基于行人重识别的跨摄像头视频浓缩方法与流程
本发明属于视频处理技术领域,具体涉及一种基于行人重识别的跨摄像头视频浓缩方法。
背景技术
自上世纪进入数字化时代以来,数以万计的监控摄像头被部署在例如火车站、飞机场等交通枢纽及城市各交通路口处并处于24小时不断工作状态,监控视频的数量呈爆发性增长的趋势。此外监控视频在智能安保、交通管理及刑侦调查等实际应用中扮演着越来越重要的角色,因此简洁又包含丰富信息的监控视频无论对存储或查看监控视频都具有不可小觑的价值。
但是大量冗长的监控视频对视频的存储具有很高的要求,现实中往往许多视频会由于存储空间的限制很快被删除,导致一些包含重要信息的视频丢失。此外浏览视频中许多无用的信息会浪费大量人力成本,给视频监控人员带来了很大的不便。获得更紧凑、信息密度更大的视频不仅可以有效提高监控人员的工作效率节省大量人力成本还极大程度上减少内存的占据为更多视频提供了充足的存储空间提高了信息密集度,在一定程度上也更适应于现代社会信息量的爆炸式发展趋势。因此旨在对视频时间域上的压缩以获得尽可能更高还原度的视频描述的视频浓缩技术成为目前学术界及工业界的关注重点。
视频浓缩是指通过对视频进行时间轴的压缩,在较短的时间内尽可能对原视频中的关键细节进行描述,去除视频时间域上的冗余信息。视频浓缩技术令监控视频具有更密集的信息量,使用户可以快速浏览海量监控视频。此外通过加入视频检索技术还可以提供浓缩后视频中物体在原视频中的具体定位,使浓缩视频具有对原监控视频进行索引的功能。现有的解决视频浓缩问题的方法可以分为以下几类:快进(以固定比率直接提取视频中的某几帧来达到浓缩的目的)、关键帧提取,这两种方法都无法较好的保存视频中物体的动态效果。此外还有将相关视频片断进行排列来缩短视视频长度的蒙太奇方法。而本发明提出框架可以根据不同需求选取不同特性的视频浓缩方法,来最大程度上满足不同的用户需求。
但通常在实际应用中,不同的场合对不同对象具有不同兴趣,传统的视频浓缩方法对视频中所有运动对象(如:行人、车辆等)赋予了相同的重要性,使浓缩后的视频没有较强的针对性。此外,传统的视频浓缩技术通常仅用于一段视频中,而往往在现实生活中(如:跨摄像头行人检测、轨迹跟踪等),还需要根据不同的检测目标找到该目标在不同视频间的联系。比如在利用多段监控视频搜索犯罪嫌疑人的活动轨迹时,视频监控人员通常不仅仅需要监控单摄像头拍摄的视频并查找嫌疑人物,还需要在不同视频间检索该目标在跨摄像头的监控范围内的活动信息以获得该目标连贯的运动轨迹,起到跟踪嫌疑人辅助破案的作用。而这一过程仍需耗费大量人力物力而仅对视频进行压缩处理是远远不够的,因此对包含相同关键对象的不同视频进行视频浓缩具有很高的研究价值。
行人重识别技术(reid)旨在弥补目前固定的摄像头的视觉局限,智能实现对目标行人的跨摄像头匹配及检索功能,并可通过与行人检测、跟踪等技术相结合广泛应用于智能视频监控、智能安保等领域。利用行人重识别技术的思想可以跨视频匹配目标对象,实现在多段视频中有效快速地定位目标并查找该目标在不同场景下的运动信息,提高了实际工作效率。
现有的行人重识别领域的研究工作主要分为以下两类:基于特征表示方法[2-3]、基于距离度量方法[4-5]。基于特征表示的方法通过提取具有鲁棒性的鉴别特征对行人进行表示,并在不同视频中根据特征来匹配目标对象,这种方法的运算复杂度较简单,但效果并不理想。基于距离度量学习方法通过学习一个有判别力的距离度量函数来计算视频间对应对象的图像距离,使同一对象的图像间距离小于不同对象图像间距离,这类方法虽然提升了识别精确度,但往往需要一个复杂的学习过程。近年来,随着深度学习的发展及神经网络在计算机视觉领域的成功应用,基于深度学习的行人重识别算法[6-7]也逐步成为研究热点并实现了更好的效果。
