收待进行云存储的文件后,将所述文件转换成多个数据块;每一数据块包括所述文件的标识、版本号和所述文件的数据部分,第一个数据块包括所述文件转换后的数据块数量、所述文件的标识、版本号和所述文件的部分数据;
步骤102、所述客户端根据所述标识、所述数据块数量,预先获取的存储空间信息,获取所有数据块的随机序列;所述随机序列包括:存储空间中待存储每一个数据块的伪随机地址;
步骤103、所述客户端对每一个数据块进行加密处理;
步骤104、所述客户端根据所述随机序列,建立所有数据块的索引信息;
步骤105、所述客户端将所述索引信息和所有数据块发送所述云服务器,以使所述云服务器根据所述索引信息将所述数据块存储在所述随机序列中伪随机地址对应的伪随机位置。
可选地,所述步骤101之前,所述方法还包括:
步骤100a、所述客户端接收用户用于申请存储空间的指令,根据该指令向云服务器发送用于申请存储空间的请求;
步骤100b、所述客户端接收所述云服务器根据所述请求向所述客户端发送分配所述客户端的存储空间d信息,所述存储空间d信息包括:nd个大小为md比特的数据块的数组;所述每一个数据块为所述服务器采用全0初始化后的数据块;
所述存储空间d属于所述云服务器中为用户开辟的盲存储空间。
可选地,在用户读取存储的文件时,所述方法还包括:
步骤s1、所述客户端接收到用户触发的读取文件读取指令,所述读取指令包括:待读取文件的文件标识;
步骤s2、所述客户端根据所述文件标识,查找所述待读取文件的随机序列;所述随机序列包括:存储空间中待读取文件的每一个数据块的伪随机地址;
步骤s3、所述客户端向云服务器发送数据块请求,所述数据块请求包括所述随机序列;
步骤s4、所述客户端接收所述云服务器根据所述随机序列中的所有伪随机地址查找到的所有数据块;
步骤s5、所述客户端将接收的所有数据块解密;
步骤s6、所述客户端将解密后的所有数据块整合成待读取的文件。
可选地,在用户更新存储的文件时,所述方法还包括:
步骤m1、接收到原存储文件的更新文件时,获取更新文件的文件标识;
根据所述文件标识,执行所述步骤s2至步骤s6的步骤,在原存储文件更新之后,得到更新文件;
步骤m2、确定原存储文件的数据块的数量;
步骤m3、将更新文件转换成多个数据块,查看更新文件的多个数据块的数量和确定原存储文件的数据块的数量是否相同;
步骤m4、若相同,将更新文件的版本号更新,以及将更新文件的多个数据块、所述随机序列的索引信息发送所述云服务器以存储。
可选地,包括:
步骤m5、若不相同,将更新文件的版本号更新,以及在更新文件的数据块的数量大于原存储文件的数据块的数量;
则,根据所述文件标识、待增加的数据块数量、服务器发送的存储空间信息、获取待增加的数据块数量的随机序列;
待增加的数据块数量为更新文件的数据块的数量减去原存储文件的数据块的数量的差值;
所述客户端对更新文件的每一个数据块进行加密处理,并执行步骤104和步骤105;
或者,
若不相同,将更新文件的版本号更新,以及在更新文件的数据块的数量小于原存储文件的数据块的数量;
则,根据所述文件标识、更新文件的数据块数量、服务器发送的存储空间信息、获取所述更新文件的随机序列;
所述客户端对更新文件的每一个数据块进行加密处理,并执行步骤104和步骤105。
可选地,所述方法还包括:
所述服务器在存储数据块之后,更新存储空间,并将更新的存储空间信息发送所述客户端,以使所述客户端依据更新后的存储空间信息、下一待存储文件的相关信息生成下一待存储文件的随机序列。
