一种基于DNS映射IP的恶意域名匹配方法与流程
本发明是关于网络安全领域,特别涉及一种基于dns映射ip的恶意域名匹配方法。
背景技术
病毒、木马在感染设备后,往往会通过回连访问命令与控制服务器(c&c服务器),以获取新的指令或上传窃取的信息,回连访问c&c服务器通常用有固定域名、固定ip、dga域名等方式。
传统的恶意域名恶意ip检测手段主要是对使用固定域名和固定ip的回连行为进行域名、ip匹配,而大多数恶意域名匹配系统都只匹配了web中的域名,但是事实上,使用固定域名的回连远不止web协议,还有很多其他的协议甚至自己实现的socket连接。
很多病毒往往是将固定域名通过dns实时解析成对应的ip,然后直接对这个ip进行访问,所使用的协议、端口各式各样,也可以是完全自己实现的socket连接。通过这种方式实现的回连,尤其是域名对应的ip经常变化的时候,即使是拥有这些已知病毒的固定回连域名,传统只匹配web中域名的方法也依然检测不到。
技术实现要素:
本发明的主要目的在于克服现有技术中的不足,提供一种能对已知恶意域名的访问行为进行匹配告警,同时能对非常用协议或加密流量进行数据包保存的方法。为解决上述技术问题,本发明的解决方案是:
提供一种基于dns映射ip的恶意域名匹配方法,具体包括下面步骤:
步骤一:搜集c&c域名:
搜集已知的c&c域名(从国内外多个安全网站上搜集已知的c&c域名),形成恶意域名名单库;
所述恶意域名名单库是域名的集合(已知的被黑客利用的域名,后续需要持续更新加入新的恶意域名并删除已经无效的域名);
步骤二:采集流量(流量采集模块):
使用dpdk捕获流经网卡的全部ip协议流量数据包,用于后续分析;
步骤三:解析dns流量(dns解析模块):
对步骤二采集的ip协议流量数据包,先判断流量是否属于dns协议:
如果是dns协议,则按照dns协议格式进行解析,解析得到相关信息,相关信息包括请求的域名、请求的时间、域名对应的ip地址和域名对应ip的ttl(域名解析的生命周期),然后进入步骤四;
如果不是dns协议,则进入步骤五;
步骤四:识别dns中的恶意域名(恶意域名识别模块):
判断dns请求的域名是否属于恶意域名:
如果不属于恶意域名,则结束,不再进行后续步骤;
如果属于恶意域名,则判断域名对应的ip地址是否属于公网ip:如果是公网ip,则将该域名对应的ip地址加入恶意ip名单库,并记录有效时间,如果该域名对应的ip地址已经在恶意ip名单库中,则更新有效时间;如果不是公网ip,则结束,不再进行后续步骤;
所述恶意ip名单库是恶意域名对应的ip地址的集合,且每个恶意ip保存有效时间,对应的恶意域名(恶意ip名单库是恶意域名名单库根据dns流量,把域名和ip对应起来后形成的,这个域名和ip的对应是有有效时间的);
所述有效时间是指请求的时间和域名对应ip的ttl(请求时间+ttl);
步骤五:识别恶意ip(恶意ip识别模块):
对于不是dns协议的流量,判断数据包中源ip和目的ip是否属于恶意ip名单库:
如果源ip和目的ip中至少有一个属于恶意ip名单库,则判断该数据包的时间是否在该恶意ip的有效时间内:如果在有效时间内,则进入步骤六;如果不在有效时间内,则结束,不再进行后续步骤;
如果源ip和目的ip都不属于恶意ip名单库,则结束,不再进行后续步骤;
步骤六:保存数据包(数据包保存模块):
以ip对为维度保存数据包:将源ip和目的ip相同或相反的数据包保存到同一个文件(数据包文件);
步骤七:解析识别协议(协议解析模块):
先判断数据包是否是常用解析(常用协议包括http、smb、pop、smtp、imap、ftp、telnet等协议):
如果不是常用协议,则直接进行告警,告警信息包括访问时间、访问的源ip、访问的目的ip、恶意ip以及其对应的恶意域名、使用的端口和保存的数据包;
如果是常用协议,则按照相应协议规范进行解析还原,并产生告警,告警信息包括访问时间、访问的源ip、访问的目的ip、恶意ip以及其对应的恶意域名、使用的端口、保存的数据包、使用的协议和解析后的内容。
