使用元数据处理的耳机的双耳呈现的制作方法
相关申请的交叉引用
本申请要求2013年10月31日提交的美国临时专利申请no.61/898,365的优先权,该申请的全部内容特此通过引用并入。
一个或多个实现一般涉及音频信号处理,并且更具体地涉及用于耳机回放的基于声道和对象的音频的双耳呈现。
背景技术
空间音频通过一对扬声器的虚拟呈现通常涉及立体声双耳信号的创建,所述立体声双耳信号表示到达收听者的左耳和右耳的期望声音,并且被合成以模拟可能包含在不同位置处的众多源的三维(3d)空间中的特定音频场景。对于通过耳机、而不是扬声器的回放,双耳处理或呈现可以被定义为一组信号处理操作,这些信号处理操作旨在通过仿真人类主体的自然空间收听线索来通过耳机再现声源的预期3d位置。双耳呈现器的典型的核心组件是头部相关滤波以再现方向相关的线索以及距离线索处理,这些可能涉及对真实的或虚拟的收听房间或环境的影响进行建模。目前的双耳呈现器的一个示例将基于声道的音频展现(presentation)中的5.1或7.1环绕的5或7个声道中的每一个处理为围绕收听者的2d空间中的5/7个虚拟声源。双耳再现也通常在游戏或游戏音频硬件中找到,在这种情况下,处理可以基于游戏中的单个音频对象的单个3d位置而被应用于这些音频对象。
传统地,双耳呈现是应用于基于多声道或对象的音频内容的盲后处理的形式。双耳呈现中涉及的处理中的一些可能对内容的音色具有不期望的和负面的影响,诸如瞬态的平滑或者添加到对话或一些效果和音乐元素的过度的混响。随着耳机收听的重要性增长以及基于对象的内容(诸如
只要内容未被配置为与可以被即时提供给双耳呈现器的附加元数据一起在设备上被接收,目前的系统在流水线的回放端也未被优化。虽然实时头部跟踪先前已经被实现并且被显示出改进了双耳呈现,但是这一般阻止了其它特征,诸如自动化的连续头部大小感测和房间感测、以及将双耳呈现的质量改进得在基于耳机的回放系统中被有效地、高效率地实现的其它定制特征。
因此,需要在回放设备上运行的将制作元数据与实时地局部地产生的元数据组合以当通过耳机收听基于声道和对象的音频时为终端用户提供最好的可能的体验的双耳呈现器。此外,对于基于声道的内容,一般要求艺术意图通过合并音频分段分析而被保留。
背景部分中讨论的主题不应仅由于其在背景部分中被提及就被假定为是现有技术。类似地,背景部分中提及的或者与背景部分的主题相关联的问题不应被假定为先前在现有技术中就已经被认识到。背景部分中的主题仅代表不同的方法,这些方法本身也可以是发明。
技术实现要素:
描述了关于在基于耳机的回放系统中虚拟呈现基于对象的音频内容并且改进均衡的系统和方法的实施例。实施例包括一种用于呈现音频以供通过耳机回放的方法,该方法包括:接收数字音频内容;接收由对接收的数字音频内容进行处理的制作工具产生的双耳呈现元数据;接收由回放设备产生的回放元数据;并且组合双耳呈现元数据和回放元数据以优化数字音频内容通过耳机的回放。数字音频内容可以包括基于声道的音频和基于对象的音频,基于对象的音频包括用于再现相应的声源在三维空间中相对于收听者的预期位置的位置信息。该方法还包括基于内容类型将数字音频内容分成一个或多个成分,并且其中,内容类型选自由以下项构成的组:对话、音乐、音效、瞬态信号以及周围环境信号。双耳呈现元数据控制多个声道和对象特性,包括:位置、大小、增益调整以及内容相关的设置或处理预设;回放元数据控制多个收听者特定特性,包括头部位置、头部朝向、头部大小、收听房间噪声水平、收听房间性质以及回放设备或屏幕相对于收听者的位置。该方法还可以包括接收修改双耳呈现元数据的一个或多个用户输入命令,这些用户输入命令控制一个或多个特性,包括:提升强调,其中,提升的对象和声道可以接收增益提高;用于对象或声道定位的优选1d(一维)声音半径或3d缩放因子;以及处理模式启用(例如,以在传统立体声或内容的全处理之间切换)。回放元数据可以响应于由容纳多个传感器的使能(enabled)耳麦提供的传感器数据而产生,所述使能耳麦构成回放设备的一部分。该方法还可以包括:例如通过内容类型将输入音频分为单独的子信号,或者将(基于声道的和基于对象的)输入音频去混合为组成的直接内容和扩散内容,其中,扩散内容包括混响的或反射的声音元素;并且独立地对单独的子信号执行双耳呈现。
实施例还涉及一种用于通过以下步骤呈现音频以供通过耳机回放的方法:接收决定内容元素如何通过耳机呈现的内容相关元数据;从耦合到耳机的回放设备和包括耳机的使能耳麦中的至少一个接收传感器数据;并且利用传感器数据修改内容相关元数据以相对于一个或多个回放特性和用户特性优化呈现的音频。内容相关元数据可以由内容创建者操作的制作工具产生,并且其中,内容相关元数据决定包含音频声道和音频对象的音频信号的呈现。内容相关元数据控制选自由以下项构成的组的多个声道和对象特性:位置、大小、增益调整、提升强调、立体声/全切换、3d缩放因子、内容相关设置、以及呈现的声场的其它的空间和音色性质。该方法还可以包括将传感器数据格式化为与内容相关元数据兼容的元数据格式以生成回放元数据。回放元数据控制选自由以下项构成的组的多个收听者特定特性:头部位置、头部朝向、头部大小、收听房间噪声水平、收听房间性质以及声源设备位置。在实施例中,元数据格式包括容器,该容器包括符合定义的语法的一个或多个有效载荷分组,并且对相应的音频内容元素的数字音频定义进行编码。该方法还可以包括将组合的回放元数据和内容相关元数据与源音频内容一起编码为用于在呈现系统中处理的比特流;并且对编码的比特流进行解码以提取从内容相关元数据和回放元数据得到的一个或多个参数以产生修改用于通过耳机回放的源音频内容的控制信号。
所述方法还可以包括在通过耳机回放之前对源音频内容执行一个个或多个后处理功能;其中,后处理功能包括以下中的至少一个:从多个环绕声声道到双耳混合或立体声混合之一的下混、水平管理、均衡、音色校正以及噪声消除。
