基于概率密度函数拟合和模糊逻辑的相干光通信系统盲均衡方法与流程
本发明属于数字相干光通信技术领域,具体是指基于概率密度函数拟合和模糊逻辑的相干光通信系统盲均衡方法。
背景技术:
随着光通信网络在容量上的需求日益增加,人们提出了很多提高传输容量和频谱效率的技术。例如,结合了可有效消除传播损耗的数字信号处理(DSP)技术的数字相干接收器,已彻底改变了光通信系统的设计方式。同时,偏振复用(PolMux)相干技术因其能使系统频谱效率加倍而被广泛应用于相干光通信系统中。
此外,为满足光通信系统日益增长的容量需求,涉及两种技术:采用M进制相移键控调制(MPSK)和M进制正交幅度调制(MQAM)等高阶多级调制,相干正交频分复用(Co-OFDM)和奈奎斯特波分复用(WDM)等光副载波多路复用技术。然而,当调制星座大小增加,码间干扰(ISI)也相应的大幅增加,这就给用来消除由传输损耗(如色度色散(CD)和偏振模色散(PMD))引起的码间干扰(ISI)的DSP算法带来了新的挑战。为了消除码间干扰(ISI),盲均衡器因其避免了传输导频数据,且其带宽利用率高,从而在光通信系统中有非常重要的应用。过去几十年中,涌现了大量关于高阶正交幅度调制(QAM)相干传输系统的盲均衡器的有价值的研究成果,其中恒模算法(CMA)和多模算法(MMA)最有名。恒模算法(CMA)和多模算法(MMA)最小化一个代价函数,从而间接提取均衡器输出端信号的高阶统计量或码间干扰(ISI)的当前水平。然而,恒模算法(CMA)仅对恒模调制有效,对于高阶正交幅度调制(QAM)系统则存在较大的误差。此外,恒模算法(CMA)和多模算法(MMA)的收敛性能与步长的选择密切相关。由于上述问题,期望找到更好的代价函数使得性能得以改进。
由信息理论的知识可知,数据分布比基于简单统计的评估包含更多的信息。因此,可预测基于数据分布的均衡器性能优于仅基于简单统计(如CMA,MMA)的均衡器性能。基于信息理论准则和传输数据概率密度函数(PDF)评估的盲均衡技术已被应用于盲反卷积线性信道,并实现了良好的性能。在此类均衡器中,运用Parzen窗评估数据概率密度函数(PDF)。
然而,由于此技术无法克服相位模糊问题,因此需要一个载波相位旋转器产生正确的星座方向。此外,Parzen窗法的关键之处是窗口大小的选择,其最佳内核的大小很难选择。因此,对于不同的应用程序,可能会采取不同的方法,无法做到自适应调整匹配。
技术实现要素:
本发明实施例所要解决的技术问题在于,提供一种基于概率密度函数拟合和模糊逻辑的相干光通信系统盲均衡方法。通过该方法保持相位恢复的能力,使得Parzen窗的内核大小可以使用模糊逻辑方法自适应调整,以产生从盲均衡到决策引导均衡的软过渡。
为实现上述目的,本发明的技术方案是包括步骤:
(1)、步骤(1)包括以下分步骤:
(1.1)已调符号序列{s(k)}通过一个成型滤波器g(t),输出基带信号矩阵,其中,k表示第k个码元、t表示时间;然后基带信号在光信道中传播受到加性噪声的影响输出连续时间矩阵信号;
(1.2)对连续时间矩阵信号进行采样,分别得到基于X方向偏振的p信道和基于Y方向偏振的q信道的离散时间信号;
(1.3)光通信接收端蝶形分数间隔均衡器的输出信号,该输出信号包括有基于X方向偏振的p信道的输出信号和基于Y方向偏振的q信道的输出信号;
(2)、分别计算蝶形分数间隔均衡器输出信号与概率密度函数实部、虚部之间的平方距离;
(3)、使用Parzen窗方法的无参数估计值估计概率密度函数值,使得光通信接收端蝶形分数间隔均衡器输出端的概率密度函数的实部和虚部匹配所发送的已知星座,Parzen窗的内核大小基于模糊逻辑原则自适应调整。
