用于自适应连接与连接优化之间的动态切换中的机器学习方案的技术的制作方法
本申请要求2017年8月30日提交的印度临时专利申请号201741030632和2017年11月10日提交的美国临时专利申请号62/584,401的权益。
背景技术:
在在(例如,数据中心中的)多个计算设备之间分发工作负荷(workload)的系统中,集中式服务器可以组成用来处理工作负荷的计算设备的节点。每一个节点表示由每一个计算设备提供的资源(例如,计算、存储、加速等)的逻辑聚合。例如,节点可以包括配置有硬件加速器的计算设备,诸如现场可编程门阵列(fpga)器件和/或图形处理单元(gpu)。一般地,硬件加速器改进工作负荷功能的执行速度。为了使工作负荷的给定功能(诸如应用的给定功能)加速,集中式服务器可以给加速器设备配置适合于使任务加速的经加速的内核。
一旦完成,加速器设备就将由经加速的功能所产生的数据返回给应用。在一些情况下,系统可以提供内核到内核网络,其允许给定内核向另一内核传输所得数据以进一步处理工作负荷。加速器设备中的内核可以经由一些网络通信协议与另一内核设备建立网络通信,所述一些网络通信协议诸如是tcp/ip(传输控制协议/因特网协议)或者udp(用户数据报协议)。基于系统中的目前资源负荷,使用给定的网络通信协议可以比使用另一协议更加高效。
附图说明
在随附各图中,本文中描述的概念被图示作为示例而非作为限制。为了说明的简单和清楚,在各图中图示的元件不一定按比例绘制。在认为适当的地方,已经在各图之间重复参考标签以指示对应或类似的元件。
图1是用于利用分解的资源来执行工作负荷的数据中心的至少一个实施例的简化图;
图2是图1的数据中心的pod的至少一个实施例的简化图;
图3是可以被包括在图2的pod中的机架(rack)的至少一个实施例的透视图;
图4是图3的机架的侧面正视图;
图5是其中安装有滑板(sled)的图3的机架的透视图;
图6是图5的滑板的正面(topside)的至少一个实施例的简化框图;
图7是图6的滑板的反面(bottomside)的至少一个实施例的简化框图;
图8是在图1的数据中心中可使用的计算滑板的至少一个实施例的简化框图;
图9是图8的计算滑板的至少一个实施例的顶部透视图;
图10是在图1的数据中心中可使用的加速器滑板的至少一个实施例的简化框图;
图11是图10的加速器滑板的至少一个实施例的顶部透视图;
图12是在图1的数据中心中可使用的存储滑板的至少一个实施例的简化框图;
图13是图12的存储滑板的至少一个实施例的顶部透视图;
图14是在图1的数据中心中可使用的存储器滑板的至少一个实施例的简化框图;以及
图15是可以在图1的数据中心内建立以利用由分解的资源组成的受管理节点来执行工作负荷的系统的简化框图;
图16是用于使通信协议适配端点之间的网络通信的系统的至少一个实施例的简化框图;
图17是图16的系统的加速器滑板的至少一个实施例的简化框图;
图18是可以通过图16和17的加速器滑板建立的环境的至少一个实施例的简化框图;
图19a和19b是内核到内核通信网络的示例实施例的图;以及
图20和21是用于使通信协议适配端点之间的网络通信的方法的至少一个实施例的简化流程图。
具体实施方式
虽然本公开的概念容许有各种修改和替代形式,但是已经在附图中作为示例示出并且将在本文中详细地描述其特定实施例。然而,应当理解,不意图将本公开的概念限于所公开的特定形式,而是相反,本发明要涵盖与本公开和所附权利要求一致的所有修改、等同方案和替代方案。
在说明书中对“一个实施例”、“实施例”、“说明性实施例”、等的引用指示所描述的实施例可以包括特定特征、结构或特性,但是每一个实施例可能包括或者可能不一定包括该特定特征、结构或特性。此外,这样的短语不一定是指同一实施例。进一步地,当结合实施例描述特定特征、结构或特性时,主张的是,不管是否明确地描述,结合其它实施例实现这样的特征、结构或特性在本领域技术人员的知识内。附加地,应当领会,被包括在以“a、b和c中的至少一个”的形式的列表中的项目可以意味着(a);(b);(c);(a和b);(a和c);(b和c);或者(a、b和c)。类似地,以“a、b或c中的至少一个”的形式列出的项目可以意味着(a);(b);(c);(a和b);(a和c);(b和c);或者(a、b和c)。
在一些情况下,所公开的实施例可以以硬件、固件、软件或其任何组合来实现。所公开的实施例还可以被实现为由暂时性或非暂时性机器可读(例如,计算机可读)存储介质承载或者存储在其上的指令,所述指令可以由一个或多个处理器读取和执行。机器可读存储介质可以体现为用于存储或传输以由机器可读的形式的信息的任何存储设备、机构或其它物理结构(例如,易失性或非易失性存储器、介质盘或其它介质设备)。
在附图中,可以以特定布置和/或排序示出一些结构或方法特征。然而,应当领会,可以不要求这样的特定布置和/或排序。相反,在一些实施例中,这样的特征可以以与在说明性图中示出方式和/或次序不同的方式和/或次序进行布置。附加地,特定图中的结构或方法特征的包括不打算暗示着在所有的实施例中都要求这样的特征,并且在一些实施例中可以不包括这样的特征或者这样的特征可以与其它特征组合。
现在参考图1,其中分解的资源可以合作地执行一个或多个工作负荷(例如,代表顾客合作地执行应用)的数据中心100包括多个pod110、120、130、140,所述多个pod中的每一个包括一行或多行机架。如在本文中更详细地描述的,每一个机架容纳多个滑板,所述多个滑板中每一个可以体现为诸如服务器之类的计算设备,其主要装备有特定类型的资源(例如,存储器设备、数据存储设备、加速器设备、通用处理器)。在说明性实施例中,每一个pod110、120、130、140中的滑板连接到多个pod交换机(例如,将向和从pod内的滑板路由数据通信的交换机)。pod交换机继而与脊柱交换机150连接,所述脊柱交换机150在数据中心100中的pod(例如,pod110、120、130、140)之间切换通信。在一些实施例中,滑板可以与使用英特尔全方位路径(omni-path)技术的结构连接。如在本文中更加详细地描述的,数据中心100中的滑板内的资源可以被分配给群组(本文中称为“受管理节点”),其包含要在工作负荷的执行中共同地利用的来自一个或多个其它滑板的资源。工作负荷可以好像属于受管理节点的资源位于同一滑板上一样来执行。受管理节点中的资源甚至可以属于归属于不同机架并且甚至归属于不同pod110、120、130、140的滑板。可以将单个滑板的一些资源分配给一个受管理节点,而将同一滑板的其它资源分配给不同的受管理节点(例如,将一个处理器分配给一个受管理节点,并且将同一滑板的另一处理器分配给不同的受管理节点)。通过将资源分解到占主导地位地包括单个类型的资源的滑板(例如,主要包括计算资源的计算滑板、主要包含存储器资源的存储器滑板),以及选择性地分配和解除分配分解的资源以形成被分配来执行工作负荷的受管理节点,数据中心100提供了比起包括包含计算、存储器、存储以及也许附加的资源的超融合服务器的典型数据中心更高效的资源使用。照此,数据中心100可以提供比具有相同数目的资源的典型数据中心较好的性能(例如,吞吐量、每秒的操作数、等待时间等)。
现在参考图2,在说明性实施例中,pod110包括机架240的行200、210、220、230的集合。每一个机架240可以容纳多个滑板(例如,十六个滑板)并且向所容纳的滑板提供电力和数据连接,如在本文中更加详细地描述的。在说明性实施例中,每一行200、210、220、230中的机架连接到多个pod交换机250、260。pod交换机250包括pod110的机架的滑板连接到的一组端口252以及将pod110连接到脊柱交换机150以向数据中心100中的其它pod提供连接性的另一组端口254。类似地,pod交换机260包括pod110的机架的滑板连接到的一组端口262的集合以及将pod110连接到脊柱交换机150的一组端口264。照此,这对交换机250、260的使用向pod110提供了冗余量。例如,如果交换机250、260中的任一个失效,则pod110中的滑板仍然可以通过另一交换机250、260来维持与数据中心100的剩余部分(例如,其它pod的滑板)的数据通信。此外,在说明性实施例中,交换机150、250、260可以体现为双模式光学交换机,其能够经由光纤的光学信令介质来路由承载因特网协议(ip)分组的以太网协议通信和根据第二、高性能链路层协议(例如,英特尔的全方位路径架构的、无限带宽(infiniband))的通信二者。
应当领会,其它pod120、130、140(以及数据中心100的任何附加的pod)中的每一个可以类似地构造为在图2中示出并且关于图2描述的pod110并且具有与pod110类似的组件(例如,每一个pod可以具有多行容纳多个滑板的机架,如上文描述的)。附加地,虽然示出了两个pod交换机250、260,但是应当理解,在其它实施例中,每一个pod110、120、130、140可以连接到不同数目的pod交换机(例如,提供甚至更大的失效备援能力)。
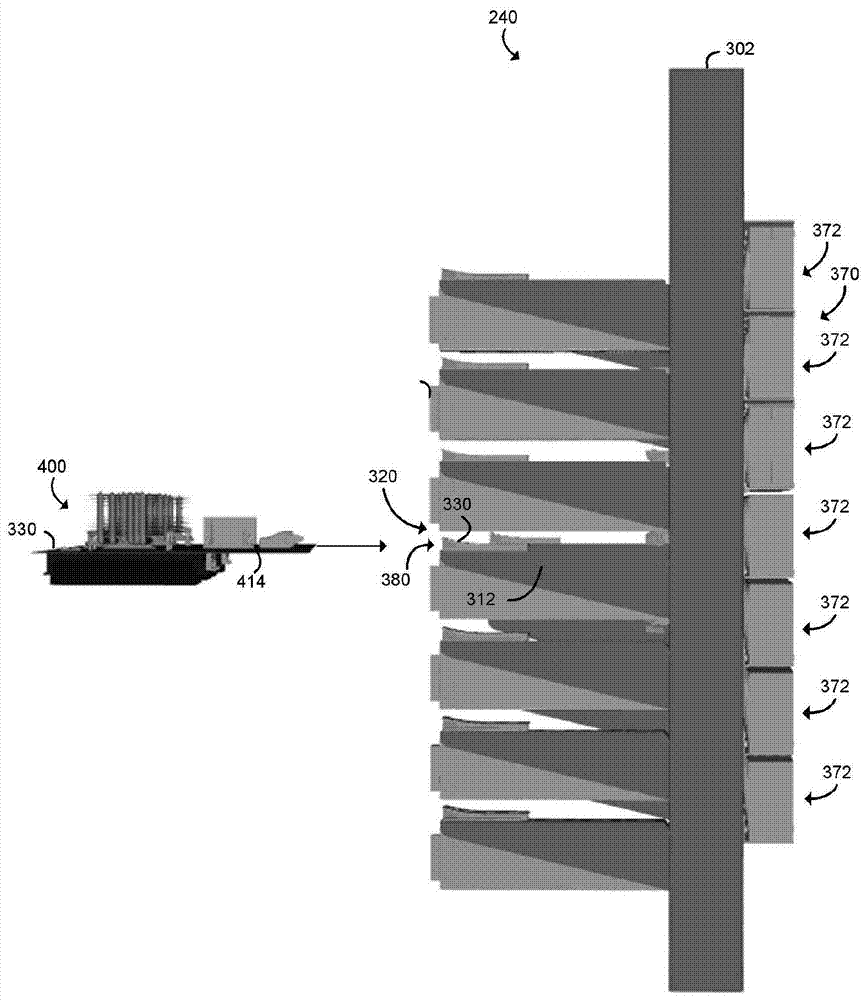
现在参考图3-5,数据中心100的每一个说明性机架240包括垂直布置的两个加长支撑柱302、304。例如,加长支撑柱302、304在被部署时从数据中心100的底部(floor)向上延伸。机架240还包括被配置成支撑数据中心100的滑板的加长支撑臂312的一个或多个水平对310(在图3中经由虚线椭圆标识),如下文描述的。加长支撑臂312的对中的一个加长支撑臂312从加长支撑柱302向外延伸,并且另一加长支撑臂312从加长支撑柱304向外延伸。
在说明性实施例中,数据中心100的每一个滑板体现为无底盘(chassis-less)滑板。也就是说,每一个滑板具有在其上安装物理资源(例如,处理器、存储器、加速器、储存器等)的无底盘电路板基板,如下文更加详细地讨论的。照此,机架240被配置成容纳无底盘滑板。例如,加长支撑臂312的每一对310限定机架240的滑板插槽320,所述滑板插槽320被配置成容纳对应的无底盘滑板。为了这么做,每一个说明性的加长支撑臂312包括被配置成容纳滑板的无底盘电路板基板的电路板导引物(guide)330。每一个电路板导引物330被固定到或者以其它方式安装到对应的加长支撑臂312的正面332。例如,在说明性实施例中,每一个电路板导引物330被安装在对应的加长支撑臂312相对于对应的加长支撑柱302、304的远端处。为了图的清楚,可能没有在每一个图中引用每一个电路板导引物330。
每一个电路板导引物330包括限定电路板插槽380的内壁,所述电路板插槽380被配置成在滑板400被容纳在机架240的对应滑板插槽320中时容纳滑板400的无底盘电路板基板。为了这么做,如图4中所示,用户(或机器人)将说明性无底盘滑板400的无底盘电路板基板对准到滑板插槽320。用户或者机器人然后可以将无底盘电路板基板向前滑动到滑板插槽320中,使得无底盘电路板基板的每一个侧边414被容纳在限定对应的滑板插槽320的加长支撑臂312的对310的电路板导引物330的对应电路板插槽380中,如图4中所示。通过具有包括分解的资源的机器人可访问且机器人可操纵的滑板,每一个类型的资源可以与彼此独立地并且以它们自己优化的刷新速率进行升级。此外,滑板被配置成与每一个机架240中的电力和数据通信线缆盲配,从而增强其被快速地移除、升级、重新安装和/或替换的能力。照此,在一些实施例中,数据中心100可以在没有人类参与的情况下在数据中心底部上操作(例如,执行工作负荷、经历维护和/或升级等)。在其它实施例中,人类可以促进数据中心100中的一个或多个维护或升级操作。