可选地,所述步骤101还包括:
所述客户端在接收待进行云存储的文件后,利用fileid类的构造函数获取所述文件的标识。
可选地,所述步骤103包括:
使用伪随机函数φ和密钥kφ加密待存入存储空间d中的每一个数据块;对于第i个数据块d[i],写成vi||b[i],加密后
vi是版本号,b[i]表示所述文件的第i个原始数据块;
所述密钥kφ为获取所述文件标识的过程中生成的哈希函数的密钥。
可选地,所述步骤102包括:
利用完全定义域伪随机函数生成种子,将种子输入伪随机生成器,得到随机序列。
可选地,包括:
1021、所述客户端根据所述标识、所述数据块数量、预先获取的存储空间信息,生成一个随机子集
其中,α为膨胀参数,nd为存储空间d中数据块的个数,κ为存储空间中每次访问的最小数据块个数,文件的内容dataf被分块处理后的数据块个数表示为sizef;
1022、利用文件标识idf计算该文件的种子
1023、让sf作为在序列λ[σf,|sf|]的整数集合;这里λ[σ,l]指的是按照如下方式获得的l个整数的序列;
1)将种子σ作为伪随机生成器γ的输入,得到一个长度固定的输出;然后在[nd]的范围内解析此输出作为一个整数序列;
2)λ[σ,l]指的是在所述整数序列中的第一个l长的可区分整数;
1024、挑选一个伪随机的子集合
即在sf序列中挑选包含sizef个可检索空数据块的最短前缀,并让
可选地,步骤s2包括:计算
步骤s3包括:向云服务器发送检索sf0指示的数据块请求;
步骤s4包括:云服务器会存储空间d读取随机序列指定伪随机位置上的数据块,按照在λ[σf,κ]中的顺序将d[sf0]返回给客户端;
步骤s5包括:所述客户端将得到的数据块进行解密,并在第一个数据块中读取数据块集合的大小;包括:
把
如果一个被标记为idf的数据块被找到,这个数据块就是标识符为idf的文件的第一个数据块,可以从这个数据块的头部域恢复出文件的大小sizef;让
以及,根据随机序列指示的位置,将剩下的数据块从云服务器中的存储空间d上读取到客户端本地并解密,即请求能通过sf/s0f被检索的数据块。
将所有的数据块整合为一个完整的文件,若
第二方面,本发明实施例还提供一种云环境下抗访问模式泄露的盲存储方法,包括:
步骤s1、客户端接收到用户触发的读取文件读取指令,所述读取指令包括:待读取文件的文件标识;
步骤s2、所述客户端根据所述文件标识,查找所述待读取文件的随机序列;所述随机序列包括:存储空间中待读取文件的每一个数据块的伪随机地址;
步骤s3、所述客户端向云服务器发送数据块请求,所述数据块请求包括所述随机序列;
步骤s4、所述客户端接收所述云服务器根据所述随机序列中的所有伪随机地址查找到的所有数据块;
步骤s5、所述客户端将接收的所有数据块解密;
步骤s6、所述客户端将解密后的所有数据块整合成待读取的文件。
本发明具有的有益效果如下:
本发明的一种云环境下抗访问模式泄露的盲存储方法,首先将文件以数据块的形式进行加密,并利用伪随机函数和抗碰撞哈希函数将密态数据块上传至云服务器的伪随机集合超集内,构建安全云存储结构;同时,针对用户的上传、下载以及更新文件等操作,客户端采用二层访问协议,在隐藏了访问模式的同时实现文件的动态高效更新;与以往的基于oram的安全存储方法相比,本发明的方法大大降低了存储代价和访问交互次数,即在保障密态数据安全存储的同时,适用于实际的云存储环境。
上述方法保证了数据安全,使得云存储环境的使用更便捷,且保证数据的隐私性。
附图说明
