一种用于HEVC的CU划分方法与流程
本发明涉及视频编码技术领域,具体涉及高效视频编码技术hevc(h.265)。
背景技术:
名词解释:
hevc:highefficiencyvideocoding,高性能视频编码
ctu:codingtreeunit,编码树单元
cu:codingunit,编码单元
pu:predictionunit,预测单元
rd:ratedistortion,率失真
近年来,随着计算机技术和互联网的发展,数字视频在视频通信,影视娱乐,安防监控,军事勘探等领域发挥着越来越重要的作用。而图像和视频这类信息含有较大部分的冗余信息,价值密度低,直接存储会浪费巨大的存储空间,因此高效率的视频压缩技术是视频应用的前提。随着2k、4k超高清分辨率的提出,现有的h.264/avc技术已经无法达到其相应的压缩率。
为满足海量超清视频数据的传输和存储要求,视频编码国际标准组织jct-vc(jointcollaborativeteamonvideocoding)于2013年提出了新一代视频压缩标准hevc(highefficiencyvideocoding)。和上一代视频压缩标准h.264/avc对比,它能够在保证相同的视频质量的前提下,节约大概一半的码率。然而hevc在降低码率的同时,使计算复杂度大大提高,巨大的计算了限制了该技术在实时视频传输的推广与应用。
cu的四叉树划分技术是hevc提出的一个很重要的创新点。对于图像上纹理细节匮乏或者变化不大的区域,如果采用小尺寸cu预测,可能会携带大量冗余的编码信息,降低压缩效率,因此这些区域适合用大尺寸cu来进行预测编码。对于图像上纹理细节丰富或者变化剧烈的区域,只有小尺寸的cu才可以保证预测的准确性。cu的四叉树划分结构正是基于这两点,从而进一步提高了hevc的压缩效率。
ctu是在编码过程中的独立编码单位,而每一个ctu可以进一步均匀划分成4个cu,一个cu又可以递归地按四叉树结构划分成4个更小的cus,依次类推,直到cu的划分深度达到最大值3的时候,终止cu的分割。当ctu的尺寸是64x64时,根据其划分深度(0,1,2,3)的不同,cu可以分为64x64,32x32,16x16,8x8四种尺寸大小。在对某一个ctu进行预测编码时,首先需要令不同深度的cu全部遍历一遍,即对85种可能的cu划分情况下的预测残差进行量化、编码,需要计算多次率失真代价。然后再根据率失真代价得到cu的最佳划分结果。
因此,为了使该技术更好地推广到对实时性要求高的视频应用中,亟需一种低复杂度的hevc算法,在几乎不影响比特率和视频质量的前提下,能够节约编码时间,特别是能加快效率极低的cu划分过程。
技术实现要素:
本发明的目的是为了解决现有hevc编码的计算复杂度高,编码速度慢的问题,而提出一种用于hevc的cu划分方法。
一种用于hevc的cu划分方法,具体过程为:
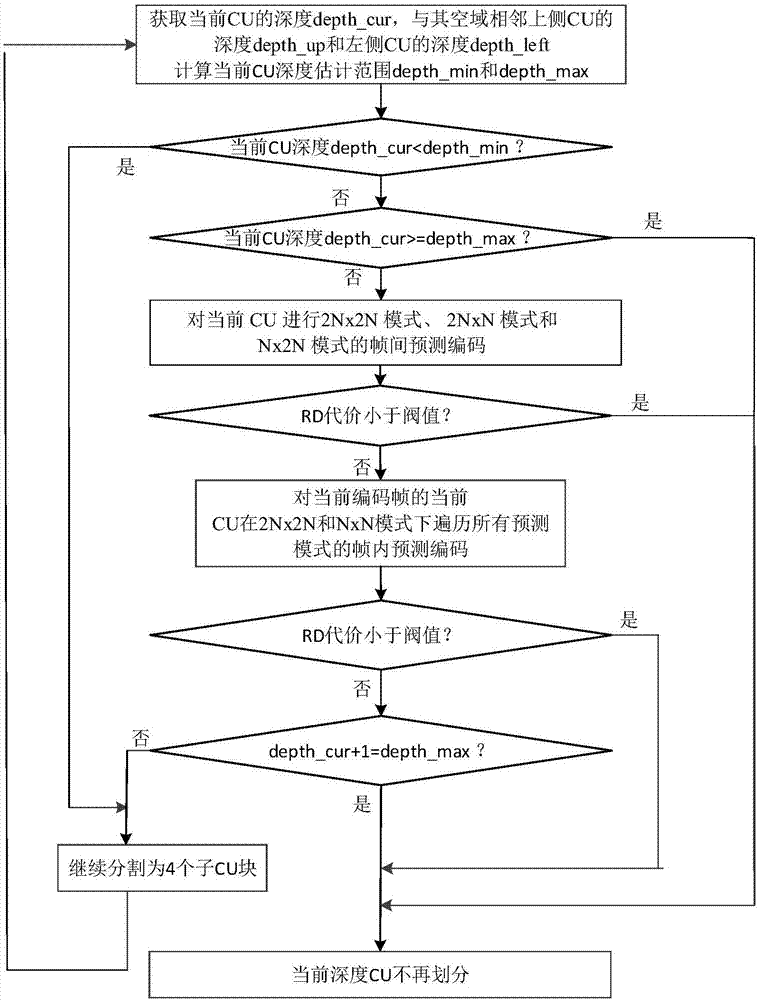
步骤1、当前编码帧的当前cu的大小为2nx2n,获取当前编码帧的当前cu的深度depth_cur,并获取与当前编码帧的当前cu空域相邻上侧cu和左侧cu的深度,从而估计出当前编码帧的当前cu深度最小值depth_min和最大值depth_max;
即|depth_cur-depth_up|≤1和|depth_cur-depth_left|≤1;
