基于岭回归和极限学习机的室内定位方法与流程
本发明涉及一种定位方法,具体而言,涉及一种基于岭回归和极限学习机的室内定位方法,属于机器学习领域。
背景技术:
随着通信和智能产业的不断发展,定位技术在我们的日常生活中扮演着越来越重要的角色。虽然全球定位系统可以在户外提供高精度的定位结果,但在复杂的室内环境中效果不佳。因此,如何实现室内环境中的精准定位,已经成为当下研究的热点问题。
目前市面上出现了很多的室内定位系统,主要包括基于rfid的定位系统、基于红外的定位系统、基于超声波的定位系统和基于蓝牙的定位系统等。上述系统虽然能在一定程度上满足人们的使用需求。但是这些系统在使用时都需要额外增加部署传感器节点、成本较大,而且存在功耗大、不稳定等弊端。相比较而言,基于wifi信号的室内定位方法凭借其使用方便、无需额外部署传感器、成本低廉等优点越来越受到人们的关注。
基于wifi信号的定位技术包括基于信号传播模型的方法和基于信号指纹的定位方法。具体而言,基于信号传播模型的方法,其工作原理为:移动终端从wifi接入点收到wifi信号强度之后,首先,通过经典传播模型来估计距离wifi接入点的距离,然后,通过三点(或多点)定位方法估计最终位置。基于信号指纹的定位方法包括两个阶段:离线阶段和在线阶段。在离线阶段中,移动终端在所定位区域采集wifi信号强度构建wifi信号强度指纹数据库,并且映射到相应的位置坐标组成训练集。在在线阶段中,移动终端采集周围环境中的wifi信号强度,组成wifi信号强度指纹,然后使用一些匹配方法把wifi信号强度指纹匹配到相应的位置。在实际的使用过程中,人们发现由于应用场景中环境的复杂性和多样性,基于信号传播模型的方法所计算出的距离往往不太准确,这样一来无疑会导致定位结果的精度不高。相比较而言,基于信号指纹的定位方法更为稳定、实现方式更为便捷、结果精度更高。
近年来,随着机器学习技术的发展,定位问题可以通过机器学习技术来解决。基于机器学习的定位方法已经成为研究的热点。支持向量机(svm)、神经网络(nn)以及极限学习机(elm)作为三种优秀的机器学习方法,已被广泛应用于室内定位。其中,基于elm的室内定位系统,具有学习速度快,计算复杂度低,泛化性能好等优点。然而,基于elm的室内定位系统也存在一些缺点。首先,其存在过拟合的风险。此外,基于elm的室内定位系统直接计算最小范数的最小二乘解,定位结果稳定性弱,存在出现较大误差的风险。最后,传统的elm在数据异常情况下的鲁棒性差,对数据集比较敏感。为了解决这些问题,黄广斌等人提出了基于约束优化的elm,通过在hth或hht的对角线上加上一正值k的方式,获取到更稳定、泛化能力更强的结果(其中h表示随机的隐层输出矩阵)。但在这一方法中,正值k要求由用户指定,而选择最优正值k的过程十分繁琐且耗时,因此这一方法在实际的使用过程中,使用效果并不理想。
综上所述,如何在现有技术的基础上提出一种新的定位方法,结合现有技术中的诸多优点、克服诸多缺陷,也就成为了本领域内技术人员亟待解决的问题。
技术实现要素:
鉴于现有技术存在上述缺陷,本发明提出了一种基于岭回归和极限学习机的室内定位方法,包括如下步骤:
s1、离线数据集构建步骤,在定位区域内采集无线信号接收强度数据,建立离线数据训练集;
s2、离线学习步骤,利用岭回归技术和极限学习机技术,学习离线数据训练集中的无线信号接收强度与目标位置之间的关系,训练得到基于位置的递归模型;
s3、在线数据获取步骤,在线收集待估计位置处的无线信号接收强度数据并将其代入基于位置的递归模型中,得到位置估计结果。
优选地,所述无线信号为wifi信号。
优选地,s1所述离线数据集构建步骤,具体包括:在定位区域的不同位置处采集无线信号接收强度数据,结合所述无线信号接收强度数据及与其相匹配的位置坐标数据,建立信号强度-目标位置指纹库、并将其作为离线数据训练集。
优选地,假定所述离线数据训练集为{xi,ti},其中xi∈r1×n,ti∈r1×m,i=1,2,...,n,s2所述离线学习步骤,具体包括:
s21、随机生成隐层输出矩阵h,
其中,h(xi)是隐层行向量的输出,h(xi)=[h1(x),h2(x),......,hl(x)],
h(xi)∈r1×l,h(xi)=h(ωi·xj+bi),