为了更清楚地说明本发明实施例或现有技术中的技术方案,下面将对实施例或现有技术描述中所需要使用的附图作简单地介绍,显而易见地,下面描述中的附图仅仅是本发明的一些实施例,对于本领域普通技术人员来讲,在不付出创造性劳动性的前提下,还可以根据这些附图获得其它的附图。
图1为本发明云环境下抗访问模式泄露的盲存储方法架构示意图;
图2为本发明云环境下抗访问模式泄露的盲存储方法数据块集合示意图;
图3为本发明云环境下抗访问模式泄露的盲存储方法盲存储构建示意图;
图4为本发明云环境下抗访问模式泄露的盲存储方法中下载文件示意图;
图5为本发明云环境下抗访问模式泄露的盲存储方法生成文件id流程图;
图6为本发明云环境下抗访问模式泄露的盲存储方法中选取空闲数据块流程图;
图7为本发明云环境下抗访问模式泄露的盲存储方法生成加密数据块流程图;
图8为本发明云环境下抗访问模式泄露的盲存储方法文件上传的流程图;
图9为本发明云环境下抗访问模式泄露的盲存储方法第一轮文件数据块读取流程图;
图10为本发明云环境下抗访问模式泄露的盲存储方法第二轮文件数据块读取流程图;
图11为本发明云环境下抗访问模式泄露的盲存储方法更新文件流程图。
具体实施方式
为了更好的解释本发明,以便于理解,下面结合附图,通过具体实施方式,对本发明作详细描述。
在以下的描述中,将描述本发明的多个不同的方面,然而,对于本领域内的普通技术人员而言,可以仅仅利用本发明的一些或者全部结构或者流程来实施本发明。为了解释的明确性而言,阐述了特定的数目、配置和顺序,但是很明显,在没有这些特定细节的情况下也可以实施本发明。在其它情况下,为了不混淆本发明,对于一些众所周知的特征将不再进行详细阐述。
本发明的技术方案是这样实现的:一种云环境下抗访问模式泄露的盲存储方法,包括两个类型的实体。其中一个是客户端(用户可以直接操作的设备或程序),另一个是云存储服务提供商(简称为云服务器),用户通过客户端在云服务器中存储文件。如图1所示为盲存储方案的架构图。从图1中可以看出客户端首先对文件集进行处理,然后将处理得到的数据块存储到云服务器的盲存储结构中,即完成对盲存储的构建。接下来,客户端与云服务器之间就可以进行上传、下载或更新文件等操作。
从架构图中可以看到方案的功能主要通过图1中的①、②、③、④这四个步骤来实现。其中,①表示客户端对文件集中的每个文件进行处理,即将每个文件转换成多个固定形式的数据块的格式;
②表示将所有文件数据块随机的存放在盲存储结构的随机位置上,在存放之前要对数据块进行加密处理;
③表示从盲存储结构中读取出想要查找的文件所对应的数据块;
④表示对读取下来的数据块进行解密和整合,最终得到完整的文件内容。
构建盲存储和上传文件需要通过步骤①和②来完成,而读取文件需要通过步骤③和④来完成,更新文件则在读取文件的基础上再通过步骤①和②来完成。
本发明中的客户端指的是所有想要存储文件在远程服务器的终端,而服务器是只需要具有存储功能的云存储服务提供商。当客户端想要将自己的文件存储到云服务器中时,按照本发明实施例的算法即方法对文件进行处理和加密,将文件转化成数据块的集合。然后将处理后的数据块集合保存在云存储服务器中的一些伪随机位置上。由于数据块集合存储在伪随机位置上,因此服务器无法获知关于文件的大小、内容和数量等信息。只有在客户端搜索某文件后,服务器才会知道文件的存在,但也只能获知文件的大小,仍然不能知道文件的名字以及内容。同时本发明的方法允许客户端动态地添加新文件,也可以更新已经存在的文件。
