跨地域云数据中心间社交用户数据分布式存储方法及系统与流程
本发明属于社交网络、大数据副本和分布式存储领域技术领域,具体涉及一种跨地域云数据中心间社交用户数据分布式存储方法及系统。
背景技术:
信息时代互联网技术的不断进步正在影响甚至深刻改变本发明的生活,作为时下最热门的互联网应用之一,在线社交网络(onlinesocialnetworks,简称osns)吸引着全球几十亿用户的参与,人们利用社交网络可以结交朋友、发表观点、分享信息和交流感情等。可以说,社交网络不仅已成为现实人类社会在网络虚拟空间的投影,更是融入到人们的日常生活中。
随着新用户的不断涌入,社交网络的用户规模急剧增长,著名社交网站facebook在2017年第二季度的月度活跃用户数达到20亿,这一数字意味着全球每四个人中就有一个人每天在使用facebook;不仅如此,社交用户的分布也是相当广泛,地域上facebook的用户遍布五大洲。一方面,面对eb级的大数据副本(bigdata),任何集中存储技术都无法满足如此大规模数据副本的存储需求;另一方面,用户跨地域广泛分布的特点使得单一地域的单个云数据中心存储无法满足用户频繁跨地域访问的需求。近年来,内容分发网络(contentdeliverynetwork,简称cdn)技术被广泛应用于社交网络用户的跨地域分布式存储。
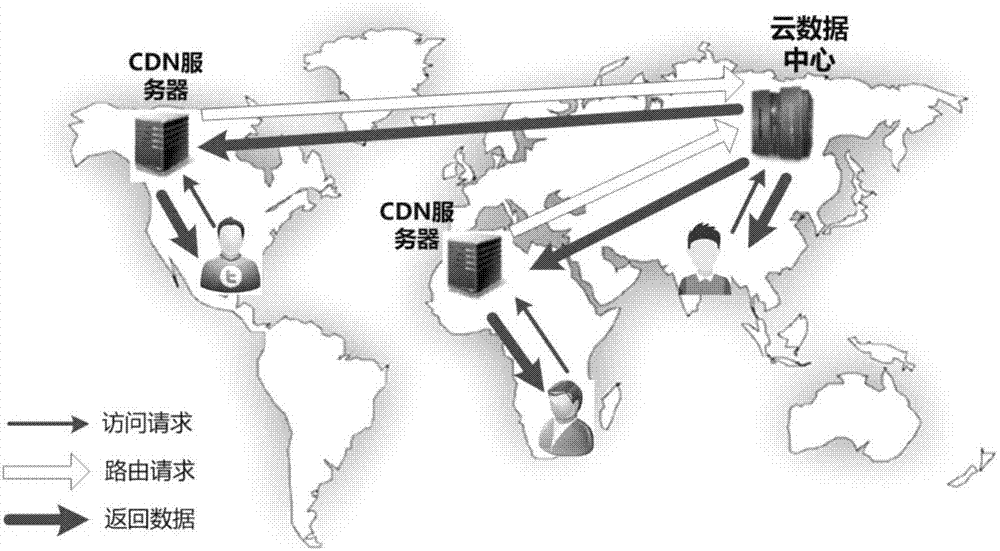
目前,许多社交网络服务商利用cdn技术来支持跨地域用户的访问,如图1所示,所有数据副本均存储在云数据中心内,近距离用户可直接访问该数据副本中心获取数据副本,对于远距离用来而言,他们的访问请求先到达就近的cdn服务器,cdn服务器会缓存部分数据副本,若缓存命中则直接返回数据副本,否则将请求路由到云数据中心获取访问数据副本,并将数据副本缓存在cdn服务器,以便后续访问使用。如今一些大型社交网络服务商开始在多地建立云数据中心,例如截止2017年facebook已在全球建立8个云数据中心,以支持世界各地用户的访问。如图2所示,数据副本中心间的数据副本同步主要采用全复制(fullreplication)的策略,即各地云数据中心的数据副本会周期性地汇总到一处,通常为主数据副本中心,然后再由主数据副本中心分发到其他云数据中心。
cdn技术用于支持社交网络跨地域用户访问的缺点在于:首先,社交网络的内部交互信息对cdn是透明的,cdn并不了解用户间的交互情况,它仅根据数据副本访问频度来决定缓存哪些用户数据副本,无法对跨地域用户访问提供精准的、可靠的支持;其次,由于缓存准确度不可靠,导致cdn服务器与云数据中心之间频繁通信,耗费大量网络带宽,增加高额的费用支出。在跨地域多数据副本中心环境下,全复制策略虽可以保障访问可靠性,降低访问延迟,但该策略缺点在于:首先,在所有数据副本中心保存所有用户的全部数据副本,存储开销巨大;其次,为了让所有云数据中心的数据副本保持同步,在数据副本中心间进行大量的数据副本交换,同样会产生巨大的网络开销。
鉴于上述的缺陷,本设计人积极加以研究创新,以期创设一种跨地域云数据中心间社交用户数据分布式存储方法及系统,使其更具有产业上的利用价值。
技术实现要素:
为解决上述技术问题,本发明的目的是提供一种降低存储开销和各数据副本中心间通信量,从而减少存储系统运行的成本费用的跨地域云数据中心间社交用户数据分布式存储方法及系统。
为达到上述发明目的,本发明跨地域云数据中心间社交用户数据分布式存储方法,包括:
s1构建网络社交模型图g=(v,e,r,w),其中,以社交网络中每个用户u作为社交图g中的一个顶点,用户v为与用户u有交互关系的用户,用户u与用户v间的交互关系用交互边euv表示;e为社交用户间交互关系集合,r为任意交互边上读操作频度的集合,w表示任意交互边上写操作频度的集合;用户u与用户v间交互的数据副本操作至少包括两种,即读操作ruv和写操作wuv,ruv∈r,wuv∈w;
s2将各用户u的数据副本分布放置于该用户u的至少一个可用云数据中心,其中所述可用云数据中心满足用户u、与该用户有交互关系的用户v对访问延迟的要求,且存储单价最低;
s3分别找到迁移候选目标集合xu和迁移候选源集合yu,以得到多个候选迁移方案,计算所有候选迁移方案的迁移费用,选择其中费用最小的迁移方案执行用户u的数据副本的数据迁移;其中,找出满足与用户u有交互关系的用户v的访问延迟要求且存储单价最低的云数据中心集合lv,对所有云数据中心集合lv求交集得到迁移候选目标集合xu;将存储用户u的数据副本的云数据中心集合du分别与每一个集合lv求交集,求得结果的集合再合并求并集,得到迁移候选源集合yu。
进一步地,所述的s2具体包括:
s2.1确定用户u的可用云数据中心,选择所述的可用云数据中心中满足所述用户u访问延迟要求且存储单价最低的云数据中心i存储用户u的数据副本;
s2.2判断与用户u有交互关系的各用户v访问存储在云数据中心i的数据副本时的访问延迟是否超出预定阈值,
若超出,则将该用户v放入访问超时集合ωu;依次从集合ωu中选择一个待处理用户v,从用户u的可用云数据中心里找出能够满足该待处理用户v的访问延迟要求且存储单价最低的云数据中心j,将用户u的数据副本放置在云数据中心j上;
若未超出,则不做处理;
进一步地,s3中迁移费用的计算方法具体包括:
s3.1计算云数据中心间的传输费用,包括读操作费用和写操作费用,用户u的读、写费用分别表示为:
其中nu表示与用户u有交互关系的用户v的集合,ptrans表示传输单价,|du|表示存储用户u的数据副本的云数据中心数目,
与用户u相关的传输费用表示为
πu=cu-read+cu-write
s3.2计算一次迁移导致的传输费用的变化,用π'u表示迁移后与用户u相关的传输费用,则迁移变化表示为:
s3.3计算将用户u的数据副本从云数据中心i迁移到j的迁移费用
若迁移的目标数据副本中心已存储用户u的副本,即j∈du,则此次迁移操作等价于删除操作,将u的数据副本从源数据副本中心i删除,费用为
进一步地,还包括计算用户u的数据副本的存储费用,具体计算公式如下:
其中du表示所有存储用户u的数据副本的云数据中心构成的集合,sizeu表示u的数据副本大小,pi表示云数据中心i的存储单价。
为达到上述发明目的,本发明跨地域云数据中心间社交用户数据分布式存储系统,包括:
社交网络模型图构建单元,用于构建网络社交模型图g=(v,e,r,w),其中,以社交网络中每个用户u作为社交图g中的一个顶点,用户v为与用户u有交互关系的用户,用户u与用户v间的交互关系用交互边euv表示;e为社交用户间交互关系集合,r为任意交互边上读操作频度的集合,w表示任意交互边上写操作频度的集合;用户u与用户v间交互的数据副本操作至少包括两种,即读操作ruv和写操作wuv,ruv∈r,wuv∈w;
数据副本分布放置单元,用于将各用户u的数据副本分布放置于该用户u的至少一个可用云数据中心,其中所述可用云数据中心满足用户u、与该用户有交互关系的用户v对访问延迟的要求,且存储单价最低;
数据副本迁移单元,用于分别找到迁移候选目标集合xu和迁移候选源集合yu,以得到多个候选迁移方案,计算所有候选迁移方案的迁移费用,选择其中费用最小的迁移方案执行用户u的数据副本的数据迁移;其中,找出满足与用户u有交互关系的用户v的访问延迟要求且存储单价最低的云数据中心集合lv,对所有云数据中心集合lv求交集得到迁移候选目标集合xu;将存储用户u的数据副本的云数据中心集合du分别与每一个集合lv求交集,求得结果的集合再合并求并集,得到迁移候选源集合yu。