实施例进一步涉及执行或实施执行或实现上述方法等的处理命令的系统和制造品。
通过引用合并
本说明书中提及的每个出版物、专利和/或专利申请的全部内容通过引用并入本文,达到如同每一个出版物和/或专利申请被明确地分别地指示被通过引用并入一样的程度。
附图说明
在下面的附图中,相似的标号用于指代相似的元件。尽管下面的图描绘了各种例子,但是所述一个或多个实现不限于这些图中描绘的例子。
图1示出一些实施例下的合并内容创建、呈现和回放系统的实施例的总系统。
图2a是实施例下的在基于对象的耳机呈现系统中使用的制作工具的框图。
图2b是替代实施例下的在基于对象的耳机呈现系统中使用的制作工具的框图。
图3a是实施例下的在基于对象的耳机呈现系统中使用的呈现组件的框图。
图3b是替代实施例下的在基于对象的耳机呈现系统中使用的呈现组件的框图。
图4是提供实施例下的双端双耳呈现系统的概览的框图。
图5示出实施例下的可以与耳机呈现系统的实施例一起使用的制作工具gui。
图6示出实施例下的使能耳机,该耳机包括感测回放状况以用于编码为在耳机呈现系统中使用的元数据的一个或多个传感器。
图7示出实施例下的耳机和包括耳机传感器处理器的设备之间的连接。
图8是示出实施例下的可以用在耳机呈现系统中的不同的元数据组件的框图。
图9示出实施例下的用于耳机处理的双耳呈现组件的功能组件。
图10示出实施例下的耳机呈现系统中的用于呈现音频对象的双耳呈现系统。
图11示出实施例下的图10的双耳呈现系统的更详细的表示。
图12是示出实施例下的在用在耳机呈现系统中的hrtf建模系统中使用的不同工具的系统示图。
图13示出实施例下的使得能够对耳机呈现系统递送元数据的数据结构。
图14示出耳机均衡处理的实施例中的用于每个耳朵的三个脉冲响应测量的示例情况。
图15a示出实施例下的用于计算自由场声音传输的电路。
图15b示出实施例下的用于计算耳机声音传输的电路。
具体实施方式
描述了用于通过耳机虚拟呈现基于对象的内容的系统和方法以及用于这样的虚拟呈现的元数据递送和处理系统,但是应用不限于此。本文描述的一个或多个实施例的方面可以在包括执行软件指令的一个或多个计算机或处理设备的混合、呈现和回放系统中的对源音频信息进行处理的音频或视听系统中实现。所描述的任何实施例可以单独使用,或者按任何组合相互一起使用。尽管各种实施例的动机可能是在本说明书中的一个或多个地方可能讨论的或暗指的现有技术的各种缺陷,但是实施例不一定解决这些缺陷中的任何一个。换句话说,不同的实施例可能解决在本说明书中可能讨论的不同缺陷。一些实施例可能仅部分解决在本说明书中可能讨论的一些缺陷,或者可能仅解决在本说明书中可能讨论的一个缺陷,并且一些实施例可能不解决这些缺陷中的任何一个。
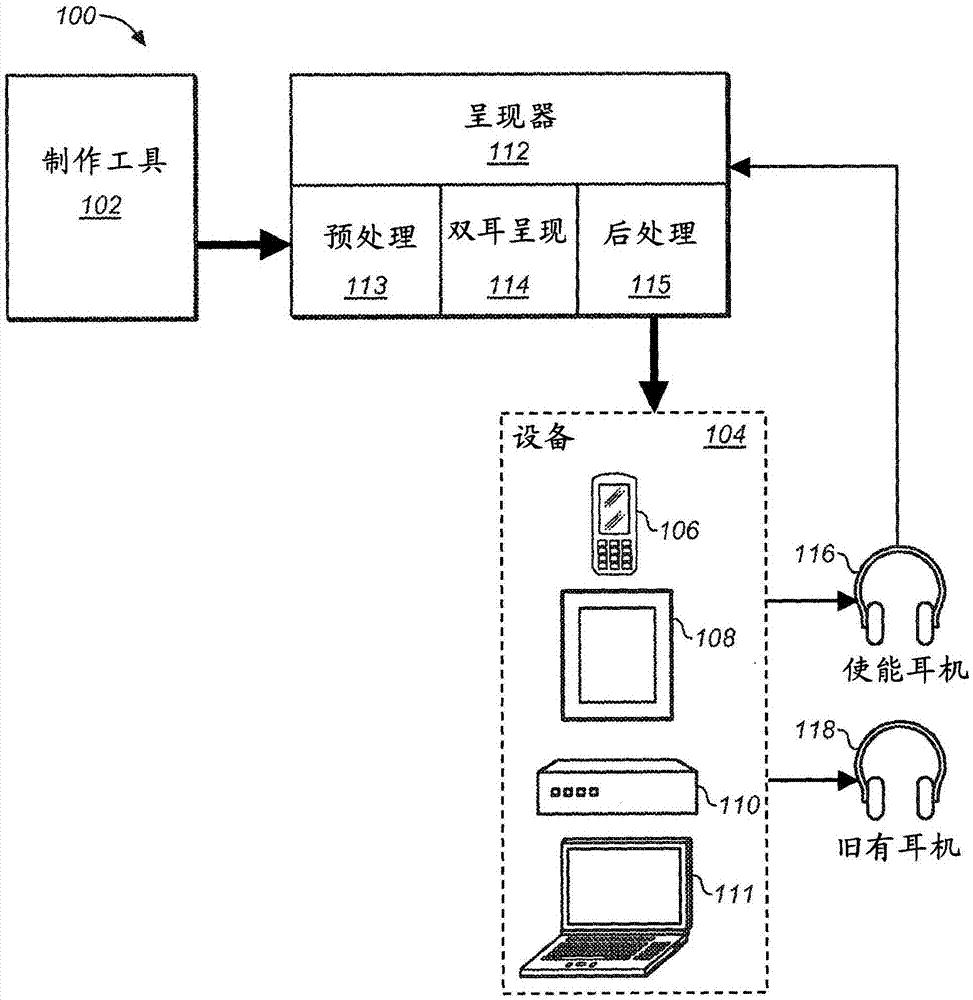
实施例针对优化基于对象和/或声道的音频通过耳机的呈现和回放的音频内容生成和回放系统。图1示出合并一些实施例下的内容创建、呈现和回放系统的实施例的总体系统。如系统100中所示的,制作工具102被创建者用于产生音频内容以供通过一个或多个设备104回放,以用于用户通过耳机116或118收听。设备104一般是运行允许回放音频内容的应用的小型计算机或移动电信设备或者便携式音频或音乐播放器。这样的设备可以是移动电话或音频(例如,mp3)播放器106、平板计算机(例如,appleipad或类似设备)108、音乐控制台110、笔记本计算机111、或任何类似的音频回放设备。音频可以包括可期望通过耳机被收听的音乐、对话、效果、或任何数字音频,并且这样的音频可以从内容源被无线地流传输、从存储介质(例如,盘、闪存驱动器等)被本地回放、或本地产生。在以下描述中,术语“耳机”通常具体指的是被用户戴在他/她的耳朵正上方的密耦合回放设备、或耳内收听设备;它还可以一般指的是作为术语“耳机处理”或“耳机呈现”的替代的、被执行以呈现意图用于在耳机上回放的信号的处理中的至少一些。
在实施例中,被系统处理的音频可以包括基于声道的音频、基于对象的音频、或基于对象和声道的音频(例如,混合型的或自适应的音频)。音频包括决定音频如何被呈现以供在特定的端点设备和收听环境上回放的元数据,或者与该元数据相关联。基于声道的音频一般指的是音频信号加元数据,在该元数据中位置被编码为声道标识符,其中音频被格式化以供通过具有相关联的标称环绕声位置的预定义的一组扬声器区(例如,5.1、7.1等)回放;基于对象意指具有参数化源描述(诸如视在源位置(例如,3d坐标)、视在源宽度等)的一个或多个音频声道。术语“自适应音频”可以用于意指基于声道的和/或基于对象的音频信号加元数据,该元数据使用音频流加元数据(在该元数据中位置被编码为空间中的3d位置)、基于回放环境来呈现音频信号。一般地,收听环境可以是任何开放的、部分封闭的、或完全封闭的区域,诸如房间,但是本文中描述的实施例一般针对通过耳机或其它紧邻的端点设备的回放。音频对象可被认为是可以被感知为源自环境中的特定的一个物理位置或多个物理位置的多组声音元素,并且这样的对象可以是静态的或动态的。音频对象由元数据控制,除了其它方面之外,该元数据详述声音在给定时间点的位置,并且当一回放时,它们就根据位置元数据而呈现。在混合型音频系统中,除了音频对象之外,基于声道的内容(例如,“床(bed)”)也可以被处理,其中音床是有效地基于声道的子混合(sub-mix)或stem。这些可以被递送以供最终回放(呈现),并且可以不同的基于声道的配置(诸如5.1、7.1)被创建。
如图1所示,用户所利用的耳机可以是仅包括简单地重新创建音频信号的无供电(non-powered)换能器的旧有或无源耳机118,或者它可以是包括将某些操作参数提供回给呈现器以供进一步对音频内容进行处理和优化的传感器和其它组件(供电或无供电)的使能耳机118。耳机116或118可以以任何适当的封闭耳朵设备(诸如开放式或封闭式耳机、耳上或耳内耳机、耳塞、耳垫、噪声消除、隔离或其它类型的耳机设备)体现。这样的耳机关于其与声源或设备104的连接可以是有线的或无线的。