需要强调的是,为了保证访问模式的零泄漏,方案中的每一个文件都以数据块的集合形式保存在云存储中的伪随机地址上。服务器只能看到文件数据块所在位置的超集,而不是存储位置的实际集合。而对于安全性方面,本实施例方法把负责存储的服务器当作敌手看待,由于客户端中伪随机生成器的随机性,使得系统(客户端和云服务器构成的系统)的存储空间中与每一个文件相关联的位置集合同其他文件相关联的位置集合是相互独立的。即,一个文件的数据块的位置信息不会影响其他文件数据块的位置信息。而且之间不会存在可连接性。
需要说明的是,本实施例中,用户需要做的操作是,打开客户端,选择上传文件,选择文件,点击上传,其余的都是客户端内部完成。
用户想要上传,下载文件时候开始启用客户端。
本实施例中提及的压缩包可当做一个文件进行处理。因为正常情况下,如果是加密的文件,一个压缩包也是对应一个文件的。
文件集这里指的是多个文件的集合的意思,由于是具有隐私保护的盲化的性质,所以将文件夹压缩包等形式进行了盲化,即不想泄露给服务器这些信息。
实施例一
一种云环境下抗访问模式泄露的盲存储方法主要有以下步骤构成:
步骤1:盲存储的构建,主要用来初始化构建文件存储,主要包括以下步骤:
步骤1-1:用户通过客户端在服务器中申请一个由n个固定大小数据块组成的存储空间d;
本实施例中定义空间大小就是n个数据块的大小。
例如,用户打开本地客户端,输入用户名密码进入,点击构建盲存储,选择按钮云中空间大小(数据块多少,本实施例设为n)。申请信息由客户端发送给云服务器,云服务器开辟n个数据块大小的存储空间返回客户端。存储空间中每个数据块初始化均是空的。
步骤1-2:客户端对要存储的文件集合进行处理,使得每一个文件都被转换成多个数据块的形式,其中每个数据块又固定包含文件id标签,版本号和数据部分,其中第一个数据块还要包含该文件转换后的数据块个数。
步骤1-3:利用每一个文件的文件标识(即下述的id标签)和转换后的数据块个数以及多个伪随机函数,生成一个伪随机序列,即利用完全定义域伪随机函数生成种子,并根据种子得到随机序列。
本实施例中,多个伪随机函数是本地客户端里面的算法函数,这些函数函数是固定的。每个文件都需要经过这些函数才能得到存储序列。函数输入每一个文件的文件标识和转换后的数据块个数,函数输出这些数据块存储位置的序列。
这个伪随机序列是由一个短的种子和文件转换成的数据块集合的大小所定义:其中该种子可以被用来生成一个伪随机序列,而数据块集合的大小用来指定在这个伪随机序列中截取的前缀长度。这个序列,一方面它是可以预先确定的,并且是可以重复地生产和复制的;一方面它又具有某种随机序列的随机特性(即统计特性)。
例如,可以通过一个伪随机函数f生成伪随机序列,输入长度为t的字符串,输出长度为m的字符串,这里m远大于t,即f:(0,1)t→(0,1)m。如果这个函数无论输入的是什么,输出的长度为m的序列都无法在理论计算时间内发现规律,即看起来具有随机性,而且同一个输入字符串输出的序列是相同的,那么这个函数生成的序列具有伪随机性。
步骤1-4:为了保证数据的机密性,对所有的数据块进行加密。最后根据伪随机序列将数据块进行索引并存储到存储空间d中。
该步骤的密钥是客户端在初始化的时候为当前用户生成的。
步骤2:客户端向云服务器上传文件,即将该文件加密的数据快上传云服务器实现盲存储。
应说明的是,本实施例的方法还包括如何在云服务器中读取存储的文件,具体参见如下步骤:
步骤3:下载文件。
运行于客户端和服务器两端,主要用于完成从盲存储中读取文件数据;主要包括以下步骤:
步骤3-1:当用户触发客户端读取存储在云服务器中的某个文件时,利用该文件的文件标识生成种子,然后利用种子得到随机序列。
步骤3-2:服务器会在盲存储d读取随机序列指定伪随机位置上的数据块,然后返回给客户端。
步骤3-3:客户端将得到的数据块进行解密,并在第一个数据块中读取数据块集合的大小;
步骤3-4:客户端根据随机序列指示的位置,将剩下的数据块从服务器中的盲存储d上读取到本地并解密;
步骤3-5:客户端将所有的数据块整合为一个完整的文件。
应说明的是,本实施例的方法还包括用户想更新文件时,如何实现文件的更新,具体参见如下步骤:
步骤4:更新文件。
运行于客户端和服务器两端,主要用于更新盲存储中的文件内容;主要包括以下步骤:
步骤4-1:当用户通过客户端想要更新某个文件时,首先从服务器中读取此文件,利用该文件的文件标识生成种子,然后利用种子得到随机序列。
步骤4-2:云服务器会在盲存储d读取随机序列指定伪随机位置上的数据块,然后返回给客户端。
步骤4-3:客户端将得到的数据块进行解密,并在第一个数据块中读取数据块集合的大小,并计算当前文件的大小与更新后文件大小的最大值k。
本实施例中文件大小,可理解为数据块个数。
步骤4-4:客户端根据随机序列指示的位置,将剩余k个数据块从服务器中的盲存储空间d上读取到本地并解密。
本实施例中前面的最大值k和该处的剩余k个数据块的表述是一致的。因为在更新文件协议过程中,更新文件可能需要比原始文件更多或更少的数据块。让被检索的集合sf(集合中有多个文件)的大小与两个版本中最大的那个文件相一致。如果更新后的版本比原始版本需要更少的数据块,那么sf中额外的数据块都要设置为空。如果更新后的文件需要更多的数据块,那么被检索的集合sf的大小要与更新后的文件相一致;那么,在sf中额外的空闲数据块要用于扩展
步骤4-5:客户端将所有的数据块整合为一个完整的文件。
步骤4-6:客户端更新文件内容;
步骤4-7:客户端把所有被检索数据块重新加密并重新上传到服务器中。
实施例二
下面结合附图和实施例对本发明方案作进一步详细说明。
了方便描述,对本实施例用到的符号加以说明,各符号定义如表1所示:
表1符号说明
步骤001:盲存储的构建,主要用来初始化构建文件存储;
具体准备工作如下:
为每个文件生成文件id,由于已知文件的名字,所以利用fileid类的构造函数完成文件id的生成。
文件id的主要生成过程是:先判断哈希函数的密钥是否已生成,若已经生成则调用hashmac类的setkey函数获取已有密钥;
若没有生成,则调用prf类中的setupkey函数完成密钥的生成。
基于生成的密钥,之后调用hashmac类中的dofinal函数,该函数主要是使用hmac<cryptpp::sha256>对文件名计算摘要值,作为文件的id,以便唯一标识,具体流程如图5所示。
哈希函数的密钥是用户的客户端为用户生成的,如果是用户来处理第一个文件id,则需要生成哈希函数的密钥,再通过此密钥生成文件id;如果用户之前上传过文件,则哈希函数的密钥则存在客户端中,所以可以调用函数来获得密钥。哈希函数的密钥主要是一串具有唯一性的随机字符串,和用户绑定。
本实施例中不是每一个文件id都需要重新生成密钥,而是针对此文件,需要用密钥生成文件id。
hmac<cryptpp::sha256>这是一个哈希函数,这个函数需要输入密钥,才能生成id。
本实施例中,将待进行盲存储的所有文件的文件列表表示为