进一步地,所述数据副本分布放置单元包括:
主云数据中心确定模块,用于确定用户u的可用云数据中心,选择所述的可用云数据中心中满足所述用户u访问延迟要求且存储单价最低的云数据中心i存储用户u的数据副本;
其他云数据中心确定模块,用于判断与用户u有交互关系的各用户v访问存储在云数据中心i的数据副本时的访问延迟是否超出预定阈值,
若超出,则将该用户v放入访问超时集合ωu;依次从集合ωu中选择一个待处理用户v,从用户u的可用云数据中心里找出能够满足该待处理用户v的访问延迟要求且存储单价最低的云数据中心j,将用户u的数据副本放置在云数据中心j上;
若未超出,则不做处理。
进一步地,数据副本迁移单元包括迁移候选目标集合、源集合确定模块以及迁移费用的计算模块,其中,
所述迁移候选目标集合、源集合确定模块,用于分别找到迁移候选目标集合xu和迁移候选源集合yu,以得到多个候选迁移方案,所述的迁移候选目标集合xu和迁移候选源集合yu的确定方法包括:找出满足与用户u有交互关系的用户v的访问延迟要求且存储单价最低的云数据中心集合lv,对所有云数据中心集合lv求交集得到迁移候选目标集合xu;将存储用户u的数据副本的云数据中心集合du分别与每一个集合lv求交集,求得结果的集合再合并求并集,得到迁移候选源集合yu;
所述迁移费用的计算模块,用于计算所述迁移候选目标集合、源集合确定模块找出的所有候选迁移方案的迁移费用,选择其中费用最小的迁移方案执行用户u的数据副本的数据迁移;所述迁移费用的计算模块包括:
与用户u相关的传输费用计算子模块,用于计算云数据中心间的传输费用,包括读操作费用和写操作费用,用户u的读、写费用分别表示为:
其中nu表示与用户u有交互关系的用户v的集合,ptrans表示传输单价,|du|表示存储用户u的数据副本的云数据中心数目,
与用户u相关的传输费用表示为
πu=cu-read+cu-write
一次迁移的传输费用的变化计算子单元,用于计算一次迁移导致的传输费用的变化,用π'u表示迁移后与用户u相关的传输费用,则迁移变化表示为:
最终计算结果输出子单元,用于计算将用户u的数据副本从云数据中心i迁移到j的迁移费用
若迁移的目标数据副本中心已存储用户u的副本,即j∈du,则此次迁移操作等价于删除操作,将u的数据副本从源数据副本中心i删除,费用为
进一步地,还包括存储费用计算单元,用于计算用户u的数据副本的存储费用,具体计算公式如下:
其中du表示所有存储用户u的数据副本的云数据中心构成的集合,sizeu表示u的数据副本大小,pi表示云数据中心i的存储单价。
借由上述方案,本发明跨地域云数据中心间社交用户数据分布式存储方法及系统至少具有以下优点:
本发明本发明的轻量级用户数据副本分布式存储方法,考虑云数据中心存储价格、用户数据副本大小和用户具体交互行为,综合利用数据副本复制和数据副本放置两种方法对社交用户数据副本进行分布式存储优化,可以极大地降低网络开销,减少存储费用和网络传输费用,同时确保用户对数据副本的访问延迟在可接受的范围内。本发明的方法包括三个步骤:构建基于交互的社交网络模型、用户数据副本分布式放置和用户数据迁移。本发明能够在保证用户访问延迟的前提下根据社交网络用户交互行为优化用户数据副本在各大云数据中心的存储,从整体上降低存储开销和数据副本中心间网络通信量,减少费用支出。
上述说明仅是本发明技术方案的概述,为了能够更清楚了解本发明的技术手段,并可依照说明书的内容予以实施,以下以本发明的较佳实施例并配合附图详细说明如后。
附图说明
