一种基于节点数据值的Ad-hoc网络分簇算法的制作方法
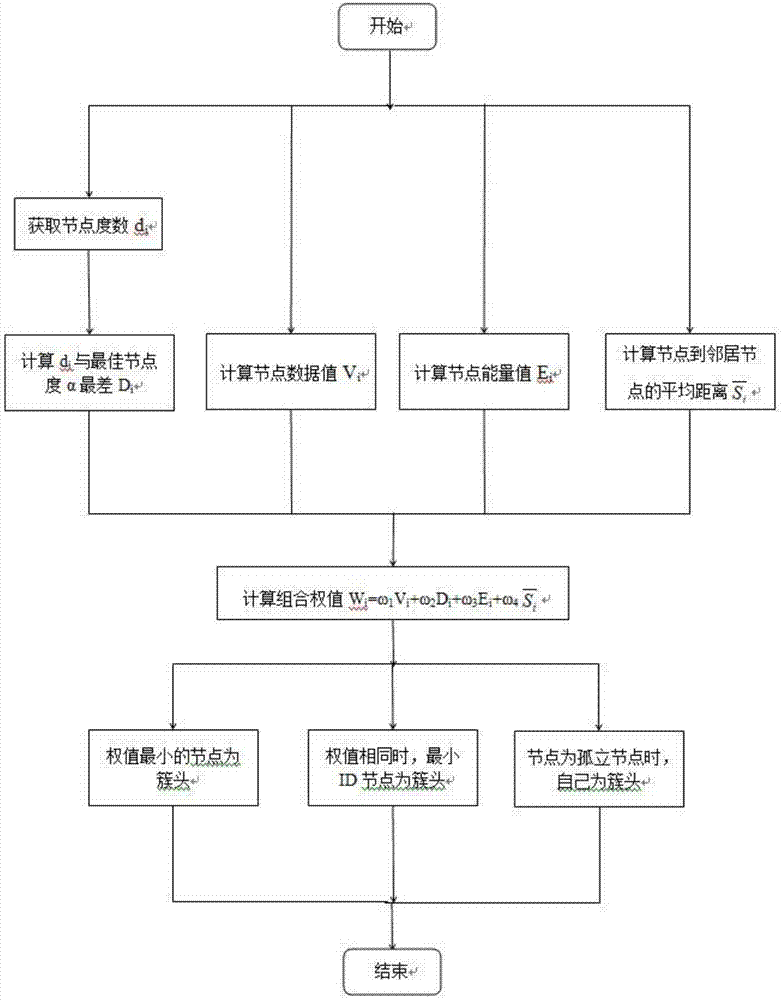
本发明涉及一种基于节点数据值的ad-hoc网络分簇算法,属于ad-hoc无线网络
技术领域:
。
背景技术:
ad-hoc网络是一种多跳的、无中心的、自组织的无线网络,整个网络没有固定的基础设施,每个节点都是移动的,正是由于其特点为其扩展性和管理带来一系列不便。为了提高ad-hoc网络的可扩展性、实现网络均衡负载,我们对网络多采用分簇算法,利用簇头和簇成员的协同工作,提高网络的整体性能。目前较普遍的分簇算法有最小id算法、最高节点度算法和wca算法。最小id算法(lid),此算法容易实现,簇头更换较慢,簇维护开销较小,但id较小的节点因长期担任簇头而消耗很高的能量,缩短网络的生命周期。最高节点度算法(hd),此算法的簇的数目较少,降低了分组时延,但较少的簇数目会导致信道的利用率降低。wca算法,该算法考虑多方面的因素并计算对应的权值,通过权值选举簇头和划分网络节点的簇结构,但分簇过程需预先知道节点的权值,延长网络的周期,使得信息转发开销较大,同时增加了节点的能量消耗。技术实现要素:本发明针对现有技术的不足,提出了基于节点数据值的分簇算法(nodedatavalueclusteringalgorithm,ndva),旨在提高分簇网络结构的稳定性,均衡网络的负载,延长网络的生命周期。为达到上述目的,本发明所采用的技术方案是:一种基于节点数据值的ad-hoc网络分簇算法,包括:1、计算任意节点mi的节点度数di与最佳节点度α在网络初始化时,处于未决定状态的节点mi通过周期性地发送探测报文信息,获取邻居节点的信息的个数,作为其节点度数di。在ad-hoc网络中,簇的大小受诸多条件的制约。簇头节点覆盖范围过大,网络会发生拥塞现象,而覆盖范围过小,则网络的的带宽利用率较低。为了获取适宜的吞吐量。假设k1,k2分别代表簇内通信带宽和簇间通信带宽,n代表网络中所有节点的数量,那么最佳节点度大小为:因为研究的节点均为同质节点,簇内通信带宽k1与簇间通信带宽k2相同,因此,最佳节点度α为则di=di-α。2、计算节点数据值vi节点数据值是由两部分组成:数据大小值和数据一致性值。节点在传输数据时,应充分考虑传输数据值的大小,当数据值过大时,节点的能耗将增大,可能导致节点的失效;当传输的数据值过小时,节点为了节省自身能量而选择丢包,有可能成为自私节点,最后导致传输的数据短缺或不真实。因此在充分考虑能量消耗的同时,也要保证传输数据的大小不超出合理的界限,这就是节点的数据值。假设一节点在传输数据时的门阈值为vs,经过节点mi传输给mj的数据d,节点mi和节点mj同簇,均属于网络初始时随机形成的同簇节点集合p,p={m1,m2,m3,…mi,…mj,…mk},其数据大小值为nij为在节点集合p中计算出由节点mi传输给它所有邻居节点的数据大小值并求出均值,最后得到节点mi的数据大小值:k为节点集合p的节点数量。设节点mi收集到的一致数据的次数为xi,同时收集的不一致数据的次数为yi,那么节点mi的数据一致性值qi为:根据节点的数据大小值和数据一致性值,那么节点mi的数据值vi为:vi=ni+qi。3、计算节点能量值ei设节点mi的初始能量值为e0,现有能量值为e1,剩余能量值e2大小为:节点mi在通信的过程中传输数据、接收数据和处理数据所用的能量为β,h=β/e1那么,则节点能量值ei=e2+q,即节点能量值的大小由节点剩余能量和q共同决定。