技术实现要素:
为了解决上述现有技术的问题,本发明的目的在于提供一种基于行人重识别的跨摄像头视频浓缩方法。本发明提出将现有的行人重识别技术和视频浓缩技术相结合,在对多段跨摄像头视频进行时间域压缩的基础上利用行人重识别的思想找到目标对象在不同摄像头拍摄的多段视频中的匹配位置,实现连贯地追踪目标对象的活动轨迹并获得多段包含该目标对象的跨摄像头的浓缩视频,不仅节省了大量人力劳动还一定程度上提高了目标对象的识别准确度。本发明的技术方案具体介绍如下。
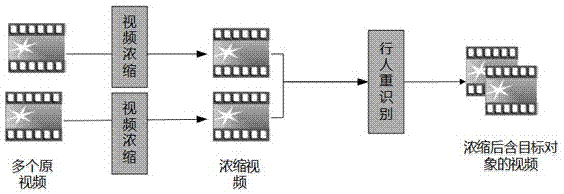
一种基于行人重识别的跨摄像头视频浓缩方法,具体步骤如下:
(1)视频浓缩阶段
以获得的多段不同摄像头所拍摄的视频作为输入,通过对视频中的当前场景建立背景模型、对运动目标进行检测、跟踪并提取其运动轨迹和重新组合多个目标的运动轨迹,最终输出多段浓缩后的视频;
(2)行人重识别阶段
基于视频浓缩阶段获得的多段浓缩后的视频,针对具体的目标对象,首先基于深度学习的思想,使用神经网络去学习目标对象的特征及度量方法,在浓缩后的视频中查找到该目标对象在不同视频中出现的具体位置,提取出含有目标对象的浓缩视频片段,最后根据匹配得到的该目标在多段视频中出现的位置,提取出多段包含该对象的浓缩视频片段以获得该目标对象在多视频中连贯运动轨迹的描述。
本发明中,步骤(2)中,行人重识别阶段,以基于视频浓缩阶段获得的任意两段跨摄像头浓缩视频作为输入,经过多层卷积神经网络的处理输出匹配到的任意两段视频中对应的目标对象的出现位置,实现了端到端的行人重识别过程。
本发明中,步骤(2)中,行人重识别阶段使用神经网络通过训练主动学习到了以下过程:首先自动检测任意两段跨摄像头浓缩视频中的目标行人,得到目标行人的边界框;随后提取出目标框内行人的特征,再计算两段视频间对应框架内特征之间的距离;神经网络结构自动学习出最佳的度量特征间距离的方法,并为不同特征赋予不同重要性权值,使得同类样本之间的距离较小,而不同类样本之间的距离较大(不同类样本之间的距离大于同类样本之间的距离);最后根据学习到的特征距离就可以为某一目标行人找到与其最相近的对应目标。
和现有技术相比,本发明的有益效果在于:
1、本发明提出了一种简单易行且灵活搭建的方法框架,可以有效地将现有的视频浓缩技术与行人重识别技术相结合。不仅最大程度上减少了视频时间上的冗余信息,获得信息量更丰富紧凑的视频,同时将出现在不同视频的相同目标对象的运动信息相联系,获得多段包含该对象运动信息的浓缩视频来实现对具体对象跨摄像头间运动轨迹的提取。
2、本发明主要针对监控视频的浓缩及目标运动轨迹提取的应用领域,直接将跨摄像头的不同视频作为输入,依次执行视频浓缩和行人重识别操作最终得到针对目标对象在不同视频中连贯的运动描述的浓缩视频,通过结合行人重识别的思想实现了在不同视频之间检索同一目标对象在跨摄像头视频内的活动描述,代替了人为对跨摄像头视频的目标检索,极大程度上解放了人力成本提高了目标识别精确度。
附图说明
图1为本发明的流程图。
图2为本发明示例的视频浓缩过程。
图3为本发明示例的行人重识别过程。
图4为利用本发明对跨摄像头的多段视频进行基于行人重定向技术的视频浓缩处理后的效果图。
具体实施方式
下面结合附图和实施例对本发明的技术方案进行详细介绍。本发明方法的具体流程如图1所示。
(1)视频浓缩阶段