在实施例中,除了基于对象的音频之外,来自制作工具102的音频内容还包括立体声或基于声道的音频(例如,5.1或7.1环绕声)。对于图1的实施例,呈现器112从制作工具接收音频内容,并且提供优化音频内容以供通过设备104和耳机116或118回放的某些功能。在实施例中,呈现器112包括预处理级113、双耳呈现级114和后处理级115。除了其它功能之外,预处理级113一般对输入音频执行某些分段操作,诸如基于音频的内容类型对其进行分段;双耳呈现级114一般组合并处理与音频的声道成分和对象成分相关联的元数据,并且产生双耳立体声或具有双耳立体声和附加的低频输出的多声道音频输出;并且后处理组件115在将音频信号发送到设备104之前一般执行下混、均衡、增益/响度/动态范围控制以及其它功能。应注意,虽然呈现器在大多数情况下将有可能产生两声道信号,但是它可以被配置为将输入的多于两个的声道提供给特定的使能耳机,例如以递送单独的低音声道(类似于传统环绕声中的lfe.1声道)。使能耳机可以具有与中频到较高频声音分开地再现低音成分的特定的多组驱动器。
应注意,图1的组件一般表示音频产生、呈现和回放系统的主要功能块,并且某些功能可以被作为一个或多个其它组件的一部分而合并。例如,呈现器112的一个或多个部分可以部分地或整个地合并在设备104中。在这种情况下,音频播放器或平板(或其它设备)可以包括集成在该设备内的呈现器组件。类似地,使能耳机116可以至少包括与回放设备和/或呈现器相关联的一些功能。在这样的情况下,完全集成的耳机可以包括集成的回放设备(例如,内置内容解码器,例如,mp3播放器)以及集成的呈现组件。另外,呈现器112的一个或多个组件(诸如预处理组件113)可以至少部分地在制作工具中实现,或者作为单独的预处理组件的一部分实现。
图2a是实施例下的基于对象的耳机呈现系统中使用的制作工具的框图。如图2a所示,来自音频源(例如,现场源、记录等)的输入音频202被输入到数字音频工作站(daw)204以供声音工程师处理。输入音频201通常是数字形式,并且如果模拟音频被使用,则需要a/d(模数)转换步骤(未示出)。该音频通常包括诸如在自适应音频系统(例如,dolbyatmos)中可以使用的基于对象和声道的内容,并且常常包括几种不同类型的内容。输入音频可以通过(可选的)音频分段预处理204进行分段,该音频分段预处理204基于音频的内容类型对音频进行分割(或分段),以使得不同类型的音频可以被不同地呈现。例如,对话可以被与瞬态信号或周围环境(ambient)信号不同地呈现。daw204可以被实现为用于对分段的或未分段的数字音频202进行编辑和处理的工作站,并且可以包括混合控制台、控制面、音频转换器、数据储存器和其它适当的元件。在实施例中,daw是运行数字音频软件的处理平台,除了其它功能(诸如均衡器、合成器、效果等)之外,该数字音频软件提供全面的编辑功能以及用于一个或多个插件程序(诸如声像器(panner)插件)的接口。daw204中所示的声像器插件执行声像功能,所述声像功能被配置为以将每个相应的对象信号的期望位置传递给收听者的方式将每个对象信号分配到2d/3d空间中特定的扬声器对或位置。
在制作工具102a中,来自daw204的处理的音频被输入到双耳呈现组件206。该组件包括音频处理功能,该音频处理功能生成双耳音频输出210以及双耳呈现元数据208和空间媒体类型元数据212。音频210以及元数据成分208和212与双耳元数据有效载荷214一起形成编码音频比特流。一般地,音频成分210包括与元数据成分208和212一起传递给比特流214的基于声道和对象的音频;然而,应注意,音频成分210可以是标准的多声道音频、双耳呈现的音频、或这两种音频类型的组合。双耳呈现组件206还包括直接生成用于直接连接到耳机的耳机输出216的双耳元数据输入功能。对于图2a的实施例,用于双耳呈现的元数据在制作工具102a内在混合时产生。在替代实施例中,如参照图2b所示的,元数据可以在编码时产生。如图2a所示,混合器203使用应用或工具来创建音频数据以及双耳和空间元数据。混合器203对daw204提供输入。可替代地,它还可以对双耳呈现处理206直接提供输入。在实施例中,混合器接收耳机音频输出216,以使得混合器可以监视音频和元数据输入的效果。这有效地构成反馈环路,在该反馈环路中,混合器接收通过耳机输出的耳机呈现的音频以确定是否需要任何输入改变。混合器203可以是人操作设备,诸如混合控制台或计算机,或者它可以是远程控制的或预编程的自动化处理。
图2b是替代实施例下的基于对象的耳机呈现系统中使用的制作工具的框图。在该实施例中,用于双耳呈现的元数据在编码时产生,并且编码器运行内容分类器和元数据产生器以从旧有的基于声道的内容产生附加元数据。对于图2b的制作工具102b,不包括任何音频对象、而仅包括基于声道的音频的旧有的多声道内容220被输入到编码工具和呈现耳机仿真组件226。基于对象的内容222也单独地输入到该组件。基于声道的旧有内容220可以首先被输入到可选的音频分段预处理器224以供分成不同的内容类型以用于单个呈现。在制作工具102b中,双耳呈现组件226包括耳机仿真功能,该耳机仿真功能生成双耳音频输出230以及双耳呈现元数据228和空间媒体类型元数据232。音频230以及元数据成分228和232与双耳元数据有效载荷236一起形成编码音频比特流。如上所述,音频成分230通常包括与元数据成分228和232一起传递给比特流236的基于声道和对象的音频;然而,应注意,音频成分230可以是标准的多声道音频、双耳呈现的音频、或这两种音频类型的组合。当旧有内容被输入时,输出的编码音频比特流可以包含明确分开的子成分音频数据或元数据,该元数据隐含描述内容类型,该内容类型允许接收端点执行分段并且适当地处理每个子成分。双耳呈现组件226还包括双耳元数据输入功能,该双耳元数据输入功能直接生成用于直接连接到耳机的耳机输出234。如图2b所示,可选的混合器(人或处理)223可以被包括以监视耳机输出234,以输入和修改可以直接提供给呈现处理226的音频数据和元数据输入。