进一步设置是所述的步骤(1.1)中:
基带信号矩阵x(t)=[xp(t),xq(t)]T,p和q分别表示X方向偏振和Y方向偏振,上标T表示矩阵转置,k表示第k个码元,t表示时间;
连续时间矩阵信号其中t0表示时间延迟,连续时间矩阵信号y(t)=[yp(t),yq(t)]T,yp(t),yq(t)中的yp和yq表示p信道和q信道的均衡器输出;
加性高斯噪声n(t)=[np(t),nq(t)]T,np(t),nq(t)中的np和nq表示p信道和q信道的噪声;信道脉冲响应c(t)表示为:这里cp,p(t)和cp,q(t)分别表示p发送端与p接收端之间以及p发送端与q接收端之间的信道冲激响应;Ts为符号周期,n表示第n个码元。
进一步设置是所述的步骤(1.2)为:对信号y(t)进行采样得到离散时间信号yp(n)和yq(n):
式中Ts为符号周期,n表示第n个码元。
进一步设置是所述的步骤(1.3)为:接收端蝶形分数间隔均衡器(FSE)的输出信号zp(n)和zq(n)分别为:
其中L是蝶形分数间隔均衡器的长度,蝶形分数间隔均衡器权系数向量w表示为
其中,
wp,q=[wp,q(2i),wp,q(2i+1)]
wp,p=[wp,p(2i),wp,p(2i+1)]
wq,p=[wq,p(2i),wq,p(2i+1)]
wq,q=[wq,q(2i),wq,q(2i+1)]
其中:wp,q,wp,p,wq,q,wq,p分别为p发送端与q接收端,p发送端与p接收端,q发送端与q接收端,q发送端与p接收端的均衡器权值向量;wp,q,wp,p,wq,p,wq,q分别表示相应的抽头系数,i表示抽头的位置。
进一步设置是所述步骤(2)中,代价函数定义为:
这里:和分别表示实部和虚部;b为正整数;s表示发送数据,x表示接收数据,fX(x)表示X指代价函数中的在x处的概率密度函数。
进一步设置是所述步骤(3)使用Parzen窗方法的无参数估计值估计PDF值为:
其中:b为正整数,为fX(x)的估计值,为的估计值,为的估计值,为的估计值,为的估计值;NL表示符号总数;Ns为星座中复合符号的数量;表示Parzen窗的内核,内核大小为σ0。
进一步设置是所述步骤(3)中基于模糊逻辑原则自适应调整Parzen窗的内核大小,包括以下分步骤:
(7.1)该系统将两个输入变量和映射到一个大小正好为σ(n)的内核中,两个输入变量分别定义为:
δ|en|2=|en|2-|en-1|2
其中:Nsm是获取短期平均数过程中的错误采样数;表示取整运算。
(7.2)判决误差e(k)表示为:e(k)=d(k)-z(k),d为预期值。
(7.3)选择高斯隶属函数以覆盖输入和输出变量的整体:
其中:对于|en|2,X表示范围为小(Se),中(Me),大(Le)的模糊集合被用来划分论域,除x≥a,mLe=1的情况之外,Xc表示质心分别为Sec,Mec,Lec的高斯隶属函数,ρ表示ρe;对于δ|en|2,X表示模糊集负数(Nδ),零(Zδ)和正数(Pδ),除和的情况以外,Xc表示质心分别为Nδc,Zδc和Pδc的高斯隶属函,ρ表示ρδ。
(7.4)模糊集合用来划分大小为σ的内核,并标记为小(Sσ),中(Mσ)和大(Lσ),采用最小值运算来截断每个规则的输出模糊集合。
本发明效果实例:
对于模糊推理系统FIS,分别需要6个指数运算用于更新X和Y偏振方向的每个σn。注意,由于每个Nsm样本,σn更新一次,因此Nsm除以计算复杂度用来更新每个符号。
