一种内容流行度随时间变化下的基站缓存方法与流程
本发明涉及移动通信系统技术领域,尤其是一种内容流行度随时间变化下的基站缓存方法。
背景技术
为了应对海量数据增长带来的对系统容量的挑战,一种有效的方案是在宏基站周围部署helper,其中helper拥有缓存容量且能够缓存内容。当用户请求的内容存储在helper的缓存中,内容直接从helper传给用户,不会占用回程链路资源,同时减少传输时延,提高用户体验。如果用户请求的内容不在helper中,则将请求发送给宏基站并从宏基站下载所请求的内容。基站主动存储是在请求未到达之前将内容存储在helper中,可以减小回传链路的流量,进而缓解蜂窝系统中的流量负载,改善系统的性能。但目前多数缓存研究都是在内容流行度已知且不随时间变化的情况下研究缓存性能,在内容流行度随时间变化情况下,性能尚待改进。
技术实现要素:
发明目的:本发明目的在于提供一种基站缓存方法,能够在内容流行度随时间变化情况下优化缓存内容,提高缓存命中率,缓解回程链路负载,提高用户满意度。
技术方案:为实现上述发明目的,本发明采用如下技术方案:
一种内容流行度随时间变化下的基站缓存方法,包括如下步骤:
(1)在每个时刻t,对在时刻
(2)每隔设定的时间段td,基于缓存在各个helper中的新内容的请求历史,利用隐语义模型估计每个helper下覆盖用户对新内容的流行度,并按照内容流行度从高到低缓内容。
作为优选,步骤(1)中根据公式
作为优选,步骤(2)中,利用隐语义模型估计新内容的流行度,包括如下步骤:
(2.1)将新产生的内容依次存储在helper中,观测helper覆盖用户对新内容的请求频率,构造不完全流行度矩阵;
(2.2)初始化参数向量pn和qf,其中pn表征用户n对潜在特征的感兴趣程度,qf表征内容f在特征的权重;
(2.3)采用梯度下降法求解获得参数pn和qf直到如下损失函数达到最小:
其中,
(2.4)根据计算出的pn和qf,利用式
作为优选,步骤(2.1)中对于第f个新内容,则将内容f缓存在第n=f%n个helper中,其中n是所有helper的个数。
作为优选,如果helper中没有足够的容量对时间段td之间产生的新内容进行缓存,则对新内容采用先进先出的规则进行替换。
作为优选,步骤(2.1)中新内容的不完全流行度矩阵根据
有益效果:本发明结合机器学习中的多臂赌博机和隐语义模型提出一种在线实时的缓存策略。一方面多臂赌博机模型能够边学习内容的流行度,边缓存流行度高的内容。另一方面,隐语义模型采取基于用户行为统计的自动聚类,能反应用户对于内容的分类意见,能有效估计新内容的流行度,同时减少多臂赌博机对新内容的探索次数。本发明将多臂赌博机和隐语义模型进行结合,在内容流行度随时间变化情况下,能有效估计内容流行度,从而提高缓存命中率,改善用户满意度和网络回程负载;与现有技术相比,本发明将机器学习引入到对缓存内容的决策中,在内容流行度随时间变化的情况下,大大提高了缓存命中率,有效的缓解了回程链路负载,提高用户满意度。
附图说明
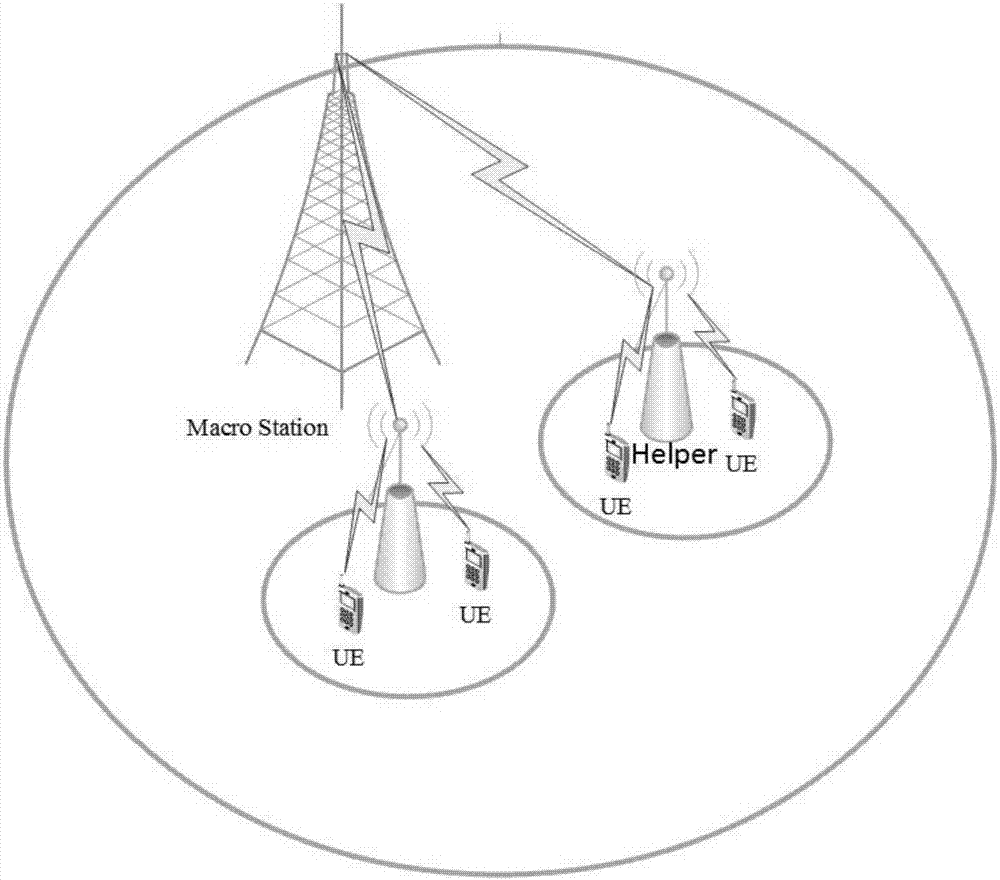
图1为本发明实施例的应用场景图。
图2为本发明实施例的方法流程示意图。
具体实施方式
下面结合附图和具体实施例对发明的技术方案做进一步介绍。
考虑一个部署n个helpers的宏蜂窝网络,helper用集合