应当领会,每一个电路板导引物330是双面的。也就是说,每一个电路板导引物330包括限定电路板导引物330的每一侧上的电路板插槽380的内壁。以该方式,每一个电路板导引物330可以在任一侧上支撑无底盘电路板基板。照此,可以向机架240添加单个附加的加长支撑柱以使机架240变成可以保持如图3中所示的滑板插槽320的两倍之多的双机架解决方案。说明性机架240包括限定对应的七个滑板插槽320的加长支撑臂312的七对310,所述七个滑板插槽320中的每一个被配置成如上文所讨论那样容纳并且支撑对应滑板400。当然,在其它实施例中,机架240可以包括加长支撑臂312的附加对或者更少对310(即,附加的或者更少的滑板插槽320)。应当领会,因为滑板400是无底盘的,所以滑板400可以具有与典型服务器不同的总体高度。照此,在一些实施例中,每一个滑板插槽320的高度可以短于典型服务器的高度(例如,短于单个机架单元“1u”)。也就是说,加长支撑臂312的每一对310之间的垂直距离可以小于标准机架单元“1u”。附加地,由于滑板插槽320的高度中的相对减小,机架240的总体高度在一些实施例中可以短于传统机架外壳的高度。例如,在一些实施例中,加长支撑柱302、304中的每一个可以具有六英尺或更小的长度。再次,在其它实施例中,机架240可以具有不同的尺寸。进一步地,应当领会,机架240不包括任何壁、外壳等。相反,机架240是向本地环境敞开的无外壳机架。当然,在一些情况下,在其中机架240形成数据中心100中的行末机架的那些情况下,可以将端板附连到加长支撑柱302、304中的一个。
在一些实施例中,各种互连可以被布线(route)成向上或者向下通过加长支撑柱302、304。为了促进这样的布线,每一个加长支撑柱302、304包括限定互连可以位于其中的内腔的内壁。被布线成通过加长支撑柱304、304的互连可以体现为任何类型的互连,包括但不限于向每一个滑板插槽320提供通信连接的数据或者通信互连、向每一个滑板插槽320提供电力的电力互连和/或其它类型的互连。
在说明性实施例中,机架240包括在其上安装(未示出的)对应的光学数据连接器的支撑平台。每一个光学数据连接器与对应滑板插槽320相关联,并且被配置成在滑板400被容纳在对应滑板插槽320中时与对应滑板400的光学数据连接器配合(mate)。在一些实施例中,数据中心100中的组件(例如,滑板、机架和交换机)之间的光学连接利用盲配光学连接来做出。例如,每一个线缆上的门可以防止灰尘污染线缆内的光纤。在连接到盲配光学连接器机构的过程中,当线缆的末端进入连接器机构时,门被推开。随后,线缆内部的光纤进入连接器机构内的凝胶,并且一个线缆的光纤与连接器机构内部的凝胶内的另一线缆的光纤接触。
说明性机架240还包括耦合到机架240的交叉支撑臂的风扇阵列370。风扇阵列370包括在加长支撑柱302、304之间以水平线对准的一行或多行冷却风扇372。在说明性实施例中,风扇阵列370包括用于机架240的每一个滑板插槽320的一行冷却风扇372。如上文所讨论的,在说明性实施例中,每一个滑板400不包括任何板载冷却系统,并且照此,风扇阵列370提供用于容纳在机架240中的每一个滑板400的冷却。在说明性实施例中,每一个机架240还包括与每一个滑板插槽320相关联的电力供应。每一个电力供应被固定到限定对应滑板插槽320的加长支撑臂312的对310中的一个加长支撑臂312。例如,机架240可以包括耦合到或者固定到从加长支撑柱302延伸的每一个加长支撑臂312的电力供应。每一个电力供应包括电力连接器,所述电力连接器被配置成在滑板400被容纳在对应滑板插槽320中时与滑板400的电力连接器配合。在说明性实施例中,滑板400不包括任何板载的电力供应,并且照此,在机架240中提供的电力供应在安装到机架240时向对应滑板400供应电力。
现在参考图6,在说明性实施例中,滑板400被配置成安装在数据中心100的对应机架240中,如上文所讨论的。在一些实施例中,每一个滑板400可以被优化或者以其它方式配置用于执行特定任务,诸如计算任务、加速任务、数据存储任务等。例如,滑板400可以体现为如在下文关于图8-9讨论的计算滑板800、如在下文关于图10-11讨论的加速器滑板1000、如在下文关于图12-13讨论的存储滑板1200,或者体现为被优化或以其它方式配置成执行其它专门的任务的滑板,诸如在下文关于图14讨论的存储器滑板1400。
如上文所讨论的,说明性滑板400包括支撑被安装在其上的各种物理资源(例如,电气组件)的无底盘电路板基板602。应当领会,电路板基板602是“无底盘的”,因为滑板400不包括壳体或外壳。相反,无底盘电路板基板602向本地环境敞开。无底盘电路板基板602可以由能够支撑被安装在其上的各种电气组件的任何材料组成。例如,在说明性实施例中,无底盘电路板基板602由fr-4玻璃增强环氧树脂层压材料组成。当然,在其它实施例中,可以使用其它材料来形成无底盘电路板基板602。
如在下文更加详细地讨论的,无底盘电路板基板602包括改进被安装在无底盘电路板基板602上的各种电气组件的热冷却(heatcooling)特性的多个特征。如所讨论的,无底盘电路板基板602不包括壳体或外壳,这可以通过减少可能抑制空气流动的那些结构而改进滑板400的电气组件之上的气流。例如,因为无底盘电路板基板602未被定位在单独的壳体或外壳中,所以不存在到无底盘电路板基板602的底板(例如,底盘的后板),这可能抑制跨电气组件的空气流动。附加地,无底盘电路板基板602具有被配置成减小跨安装到无底盘电路板基板602的电气组件的气流路径的长度的几何形状。例如,说明性无底盘电路板基板602具有比无底盘电路板基板602的深度606大的宽度604。在一个特定实施例中,例如,与具有大约17英寸的宽度和大约39英寸的深度的典型服务器相比,无底盘电路板基板602具有大约21英寸的宽度和大约9英寸的深度。照此,从无底盘电路板基板602的前边610朝向后边612延伸的气流路径608具有相对于典型服务器较短的距离,这可以改进滑板400的热冷却特性。此外,虽然没有在图6中图示,但是安装到无底盘电路板基板602的各种物理资源被安装在对应位置中,使得两个实质上产生热量的电气组件不彼此遮蔽,如在下文更加详细地讨论的。也就是说,在操作期间产生相当可观的热量(即,大于充分足以不利地影响另一电气组件的冷却的标称热量)的两个电气组件不被沿着气流路径608的方向(即,沿着从无底盘电路板基板602的前边610朝向后边612延伸的方向)与彼此一致成直线地安装到无底盘电路板基板602。
如上文所讨论的,说明性滑板400包括被安装到无底盘电路板基板602的正面650的一个或多个物理资源620。虽然在图6中示出了两个物理资源620,但是应当领会,在其它实施例中滑板400可以包括一个、两个或更多个物理资源620。取决于例如滑板400的类型或预期功能性,物理资源620可以体现为能够执行各种任务(诸如计算功能)和/或控制滑板400的功能的任何类型的处理器、控制器或其它计算电路。例如,如在下文更加详细地讨论的,物理资源620可以在其中滑板400体现为计算滑板的实施例中体现为高性能处理器,在其中滑板400体现为加速器滑板的实施例中体现为加速器协处理器或电路,在其中滑板400体现为存储滑板的实施例中体现为存储控制器,或者在其中滑板400体现为存储器滑板的实施例中体现为一组存储器设备。
滑板400还包括被安装到无底盘电路板基板602的正面650的一个或多个附加物理资源630。在说明性实施例中,附加物理资源包括如在下文更加详细地讨论的网络接口控制器(nic)。当然,取决于滑板400的类型和功能性,在其它实施例中物理资源630可以包括附加的或者其它的电气组件、电路和/或设备。
物理资源620经由输入/输出(i/o)子系统622通信地耦合到物理资源630。i/o子系统622可以体现为用来利用物理资源620、物理资源630和/或滑板400的其它组件促进输入/输出操作的电路和/或组件。例如,i/o子系统622可以体现为或者以其它方式包括存储器控制器中枢、输入/输出控制中枢、集成传感器中枢、固件设备、通信链路(例如,点对点链路、总线链路、导线、线缆、光导、印刷电路板迹线等)和/或用来促进输入/输出操作的其它组件和子系统。在说明性实施例中,i/o子系统622体现为或者以其它方式包括双数据速率4(ddr4)数据总线或ddr5数据总线。
在一些实施例中,滑板400还可以包括资源到资源互连624。资源到资源互连624可以体现为能够促进资源到资源通信的任何类型的通信互连。在说明性实施例中,资源到资源互连624体现为高速点对点互连(例如,比i/o子系统622更快)。例如,资源到资源互连624可以体现为快速路径互连(qpi)、超级路径互连(upi)或者专用于资源到资源通信的其它高速点对点互连。
滑板400还包括电力连接器640,所述电力连接器640被配置成在滑板400被安装在对应机架240中时与机架240的对应电力连接器配合。滑板400经由电力连接器640从机架240的电力供应接收电力以向滑板400的各种电气组件供应电力。也就是说,滑板400不包括用来向滑板400的电气组件提供电力的任何本地电力供应(即,板载电力供应)。本地或板载电力供应的排除促进无底盘电路板基板602的总体占用空间中的减少,这可以增加如上文所讨论的被安装在无底盘电路板基板602上的各种电气组件的热冷却特性。在一些实施例中,通过直接在处理器820下方的通孔(例如,通过无底盘电路板基板602的反面750)向处理器820提供电力,从而提供增加的热预算、附加的电流和/或电压以及比起典型板更好的电压控制。
在一些实施例中,滑板400还可以包括安装特征642,其被配置成与机器人的安装臂或其它结构配合以促进通过机器人在机架240中对滑板600的放置。安装特征642可以体现为允许机器人抓住滑板400而不毁坏无底盘电路板基板602或安装到其的电气组件的任何类型的物理结构。例如,在一些实施例中,安装特征642可以体现为附连到无底盘电路板基板602的非传导焊盘。在其它实施例中,安装特征可以体现为附连到无底盘电路板基板602的支架、支柱或其它类似结构。安装特征642的特定数目、形状、大小和/或组成可以取决于被配置成管理滑板400的机器人的设计。
现在参考图7,除被安装在无底盘电路板基板602的正面650上的物理资源630之外,滑板400还包括被安装到无底盘电路板基板602的反面750的一个或多个存储器设备720。也就是说,无底盘电路板基板602体现为双面电路板。物理资源620经由i/o子系统622通信地耦合到存储器设备720。例如,物理资源620和存储器设备720可以经由贯穿无底盘电路板基板602的一个或多个通孔而通信地耦合。在一些实施例中每一个物理资源620可以通信地耦合到一个或多个存储器设备720的不同集合。替代地,在其它实施例中,每一个物理资源620可以通信地耦合到每一个存储器设备720。