若当前编码帧的当前cu的深度depth_cur小于估计出的当前编码帧的当前cu深度最小值depth_min,则执行步骤5;
若当前编码帧的当前cu的深度depth_cur大于或等于估计出的当前编码帧的当前cu深度最大值depth_max,则执行步骤6;
反之,执行步骤2;
所述cu为编码单元;n取值为2n,且为正整数;
步骤2、对当前编码帧的当前cu进行2nx2n模式、2nxn模式和nx2n模式的帧间预测编码,并计算相应每个模式下的率失真代价,若率失真代价小于阈值,则执行步骤6,反之执行步骤3;
步骤3、对当前编码帧的当前cu在2nx2n和nxn模式下遍历所有预测模式的帧内预测编码,并计算相应每个模式下的率失真代价,若率失真代价小于阈值,则执行步骤6,反之执行步骤4;
步骤4、判断当前编码帧的当前cu是否达到当前编码帧的当前cu深度最大值,即depth_cur=depth_max,若是,则执行步骤6,反之执行步骤5;
步骤5、将当前编码帧的当前cu继续分割为四个nxn大小相等的子cu,继续执行步骤1;
步骤6、当前编码帧的当前cu处理结束,不再继续划分。
本发明的有益效果为:
本发明提出一种用于hevc的cu划分方法,利用空域相邻cu的深度信息限定当前cu的深度范围,并将率失真代价作为cu划分是否提前终止的依据:如果当前cu的rd代价小于该阀值,则认为当前cu的帧内预测已经足够好,不需要再继续分割。而率失真代价的阈值则需要事先统计rd代价的概率分布。
(1)本发明利用空域相邻cu的深度信息来限定当前cu的深度范围,利用rd代价来判别是否提前结束cu的划分,无需遍历cu所有可能的四叉树结构,在几乎不影响比特率和视频质量的前提下,降低了hevc编码的计算复杂度,提高了hevc标准的编码速度。
(2)本发明可以同时兼容于帧内与帧间预测的cu划分过程,使加速效果更加明显。
(3)本发明可根据需要,在具体的编码质量需求和编码速度要求中权衡,得到一个较为合适的错误判决概率αt,从而实现快速cu划分。
实验时,设置量化参数qp=32,当αt=5%时,可以节约大约32.1%的编码时间,而当αt=10%时,可以节约38.3%左右的编码时间。
附图说明
图1是本发明的cu划分加速算法流程图;
图2是本发明中率失真代价阈值的计算过程流程图;
图3是本发明中实施例二的某一个具体的ctu的最优划分结构示意图;
图4是本发明中实施例二对图三中的ctu统计cu按照深度为0的情况划分结构示意图;
图5是本发明中实施例二对图三中的每个ctu统计cu按照深度为1的情况划分结构示意图;
图6是本发明中实施例二对图三中的每个ctu统计cu按照深度为2的情况划分结构示意图;
图7为本发明中实施例一中某个特定的cu上侧和左侧cu的示意图,其中l为当前cu的左侧cu,u为当前cu的上侧cu。
具体实施方式
具体实施方式一:结合图1说明本实施方式,本实施方式的一种用于hevc的cu划分方法具体过程为:
步骤1、当前编码帧的当前cu的大小为2nx2n,获取当前编码帧的当前cu的深度depth_cur,并获取与当前编码帧的当前cu空域(只考虑同一帧的上侧和左侧)相邻上侧cu和左侧cu的深度,从而估计出当前编码帧的当前cu深度最小值depth_min和最大值depth_max;
其中一个cu的左侧和上侧cu指的是与该cu左上角紧接着的左侧和上侧的cu(如图7所示)。
即|depth_cur-depth_up|≤1和|depth_cur-depth_left|≤1;