关于内容类型和内容分类器的操作,音频一般被分类为多个定义的内容类型(诸如对话、音乐、周围环境、特殊效果等)中的一个。对象可以在其整个持续时间内改变内容类型,但是在任何特定的时间点,它一般仅是一种内容类型。在实施例中,内容类型被表达为对象在任何时间点为特定的内容类型的概率。因此,例如,持久的对话对象将被表达为百分之百概率的对话对象,而从对话变换到音乐的对象可以被表达为百分之五十的对话/百分之五十的音乐。处理具有不同内容类型的对象可以通过以下操作来执行:即,对它们的每种内容类型的相应概率进行平均,选择一组对象内的最主导(dominant)的对象、或单个对象随着时间、或内容类型度量的某一其它的逻辑组合的内容类型概率。内容类型也可以被表达为n维向量(其中,n是不同内容类型的总数,例如,在对话/音乐/周围环境/效果的情况下为四)。内容类型元数据可以被体现为组合的内容类型元数据定义,其中,内容类型的组合反映被组合的概率分布(例如,音乐、语音等的概率的向量)。
关于音频的分类,在实施例中,所述处理以每一个时间帧为基础进行操作以分析信号、识别信号的特征、以及将识别的特征与已知类的特征进行比较以便确定对象的特征与特定类的特征匹配的程度。基于特征与特定类匹配的程度,分类器可以识别对象属于特定类的概率。例如,如果在时间t=t,对象的特征与对话特征非常好地匹配,则该对象将被以高的概率分类为对话。如果在时间=t+n,对象的特征与音乐特征非常好地匹配,则该对象将被以高的概率分类为音乐。最后,如果在时间t=t+2n,对象的特征与对话或音乐均不特别好地匹配,则该对象可能被分类为50%音乐和50%对话。因此,在实施例中,基于内容类型概率,音频内容可以被分成与不同内容类型对应的不同的子信号。这例如通过按由计算的媒体类型概率决定(drive)的比例将原始信号的一些百分比发送到每个子信号(以宽带为基础或者以每一个频率子带为基础)来实现。
参照图1,来自制作工具102的输出被输入到呈现器112以供呈现为用于通过耳机或其它端点设备回放的音频输出。图3a是实施例下的基于对象的耳机呈现系统中使用的呈现组件112a的框图。图3a更详细地示出呈现器112的预处理113、双耳呈现114和后处理115子组件。从制作工具102,元数据和音频以编码音频比特流301的形式被输入到处理或预处理组件。元数据302被输入到元数据处理组件306,并且音频304被输入到可选的音频分段预处理器308。如参照图2a和2b所示的,音频分段可以由制作工具通过预处理器202或224执行。如果这样的音频分段不是由制作工具执行,则呈现器可以通过预处理器308执行该任务。处理的元数据和分段的音频然后被输入到双耳呈现组件310。该组件执行某些耳机特定的呈现功能,诸如3d定位、距离控制、头部大小处理等。双耳呈现的音频然后被输入到音频后处理器314,该音频后处理器314应用某些音频操作,诸如水平(level)管理、均衡、噪声补偿或消除等。后处理的音频然后被输出312以供通过耳机116或118回放。对于耳机或回放设备104安装有用于向呈现器反馈的传感器和/或麦克风的实施例,麦克风和传感器数据316被输入回元数据处理组件306、双耳呈现组件310或音频后处理组件314中的至少一个。对于未安装有传感器的标准耳机,头部跟踪可以用更简单的伪随机产生的头部“抖动(jitter)”代替,该头部“抖动”模仿连续改变的小的头部移动。这允许回放点处的任何相关的环境或操作数据被呈现系统使用以进一步修改音频以抵消或增强某些回放状况。
如以上提及的,音频的分段可以由制作工具或呈现器执行。对于音频被预分段(pre-segment)的实施例,呈现器直接处理该音频。图3b是该替代实施例下的基于对象的耳机呈现系统中使用的呈现组件的框图。如对于呈现器112b所示的,来自制作工具的编码音频比特流321以其输入到元数据处理组件326的元数据322和输入到双耳呈现组件330的音频324的组成部分提供。对于图3b的实施例,音频在适当的制作工具中被音频预分段处理202或224预分段。双耳呈现组件330执行某些耳机特定的呈现功能,诸如3d定位、距离控制、头部大小处理等。双耳呈现的音频然后被输入到音频后处理器334,该音频后处理器334应用某些音频操作,诸如水平管理、均衡、噪声补偿或消除等。后处理的音频然后被输出332以供通过耳机116或118回放。对于耳机或回放设备104安装有用于向呈现器反馈的传感器和/或麦克风的实施例,麦克风和传感器数据336被输入回元数据处理组件326、双耳呈现组件330或音频后处理组件334中的至少一个。图2a、2b、3a和3b的制作和呈现系统允许内容制作者使用制作工具102在内容创建时创建特定的双耳呈现元数据并且对该特定的双耳呈现元数据进行编码。这允许音频数据被用于指示呈现器利用不同的算法或利用不同的设置对音频内容的部分进行处理。在实施例中,制作工具102表示允许内容创建者(制作者)选择或创建用于回放的音频内容并且对构成该音频内容的声道和/或对象中的每一个定义某些特性的工作站或计算机应用。制作工具可以包括混合器类型控制台接口或混合控制台的图形用户接口(gui)表示。图5示出实施例下的可以与耳机呈现系统的实施例一起使用的制作工具gui。如在gui显示500中可以看到的,多个不同的特性被允许由制作者设置,诸如增益水平、低频特性、均衡、声像、对象位置和密度、延迟、渐淡(fade)等。对于所示的实施例,通过使用供制作者指定设置值的虚拟滑块来便于用户输入,尽管其它的虚拟化的或直接的输入手段也是可以的,诸如直接文本输入、电位计设置、旋转拨号盘等。