存储器设备720可以体现为能够在滑板400的操作期间存储用于物理资源620的数据的任何类型的存储器设备,诸如任何类型的易失性存储器(例如,动态随机存取存储器(dram)等)或者非易失性存储器。易失性存储器可以是要求电力来维持由介质存储的数据的状态的存储介质。易失性存储器的非限制性示例可以包括各种类型的随机存取存储器(ram),诸如动态随机存取存储器(dram)或静态随机存取存储器(sram)。可以在存储器模块中使用的一个特定类型的dram是同步动态随机存取存储器(sdram)。在特定实施例中,存储器组件的dram可以遵从由jedec颁布的标准,诸如用于ddrsdram的jesd79f、用于ddr2sdram的jesd79-2f、用于ddr3sdram的jesd79-3f、用于ddr4sdram的jesd79-4a、用于低功率ddr(lpddr)的jesd209、用于lpddr2的jesd209-2、用于lpddr3的jesd209-3以及用于lpddr4的jesd209-4(这些标准在www.jedec.org处可获得)。这样的标准(以及类似的标准)可以被称为基于ddr的标准,并且实现这样的标准的存储设备的通信接口可以被称为基于ddr的接口。
在一个实施例中,存储器设备是块可寻址存储器设备,诸如基于nand或nor技术的那些。存储器设备还可以包括下一代非易失性设备,诸如英特尔3dxpointtm存储器或其它类型的可寻址的在适当的位置写入(write-in-place)非易失性存储器设备。在一个实施例中,存储器设备可以是或者可以包括使用硫属化物玻璃的存储器设备,多阈值水平nand闪速存储器,nor闪速存储器,单或多级相变存储器(pcm),电阻存储器,纳米线存储器,铁电晶体管随机存取存储器(fetram),反铁电存储器,合并忆阻器技术的磁阻随机存取存储器(mram)存储器,包括金属氧化物基底、氧空位基底和传导桥随机存取存储器(cb-ram)的电阻存储器,或者自旋转移扭矩(stt)-mram,基于自旋电子磁结存储器的设备,基于磁隧道结(mtj)的设备,基于dw(畴壁)和sot(自旋轨道转移)的设备,基于半导体闸流管的存储器设备,或上文中的任何存储器设备的组合,或者其它存储器。存储器设备可以是指管芯本身和/或经封装的存储器产品。在一些实施例中,存储器设备可以包括无晶体管的可堆叠交叉点架构,其中存储器单元位于字线和位线的交叉处且可被单独地寻址并且其中位存储基于体电阻中的改变。
现在参考图8,在一些实施例中,滑板400可以体现为计算滑板800。计算滑板800被优化或者以其它方式配置成执行计算任务。当然,如上文所讨论的,计算滑板800可以依靠其它滑板,诸如加速滑板和/或存储滑板,来执行这样的计算任务。计算滑板800包括与滑板400的物理资源类似的各种物理资源(例如,电气组件),其已经被在图8中使用相同的参考号码来标识。上文关于图6和7提供的对这样的组件的描述适用于计算滑板800的对应组件,并且为了计算滑板800的描述的清楚而不在本文中进行重复。
在说明性计算滑板800中,物理资源620体现为处理器820。虽然在图8中仅示出了两个处理器820,但是应当领会,在其它实施例中计算滑板800可以包括附加的处理器820。说明性地,处理器820体现为高性能处理器820,并且可以被配置成在相对高的额定功率下操作。虽然在比典型处理器(其在大约155-230w下操作)大的额定功率下操作的处理器820生成附加的热量,但是上文讨论的无底盘电路板基板602的增强的热冷却特性促进更高功率的操作。例如,在说明性实施例中,处理器820被配置成在至少250w的额定功率下操作。在一些实施例中,处理器820可以被配置成在至少350w的额定功率下操作。
在一些实施例中,计算滑板800还可以包括处理器到处理器互连842。类似于上文讨论的滑板400的资源到资源互连624,处理器到处理器互连842可以体现为能够促进处理器到处理器互连842通信的任何类型的通信互连。在说明性实施例中,处理器到处理器互连842体现为高速点对点互连(例如,比i/o子系统622快)。例如,处理器到处理器互连842可以体现为快速路径互连(qpi)、超级路径互连(upi)或者专用于处理器到处理器通信的其它高速点对点互连。
计算滑板800还包括通信电路830。说明性通信电路830包括网络接口控制器(nic)832,其还可以被称为主机结构接口(hfi)。nic832可以体现为或者以其它方式包括任何类型的集成电路、分立电路、控制器芯片、芯片组、内插板、子卡、网络接口卡、可以由计算滑板800使用以与另一计算设备(例如,与其它滑板400)连接的其它设备。在一些实施例中,nic832可以体现为包括一个或多个处理器的片上系统(soc)的部分,或者被包括在也包含一个或多个处理器的多芯片封装上。在一些实施例中,nic832可以包括(未示出的)本地处理器和/或(未示出的)本地存储器,其二者对nic832而言都是本地的。在这样的实施例中,nic832的本地处理器可以能够执行处理器820的功能中的一个或多个。附加地或者替代地,在这样的实施例中,nic832的本地存储器可以在板级别、插座(socket)级别、芯片级别和/或其它级别处集成到计算滑板的一个或多个组件中。
通信电路830通信地耦合到光学数据连接器834。光学数据连接器834被配置成在计算滑板800被安装在机架240中时与机架240的对应光学数据连接器配合。说明性地,光学数据连接器834包括从光学数据连接器834的配合表面引向光学收发器836的多个光纤。光学收发器836被配置成将来自机架侧光学数据连接器的传入光学信号转换成电气信号并且将电气信号转换成到机架侧光学数据连接器的传出光学信号。虽然在说明性实施例中示出为形成光学数据连接器834的部分,但是在其它实施例中光学收发器836可以形成通信电路830的部分。
在一些实施例中,计算滑板800还可以包括扩展连接器840。在这样的实施例中,扩展连接器840被配置成与扩展无底盘电路板基板的对应连接器配合以向计算滑板800提供附加物理资源。附加物理资源可以例如由处理器820在计算滑板800的操作期间使用。扩展无底盘电路板基板可以基本上类似于上文讨论的无底盘电路板基板602并且可以包括被安装到其的各种电气组件。安装到扩展无底盘电路板基板的特定电气组件可以取决于扩展无底盘电路板基板的预期功能性。例如,扩展无底盘电路板基板可以提供附加的计算资源、存储器资源和/或存储资源。照此,扩展无底盘电路板基板的附加物理资源可以包括但不限于处理器、存储器设备、存储设备和/或加速器电路,其包括例如现场可编程门阵列(fpga)、专用集成电路(asic)、安全协处理器、图形处理单元(gpu)、机器学习电路或者其它专门的处理器、控制器、设备和/或电路。
现在参考图9,示出了计算滑板800的说明性实施例。如所示,处理器820、通信电路830和光学数据连接器834被安装到无底盘电路板基板602的正面650。可以使用任何适合的附连或安装技术将计算滑板800的物理资源安装到无底盘电路板基板602。例如,各种物理资源可以被安装在对应的插座(例如,处理器插座)、支持物或支架中。在一些情况下,电气组件中的一些可以经由焊接或类似技术直接地安装到无底盘电路板基板602。
如上文所讨论的,单独的处理器820和通信电路830被安装到无底盘电路板基板602的正面650,使得两个产生热量的电气组件不遮蔽彼此。在说明性实施例中,处理器820和通信电路830被安装在无底盘电路板基板602的正面650上的对应位置中,使得那些物理资源中的两个不沿着气流路径608的方向与其它物理资源成直线地一致。应当领会,虽然光学数据连接器834与通信电路830一致,但是光学数据连接器834在操作期间不产生热量或者产生标称热量。
计算滑板800的存储器设备720被安装到如上文关于滑板400讨论的无底盘电路板基板602的反面750。虽然被安装到反面750,但是存储器设备720经由i/o子系统622通信地耦合到位于正面650上的处理器820。因为无底盘电路板基板602体现为双面电路板,所以存储器设备720和处理器820可以经由贯穿无底盘电路板基板602的一个或多个通孔、连接器或其它机构而通信地耦合。当然,在一些实施例中每一个处理器820可以通信地耦合到一个或多个存储器设备720的不同集合。替代地,在其它实施例中,每一个处理器820可以通信地耦合到每一个存储器设备720。在一些实施例中,存储器设备720可以被安装到无底盘电路板基板602的反面上的一个或多个存储器夹层,并且可以通过球栅阵列与对应处理器820互连。
处理器820中的每一个包括被固定到其的散热器850。由于存储器设备720向无底盘电路板基板602的反面750的安装(以及对应机架240中的滑板400的垂直间距),无底盘电路板基板602的正面650包括附加的“自由”区域或空间,其促进对具有相对于在典型服务器中使用的传统散热器更大的大小的散热器850的使用。附加地,由于无底盘电路板基板602的改进的热冷却特性,处理器散热器850都不包括附连到其的冷却风扇。也就是说,散热器850中的每一个体现为无风扇散热器。
现在参考图10,在一些实施例中,滑板400可以体现为加速器滑板1000。加速器滑板1000被优化或者以其它方式配置成执行专门的计算任务,诸如机器学习、加密、散列或者其它计算密集型任务。在一些实施例中,例如,计算滑板800可以在操作期间将任务卸载到加速器滑板1000。加速器滑板1000包括与滑板400和/或计算滑板800的组件类似的各种组件,其已经被在图10中使用相同的参考号码来标识。上文关于图6、7和8提供的对这样的组件的描述适用于加速器滑板1000的对应组件,并且为了加速器滑板1000的描述的清楚而不在本文中进行重复。
在说明性加速器滑板1000中,物理资源620体现为加速器电路1020。虽然在图10中仅示出了两个加速器电路1020,但是应当领会,在其它实施例中加速器滑板1000可以包括附加的加速器电路1020。例如,如图11中所示,在一些实施例中加速器滑板1000可以包括四个加速器电路1020。加速器电路1020可以体现为任何类型的处理器、协处理器、计算电路或者能够执行计算或处理操作的其它设备。例如,加速器电路1020可以体现为例如现场可编程门阵列(fpga)、专用集成电路(asic)、安全协处理器、图形处理单元(gpu)、机器学习电路或者其它专门的处理器、控制器、设备和/或电路。
在一些实施例中,加速器滑板1000还可以包括加速器到加速器互连1042。类似于上文讨论的滑板600的资源到资源互连624,加速器到加速器互连1042可以体现为能够促进加速器到加速器通信的任何类型的通信互连。在说明性实施例中,加速器到加速器互连1042体现为高速点对点互连(例如,比i/o子系统622快)。例如,加速器到加速器互连1042可以体现为快速路径互连(qpi)、超级路径互连(upi)或者专用于处理器到处理器通信的其它高速点对点互连。在一些实施例中,加速器电路1020可以与主要加速器电路1020和辅助加速器电路1020进行菊花链接,所述主要加速器电路1020通过i/o子系统622连接到nic832和存储器720,所述辅助加速器电路1020通过主要加速器电路1020连接到nic832和存储器720。