这个公式里是相邻上侧cu和左侧cu的深度是已知的,将两个方程组联立,可以估计出当前cu深度最小值depth_min和最大值depth_max,即估计出当前cu的深度范围;
若当前编码帧的当前cu的深度depth_cur小于估计出的当前编码帧的当前cu深度最小值depth_min,则执行步骤5;
若当前编码帧的当前cu的深度depth_cur大于或等于估计出的当前编码帧的当前cu深度最大值depth_max,则执行步骤6;
反之,执行步骤2;
所述cu为编码单元;n取值为2n,且为正整数;
步骤2、对当前编码帧的当前cu进行2nx2n模式、2nxn模式和nx2n模式的帧间预测编码,并计算相应每个模式下的率失真代价,若率失真代价小于阈值(该阈值的计算方法会在后续详细介绍),则执行步骤6,反之执行步骤3;
步骤3、对当前编码帧的当前cu在2nx2n和nxn模式下遍历所有预测模式的帧内预测编码,并计算相应每个模式下的率失真代价,若率失真代价小于阈值,则执行步骤6,反之执行步骤4;
步骤4、判断当前编码帧的当前cu是否达到当前编码帧的当前cu深度最大值(步骤1得到的),即depth_cur=depth_max,若是,则执行步骤6,反之执行步骤5;
步骤5、将当前编码帧的当前cu继续分割为四个nxn大小相等的子cu,继续执行步骤1;
步骤1的2n是会变化的,就是当前cu的大小,比如说步骤5分成16x16的cu了,执行步骤1时,2n就变成16了,n就变成8了;
步骤6、当前编码帧的当前cu处理结束,不再继续划分。
具体实施方式二:本实施方式与具体实施方式一不同的是:所述步骤2和步骤3中率失真代价的具体计算公式如下:
j(s,c,qp,λm)=ssd(s,c)+λmb(s,c,qp)
其中,j为率失真代价,λm表示拉格朗日乘数,qp表示量化系数,b是编码所需的比特数,s为原始cu,c为对原始cu进行帧间预测或者帧内预测得到的重建cu,ssd(s,c)表示s和c的差值平方和;
编码所需的比特率b通过hevc编码器对原始cus和重建cuc的预测残差进行量化编码得到。
通过对s和c的残差进行量化编码,得到比特数为b(s,c,qp),qp的大小影响b(s,c,qp);
ssd(s,c)具体计算方式如下:
式中,i为cu像素的行索引,j为cu像素的列索引,2n为cu尺寸大小,c(i,j)为预测重建cu第i行第j列的像素值,s(i,j)为原始cu第i行第j列的像素值。
其它步骤及参数与具体实施方式一相同。
具体实施方式三:结合图2说明本实施方式,本实施方式与具体实施方式一或二不同的是:所述量化系数qp取0~51之间的一个整数(每次只取一个qp值)。
其它步骤及参数与具体实施方式一或二相同。
具体实施方式四:本实施方式与具体实施方式一至三之一不同的是:所述步骤2和步骤3中的阈值按照以下具体方法设定:
步骤a1、挑选一些视频帧作为训练帧,给出错误判决概率αt,依次统计训练帧中每一帧的每个ctu的最优分割信息(已知的),如图3所示;
所述ctu为编码树单元;
步骤a2、记录ctu中深度范围在0-2之间的cu累积的总个数,n′(total)=n(total)+21;
n′(total)为当前累积得到的ctu中深度范围在0-2之间的cu的总个数;n(total)为上一次累积得到的深度范围在0-2之间的cu的总个数;21为每个ctu可能划分的且深度范围在0-2之间的cu总数;