4、计算节点到所有邻居节点的平均距离计算节点到其所有邻居节点的平均距离,利用发送的信号强度与接受的信号强度之间的关系:上式中,pi代表节点mi发送的信号强度,pj代表节点mj接受的信号强度,sij代表节点mi与节点mj之间的距离,g代表节点mi与节点mj之间的增益,hi代表节点mi的高度,hj代表节点mj的高度,则最后可得节点mi到同簇节点集合p中其所有邻居节点的平均距离:5、计算每个节点的组合权值在给定的某一环境中ω1、ω2、ω3和ω4的值是固定不变的,且ω1+ω2+ω3+ω4=1。通过层次分析法来确定权重值的大小,具体过程如下:层次分析法就是用两两重要性程度之比的形式表示出两个方案的相应重要性程度等级,并按其重要性程度评定等级,表1是比例标度表。表1比例标度表根据研究的重点确定出最重要的因素,标度为b,假设其他因素同等重要,其他因素相比于最终的因素的标度为1/b其他因素之间相比较后的标度都为1,最后得出判断矩阵为:通过计算该判断矩阵通过一致性检验,可得出最终的权重值。6、节点mi通过与邻居节点的权值相比较来进行分簇,权值节点最小的作为簇头,并向邻居节点广播消息,宣布自己成为簇头,在权值相同的状况下,拥有最小id的节点优先成为簇头,同时接受邻居节点的加入成为该簇头的簇成员,簇成员修改自身的列表,不再参与簇首的选举;若节点是孤立节点,则此节点单独成簇。本发明的优点是,分簇网络根据节点数据值、节点能量值、节点度数和节点平均距离选择簇首,产生的簇首稳定性好,更新频率低,负载平衡度高,网络生命周期较长,同时有效地避免了因节点传输数据过大而导致的能耗过大和数据过小而导致的传输数据的不真实的问题。附图说明图1为本发明算法流程图。图2为簇头数目随节点传输范围的变化图;图3为重入簇次数随节点移动速度的变化图.具体实施方式以下对本发明的实施例进行详细说明,但是本发明可以由权利要求限定和覆盖的多种不同方式实施。基于
背景技术:
中的描述,为了改善传统分簇算法存在的不足,本发明提出了基于节点数据值的ad-hoc网络分簇算法。首先分别计算任意节点mi的各项指标,包括其节点度数di与最佳节点度α的差值di、节点数据值vi、节点能量值ei和节点mi到同簇中所有邻居节点的平均距离然后计算组合权值其中ω1+ω2+ω3+ω4=1;最后通过比较节点mi与邻居节点的权值来进行分簇,权值最小的节点作为簇头,并向邻居节点广播消息,宣布自己成为簇头,在权值相同的状况下,拥有最小id的节点优先成为簇头;若节点是孤立节点,则此节点单独成簇。具体步骤如下:step1在网络初始化时,处于未决定状态的节点mi通过周期性地发送探测报文信息,获取邻居节点的信息的个数,作为其节点度数di。step2计算最佳节点度α。在ad-hoc网络中,簇的大小受诸多条件的制约。簇头节点覆盖范围过大,网络会发生拥塞现象,而覆盖范围过小,则网络的的带宽利用率较低。为了获取适宜的吞吐量。假设k1,k2分别代表簇内通信带宽和簇间通信带宽,n代表网络中所有节点的数量,那么最佳节点度大小为:因为研究的节点均为同质节点,簇内通信带宽与簇间通信带宽相同,因此,最佳节点度为最后每个节点计算其度数与最佳节点度α之差di=di-α。step3计算节点mi的节点数据值vi节点数据值是由两部分组成:数据大小值和数据一致性值。节点在传输数据时,应充分考虑传输数据值的大小,当数据值过大时,节点的能耗将增大,可能导致节点的失效;当传输的数据值过小时,节点为了节省自身能量而选择丢包,有可能成为自私节点,最后导致传输的数据短缺或不真实。