现在参考图11,示出了加速器滑板1000的说明性实施例。如上文所讨论的,加速器电路1020、通信电路830和光学数据连接器834被安装到无底盘电路板基板602的正面650。再次,单独的加速器电路1020和通信电路830被安装到无底盘电路板基板602的正面650,使得两个产生热量的电气组件不遮蔽彼此,如上文所讨论的。加速器滑板1000的存储器设备720被安装到无底盘电路板基板602的反面750,如上文关于滑板600所讨论的。虽然被安装到反面750,但是存储器设备720经由i/o子系统622(例如,通过通孔)通信地耦合到位于正面650上的加速器电路1020。进一步地,加速器电路1020中的每一个可以包括比在服务器中使用的传统散热器更大的散热器1070。如上文参考散热器870所讨论的,散热器1070可以大于传统散热器,由于由位于无底盘电路板基板602的反面750上而不是正面650上的存储器设备720提供的“自由”区域。
现在参考图12,在一些实施例中,滑板400可以体现为存储滑板1200。存储滑板1200被优化或者以其它方式配置成在对存储滑板1200而言本地的数据储存器1250中存储数据。例如,在操作期间,计算滑板800或者加速器滑板1000可以存储和检索来自存储滑板1200的数据储存器1250的数据。存储滑板1200包括与滑板400和/或计算滑板800的组件类似的各种组件,其已经被在图12中使用相同的参考号码来标识。上文关于图6、7和8提供的对这样的组件的描述适用于存储滑板1200的对应组件,并且为了存储滑板1200的描述的清楚而不在本文中进行重复。
在说明性存储滑板1200中,物理资源620体现为存储控制器1220。虽然在图12中仅示出两个存储控制器1220,但是应当领会,在其它实施例中存储滑板1200可以包括附加的存储控制器1220。存储控制器1220可以体现为能够基于经由通信电路830接收的请求而控制向数据储存器1250中存储和检索数据的任何类型的处理器、控制器或控制电路。在说明性实施例中,存储控制器1220体现为相对低功率的处理器或控制器。例如,在一些实施例中,存储控制器1220可以被配置成在大约75瓦特的额定功率下操作。
在一些实施例中,存储滑板1200还可以包括控制器到控制器互连1242。类似于上文讨论的滑板400的资源到资源互连624,控制器到控制器互连1242可以体现为能够促进控制器到控制器通信的任何类型的通信互连。在说明性实施例中,控制器到控制器互连1242体现为高速点对点互连(例如,比i/o子系统622更快)。例如,控制器到控制器互连1242可以体现为快速路径互连(qpi)、超级路径互连(upi)或者专用于处理器到处理器通信的其它高速点对点互连。
现在参考图13,示出了存储滑板1200的说明性实施例。在说明性实施例中,数据储存器1250体现为或者以其它方式包括被配置成容纳一个或多个固态驱动器(ssd)1254的存储笼1252。为了这么做,存储笼1252包括数个安装插槽1256,所述数个安装插槽1256中的每一个被配置成容纳对应的固态驱动器1254。安装插槽1256中的每一个包括进行合作来限定对应安装插槽1256的访问开口1260的数个驱动器导引物1258。存储笼1252被固定到无底盘电路板基板602使得访问开口背对着无底盘电路板基板602(即,朝向其前面)。照此,当存储滑板1200被安装在对应机架204中时,固态驱动器1254是可访问的。例如,在存储滑板1200保持安装在对应机架240中时,可以(例如,经由机器人)从机架240换出固态驱动器1254。
存储笼1252说明性地包括十六个安装插槽1256并且能够安装和存储十六个固态驱动器1254。当然,在其它实施例中存储笼1252可以被配置成存储附加的或者更少的固态驱动器1254。附加地,在说明性实施例中,固态驱动器被垂直地安装在存储笼1252中,但是在其它实施例中可以以不同的定向安装在存储笼1252中。每一个固态驱动器1254可以体现为能够存储长期数据的任何类型的数据存储设备。为了这么做,固态驱动器1254可以包括上文讨论的易失性和非易失性存储器设备。
如图13中所示,存储控制器1220、通信电路830和光学数据连接器834被说明性地安装到无底盘电路板基板602的正面650。再次,如上文所讨论的,可以使用任何适合的附连或安装技术将存储滑板1200的电气组件安装到无底盘电路板基板602,其包括例如插座(例如,处理器插座)、支持物、支架、经焊接的连接和/或其它安装或被固定技术。
如上文所讨论的,单独的存储控制器1220和通信电路830被安装到无底盘电路板基板602的正面650,使得两个产生热量的电气组件不遮蔽彼此。例如,存储控制器1220和通信电路830被安装在无底盘电路板基板602的正面650上的对应位置中,使得那些电气组件中的两个不沿着气流路径608的方向与其它成直线地一致。
存储滑板1200的存储器设备720被安装到无底盘电路板基板602的反面750,如上文关于滑板400所讨论的。虽然被安装到反面750,但是存储器设备720经由i/o子系统622通信地耦合到位于正面650上的存储控制器1220。再次,因为无底盘电路板基板602体现为双面电路板,所以存储器设备720和存储控制器1220可以经由贯穿无底盘电路板基板602的一个或多个通孔、连接器或其它机构而通信地耦合。存储控制器1220中的每一个包括被固定到其的散热器1270。如上文所讨论的,由于存储滑板1200的无底盘电路板基板602的改进的热冷却特性,散热器1270都不包括附连到其的冷却风扇。也就是说,散热器1270中的每一个体现为无风扇散热器。
现在参考图14,在一些实施例中,滑板400可以体现为存储器滑板1400。存储器滑板1400被优化或者以其它方式配置成给其它滑板400(例如,计算滑板800、加速器滑板1000等)提供对对于存储器滑板1200而言本地的(例如,在存储器设备720的两个或更多集合1430、1432中的)存储器池的访问。例如,在操作期间,计算滑板800或加速器滑板1000可以使用逻辑地址空间远程地向存储器滑板1200的存储器集合1430、1432中的一个或多个写入和/或从其读取,所述逻辑地址空间映射至存储器集合1430、1432中的物理地址。存储器滑板1400包括与滑板400和/或计算滑板800的组件类似的各种组件,其已经被在图14中使用相同的参考号码来标识。上文关于图6、7和8提供的对这样的组件的描述适用于存储器滑板1400的对应组件,并且为了存储器滑板1400的描述的清楚而不在本文中进行重复。
在说明性存储器滑板1400中,物理资源620体现为存储器控制器1420。虽然在图14中仅示出了两个存储器控制器1420,但是应当领会,在其它实施例中存储器滑板1400可以包括附加的存储器控制器1420。存储器控制器1420可以体现为能够基于经由通信电路830接收的请求而控制向存储器集合1430、1432中写入和读取数据的任何类型的处理器、控制器或控制电路。在说明性实施例中,每一个存储控制器1220连接到对应的存储器集合1430、1432以向对应的存储器集合1430、1432内的存储器设备720写入以及从其读取,并且实施与已经向存储器滑板1400发送执行存储器访问操作(例如,读取或写入)的请求的滑板400相关联的任何准许(例如,读取、写入等)。
在一些实施例中,存储器滑板1400还可以包括控制器到控制器互连1442。类似于上文讨论的滑板400的资源到资源互连624,控制器到控制器互连1442可以体现为能够促进控制器到控制器通信的任何类型的通信互连。在说明性实施例中,控制器到控制器互连1442体现为高速点对点互连(例如,比i/o子系统622更快)。例如,控制器到控制器互连1442可以体现为快速路径互连(qpi)、超级路径互连(upi)或者专用于处理器到处理器通信的其它高速点对点互连。照此,在一些实施例中,存储器控制器1420可以通过控制器到控制器互连1442访问在与另一存储器控制器1420相关联的存储器集合1432内的存储器。在一些实施例中,可扩展的存储器控制器由存储器滑板(例如,存储器滑板1400)上的在本文中称为“小芯片(chiplet)”的多个较小的存储器控制器组成。小芯片可以(例如,使用emib(嵌入式多管芯互连桥))互连。组合的小芯片存储器控制器可以扩展直到相对大数目的存储器控制器和i/o端口(例如,多达16个存储器信道)。在一些实施例中,存储器控制器1420可以实现存储器交错(例如,将一个存储器地址映射至存储器集合1430,将下一个存储器地址映射至存储器集合1432,并且将第三个地址映射至存储器集合1430等)。交错可以在存储器控制器1420内进行管理,或者从(例如,计算滑板800的)cpu插座跨网络链路到存储器集合1430、1432进行管理,并且与从同一存储器设备访问邻近的存储器地址相比,可以改进与执行存储器访问操作相关联的等待时间。
进一步地,在一些实施例中,存储器滑板1400可以通过波导、使用波导连接器1480连接到(例如,在同一机架240或者相邻的机架240中的)一个或多个其它滑板400。在说明性实施例中,波导是提供16个rx(即,接收)通道和16个rt(即,传输)通道的64毫米波导。在说明性实施例中,每一个通道是16ghz或者32ghz。在其它实施例中,频率可以不同。使用波导可以向另一滑板(例如,在与存储器滑板1400相同的机架240或者相邻的机架240中的滑板400)提供对存储器池(即,存储器集合1430、1432)的高吞吐量访问,而没有在光学数据连接器834上增加负荷。
现在参考图15,用于执行一个或多个工作负荷(例如,应用)的系统可以依照数据中心100来实现。在说明性实施例中,系统1510包括编排器(orchestrator)服务器1520,所述编排器服务器1520可以体现为包括执行管理软件(例如,云操作环境,诸如openstack)的计算设备(例如,计算滑板800)的受管理节点,其通信地耦合到包括大量计算滑板1530(例如,每一个类似于计算滑板800)、存储器滑板1540(例如,每一个类似于存储器滑板1400)、加速器滑板1550(例如,每一个类似于存储器滑板1000)和存储滑板1560(例如,每一个类似于存储滑板1200)的多个滑板400。滑板1530、1540、1550、1560中的一个或多个可以被(诸如通过编排器服务器1520)分组到受管理节点1570中,以共同地执行工作负荷(例如,在虚拟机中或者在容器中执行的应用1532)。受管理节点1570可以体现为来自相同或不同滑板400的诸如处理器820、存储器资源720、加速器电路1020或者数据储存器1250之类的物理资源620的组装件。进一步地,受管理节点可以由编排器服务器1520在工作负荷要被分配给受管理节点时或者在任何其它时间来建立、限定或“起转(spinup)”,并且不管目前是否将任何工作负荷分配给受管理节点,都可以存在。在说明性实施例中,根据与用于工作负荷(例如,应用1532)的服务级别协议相关联的服务质量(qos)目标(例如,与吞吐量、等待时间、每秒的指令数等相关联的性能目标),编排器服务器1520可以选择性地分配和/或解除分配来自滑板400的物理资源620和/或添加或移除来自受管理节点1570的一个或多个滑板400。在这么做时,编排器服务器1520可以接收指示受管理节点1570的每一个滑板400中的性能状况(例如,吞吐量、等待时间、每秒的指令数等)的遥测数据,并且将遥测数据与服务质量目标相比较以确定服务质量目标是否被满足。如果是这样的话,则编排器服务器1520可以附加地确定是否可以在仍然满足qos目标时从受管理节点1570解除分配一个或多个物理资源,从而释放那些物理资源以用于在另一受管理节点中使用(例如,以执行不同的工作负荷)。替代地,如果目前没有满足qos目标,则编排器服务器1520可以决定动态地分配附加的物理资源以在工作负荷(例如,应用1532)正在执行时帮助执行工作负荷。