图1为cdn支持的数据副本跨地域访问示例图;
图2为多个云数据中心支持的跨地域访问示例图;
图3为本发明跨地域云数据中心间社交用户数据分布式存储方法的流程框图;
图4为本发明仿真实验下不同算法的成本费用比较图;
图5为本发明仿真实现下不同算法所带来的访问延迟累计分布比较图。
具体实施方式
下面结合附图和实施例,对本发明的具体实施方式作进一步详细描述。以下实施例用于说明本发明,但不用来限制本发明的范围。
实施例1
本实施例跨地域云数据中心间社交用户数据分布式存储方法,包括:
s1构建网络社交模型图g=(v,e,r,w),其中,以社交网络中每个用户作为社交图g中的一个顶点;用户间的交互关系用交互边euv表示,在考虑任意用户u的数据放置前,用u表示用户,v表示与用户有交互关系的用户,v通常不止一个;e为社交用户间交互关系集合,r为任意交互边上读操作频度的集合,w表示任意交互边上写操作频度的集合;用户与用户间交互的数据操作至少包括两种,即读操作ruv和写操作wuv,ruv∈r,wuv∈w;
s2将各用户u的数据副本分布放置于该用户u的至少一个可用云数据中心,其中所述可用云数据中心满足用户u、与该用户有交互关系的用户v对访问延迟的要求,且存储单价最低,也即放置用户u的数据副本的云数据中心无需同时满足用户u、与该用户有交互关系的用户v的延迟满足,仅需满足用户u或用户v之一即可于放置用户u的数据副本。
s3分别找到迁移候选目标集合xu和迁移候选源集合yu,以得到多个候选迁移方案,计算所有候选迁移方案的迁移费用,选择其中费用最小的迁移方案执行用户u的数据副本的数据迁移;其中,找出满足与用户u有交互关系的用户v的访问延迟要求且存储单价最低的云数据中心集合lv,对所有云数据中心集合lv求交集得到迁移候选目标集合xu;将存储用户u的数据副本的云数据中心集合du分别与每一个集合lv求交集,求得结果的集合再合并求并集,得到迁移候选源集合yu。
本实施例中,所述的s2具体包括:
s2.1确定用户u的可用云数据中心,选择所述的可用云数据中心中满足所述用户u访问延迟要求且存储单价最低的云数据中心i存储用户u的数据副本;
s2.2判断与用户u有交互关系的各用户v访问存储在云数据中心i的数据副本时的访问延迟是否超出预定阈值,
若超出,则将该用户v放入访问超时集合ωu;依次从集合ωu中选择一个待处理用户v,从用户u的可用云数据中心里找出能够满足该待处理用户v的访问延迟要求且存储单价最低的云数据中心j,将用户u的数据副本放置在云数据中心j上;
若未超出,则不做处理。
本实施例针对现有技术存在的跨地域访问延迟大、网络通信量大、存储费用高等问题,本发明提供一种轻量级的用户数据副本分布式存储方法,联合利用数据副本复制与放置进行同步优化,解决大规模用户数据副本在跨地域云数据中心间的分布式存储问题,以降低存储开销和各数据副本中心间通信量,从而减少费用,同时保证数据副本访问延迟。
实施例2
本实施例跨地域云数据中心间社交用户数据分布式存储方法,在实施例1的基础上,迁移费用的计算方法具体包括:
s3.1计算云数据中心间的传输费用,包括读操作费用和写操作费用,用户u的读、写费用分别表示为:
其中nu表示与用户u有交互关系的用户v的集合,ptrans表示传输单价,|du|表示存储用户u的数据副本的云数据中心数目,
与用户u相关的传输费用表示为
πu=cu-read+cu-write
s3.2计算一次迁移导致的传输费用的变化,用π'u表示迁移后与用户u相关的传输费用,则迁移变化表示为:
s3.3计算将用户u的数据副本从云数据中心i迁移到j的迁移费用
若迁移的目标数据副本中心已存储用户u的副本,即j∈du,则此次迁移操作等价于删除操作,将u的数据副本从源数据副本中心i删除,费用为