这一阶段以获得的多段不同摄像头所拍摄的视频作为输入,实现对视频内容的一个简单概括,最终输出多段浓缩后的视频。本阶段可以根据不同应用场景的需求采用现有的各种视频浓缩技术来分别对跨摄像头的多段视频进行浓缩处理,具有较高的灵活性及实用性。目前现有的视频浓缩方法通常通过对视频中的运动目标进行算法分析,提取运动目标,然后对各个目标的运动轨迹进行分析,将不同的目标拼接到一个共同的背景场景中,并将它们以某种方式进行组合,生成新的浓缩后视频。
(2)行人重识别阶段
这一阶段是基于前一阶段获得的浓缩后的多段视频,针对具体的目标对象,首先在浓缩后的视频中根据相应匹配度量方法查找到该目标对象在不同视频中出现的具体位置,并提取出含有目标对象的浓缩视频片段。本阶段使用的基于视频的行人重识别技术是基于深度学习思想,利用神经网络的简单结构及端到端的方便特性来快速实现跨摄像头的目标匹配过程,使用神经网络去学习目标对象的特征及度量方法,起到准确快速的目标检索。最后根据匹配得到的该目标在多段视频中出现的位置,提取出多段包含该对象的浓缩视频片段以获得该目标对象在多视频中连贯运动轨迹的描述。
在步骤(1)中主要包括以下内容:对视频中的当前场景建立背景模型、对运动目标进行检测、跟踪并提取其运动轨迹、重新组合多个目标的运动轨迹、融合重组后的轨迹及背景模型。
建立当前场景背景模型,通过将原始视频分为静态和动态视频段,同时为每个视频段生成一个统一的背景模型。运动目标检测,基于建模好的背景,使用目标检测算法检测并跟踪目标物体,提取其运动轨迹,通过运动轨迹表示该目标对象。然后重新组合多个目标的运动轨迹,去除视频的空间冗余,在重组的过程中同时还要考虑避免目标组合过程中的交叉碰撞等问题来保护原始目标的基本运动,防止出现运动轨迹丢失及目标物体变形等奇怪的视觉效果。生成浓缩视频,通过对重组后的多目标运动轨迹及背景模型进行融合,合成浓缩后的视频,这一步需要注意多目标轨迹与背景间的无痕融合。
为具体展示本发明提出框架的实现方法及效果,本发明的步骤(1)采取发明人之前提出的基于线裁剪的视频浓缩方法为示例,对多段视频分别采取视频浓缩。具体浓缩流程参见文献[1]。
在步骤(2)中,以一种基于深度学习的行人重识别的方法为例:如图3所示,本阶段使用现有的神经网络结构,将前一步得到的两段跨摄像头浓缩视频作为输入,经过多层卷积神经网络的处理输出匹配到的两段视频中对应的目标对象的出现位置,实现了端到端的行人重识别过程。
本阶段使用的网络结构首先使用多层卷积层自动检测两段视频中的目标行人,得到目标行人的边界框。随后提取出目标框内行人的特征,再计算两段视频间对应框架内特征之间的距离。神经网络结构可以自动学习出最佳的度量特征间距离的方法(如曼哈顿距离、欧氏距离和巴氏距离等),并为不同特征赋予不同重要性权值,使得同类样本之间的距离较小,而不同类样本之间的距离较大。最后根据学习到的特征距离就可以为某一目标行人找到与其最相近的对应目标。由于神经网络的特性,其每一具体的中间卷积层可以表示上述整个过程,因此本阶段没有显示执行以上操作,而是通过网络结构主动学习具体流程,得到的模型可以高效地实现行人重识别过程。
图2为本发明示例选择的视频浓缩过程,具体步骤为:
如图2所示,以一种基于线裁剪的方法为例,其包括以下步骤:
(1)背景建模,根据视频中的静态与动态内容间的不同特性,对视频进行场景分割,划分出当前场景的统一的背景模型。
(2)提取目标轨迹,基于建模好的背景,检测运动目标并跟踪目标物体运动轨迹,通过运动轨迹表示该目标对象。
(3)合并目标轨迹,将提取到的多个运动目标的活动轨迹进行重新组合,去除视频的空间冗余,在重组过程的同时还要考虑避免目标组合过程中的交叉碰撞等问题来保护原始目标的基本运动信息,防止出现运动轨迹丢失及目标物体变形等奇怪的视觉效果。
(4)生成浓缩视频,通过拼接目标轨迹集合与背景图像合成浓缩视频,这一步需要注意多目标轨迹与背景间的无痕融合。