因此在充分考虑能量消耗的同时,也要保证传输数据的大小不超出合理的界限,这就是节点的数据值。假设一节点在传输数据时的门阈值为vs,经过节点mi传输给节点mj的数据d,节点mi和节点mj同簇,均属于网络初始时随机形成的同簇节点集合p,p={m1,m2,m3,…mi,…mj,…mk},其数据大小值为nij为在节点集合p中计算出由节点mi传输给它所有邻居节点的数据大小值并求出均值,最后得到节点mi的数据大小值:k为节点集合p的节点数量。设节点mi收集到的一致数据的次数为xi,同时收集的不一致数据的次数为yi,那么节点mi的数据一致性值qi为:根据节点的数据大小值和数据一致性值,那么节点mi的数据值vi为:vi=ni+qistep4计算节点mi的能量值ei设节点mi的初始能量值为e0,现有能量值为e1,剩余能量值e2大小为:节点mi在通信的过程中传输数据、接收数据和处理数据所用的能量为β,h=β/e1那么,则节点mi的能量值ei=e2+q,节点能量值的大小由节点剩余能量和q共同决定。step5计算节点mi到所有邻居节点的平均距离计算节点到其所有邻居节点的平均距离利用发送的信号强度与接受的信号强度之间的关系:上式中,pi代表节点mi发送的信号强度,pj代表节点mj接受的信号强度,sij代表节点mi与节点mj之间的距离,g代表节点mi与节点mj之间的增益,hi代表节点mi的高度,hj代表节点mj的高度,则最后可得节点mi到同簇节点集合p中其所有邻居节点的平均距离:step6计算节点mi的组合权值在给定的某一环境中ω1、ω2、ω3和ω4的值是固定不变的,且ω1+ω2+ω3+ω4=1,通过层次分析法可以确定权重的大小,最后可得ω1=0.625,ω1=0.125,ω1=0.125,ω1=0.125。step7对网络中所有的节点分别进行上述步骤的计算得到权值,在随机分成的每簇内将某一节点与邻居节点的权值相比较来进行簇首的选取,权值节点最小的作为簇头,并向邻居节点广播消息,宣布自己成为簇头,在权值相同的状况下,拥有最小id的节点优先成为簇头,同时接受邻居节点的加入成为该簇头的簇成员,簇成员修改自身的列表,不再参与簇首的选举;若节点是孤立节点,则此节点单独成簇。本实施例中网络中所有的节点数n设置为100,在一开始就自动随机编号或者手工编号,最后利用ns2仿真软件,分别对最小id算法、最高节点度算法和wca算法三种传统的分簇算法与本文提出的ndva算法进行对比实验,通过将四种算法的实验结果进行对比,仿真实验的参数设置列表如表2所示。表2仿真实验参数列表参数参数取值仿真区域/m200*200节点总数/个100节点初始能量/j5节点数据长度/bit600节点数据控制长度/bit200节点传输范围/m0~50节点能量消耗值/(nj.b-1)0.005模拟时间/s300检测周期/s5其结果如图2和图3所示,其中图2为簇头数目随节点传输范围的变化;分析对比结果可知,随着节点传输范围的增加,簇头数目逐渐减少,当传输范围达到10m时,减少的趋势逐渐放缓。图3为重入簇次数随节点移动速度的变化;分析对比结果可知,随着节点移动速度的增加,四种算法的重入簇次数随之增加,其中3种传统算法增加的幅度都较大,由于ndva算法考虑了节点的数据值,因此重入簇次数增加最为缓慢,所形成的分簇结构更为稳定。上面结合附图对本发明的具体实施例作了详细说明,但是本发明并不限于上述实施例,在本领域普通技术人员所具备的知识范围内,还可以在不脱离本发明宗旨的前提下作出各种变化。当前第1页12
相关技术
网友询问留言
已有0条留言
- 还没有人留言评论。精彩留言会获得点赞!
1