接下来按照下面的方法对一个文件内容dataf进行分块处理。每一个数据块都具有两个短头部域:包括一个初始化为0的版本号,和h(idf)。h(idf)不允许全部为0,全为0的块用来指示空块。除此之外,第一个数据块需要多保存一个头部域以存储记录sizef。
主要包括以下步骤:
步骤001-1:用户打开客户端,输入用户名密码,进入客户端界面,点击构建盲存储功能按钮,进入构建界面,输入预先设定的云服务器存储空间大小,在云服务器中申请一个由n个固定大小数据块组成的存储空间d;让d作为拥有nd个大小为md比特大小的数据块的数组。在d中用全0初始化每一个数据块。
步骤001-2:云服务器接收到客户端的发送的申请存储空间的指令,根据该指令构架建存储空间d,在d中用全0初始化每一个数据块,在初始化完成后,向客户端返回构建成功响应,并将构建的存储空间d的信息通知客户端。
步骤001-3:用户点击客户端的一界面展示的上传文件按钮,客户端的一界面弹出文件列表,用户触发想要上传的文件,点击确定。
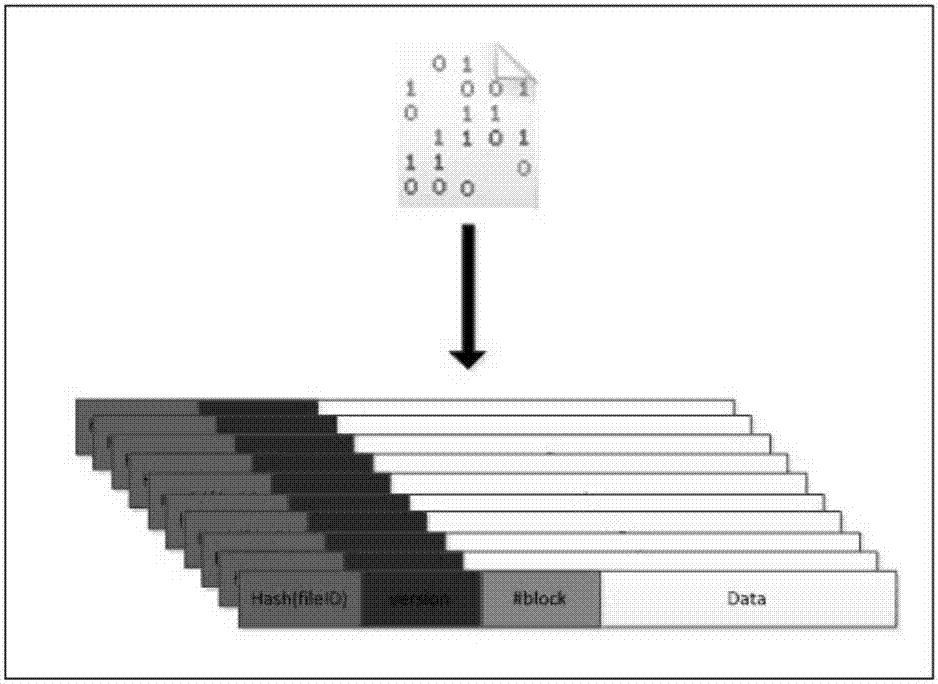
步骤001-4:客户端对要存储的文件集合进行预处理,使得每一个文件都被转换成多个数据块的形式,如图2所示,从图2中可以看出一个文件被转换成多个固定大小的数据块,而每个数据块又固定包含文件id标签hash(fileid),版本号version和数据部分data,其中第一个数据块还要包含该文件转换后的数据块个数#block。
步骤001-5:客户端利用每一个文件的文件标识和转换后的数据块个数以及多个伪随机函数(该些函数属于客户端中的函数),生成一个伪随机序列。
每个文件的多个伪随机函数都是相同的。
如图3所示,步骤001-5的具体过程如下:
对于文件列表中的每一个文件f,
●根据文件标识、文件的数据块数量、存储空间d信息生成一个随机子集
1)通过计算为该文件生成一个种子
2)让sf作为在序列λ[σf,|sf|]的整数集合。这里λ[σ,l]指的是按照如下方法获得的l个整数的序列。
①将种子σ作为伪随机生成器γ的输入,得到一个足够长(即固定长度)的输出。然后在[nd]的范围内解析此输出作为一个整数序列。
②λ[σ,l]指的是在这个序列中的第一个l长的可区分整数。
其中,整数序列的前sf长的序列为λ[σf,|sf|]。
●检查是否满足如下两个条件:
1)至少通过sf中的数字而被检索的d中的sizef个数据块是空的;
2)至少通过sf0(大小为κ的集合)中的数字而被检索的d中的一个数据块是空的。
如果任意一个条件都没满足,则终止。
●挑选一个伪随机的子集合
●按照
步骤001-6:为了保证数据的机密性,客户端对所有的数据块进行加密。最后根据伪随机序列将数据块上传到存储空间d中相关位置。
步骤001-6的具体过程如下:
使用伪随机函数φ和密钥kφ加密d中的每一个数据块。其中,每个数据块的版本号部分vi,要保持不加密(即明文形态),而每个数据块的其余部分都要使用版本号vi(初始化为0)和此数据块的索引号进行加密。更准确来说,对于第i个数据块d[i],将其写为vi||b[i](vi是版本号),然后将b[i]更新成
这里索引号,就是第几个数据块的意思,比如说,一个文件有n个数据块,第i块数据块的索引号就是i。
步骤002:上传文件,运行于客户端和服务器两端,主要用于完成向盲存储空间中写入文件的数据块。
具体流程如图8所示。主要包括以下步骤:
步骤002-1:客户端对要上传的文件集合进行处理,使得每一个文件都被转换成多个数据块的形式,具体实施过程如下:即将文件内容data被编码后的数据块个数表示为sizef,每一个数据块都具有两个短头部域:包括一个初始化为0的版本号,和h(idf)。h(idf)不允许全部为0,全为0的块用来指示空块。除此之外,第一个数据块需要多保存一个头部域以存储记录sizef。
步骤002-2:利用每一个文件的文件标识和转换后的数据块个数以及多个伪随机函数,生成一个伪随机序列;具体实施过程如下:
●生成一个随机子集
●利用文件标识idf计算
●让sf作为在序列λ[αf,|sf|]的整数集合。这里λ[α,l]指的是按照如下方法获得的l个整数的序列。
1)将种子σ作为伪随机生成器γ的输入,得到一个足够长的输出。然后在[nd]的范围内解析此输出作为一个整数序列。
2)λ[σ,l]指的是在这个序列中的第一个l长的可区分整数。
●挑选一个伪随机的子集合
步骤002-3:为了保证数据的机密性,对所有的数据块进行加密。最后根据伪随机序列将数据块索引并存储到存储空间d中;具体实施过程如下:
●使用伪随机函数φ和密钥kφ加密要上传的每一个数据块。其中,每个数据块的版本号部分vi,要保持不加密(即明文形态),而每个数据块的其余部分都要使用版本号vi(初始化为0)和此数据块的索引号进行加密。更准确来说,对于第i个数据块d[i],将其写为vi||b[i](vi是版本号),然后将b[i]更新成
●将文件内容data的sizef个数据块传送到云服务器s中的盲存储空间d中。
●云服务器s接收到sizef个数据块后,在盲存储d中将其按照
步骤003:下载文件,运行于客户端和服务器两端,主要用于完成从盲存储中读取文件数据;包括两轮操作,如图4所示,主要包括以下步骤:
第一轮操作包括步骤003-1至步骤003-3,流程图如图9所示。
步骤003-1:当用户想要读取某个文件时,登陆客户端,选择文件标识。
步骤003-2:客户端利用该文件的文件标识生成种子,然后利用种子得到随机序列;具体实施过程如下:
●客户端计算种子
●客户端向云服务器发送检索sf0指示的数据块请求。
步骤003-3:服务器收到读取文件请求后,会在盲存储空间d读取随机序列指定伪随机位置上的数据块,然后返回给客户端;即按照在λ[σf,κ]中的顺序将d[sf0]返回给客户端。
步骤003-4:客户端将得到的数据块进行解密,并在第一个数据块中读取数据块集合的大小;具体实施过程如下:
●客户端对返回回来的数据块进行解密,即把
●如果没有找到这样的数据块,那么说明这个文件不存在于云服务器中。在这种情况下,交互结束。
●如果一个被标记为idf的数据块被找到,这个数据块就是标识符为idf的文件的第一个数据块,可以从这个数据块的头部域恢复出文件的大小sizef。让
第二轮操作包括步骤003-5至步骤003-6,流程图如图10所示。
步骤003-5:客户端根据随机序列指示的位置,将剩下的数据块从服务器中的存储空间d上读取到本地并解密,即请求能通过sf/s0f被检索的数据块。
步骤003-6:客户端将所有的数据块整合为一个完整的文件。若
步骤004:更新文件,运行于客户端和服务器两端,主要用于更新盲存储空间中的文件内容;操作流程图如图11所示,主要包括以下步骤:
步骤004-1:当用户想要读取某个文件时,利用该文件的文件标识生成种子,然后利用种子得到随机序列;具体实施过程如下:
客户端计算种子
●客户端向云服务器发送检索sf0指示的数据块请求。
●步骤004-2:云服务器会在盲存储d读取随机序列指定伪随机位置上的数据块,然后返回给客户端;即按照在λ[σf,κ]中的顺序将d[sf0]返回给客户端。