由用户输入的参数设置中的至少一些被编码为与相关的声道或音频对象相关联的元数据以供与音频内容一起传输。在实施例中,元数据可以在音频系统中的编解码器(编码器/解码器)电路中被打包为附加的特定的耳机有效载荷的一部分。使用使能设备,对某些操作状况和环境状况(例如,头部跟踪、头部大小感测、房间感测、周围环境状况、噪声水平等)进行编码的实时元数据可以被即时提供给双耳呈现器。双耳呈现器组合制作的元数据内容和实时地本地产生的元数据以为用户提供优化的收听体验。一般地,由制作工具提供的对象控件和用户输入接口允许用户控制某些重要的耳机特定的参数,诸如双耳和立体声旁路(stereo-bypass)动态呈现模式、lfe(低频元素)增益和对象增益、媒体智能和内容相关控制。更具体地,可以使用耳间时间延迟和立体声幅度或强度声像、或者整个双耳呈现的组合(即,耳间时间延迟和水平以及频率相关的频谱线索的组合),在立体声(lo/ro)、矩阵化立体声(lt/rt)之间以内容类型为基础或以对象为基础来选择呈现模式。另外,频率交叉(crossover)点可以被指定以回到低于给定频率的立体声处理。低频增益也可以被指定以使低频成分或lfe内容衰减。如下面更详细地描述的,低频内容也可以被单独地传输到使能耳机。其它元数据可以以每一内容类型或每一声道/对象为基础指定,诸如一般通过直接/混响增益和频率相关的混响时间以及耳间目标互相关性描述的房间模型。它还可以包括房间的其它更详细的建模(例如,早期反射位置、增益和晚期混响增益)。它还可以包括直接指定的对特定房间响应进行建模的滤波器。其它元数据包括扭曲(warp)到屏幕标志(其控制对象如何被重新映射以适合作为距离的函数的观看角度和屏幕纵横比)。最后,收听者相对(relative)标志(即,是否应用头部跟踪信息)、优选的缩放(指定用于呈现内容的“虚拟房间”的默认大小/纵横比,其用于缩放对象位置以及重新映射到屏幕(根据设备屏幕大小和到设备的距离))、以及控制距离衰减定律(例如,1/(1+rα))的距离模型指数也是可以的。还可以用信号发送可应用于不同声道/对象或者根据内容类型而应用的参数组或“预设”。
如关于制作工具和/或呈现器的预分段组件所示的,不同类型的内容(例如,对话、音乐、效果等)可以基于制作者的意图和最佳的呈现配置而被不同地处理。基于类型或其它显著特性对内容的分割可以在制作期间先验地实现(例如,通过手动地将分割的对话保存在它们自己的一组音轨或对象中),或者在接收设备中呈现之前即时后验地实现。附加的媒体智能工具可以在制作期间被用于根据不同的特性对内容进行分类并且产生可以携载不同的多组呈现元数据的附加声道或对象。例如,在知晓stem(音乐、对话、拟音(foley)、效果等)和相关联的环绕(例如,5.1)混合之后,可以针对内容创建处理训练媒体分类器以开发识别不同的stem混合比例的模型。相关联的源分割技术可以被利用以使用从媒体分类器得到的加权功能来提取近似的stem。从提取的stem,将被编码为元数据的双耳参数可以在制作期间被应用。在实施例中,在终端用户设备中应用镜像处理,由此使用解码的元数据参数将创建与内容创建期间基本上类似的体验。
在实施例中,对于现有的工作室制作工具的扩展包括双耳监视和元数据记录。在制作时捕捉的典型的元数据包括:对于每个声道和音频对象的声道/对象位置/大小信息、声道/对象增益调整、内容相关元数据(可以基于内容类型而改变)、指示设置(诸如立体声/左/右呈现应当替代双耳而被使用)的旁路标志、交叉点和指示低于交叉点的低音频率必须被旁路和/或衰减的水平、以及描述直接/混响增益和频率相关混响时间或其它特性(诸如早期反射和晚期混响增益)的房间模型信息。其它内容相关元数据可以提供扭曲到屏幕功能,所述扭曲到屏幕功能重新映射图像以适合屏幕纵横比或改变作为距离的函数的观看角度。头部跟踪信息可以被应用于提供收听者相对体验。实现根据衰减定律(例如,1/(1+rα))控制距离的距离模型指数的元数据也可以被使用。这些仅表示可以通过元数据编码的某些特性,并且其它特性也可以被编码。
图4是实施例下的提供双端双耳呈现系统的概览的框图。在实施例中,系统400提供内容相关元数据和影响不同类型的音频内容将如何被呈现的呈现设置。例如,原始音频内容可以包括不同的音频元素,诸如对话、音乐、效果、周围环境声音、瞬态等。这些元素中的每一个可以被以不同的方式最佳地呈现,而不是将它们限制为全部以唯一一种方式呈现。对于系统400的实施例,音频输入401包括多声道信号、基于对象的声道、或声道加对象的混合音频。音频被输入到编码器402,该编码器402添加或修改与音频对象和声道相关联的元数据。如系统400中所示的,音频被输入到耳机监视组件410,该耳机监视组件410应用用户可调整参数化工具来控制耳机处理、均衡、下混以及适合于耳机回放的其它特性。用户优化的参数集(m)然后被编码器402作为元数据或附加元数据嵌入以形成被发送到解码器404的比特流。解码器404对元数据以及基于对象和声道的音频的用于控制耳机处理和下混组件406的参数集m进行解码,该耳机处理和下混组件406生成到耳机的耳机优化和下混(例如,5.1到立体声)的音频输出408。尽管某个内容相关处理已在目前的系统和后处理链中被实现,但是它一般尚未被应用于诸如图4的系统400中所示的双耳呈现。
如图4所示,某些元数据可以由耳机监视组件410提供,该耳机监视组件410提供控制耳机特定的回放的特定的用户可调整参数化工具。这样的组件可以被配置为为用户提供对针对被动地回放发送的音频内容的旧有耳机118的耳机呈现的一定程度的控制。可替代地,端点设备可以是使能耳机116,其包括传感器和/或一定程度的处理能力以产生元数据或信号数据,该元数据或信号数据可以被编码为兼容的元数据以进一步修改制作的元数据,以针对通过耳机的呈现对音频内容进行优化。因此,在内容的接收端,呈现被即时执行,并且可以考虑本地产生的传感器阵列数据,该传感器阵列数据可以由耳麦(headset)或耳麦附连的实际的移动设备104产生,并且这样的硬件产生的元数据可以进一步与内容创建者在制作时创建的元数据组合以增强双耳呈现体验。