在每个时间段,helper将缓存的内容广播给它所服务的用户,注意内容控制器仅能观测到缓存在helper中的内容请求信息。如果有新内容产生,我们应该将新内容缓存在helper中来通知用户。
我们定义
内容控制器的目标是在事先不知道内容流行度的情况下,仅仅通过观察缓存在helper中的内容请求频率,采用合适的缓存策略,估计内容流行度,在每个时间段优化缓存放置内容,使用户直接从helper获得的数据流量最大化。
当用户请求的内容f从helper中获得,我们认为网络中有一个sf的奖赏,这里sf是内容f的大小。这个奖赏可以被看作用户的qoe增益,或者是宏蜂窝网络中的带宽缓解。所以对于每一个helper,其平均瞬时奖赏可以描述为:
其中ft表示该时刻存在的所有内容的总数,
我们定义内容流行度矩阵
我们采用如下的方式进行缓存,主要包括:
首先,考虑利用多臂赌博机模型估计内容流行度的问题:内容控制器仅仅能观测到缓存在helper中的内容请求频率,内容在helper中缓存的次数越多,对于内容流行度估计的就越准确,同时,内容控制器也要缓存当前它认为最流行的内容以确保缓存命中率。这是多臂赌博机中的探索和利用权衡问题。将内容作为多臂赌博机中的“臂”,采用组合置信区间上界算法(cucb),对缓存在helper中的内容估计内容流行度。并缓存内容流行度高的内容。
然后,对于一段时间产生的新内容,将新内容依次存储在helper中,并观察请求频率,利用隐语义模型(lfm)估计每个helper下覆盖用户对新内容的流行度。
最后,综合上述两方面,对于每个helper,根据估计的内容流行度,按照内容流行度从高到低将内容依次存储在helper中。
如图2所示,本发明实施例公开的一种内容流行度随时间变化下的基站缓存方法,包括如下步骤:
(1)利用多臂赌博机模型根据瞬时请求频率去估计内容流行度,并根据估计的内容流行度缓存内容。
在每个时刻t,我们对在时刻
(1.1)初始化阶段,将所有内容都至少在helper中缓存一次,观测瞬时请求次数
(1.2)观测缓存在helper中内容的瞬时请求次数
(1.3)更新
(1.4)计算
(1.5)t←t+1,重复(1.2)~(1.4)根据瞬时请求估计内容流行度,实时更新缓存内容。
(2)利用隐语义模型估计新内容的流行度,并根据估计的内容流行度缓存内容。
在每个t%td==0时刻,基于缓存在各个helper中的新内容的请求历史,构造不完全流行度矩阵θ(t),利用隐语义模型计算参数向量pn和qf,根据公式
(2.1)将新产生的内容依次存储在helper中,观测helper覆盖用户对新内容的请求频率,根据
(2.2)为了获得不同helper对新内容的流行度,即补全流行度矩阵θ(t),我们利用隐语义模型估计某个helper对新内容的流行度,首先用较小的值初始化参数向量pn和qf,其中pn表征用户n对潜在特征k的感兴趣程度,qf表征内容f在特征k的权重。
(2.3)隐语义模型通过最小化如下损失函数来获得参数pn和qf:
这里,
本步骤可采用梯度下降法求解获得参数pn和qf,计算参数最快下降方向也就是梯度
用如下公式更新参数pn和qf:
其中α是学习速率。
(2.4)根据计算出的pn和qf,利用式
尽管本发明就优选实施方式进行了示意和描述,但本领域的技术人员应当理解,只要不超出本发明的权利要求所限定的范围,可以对本发明进行各种变化和修改。
- 还没有人留言评论。精彩留言会获得点赞!