步骤004-3:客户端将得到的数据块进行解密,并在第一个数据块中读取数据块集合的大小,并计算当前文件的大小与更新后文件大小的最大值k;
●客户端遍历数据块,如果一个被标记为idf的数据块被找到,这个数据块就是标识符为idf的文件的第一个数据块,可以从这个数据块的头部域恢复出文件的大小sizef。
1)将sizef接收作为sizef′,即文件更新后的大小。
2)让
2)让
步骤004-4:客户端根据随机序列指示的位置,将剩余k个数据块从服务器中的盲存储d上读取到本地并解密;即向云服务器s请求能通过sf/s0f被检索的数据块,解密通过sf被检索的剩余的数据块d[sf/s0f]。
步骤004-5:客户端将所有的数据块整合为一个完整的文件。客户端用
步骤004-6:客户端对更新前内容进行修改和更新,命名为data′。
步骤004-7:客户端随机对新内容data′分块编码为size′f个数据块。
步骤004-8:客户端把所有被检索数据块重新加密并重新上传到服务器中。该步骤中的被检索数据块是指从云中下载下来的数据块,把更新前的内容替换掉,填充进更新后文件的数据块。
具体实施方法如下:
●客户端识别一个子集
1)如果没有这样的前缀存在,或者在被标识的size′f个数据块中的第一个不存在于λ[σf,κ](只有在sizef=0的情况下才会发生),那么这时终止。
2)同时要说明的是如果size′f<sizef,那么有
●客户端对所有通过sf检索到的数据块进行加密。即对于第i个数据块d[i],将其写为vi||b[i](vi是版本号),然后将b[i]更新成
●接下来,客户端将加密后的数据块发送给云服务器s。
●服务器s将接收到的数据块更新到盲存储d中通过
●上传被重新加密的新的数据块到云服务器中。要说明的是d[sf]中所有被下载下来的数据块在这一步都被重新上传了(即下载之后的数据块更新成新的数据块,再上传服务器),同时他们的版本号加1,并要重新进行加密。(在更新文件协议过程中,更新文件可能需要比原始文件更多或更少的数据块。让被检索的集合sf的大小与两个版本中最大的那个文件相一致。如果更新后的版本比原始版本需要更少的数据块,那么sf中额外的数据块都要设置为空。如果更新后的文件需要更多的数据块,那么被检索的集合sf的大小要与更新后的
文件相一致;那么,在sf中额外的空闲数据块要用于扩展
服务器更新盲存储空间d′,并将更新的盲存储空间发送客户端。
需要明确的是,本发明并不局限于上文所描述并在图中示出的特定配置和处理。为了简明起见,这里省略了对已知方法的详细描述。在上述实施例中,描述和示出了若干具体的步骤作为示例。但是,本发明的方法过程并不限于所描述和示出的具体步骤,本领域的技术人员可以在领会本发明的精神后,作出各种改变、修改和添加,或者改变步骤之间的顺序。
还需要说明的是,本发明中提及的示例性实施例,基于一系列的步骤或者装置描述一些方法或系统。但是,本发明不局限于上述步骤的顺序,也就是说,可以按照实施例中提及的顺序执行步骤,也可以不同于实施例中的顺序,或者若干步骤同时执行。
最后应说明的是:以上所述的各实施例仅用于说明本发明的技术方案,而非对其限制;尽管参照前述实施例对本发明进行了详细的说明,本领域的普通技术人员应当理解:其依然可以对前述实施例所记载的技术方案进行修改,或者对其中部分或全部技术特征进行等同替换;而这些修改或替换,并不使相应技术方案的本质脱离本发明各实施例技术方案的范围。
- 还没有人留言评论。精彩留言会获得点赞!