本发明的工作原理:要成功访问域名必然会产生dns流量,并且dns流量中必然存在域名对应的ip。本发明通过dns流量映射某个时间段内恶意域名对应的恶意ip,并匹配映射后的恶意ip,同时基于全ip流量进行匹配并保存数据包,可以匹配非web的恶意域名访问行为,对于非常用协议或加密的恶意域名访问行为具有保存数据包供后续分析研究。
与现有技术相比,本发明的有益效果是:
本发明通过dns实时流量实时映射已知恶意域名对应的ip,并对全ip流量进行匹配,能捕获访问恶意域名的具体行为,并且不只是web协议的,其他协议的也能捕获。
本发明可以有效地对访问恶意域名的行为进行告警,包括匹配非web的恶意域名访问行为(非web的恶意域名访问行为是指先通过dns域名解析获取动态ip,然后直接对该ip进行访问的行为),同时对非常用协议或加密流量进行数据包保存供后续分析研究。
附图说明
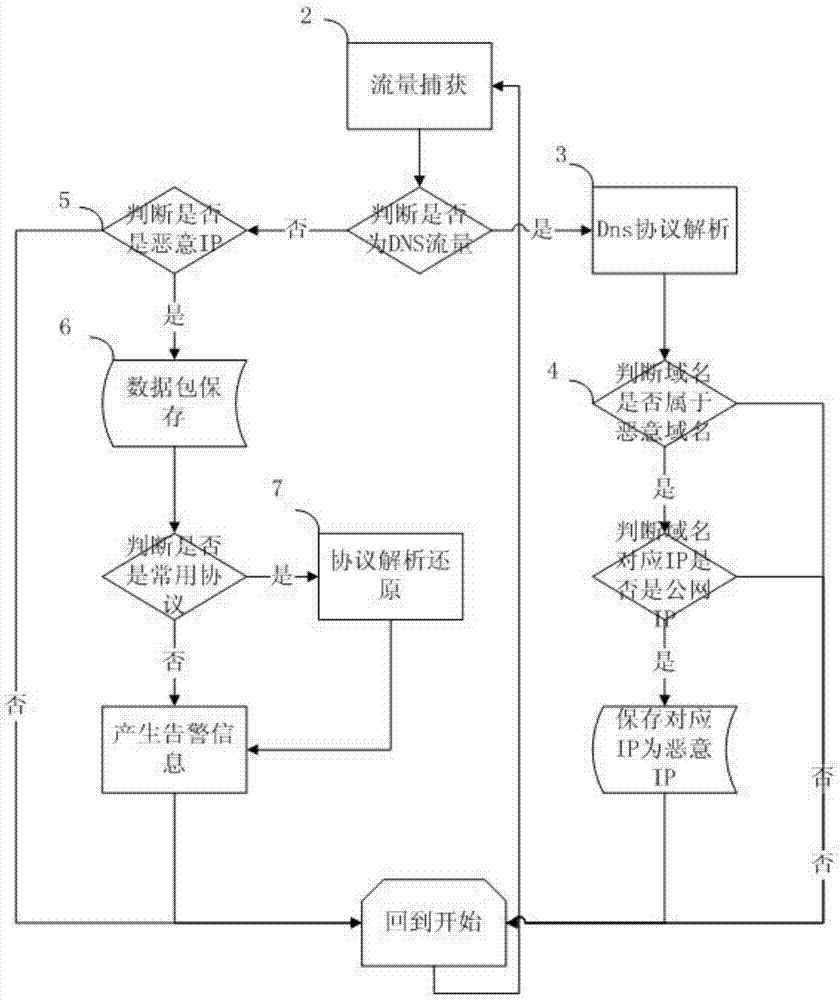
图1为本发明的工作流程图。
具体实施方式
下面结合附图与具体实施方式对本发明作进一步详细描述:
如图1所示的一种基于dns映射ip的恶意域名匹配方法,具体包括下面步骤:
步骤一:搜集c&c域名:
从国内外多个安全网站上搜集已知的c&c域名,形成恶意域名名单库。
所述恶意域名名单库是指:已知的被黑客利用的域名的集合,后续需要持续更新加入新的恶意域名并删除已经无效的域名。
步骤二:流量采集模块采集流量:
采集模块使用dpdk捕获流经网卡的全部ip协议流量数据包,用于后续分析。
步骤三:dns解析模块解析dns流量:
对步骤二采集的ip协议流量数据包,dns解析模块先判断流量是否属于dns协议:
如果是dns协议,则按照dns协议格式进行解析,解析得到请求的域名、请求的时间、域名对应的ip地址和域名对应ip的ttl(域名解析的生命周期)等信息,然后进入步骤四。
如果不是dns协议,则进入步骤五。
步骤四:恶意域名识别模块识别dns中的恶意域名:
恶意域名识别模块判断dns请求的域名是否属于恶意域名:
如果不属于恶意域名,则结束。
如果属于恶意域名,则判断域名对应的ip地址是否属于公网ip:如果是公网ip,则将域名对应的ip地址加入恶意ip名单库,并记录有效时间(请求时间+ttl),如果域名对应的ip地址已经在恶意ip名单库中,则更新有效时间;如果不是公网ip,则结束。
所述恶意ip名单库是指:恶意域名对应的ip地址的集合,每个恶意ip需要保存有效时间,对应的恶意域名。
步骤五:恶意ip识别模块识别恶意ip:
对于不是dns协议的流量,由恶意ip识别模块判断数据包中源ip和目的ip是否属于恶意ip名单库:
如果源ip和目的ip中至少有一个属于恶意ip名单库,则判断该数据包的时间是否在该恶意ip的有效时间内:如果在有效时间内,则进入步骤六;如果不在有效时间内,则结束。
如果源ip和目的ip都不属于恶意ip名单库,则结束。
步骤六:数据包保存模块保存数据包:
对于识别为恶意ip的数据包,数据包保存模块以ip对为维度保存数据包。以ip对为维度是指将同一ip对之间的数据包保存到同一个数据包文件中。
步骤七:协议解析模块解析识别协议:
协议解析模块先判断数据包是否是常用解析(常用协议包括http、smb、pop、smtp、imap、ftp、telnet等协议):
如果不是常用协议,则直接进行告警,告警信息包括访问时间、访问的源ip、访问的目的ip、恶意ip以及其对应的恶意域名、使用的端口和保存的数据包等信息。
如果是常用协议,则按照相应协议规范进行解析还原,并产生告警,告警信息包括访问时间、访问的源ip、访问的目的ip、恶意ip以及其对应的恶意域名、使用的端口、保存的数据包、使用的协议和解析后的内容等信息。
最后,需要注意的是,以上列举的仅是本发明的具体实施例。显然,本发明不限于以上实施例,还可以有很多变形。本领域的普通技术人员能从本发明公开的内容中直接导出或联想到的所有变形,均应认为是本发明的保护范围。
- 还没有人留言评论。精彩留言会获得点赞!