如上所述,在一些实施例中,低频内容可以被单独地传输到允许多于一个立体声输入(通常3或4个音频输入)的使能耳机,或者被编码和调制到携载到具有唯一立体声输入的耳麦的主要立体声波形的较高频中。这将允许进一步的低频处理在耳机中发生(例如,路由到针对低频优化的特定驱动器)。这样的耳机可以包括低频特定的驱动器和/或滤波器加交叉和放大电路以优化低频信号的回放。
在实施例中,在回放侧提供从耳机到耳机处理组件的链路以使得能够手动识别耳机以用于耳机的自动耳机预设加载或其它配置。这样的链路可以被实现为例如图4中从耳机到耳机处理406的无线或有线链路。该识别可以被用于配置目标耳机或者将特定的内容或特别呈现的内容发送到特定的一组耳机,如果多个目标耳机正被使用的话。耳机标识符可以被体现为任何适当的字母数字或二进制码,该字母数字或二进制码被呈现处理作为元数据的一部分或者单独的数据处理操作而处理。
图6示出实施例下的使能耳机,该使能耳机包括感测回放状况以供编码为在耳机呈现系统中使用的元数据的一个或多个传感器。各种传感器可以被布置成可以被用于在呈现时将即时元数据提供给呈现器的传感器阵列。对于图6的示例耳机600,除了其它适当的传感器之外,传感器包括测距传感器(诸如红外ir或飞行时间tof照相机)602、张力/头部大小传感器604、陀螺仪传感器606、外部麦克风(或对)610、周围环境噪声消除处理器608、内部麦克风(或对)612。如图6所示,传感器阵列可以包括音频传感器(即,麦克风)以及数据传感器(例如,朝向、大小、张力/应力和测距传感器)两者。特别地,为了与耳机一起使用,朝向数据可以被用于根据收听者的头部运动“锁定”或旋转空间音频对象,张力传感器或外部麦克风可以被用于推断收听者的头部的大小(例如,通过监视位于耳杯上的两个外部麦克风处的音频互相关)并且调整相关的双耳呈现参数(例如,耳间时间延迟、肩部反射定时等)。测距传感器602可以被用于在移动a/v回放的情况下评估到显示器的距离并且校正屏上对象的位置以考虑距离相关的观看角度(即,随着屏幕越接近收听者,越宽地呈现对象)或者调整全局增益和房间模型以传递适当的距离呈现。如果音频内容是在范围可以从小型移动电话(例如,2-4”屏幕大小)到平板(例如,7-10”屏幕大小)、再到膝上型计算机(例如,15-17”屏幕大小)的设备上回放的a/v内容的一部分,则这样的传感器功能是有用的。另外,传感器也可以被用于自动地检测和设置左和右音频输出到正确的换能器的路由,而不需要耳机上的特定的先验朝向或明确的“左/右”标记。
如图1所示,发送到耳机116或118的音频或a/v内容可以通过手持或便携式设备104提供。在实施例中,设备104本身可以包括一个或多个传感器。例如,如果设备是手持游戏控制台或游戏控制器,则某些陀螺仪传感器和加速度计可以被提供以跟踪对象移动和位置。对于该实施例,耳麦连接的设备104也可以提供附加的传感器数据(诸如朝向、头部大小、照相机等)作为设备元数据。
对于该实施例,实现某些耳机到设备通信手段。例如,耳麦可以通过有线或无线数字链路或模拟音频链路(麦克风输入)连接到设备,在这种情况下,元数据将被频率调制和添加到模拟麦克风输入。图7示出实施例下的耳机和包括耳机传感器处理器702的设备104之间的连接。如系统700中所示的,耳机600通过有线或无线链路将某些传感器、音频和麦克风数据701发送到耳机传感器处理器702。来自处理器702的处理的数据可以包括具有元数据的模拟音频704或空间音频输出706。如图7所示,每个连接包括耳机、处理器和输出之间的双向链路。这允许传感器和麦克风数据在耳机和设备之间发送以供创建或修改适当的元数据。除了硬件产生的元数据之外,还可以提供用户控制以补充或产生适当的元数据,如果元数据不可通过硬件传感器阵列获得的话。示例用户控制可以包括:提升(elevation)强调、双耳开/关切换、优选声音半径或大小、以及其它类似的特性。这样的用户控制可以通过与耳机处理器组件、回放设备和/或耳机相关联的硬件或软件接口元件来提供。
图8是示出实施例下的可以在耳机呈现系统中使用的不同的元数据成分的框图。如图800所示,被耳机处理器806处理的元数据包括制作的元数据(诸如由制作工具102和混合控制台500生成的元数据)和硬件产生的元数据804。硬件产生的元数据804可以包括用户输入的元数据、由设备808提供的或者从从设备808发送的数据产生的设备侧元数据、和/或由耳机810提供的或者从从耳机810发送的数据产生的耳机侧元数据。
在实施例中,制作的802和/或硬件产生的804元数据在呈现器112的双耳呈现组件114中被处理。元数据提供对特定的音频声道和/或对象的控制以优化通过耳机116或118的回放。图9示出实施例下的用于耳机处理的双耳呈现组件的功能组件。如系统900中所示的,解码器902输出多声道信号或声道加对象音轨,连同用于控制由耳机处理器904执行的耳机处理的解码的参数集m。耳机处理器904还从基于照相机的或基于传感器的跟踪设备910接收某些空间参数更新906。跟踪设备910是测量与用户的头部相关联的某些角度和位置参数(r、θ、ф)的面部跟踪或头部跟踪设备。空间参数可以对应于距离和某些朝向角度,诸如偏航(yaw)、倾斜和滚动(roll)。原始的空间参数集x可以随着传感器数据910被处理而更新。这些空间参数更新y然后被传递到耳机处理器904以供进一步修改参数集m。处理的音频数据然后被发送到后处理级908,该后处理级908执行某些音频处理,诸如音色校正、滤波、下混和其它相关处理。音频然后被均衡器912均衡,并且被发送到耳机。在实施例中,如在下面的描述中更详细地描述的,均衡器912可以使用或不使用压力分配比(pdr)变换来执行均衡。