附加地,在一些实施例中,诸如通过标识工作负荷(例如,应用1532)的执行阶段(例如,其中执行不同操作的时间段,每一个操作具有不同的资源利用特性)以及抢先标识数据中心100中的可用资源并且(例如,在相关联的阶段开始的预定义的时间段内)将它们分配给受管理节点1570,编排器服务器1520可以标识工作负荷(例如,应用1532)的资源利用方面的趋势。在一些实施例中,编排器服务器1520可以基于各种等待时间和分发方案对性能进行建模,以在数据中心100中的计算滑板和其它资源(例如,加速器滑板、存储器滑板、存储滑板)之间放置工作负荷。例如,编排器服务器1520可以利用计及滑板400上的资源的性能(例如,fpga性能、存储器访问等待时间等)以及通过网络到资源(fpga)的路径的性能(例如,拥塞、等待时间、带宽)的模型。照此,编排器服务器1520可以基于与数据中心100中可用的每一个潜在资源相关联的总等待时间(例如,除了与在执行工作负荷的计算滑板与资源位于其上的滑板400之间的通过网络的路径相关联的等待时间之外,与资源本身的性能相关联的等待时间)来确定哪个(哪些)资源应当关于哪些工作负荷进行使用。
在一些实施例中,编排器服务器1520可以使用从滑板400报告的遥测数据(例如,温度、风扇速度等)来生成数据中心100中的热量生成图,并且根据热量生成图以及所预测的与不同工作负荷相关联的热量生成向受管理节点分配资源,以维持数据中心100中的目标温度和热量分布。附加地或者替代地,在一些实施例中,编排器服务器1520可以将所接收的遥测数据组织到分层模型中,所述分层模型指示受管理节点之间的关系(例如,空间关系,诸如数据中心100内的受管理节点的资源的物理位置,和/或功能关系,诸如通过受管理节点为其提供服务的顾客对受管理节点的分组、受管理节点通常执行的功能的类型、通常在彼此之间共享或交换工作负荷的受管理节点等)。基于受管理节点中的物理位置和资源方面的差异,给定的工作负荷可以跨不同的受管理节点的资源展现不同的资源利用(例如,引起不同的内部温度、使用处理器或存储器容量的不同百分比)。编排器服务器1520可以基于存储在分层模型中的遥测数据来确定所述差异,并且如果从一个受管理节点向另一受管理节点重新分配工作负荷,则将所述差异因素包括到对工作负荷的未来资源利用的预测中,以在数据中心100中准确地均衡资源利用。
为了减少编排器服务器1520上的计算负荷和网络上的数据转移负荷,在一些实施例中,编排器服务器1520可以将自测试信息发送给滑板400以使得每一个滑板400能够在本地(例如,在滑板400上)确定由滑板400生成的遥测数据是否满足一个或多个条件(例如,满足预定义的阈值的可用容量、满足预定义的阈值的温度等)。每一个滑板400然后可以将简化结果(例如,是或否)向后报告给编排器服务器1520,编排器服务器1520可以在确定资源到受管理节点的分配时利用所述简化结果。
现在参考图16,用于使通信协议动态地适配端点之间的网络通信的系统1610可以依照上文参考图1描述的数据中心100来实现。在示例实施例中,系统1610包括与多个滑板通信地耦合的编排器服务器1620,所述多个滑板包括计算滑板1630以及加速器滑板1640、1650和1660。
诸如通过编排器服务器1620,可以将计算滑板1630以及加速器滑板1640、1650和1660或者其部分分组到受管理节点中。受管理节点可以共同地执行工作负荷,诸如应用(例如,应用1634)。受管理节点可以体现为来自相同或不同滑板或机架的资源(例如,物理资源)的组装件,所述资源诸如是计算资源、存储器资源、存储资源或者其它资源。照此,应当领会,滑板可以包括多个资源,并且每一个资源可以专用于不同的受管理节点。进一步地,受管理节点可以由编排器服务器1620在工作负荷要被分配给受管理节点时或者在任何其它时间建立、限定或“起转”,并且不管目前是否将任何工作负荷分配给受管理节点,都可以存在。系统1610可以位于数据中心中,并且向通过网络1612与系统1610通信的客户端设备1614提供存储和计算服务(例如,云服务)。编排器服务器1620可以支持云操作环境,诸如openstack,并且由编排器服务器1620建立的受管理节点可以代表客户端设备1614的用户诸如在虚拟机或者容器中执行一个或多个应用或过程(即,工作负荷)。
说明性地,计算滑板1630包括执行工作负荷(例如,应用1634)的一个或多个中央处理单元(cpu)1632(例如,处理器或能够执行一系列操作的其它设备或电路)。加速器滑板1640包括加速器设备1642,加速器滑板1650包括加速器设备1652,并且加速器滑板1660包括加速器设备1662。加速器设备1642、1652或1662中的每一个可以体现为可用于使一个或多个操作的执行加速的任何设备或电路。例如,本文中描述的加速器设备可以体现为能够使诸如工作负荷任务(例如,工作负荷内的一组操作)之类的工作负荷的部分的执行加速的任何设备或电路(例如,专门的处理器、现场可编程门阵列(fpga)、专用集成电路(asic)、图形处理单元(gpu)、可再配置的硬件等)。进一步地,加速器设备中的每一个配置有经加速的内核。说明性地,加速器设备1642包括内核1644,加速器设备1652包括内核1654,并且加速器设备1662包括内核1664。经加速的内核中的每一个可以体现为一组代码或对应加速器设备的部分的配置,其使相应加速器设备执行一个或多个经加速的功能(例如,加密操作、压缩操作等)。
加速器滑板1640、1650和1660中的每一个将经加速的功能提供为针对由受管理节点处理的工作负荷的服务。特别地,每一个加速器滑板1640、1650和1660可以处理来自受管理节点内的其它滑板(例如,计算滑板1630)的使功能加速的请求。例如,图16描绘了执行应用1634的计算滑板1630。应用1634可以包括要顺次执行的功能。计算滑板1630可以向加速器滑板发送使每一个功能的执行加速的请求,从而将功能的执行卸载到驻留于加速器滑板上的加速器设备。加速器滑板可以响应于该请求而在加速器设备上提供内核。例如,加速器滑板可以将指示内核的位流加载到加速器设备的插槽(例如,电路或其它逻辑单元的子集)中。应用1634可以包括可以被加速的多种功能,诸如加密操作、机器学习算法等。在加速器设备上提供的内核可以适于使对应功能的执行加速。例如,假设底层功能牵涉矩阵乘法。关于加速器设备提供的内核可以特定于处理矩阵乘法运算。一旦内核完成功能的加速,内核就可以将所得数据返回给计算滑板1630。编排器服务器1620可以(例如,经由数据库)跟踪将哪些内核登记到哪些加速器滑板以及哪些加速器设备。
此外,系统1610可以暴露内核到内核通信网络,所述内核到内核通信网络允许内核1644、1654和1664中的任何内核与彼此通信,例如在将经处理的工作负荷数据向下游发送到处理工作负荷中的随后任务的内核时与彼此通信。内核可以经由给定的网络通信协议建立网络连接,所述网络通信协议诸如tcp/ip(传输控制协议/因特网协议)或者udp(用户数据报协议)。内核可以将工作负荷数据封装在一个或多个分组(udp中的数据报)中并且使用通信协议将分组(数据报)传输给另一内核。
一般地,网络通信协议可以表征为可靠的和非可靠的。表征为可靠的协议(例如,tcp/ip)确保由发送者传输的数据到达预期的接收者。这样的协议可以通知发送者传输是否失败(例如,分组是否被丢掉)。然而,可靠的协议通常因确定分组是否被成功地递送并且返回关于递送的通知而招致开销。因此,在通过tcp/ip发送数据时的操作成本牵涉附加的等待时间。相比而言,表征为非可靠的协议(例如,udp)不通知发送者传输是否失败。然而,因为非可靠协议一般不具有(另外由可靠协议提供的)误差检查与纠正机制,所以这样的协议招致较少的开销并且因此比可靠协议更加可扩展。可靠协议常常在其中分组丢失的可能性相对高的实例中更合期望,诸如在其中系统(例如,系统1610)中的资源和网络利用高的实例中更合期望。相反地,非可靠协议可以用在其中分组丢失的可能性相对低的实例中,诸如其中资源和网络利用低的实例中。
如本文中进一步描述的,本公开的实施例提供了用于基于系统1610中所观察到的遥测而针对网络通信(例如,内核到内核通信)在可靠协议到非可靠协议之间动态地转换(并且反之亦然)的技术。更具体地,系统1610中的加速器设备(例如,加速器设备1642、1652或1662)可以包括用来接收(或监视)部分地涉及用于内核到内核链路的网络利用的遥测数据的逻辑。遥测数据可以包括特性,诸如内核之间的通信中的等待时间、吞吐量、(多个)底层加速器设备上的目前负荷等。加速器设备可以对照策略的一个或多个条件来评估遥测数据以确定是否要将目前的网络通信协议转换(例如,改变)成另一网络通信协议。例如,假设内核a目前正使用udp协议向内核b传送数据。加速器设备可以观察到指示内核a和内核b之间的网络利用的遥测数据超过某一阈值,其触发策略中的条件。因为可靠协议可以更加适于其中网络利用高的情况,所以策略可以指定从udp改变成可靠协议,诸如tcp/ip。
进一步地,随着时间的过去,加速器设备可以根据时间来学习遥测数据的模式以预测用于从一个网络通信协议向另一个改变的实例。例如,加速器设备可以使用所观察到的遥测和时间数据作为输入来执行多种机器学习技术以生成预测数据。基于随后观察到的遥测数据,预测数据可以指示用于给定的内核链路的网络通信应当从一个内核转换到另一个的可能性。
现在参考图17,加速器滑板1700可以体现为能够执行本文中描述的功能的任何类型的计算设备,所述功能包括监视与经加速的内核之间的网络通信相关联的遥测数据、根据所监视的遥测数据来确定要将网络通信从给定的通信协议转换(例如,改变)成另一通信协议的条件被触发,并且将网络通信改变到其它通信协议。加速器滑板1700可以代表在图16中描绘的加速器滑板1640、1650或1660中的任何加速器滑板。
如图17中所示,加速器滑板1700包括计算引擎1702、i/o子系统1708、通信电路1710、一个或多个数据存储设备1714以及一个或多个加速器设备1718。当然,在其它实施例中,加速器滑板1700可以包括其它或者附加的组件,诸如在计算机中通常找到的那些(例如,显示器、外围设备等)。附加地,在一些实施例中,说明性组件中的一个或多个可以被合并在另一组件中或者以其它方式形成另一组件的部分。