其中,ωi是连接输入层与输出层的权值,bi是第i隐层的阈值,ωi·xj表示ωi和xj的内积;
s22、计算hth的特征值λi和特征向量矩阵φ,
φ=[φ1,φ2,......,φn],
其中,φi为特征值λi对应的特征向量;
s23、计算初始输出权值β0,
计算训练误差ξ和对应的方差σ2,σ2i=cov(ξξt);
s24、计算岭回归参数k;
s25、计算输出权值β,
β=(hth+ki)-1t,
s26、对于给定迭代次数n,若训练误差ξ小于给定值ε,则结束循环,否则定义h的广义逆
s27、输出权值β=(hth+ki)-1t,得到基于位置的递归模型。
优选地,s24所述计算岭回归参数k,具体包括:
s241、将t=hβ+ξ写为等价形式t=zα+ξ,
其中,α=φtβ;
s242、计算α,α=(ztz)-1ztt;
s243、计算岭回归参数k,
优选地,s3所述在线位置估计步骤,具体包括:
s31、对定位区域内待估计位置处的无线信号接收强度数据进行在线收集、并将其作为待估计位置的无线信号接收强度指纹;
s32、将无线信号接收强度指纹代入基于位置的递归模型中,所述基于位置的递归模型的输出结果即为位置估计结果。
与现有技术相比,本发明的优点主要体现在以下几个方面:
本发明具有在离线阶段学习稳定性好、在在线阶段定位精度高等优点,可以充分满足实际的使用需求。同时,本发明对于离线训练数据集中异常数据元素的敏感性低,在数据异常情况下的鲁棒性好,具有很强的抗干扰性能,从而进一步确保了本发明定位结果的精确性。
此外,本发明也为同领域内的其他相关问题提供了参考,可以以此为依据进行拓展延伸,运用于同领域内其他定位方法和机器学习系统的技术方案中,具有十分广阔的应用前景。
以下便结合实施例附图,对本发明的具体实施方式作进一步的详述,以使本发明技术方案更易于理解、掌握。
附图说明
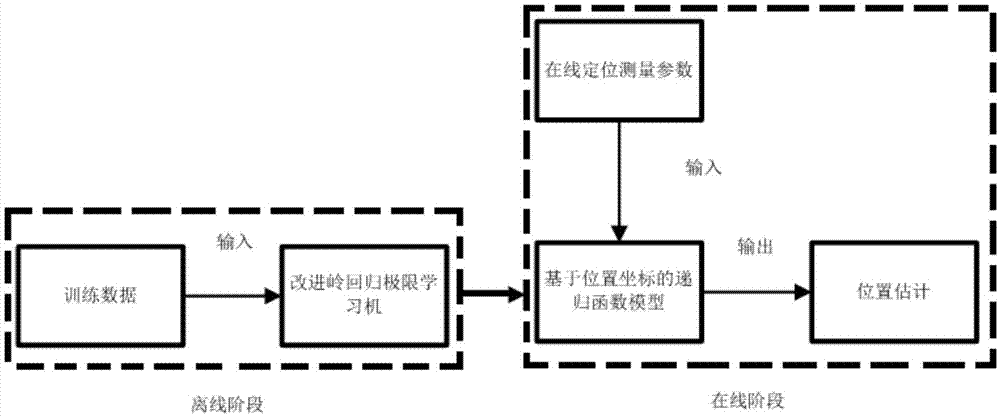
图1为本发明的流程示意图;
图2为本发明在不同激活函数下的性能表现比较图;
图3为本发明在不同激活函数下与常规elm的性能比较图;
图4为本发明在不同隐层节点数下与常规elm的性能比较图。
具体实施方式
如图1所示,本发明揭示了一种基于岭回归和极限学习机的室内定位方法。
为了更好的对本发明的技术方案进行说明,接下来对现有技术中的极限学习机(elm)技术进行具体解释。
elm算法是一种针对单层前馈神经网络的机器学习算法。它随机生成输入层和隐层之间的输入权值和阈值。使用
在训练数据数n大于隐层节点数l时
在算法的离线阶段中,对于k的求法包括如下步骤,首先需要计算训练阶段elm的训练误差ξ,
将上述二式结合可得,t=hβ+ξ。
随后计算hth的特征值λi和相应的特征向量φi,则可以得到hth=φλφt。
其中φ为特征向量矩阵,λ为对角阵。φ=[φ1,φ2,......,φn]组成一个n×n的特征矩阵,λ=diag[λ1,λ2,......,λn],λ1,λ2,......,λn是hth的特征值。
则t=hβ+ξ可以改写成t=zα+ξ,其中α=φtβ,z=hφ。
利用最小二乘解法,可得α=(ztz)-1ztt,
依据上述结果,即可计算输出权值β,β=(hth+ki)-1t。
为了获得更精确的结果,把循环迭代用于计算k。
给定迭代次数n,如果训练误差ξ小于给定值ε,则输出结果β,退出循环。否则重复迭代。直到迭代次数超过n或者训练误差ξ小于给定值ε。
在在线阶段中,则根据循环迭代得到的权重系数β来进行预测
结合上述现有技术,本发明的基于岭回归和极限学习机的室内定位方法,同样包括离线和在线两个阶段,其中离线阶段主要用于回归学习,而在线阶段主要用于位置预测。大体而言,离线阶段包括输入训练数据、利用改进的基于岭回归的elm算法进行回归学习,以及输出权值等步骤,在线阶段包括根据接收到的测量值,利用机器学习模型进行位置预测,输出位置估计等步骤。
具体而言,本发明包括如下步骤:
s1、离线数据集构建步骤,在定位区域内采集无线信号接收强度数据,建立离线数据训练集。
具体而言,s1所述离线数据集构建步骤,包括:在定位区域的不同位置处采集无线信号接收强度数据,结合所述无线信号接收强度数据及与其相匹配的位置坐标数据,建立信号强度-目标位置指纹库、并将其作为离线数据训练集。