图10示出实施例下的耳机呈现系统中的用于呈现音频对象的双耳呈现系统。图10示出信号成分中的一些在它们通过双耳耳机处理器被处理时。如图1000所示,对象音频成分被输入到去混合器(unmixer)1002,该去混合器1002分离音频的直接成分和扩散(diffuse)成分(例如,使直接与混响路径分离)。直接成分被输入到下混组件1006,该下混组件1006利用相移信息将环绕声道(例如,5.1环绕)下混为立体声。直接成分还被输入到直接内容双耳呈现器1008。两个两声道成分然后被输入到动态音色均衡器1012。对于基于对象的音频输入,对象位置和用户控制信号被输入到虚拟器操纵器(virtualizersteerer)组件1004。这产生缩放的对象位置,该缩放的对象位置连同直接成分一起被输入到双耳呈现器1008。音频的扩散成分被输入到单独的双耳呈现器1010,并且在作为两声道输出音频输出之前被加法器电路与呈现的直接内容组合。
图11示出实施例下的图10的双耳呈现系统的更详细的表示。如图11的示图1100所示,基于多声道和对象的音频被输入到去混合器1102以供分离成直接成分和扩散成分。直接内容被直接双耳呈现器1118处理,而扩散内容被扩散双耳呈现器1120处理。在直接内容的下混1116和音色均衡1124之后,扩散音频成分和直接音频成分然后通过加法器电路被组合以供诸如通过耳机均衡器1122和其它可能的电路进行后处理。如图11所示,某些用户输入和反馈数据被用于修改扩散双耳呈现器1120中的扩散内容的双耳呈现。对于系统1100的实施例,回放环境传感器1106提供关于收听房间性质和噪声估计(周围环境声音水平)的数据,头部/面部跟踪传感器1108提供头部位置、朝向和大小数据,设备跟踪传感器1110提供设备位置数据,并且用户输入1112提供回放半径数据。该数据可以由位于耳机116和/或设备104中的传感器提供。各种传感器数据和用户输入数据被与内容元数据组合,这在虚拟器操纵器组件1104中提供对象位置和房间参数信息。该组件还从去混合器1102接收直接和扩散能量信息。虚拟器操纵器1104将包括对象位置、头部位置/朝向/大小、房间参数以及其它相关信息的数据输出到扩散内容双耳呈现器1120。以这种方式,输入音频的扩散内容被调整以适应传感器和用户输入数据。
虽然当传感器数据、用户输入数据和内容元数据被接收时实现虚拟器操纵器的最佳性质,但是即使在不存在这些输入中的一个或多个的情况下,也可以实现虚拟器操纵器的有益性能。例如,当对旧有内容(例如,不包含双耳呈现元数据的编码比特流)进行处理以供通过传统的耳机(例如,不包括各种传感器、麦克风等的耳机)回放时,即使在不存在对于虚拟器操纵器的一个或多个其它的输入的情况下,仍可以通过将去混合器1102的直接能量输出和扩散能量输出提供给虚拟器操纵器1104以产生用于扩散内容双耳呈现器1120的控制信息来获得有益结果。
在实施例中,图11的呈现系统1100允许双耳耳机呈现器高效地基于耳间时间差(itd)和耳间水平差(ild)以及头部大小的感测来提供个性化。ild和itd是关于方位角的重要线索,该方位角是当音频信号在水平面中被生成时该音频信号相对于头部的角度。itd被定义为声音在两个耳朵之间的到达时间的差,并且ild效果使用进入耳朵的声音水平的差来提供定位线索。一般接受的是,itd被用于定位低频声音,并且ild被用于定位高频声音,而两者都被用于包含高频和低频两者的内容。
呈现系统1100还允许适应源距离控制和房间模型。它进一步允许直接对扩散/混响(干/湿)内容提取和处理、房间反射的优化以及音色匹配。
hrtf模型
在空间音频再现中,某些声源线索被虚拟化。例如,意图被从收听者后面听到的声音可以由物理上位于它们后面的扬声器产生,并且这样,所有的收听者都将这些声音感知为来自后面。利用通过耳机的虚拟空间呈现,另一方面,来自后面的音频的感知由用于产生双耳信号的头部相关传递函数(hrtf)控制。在实施例中,基于元数据的耳机处理系统100可以包括某些hrtf建模机制。这样的系统的基础一般建立于头部和躯干的结构模型上。该方法允许算法被建立于模块化方法中的核心模型上。在该算法中,模块化算法被称为“工具”。除了提供itd和ild线索之外,模型方法提供相对于头部上的耳朵的位置(更广泛地,建立于模型上的工具)的参考点。系统可以根据用户的人体测量特征而被调谐或修改。模块化方法的其它益处允许突出某些特征以便放大特定的空间线索。例如,某些线索可以被夸大超出声学双耳滤波器将给予个体的线索。图12是示出实施例下的在用在耳机呈现系统中的hrtf建模系统中使用的不同工具的系统示图。如图12所示,在至少一些输入成分被滤波1202之后,某些输入(包括方位角、仰角、fs和范围)被输入到建模级1204。在实施例中,滤波器级1202可以包括雪人(snowman)滤波器模型,该雪人滤波器模型由在球形身体的顶部的球形头部构成,并且考虑躯干以及头部对hrtf的贡献。建模级1204计算耳廓模型和躯干模型,并且左和右(l,r)成分被后处理1206以供最终输出1208。
元数据结构
如上所述,被耳机回放系统处理的音频内容包括声道、对象和相关联的元数据,该元数据提供优化音频通过耳机的呈现所必需的空间线索和处理线索。这样的元数据可以从制作工具被作为制作的元数据以及从一个或多个端点设备被作为硬件产生的元数据产生。图13示出实施例下的使得能够为耳机呈现系统递送元数据的数据结构。在实施例中,图13的元数据结构被配置为补充在比特流的其它部分中递送的元数据,所述比特流可以根据已知的基于声道的音频格式(诸如dolbydigitalac-3或增强ac-3比特流语法)而打包。如图13所示,数据结构由容器1300构成,该容器1300包含一个或多个数据有效载荷1304。每个有效载荷在容器中通过使用提供有效载荷中存在的数据的类型的明确的指示的唯一的有效载荷标识符值而被识别。容器内的有效载荷的次序未被定义。有效载荷可以按任何次序存储,并且解析器必须能够对整个容器进行解析以提取相关的有效载荷,并且忽略既不相关的、又不支持的有效载荷。可以被解码设备使用以验证容器和容器内的有效载荷无错误的保护数据1306跟随容器中的最后的有效载荷。包含同步、版本和key-id信息的初始部分1302在容器中的第一个有效载荷的前面。