计算引擎1702可以体现为能够执行下文描述的各种计算功能的任何类型的设备或者设备的集合。在一些实施例中,计算引擎1702可以体现为单个设备,诸如集成电路、嵌入式系统、fpga、片上系统(soc)或者其它集成系统或设备。附加地,在一些实施例中,计算引擎1702包括或者体现为处理器1704和存储器1706。处理器1704可以体现为能够执行本文中描述的功能的任何类型的处理器。例如,处理器1704可以体现为(多个)单核或多核处理器、微控制器或者其它处理器或处理/控制电路。在一些实施例中,处理器1704可以体现为、包括或者耦合到fpga、asic、可再配置的硬件或硬件电路、或者其它专门的硬件,用来促进本文中描述的功能的执行。
存储器1706可以体现为能够执行本文中描述的功能的任何类型的易失性存储器(例如,动态随机存取存储器(dram)等)或者非易失性存储器或数据储存器。易失性存储器可以是要求电力来维持由介质存储的数据的状态的存储介质。易失性存储器的非限制性示例可以包括各种类型的随机存取存储器(ram),诸如dram或静态随机存取存储器(sram)。可以在存储器模块中使用的一个特定类型的dram是同步动态随机存取存储器(sdram)。在特定实施例中,存储器组件的dram可以遵从由jedec颁布的标准,诸如用于ddrsdram的jesd79f、用于ddr2sdram的jesd79-2f、用于ddr3sdram的jesd79-3f、用于ddr4sdram的jesd79-4a、用于低功率ddr(lpddr)的jesd209、用于lpddr2的jesd209-2、用于lpddr3的jesd209-3以及用于lpddr4的jesd209-4(这些标准在www.jedec.org处可获得)。这样的标准(以及类似的标准)可以被称为基于ddr的标准,并且实现这样的标准的存储设备的通信接口可以被称为基于ddr的接口。
在一个实施例中,存储器设备是块可寻址存储器设备,诸如基于nand或nor技术的那些。存储器设备还可以包括未来一代非易失性设备,诸如三维交叉点存储器设备(例如,英特尔3dxpointtm存储器)或其它字节可寻址的在适当的位置写入的非易失性存储器设备。在一个实施例中,存储器设备可以是或者可以包括使用硫属化物玻璃的存储器设备,多阈值水平nand闪速存储器,nor闪速存储器,单或多级相变存储器(pcm),电阻存储器,纳米线存储器,铁电晶体管随机存取存储器(fetram),反铁电存储器,合并忆阻器技术的磁阻随机存取存储器(mram)存储器,包括金属氧化物基底、氧空位基底和传导桥随机存取存储器(cb-ram)的电阻存储器,或者自旋转移扭矩(stt)-mram,基于自旋电子磁结存储器的设备,基于磁隧道结(mtj)的设备,基于dw(畴壁)和sot(自旋轨道转移)的设备,基于半导体闸流管的存储器设备,或上文中的任何存储器设备的组合,或者其它存储器。存储器设备可以是指管芯本身和/或经封装的存储器产品。
在一些实施例中,3d交叉点存储器(例如,英特尔3dxpointtm存储器)可以包括无晶体管的可堆叠交叉点架构,其中存储器单元位于字线和位线的交叉处且可被单独地寻址并且其中位存储基于体电阻中的改变。在一些实施例中,存储器1706的全部或部分可以集成到处理器1704中。在操作中,存储器1706可以存储在操作期间使用的各种软件和数据。
计算引擎1702经由i/o子系统1708与加速器滑板1700的其它组件通信地耦合,所述i/o子系统1708可以体现为用来利用计算引擎1702(例如,利用处理器1704和/或存储器1706)和加速器滑板1700的其它组件促进输入/输出操作的电路和/或组件。例如,i/o子系统1708可以体现为或者以其它方式包括存储器控制器中枢、输入/输出控制中枢、集成传感器中枢、固件设备、通信链路(例如,点对点链路、总线链路、导线、线缆、光导、印刷电路板迹线等)和/或用来促进输入/输出操作的其它组件和子系统。在一些实施例中,i/o子系统1708可以形成片上系统(soc)的部分并且连同处理器1704、存储器1706和加速器滑板1700的其它组件中的一个或多个被合并到计算引擎1702中。
通信电路1710可以体现为能够使得能实现加速器滑板1700与另一计算设备(例如,计算滑板1630,加速器滑板1640、1650和1660等)之间的通过网络1612的通信的任何通信电路、设备或其集合。通信电路1710可以被配置成使用任何一个或多个通信技术(例如,有线或无线通信)和相关联的协议(例如,以太网、蓝牙®、wi-fi®、wimax等)来实现这样的通信。
说明性通信电路1710包括网络接口控制器(nic)1712,其还可以被称为主机结构接口(hfi)。nic1712可以体现为一个或多个内插板、子卡、网络接口卡、控制器芯片、芯片组、或者可以由加速器滑板1700使用以与另一计算设备(例如,编排器服务器1620,计算滑板1630,加速器滑板1640、1650和1660等)连接的其它设备。在一些实施例中,nic1712可以体现为包括一个或多个处理器的片上系统(soc)的部分,或者被包括在也包含一个或多个处理器的多芯片封装上。在一些实施例中,nic1712可以包括(未示出的)本地处理器和/或(未示出的)本地存储器,其二者对nic1712而言都是本地的。在这样的实施例中,nic1712的本地处理器可以能够执行本文中描述的计算引擎1702的功能中的一个或多个。附加地或者替代地,在这样的实施例中,nic1712的本地存储器可以在板级别、插座级别、芯片级别和/或其它级别处集成到加速器滑板1700的一个或多个组件中。
所述一个或多个说明性数据存储设备1714可以体现为被配置用于数据的短期或长期存储的任何类型的设备,诸如例如存储器设备和电路、存储器卡、硬盘驱动器(hdd)、固态驱动器(ssd)或其它数据存储设备。每一个数据存储设备1714可以包括存储用于数据存储设备1714的数据和固件代码的系统分区。每一个数据存储设备1714还可以包括存储用于操作系统的数据文件和可执行文件的操作系统分区。
加速器设备1718可以代表在图16中描绘的系统1610中的加速器设备,诸如加速器设备1642、1652或1662的任何组合。加速器设备1718可以形成加速器子系统,其在加速器滑板1700中的加速器设备之间包括一个或多个总线或其它接口,以使得加速器设备能够共享数据。进一步地,每一个加速器设备1718可以基于由编排器服务器1620限定的内核配置、经由nic1712向系统1610中的其它加速器设备发送数据。每一个加速器设备1718可以体现为能够使功能的执行加速的任何设备或电路(例如,专门的处理器、fpga、asic、gpu、可再配置的硬件等)。
附加地或者替代地,加速器滑板1700可以包括一个或多个外围设备1716。这样的外围设备1716可以包括在计算设备中通常找到的任何类型的外围设备,诸如显示器、扬声器、鼠标、键盘和/或其它输入/输出设备、接口设备和/或其它外围设备。
编排器服务器1620、客户端设备1614和计算滑板1630可以具有与相对于图17描述的那些类似的组件。加速器滑板1700的那些组件的描述等同地适用于那些设备的组件的描述,并且为了描述的清楚而不在本文中进行重复。进一步地,应当领会,客户端设备1614、编排器服务器1620以及滑板1630、1640、1650和1660中的任何可以包括在计算设备中通常找到的其它组件、子组件和设备,其没有在上文中参考加速器滑板1700进行讨论并且为了描述的清楚没有在本文中讨论。
如上文所描述的,客户端设备1614、编排器服务器1620以及滑板1630、1640、1650和1660说明性地经由网络1612通信,所述网络1612可以体现为任何类型的有线或无线通信网络,包括全球网络(例如,因特网)、局域网(lan)或广域网(wan)、蜂窝网络(例如,全球移动通信系统(gsm)、3g、长期演进(lte)、全球微波接入互操作性(wimax)等)、数字订户线(dsl)网络、线缆网络(例如,同轴网络、光纤网络等)或其任何组合。
现在参考图18,加速器滑板1700可以在操作期间建立环境1800。当然,加速器滑板1640、1650、1660中的任何加速器滑板可以类似地在操作期间建立环境1800。说明性地,环境1800包括网络通信器1820和协议管理器1830。环境1800的组件中的每一个可以体现为硬件、固件、软件或其组合。照此,在一些实施例中,环境1800的组件中的一个或多个可以体现为电路或者电气设备的集合(例如,网络通信器电路1820、协议管理器电路1830等)。应当领会,在这样的实施例中,网络通信器电路1820或协议管理器电路1830中的一个或多个可以形成计算引擎1702、通信电路1710、i/o子系统1708、加速器设备1718和/或加速器滑板1700的其它组件中的一个或多个的部分。如所示,环境1800包括内核配置数据1802,其可以体现为指示相对于工作负荷的流的系统1610中的内核配置的映射的任何数据。内核配置数据1802还可以指示由系统1610中的内核到内核链路使用的网络通信协议。进一步地,环境1800包括策略数据1804,其可以体现为指示协议改变策略的任何数据,其包括根据所监视的资源和网络利用来评估的一个或多个改变条件。进一步地,环境1800包括遥测数据1806,其可以体现为指示加速器滑板1700、加速器设备1718以及系统1610的其它加速器滑板和设备的所观察到的性能的任何数据(例如,功率消耗、内核连接的量、等待时间、连接的平均时段、每一连接所传递的数据的量等)。更进一步地,环境1800包括预测数据1808,其可以体现为指示基于随后观察到的遥测数据1806而触发协议改变策略条件的可能性的任何数据。
网络通信器1820,其如上文所讨论的那样可以体现为硬件、固件、软件、虚拟化硬件、所模拟的架构和/或其组合,被配置成分别促进到和来自加速器滑板1700的进站和出站网络通信(例如,网络业务、网络分组、网络流等)。为了这么做,网络通信器1820被配置成接收和处理来自一个系统或计算设备(例如,加速器滑板1640、1650或1660)的数据分组,并且准备且发送数据分组给另一计算设备或系统(例如,计算滑板1630或者其它加速器滑板1640、1650或1660)。相应地,在一些实施例中,网络通信器1820的功能性的至少一部分可以由通信电路1710来执行并且在说明性实施例中由nic1712来执行。
协议管理器1830,其可以体现为硬件、固件、软件、虚拟化硬件、所模拟的架构和/或其组合的,被配置成监视与内核和另一内核之间的一个或多个网络通信相关联的遥测数据1806,其中网络通信被经由给定的通信协议建立。协议管理器1830还被配置成根据所监视的遥测数据1806来确定将网络通信从目前通信协议改变成另一通信协议的策略数据1804中的条件被触发。协议管理器1830还被配置成将内核之间的网络通信改变到其它通信协议。如所示,协议管理器1830包括监视器组件1832、选择器组件1834、配置组件1836和预测器组件1838。