与现有技术相比,本发明所具有的有益效果为:本发明假设了两个一维高斯分布(实部和虚部各一个),因此它可以保持相位恢复的能力。Parzen窗的内核大小可以使用模糊逻辑方法自适应调整,以产生从盲均衡到决策引导均衡的软过渡;本发明的方法可以获得比恒模算法(CMA)和多模算法(MMA)更快的收敛速度和更小的稳定MSE,适用于偏振复用(PolMux)正交幅度调制(QAM)相干光通信系统中。。
本发明的技术方案用于偏振复用(PolMux)相干光通信系统,特别是在均衡器输出端,运用Parzen窗评估数据概率密度函数(PDF)时无法克服相位模糊问题且无法确定Parzen窗内核大小的情况,是一种运用模糊推理系统(FIS)自适应调整Parzen窗的内核大小的盲均衡方法。
附图说明
为了更清楚地说明本发明实施例或现有技术中的技术方案,下面将对实施例或现有技术描述中所需要使用的附图作简单地介绍,显而易见地,下面描述中的附图仅仅是本发明的一些实施例,对于本领域普通技术人员来讲,在不付出创造性劳动性的前提下,根据这些附图获得其他的附图仍属于本发明的范畴。
图1是本发明的信号模型图;
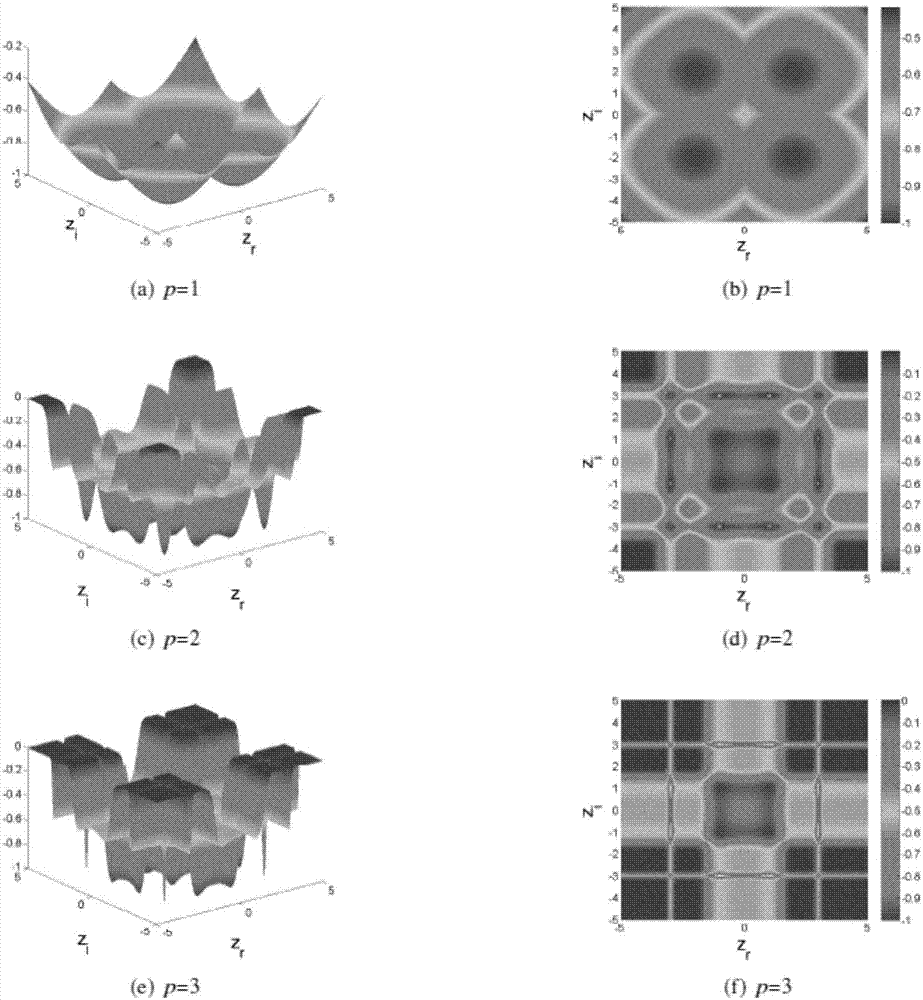
图2是本发明在16QAM调制方式下,当NL=1,σ=2,分别取p=1,2,3时,代价函数的三维表面图及等高线图;
图3是本发明在16QAM调制方式下,当p=2,分别取σ=2,3,6时,代价函数的三维表面和等高线图;
图4是本发明用于调整Parezen窗的内核大小的FIS示意图;
图5是本发明的FIS的输入变量|en|2的隶属函数与论域之间的关系曲线图;
图6是本发明的FIS的输入变量δ|en|2的隶属函数与论域之间的关系曲线图;
图7是在PolMux-16QAM相干系统中,进行均衡前信号以及分别应用了CMA、MMA和本发明所提出的基于PDF拟合和模糊逻辑的算法(PDF-FL)进行均衡后的符号星座图;
图8是在PolMux-16QAM相干系统中,CMA、MMA和PDF-FL的比特误码率(BER)与光信噪比(OSNR)的关系曲线图;
图9是在PolMux-16QAM相干系统中,CMA、MMA和PDF-FL的BER与剩余CD的关系曲线图;
图10是在PolMux-16QAM相干系统中,CMA、MMA和PDF-FL的BER与迭代次数的关系曲线图;
图11是在PolMux-16QAM相干系统中,CMA、MMA和PDF-FL的BER与旋转速度的关系曲线图;
图12是本发明的FIS的输入变量|en|2和δ|en|2,内核大小σn与迭代次数的关系图;
图13是本发明在PolMux-16QAM相干系统中,大小不同的内核的BER与迭代次数的关系曲线图。
具体实施方式
为使本发明的目的、技术方案和优点更加清楚,下面将结合附图对本发明作进一步地详细描述。
为本发明实施例中,本发明只涉及线性传播损伤,如色度色散(CD)和偏振膜色散(PMD)。同时,本发明的讨论仅限于光纤产生的线性损伤,相位恢复不属讨论范围。对于传输速率超过100Gps的系统,符号周期远小于信道的相干时间,因此可以假设光传播信道的所有过程都是线性时不变的。
本发明提供了一种基于概率密度函数(PDF)拟合和模糊逻辑的相干光通信系统盲均衡方法,包括以下步骤:
(1)本发明的信号模型如图1所示,首先,已调符号序列{s(k)}(k表示第k个码元)通过一个成型滤波器g(t)(t表示时间),输出基带信号矩阵x(t)=[xp(t),xq(t)]T,这里p和q分别表示X方向偏振和Y方向偏振,上标T表示矩阵转置,接着基带信号在光信道中传播,受到加性噪声的影响输出连续时间矩阵信号:
其中连续时间矩阵信号y(t)=[yp(t),yq(t)]T,其中t0表示时间延迟,yp和yq表示p信道和q信道的均衡器输出;加性高斯噪声n(t)=[np(t),nq(t)]T,np和nq表示p信道和q信道的噪声;信道脉冲响应c(t)表示为:这里cp,p(t)和cp,q(t)分别表示p发送端与p接收端之间以及p发送端与q接收端之间的信道冲激响应。