此外,需要说明的是,在本实施例中,所述无线信号为wifi信号。
s2、离线学习步骤,利用岭回归技术和极限学习机技术,学习离线数据训练集中的无线信号接收强度与目标位置之间的关系,训练得到基于位置的递归模型。
接下来对s2所述离线学习步骤,进行具体说明,首先假定所述离线数据训练集为{xi,ti},其中xi∈r1×n,ti∈r1×m,i=1,2,...,n。则s2所述离线学习步骤,具体包括:
s21、随机生成隐层输出矩阵h,
其中,h(xi)是隐层行向量的输出,h(xi)=[h1(x),h2(x),......,hl(x)],h(xi)∈r1×l,h(xi)=h(ωi·xj+bi),
其中,ωi是连接输入层与输出层的权值,bi是第i隐层的阈值,ωi·xj表示ωi和xj的内积。
s22、计算hth的特征值λi和特征向量矩阵φ,
φ=[φ1,φ2,......,φn],
其中,φi为特征值λi对应的特征向量。
s23、计算初始输出权值β0,
计算训练误差ξ和对应的方差σ2,σ2i=cov(ξξt)。
s24、计算岭回归参数k。
s25、计算输出权值β,
β=(hth+ki)-1t,
s26、对于给定迭代次数n,若训练误差ξ小于给定值ε,则结束循环,否则定义h的广义逆
s27、输出权值β=(hth+ki)-1t,得到基于位置的递归模型。
其中,s24所述计算岭回归参数k,又包括如下子步骤:
s241、将t=hβ+ξ写为等价形式t=zα+ξ,
其中,α=φtβ。
s242、计算α,α=(ztz)-1ztt。
s243、计算岭回归参数k,
s3、在线数据获取步骤,在线收集待估计位置处的无线信号接收强度数据并将其代入基于位置的递归模型中,得到位置估计结果。
具体而言,s3所述在线数据获取步骤,包括:
s31、对定位区域内待估计位置处的无线信号接收强度数据进行在线收集、并将其作为待估计位置的无线信号接收强度指纹。
s32、将无线信号接收强度指纹代入基于位置的递归模型中,所述基于位置的递归模型的输出结果即为位置估计结果。
以下结合测试结果对本发明的使用效果进行说明,在发明中,离线数据集构建过程中均使用的是实测数据。用于训练和测试的测量值的容量大小分别为1550和713。假设隐层节点的数量为250。
图2描述了本发明的定位性能。可以看到,本发明在所选函数下都能很好地执行。其中,sigmode函数的性能具有最佳。
图3描述了不同激活函数之间的定位性能比较。我们发现本发明具有比传统的基于elm的方法更好的定位性能。原因如下,岭回归用于离线阶段,本发明可以获得更稳定的预测结果并具有更好的泛化能力。
图4描述了当激活函数为sigmode时,不同隐层节点数之间的定位性能比较。因为隐层节点的数量对训练性能有很大影响,两种方法的隐层节点数越多,则具有更好的定位性能。由于岭回归用于输出权值的计算,本发明具有更好的性能。
综上所述,本发明具有在离线阶段学习稳定性好、在在线阶段定位精度高等优点,可以充分满足实际的使用需求。同时,本发明对于离线训练数据集中异常数据元素的敏感性低,在数据异常情况下的鲁棒性好,具有很强的抗干扰性能,从而进一步确保了本发明定位结果的精确性。
此外,本发明也为同领域内的其他相关问题提供了参考,可以以此为依据进行拓展延伸,运用于同领域内其他定位方法和机器学习系统的技术方案中,具有十分广阔的应用前景。
对于本领域技术人员而言,显然本发明不限于上述示范性实施例的细节,而且在不背离本发明的精神和基本特征的情况下,能够以其他的具体形式实现本发明。因此,无论从哪一点来看,均应将实施例看作是示范性的,而且是非限制性的,本发明的范围由所附权利要求而不是上述说明限定,因此旨在将落在权利要求的等同要件的含义和范围内的所有变化囊括在本发明内,不应将权利要求中的任何附图标记视为限制所涉及的权利要求。
此外,应当理解,虽然本说明书按照实施方式加以描述,但并非每个实施方式仅包含一个独立的技术方案,说明书的这种叙述方式仅仅是为清楚起见,本领域技术人员应当将说明书作为一个整体,各实施例中的技术方案也可以经适当组合,形成本领域技术人员可以理解的其他实施方式。
- 还没有人留言评论。精彩留言会获得点赞!