在一些实施例中,监视器组件1832被配置成获取与给定内核和另一内核之间的网络信道相关联的遥测数据1806。更具体地,被配置在给定的加速器设备1818内的内核可以与另一内核互连。另一内核可以配置有相同的加速器设备1818或者系统1610中的另一加速器设备。内核可以通过多种方案互连。例如,假设另一内核被配置在滑板1700上的加速器设备上。内核可以经由nic1712与彼此通信。作为另一示例,另一内核可能被配置在系统1610中的另一加速器滑板上。在这样的情况下,内核可以经由将该滑板与滑板1300互连的系统1610中的交换机设备进行互连。监视器组件1832可以从nic1712或者系统1610中的交换机设备获取涉及内核之间的链路的遥测。例如,资源监视器可以驻留在nic1712或交换机设备中,并且获取关于性能和利用的原始度量并且将度量发送给监视器组件1832。继而,监视器组件1832接收原始度量并且可以对度量进行归一化以生成遥测数据1806。对度量进行归一化可以牵涉将原始度量转换成可以由协议管理器1830进一步评估的值和类型。在其它实施例中,监视器组件1832也被配置成获取与系统1610相关联的遥测数据1806,诸如系统1610上的目前负荷、内核连接之间的平均网络利用、内核连接中的平均分组丢失等。
在一些实施例中,选择器组件1834被配置成基于对遥测数据1806的评估来确定是否要将关于加速器设备1818配置的内核与另一内核之间的网络通信转换(例如,改变)到不同的协议。例如,假设内核a和内核b之间的网络通信目前经由非可靠协议(诸如udp)执行。选择器组件1834可以相对于策略数据1804来评估遥测数据1806以确定用于改变成可靠协议(诸如tcp/ip)的一个或多个条件是否被触发。例如,策略数据1804可以指定以下条件:如果内核之间的网络利用超过指定阈值,则内核之间的通信应当经由可靠协议来执行,以确保不管由可靠协议的使用产生的任何附加等待时间如何,内核b都接收数据。
在一些实施例中,配置组件1836被配置成将内核之间的网络通信改变到不同的协议,如果选择器组件1834确认是这样的话。配置组件1836可以修改内核配置数据1802以指示其针对加速器设备1818上的给定内核与另一内核之间的链路要使用不同的协议来执行,如由选择器组件1834所确定的。配置组件1836还可以将协议中的改变通知编排器服务器1620。为了这么做,配置组件1836可以向编排器服务器1620发送标识内核、内核被配置在其上的加速器设备以及协议的消息。作为响应,编排器服务器1620可以将更新传播给系统1610中的其它滑板和网络设备。
在一些实施例中,预测器组件1838被配置成基于遥测数据1806来学习一个或多个模式并且随着时间的过去在协议之间改变,以更早地标识其中将执行给定协议向另一个之间的改变的实例。例如,预测器组件1838可以执行多种机器学习算法(例如,基于优化的机器学习算法、预测算法等),并且接收涉及给定内核到内核网络链路和系统1610的遥测数据1806作为输入。预测器组件1838还可以接收时间戳输入,其限定其中网络链路从一个通信协议改变成另一个的实例和时段。机器学习算法因此可以生成预测数据1808。选择器组件1834可以被进一步配置成在确定是否要针对给定内核到内核链路而改变成不同的网络通信协议时评估预测数据1808。例如,选择器组件1834可以从监视器组件1832检索随后收集的遥测数据1806。选择器组件1834可以将遥测数据1806输入到机器学习算法,其可以对照预测数据1808来评估遥测数据1806。结果可以指示是否要将目前配置的网络通信协议改变成另一网络通信协议。
进一步地,预测器组件1838可以包括多种预测算法并且基于关于每一个算法的遥测数据1806的执行而提供算法的排名以用于选择。例如,排名可以基于每一个算法的结果朝向可能的最佳结果聚集的百分比。一旦选择被提供,预测器组件1838就可以在随后的计算中继续使用所选择的算法。
现在参考图19a和19b,示出了内核到内核通信网络的示例实施例的图。特别地,图19a和19b图示了其中可以实现用于动态地适配可靠和非可靠的网络通信协议的技术的内核到内核通信网络。图19a描绘了系统1610中的各种内核之间的相互通信。特别地,图19a包括加速器滑板1902和1912,其代表系统1610中的加速器滑板1640、1650、1660或1700中的任何加速器滑板。加速器滑板1902提供加速器设备1903和1907,并且加速器滑板1912提供加速器设备1913。进一步地,加速器设备中的每一个包括用于加载一个或多个经加速的内核的一个或多个插槽。例如,加速器设备1903包括插槽1904,加速器设备1907包括插槽1908,并且加速器设备1913包括插槽a1914和插槽b1917。更进一步地,插槽中的每一个配置有经加速的内核。说明性地,插槽1904配置有内核a1905和内核b1906;插槽1908配置有内核c1909和内核d1910;插槽a1914配置有内核e1915和内核f1916;并且插槽b配置有内核g1918和内核h1919。
如由双向箭头所指示的,内核中的每一个可以经由系统1610所暴露的内核到内核网络而与彼此通信。特别地,系统1610可以提供内核网络配置,所述内核网络配置使加速器滑板1902和1912中的每一个中包括nic并且包括将加速器滑板1902和1912与彼此互连的网络设备(例如,网络交换机)。编排器服务器1620可以配置nic和网络设备中的每一个,使得给定内核根据工作负荷流向另一内核发送数据。nic和网络设备可以形成编排器子系统接口,所述编排器子系统接口将包括内核的加速器设备的组件与彼此连接以形成内核到内核网络。加速器子系统接口可以暴露允许内核标识并且在网络中与彼此通信的虚拟地址空间。
图19b图示了内核a1905与内核b1906、c1909和h1919之间的通信的抽象。内核a1905可以通过网络1920(例如,上文描述的加速器子系统)通信。例如,内核b1906、c1909和h1919可以表示内核a1905依照工作负荷执行的部分将经处理的数据向下游传输到的内核。说明性地,内核a1905可以经由tcp/ip或udp与内核中的每一个互连。可以根据与链路相关联的资源和网络利用来确定用于给定内核到内核链路的网络通信协议。例如,内核a1905和内核b1906经由udp互连。使用udp可以指示具有相对低利用的网络链路。在这样的利用下,分组较不可能被丢掉,并且因此分组丢失检测机制较不必要。相比而言,内核a经由tcp/ip与内核c1909和内核h1919互连。使用tcp/ip可以指示具有相对高网络利用的网络链路。在这样的利用下,分组更可能被丢掉,并且因此提供分组丢失检测机制的tcp/tp可能更合期望。
现在参考图20,加速器滑板1700在操作中可以执行方法2000以使通信协议适配端点(例如,内核端点)之间的网络连接。当然,加速器滑板1640、1650和1660也可以执行方法2000。如所示,方法2000在框2002中开始,其中加速器滑板1700经由给定的网络通信协议、在被配置于其上(例如,在加速器设备1718中)的内核与系统1610中的另一内核之间建立网络通信。例如,加速器滑板1700可以通过评估内核配置(例如,内核配置数据1802)以确定要用于内核与另一内核之间的通信链路的目前指定的网络通信协议来这么做。内核配置数据1802可以指定目前协议是可靠协议(例如,tcp/ip)还是非可靠协议(例如,udp)。
在框2004中,加速器滑板1700监视与所建立的通信相关联的遥测数据。例如,加速器滑板1700可以从nic1712以及将内核与彼此互连的其它网络组件收集原始度量。一旦收集到,加速器滑板1700就可以进一步处理度量以用于评估。在框2006中,加速器滑板1700确定改变条件是否被触发。为了这么做,加速器滑板1700可以相对于策略数据来评估遥测数据以用于在给定的网络通信协议和另一个之间改变。例如,在策略中指定的改变条件可以指示,如果在遥测数据中所观察到的网络利用超过预定义的阈值,则从udp改变成tcp/ip。如果策略中的条件没有被触发,则方法2000返回到框2004,并且加速器滑板1700继续监视遥测数据。
否则,如果策略中的改变条件被触发,则在框2008中,加速器滑板1700改变在内核之间的通信中使用的网络通信协议。特别地,在框2010中,加速器滑板1700相对于策略来评估所监视的遥测数据和目前使用的用于内核到内核链路的协议。在框2012中,加速器滑板1700根据策略来确定要改变成可靠协议(例如,tcp/ip)还是非可靠协议(udp)。例如,策略可以指定,如果目前使用的协议是非可靠协议并且网络带宽在指定的持续时间内超过指定阈值,则将网络通信协议改变成可靠协议。作为另一示例,策略可以指定,如果目前使用的协议是可靠协议并且平均分组丢失在指定的持续时间内落至指定阈值以下,则将网络通信协议改变成非可靠协议。
在框2014中,加速器滑板1700基于所述确定来修改内核到内核链路的配置。例如,加速器滑板1700可以通过访问本地存储的配置(例如,内核配置数据1802)以及将配置修改成指示用于内核链路的协议来这么做。进一步地,加速器滑板1700可以通知编排器服务器1620将用于内核链路的通信协议中的改变。因此,编排器服务器1620可以传播对系统1610中的其它加速器滑板的配置的改变以保留完整性。在框2016中,加速器滑板1700使用基于策略所确定的协议来在内核之间建立随后的网络通信。
现在参考图21,加速器滑板1700在操作中可以应用机器学习技术以确定是否要在非可靠协议和可靠协议之间改变(并且反之亦然)。在框2018中,加速器滑板1700基于所监视的遥测数据来学习一个或多个改变模式。例如,在框2020中,加速器滑板1700相对于加速器滑板1700从通信协议改变成另一个的(例如,如由时间戳指示的)给定时间点来评估与内核到内核链路相关联的所监视的遥测数据。在框2022中,加速器滑板1700根据所评估的遥测数据和时间来标识模式。例如,加速器滑板1700可以标识其中加速器滑板1700改变到另一网络通信协议的前一时间点处的遥测值的元组。加速器滑板1700可以标识其中遥测值的元组触发向另一协议的改变的附加时间点。所标识的时间点可以指示与向另一协议的改变相关的模式。
在框2024中,加速器滑板1700基于所述一个或多个所学习的模式来生成预测数据。预测数据指示基于随后观察到的遥测数据1806而触发要从一个协议改变成另一协议的策略条件的可能性。预测数据可以减少在改变成另一协议之前实际观察到的遥测数据的量,并且因此改进网络利用。在框2026中,加速器滑板1700使用预测数据来确定从网络通信协议向另一协议的随后改变。例如,加速器滑板1700可以返回到方法2000的开始,并且除了相对于策略来评估随后监视的遥测数据之外,加速器滑板1700还可以进一步相对于预测数据来评估遥测数据。例如,加速器滑板1700可以在将不会以其它方式触发改变条件的工作负荷的执行中的给定时间点处观察遥测数据的给定元组。然而,加速器滑板1700可以在对照预测的评估之后将元组标识为模式的开始,从而导致协议之间的改变。一旦被标识,加速器滑板1700就可以抢先改变协议。
示例
下文提供了本文中公开的技术的说明性示例。技术的实施例可以包括下文描述的示例中的任何一个或多个以及任何组合。
示例1包括一种滑板,所述滑板包括计算引擎,所述计算引擎要监视与滑板的第一内核和被配置在第二滑板上的第二内核之间的一个或多个网络通信相关联的遥测数据,其中所述一个或多个网络通信经由第一通信协议来建立,根据所监视的遥测数据来确定要将网络通信从第一通信协议改变成第二通信协议的条件被触发,并且将网络通信从第一通信协议改变成第二通信协议。