然后对信号y(t)进行采样得到离散时间信号yp(n)和yq(n):
式中Ts为符号周期,n表示第n个码元。最后接收端蝶形分数间隔均衡器(FSE)的输出信号zp(n)和zq(n)分别为:
其中L是蝶形FSE的长度。蝶形FSE的权系数向量w表示为:
这里:
wp,q=[wp,q(2i),wp,q(2i+1)]
wp,p=[wp,p(2i),wp,p(2i+1)]
wq,p=[wq,p(2i),wq,p(2i+1)]
wq,q=[wq,q(2i),wq,q(2i+1)]
其中:wp,q,wp,p,wq,q,wq,p分别为p发送端与q接收端,p发送端与p接收端,q发送端与q接收端,q发送端与p接收端的均衡器权值向量;wp,q,wp,p,wq,p,wq,q分别表示相应的抽头系数,i表示抽头的位置。
(2)分别计算均衡器输出与PDF实部和虚部之间的平方距离。代价函数定义为:
这里:和分别表示实部和虚部;b为正整数;s表示发送数据,x表示接收数据,fX(x)表示X指代价函数中的在x处的PDF。
(3)使用Parzen窗方法的无参数估计值估计PDF值:
其中:b为正整数,为fX(x)的估计值,为的估计值,为的估计值,为的估计值,为的估计值;NL表示符号总数;Ns为星座中复合符号的数量,各符号的概率近似相等;表示Parzen窗的内核,内核大小为σ0。若考虑高斯核,可得:
其中:高斯核函数π为圆周率;C1和C2为正数。
(4)在应用中,内核σ的大小通常取决于对偏差或方差的敏感程度。当应用于均衡器时,选择一个较大的σ意味着一个均衡符号和星座图中更多符号的相互作用,这会导致快速收敛,然而一个小的σ会使最后方案的准确度更高。当b=2,分别取σ=2,3,6时,代价函数的三维表面和等值图如图3所示。显然,σ越大,全局收敛速度越快,准确度越低,反之亦然。因此,σ的值在收敛过程中应自适应调整。模糊推理系统(FIS)基于模糊逻辑原则自适应调整Parzen窗的内核大小。
(5)结合步骤(3),将步骤(2)中的代价函数改写为:
这里右边第三部分const(常数)与w是相互独立的。
假设NL=1,当σ=2,分别取b=1,2,3时,16QAM的代价函数J(w)的三维表面和等值图如图2所示。显然,b的值越小,表面越平滑。当b=2时,理想16QAM星座图中的一些点如[(±1,±1),(±1,±3),(±3,±1),(±3,±3)]存在对应于代价函数J(w)的全局极小值,这些值可通过随机梯度下降法得到。因此,本发明取b=2。
(6)取NL=1,b=2,J(w)相对均衡器系数的导数为:
其中:▽表示梯度运算;K′(·)是K(·)的导数;上标*表示复共轭运算;j表示虚数单位。
(7)用RR表示|sR(l)|2,RI表示|sI(l)|2,且式中E[·]是数学期望运算,将步骤(5)中的公式改写为:
调整均衡器系数权值可按如下规则调整,直至代价函数不再大幅变换,更新截止:
其中μ为步长函数。指出:为补偿高斯核Kσ′(x)中的项,采用了一个大小为σ3的3倍的标准步长。
(4)本发明选择的基于模糊逻辑原则FIS如图4所示,步骤如下:
(4.1)该系统将两个输入变量和映射到一个大小正好为σ(n)的内核中,两个输入变量分别定义为:
δ|en|2=|en|2-|en-1|2
其中:Nsm是获取短期平均数过程中的错误采样数;表示取整运算。
(4.2)判决误差e(k)表示为:e(k)=d(k)-z(k),d为预期值。