如图3所示,以一种基于深度学习的行人重识别的方法为例,具体步骤如下:
(1)首先使用现有的网络结构[如2,3],将前一步得到的两段跨摄像头浓缩视频作为输入,使用多层卷积层自动检测两段视频中的目标行人,得到目标行人的边界框。
(2)然后使用卷积层提取出目标框内行人的特征,并计算两段视频间对应框架内特征之间的距离。神经网络结构可以自动学习出最佳的度量特征间距离的方法(如曼哈顿距离、欧氏距离和巴氏距离等),并为不同特征赋予不同重要性权值,使得同类样本之间的距离较小,而不同类样本之间的距离较大。
(3)最后根据学习到的特征距离就可以为某一目标行人找到与其最相近的对应目标,输出匹配到的两段视频中对应的目标对象的出现位置。
图4展示了本方法的效果图:
图(a)、(b)为分别对不同摄像头所拍摄的两段视频仅使用视频浓缩处理得到的浓缩视频帧。图(c)、(d)为应用基于行人重识别的视频浓缩技术提取到的对应的浓缩视频帧,其中两图中相同颜色的边界框分别对应于两图中的同一个目标物体。可以看出,本方法很好地实现了视频时间域上的压缩完整保存了视频中的物体运动信息,同时有效地检测出两段视频之间目标物体的运动对应关系并准确提取出目标物体跨视频的运动轨迹。
参考文献
[1]颜波,薛向阳,李可,王伟祎.一种基于线裁剪的视频浓缩方法:,cn103763562a[p].2014.
[2]farenzenam,bazzanil,perinaa,etal.personre-identificationbysymmetry-drivenaccumulationoflocalfeatures[c]//computervisionandpatternrecognition.ieee,2010:2360-2367.
[3]dongsc,cristanim,stoppam,etal.custompictorialstructuresforre-identification[j].2011:68.1-68.11.
[4]xingep,ngay,jordanmi,etal.distancemetriclearning,withapplicationtoclusteringwithside-information[c]//internationalconferenceonneuralinformationprocessingsystems.mitpress,2002:521-528.
[5]zhengws,gongs,xiangt.personre-identificationbyprobabilisticrelativedistancecomparison[c]//computervisionandpatternrecognition.ieee,2011:649-656.
[6]ruizhao,wanlioyang,xiaogangwang.personre-identificationbysaliencylearning[j].ieeetransactionsonpatternanalysisandmachineintelligence,2017.39(2):356–370.
[7]niallmclaughlin,jesusmartinezdelrincon,paulmiller.recurrentconvolutionalnetworkforvideobasedpersonre-identification[c]//proceedingsoftheieeeconferenceoncomputervisionandpatternrecognition.2016:1325–1334。
- 还没有人留言评论。精彩留言会获得点赞!