示例2包括示例1的主题,并且其中要将网络通信从第一通信协议改变成第二通信协议包括要使用第二通信协议在第一内核和第二内核之间建立随后的网络通信。
示例3包括示例1和2中的任何示例的主题,并且其中根据策略和所监视的遥测数据来确定第二通信协议,其中策略限定用于从给定的网络通信协议改变成另一网络通信协议的多个条件。
示例4包括示例1-3中的任何示例的主题,并且其中第二通信协议对应于tcp/ip(传输控制协议/因特网协议)或udp(用户数据报协议)中的一个。
示例5包括示例1-4中的任何示例的主题,并且其中计算引擎进一步要从所监视的遥测数据学习一个或多个改变模式,其中每一个改变模式限定随着时间的过去所观察到的遥测数据。
示例6包括示例1-5中的任何示例的主题,并且其中计算引擎进一步要基于所学习的一个或多个改变模式来生成预测数据,其中预测数据指示以下的可能性:基于随后监视的遥测数据,网络通信要从第一通信协议转换成第二通信协议,或者网络通信要从第二通信协议转换成第一通信协议。
示例7包括示例1-6中的任何示例的主题,并且其中要确定要改变网络通信的条件被触发是进一步根据预测数据来确定的。
示例8包括示例1-7中的任何示例的主题,并且其中要从所监视的遥测数据学习一个或多个改变模式包括要随着时间的过去评估与内核网络连接相关联的遥测数据;以及基于该评估来标识改变模式。
示例9包括示例1-8中的任何示例的主题,并且其中计算引擎进一步要经由机器学习技术来生成预测数据。
示例10包括示例1-9中的任何示例的主题,并且其中计算引擎进一步要经由一个或多个机器学习技术来生成预测数据;并且根据所述多个机器学习技术中的每一个对预测数据进行排名。
示例11包括示例1-10中的任何示例的主题,并且其中遥测数据包括分组丢失率、网络连接的总量、网络连接的吞吐量以及网络连接的等待时间中的至少一个。
示例12包括示例1-11中的任何示例的主题,并且其中计算引擎进一步要监视与第一内核和第三内核之间的一个或多个网络连接相关联的遥测数据,其中第一内核和第三内核之间的所述一个或多个网络连接经由第二通信协议来建立。
示例13包括示例1-12中的任何示例的主题,并且其中计算引擎进一步要根据所监视的遥测数据将第一内核和第三内核之间的网络通信改变到第一通信协议。
示例14包括示例1-13中的任何示例的主题,并且其中要改变网络通信的条件是第一内核和第二内核之间的网络利用超过指定阈值的指示。
示例15包括一种方法,所述方法包括监视与滑板的第一内核和被配置在第二滑板上的第二内核之间的一个或多个网络通信相关联的遥测数据,其中所述一个或多个网络通信经由第一通信协议来建立,根据所监视的遥测数据来确定要将网络通信从第一通信协议改变成第二通信协议的条件被触发,以及将网络通信从第一通信协议改变成第二通信协议。
示例16包括示例15的主题,并且其中将网络通信从第一通信协议改变成第二通信协议包括使用第二通信协议在第一内核和第二内核之间建立随后的网络通信。
示例17包括示例15和16中的任何示例的主题,并且其中根据策略和所监视的遥测数据来确定第二通信协议,其中策略限定用于从给定的网络通信协议改变成另一网络通信协议的多个条件。
示例18包括示例15-17中的任何示例的主题,并且其中第二通信协议对应于tcp/ip(传输控制协议/因特网协议)或udp(用户数据报协议)中的一个。
示例19包括示例15-18中的任何示例的主题,并且进一步包括从所监视的遥测数据学习一个或多个改变模式,其中每一个改变模式限定随着时间的过去所观察到的遥测数据。
示例20包括示例15-19中的任何示例的主题,并且进一步包括基于所学习的一个或多个改变模式来生成预测数据,其中预测数据指示以下的可能性:基于随后监视的遥测数据,网络通信要从第一通信协议转换成第二通信协议,或者网络通信要从第二通信协议转换成第一通信协议。
示例21包括示例15-20中的任何示例的主题,并且其中确定要改变网络通信的条件被触发是进一步根据预测数据来确定的。
示例22包括示例15-21中的任何示例的主题,并且其中从所监视的遥测数据学习一个或多个改变模式包括随着时间的过去评估与内核网络连接相关联的遥测数据;以及基于该评估来标识模式。
示例23包括示例15-22中的任何示例的主题,并且进一步包括经由机器学习技术来生成预测数据。
示例24包括示例15-23中的任何示例的主题,并且进一步包括经由一个或多个机器学习技术来生成预测数据;以及根据所述多个机器学习技术中的每一个对预测数据进行排名。
示例25包括示例15-24中的任何示例的主题,并且其中遥测数据包括分组丢失率、网络连接的总量、网络连接的吞吐量以及网络连接的等待时间中的至少一个。
示例26包括示例15-25中的任何示例的主题,并且进一步包括监视与第一内核和第三内核之间的一个或多个网络连接相关联的遥测数据,其中第一内核和第三内核之间的所述一个或多个网络连接经由第二通信协议来建立。
示例27包括示例15-26中的任何示例的主题,并且进一步包括根据所监视的遥测数据将第一内核和第三内核之间的网络通信改变到第一通信协议。
示例28包括一种或多种机器可读存储介质,所述一种或多种机器可读存储介质包括存储在其上的多个指令,所述多个指令响应于被执行而使滑板实行示例15-27中的任何示例的方法。
示例29包括一种滑板,所述滑板包括用于执行示例15-27中的任何示例的方法的部件。
示例30包括一种滑板,所述滑板包括要执行示例15-17中的任何示例的方法的计算引擎。
示例31包括一种滑板,所述滑板包括协议管理器电路,所述协议管理器电路要监视与该滑板的第一内核和被配置在第二滑板上的第二内核之间的一个或多个网络通信相关联的遥测数据,其中所述一个或多个网络通信经由第一通信协议来建立,根据所监视的遥测数据来确定要将网络通信从第一通信协议改变成第二通信协议的条件被触发,并且将网络通信从第一通信协议改变成第二通信协议。
示例32包括示例31的主题,并且其中要将网络通信从第一通信协议改变成第二通信协议包括要使用第二通信协议在第一内核和第二内核之间建立随后的网络通信。
示例33包括示例31和32中的任何示例的主题,并且其中根据策略和所监视的遥测数据来确定第二通信协议,其中策略限定用于从给定的网络通信协议改变成另一网络通信协议的多个条件。
示例34包括示例31-33中的任何示例的主题,并且其中第二通信协议对应于tcp/ip(传输控制协议/因特网协议)或udp(用户数据报协议)中的一个。
示例35包括示例31-34中的任何示例的主题,并且其中协议管理器电路进一步要从所监视的遥测数据学习一个或多个改变模式,其中每一个改变模式限定随着时间的过去所观察到的遥测数据。
示例36包括示例31-35中的任何示例的主题,并且其中协议管理器电路进一步要基于所学习的一个或多个改变模式来生成预测数据,其中预测数据指示以下的可能性:基于随后监视的遥测数据,网络通信要从第一通信协议转换成第二通信协议,或者网络通信要从第二通信协议转换成第一通信协议。
示例37包括示例31-36中的任何示例的主题,并且其中要确定要改变网络通信的条件被触发是进一步根据预测数据来确定的。
示例38包括示例31-37中的任何示例的主题,并且其中要从所监视的遥测数据学习一个或多个改变模式包括要随着时间的过去评估与内核网络连接相关联的遥测数据;以及基于该评估来标识改变模式。
示例39包括示例31-38中的任何示例的主题,并且其中协议管理器电路进一步要经由机器学习技术来生成预测数据。
示例40包括示例31-39中的任何示例的主题,并且其中协议管理器电路进一步要经由一个或多个机器学习技术来生成预测数据;并且根据所述多个机器学习技术中的每一个对预测数据进行排名。
示例41包括示例31-40中的任何示例的主题,并且其中遥测数据包括分组丢失率、网络连接的总量、网络连接的吞吐量以及网络连接的等待时间中的至少一个。
示例42包括示例31-41中的任何示例的主题,并且其中协议管理器电路进一步要监视与第一内核和第三内核之间的一个或多个网络连接相关联的遥测数据,其中第一内核和第三内核之间的所述一个或多个网络连接经由第二通信协议来建立。
示例43包括示例31-42中的任何示例的主题,并且其中协议管理器电路进一步要根据所监视的遥测数据将第一内核和第三内核之间的网络通信改变到第一通信协议。
示例44包括示例31-43中的任何示例的主题,并且其中要改变网络通信的条件是第一内核和第二内核之间的网络利用超过指定阈值的指示。
示例45包括一种滑板,所述滑板包括用于监视与滑板的第一内核和被配置在第二滑板上的第二内核之间的一个或多个网络通信相关联的遥测数据的电路,其中所述一个或多个网络通信经由第一通信协议来建立,用于根据所监视的遥测数据来确定要将网络通信从第一通信协议改变成第二通信协议的条件被触发的部件,以及用于将网络通信从第一通信协议改变成第二通信协议的部件。
示例46包括示例45的主题,并且其中用于将网络通信从第一通信协议改变成第二通信协议的部件包括用于使用第二通信协议在第一内核和第二内核之间建立随后的网络通信的电路。
示例47包括示例45和46中的任何示例的主题,并且其中根据策略和所监视的遥测数据来确定第二通信协议,其中策略限定用于从给定的网络通信协议改变成另一网络通信协议的多个条件。
示例48包括示例45-47中的任何示例的主题,并且其中第二通信协议对应于tcp/ip(传输控制协议/因特网协议)或udp(用户数据报协议)中的一个。
示例49包括示例45-48中的任何示例的主题,并且进一步包括用于从所监视的遥测数据学习一个或多个改变模式的部件,其中每一个改变模式限定随着时间的过去所观察到的遥测数据。
示例50包括示例45-49中的任何示例的主题,并且进一步包括用于基于所学习的一个或多个改变模式来生成预测数据的部件,其中预测数据指示以下的可能性:基于随后监视的遥测数据,网络通信要从第一通信协议转换成第二通信协议,或者网络通信要从第二通信协议转换成第一通信协议。
示例51包括示例45-50中的任何示例的主题,并且其中进一步根据预测数据来确定用于确定要改变网络通信的条件被触发的部件。
示例52包括示例45-51中的任何示例的主题,并且其中用于从所监视的遥测数据学习一个或多个改变模式的部件包括用于随着时间的过去评估与内核网络连接相关联的遥测数据的电路;以及用于基于该评估来标识模式的电路。
示例53包括示例45-52中的任何示例的主题,并且进一步包括用于经由机器学习技术来生成预测数据的部件。
示例54包括示例45-53中的任何示例的主题,并且进一步包括用于经由一个或多个机器学习技术来生成预测数据的部件;以及用于根据所述多个机器学习技术中的每一个对预测数据进行排名的部件。
示例55包括示例45-54中的任何示例的主题,并且其中遥测数据包括分组丢失率、网络连接的总量、网络连接的吞吐量以及网络连接的等待时间中的至少一个。
示例56包括示例45-55中的任何示例的主题,并且进一步包括用于监视与第一内核和第三内核之间的一个或多个网络连接相关联的遥测数据的电路,其中第一内核和第三内核之间的所述一个或多个网络连接经由第二通信协议来建立。
示例57包括示例45-56中的任何示例的主题,并且进一步包括用于根据所监视的遥测数据将第一内核和第三内核之间的网络通信改变到第一通信协议的部件。
- 还没有人留言评论。精彩留言会获得点赞!