实施例3
本实施例跨地域云数据中心间社交用户数据分布式存储方法,在上述各实施例的基础上,还包括计算用户u的数据副本的存储费用,具体计算公式如下:
其中du表示所有存储用户u的数据副本的云数据中心构成的集合,sizeu表示u的数据副本大小,pi表示云数据中心i的存储单价。
实施例4
本实施例跨地域云数据中心间社交用户数据分布式存储系统,能够用于实施上述实施例1至3中任一方法,包括:
社交网络模型图构建单元,用于构建网络社交模型图g=(v,e,r,w),其中,以社交网络中每个用户作为社交图g中的一个顶点;用户间的交互关系用交互边euv表示,在考虑任意用户u的数据放置前,用u表示用户,v表示与用户有交互关系的用户,v通常不止一个;e为社交用户间交互关系集合,r为任意交互边上读操作频度的集合,w表示任意交互边上写操作频度的集合;用户与用户间交互的数据操作至少包括两种,即读操作ruv和写操作wuv,ruv∈r,wuv∈w;
数据副本分布放置单元,用于将各用户u的数据副本分布放置于该用户u的至少一个可用云数据中心,其中所述可用云数据中心满足用户u、与该用户有交互关系的用户v对访问延迟的要求,且存储单价最低;
数据副本迁移单元,用于分别找到迁移候选目标集合xu和迁移候选源集合yu,以得到多个候选迁移方案,计算所有候选迁移方案的迁移费用,选择其中费用最小的迁移方案执行用户u的数据副本的数据迁移;其中,找出满足与用户u有交互关系的用户v的访问延迟要求且存储单价最低的云数据中心集合lv,对所有云数据中心集合lv求交集得到迁移候选目标集合xu;将存储用户u的数据副本的云数据中心集合du分别与每一个集合lv求交集,求得结果的集合再合并求并集,得到迁移候选源集合yu。
本实施例中,所述数据副本分布放置单元包括:
主云数据中心确定模块,用于确定用户u的可用云数据中心,选择所述的可用云数据中心中满足所述用户u访问延迟要求且存储单价最低的云数据中心i存储用户u的数据副本;
其他云数据中心确定模块,用于判断与用户u有交互关系的各用户v访问存储在云数据中心i的数据副本时的访问延迟是否超出预定阈值,
若超出,则将该用户v放入访问超时集合ωu;依次从集合ωu中选择一个待处理用户v,从用户u的可用云数据中心里找出能够满足该待处理用户v的访问延迟要求且存储单价最低的云数据中心j,将用户u的数据副本放置在云数据中心j上;
若未超出,则不做处理。
本实施例中,数据副本迁移单元包括迁移候选目标集合、源集合确定模块以及迁移费用的计算模块,其中,
所述迁移候选目标集合、源集合确定模块,用于分别找到迁移候选目标集合xu和迁移候选源集合yu,以得到多个候选迁移方案,所述的迁移候选目标集合xu和迁移候选源集合yu的确定方法包括:找出满足与用户u有交互关系的用户v的访问延迟要求且存储单价最低的云数据中心集合lv,对所有云数据中心集合lv求交集得到迁移候选目标集合xu;将存储用户u的数据副本的云数据中心集合du分别与每一个集合lv求交集,求得结果的集合再合并求并集,得到迁移候选源集合yu;
所述迁移费用的计算模块,用于计算所述迁移候选目标集合、源集合确定模块找出的所有候选迁移方案的迁移费用,选择其中费用最小的迁移方案执行用户u的数据副本的数据迁移;所述迁移费用的计算模块包括:
与用户u相关的传输费用计算子模块,用于计算云数据中心间的传输费用,包括读操作费用和写操作费用,用户u的读、写费用分别表示为:
其中nu表示与用户u有交互关系的用户v的集合,ptrans表示传输单价,|du|表示存储用户u的数据副本的云数据中心数目,
与用户u相关的传输费用表示为
πu=cu-read+cu-write