数据结构通过对特定有效载荷类型使用版本化和标识符来支持可扩展性。元数据有效载荷可以被用于描述在ac-3或增强ac-3(或其它类型)比特流中递送的音频节目(program)的性质或配置,或者可以被用于控制被设计为进一步对解码处理的输出进行处理的音频处理算法。
容器可以使用不同的编程结构、基于实现偏好来定义。以下的表示出实施例下的容器的示例语法。
下表中示出用于以上提供的示例容器语法的可变比特(variablebit)的可能的语法的示例。
下表中示出用于以上提供的示例容器语法的有效载荷配置的可能的语法的示例。
以上语法定义被作为示例实现提供,而非意在于限制,因为许多其它不同的程序结构可以被使用。在实施例中,使用被称为可变比特的方法来对有效载荷数据和容器结构内的许多字段进行编码。该方法使得能够以能够表达任意大的字段值的可扩展性来对小的字段值进行高效编码。当使用variable_bit编码时,字段由一组或多组n比特构成,其中每组之后跟着1比特的read_more字段。在最低限度,n比特的编码需要n+1比特被发送。所有使用variable_bit编码的字段都被解释为无符号整数。各种其它不同的编码方面可以根据本领域的普通技术人员已知的实践和方法来实现。以上表和图13示出了示例元数据结构、格式和程序内容。应注意,这些意图表示元数据表示的一个示例实施例,并且其它元数据定义和内容也是可能的。
耳机eq和校正
如图1所示,某些后处理功能115可以由呈现器112执行。如图9的元件912所示,一个这样的后处理功能包括耳机均衡。在实施例中,可以通过获得对于每个耳朵的不同耳机放置的被堵塞耳道脉冲响应测量来执行均衡。图14示出耳机均衡处理的实施例中的对于每个耳朵的三个脉冲响应测量的示例情况。均衡后处理计算每个响应的快速傅立叶变换(fft),并且执行得到的响应的rms(均方根)平均。响应可以是可变的、倍频程(octave)平滑的、erb平滑的、等等。所述处理然后通过对中频和高频处的逆幅值响应的限值(+/-xdb)的约束来计算rms平均的逆|f(ω)|。所述处理然后确定时域滤波器。
后处理还可以包括闭合到开放变换功能。该压力分配比(pdr)方法涉及通过在如何根据最早到达的到达声音的方向对于自由场声音传输获得测量的方面的修改来为封闭式(closed-back)耳机设计匹配鼓膜和自由场之间的声阻抗的变换。这间接地使得能够在不需要复杂的鼓膜测量的情况下匹配封闭式耳机和自由场等效条件之间的鼓膜压力信号。
图15a示出实施例下的用于计算自由场声音发送的电路。电路1500基于自由场声阻抗模型。在该模型中,p1(ω)是利用围绕正中面成θ度(例如,相对于收听者的左边和前面大约30度)的喇叭在被堵塞耳道的入口处测量的thevenin压力,该测量涉及从测量的脉冲响应提取直接声音。测量p1(ω)可以在耳道的入口处或者在耳道内部离开口某一距离(xmm)处(或在鼓膜处)对于用于测量p1(ω)(该测量涉及从测量的脉冲响应提取直接声音)的相同放置处的相同喇叭进行。
对于该模型,如下计算p2(ω)/p1(ω)的比:
图15b示出实施例下的用于计算耳机声音发送的电路。电路1510基于耳机声阻抗模拟模型。在该模型中,p4是利用耳机(rms平均的)稳态测量在被堵塞耳道的入口处测量的,并且测量p5(ω)是在去往耳道的入口处或者在耳道内部离开口一定距离处(或在鼓膜处)对于用于测量p4(ω)的相同耳机放置进行的。
对于该模型,如下计算p5(ω)/p4(ω)的比:
然后可以使用以下公式来计算压力分配比(pdr):
本文描述的方法和系统的方面可以在用于处理数字或数字化音频文件的适当的基于计算机的声音处理网络环境中实现。自适应音频系统的部分可以包括一个或多个包括任何期望数量的单个的机器的网络,所述机器包括用于缓冲和路由在计算机之间传输的数据的一个或多个路由器(未示出)。这样的网络可以构建于各种不同的网络协议上,并且可以是互联网、广域网(wan)、局域网(lan)或它们的任何组合。在网络包括互联网的实施例中,一个或多个机器可以被配置为通过web浏览器程序来访问互联网。
所述组件、块、处理或其它功能组件中的一个或多个可以通过控制系统的基于处理器的计算设备的执行的计算机程序来实现。还应注意,本文公开的各种功能就它们的行为、寄存器传送、逻辑组件和/或其它特性而言,可以使用硬件、固件的任何数量的组合来描述,和/或被描述为包含在各种机器可读或计算机可读介质中的数据和/或指令。这样的格式化的数据和/或指令可以被包含在其中的计算机可读介质包括,但不限于,各种形式的物理的(非暂时性)非易失性存储介质,诸如光学、磁性或半导体存储介质。
除非上下文另有明确要求,否则在整个描述和权利要求书中,词语“包括”等要被解释为与排他或穷举的意义完全相反的包容性的意义;也就是说,“包括但不限于”的意义。使用单数或复数的词语也分别包括复数或单数。另外,词语“本文”、“下文”、“以上”、“以下”以及类似的词语指的是作为整体的本申请,而不指的是本申请的任何特定部分。当在引用两个或更多个项的列表中使用词语“或”时,该词语涵盖该词语的以下全部解释:该列表中的任何项、该列表中的全部项以及该列表中的项的任何组合。
虽然已经以举例的方式就特定实施例描述了一个或多个实现,但是要理解一个或多个实现不限于所公开的实施例。相反,意图是涵盖对于本领域技术人员将是显而易见的各种修改和类似布置。因此,所入权利要求的范围应被给予最广泛的解释,以便包含所有这样的修改和类似的布置。
- 还没有人留言评论。精彩留言会获得点赞!