图4是举了一个特例,图5-7是分析,深度0时,可划分的子cu个数为1,深度1时,可划分的子cu个数为4,深度2时,可划分的子cu个数为16,因此每个ctu可划分的cu总数为21;
根据ctu的最优分割信息,依次判断当前ctu中深度范围在0-2之间的cu是否为最优分割,若不是最优分割,记录当前cu的率失真代价,并统计当前ctu中不是最优分割cu总个数m,n′(split)=n(split)+m;
n′(split)为当前累积得到的ctu中不是最优分割cu总个数;n(split)为上一次累积得到的ctu中不是最优分割cu总个数;
若是最优分割,结束;
步骤a3、判断当前ctu是否为训练帧中最后一帧的最后一个ctu,如果是,得到深度范围在0-2之间的cu的总个数n′(total)和不是最优分割cu总个数n′(split),执行步骤a4;否则,n(total)=n′(total),n(split)=n′(split),获取下一个ctu的信息,执行步骤a2;
步骤a4、计算得出训练帧中所有cu中不是最优分割的统计概率
步骤a5、对不是最优分割的编码单元(cu)的率失真(rd)代价进行升序排列,从中选出位置位于
其它步骤及参数与具体实施方式一至三之一相同。
具体实施方式五:本实施方式与具体实施方式一至四之一不同的是:所述错误判决概率5%≤αt≤10%,αt是人为设定的。
错误判决概率是人为可调节的,可以在具体的编码质量需求和编码速度要求中权衡。当错误判决概率过小时,cu终止划分的误判率较小,编码质量高,但加速效果越不明显;而当错误判决概率过大时,尽管编码速度提升快,但编码质量下降较多。
其它步骤及参数与具体实施方式一至四之一相同。
采用以下实施例验证本发明的有益效果:
实施例一:
本实例详细介绍了本发明如何借助空域相邻cu的深度信息来估计当前cu的深度范围。
这里限定当前编码cu的深度与其左侧或者上侧cu之一的深度相差均不超过1。这是因为自然图像的信源有记忆性,其空间相邻像素块之间往往有很强的相关性。尤其对于高分辨率视频,纹理丰富或纹理平坦或变换缓慢或变化剧烈的区域,往往覆盖多个ctu。
参照下表,本实例将左侧cu和上侧cu所有的深度组合列举了出来。
表1
例如当左侧cu的深度是2,上侧cu的深度为3,当前cu的深度为0时,即可估计出当前cu的深度集合是{1,2,3},因此该cu可以直接跳过帧内和帧间预测,直接划分成四个子cu。在这种情形下,借助空域相邻cu的深度信息对cu的划分起到了加速的效果。
实施例二
本实施例对本发明中如何统计训练帧中分割更优的cu数目进行详细介绍。
首先将每一帧都划分为大小相等的ctu。然后对每一个ctu分别进行统计,这里设定ctu的大小均为64x64,假设某一个ctu的经过计算率失真代价得到的最优四叉树结构为表1。图3,图4,图5表明了统计cu时的顺序,即按照深度大小0,1,2的顺序,每个ctu一共需要统计21种cu的划分情况。
以表1为例,可以得到继续划分最优的子cu有:1,3,4,5,10,11,13,共有7个,则该ctu中n(spilt)=7,同时记录相应子cu的率失真代价。
本发明还可有其它多种实施例,在不背离本发明精神及其实质的情况下,本领域技术人员当可根据本发明作出各种相应的改变和变形,但这些相应的改变和变形都应属于本发明所附的权利要求的保护范围。
- 还没有人留言评论。精彩留言会获得点赞!