一次迁移的传输费用的变化计算子单元,用于计算一次迁移导致的传输费用的变化,用π'u表示迁移后与用户u相关的传输费用,则迁移变化表示为:
最终计算结果输出子单元,用于计算将用户u的数据副本从云数据中心i迁移到j的迁移费用
若迁移的目标数据副本中心已存储用户u的副本,即j∈du,则此次迁移操作等价于删除操作,将u的数据副本从源数据副本中心i删除,费用为
实施例5
本实施例跨地域云数据中心间社交用户数据分布式存储系统,本实施例可用于实现实施例3所述的方法,在实施例4的基础上,还包括存储费用计算单元,用于计算用户u的数据副本的存储费用,具体计算公式如下:
其中du表示所有存储用户u的数据副本的云数据中心构成的集合,sizeu表示u的数据副本大小,pi表示云数据中心i的存储单价。
为了验证本方法的有效性,通过仿真实验提供一具体实施例,另外其他实施例不在此列具,但是本技术领域人员可根据以下具体实施例进行简单的数据替能够得到其他具体实施例,实验做如下设置。
社交网络数据副本集由网络爬虫程序对facebook抓取获得,数据副本集包含273.2万用户和1千万好友关系边,以及为期3个月时间内用户间交互频度记录。除此以外,本发明还从数据副本集中提取用户的位置信息,将位置对应到地图上,并画出覆盖所有位置的区域,对于部分未明确标识位置信息的用户,从其发布的博文中找出带位置信息的内容,以此作为其所在位置;若无带位置信息的内容发布,则从与其频繁交互的用户中提取带位置的信息,在地图上构成一块区域,在该区域内随机选择一个位置作为用户所在位置;若还是无法获取位置信息,则从目前所有用户位置所覆盖的区域内随机选择一处作为用户所在位置。仿真实验中,本发明从datacentermap中选择14个云数据中心,以用户到云数据中心的距离作为衡量访问延迟的指标,默认云数据中心的覆盖距离为1000km,以上14个云数据中心能够覆盖所有用户的访问,若用户介于多个数据副本中心覆盖范围内,则可选择任意一个或多个数据副本中心放置该用户数据副本,具体放置方法按照本发明前述步骤执行。metis作为经典的图分割算法,可用于实现将社交网络中的用户划分到不同的云数据中心存储,spar是经典的社交用户数据副本复制算法,用于将社交用户数据副本在多个云数据中心创建副本,在实验中一并实现上述两种算法并与本发明所提方法进行比较,实验结果如图4和图5所示。图4对比三种方法所耗费的成本,包括存储费用和迁移费用,为了便于观察,此处用完全复制的成本费用对所有方法的费用进行规格化。从图4结果不难看出,本发明所提的优化存储方法所耗费的成本费用最低,分别比metis划分方法和spar复制方法低83.7%和76.7%。图5对比三种方法所带来的访问延迟的分布情况,由于metis方法只将用户数据副本分配到一个云数据中心存储而创建多个副本,因此无法保证所有用户的访问延迟均达到要求,为了便于比较,此处本发明仅统计延迟即距离小于1000km的访问。图5中的结果显示,本发明所提优化算法所带来的访问延迟分布介于metis和spar之间,metis划分方法未针对延迟要求创建用户数据副本,故多数访问的延迟较高,而spar复制方法在划分基础上通过在多处创建多个副本来保证所有访问延迟,使得低延迟访问的比例高于本发明所提算法,平均延迟较本发明所提算法低13%。尽管如此,本发明所提算法的访问延迟仍远低于访问延迟要求,在满足延迟要求下本发明所提算法能够最大限度地降低成本费用,达到优化目标。
以上所述仅是本发明的优选实施方式,并不用于限制本发明,应当指出,对于本技术领域的普通技术人员来说,在不脱离本发明技术原理的前提下,还可以做出若干改进和变型,这些改进和变型也应视为本发明的保护范围。
- 还没有人留言评论。精彩留言会获得点赞!