(4.3)选择高斯隶属函数(MBFs)以覆盖输入和输出变量的整体:
其中:对于|en|2,X表示范围为小(Se),中(Me),大(Le)的模糊集合被用来划分论域,除x≥a,mLe=1的情况之外,Xc表示质心分别为Sec,Mec,Lec的MBFs(如图5所示),ρ表示ρe;对于δ|en|2,X表示模糊集负数(Nδ),零(Zδ)和正数(Pδ),除和的情况以外,Xc表示质心分别为Nδc,Zδc和Pδc的MBFs(如图6所示),ρ表示ρδ。
(4.4)模糊集合用来划分大小为σ的内核,并标记为小(Sσ),中(Mσ)和大(Lσ)。如表1所示:
表1
通常采用最小值运算来截断每个规则的输出模糊集合。例如,MBF在σn[5]的值为:
式中,min{·}表示最小值运算。
本发明效果实例:
对于FLS,分别需要6个指数运算用于更新X和Y偏振方向的每个σn。注意,由于每个Nsm样本,σn更新一次,因此Nsm除以计算复杂度用来更新每个符号。
本发明用仿真结果说明和验证理论的发展。本发明在符号速率为14GBaud的PolMux-16QAM相干系统中进行。伪随机序列的长度为16384。由于本发明不讨论相位恢复,激光器差拍线宽设置为0。均衡器长度L=9。
仿真中的参数设置如下:CMA和MMA的步长为1×10-5。对于PDF-FL,步长为4×10-4,a=1,b=0.2,ρe=0.01,ρδ=0.001,Nsm=20。Sσ,Mσ,Lσ分别为2,6,12。参数的选择已通过大量的仿真研究得到验证。
图7是进行均衡前信号以及分别应用了CMA、MMA和PDF-FL进行均衡后的符号星座图,传播信道设置如下:CD=1000ps/nm,DGD延迟τDGD=50ps,偏振旋转角度θ=π/4(最坏情况),OSNR=20dB。可见,PDF-FL算法的符号星座图比CMA和MMA的更集中,更清晰,其性能超过CMA和MMA。图8是CMA、MMA和PDF-FL的BER与OSNR的关系曲线图,由图可知,PDF-FL算法比CMA和MMA更高效。图9是CMA、MMA和PDF-FL的BER与剩余CD的关系曲线图,可知PDF-FL算法的BER明显低于MMA和CMA。图10是CMA、MMA和PDF-FL的BER与迭代次数的关系曲线图,可以发现PDF-FL可以在稳态下实现更快的收敛速度和较小的稳定BER。图11是CMA,MMA和PDF-FL的BER与旋转速度的关系曲线图,很明显,三个均衡器的性能是相似的。均衡器能够跟踪角频率的范围为8×105rad/s(弧度/秒)以内。当w<8×105rad/s,PDF-FL的性能优于CMA和MMA。图12是本发明的FIS的输入变量|en|2和δ|en|2,内核大小σn与与迭代次数的关系图,可以发现,在初始阶段(大约从0到60次迭代),|en|2,δ|en|2很大,选择大的内核来加快收敛速度。另外,当|en|2,δ|en|2很小时,选择小的内核以获得小且稳定的MSE。图13是大小不同的内核的BER与迭代次数的关系曲线图,可以发现,对于大内核该算法收敛速度快,但MSE大。另一方面,对于小内核,该算法MSE小但收敛速度慢,对于PDF-FL,如图12所示,内核大小根据|en|2和δ|en|2自适应变化,以此在稳态下获得快速收敛速率和小且稳定的MSE。
本领域普通技术人员可以理解实现上述实施例方法中的全部或部分步骤是可以通过程序来指令相关的硬件来完成,所述的程序可以存储于一计算机可读取存储介质中,所述的存储介质,如ROM/RAM、磁盘、光盘等。
以上所揭露的仅为本发明较佳实施例而已,当然不能以此来限定本发明之权利范围,因此依本发明权利要求所作的等同变化,仍属本发明所涵盖的范围。
- 还没有人留言评论。精彩留言会获得点赞!